概要
この記事では Oracle Cloud の Always Free Cloud Services によって利用可能な Autonomoud Database を利用して、AutoML UI を活用して有馬記念の着順を機械学習で予測する手順をチュートリアル形式でご紹介します。
一般的に有償であることの多いAutoMLが無償で利用できるので、ちょっと予測したいデータがある場合に気軽に試すことができます。
ボリュームが多いので、前半と後半に記事を分けています。
後半は以下のリンクからアクセスできます。
無料で始めるAutoML超入門 ~有馬記念で1位を予測する~(後編)
所要時間と必要なスキル
所要時間は学習する内容によりますが、データが手元にある場合は2時間程度で環境の用意からモデルの作成、予測結果の取得までできます。
必要なスキルは不要ですが、SQLの基礎とPythonの基礎が分かっていると理解が早いと思います。
全体の流れ
以下の流れとなります。
- 学習データの取得と整形
- テストデータの作成
- Oracle Cloud の無料トライアル申し込み ~ 仮想ネットワーク(VCN)の作成
- Autonomous Databaseの構築(Always Free)
- 機械学習用のユーザー作成と権限の付与
- 学習データのロード
- AutoML UIによるモデル作成
- 着順の予測
- 着順スコアの予測
- 実際の結果
前半の記事では 1~6 を記載します。
学習元のデータの取得と整形
学習データの取得
JRA-VANデータラボ の無料体験に登録することで、登録後1か月間は無料でデータのアクセスができます。
私は TARGET frontier JV というソフトを利用して、2019/1以降のデータをCSV形式で抽出しました。
また、今回はあくまで動きをみるということで、当日走ってみなければわからないPCIなどの情報も取得していますが、よくわからないという方はとりあえずレースの距離などの情報、馬の名前や性別、毛色、馬番や馬枠、馬の体重や斤量、騎手、人気や単勝オッズ、などの情報に絞るのが良いかもしれません。
これらの情報であれば、当日の出走データから抽出ができます。
慣れてきた場合はいろんな情報を取得して分析に役立てていただくのが良いと思いますが、最初はJRA-VANから取得する情報で明らかに予測する上で関係なさそうという情報はダウンロードせず、まず予想モデルを作って適用するという練習をするのが良いと思います。
学習データの特徴量追加
機械学習と言えば分析に役立ちそうな特徴量を追加することで精度を上げることができます。
今回は競馬新聞などに記載されている「前回の着順」「前々回の着順」「3回前の着順」を追加しました。
データ量がそれほど多くなかったので、私はExcelを駆使してデータを作りました。
SQLが得意な方はDBにデータを入れた後でPL/SQLを駆使して作っていただくのも良いですし、Pythonが得意ということでしたら後半のステップで出てくるnotebookでpythonを使ってテーブルを作ったり列を追加したりもできます。
また、特徴量から着順を予測するのは難しそうだと思ったので、1位を予測するために着順スコア列を用意しました。
- 1位:5点
- 2位:3点
- 3位:1点
- 4位以下:0点
ダウンロードしたデータに上記の特徴量を追加したファイルをrace.csvとして用意しました。
※ ExcelではSJIS形式となりますが、今後の手順のためにUTF-8へ変換して保存してください。
テスト用データの作成
モデルを作った後に、そのモデルに適用して結果を出したい情報を用意します。
ここでは、2021/12/26の有馬記念のデータを、race.csvの「確定着順列と着順スコア列」以外を作ります。
別に列の順番はrace.csvと合わせる必要はありませんが、列の名前は同じにする必要がありますので注意してください。
出走馬やオッズなどはレース直前にならないと決まらないので、予測サイトのデータを活用して事前に作ったものを活用します。
また、レースの情報は昨年のデータを、天候などの情報は晴れにして予測しました。
※ ExcelではSJIS形式となりますが、今後の手順のためにUTF-8へ変換して保存してください。
レース直前になれば実際のオッズや体重などがわかりますので、このデータを更新して、直前にまたモデルを適用した予測結果を出力するのも良いかもしれません。
Oracle Cloud の無料トライアル申し込み ~ 仮想ネットワーク(VCN)の作成
OCIチュートリアルのサイトに方法が記載されています。
以下の3つのステップを行います。
以上のステップを行うことで、AutoML UI を利用するための基盤を構築する準備が整います。
次に AutoML UI を利用するための基盤となる、Autonomous Database を構築します。
Autonomous Databaseの構築(Always Free)
画面左上のハンバーガーメニューからAutonomous Databaseを選択します。
こちら、少し古いのでインターフェースが若干変わっていますがご了承ください。
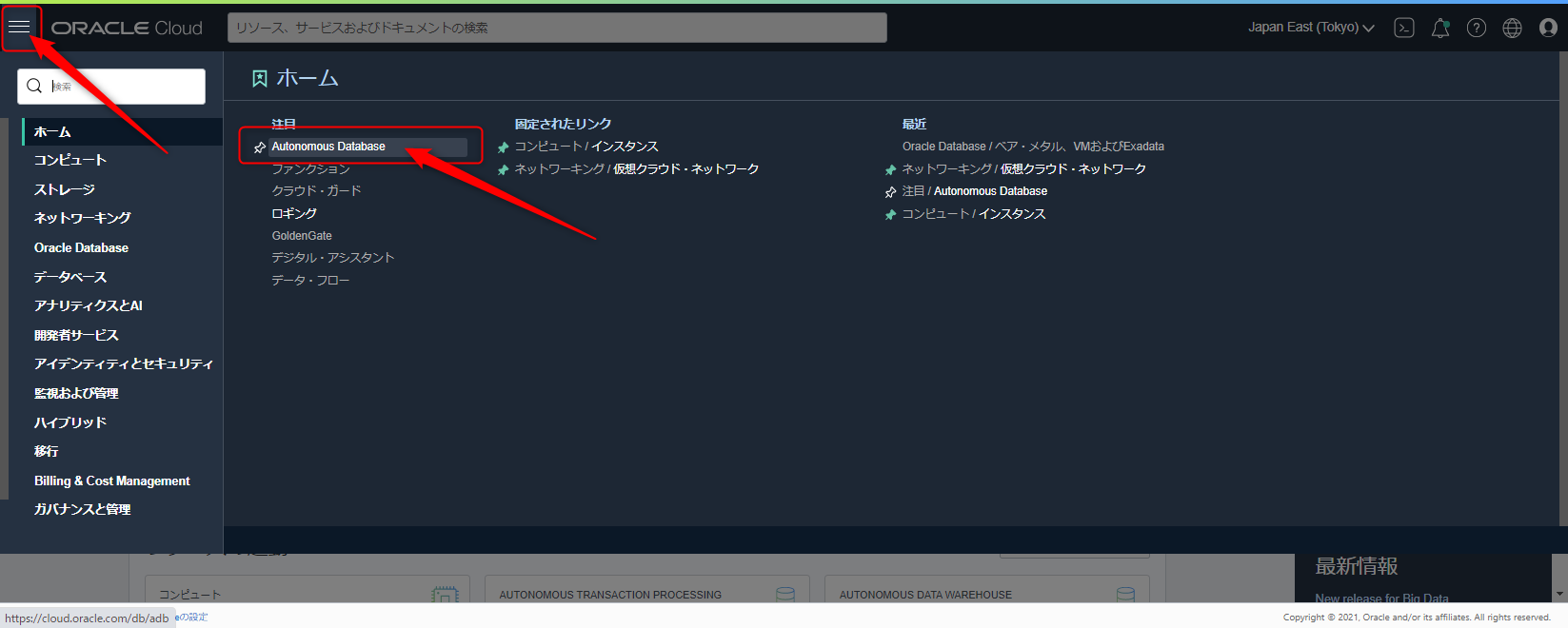
Autonomous Databaseの作成ボタンを押します
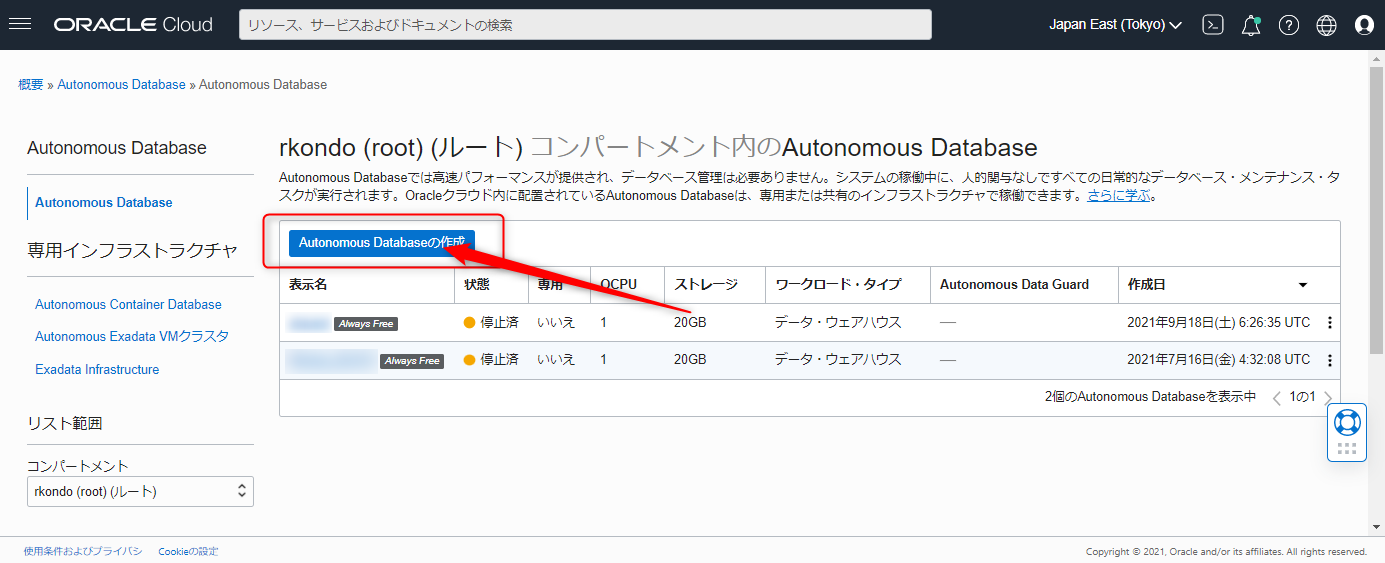
Always Freeでデータ・ウエアハウスのDB(arima)を構築します
VCNなどは前のステップで構築したものをご利用ください。
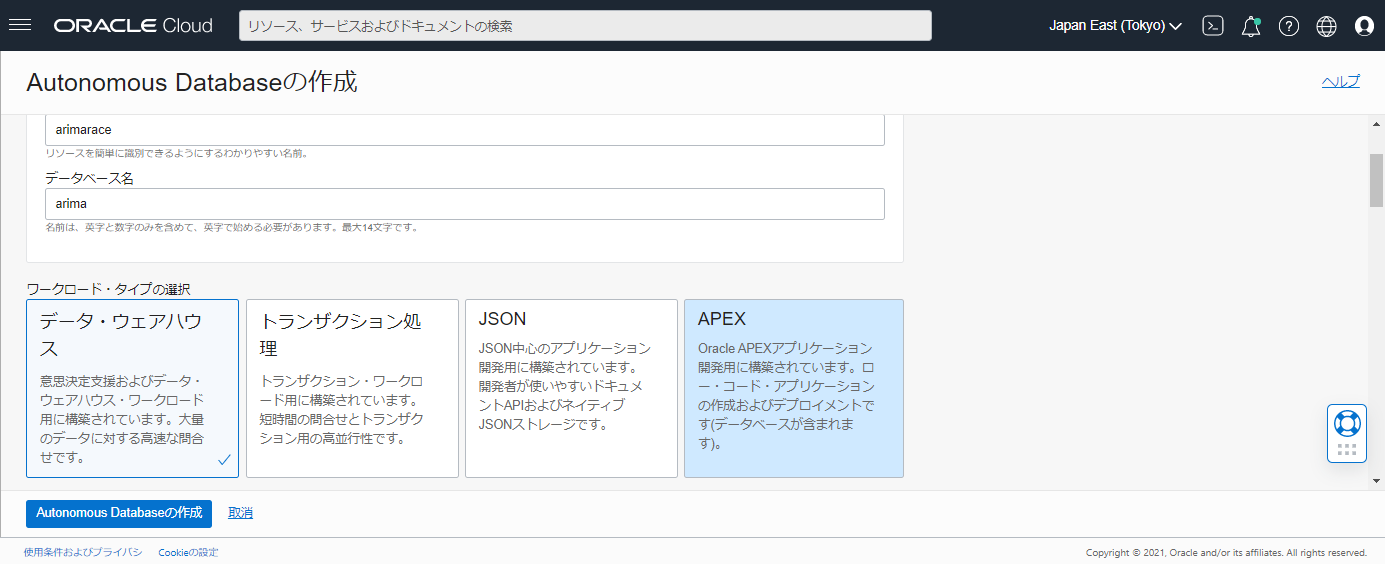
Autonomous Databaseの作成ボタンを押すと、作成中の画面になります
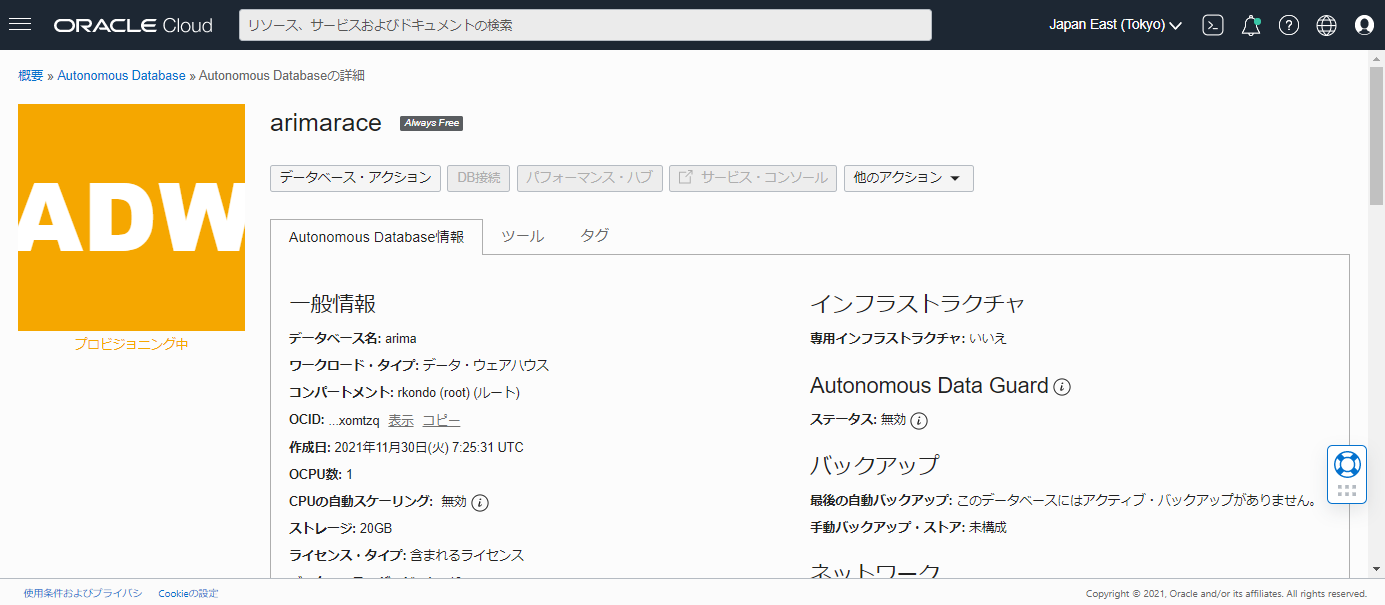
1分ほど待つと、使用可能な状態になります。
ここから2024/2時点の画面ショットで記載します。
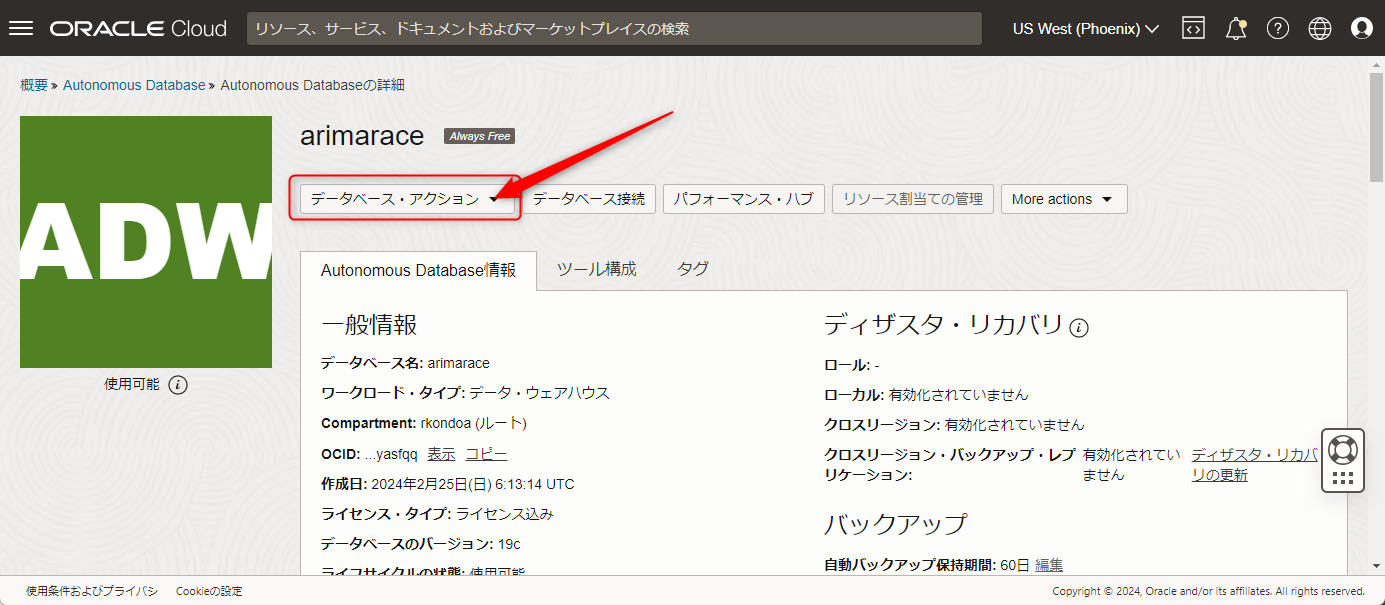
機械学習用のユーザー作成と権限の付与
機械学習用のユーザを作成するため、データベースのアクションボタンをクリックします
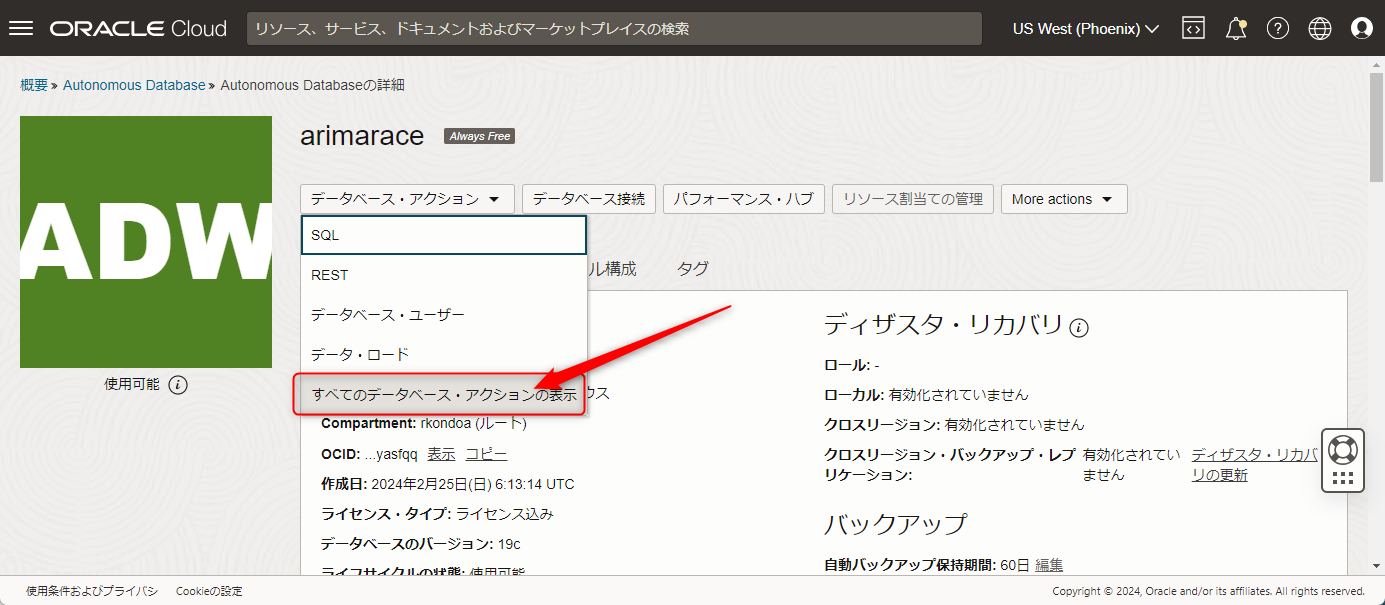
出てきた中から「すべてのデータベース・アクションの表示」をクリックします。
データベースのアクションが表示されるので下の方にスクロールして
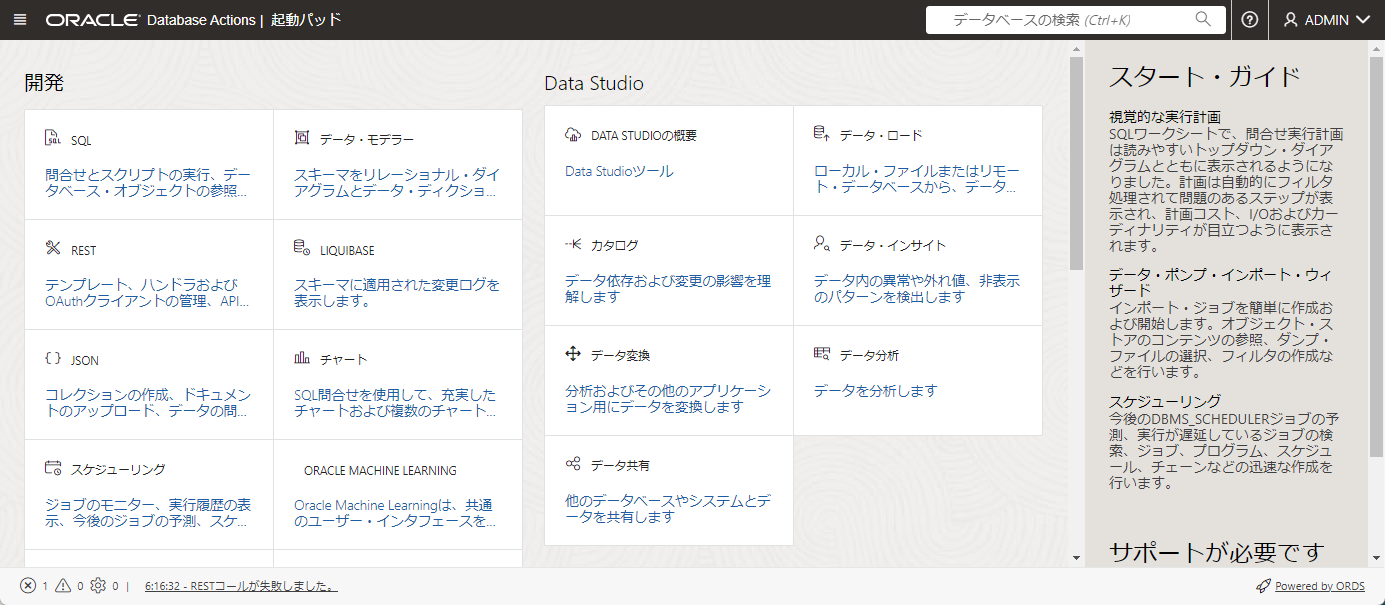
「データベース・ユーザー」をクリックします。
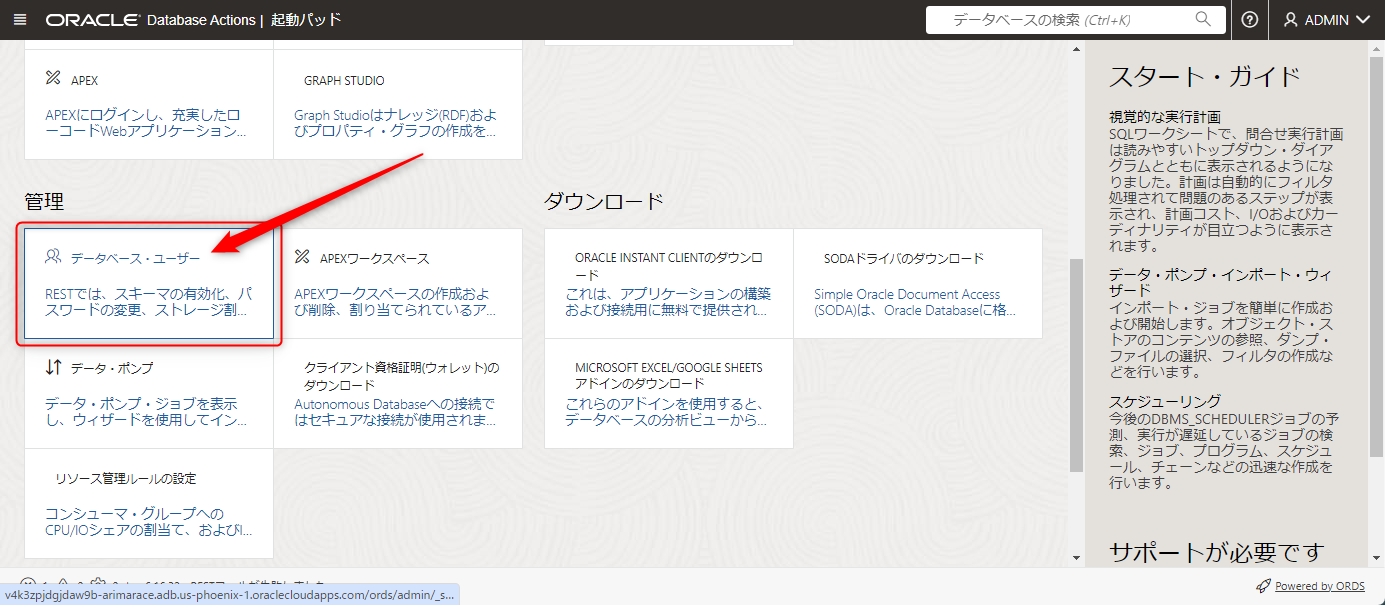
機械学習用のユーザーを作りたいので、「ユーザーの作成」ボタンを押します。
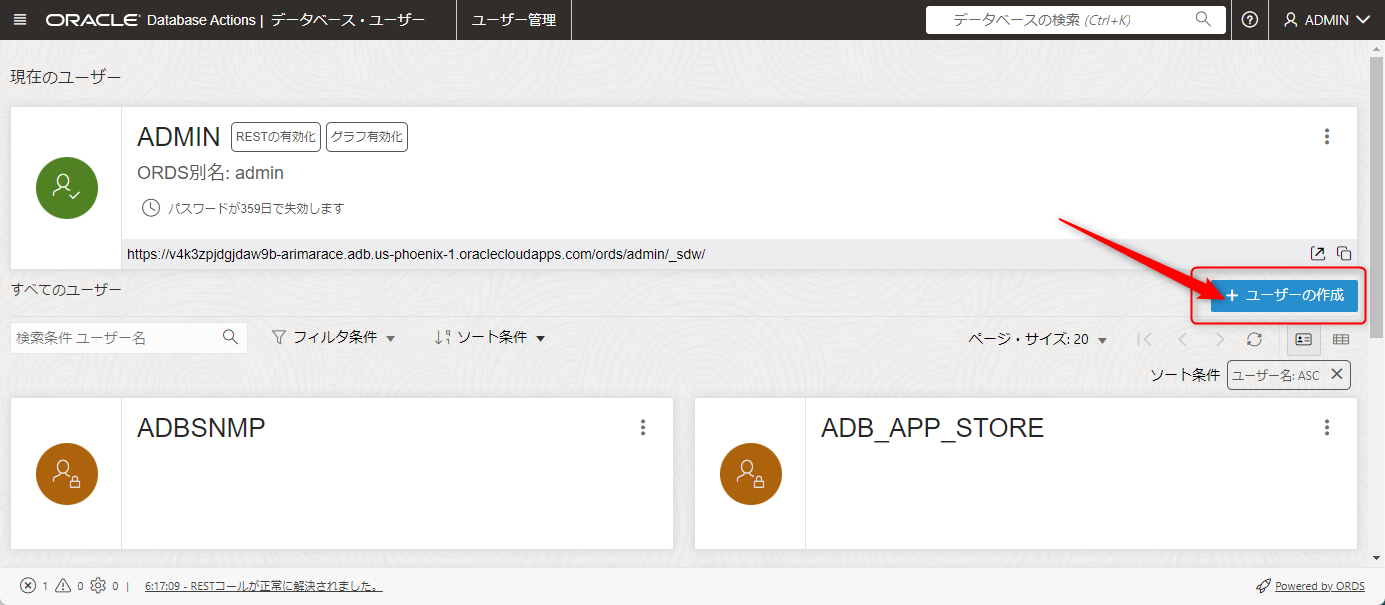
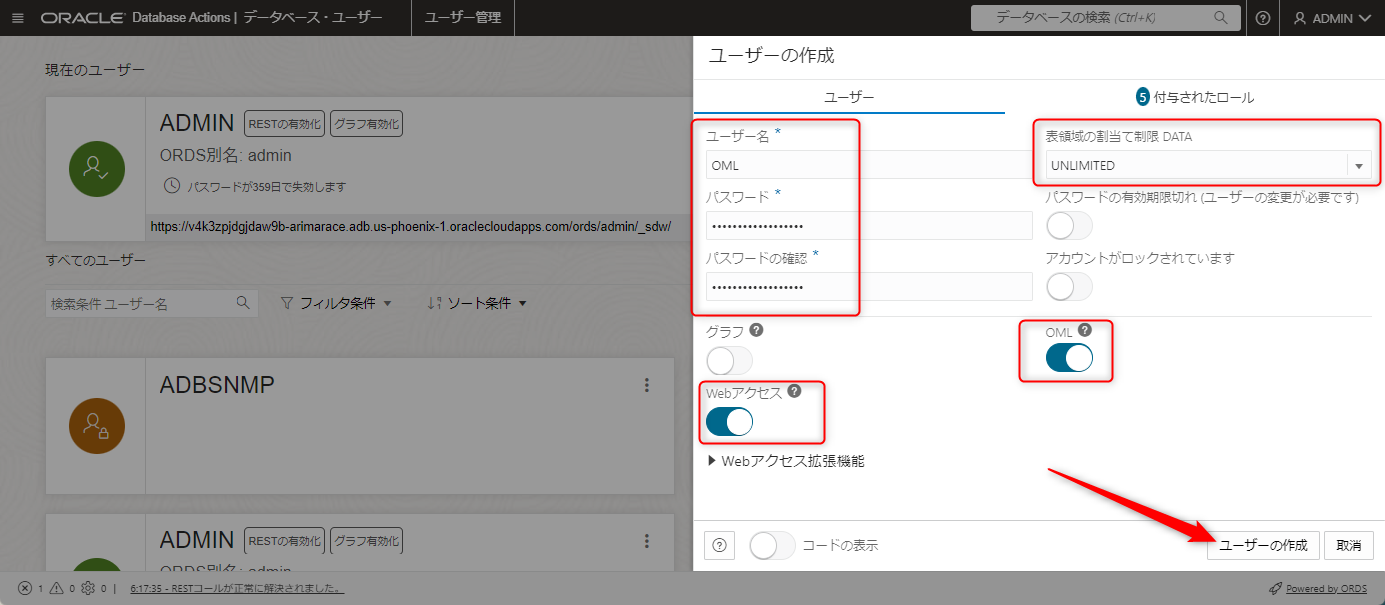
今回はOMLという名前のユーザを作成します。
OMLユーザのパスワードもここで入力します。
なお、このタイミングで表領域の割り当て制限もUNLIMITEDに設定し、OMLのボタンとWebアクセスのボタンもチェックして有効化しておきます。
この作業によって、Autonomous Databaseの機能の1つである、AutoML UIの利用が可能になります。
こちらが記載出来たら「ユーザーの作成」ボタンを押します。
OMLユーザーが作成されました。
OMLユーザーに「RESTの有効化」「OML有効」と記載されていることを確認します。
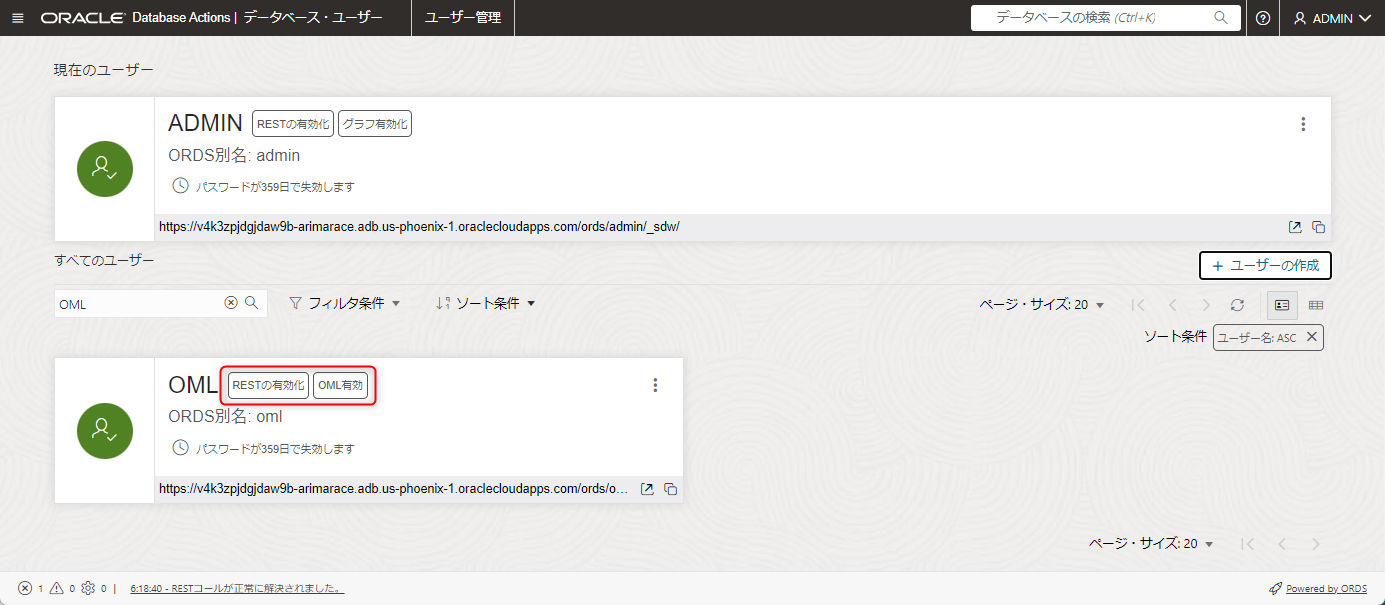
以上でOMLユーザの準備は完了しました。
次のステップのため、左上のADMINのボタンをクリックし、サインアウトを選びます。
作成したOMLユーザでログインをします
学習データのロード
OMLユーザに、先ほど用意したrace.csvとtest.csvをロードします。
画面右上のユーザー名がOMLになっていることを確認したうえで、データ・ロードボタンを押します。
左上の「データのロード」をクリックします。
データをアップロードする画面となりますので、race.csv をドラックアンドドロップします。
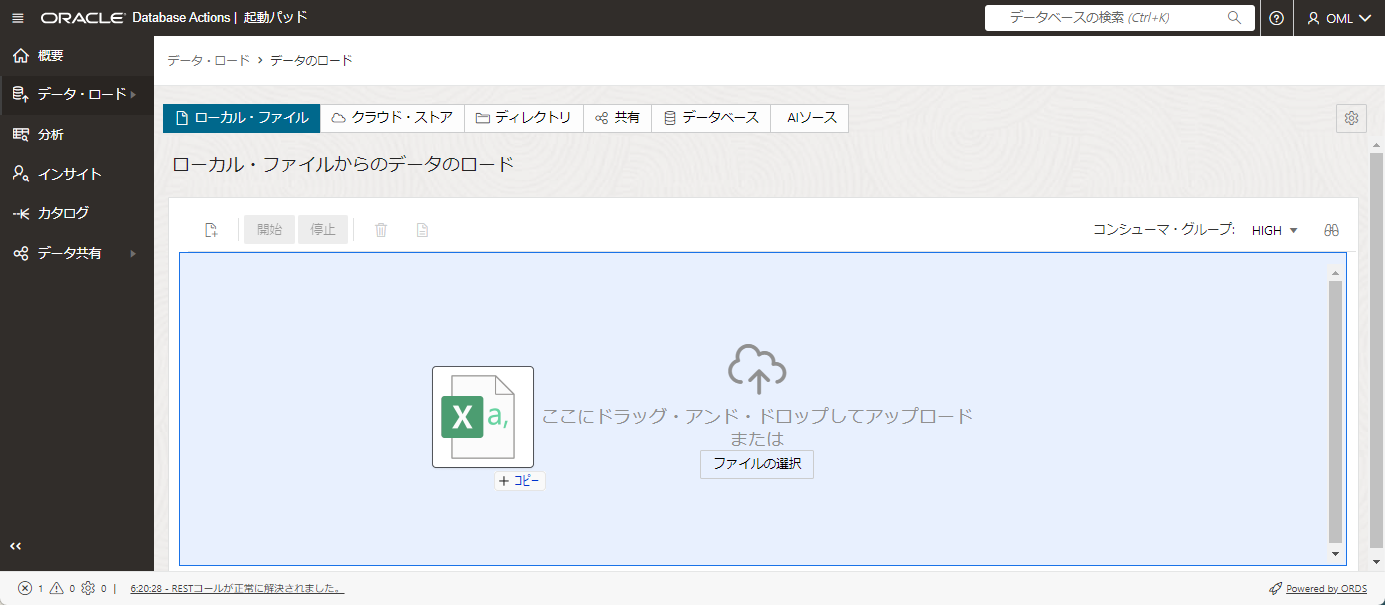
csvデータの内容が正しく判別されているかを確認するため、鉛筆のマークをクリックします。
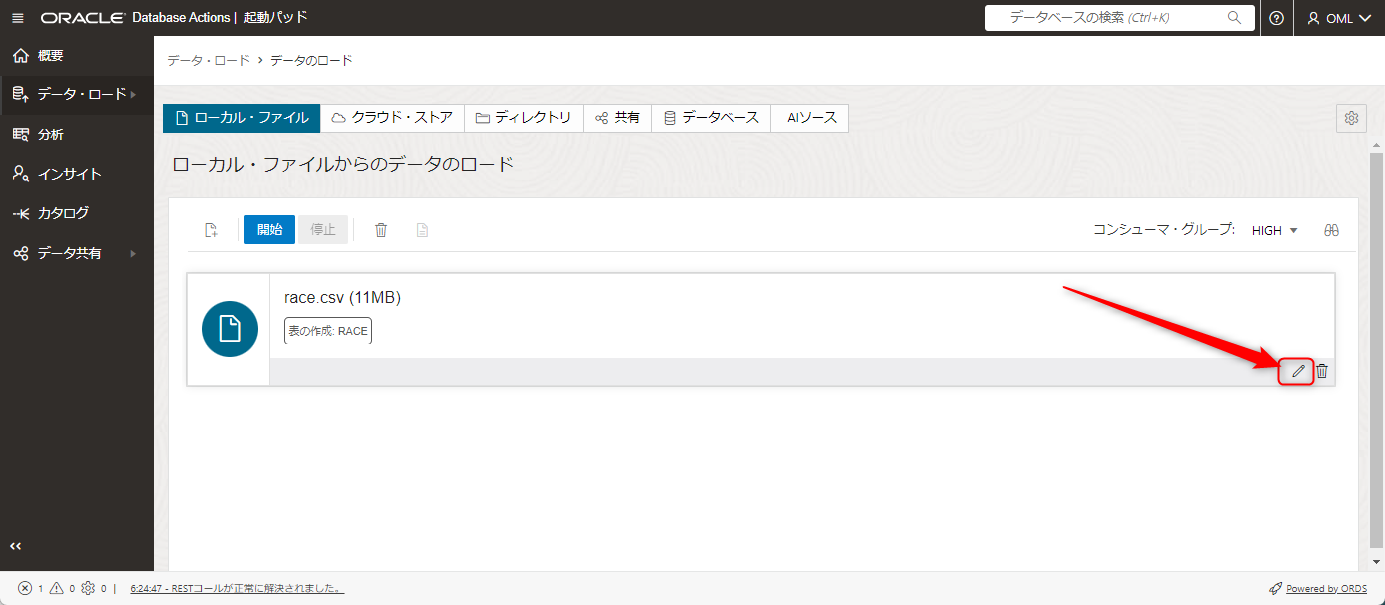
インポートするデータの詳細が開きます。
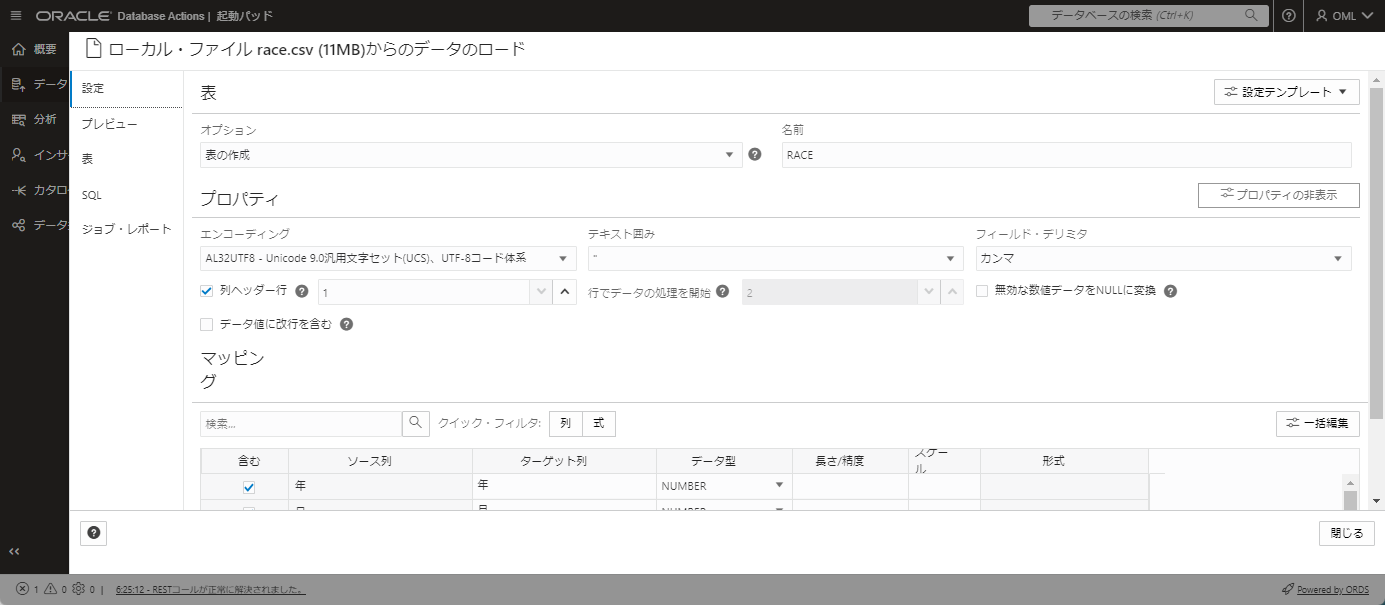
下にスクロールして、列の名前と型がマッピングされていることを確認します。
ここで、csvファイルがSJIS形式の場合、列名が文字化けします。その場合はcsvファイルの文字コードをUTF-8に変換してください。
なお、インポートでエラーが発生した場合、例えばnumber型の列に文字列を入れようとしている可能性があります。
その場合はインポートしようとしている元データを確認するのが良いかもしれません。
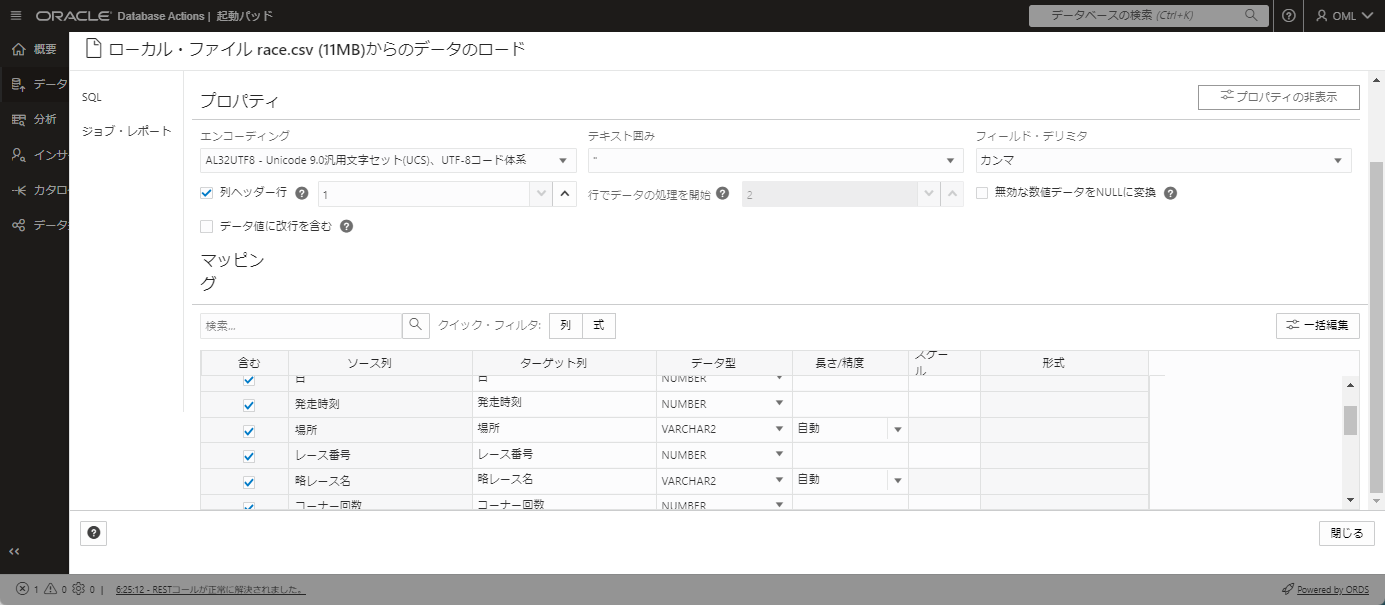
問題が無いことを確認したら、先ほどの画面下の閉じるボタンを押したのちに、開始ボタンを押します。
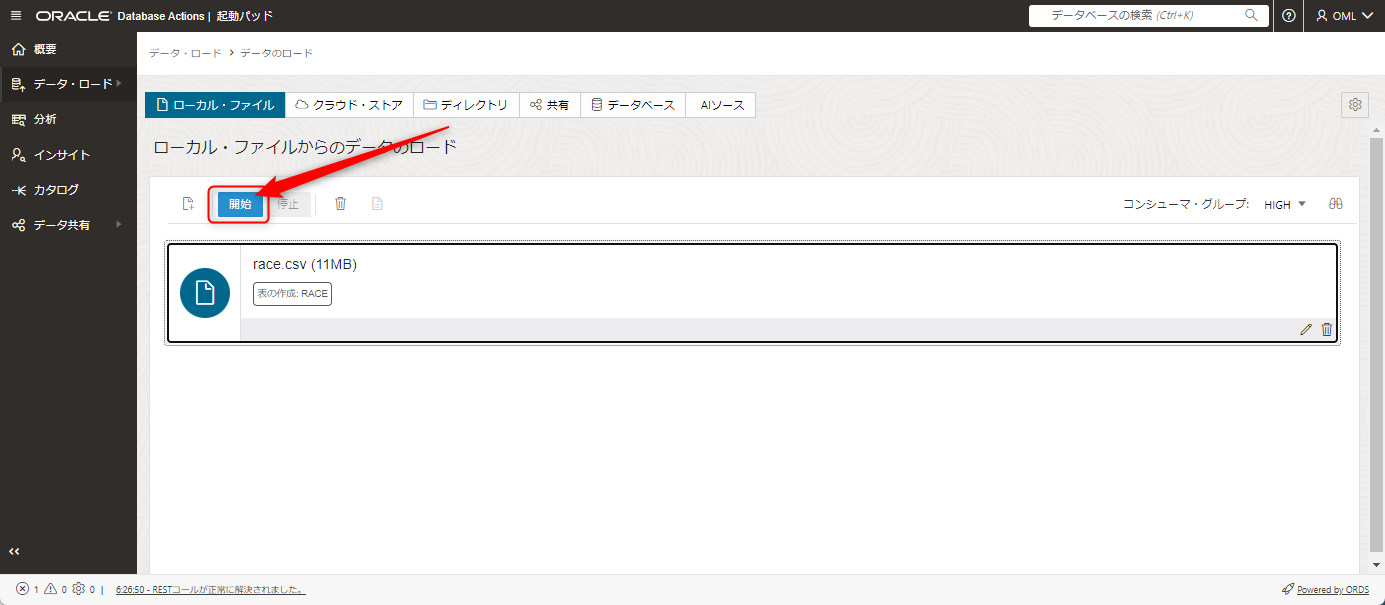
データ・ロード・ジョブの実行をするか確認がありますので、実行を押します
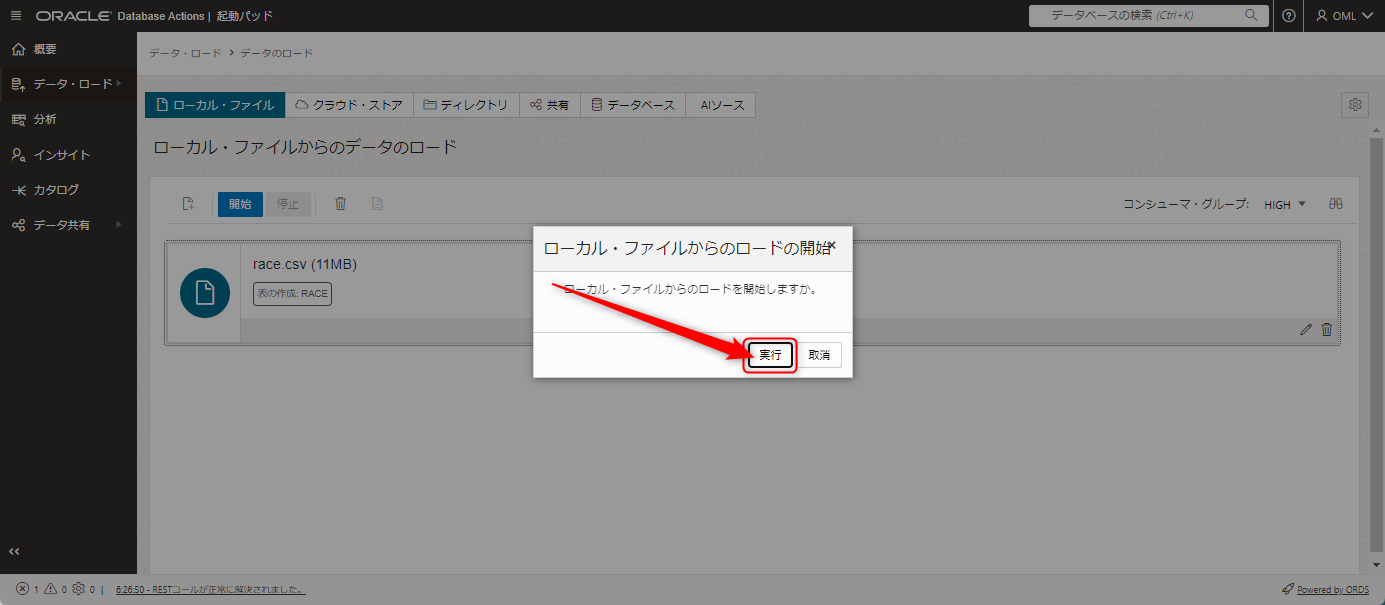
データ量に応じて時間がかかりますので、ロードが終わるまで待ちます。
ロードが終わったら画面右下の完了ボタンを押します。
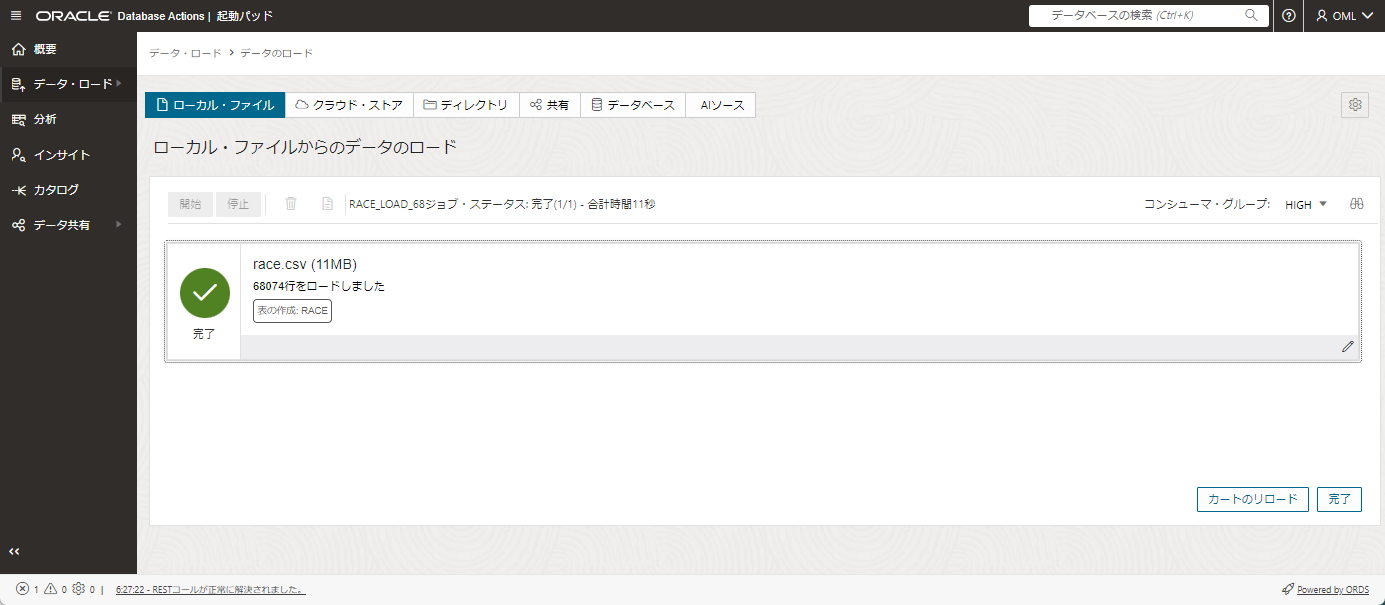
一部手順を省きますが、test.csvについても同様の手順を行いデータのロードを行います。
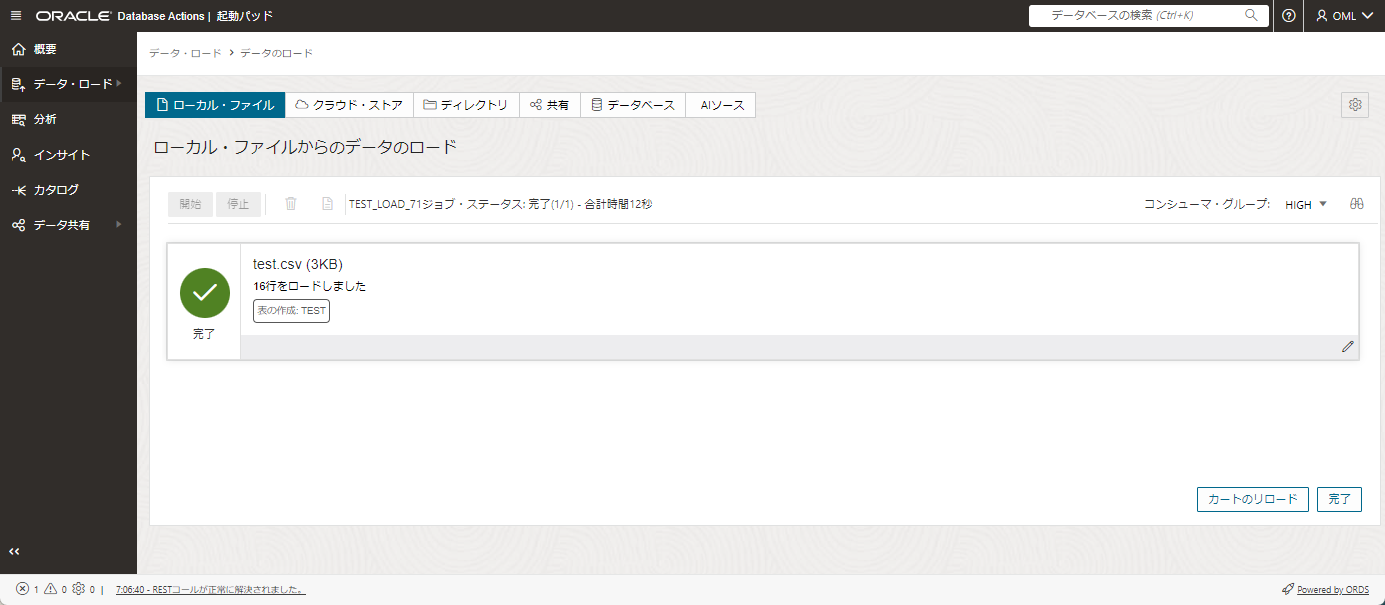
test.csvについても無事にデータのロードができました。
以上のステップで機械学習をするための準備が整いました。
引き続き、無料で始めるAutoML超入門 ~有馬記念で1位を予測する~(後編) をご確認いただき、モデルを作成して予想をしてみてください。