概要
学習済 LLM(大規模言語モデル)のパラメータ数と食うメモリ容量(予想含む)、ホストできるGPUを調べたメモ ※適宜修正、拡充していく。
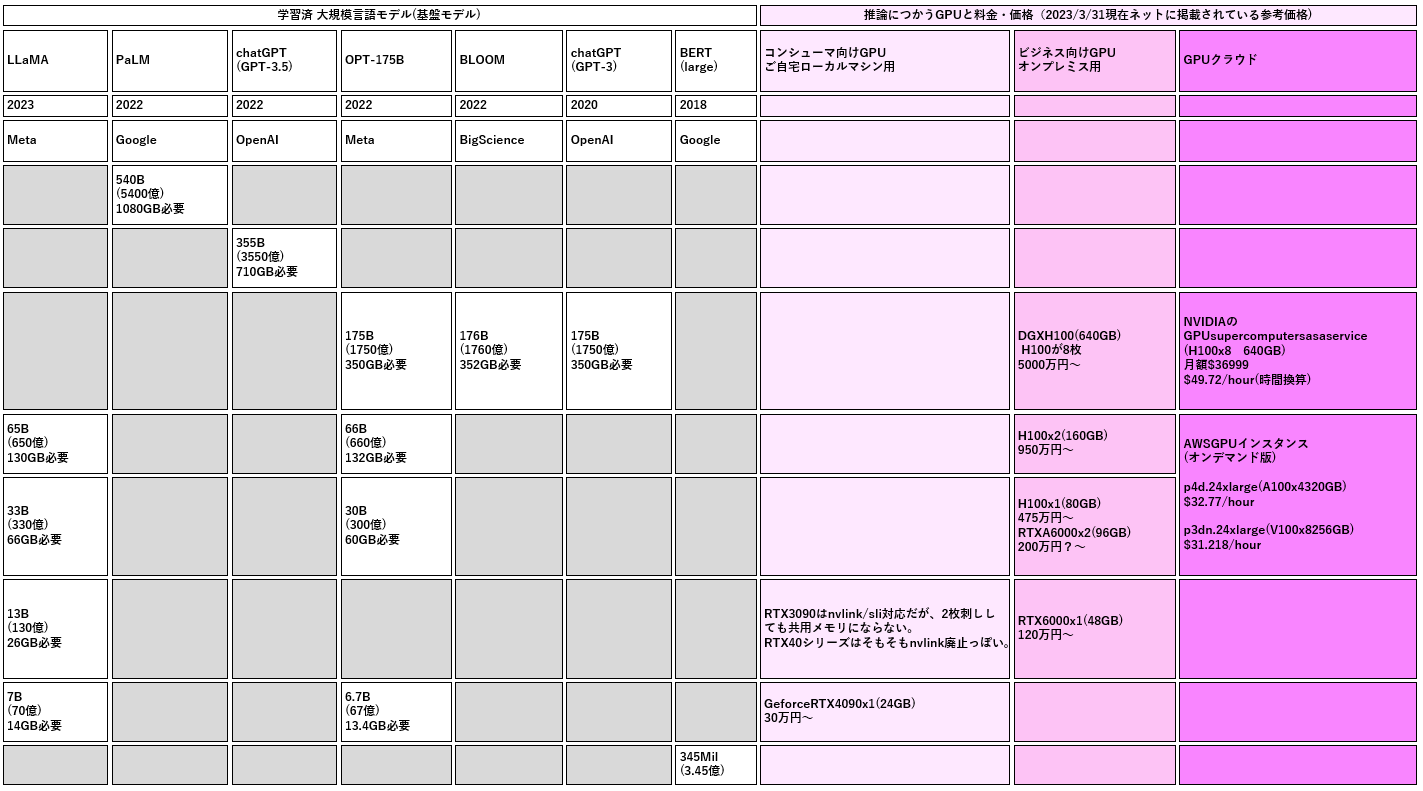
左半分:LLMのパラメータ数と、必要な GPU メモリ(fp16換算)
右半分:その基盤モデルの推論をするなら、どんなGPUなら実行可能で、それっていくら? の参考値
読み方:

手元で使う夢
ボーナスで買ったグラボ程度では相手にしてもらえんの
巨大なモデルをコンシューマ向けグラボやT4レベルでなんとか使う夢
-
量子化
- fp16(16bit) を 8bit にする
- fp16(16bit) を 4bit にする
-
FlexGen
- https://github.com/FMInference/FlexGen
- 巨大なモデルをメモリやSSDなどを活用してなんとか使う
調査元データ諸元
基盤モデル
-
GPT-4
- パラメータ数不明なので未記載。GPT-3.5の3540億は確実に超えているだろう。100兆というウワサもあったが。)
-
LLaMA
-
PaLM
- https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
- 5400億パラメータ (fp16 で 1080GB。H100 x 14枚くらい必要)
-
GPT-3.5
-
OPT
-
BLOOM
-
GPT3
-
BERT
GPU
GPUは2023年3月時点の最新アーキテクチャのフラッグシップを掲載
ご自宅向けGPU(オンプレ)
RTX 3090 は NvLink/SLI 対応で 2枚差し可能なので 48GB いけるんじゃないかと期待したが、共用メモリとして48GB にみせることはできない仕様なので記載せず。GeForce 系のゲーミングGPU と、ビジネス向け、データセンター向けのGPUをハッキリ区別する方針のようにみえます。4090 は NvLink によるSLI接続そのものに対応しなくなりました。
ビジネス向けGPU(オンプレ)
-
H100 (80GB)
-
RTX 6000 Ada
-
RTX A6000
- https://www.nvidia.com/ja-jp/design-visualization/rtx-a6000/
- https://prtimes.jp/main/html/rd/p/000000259.000057822.html
- RTX 6000 Ada が NVLink 非対応なので、2枚刺しするならこちら。
-
DGX H100
- https://www.nvidia.com/ja-jp/data-center/dgx-h100/
- https://www.nttpc.co.jp/cgi-bin/gpu/simulation/dgx/index.cgi
- H100 x 8 のモンスター。お値段もモンスター級。個人からみたら。
GPU クラウド
-
AWS p4d.24xlarge
- A100(80GB) x 4 = 320GB
- https://aws.amazon.com/jp/ec2/instance-types/p4/
-
AWS p3dn.24xlarge
-
NVIDIA supertcomputer-as-a-service
- H100(80GB) x 8 = 640GB
- https://nvidianews.nvidia.com/news/nvidia-launches-dgx-cloud-giving-every-enterprise-instant-access-to-ai-supercomputer-from-a-browser
- 月額 36,999 ドル とのことなので、これを 24hours x 31 days = 744 でわった値 $49.72 を時間換算コストとした
- 1か月使ったら日本円で 481万円。(130円/ドル換算)