#概要
この記事では Oracle Cloud の Always Free Cloud Services によって利用可能な Autonomoud Database を利用して、AutoML UI を活用して有馬記念の着順を機械学習で予測する手順をチュートリアル形式でご紹介します。
ボリュームが多いので、前半と後半に記事を分けており、本記事は後半となります。
前半は以下のリンクからアクセスできます。
無料で始めるAutoML超入門 ~有馬記念で1位を予測する~(前編)
#全体の流れ
以下の流れとなります。
- 学習データの取得と整形
- テストデータの作成
- Oracle Cloud の無料トライアル申し込み ~ 仮想ネットワーク(VCN)の作成
- Autonomous Databaseの構築(Always Free)
- 機械学習用のユーザー作成と権限の付与
- 学習データのロード
- AutoML UIによるモデル作成
- 着順の予測
- 着順スコアの予測
- 実際の結果
本記事(後半の記事)では 7~10 を記載します。
AutoML UIによるモデル作成
先ほどはOMLユーザーでロードした状態であるため、そこからの続きとして記載します。
左上のハンバーガーメニューから Oracle Machine Learning をクリックします。
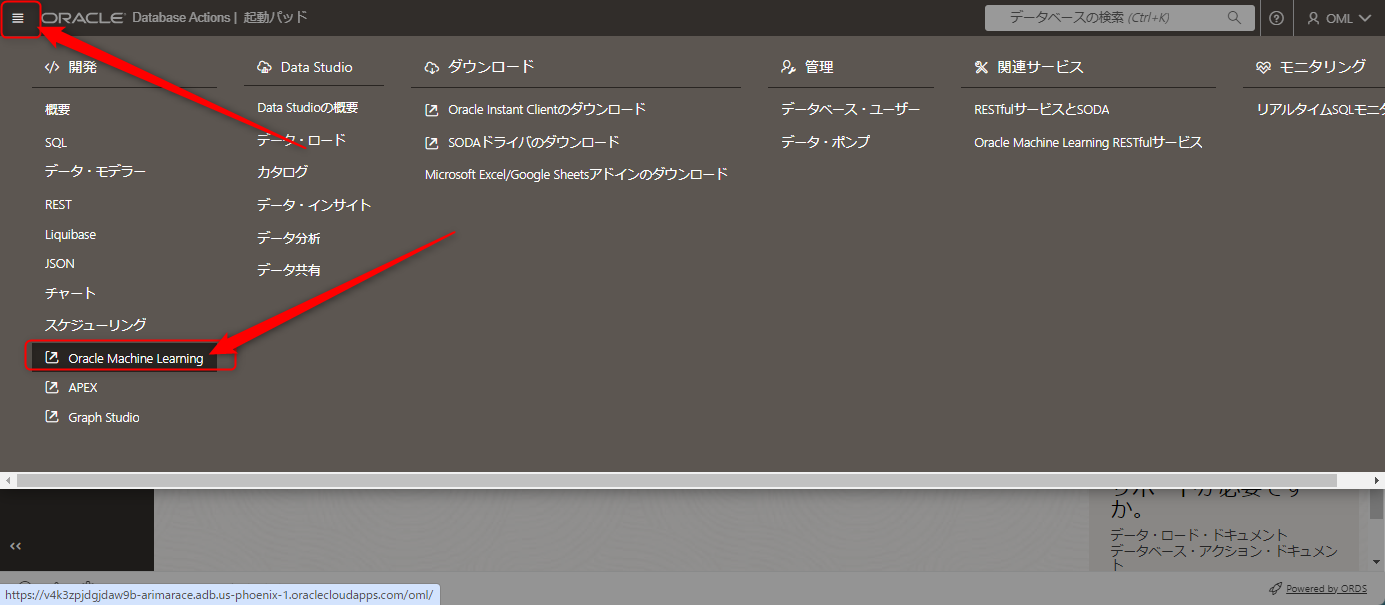
ログイン画面に移りますので、先ほどのOMLユーザーでログインします。
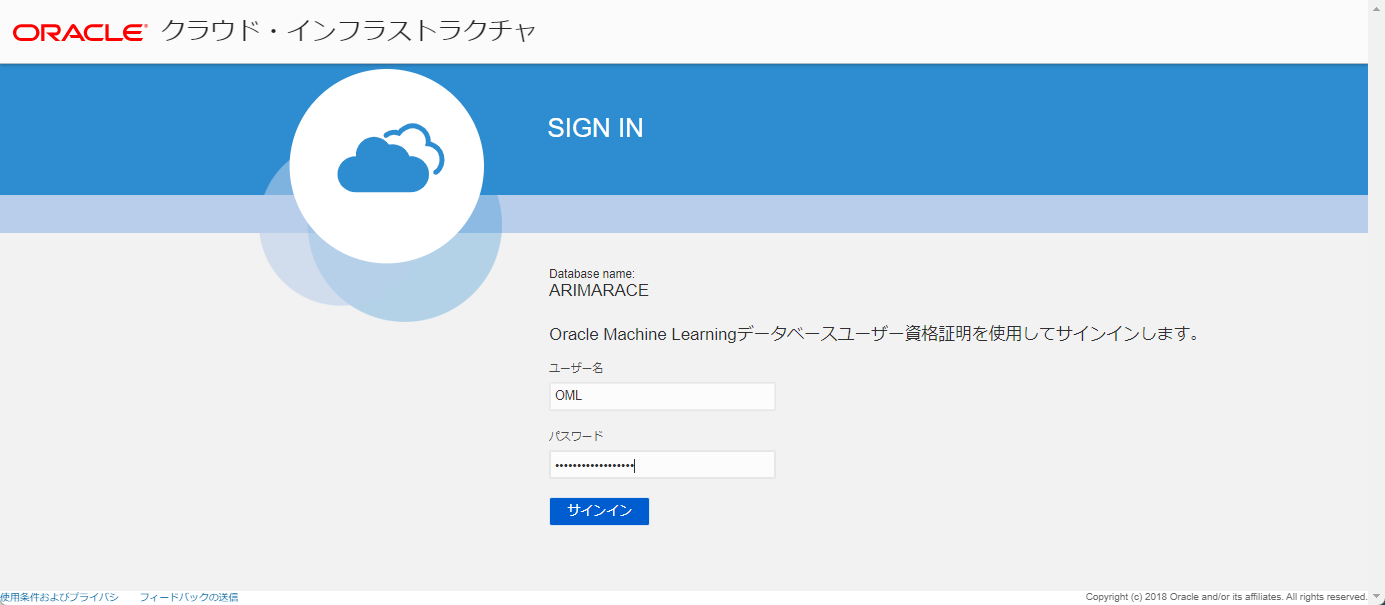
クイック・アクションのリンクの中から AutoML を選択します。
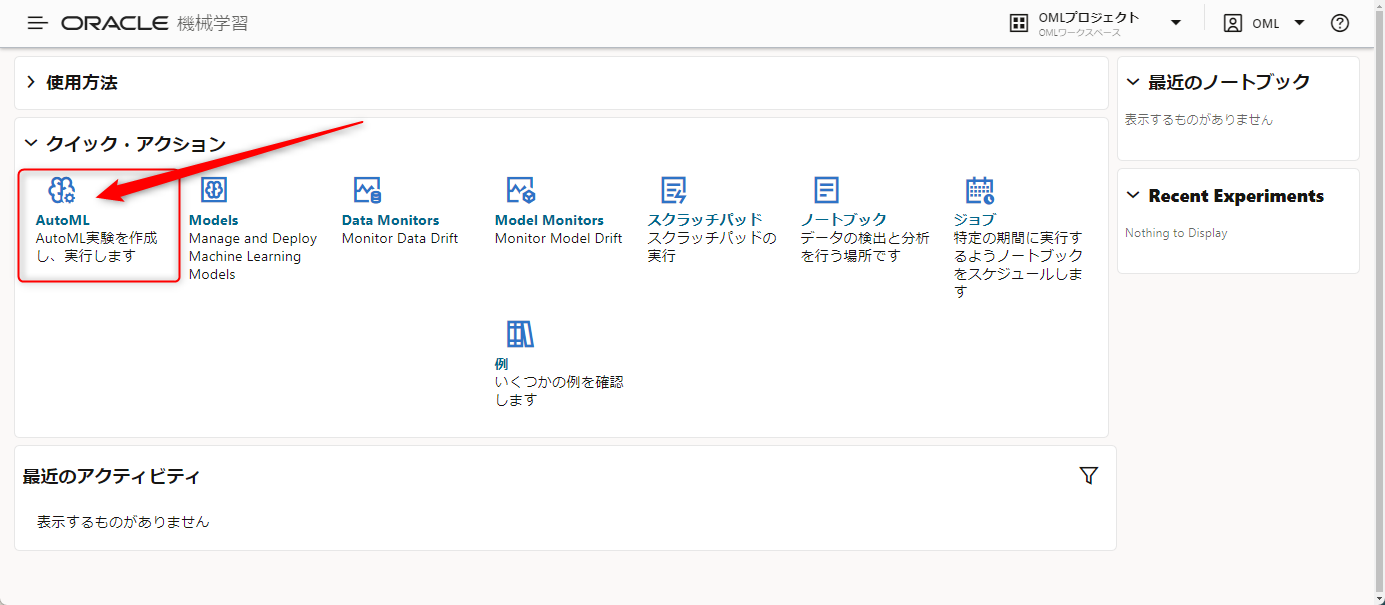
AutoML実験という画面が開きますので、作成ボタンを押してモデルを作ります。
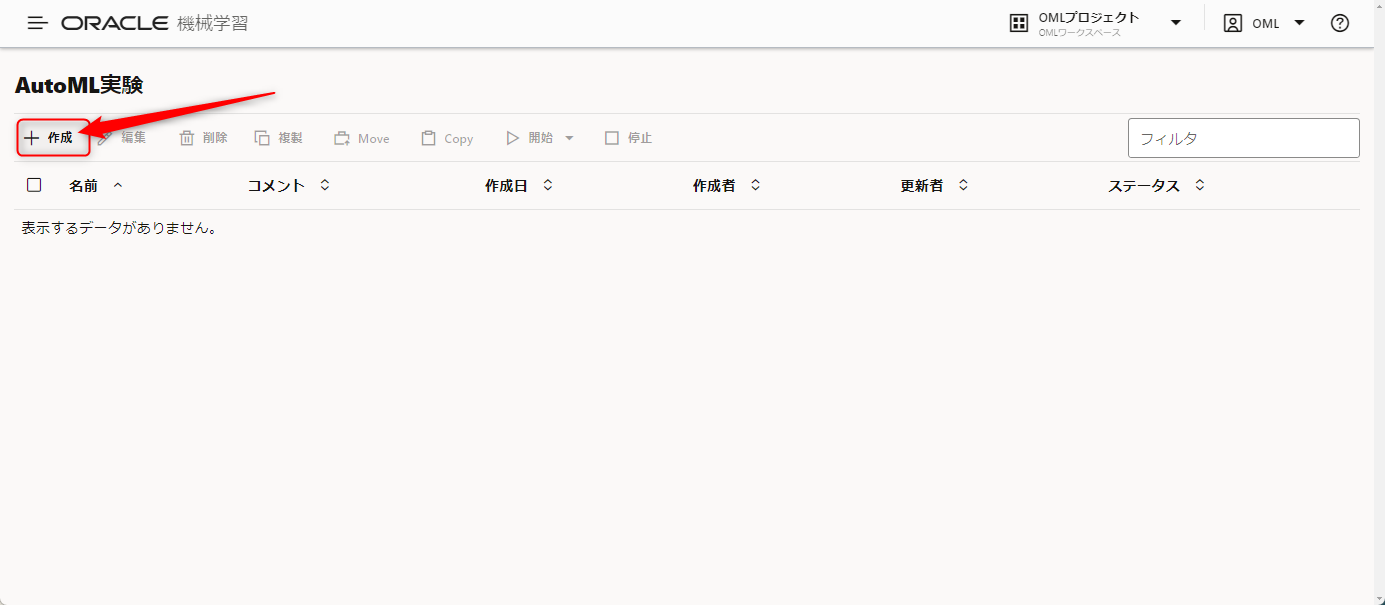
名前欄にはモデルを識別するための任意の名前を入力します。
ここでは有馬記念の確定着順を予測するモデルとわかるため、「有馬記念_確定着順予測1」としています。
モデル名が入力できたら、データ・ソースの右側の虫眼鏡をクリックします
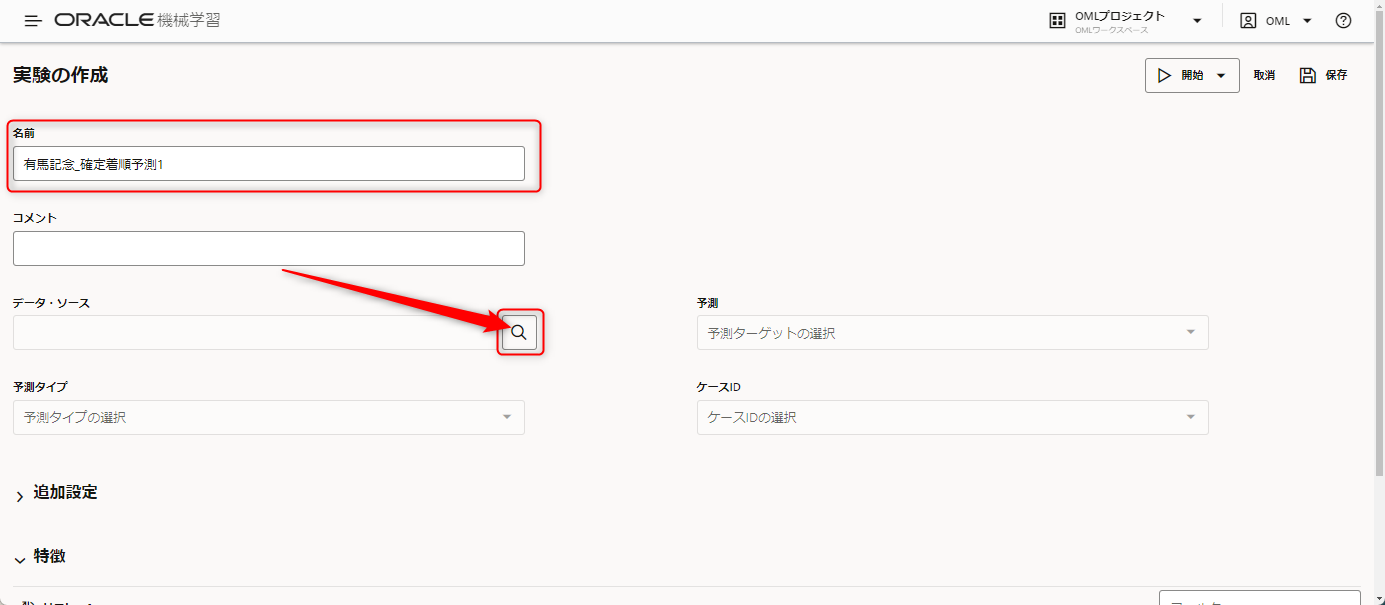
学習する元となるテーブルの選択画面が出ます。
race.csvのデータはRACE表に格納されているため、OMLユーザのRACEを選択します。

続いて予測する列を指定します。
予測ターゲットの選択の部分をクリックします。
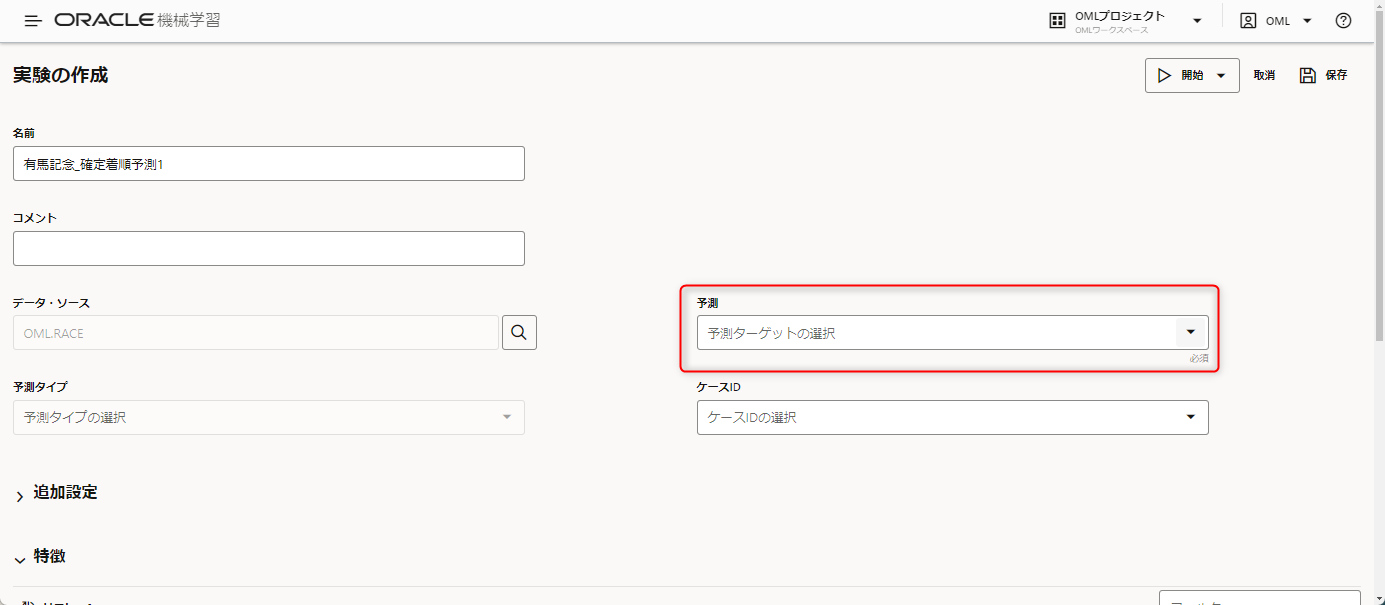
今回は確定着順データを予測するモデルを作りたいので、確定着順を選びます

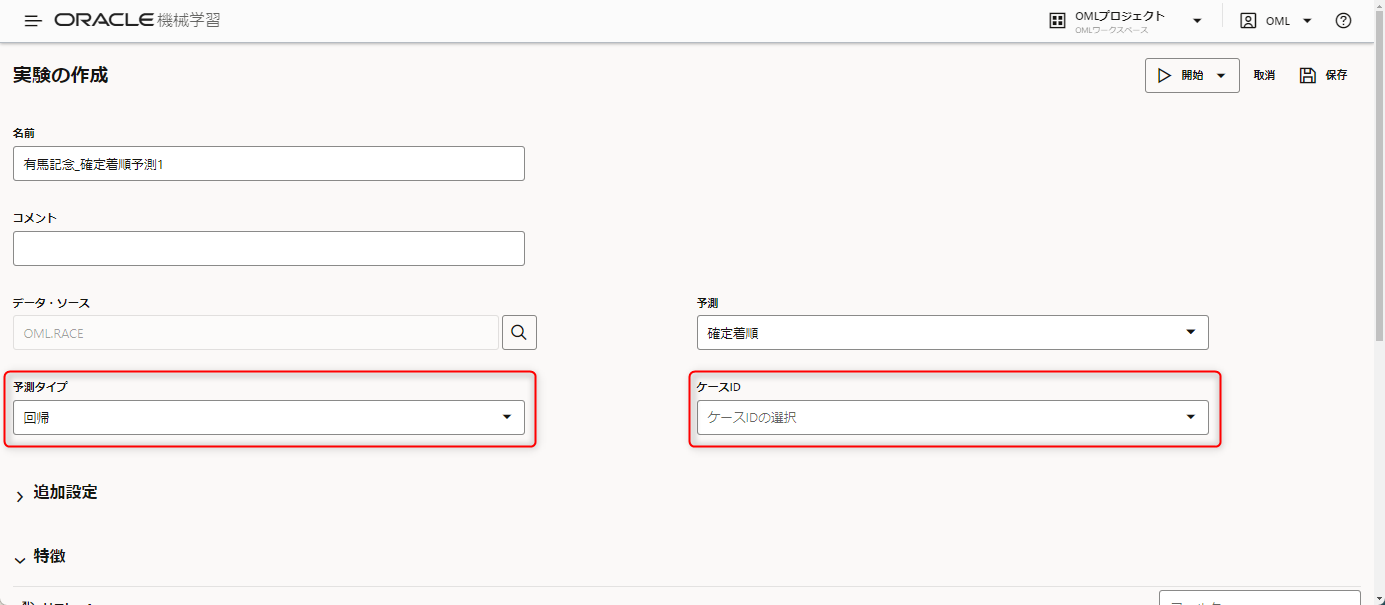
続いて予測タイプを選びます。
今回予測するのは着順となりますので、分類するようなものではありません。
回帰分析で求めるものになるため、ここでは回帰を選択します。
ケースIDはここでは何も選択しないで次に進みます。
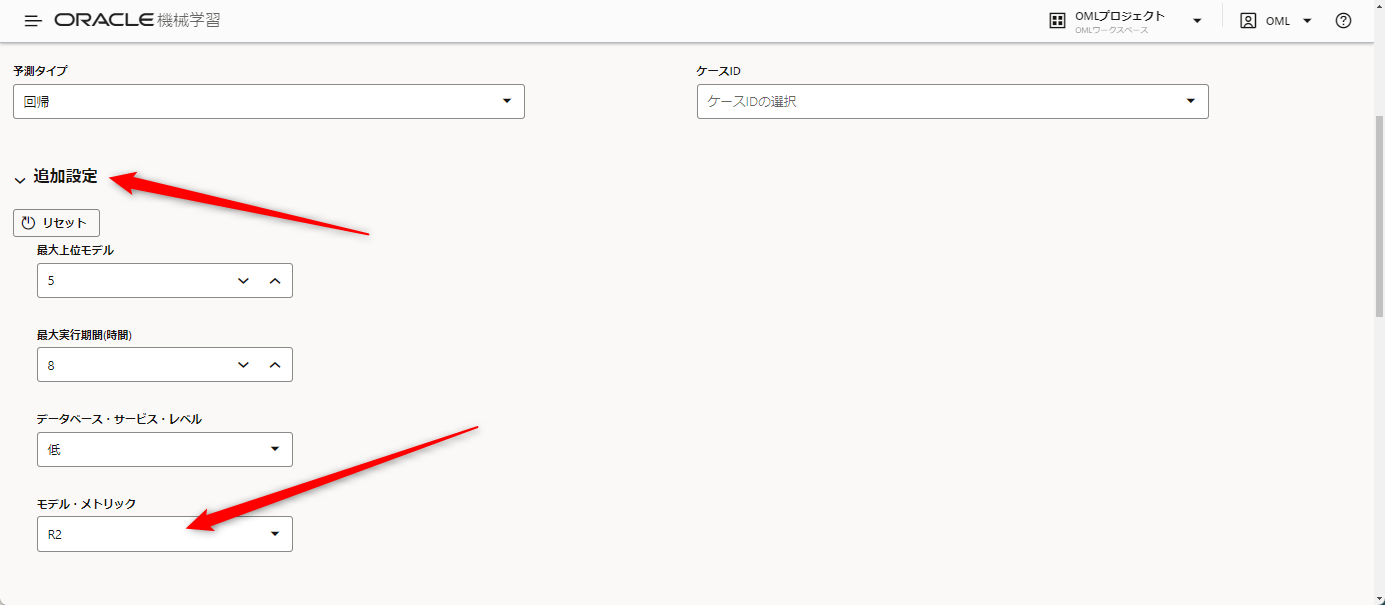
続いて、追加設定を開きます。
ここではいろいろな数字が入っていますが、基本的にはデフォルトで問題ありません。
モデル・メトリックの欄では評価のためのアルゴリズムを選びますので、ここではR2を選択しました。
さらに下にはアルゴリズムを選択する欄があります。
デフォルトではすべての欄にチェックが入っていると思います。
これは、今回予測分析するうえで実行時間を短くするという言うことであればチェックを外すのが良いですが、よくわからないということであれば全部チェックを付けた状態にするのが良いと思います。
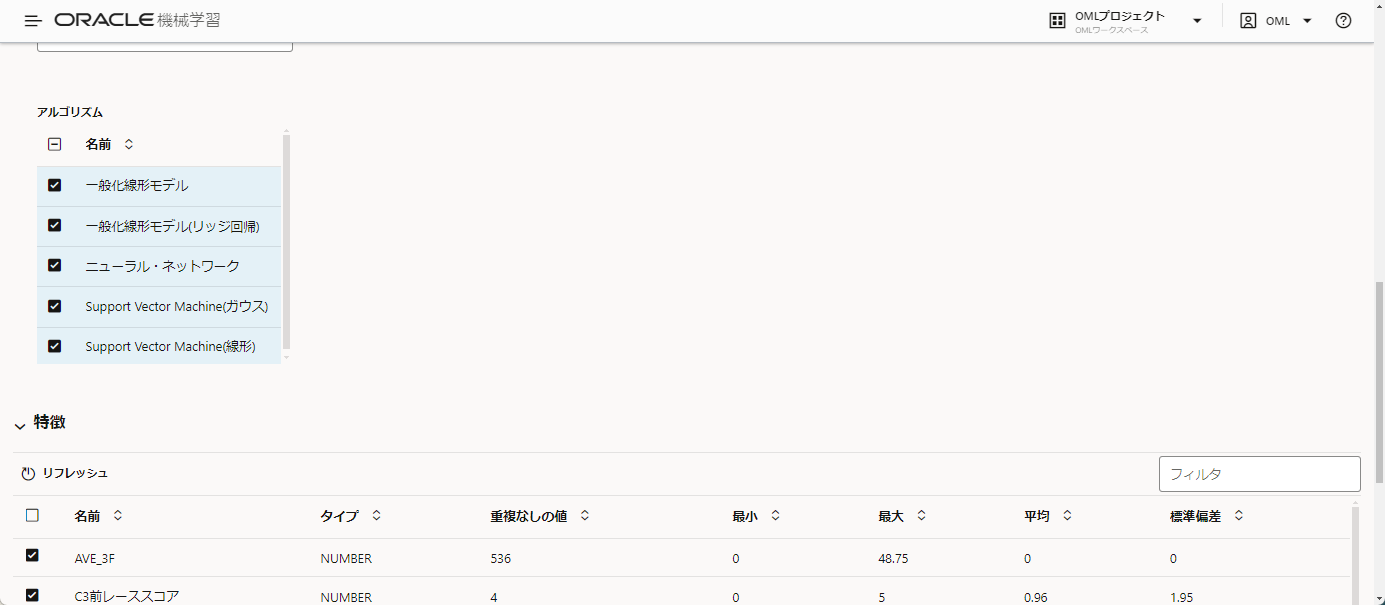
さらに下にスクロールすると、特徴というところにrace.csvの列が記載されていることがわかります。
この中で、race.csvには含まれているけどtest.csvに含まれていない列が存在する場合、チェックを外します。
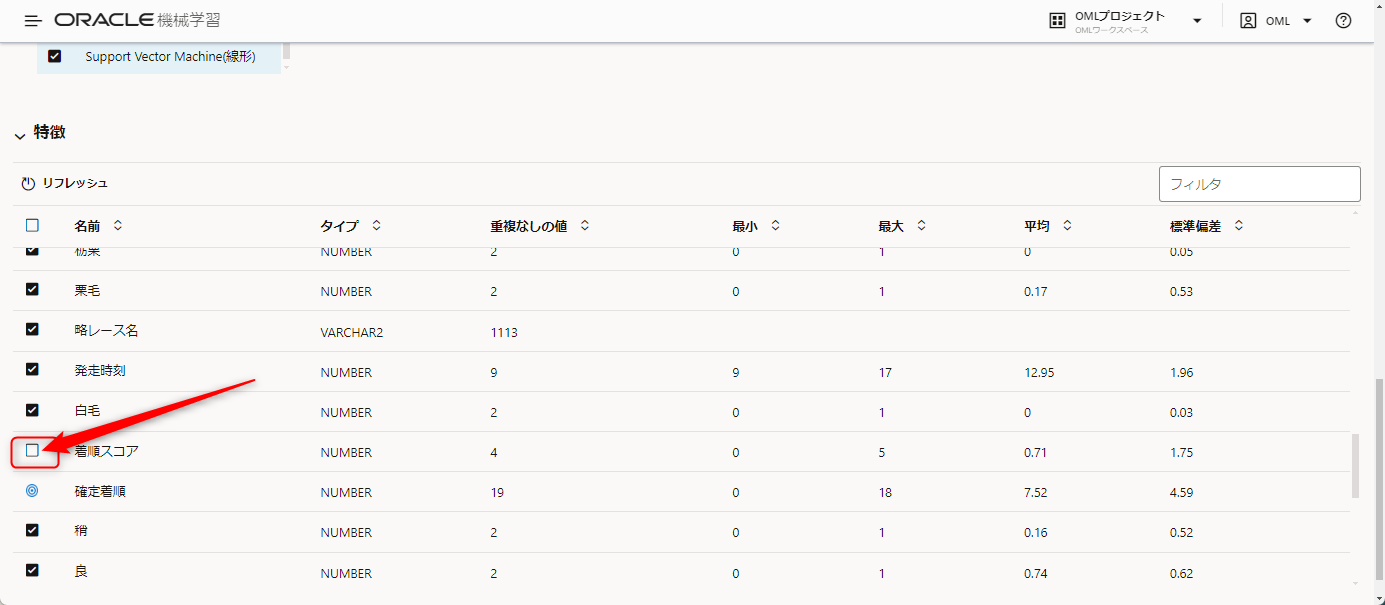
今回は「確定着順」と「着順スコア」を予想してみる予定であるため、確定着順を予測する際は着順スコアの情報は分析対象外とする必要があります。
そのため、ここでは着順スコアのチェックを外しています。
ここまで入力が完了したら、右上の開始ボタンを押して「より速い結果」と「より良い精度」のどちらかを選択します。

選択するとモデルの作成が動作していきます。

より速い速度を選択したところ、3分でモデルが作成できました。
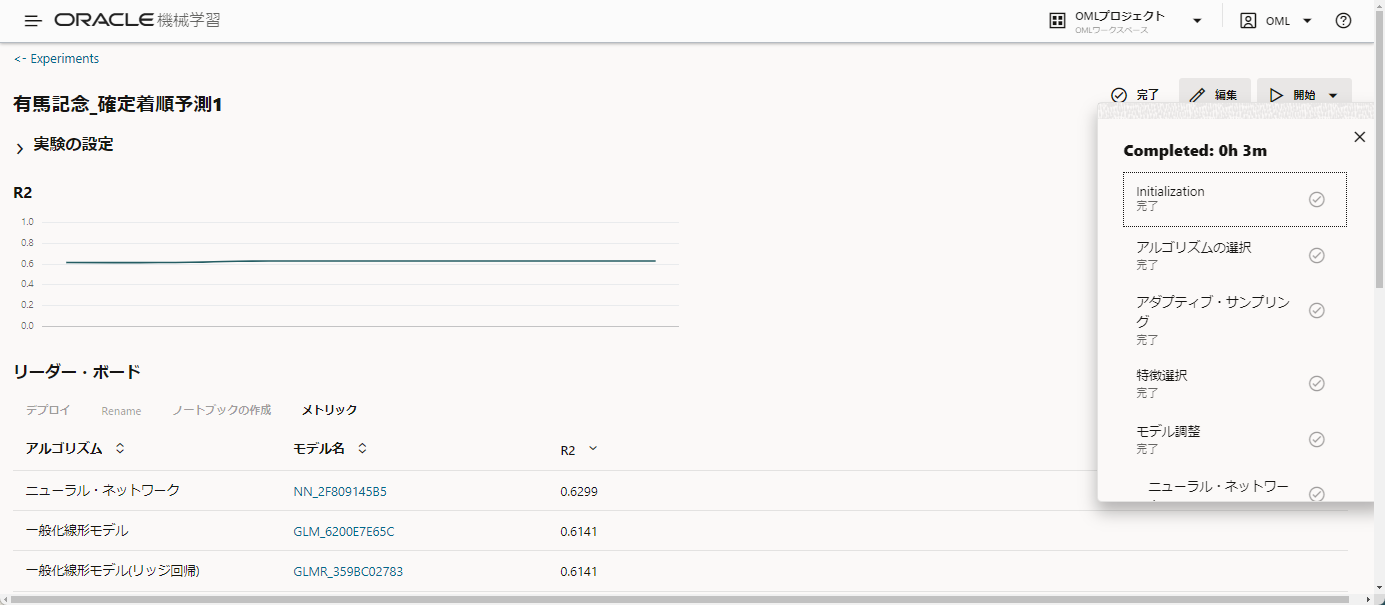
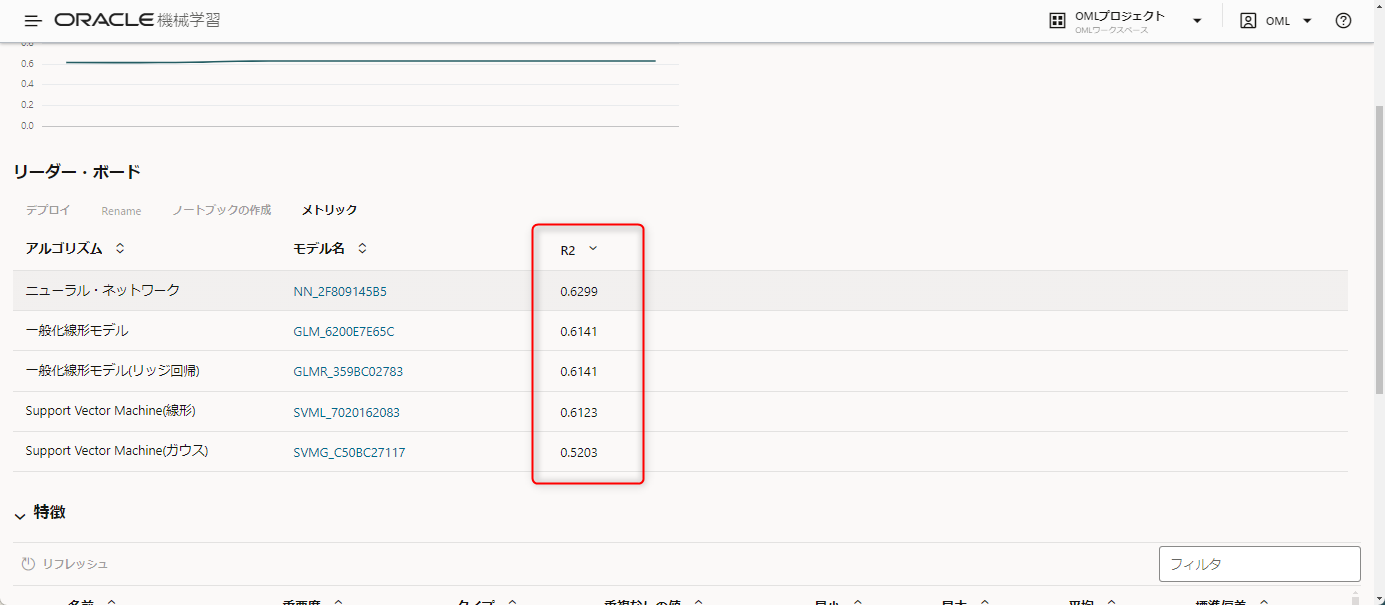
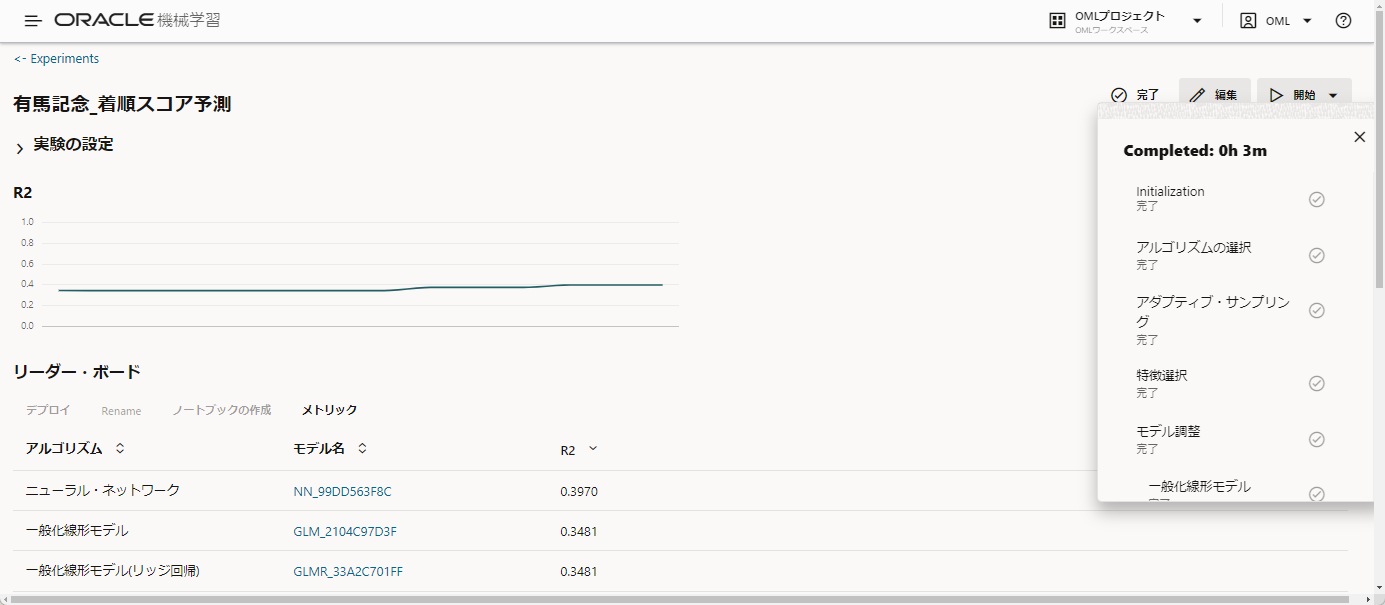
リーダー・ボードを見てみましょう。
ここにR2で評価した結果が、評価の高い順に並びます。
この例ではニューラル・ネットワークの精度が一番よかったようです。
では、ニューラル・ネットワークではどの列に着目して着順を予測しているのかを確認しましょう。
モデル名のリンクをクリックします。

すると、モデルの詳細が開きます。
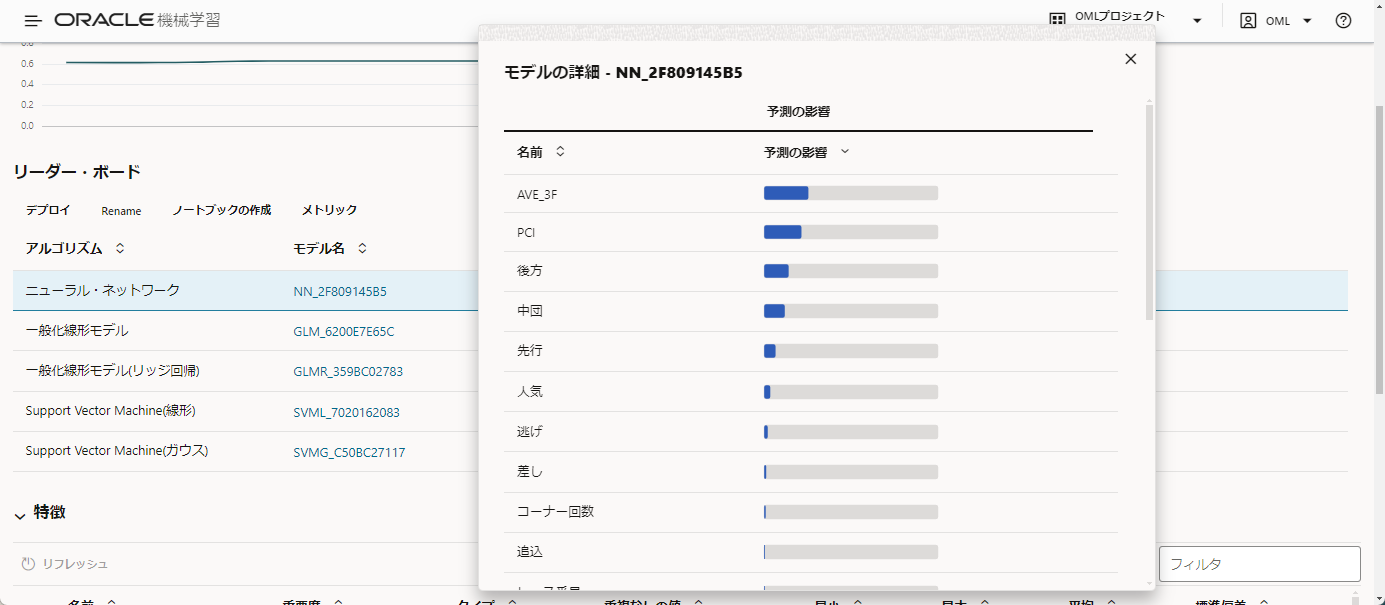
ここでは、AVE_3Fの情報と、PCIの情報の影響が大きいということが確認できます。
どちらも実は走ってみないとわからない情報ではありますが、今回はこれらのデータがわかっている想定で予測モデルを作っています。
こんかいはニューラル・ネットワークの精度が高かったということなので、ニューラル・ネットワークのモデルを利用しようと思います。
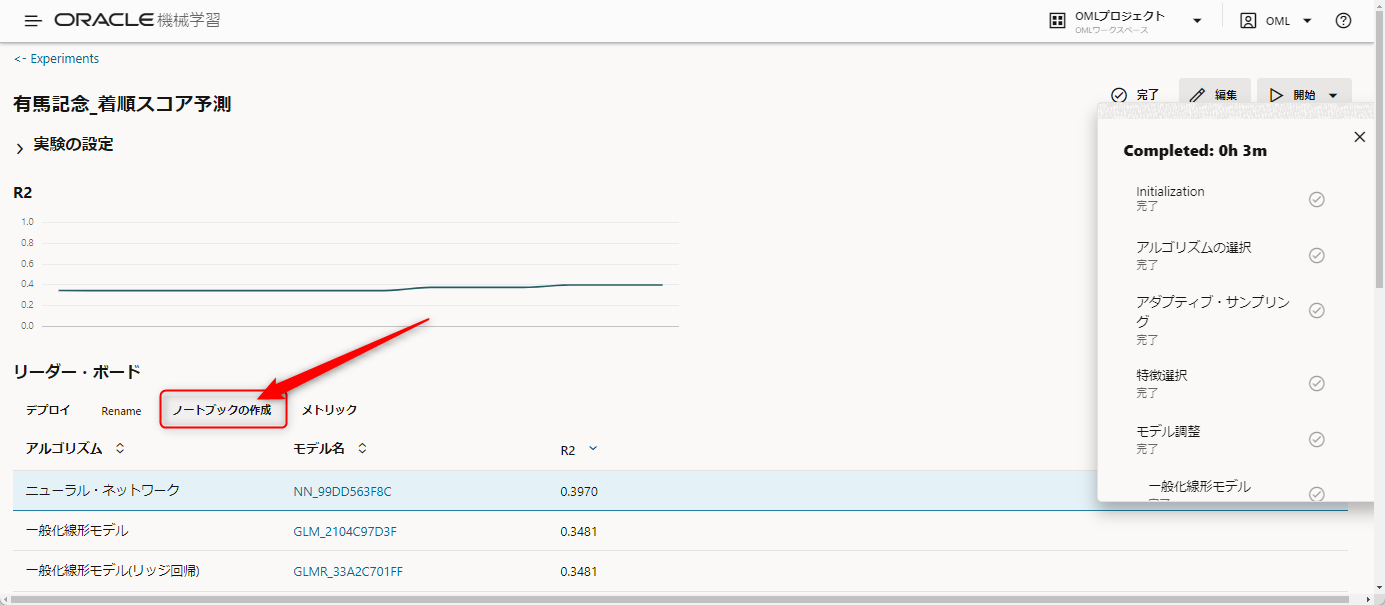
「ノートブックの作成」ボタンを押すことによって、モデルを利用するためのpythonのノートブックを作成してくれるので、今回はこの機能を使おうと思います。
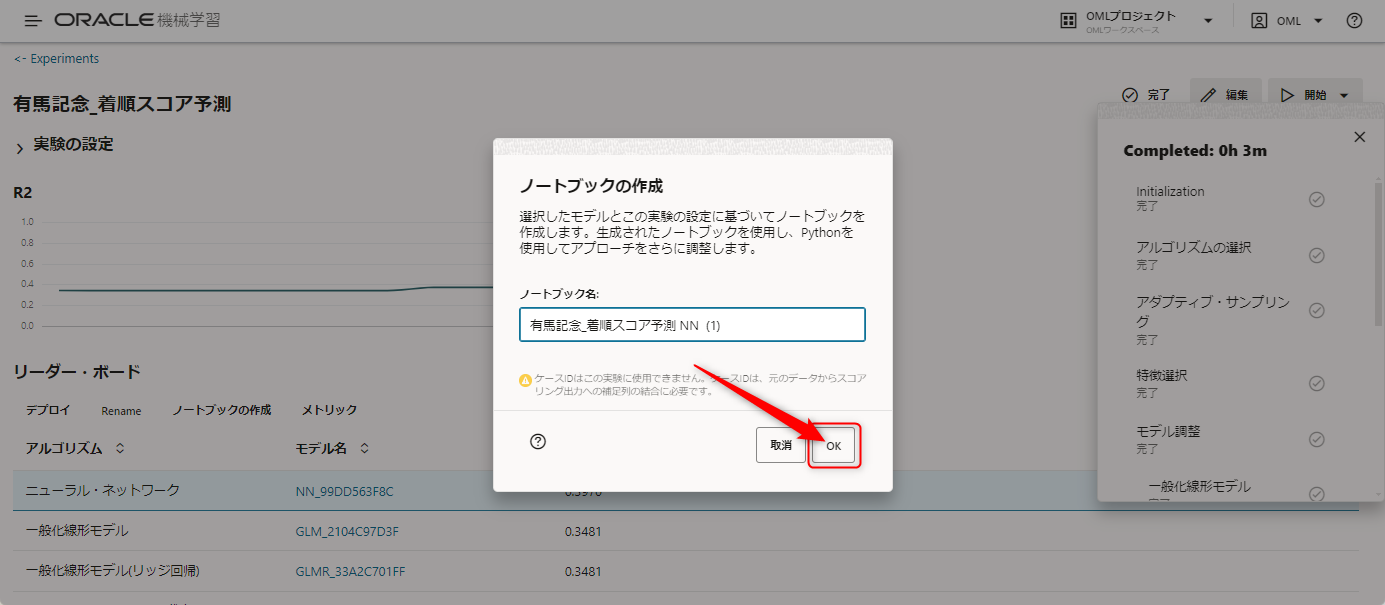
クリックすると作成するノートブックの名前を聞かれるので適当に記載してOKを押します。
そうすると、画面の下にノートブックが作成された旨のメッセージと「Open Notebook」のボタンが表示されます。
このボタンを押すことで、ノートブックを開くことができます。
では、実際にこのモデルを利用して確定着順を予測してみましょう。
着順の予測
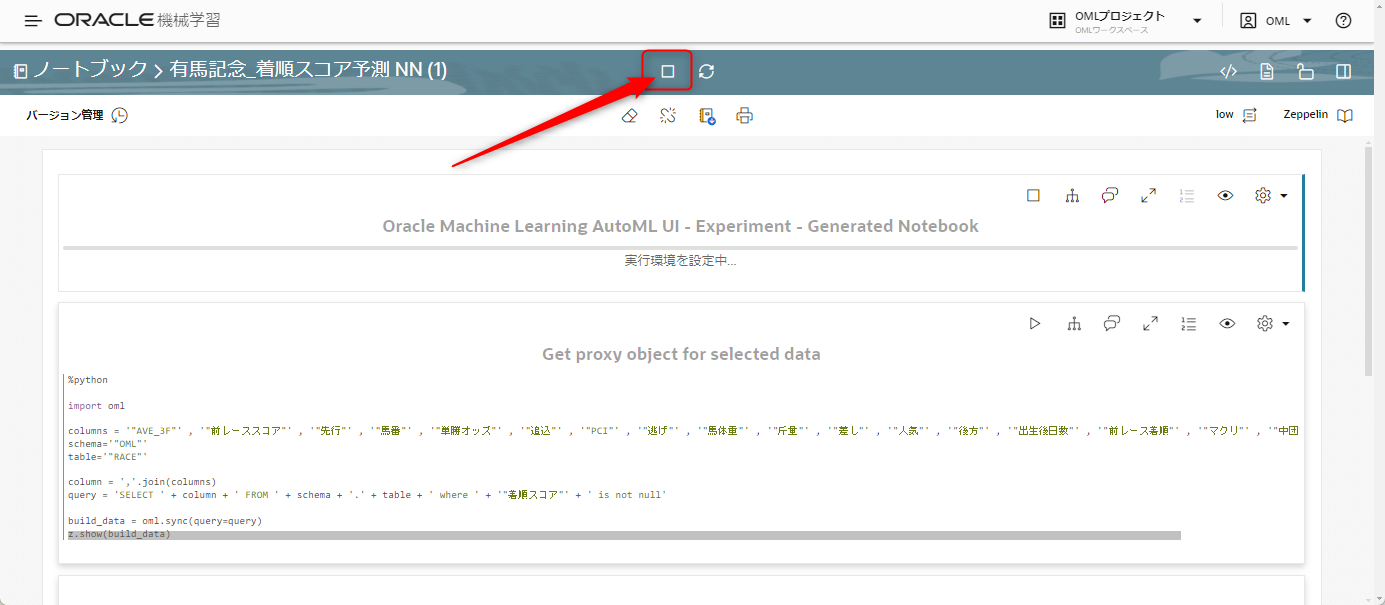
先ほどの「Open Notebook」のリンク、もしくは左上のハンバーガーメニューを押し、「Notebooks EA」をクリックすることで、先ほど作成してNotebookを開くことができます。
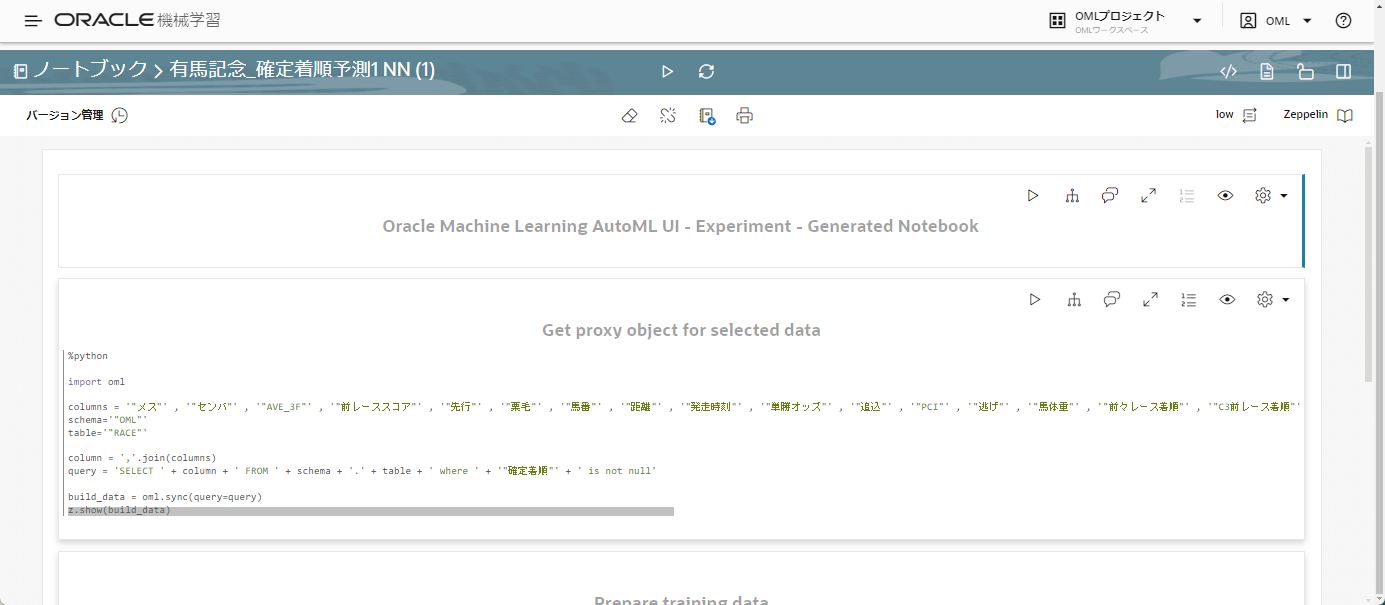
既にPythonのコードが埋め込まれていることがわかると思います。
必要な事項は既にコードが入っているので、実行ボタンを押します

実行しても良いですか?といったメッセージが出るので、
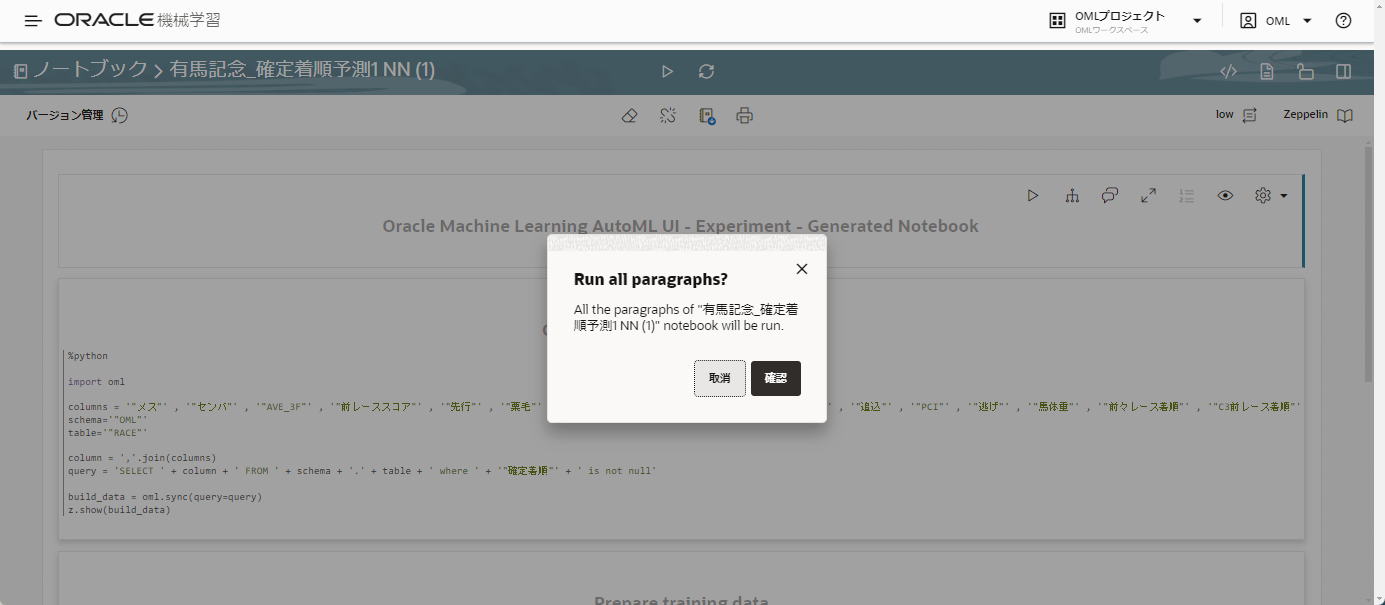
実行しても良いか聞いてきますので、確認を押します。
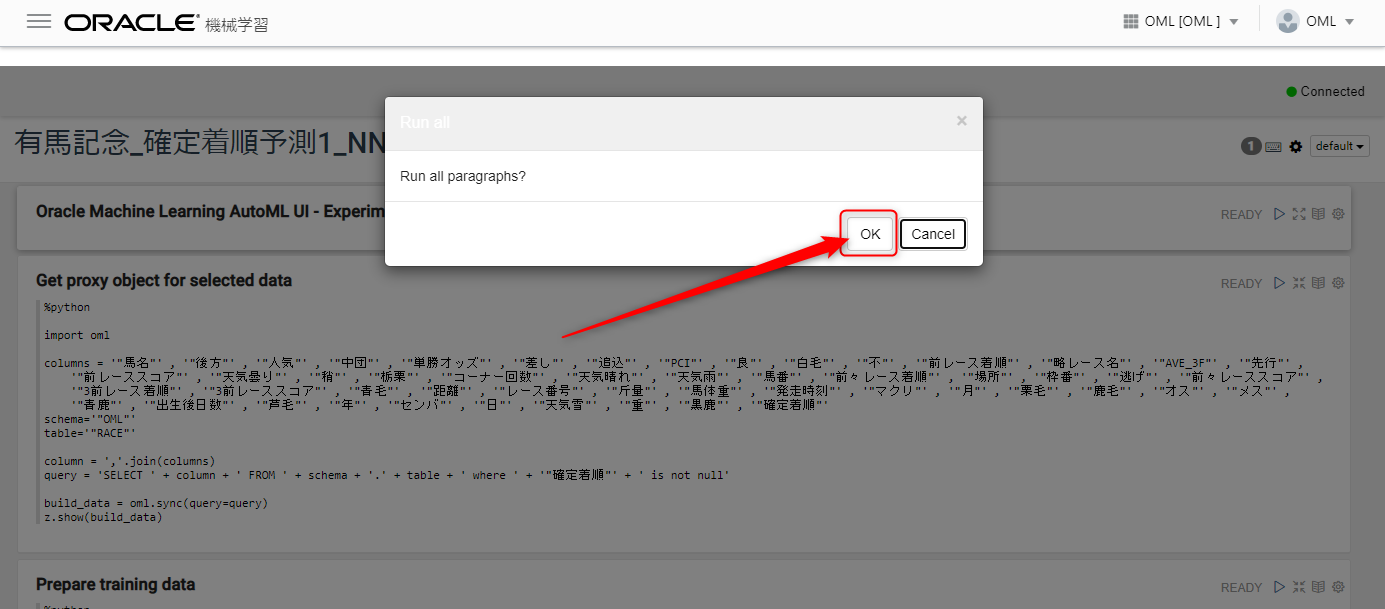
さらに「ユーザーの処理が必要」というメッセージが出現しますので、ここは「実行を許可」を押します。これによってPythonのコードが実行され、先ほどAutoMLで作成したモデルがメモリに展開されます。おそらく1分もかからずに処理が実行されると思います。

モデルに展開された後の流れとしては、TESTテーブルの内容も同様にメモリに展開し、その後でモデルに適用する形となります。
TESTテーブルの内容をメモリに展開するコードを1から書くのは面倒なので、Notebookの上の方にあるRACEテーブルを展開したときの記載を参考にしようと思います。
「Get proxy object for selected data」と書かれた部分のコードをコピーしておきます。
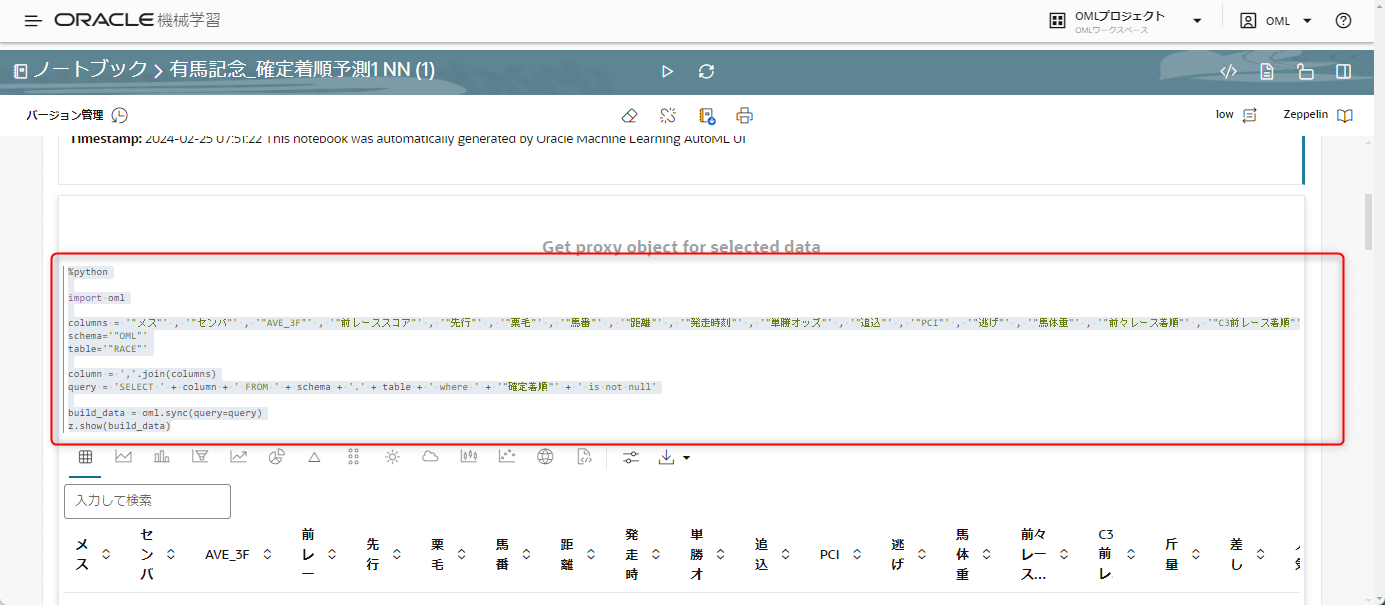
Notebookの一番下までスクロールして、その下にさらにコードを追加したいと思います。
一番下にカーソルを合わせると記号がいくつか出現しますので、+の記号をクリックします。

そうすると、入力できる欄が追加されます。
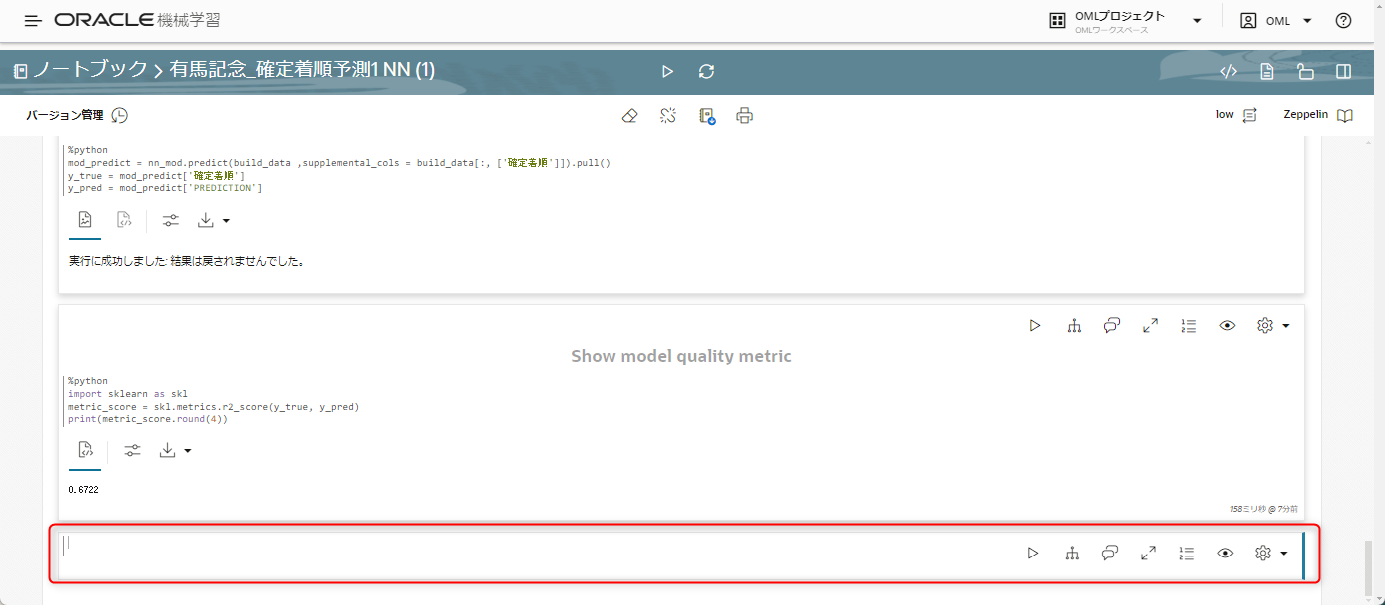
ここに、先ほどコピーした内容を張り付け、以下の4つの修正を行います。
- columns の中から予測する列の情報として「, '"確定着順"'」の情報を消す
- columns の中に馬名の情報が入っていない場合は、「'"馬名"' , 」を追加する
- tables = のところのテーブル名をTEST(大文字)に変える
- query = のところの table よりも右の文字を全部消す
画像としては以下になります。
こちらが入力出来たら、セルの右側にある三角形の実行ボタンを押します。

コードとしては以下を記載しました。
%python
import oml
columns = '"馬名"' , '"メス"' , '"センバ"' , '"AVE_3F"' , '"前レーススコア"' , '"先行"' , '"栗毛"' , '"馬番"' , '"距離"' , '"発走時刻"' , '"単勝オッズ"' , '"追込"' , '"PCI"' , '"逃げ"' , '"馬体重"' , '"前々レース着順"' , '"C3前レース着順"' , '"斤量"' , '"差し"' , '"人気"' , '"後方"' , '"コーナー回数"' , '"オス"' , '"前々レーススコア"' , '"出生後日数"' , '"前レース着順"' , '"レース番号"' , '"マクリ"' , '"場所"' , '"中団"' , '"不"' , '"C3前レーススコア"'
schema='"OML"'
table='"TEST"'
column = ','.join(columns)
query = 'SELECT ' + column + ' FROM ' + schema + '.' + table
build_data = oml.sync(query=query)
z.show(build_data)
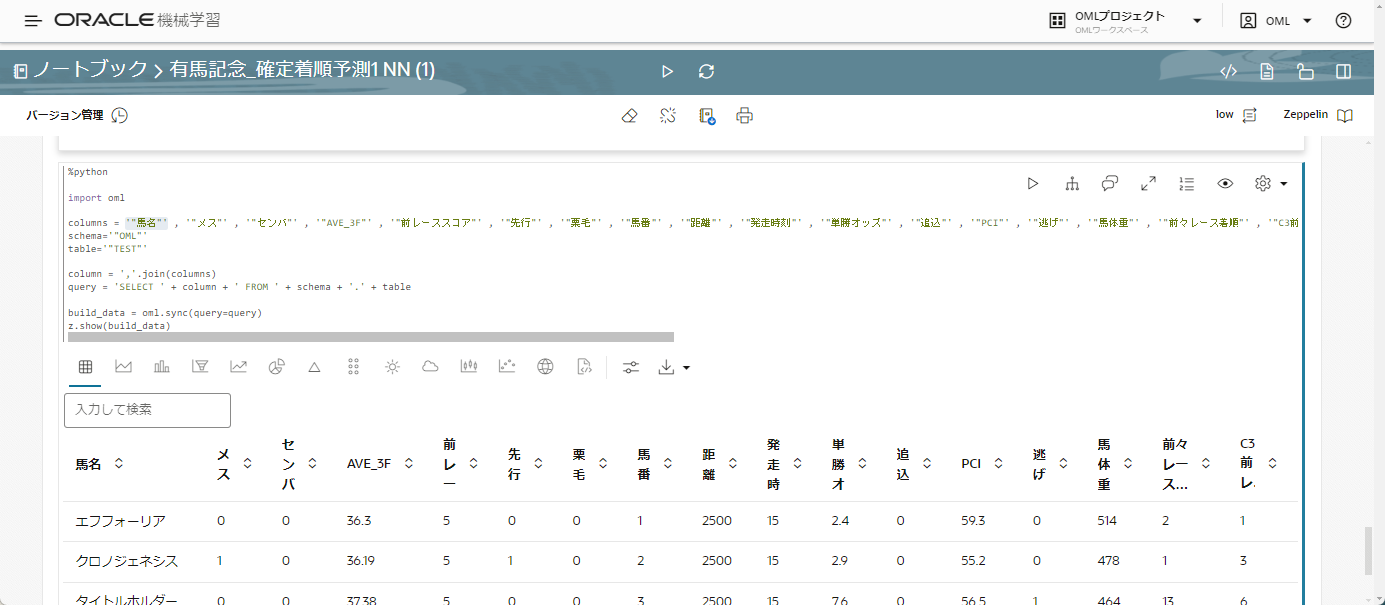
TESTテーブルのデータが表示されたらコードが正しく実行され、TESTテーブルが読み込まれた結果となります。
では続いてモデルをTESTテーブルに適用していきます。
カーソルを下に合わせ、+ボタンを押します。
新しい入力欄を出現させます。
この新しい欄にモデルを適用して予想結果を出力させていきますが、モデルの情報が格納された変数名は、採用するアルゴリズムによって異なります。そのため、自動的に生成されたPythonのコードを確認しなければわかりません。
まずは少し上の方に記載されている「Build MODEL_NAME_TITLE model」のところから、変数名を確認します。
この例では nn_mod という変数に情報が入っているようです。
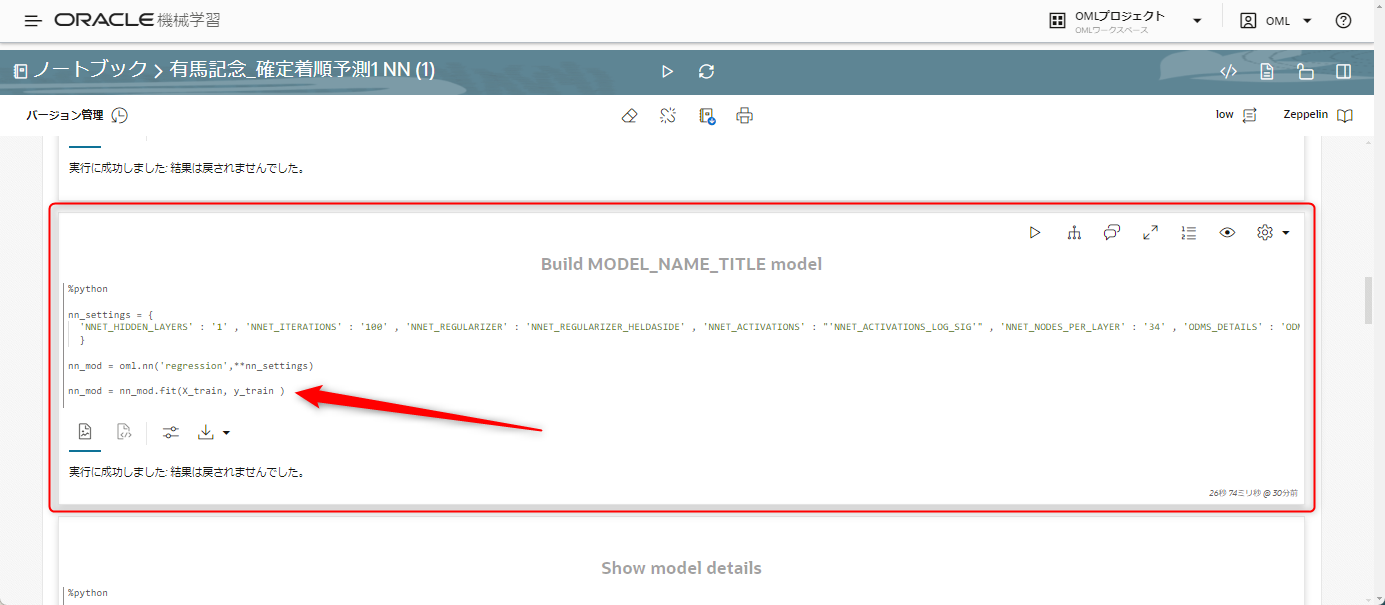
では、TESTテーブルをnn_modに適用して確定着順の予測結果を取得するために、先ほど追加した空欄にコードを書いていきます。
先ほどTESTテーブルをbuild_dataという関数に入れているため、それをモデルに適用します。
その結果を「予想着順」という列として用意し、モデルを適用する際に利用したテーブルに対して列をそのまま追加し、そのテーブルを「確定着順予測テーブル」というテーブルにして保存したのが以下のコードです。
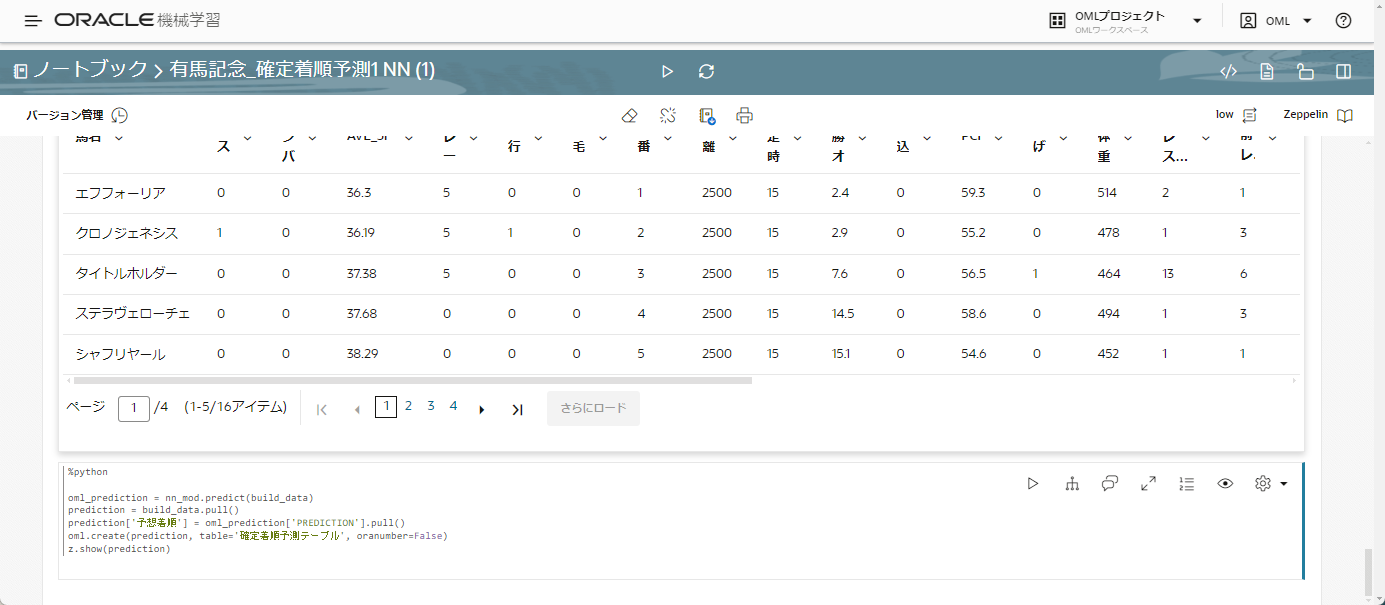
コードは以下です。
%python
oml_prediction = nn_mod.predict(build_data)
prediction = build_data.pull()
prediction['予想着順'] = oml_prediction['PREDICTION'].pull()
oml.create(prediction, table='確定着順予測テーブル', oranumber=False)
z.show(prediction)
これにより、「確定着順予測テーブル」に予測着順データが格納されました。
では、早速このデータを確認していきます。
このNotebookではSQLも実行できるため、その機能を使って結果を参照します。
まずはカーソルを下にもっていき、+ボタンを押して
以下のコードを入力して実行します。
コードは以下です。
%sql
select "馬名","予想着順" from "確定着順予測テーブル" order by "予想着順";
%sql から始まることにご注意ください。
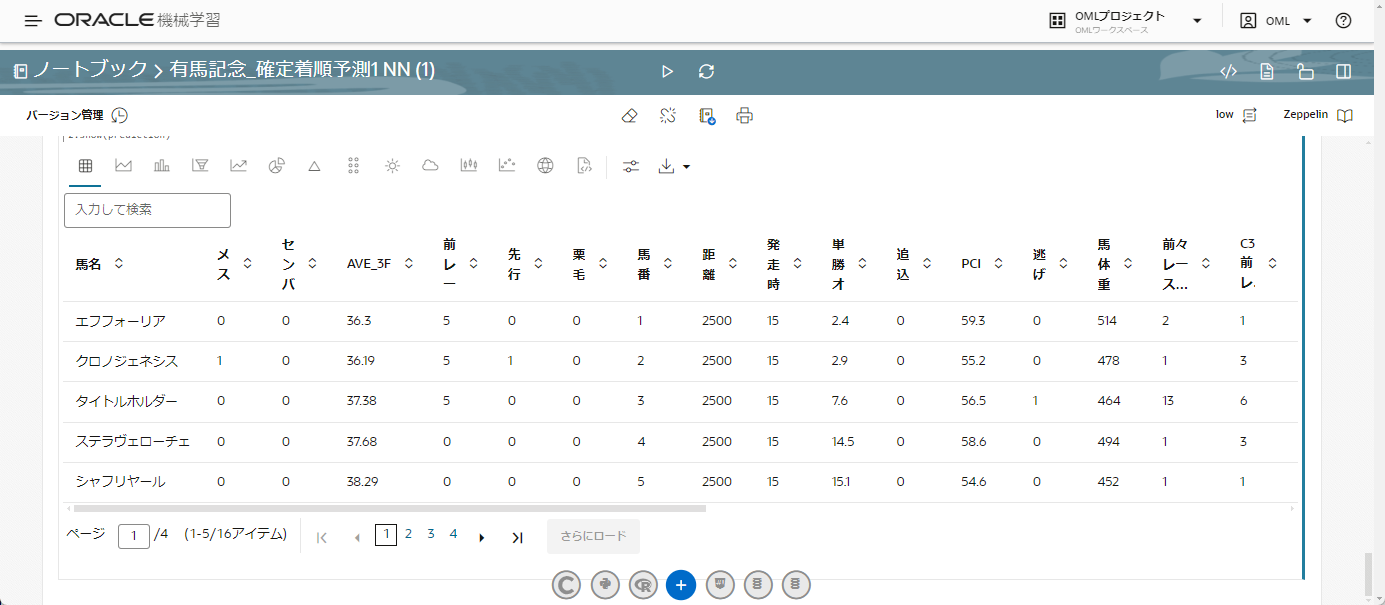
実行した結果は以下です。
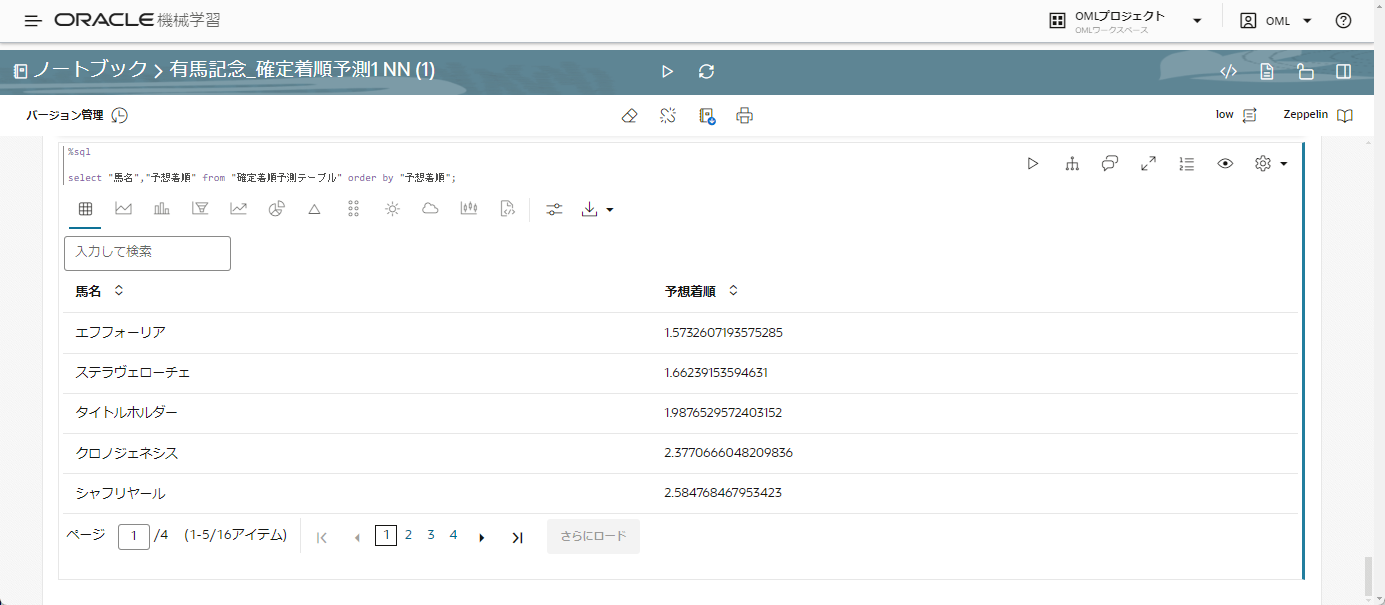
着順は値が小さければ小さいほど良い評価値なので、エフフォーリアが一番着順として数字が小さい=1着になる可能性が高いということがわかりました。
着順予想としては以上ですが、1着5点、2着3点、3着1点とした着順スコアの場合はどうなるのかも確認してみます。
着順スコアの予測
確定着順の予測を行いましたが、さすがにコースレコードの情報などから順位を予測するのは難しいと感じたため、着順のスコアを予測し、一番スコアの高い馬=1位を取る可能性が高いと考え、再分析を行いました。
AutoMLで先ほどと同様のデータを選びつつ、予測欄に「着順スコア」を選択します。
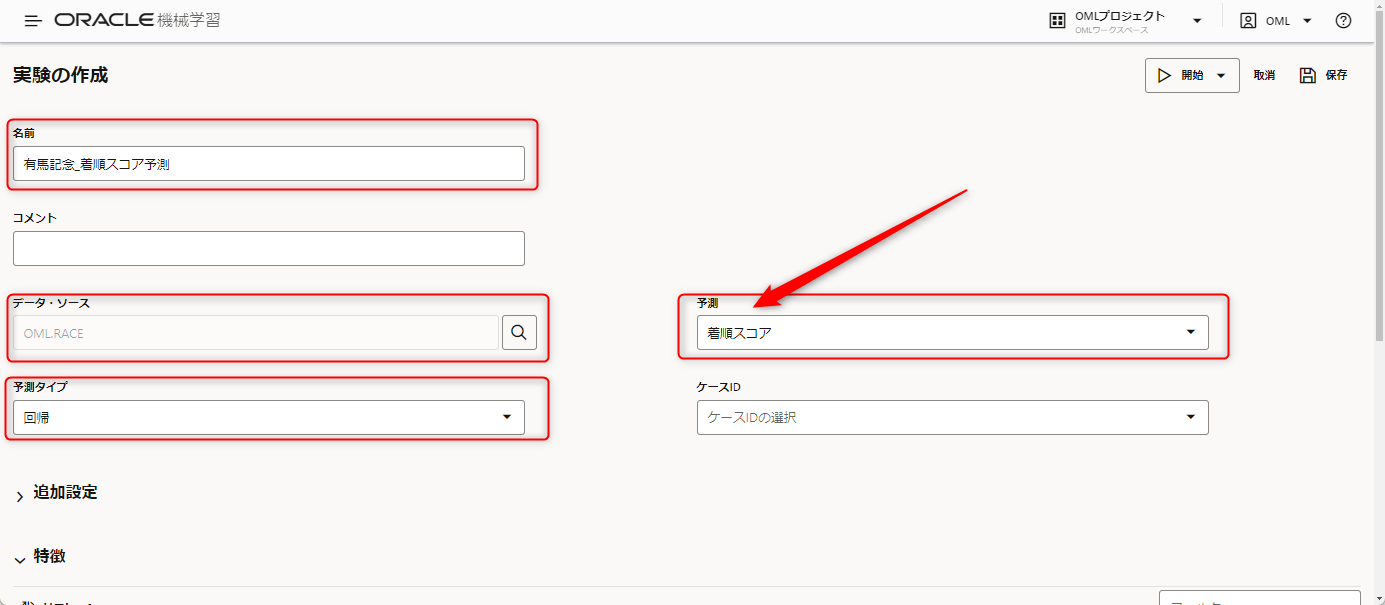
モデル・メトリックには先ほどの確定着順を予測したときと同じ評価軸を選択しています。

また、着順スコアを予想するうえで、確定着順の情報もTEST.csvには含まれていないため、チェックを外しておきます。
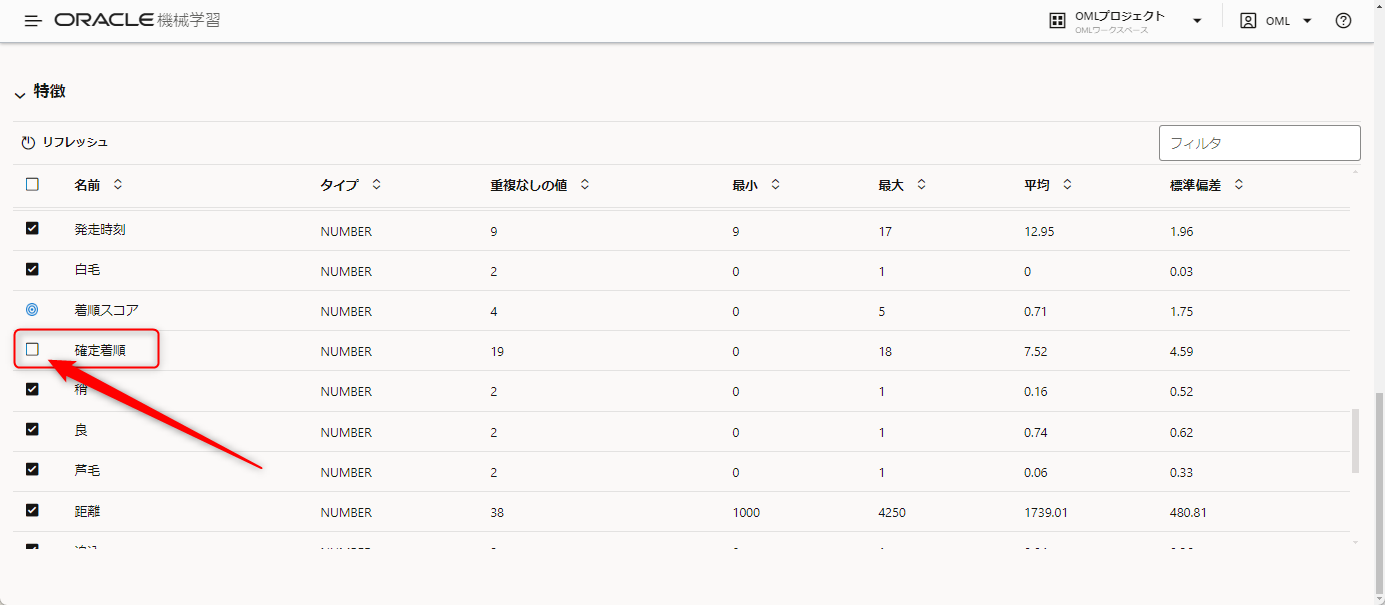
これをしておかないと、おそらく確定着順を採用した予想モデルができてしまうので注意が必要です。
この準備ができたら、画面の上までスクロールして開始ボタンを押します。
ここでは「より速い結果」を選択しました。
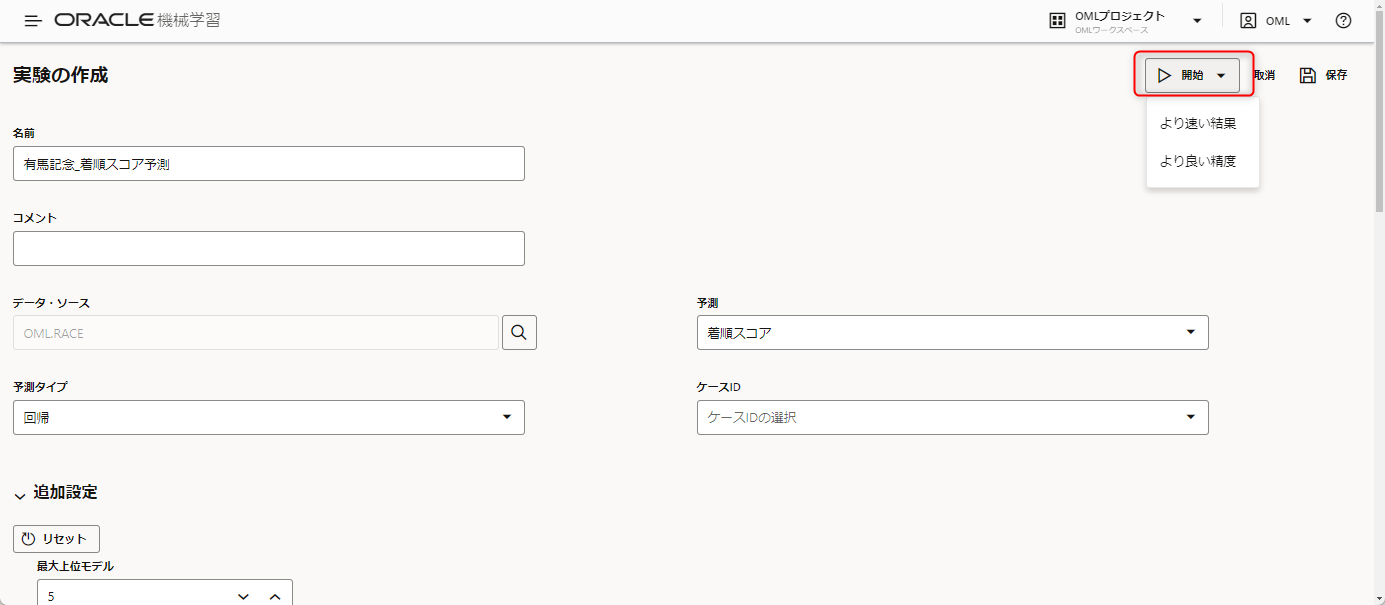
結果としては先ほど同様に3分で完了しました。
また、先ほどと同じくニューラル・ネットワークのアルゴリズムが一番精度が高い様子が確認されます。
ニューラル・ネットワークのモデルの詳細を確認してみます。
確定着順とは違い、今度は脚質の情報が多く影響しているようです。
(この例では、脚質の値ごとに列を追加し、該当する場合は1、該当しないなら0という列を追加しています)

ニューラル・ネットワークのモデルが一番精度として良いので、これでノートブックの作成を行います。
ノートブックが完成したら、ノートブックを開きます。

ノートブックの一番上の△を実行してノートブックを実行します。
画像はボタンをクリックした後の状態です。△が□になります。
最後まで実行できたら、一番下までスクロールして欄を追加します。
そこに、今度は当日のレースとして走る馬の情報が格納されたテーブルを呼び出します。
ここで、少しPythonのコードを記載します。
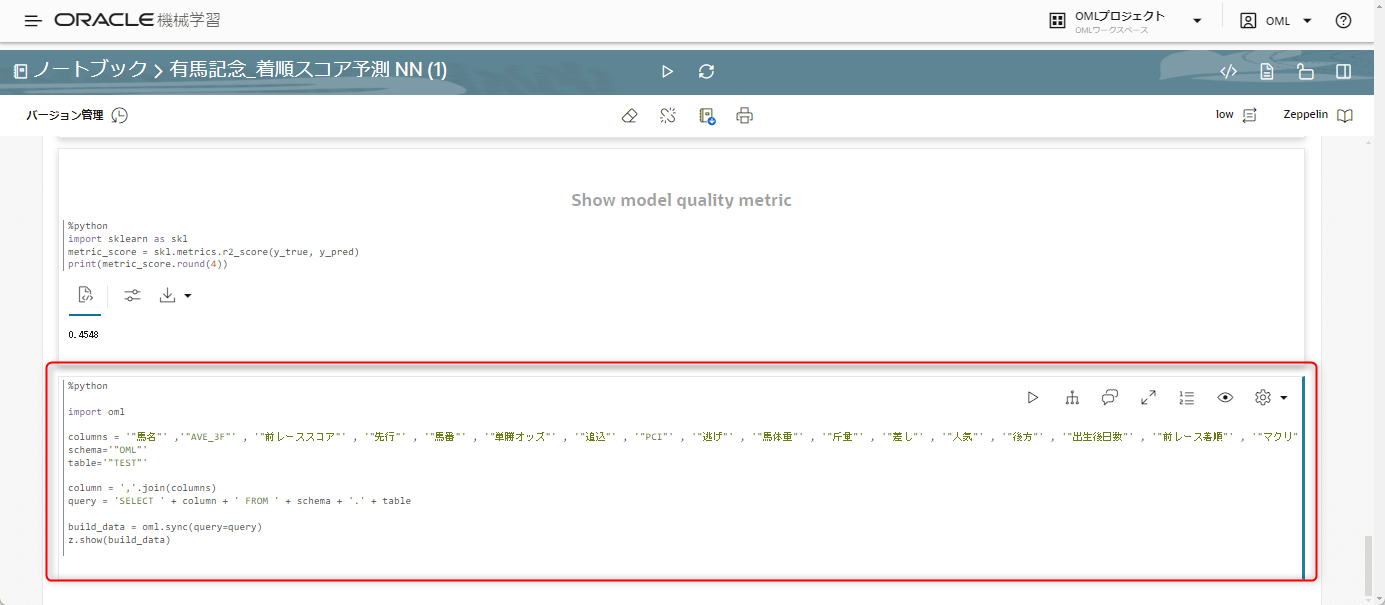
画像のコードとは違いますが、以下のコードを入力します。
今回はOMLユーザーのTESTというテーブルに、当日走る馬などの情報が格納されている想定です。
必要に応じてユーザー名とテーブル名は修正をしてください。
※ 大文字である必要がありますので注意してください。
%python
import oml
schema='"OML"'
table='"TEST"'
column = ','.join(columns)
query = 'SELECT * FROM ' + schema + '.' + table
build_data = oml.sync(query=query)
z.show(build_data)
エラー無く実行出来たら、今度はモデルを適用していきます。
今回は着順スコアを予測するモデルであるため、予測着順スコア列を追加し、結果を着順スコア予測テーブルとして生成します。

コードは以下です。
追加する列名を変更したい場合や、出力したいテーブル名を変えたい場合は自由に変更してください。
%python
oml_prediction = nn_mod.predict(build_data)
prediction = build_data.pull()
prediction['予想着順スコア'] = oml_prediction['PREDICTION'].pull()
oml.create(prediction, table='着順スコア予測テーブル', oranumber=False)
z.show(prediction)
着順スコア予測テーブルに予測結果が格納されたため、その情報をselect文で確認します。
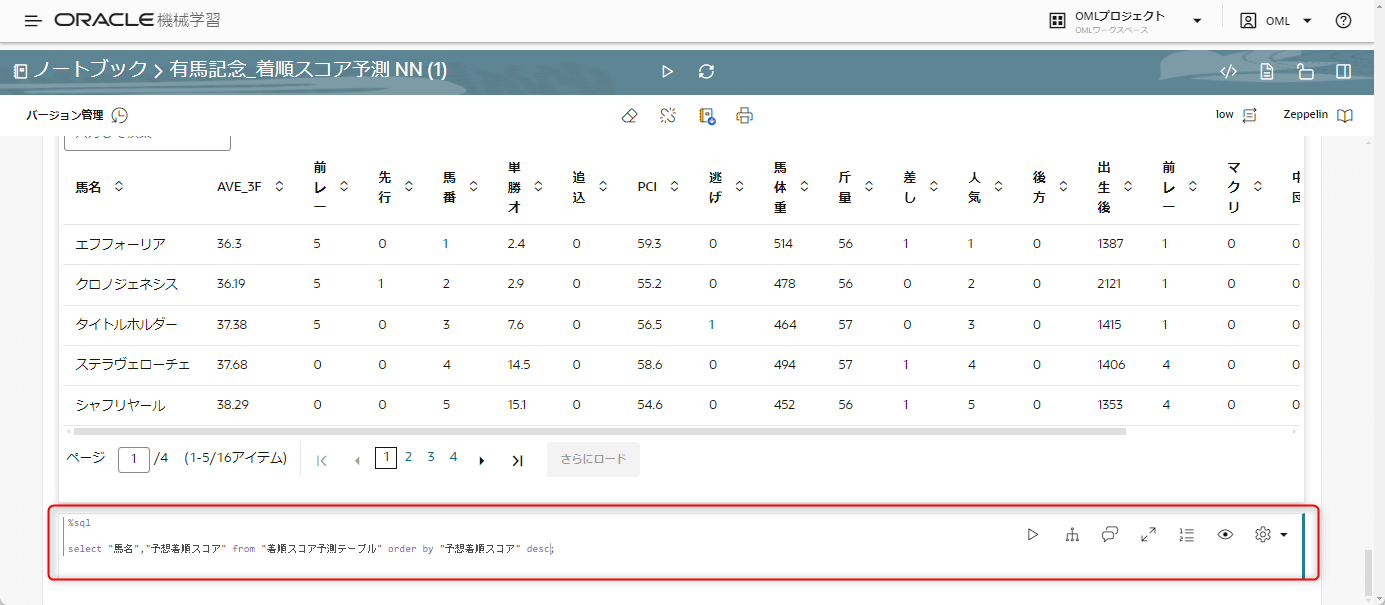
コードは以下です。
%sql
select "馬名","予想着順スコア" from "着順スコア予測テーブル" order by "予想着順スコア" desc;
実行した結果は以下になりました。

今回予想したのは着順スコアであり、スコアが高ければ高いほど予想順位が低いというものであるため、最もスコアの高い馬が1着になる可能性が高いということになります。
結果、予測スコアが最も高いのはこちらもエフフォーリアとなりました。
どちらにおいてもエフフォーリアが1着に来るという予測になっています。
実際の結果
実際のレースでは以下の順位でした
1位 エフフォーリア
2位 ディープボンド
3位 クロノジェネシス
ディープボンドの予測が出来ませんでしたが、1位の予測は的中することができました。
複勝であればかなりな確率で勝率を上げられるかもしれません。