概要
Vicuna-13B とは ChatGPT や Bard の 90% くらいの能力を持つらしい大規模言語モデルです。
13B ということで、130億パラメータだけで、3500億パラメータ以上はあるであろう ChatGPT(GPT4)の 90% の能力はおどろきじゃ、ということで、これを Vicuna-13B を自分の環境で動かす準備のメモです。
Vicuna のリリースレポジトリ の README によりますと
Announcement: Thank you for checking out our project and your interest! We plan to release the model weights once we have addressed all legal concerns and have a low-resource version of the inference code ready. Based on our current timeline, it will be available by early next week. Please stay tuned!
とのことで、
肝心の Vicuna-13B のモデルは 2023/4/3 時点で、まだ公開されておりません ので公開されたらすぐに試せるように手ぐすね引いて待って居ようという魂胆です。
Vicuna-13B の実力が知りたければ本家デモサイトにいけばすぐに試すことが可能です
本編
実験環境
- Windows 11
- Anaconda
STEP 1: 仮想環境を作る
Anaconda Prompt を起動して env-vicuna という名前の仮想環境を作る
conda create -n env-vicuna
env-vicuna 仮想環境の使用を開始する
activate env-vicuna
STEP 2: 仮想環境に python を導入する
新しく作成した仮想環境では python すら導入されてないので、pythonを入れる
python の一覧を表示する
conda search python
...
python 3.10.8 h966fe2a_1 pkgs/main
python 3.10.8 hbb2ffb3_0 pkgs/main
python 3.10.9 h966fe2a_0 pkgs/main
python 3.10.9 h966fe2a_1 pkgs/main
python 3.10.9 h966fe2a_2 pkgs/main
python 3.10.10 h966fe2a_2 pkgs/main
python 3.11.0 h966fe2a_2 pkgs/main
python 3.11.0 h966fe2a_3 pkgs/main
python 3.11.2 h966fe2a_0 pkgs/main
pythonをインストールする
conda install python=3.10.10
これで python コマンドや pip コマンドが利用できるようになった
STEP 3: インストールする
3-1 Vicuna-13B のリリース元リポジトリをクローンする
git clone https://github.com/lm-sys/FastChat.git
3-2 必要パッケージをインストールする
cd FastChat
pip3 install --upgrade pip
pip3 install -e .
pip3 install git+https://github.com/huggingface/transformers
STEP 4: windowsの場合は開発者モードを有効にしておく
次にさっそくチャットを起動するところだが、
その際、指定したモデルデータ(事前学習済データ)を huggingface_hub から自動ダウンロードする。
自動ダウンロードのとき、huggingface_hub のキャッシュシステムが重複したファイルを効率的に保存するためにデフォルトでシンボリックリンクを使用する。
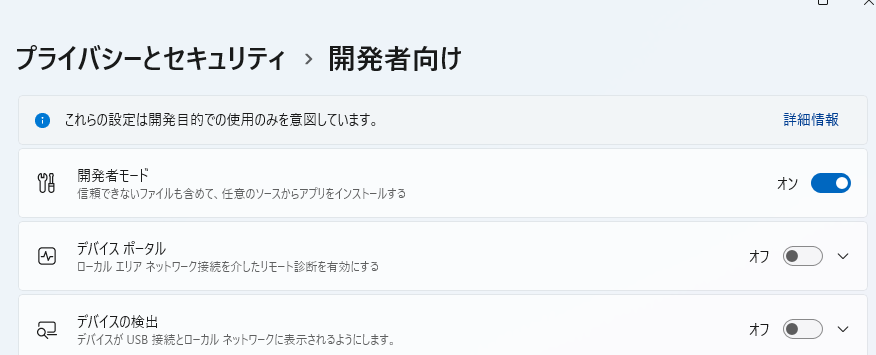
Windows の場合、通常、シンボリックリンクは使えないので、シンボリックリンクを有効にしてディスクスペースを効率的に使いたい場合は、Windows を以下の手順で 開発者モード にする。(シンボリックリンク無しでも使える)
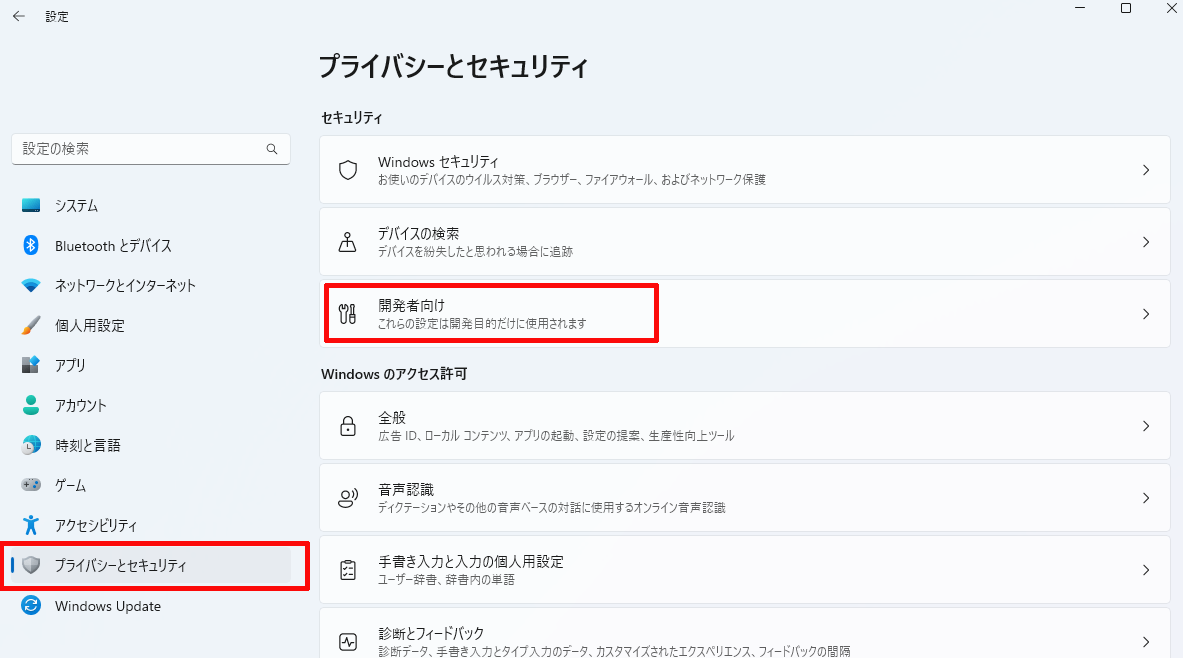
Windows を 開発者モードにする方法
設定>プライバシーとセキュリティ>開発者向け を開く
開発者モード を有効にする
STEP 5: CLIチャットを実行する
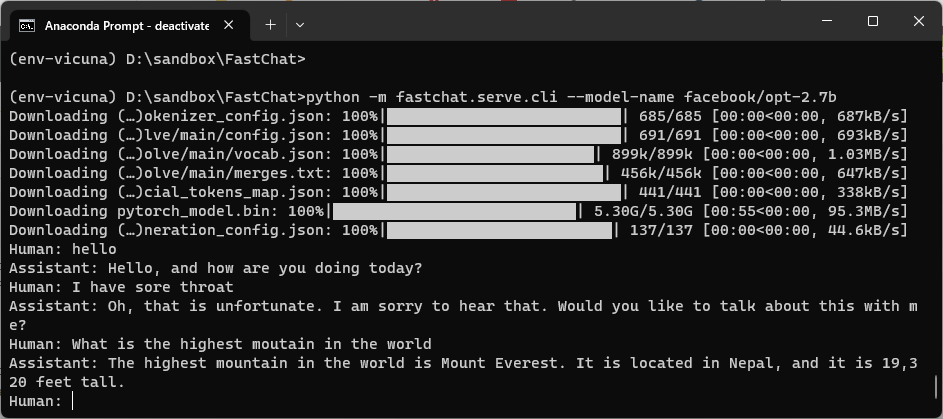
Vicuna-13B はまだ無いので、 MetaのOPT のモデルでとりあえずチャットが動くことを確認する。
python -m fastchat.serve.cli --model-name facebook/opt-2.7b
これで huggingface から facebook/opt-2.7b モデル一式をダウロード後、チャットが起動した。
ちなみに、モデルファイルは、C:/Users/[ユーザー名]/.cache/huggingface に保存される。
まとめ
- Vicuna-13B のリリース元のリポジトリをクローンしてテキストチャットするところまで準備をしました。
- 準備はととのいました。はよこい、 Vicuna-13B 学習済モデル。
- 13B ということでは、ローカルPCのGPUメモリには乗り切らないだろう。GPUクラウドで試す感じかな。
- できれば 7B もほしいなぁ。
おまけ
おまけ1
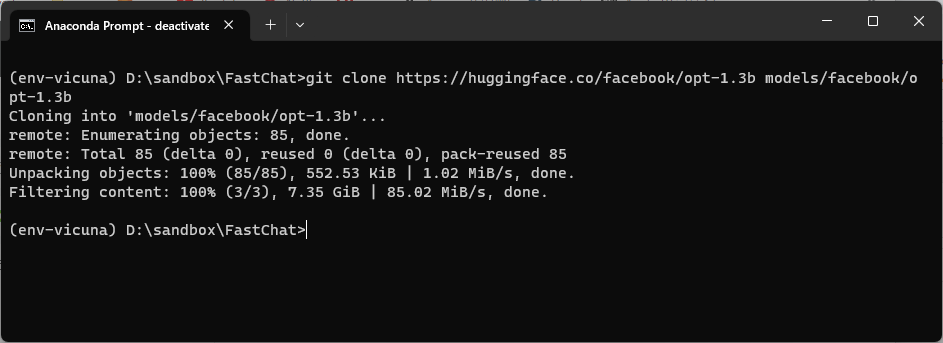
学習済モデルを自前でダウンロードする方法
(ただし、本来必要ないファイルまでダウンロードされてしまうので注意。たとえば pytorchの重みファイルだけあればいいのに、 TensorFlow や Flax といった別のライブラリ用の学習済ファイルもダウンロードされちゃう)
git clone https://huggingface.co/facebook/opt-1.3b models/facebook/opt-1.3b
python -m fastchat.serve.cli --model-name D:/sandbox/FastChat/models/facebook/opt-1.3b
おまけ2
おまけ1で git コマンドでダウンロードしたファイルは以下のようになる。1つ1つファイルの説明も記載しておく。
Hugging FaceのTransformersライブラリを使用して事前学習済みの言語モデルを利用する際に必要となるファイル
.gitattributes
config.json
flax_model.msgpack
generation_config.json
LICENSE.md
merges.txt
pytorch_model.bin
README.md
special_tokens_map.json
tf_model.h5
tokenizer_config.json
vocab.json
.gitattributes:
Gitリポジトリの属性設定ファイル。ファイルやディレクトリに対して改行コードの扱いやGit LFSの設定などを行う。
config.json:
モデルの設定情報が書かれたJSONファイル。アーキテクチャや学習時のハイパーパラメータなどが含まれる。
flax_model.msgpack:
Flaxフレームワーク用のモデルの重みファイル。FlaxはJAXをベースにしたニューラルネットワークライブラリ
generation_config.json:
文章生成タスクで使われる設定情報が書かれたJSONファイル。生成アルゴリズムや生成パラメータが記述されている。
LICENSE.md:
モデルのライセンス情報
merges.txt:
モデルのトークナイザが使うバイトペアエンコーディング(BPE)のマージルールが書かれたテキストファイル。
pytorch_model.bin:
PyTorch用のモデルの重みファイル。
README.md:
モデルのREADME
special_tokens_map.json:
特殊トークン(例:BERTでいう[CLS]や[SEP]とか)とIDのマッピングが書かれたJSONファイル。トークナイザで使われる。
tf_model.h5:
TensorFlow用のモデルの重みファイル。
tokenizer_config.json:
モデルのトークナイザで使われる語彙リストが書かれたJSONファイル。各トークンとそのIDのマッピングが定義されている。
vocab.json:
モデルのトークナイザで使用される語彙のリストが記述されたJSONファイル