概要
Oracle Autonomous DatabaseではAPEXを利用して様々なアプリを作れますが、ChatGPTに問い合わせるRAGシステムを構築するのにどうするか困る人が多いと思います。
SQLからChatGPTに問い合わせできたらRAGが捗るのにな・・・と思ったので、これを可能にするPL/SQLを作成しました。
この方法だとAutonomous DatabaseだけでRAGシステムが構築できるので、RAGシステムを作るうえでの選択肢の1つとして活用するのも良いと思います
作成したファンクションの実行イメージ
ファンクションの引数に、モデルと質問を記載すれば回答を返すイメージです。
select askllm.chatgpt('gpt-4o-mini','日本の首都は?') as chatgpt from dual;
CHATGPT
--------------------
日本の首都は東京です。
QAテーブルを作っておけば、回答も一気に出力できます。
-- 質問テーブルの作成
create table qa (id number, question varchar2(2000));
insert into qa values (1,'日本の首都は?');
insert into qa values (2,'アメリカの首都は?');
commit;
select question, askllm.chatgpt('gpt-4o-mini',question) as answer from qa;
QUESTION ANSWER
----------------- -----------------------------------------------------
日本の首都は? 日本の首都は東京です。
アメリカの首都は? アメリカの首都はワシントンD.C.(Washington, D.C.)です。
RAGもこの通り実行できます。
-- 情報テーブルの作成
create table information (id number, info varchar2(2000));
insert into information values (1,'大橋さんは六本木の帝王と呼ばれています');
commit;
set serveroutput on feed off
declare
question varchar2(2000) := '大橋さんのあだ名は何ですか?';
v_tmp varchar2(2000);
begin
select question || ' 以下の情報を参考にしてください。' || info into v_tmp from information where id = 1;
dbms_output.put_line('質問:' || question);
dbms_output.put_line('回答:' || askllm.chatgpt('gpt-4o-mini',v_tmp));
end;
/
質問:大橋さんのあだ名は何ですか?
回答:大橋さんのあだ名は「六本木の帝王」です。
前提条件
以下の環境で動作確認しています。
- Oracle Autonomous Database 19c
- Oracle Autonomous Database 23ai
また、ChatGPT APIを利用しています。
初回は無料枠が使えると思います。
事前準備
必要なステップとしては以下です。
1. ChatGPT API でAPIキーを発行する
2. Autonomous Database と、ChatGPTに問い合わせをするDBユーザーを作る
3. 作成したDBユーザーのアクセスコントロールリストにChatGPTのエンドポイントを追加する
4. 作成したDBユーザーで、ChatGPTのAPIキーなどのセンシティブな情報を格納したテーブルを作成する
5. 作成したDBユーザーで、ChatGPTに問い合わせするパッケージ askllm をインストールする
それぞれ解説します。
1. ChatGPT API でAPIキーを発行する
これに関しては多くの情報が出ていると思います。
Googleなどで検索してご確認ください
2. Autonomous Database と、ChatGPTに問い合わせをするDBユーザーを作る
OCIチュートリアルを参考にして、Autonomous DatabaseとDBユーザー(ADBUSER)を作成します。
手順通り作成すると有償のAutonomous Databaseが作成されてしまうので、検証目的であれば無償のAlways Freeをご選択ください。
この手順で作成するADBUSERというDBユーザーを利用して、これ以降のステップではChatGPTにアクセスできるようにしていきます。
なお、将来的にOCI Generative AIの利用も検討しているのであれば、大阪リージョンにAutonomous Databaseを構築したほうが良いです。
(2025/4時点で東京リージョンだとOCI Generative AIが利用できないため)
3. 作成したDBユーザーのアクセスコントロールリストにChatGPTのエンドポイントを追加する
コマンドラインでADBUSERに対してアクセスコントロールリストの更新を行います。
Autonomoous Databaseのデータベース・アクションからSQLを選び、SQLの画面を開いてください。
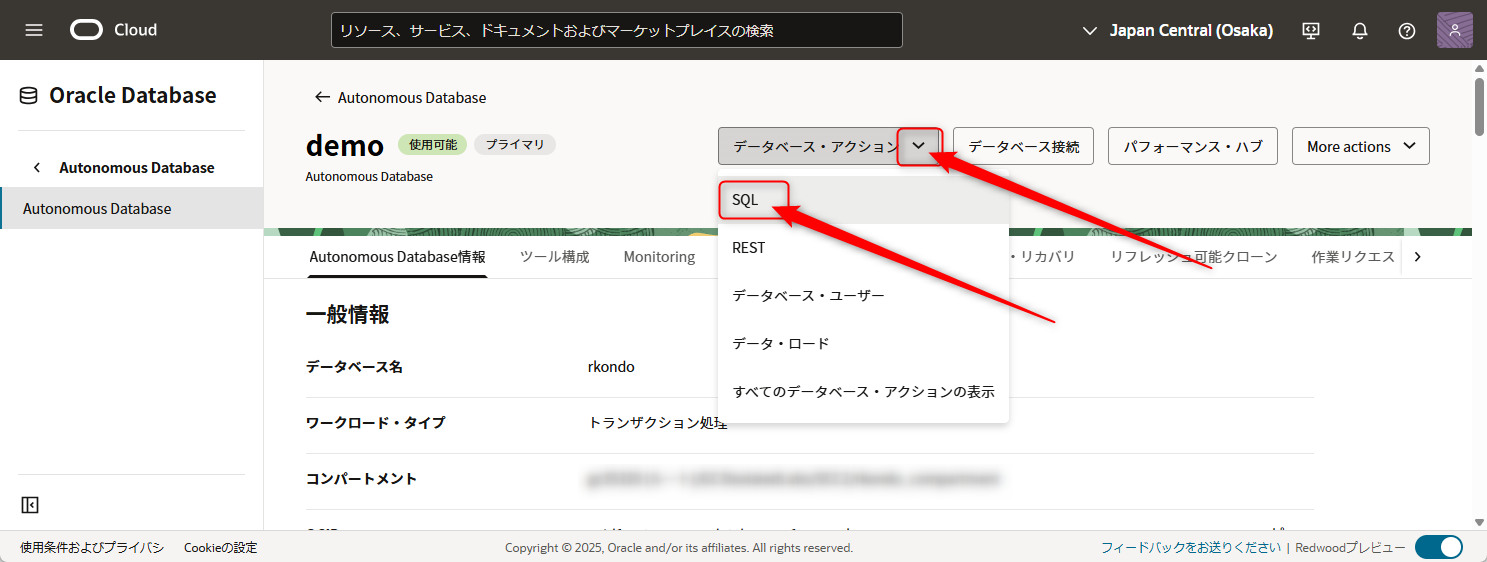
ここで追加するのは2つのアクセスコントロールです。
1つはADBUSERがWebアクセスを可能にするための設定であり、もう1つはADBUSERがChatGPTへのアクセスを可能にするための設定です。
SQLの画面が開いたら、以下に記載されたコマンドを画像の場所にペーストします
-- ADD ROLES
GRANT CONNECT,RESOURCE TO ADBUSER;
-- REST ENABLE
BEGIN
ORDS_ADMIN.ENABLE_SCHEMA(
p_enabled => TRUE,
p_schema => 'ADBUSER',
p_url_mapping_type => 'BASE_PATH',
p_url_mapping_pattern => 'adbuser',
p_auto_rest_auth=> TRUE
);
-- ENABLE DATA SHARING
C##ADP$SERVICE.DBMS_SHARE.ENABLE_SCHEMA(
SCHEMA_NAME => 'ADBUSER',
ENABLED => TRUE
);
commit;
END;
/
-- ENABLE ACCESS to ChatGPT
BEGIN
DBMS_NETWORK_ACL_ADMIN.APPEND_HOST_ACE(
host => 'api.openai.com', -- ChatGPT APIのエンドポイント
lower_port => 443, -- HTTPSのポート
upper_port => 443,
ace => xs$ace_type(privilege_list => xs$name_list('connect'),
principal_name => 'ADBUSER', -- 作成したユーザ名を指定
principal_type => xs_acl.ptype_db)
);
END;
/
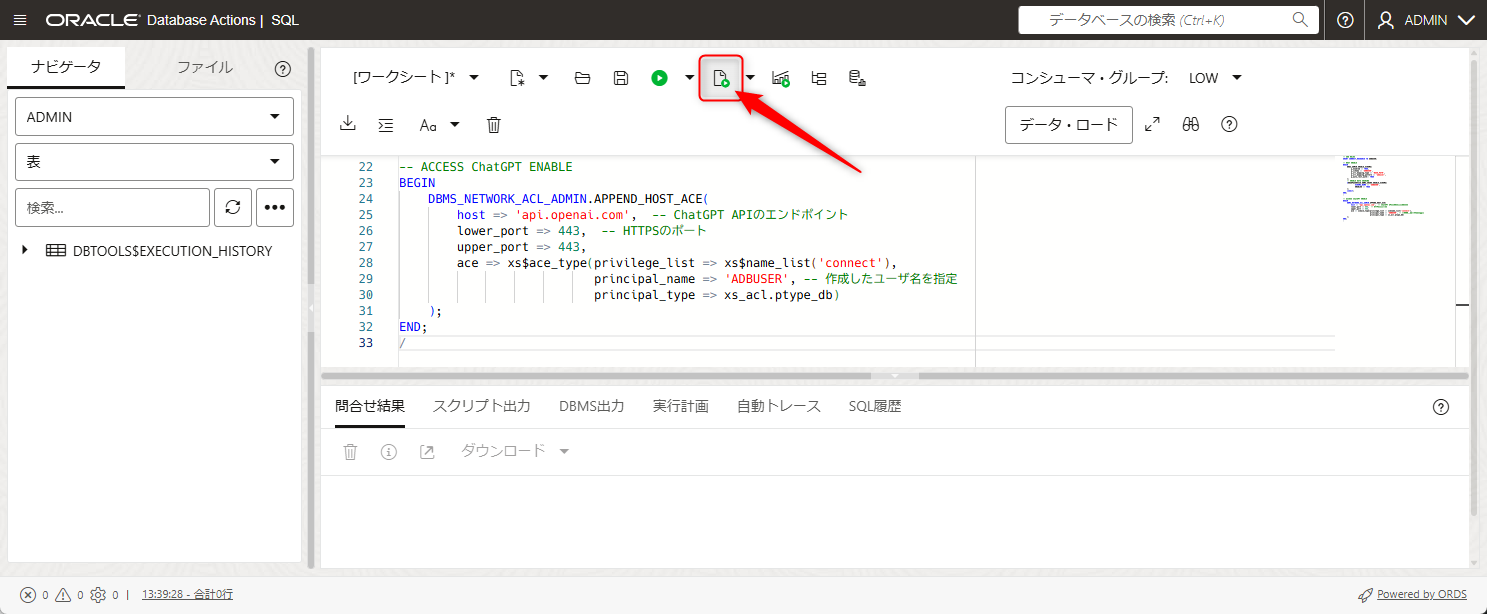
ペーストしたら矢印の場所か、F5キーを押します。
以下の部分に失敗したような記載が無ければ成功しています。
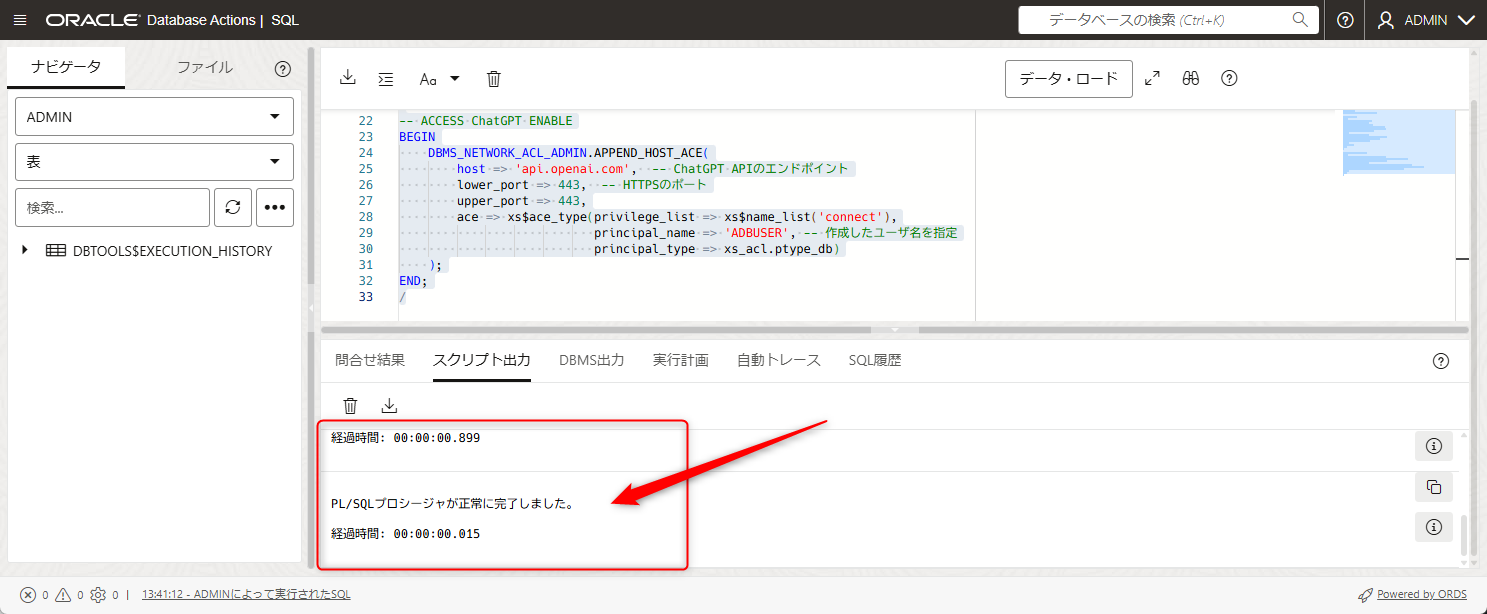
この作業によって、ADBUSERがWebアクセス、及びapi.openai.comにアクセスできるようになりました。
以上でADMINユーザーでの作業は終わりです。次からADBUSERでの作業を行います。
4. 作成したDBユーザーで、ChatGPTのAPIキーなどのセンシティブな情報を格納したテーブルを作成する
ADMINユーザーからADBUSERに切り替えるため、一旦画面右上のADMINのボタンからサインアウトを押します
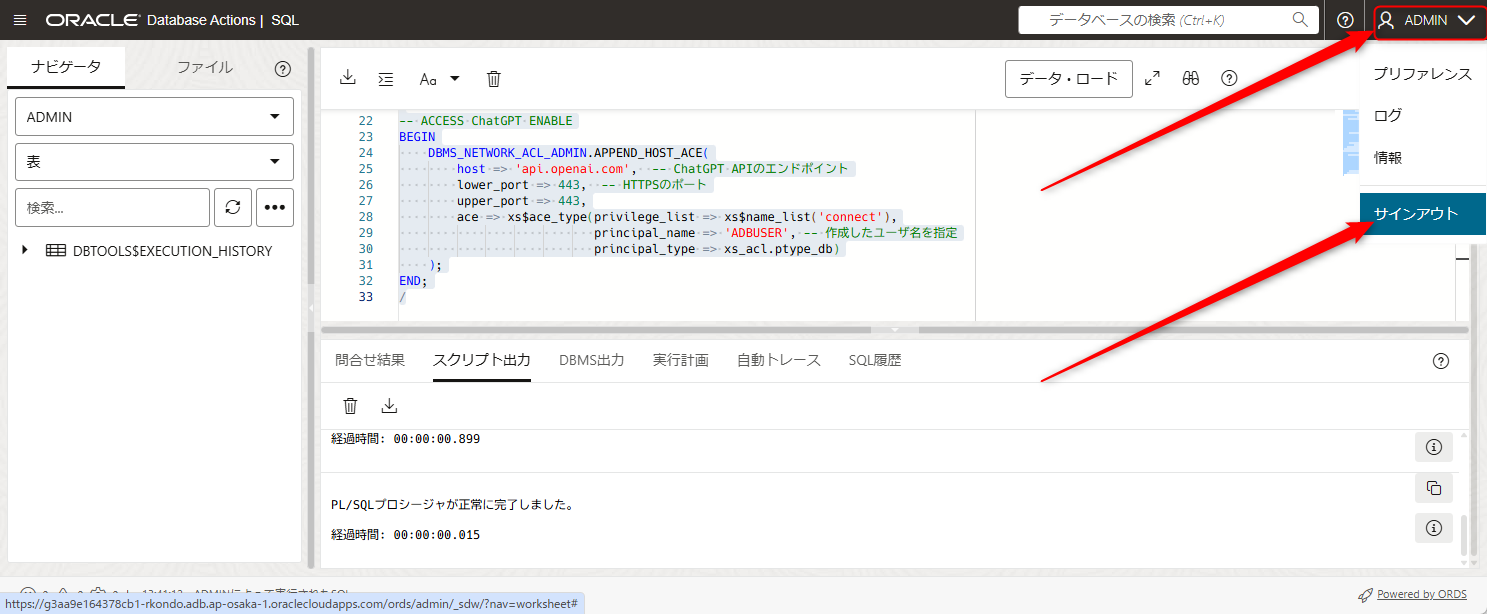
ログイン画面に切り替わりますので、作成したADBUSERでログインします。
SQLの画面になりましたら、以下のSQLを実行します。
このSQLの api_key のところは、ちゃんと利用可能なAPIキーにしてからllm_configテーブルにinsertしてください。
create table llm_config
( llm_name varchar2(100)
, llm_model varchar2(100)
, api_url varchar2(200)
, api_key varchar2(200)
);
-- sk-projから始まるところには、ChatGPTを利用するうえで有効なAPIキーを指定してください。
insert into llm_config values
( 'ChatGPT'
, 'gpt-4o'
, 'https://api.openai.com/v1/chat/completions'
, 'sk-proj-KWQZ85VNA<省略>_-z-RP4A');
insert into llm_config values
( 'ChatGPT'
, 'gpt-4o-mini'
, 'https://api.openai.com/v1/chat/completions'
, 'sk-proj-KWQZ85VNA<省略>_-z-RP4A');
commit;
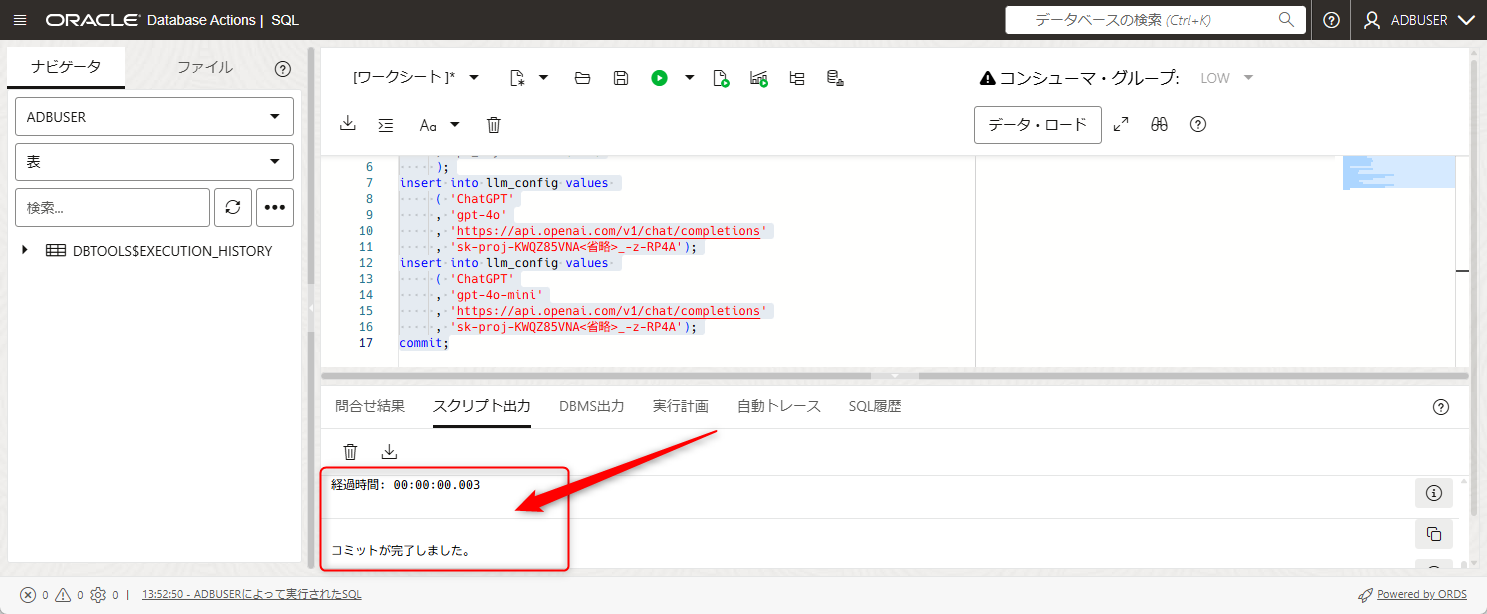
SQLを貼り付けたら、矢印の場所を押すかF5を押すことで実行されます。
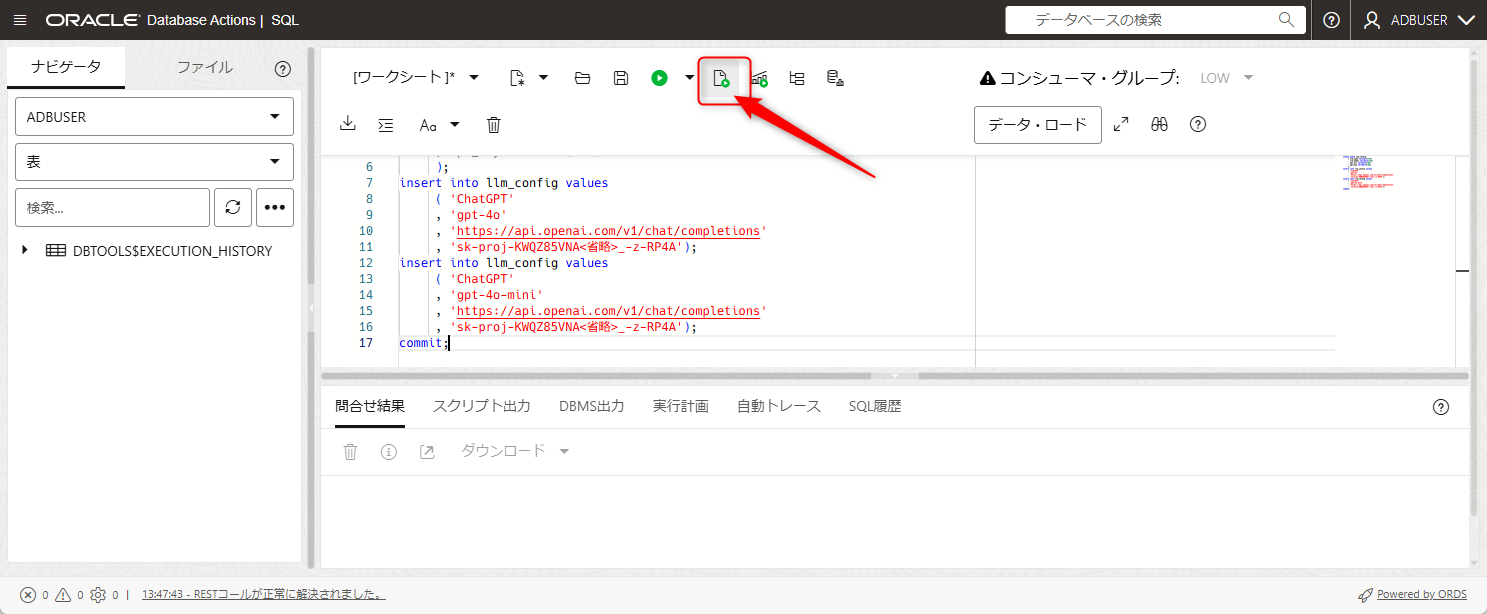
※ 上記画像のAPIキーでは動作しません。
実行したらエラーが発生していないかを確認しましょう。
5. 作成したDBユーザーで、ChatGPTに問い合わせするパッケージ askllm をインストールする
いよいよ最後の準備となります。まずは先ほど実行したSQLを削除しましょう。
その後、以下のPL/SQLのコードを貼り付けます。
create or replace package askllm
as
function chatgpt (i_model_name IN VARCHAR2, i_prompt_text IN CLOB) return CLOB;
end;
/
create or replace package body askllm
is
function chatgpt (i_model_name IN VARCHAR2, i_prompt_text IN CLOB) return CLOB
is
v_api_url VARCHAR2(200);
v_api_key VARCHAR2(200);
v_req UTL_HTTP.REQ;
v_res UTL_HTTP.RESP;
v_clob_response CLOB;
v_json_request CLOB;
o_result CLOB;
begin
-- 指定されたモデルのAPI情報を取得
SELECT api_url, api_key INTO v_api_url, v_api_key FROM llm_config WHERE llm_model = i_model_name;
-- リクエストJSONの作成
-- 参考:https://platform.openai.com/docs/api-reference/chat/create
v_json_request := '{
"model": "' || i_model_name || '",
"messages": [
{"role": "developer", "content": "You are a helpful assistant."},
{"role": "user", "content": ' || APEX_JSON.stringify(i_prompt_text) || '}
],
"max_tokens": 1000,
"temperature": 0
}';
-- HTTPリクエストの作成
v_req := UTL_HTTP.BEGIN_REQUEST(v_api_url, 'POST', 'HTTP/1.1');
UTL_HTTP.SET_HEADER(v_req, 'Content-Type', 'application/json; charset=UTF-8');
UTL_HTTP.SET_HEADER(v_req, 'Authorization', 'Bearer ' || v_api_key);
UTL_HTTP.SET_HEADER(v_req, 'Content-Length', DBMS_LOB.GETLENGTH(v_json_request));
-- リクエストボディの送信
UTL_HTTP.WRITE_TEXT(v_req, v_json_request);
-- レスポンスの取得
v_res := UTL_HTTP.GET_RESPONSE(v_req);
-- レスポンスの文字セットをUTF-8に設定(日本語対策)
UTL_HTTP.SET_BODY_CHARSET(v_res, 'AL32UTF8');
-- READ_TEXT を使用してCLOBに直接レスポンスを取得
begin
LOOP
UTL_HTTP.READ_TEXT(v_res, v_clob_response, 32767);
END LOOP;
EXCEPTION
WHEN UTL_HTTP.END_OF_BODY THEN
NULL;
UTL_HTTP.END_RESPONSE(v_res);
end;
-- レスポンスの中でchoices[0].message.contentの内容を抽出
SELECT JSON_VALUE(v_clob_response, '$.choices[0].message.content') INTO o_result FROM DUAL;
-- 抽出した回答をretuen
RETURN o_result;
end chatgpt;
END;
/
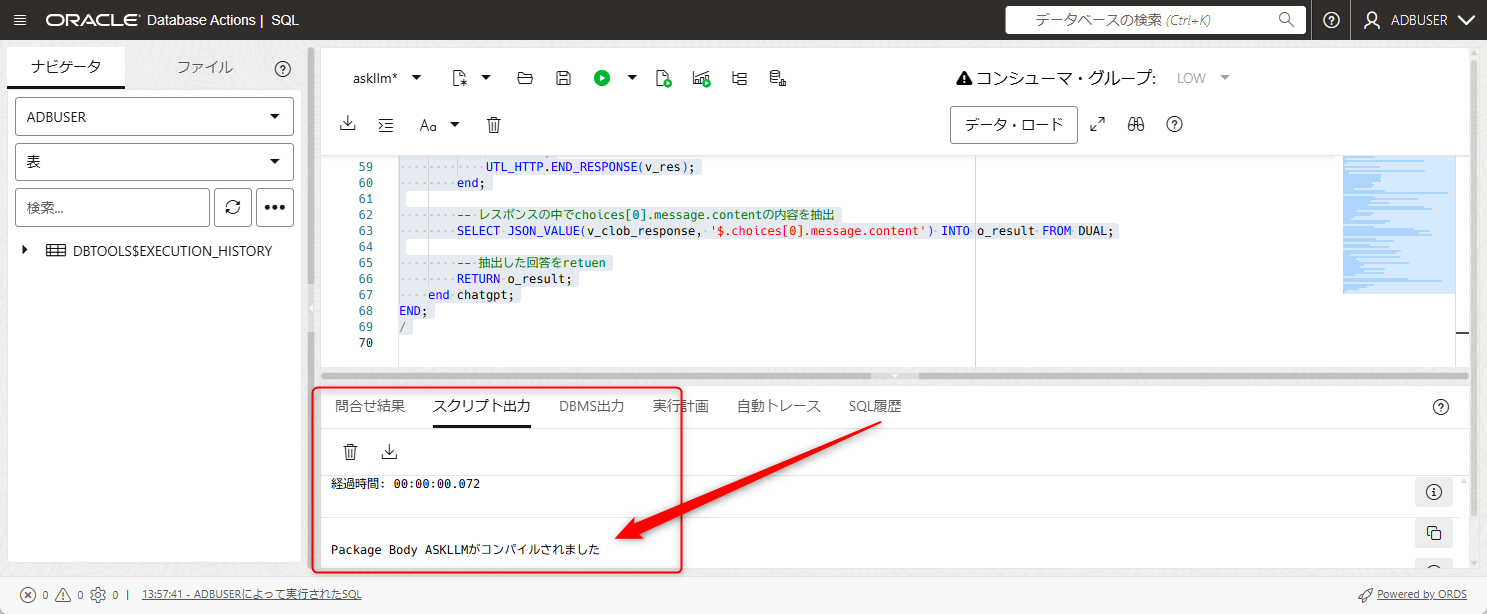
今までと同様にPL/SQLのコードを貼り付けたら、矢印の場所を押すかF5を押すことで実行されます。
実行結果のところに「Package Body ASKLLMがコンパイルされました」と表示されれば成功です。
これでChatGPTに問い合わせる準備は完了しました。
ChatGPTに問い合わせをしてみよう
例えば以下を実行してみましょう
select askllm.chatgpt('gpt-4o','人口が一番少ない都道府県はどこ?') as chatgpt from dual;
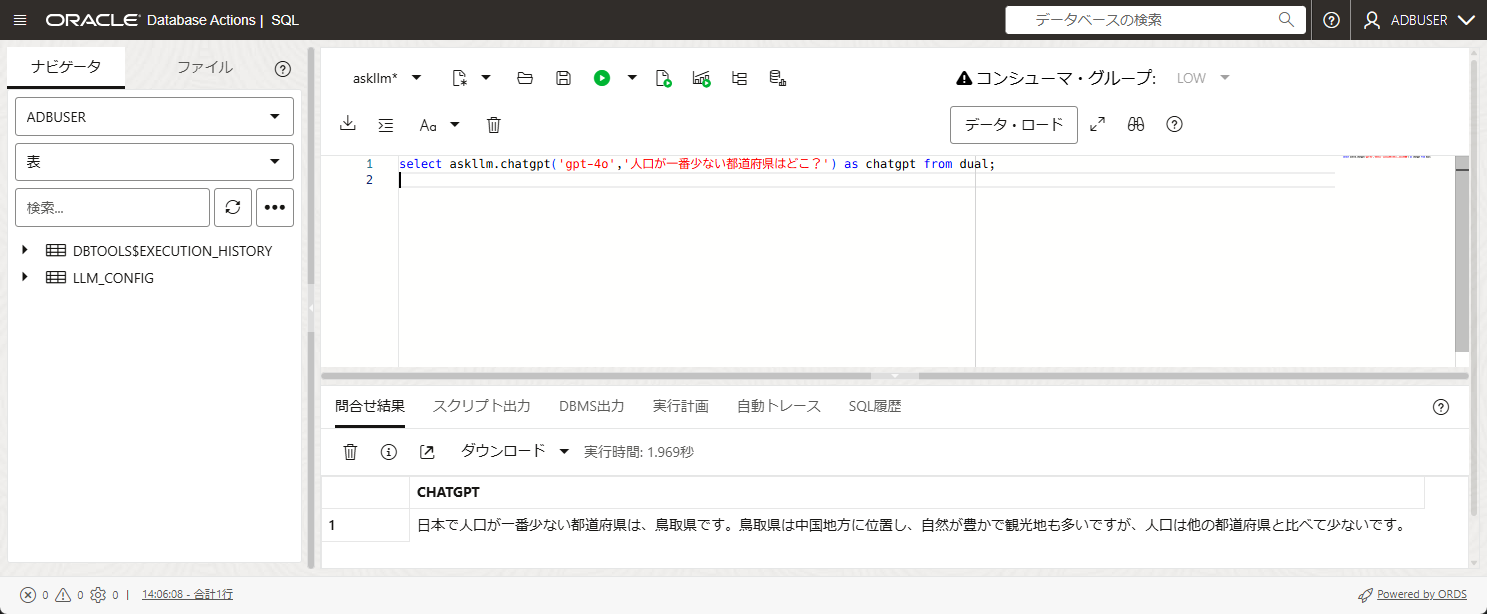
回答を取得できました!
小ネタ
SQL Developerから実行するとなぜか回答される文字が途中で切れる問題が生じました。
ファンクションはCLOBの戻り値なので、おそらくLOBの表示で何らかの制限が生じていると思います。
この場合は以下のように問い合わせすることで文字が切れずに表示させることができます。
select DBMS_LOB.SUBSTR(askllm.chatgpt('gpt-4o-mini','おいしい日本酒の提議を教えてください'), 30000, 1) as chatgpt from dual;
また、データの分析をさせる際に、例えばテーブルの内容をあたかもcsv形式のように返すファンクション(get_table_data_as_clob)を作成した場合、このファンクションと組み合わせてサマリを分析させることもできます。
※ get_table_data_as_clob は自作のファンクションなので、以下を実行しても結果は出力されません。
以下はサンプルとして提供されているEMP表の特徴をgpt-4o-miniに問い合わせた結果です。
set serveroutput on
DECLARE
v_table_data CLOB;
BEGIN
-- EMPテーブルのデータを取得
v_table_data := get_table_data_as_clob('EMP');
select askllm.chatgpt('gpt-4o-mini','以下のデータの特徴を教えてください。 ' || v_table_data) into v_table_data from dual;
-- 結果を出力
DBMS_OUTPUT.PUT_LINE(v_table_data);
END;
/
このデータは、従業員の情報を含むテーブルの形式で、各列は以下のような特徴を持っています。
1. **EMPNO (従業員番号)**: 各従業員に一意に割り当てられた番号です。数値形式で、重複はありません。
2. **ENAME (従業員名)**: 従業員の名前が含まれています。日本人の名前が記載されており、姓と名が含まれています。
3. **JOB (職種)**: 従業員の職務や役職を示しています。役職には「社長」「マネージャー」「アナリスト」「店員」「セールス」などがあります。
4. **MGR (上司の従業員番号)**: 各従業員の上司の従業員番号を示しています。上司がいない場合はNULLとなっています。これにより、組織の階層構造を把握することができます。
5. **HIREDATE (雇用日)**: 従業員が雇用された日付を示しています。形式は「YY-MM-DD」で、雇用された年と月、日が記載されています。
6. **SAL (給与)**: 従業員の月給を示しています。数値形式で、各従業員の給与が記載されています。
7. **COMM (コミッション)**: セールス職に従事する従業員のコミッション(手数料)を示しています。セールス職以外の従業員はNULLとなっています。
8. **DEPTNO (部門番号)**: 従業員が所属する部門の番号を示しています。部門番号は数値で、異なる部門が存在します。
### データの特徴
- **役職の多様性**: データには異なる役職が含まれており、特にマネージャーやセールス職が多く見られます。
- **給与の幅**: 従業員の給与は5000から950までと幅があります。社長の給与が最も高く、店員の給与が比較的低いです。
- **コミッションの存在**: セールス職の従業員にはコミッションが設定されており、他の職種には設定されていません。
- **階層構造**: 上司の従業員番号が設定されていることで、組織の階層構造を把握することができます。社長が最上位に位置し、その下にマネージャー、さらにその下に店員やセールス職がいます。
- **雇用日の分布**: 雇用日は1980年代初頭から1983年までの範囲で、比較的古いデータです。
このデータは、従業員の管理や組織の分析に役立つ情報を提供しています。
PL/SQLプロシージャが正常に完了しました。
注意点
こちらのファンクションはLLMをPL/SQL経由で簡単に使いやすくする(ラップしている)だけなので、LLMが要求するJSONのフォーマットが変わると当然動作しなくなります。
例えばChatGPTも将来gpt-5とかが出てくると思いますが、その都度JSONのフォーマットに違いが無いかなどを確認して使う必要がありますのでご注意ください。