本記事はTreasure Data Advent Calendar 16日目の記事です。
今年の11月にSoftware EngineerとしてTreasureDataに入社した成田です。
今回は、SQLで簡単にスケーラブルな機械学習ができるHivemallを1からAWSのAmazon Elastic MapReduce(EMR)上で動かし、実際に初めてkaggleの問題を解いてみたいと思います。
準備
まず準備として
・kaggleアカウントの作成
・AWS EMRのインスタンス作成
・EMR上でのHivemallの用意
を行いました。
1. kaggleの登録
kaggleのアカウントは以下から登録することができます。
https://www.kaggle.com/
基本的に英語ですが、googleアカウントなどで簡単に登録できます。
登録が終わると、このようにいくつかのコンペを見ることができます。
賞金付きコンペ、求人コンペ、リサーチ、練習問題などのジャンルに分かれているようです。
今回はTrip Type Classificationという、Walmartが出題する問題を選びました。
https://www.kaggle.com/c/walmart-recruiting-trip-type-classification
これはWalmartに来たお客さんがどのようなジャンル(日用品を買いに来た客やプレゼントを買いに来た客など)に属するかを、いくつかの要素から分類する問題になります。
2. EMR
次に、AWSのEMRを作成してみます。
https://aws.amazon.com/jp/elasticmapreduce/
以下に英語のチュートリアルがありますが、今は立ち上げ画面がもっとシンプルになっており、
そのままデフォルトの設定でも、今回の目的にあったインスタンスを作ることができます。
https://github.com/myui/hivemall/wiki/news20-binary-classification-on-Amazon-Elastic-MapReduce
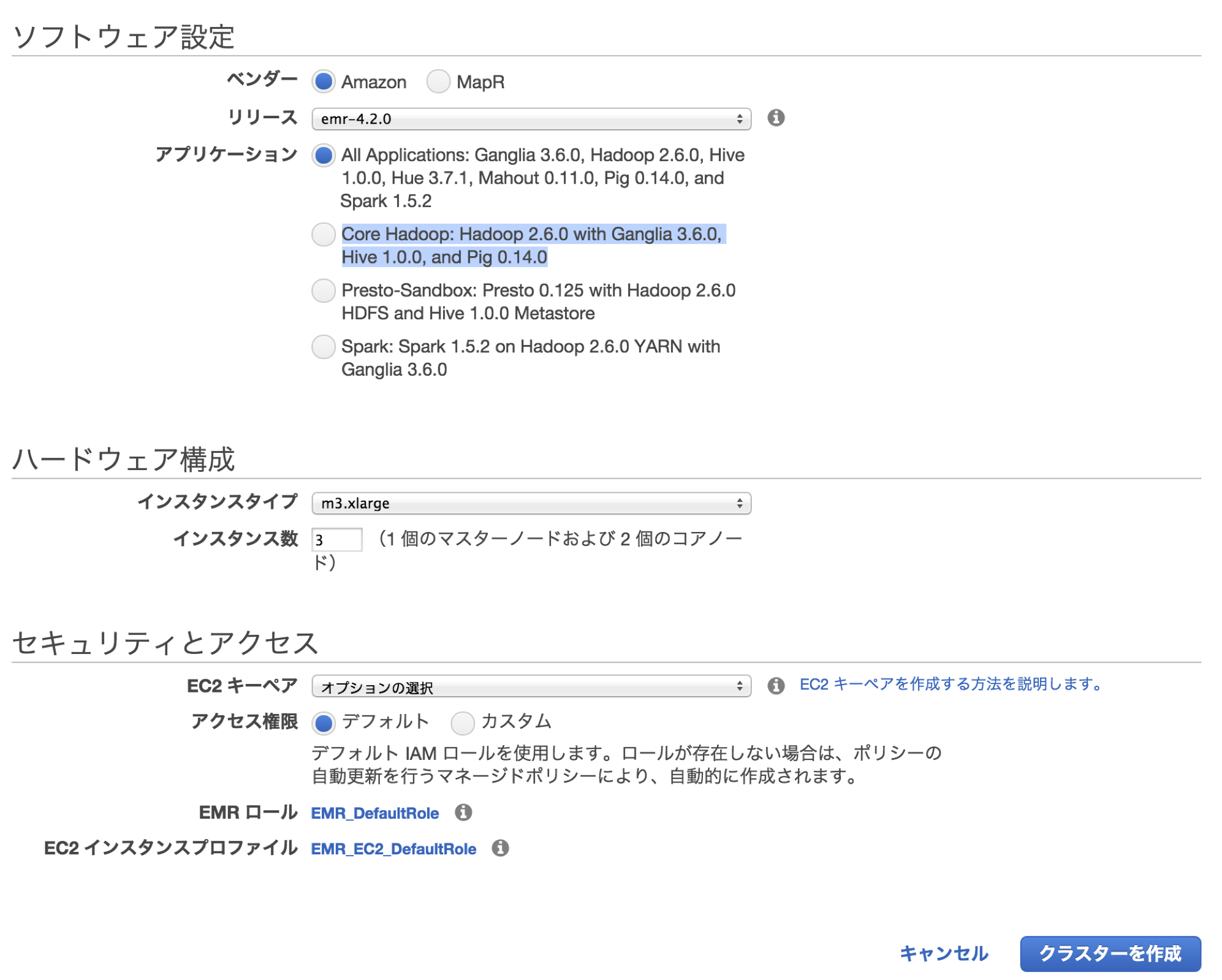
今回は汎用デフォルトであるm3.xlargeを使用しました。
また、アプリケーションはHiveのみで十分なので、
Core Hadoop: Hadoop 2.6.0 with Ganglia 3.6.0, Hive 1.0.0, and Pig 0.14.0
を選択しました。(デフォルトだと全部入りになっています)
今回は設定しませんが、s3にログファイル用のバケットを生成し、この設定で指定するとログがs3で保管でき便利です。
CLIクライアントなどでローカルからHiveなどの全ての操作ができるようですが、
今回はsshでログインして行ってみたいと思います。
EMRでは、EC2のec2-userやubuntuとは異なり、ユーザー名がhadoopになります。
$ ssh -i dev.pem hadoop@ec2-...amazonaws.com
# on EMR
[hadoop@ip- ~] $ hive
これでHiveが使えるようになりました。
3. Hivemall
そして、Hivemallの導入になります。
こちらから(https://github.com/myui/hivemall/releases )
・hivemall-with-dependencies.jar
・define-all.hive
の2つをダウンロードします。今回は最新版のv0.4.1を用いました。
そしてこの2つをEMRの/home/username/tmp/以下に配置します。
$HOME/.hivercを作成し、以下を追加します。
add jar /home/username/tmp/hivemall-with-dependencies.jar;
source /home/username/tmp/define-all.hive;
これでHivemallをEMRで使用することができます。
インストールの手間がなく、かなり簡単に使うことができます。
準備は以上になります。
問題を解くまえに
今回の問題では
TripType(客の種類)
VisitNumber(客のid)
Weekday(来客曜日)
Upc(買った商品のバーコード番号)
ScanCount(買った個数)
DepartmentDescription(商品のジャンル)
FinelineNumber(商品を更に細かく分けたときのジャンルNo.)
という7つのパラメータが与えられ、
Weekday、Upc、ScanCount、DepartmentDescription、FinelineNumber
からVisitNumber毎にTripTypeを予測することが求められます。
今回は初めに試しに解いてみるということで、
WeekdayとDepartmentDescriptionのみを使って解いてみることにします。
ここではtrain.csv、test.csv、sample_submit.csvという三種類のデータが与えられ、
train.csvで学習したモデルを用いてtest.csvで予測を行い、sample_submit.csvの形式で答えるという形になります。
まず与えられた教師データ、train.csvは以下の様な形式になっています。
"TripType","VisitNumber","Weekday","Upc","ScanCount","DepartmentDescription","FinelineNumber"
999,5,"Friday",68113152929,-1,"FINANCIAL SERVICES",1000
30,7,"Friday",60538815980,1,"SHOES",8931
30,7,"Friday",7410811099,1,"PERSONAL CARE",4504
26,8,"Friday",2238403510,2,"PAINT AND ACCESSORIES",3565
26,8,"Friday",2006613744,2,"PAINT AND ACCESSORIES",1017
26,8,"Friday",2006618783,2,"PAINT AND ACCESSORIES",1017
26,8,"Friday",2006613743,1,"PAINT AND ACCESSORIES",1017
26,8,"Friday",7004802737,1,"PAINT AND ACCESSORIES",2802
26,8,"Friday",2238495318,1,"PAINT AND ACCESSORIES",4501
26,8,"Friday",2238400200,-1,"PAINT AND ACCESSORIES",3565
26,8,"Friday",5200010239,1,"DSD GROCERY",4606
次に、テストデータであるtest.csvはこのようになっています。
"VisitNumber","Weekday","Upc","ScanCount","DepartmentDescription","FinelineNumber"
1,"Friday",72503389714,1,"SHOES",3002
1,"Friday",1707710732,1,"DAIRY",1526
1,"Friday",89470001026,1,"DAIRY",1431
1,"Friday",88491211470,1,"GROCERY DRY GOODS",3555
2,"Friday",2840015224,1,"DSD GROCERY",4408
2,"Friday",7874205264,1,"BAKERY",5019
2,"Friday",87458604271,1,"IMPULSE MERCHANDISE",8023
2,"Friday",87458604214,1,"IMPULSE MERCHANDISE",8023
3,"Friday",7410811099,1,"PERSONAL CARE",4504
3,"Friday",7410811099,-1,"PERSONAL CARE",4504
4,"Friday",7287926453,1,"FABRICS AND CRAFTS",5924
6,"Friday",7603138508,1,"BOYS WEAR",654
6,"Friday",7603138508,-1,"BOYS WEAR",654
そして、解答形式であるsample_submit.csvはこのようになっています。
"VisitNumber","TripType_3","TripType_4","TripType_5","TripType_6","TripType_7","TripType_8","TripType_9","TripType_12","TripType_14","TripType_15","TripType_18","TripType_19","TripType_20","TripType_21","TripType_22","TripType_23","TripType_24","TripType_25","TripType_26","TripType_27","TripType_28","TripType_29","TripType_30","TripType_31","TripType_32","TripType_33","TripType_34","TripType_35","TripType_36","TripType_37","TripType_38","TripType_39","TripType_40","TripType_41","TripType_42","TripType_43","TripType_44","TripType_999"
1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
3,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
6,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
13,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
14,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
16,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
この形式で、例えばVisitNumber1の答えがTripType_3であれば、TripType_3を1にする、というような形になります。
今回はいくつかの要素を用いて、分類する問題ということでRandomForestアルゴリズムを使用します。
理由としましては、RandomForestはアルゴリズムとして非常に理解しやすく、機械学習の一番はじめのとっかかりとして最適だと思われるからです。
RandomForestの説明は
http://yebisupress.dac.co.jp/2015/12/01/randomforest-mushroom/
http://shindannin.hatenadiary.com/entry/2014/12/26/184624
などがわかりやすいです。
問題を解く
1. 学習
まず、与えられたcsvファイルをHiveテーブルに入力したいと思います。
(ここでは記事を見やすくするため一つ一つ丁寧にテーブルを作っていますが、with句などを駆使して書くといいと思います。)
create database walmart;
use walmart;
drop table train;
create external table train (TripType string,VisitNumber string,Weekday string,Upc bigint,ScanCount int,DepartmentDescription string,FinelineNumber int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION '/dataset/walmart/train';
trainテーブルを作成し、hdfsの/dataset/walmart/trainのファイルを読み込むようにします。
次にこのディレクトリにcsvをputします。
$ sed '/^$/d' train.csv | hadoop fs -put - /dataset/walmart/train/train.csv
これでcsvを読むことができました。
trainテーブルはこのようになっています。
hive> select * from train limit 10;
OK
999 5 "Friday" 68113152929 -1 "FINANCIAL SERVICES" 1000
30 7 "Friday" 60538815980 1 "SHOES" 8931
30 7 "Friday" 7410811099 1 "PERSONAL CARE" 4504
26 8 "Friday" 2238403510 2 "PAINT AND ACCESSORIES" 3565
26 8 "Friday" 2006613744 2 "PAINT AND ACCESSORIES" 1017
26 8 "Friday" 2006618783 2 "PAINT AND ACCESSORIES" 1017
26 8 "Friday" 2006613743 1 "PAINT AND ACCESSORIES" 1017
26 8 "Friday" 7004802737 1 "PAINT AND ACCESSORIES" 2802
26 8 "Friday" 2238495318 1 "PAINT AND ACCESSORIES" 4501
26 8 "Friday" 2238400200 -1 "PAINT AND ACCESSORIES" 3565
つぎに、それぞれの要素を定量化します。
例えば、曜日であれば月曜日を0, 火曜日を1、・・・、日曜日を6という具合に処理しやすい形に変換します。
(実際にはorder byで指定したもの順に定量化されます)
これにはquantifyというUDTFを以下の様な形で使います。
set hivevar:output_row=true;
drop table train_quantified;
create table train_quantified
as select quantify(${output_row}, TripType, VisitNumber, Weekday, DepartmentDescription )
as ( TripType, VisitNumber, Weekday, DepartmentDescription )
from (select * from train order by cast (TripType as int) asc) t;
これにより、trainテーブルがデータ処理しやすい形に変換することができました。
hive> select * from train_quantified limit 10;
OK
0 0 0 0
0 1 1 0
0 2 0 0
0 3 2 0
0 3 2 0
0 2 0 0
0 4 3 0
0 4 3 0
0 5 2 0
0 6 0 0
そして、曜日と商品ジャンルを要素として使いますが、これをRandomForestで使うために、それぞれの要素をn次元のarrayにする必要があります。
今回は商品ジャンルが68種類、これに曜日を加えて69次元のarrayを作成することになります。
そこでまずそれぞれの値をindex:値の形のfeature(Pairのようなもの)に変換します。
ここではわかりやすくするためにジャンルと曜日をわけて作成したあと、union allにより混合させます。
drop table train_depart;
create table train_depart as select VisitNumber,feature(DepartmentDescription, count(1)) as Depart, TripType
from train_quantified group by VisitNumber, DepartmentDescription, Weekday, TripType;
drop table train_week;
create table train_week as select VisitNumber, feature(69, Weekday) as Week, TripType
from train_quantified group by VisitNumber, DepartmentDescription, Weekday, TripType;
drop table train_union;
create table train_union as select VisitNumber, Depart as Feature, TripType from train_depart
union all
select VisitNumber, Week as Feature, TripType from train_week;
ここで、train_unionは以下の様な形になります。
hive> select * from train_union limit 10;
OK
0 69:0 0
1 69:1 0
1 69:1 0
2 69:0 0
3 69:2 0
4 69:3 0
5 69:2 0
6 69:0 0
7 69:4 0
8 69:2 0
これは例えばarrayの69番目である曜日がid 0の人は0(月曜日)、id 1の人は1(火曜日)といった具合になっています。
そしてこのfeatureをcollect_listで一旦arrayにしたあと、featureのkeyをindex、valueをそのindexの値にするto_dense UDTFを使います。
drop table train_rf;
create table train_rf as select rand(31) as rnd, VisitNumber, to_dense(collect_list(Feature), 69) as features, TripType from train_union group by VisitNumber,TripType;
これにより特徴量を69次元のarrayに変換することができました。
hive> select * from train_rf limit 10;
OK
0.7314156962376819 0 [2.0,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,0.0] 0
0.39281443656790715 1 [1.0,1.0,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,1.0] 0
0.7859303306509032 2 [2.0,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,null,0.0] 0
ちなみにrandの値はHiveでサンプリングをしやすくするための値になります。
そして特徴量を作れた所で、いよいよRandomForestを適用します。
これは以下のようにtrain_rf、featuresを指定してtrain_randomforest_classifierを呼ぶだけです。
drop table model_rf;
create table model_rf as select train_randomforest_classifier(features, TripType, "-trees 30")
as (model, importance, errors, tests) from train_rf;
これでRandomForestによる学習モデルを構築することができました。
ちなみに学習モデルの中身は以下のようになっており、
hive> desc model_rf;
OK
model string
importance array<double>
errors int
tests int
modelはRandomForestそのもの(treeモデルをif文で表現したプログラム)
impotanceは説明変数の重要度
errorsはOOBエラー数
testsはOOBレコード数
になります。
2. 予測
trainの時と同様にして、test用ファイルをテーブルに読み込みます。
drop table test_raw;
create external table test_raw (VisitNumber string,Weekday string,Upc bigint,ScanCount int,DepartmentDescription string,FinelineNumber int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE LOCATION '/dataset/walmart/test_raw';
$ sed '/^$/d' test.csv | hadoop fs -put - /dataset/walmart/test/test.csv
また、同様にquantifyを行い、データを整理します。
drop table test_quantified;
create table test_quantified
as select quantify(true, VisitNumber, Weekday, DepartmentDescription )
as ( VisitNumber, Weekday, DepartmentDescription )
from (select * from test_raw order by cast (VisitNumber as int) asc) t;
drop table test_depart;
create table test_depart as select VisitNumber,feature(DepartmentDescription, count(1)) as Depart
from test_quantified group by VisitNumber, DepartmentDescription, Weekday;
drop table test_week;
create table test_week as select VisitNumber, feature(69, Weekday) as Week
from test_quantified group by VisitNumber, DepartmentDescription, Weekday;
drop table test_union;
create table test_union as select VisitNumber, Depart as Feature from test_depart
union all
select VisitNumber, Week as Feature from test_week;
drop table test_rf;
create table test_rf as select VisitNumber, to_dense(collect_list(Feature), 69) as features from test_union group by VisitNumber;
そして、予測になります。学習で作ったmodel_rfを用いて整理したデータに対してtree_predictを呼びます。
SET hivevar:classification=true;
set hive.auto.convert.join=true;
SET hive.mapjoin.optimized.hashtable=false;
SET mapred.reduce.tasks=16;
drop table predicted_rf;
create table predicted_rf as SELECT VisitNumber, predicted.label, predicted.probability, predicted.probabilities
FROM ( SELECT VisitNumber, rf_ensemble(predicted) as predicted FROM (
SELECT t.VisitNumber, tree_predict(p.model, t.features, ${classification}) as predicted
FROM ( SELECT model FROM model_rf DISTRIBUTE BY rand(1) ) p LEFT OUTER JOIN test_rf t ) t1 group by VisitNumber ) t2;
これを見てみると、それぞれのvisitnumberに対してそのlabel(ここではTripType)が予測されるかをがわかります。
hive> select visitnumber, label from predicted_rf limit 10; OK
0 0
16 14
32 9
48 5
64 26
80 0
96 6
112 17
128 18
144 6
これで予測は完成です。
trainでデータを前処理してしまえば、あとは予測まで一本道です。
3. 提出
最後に提出用に出力を行います。
以下のように、区切り文字、改行文字を指定しTEXTFILE形式で出力します。
drop table predicted_rf_submit;
create table predicted_rf_submit
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ","
LINES TERMINATED BY "\n"
STORED AS TEXTFILE
as
SELECT label as TripType
FROM predicted_rf
ORDER BY VisitNumber ASC;
$hadoop fs -getmerge /user/hive/warehouse/walmart.db/predicted_rf_submit predicted_rf_submit.csv
そして最後にsample_submission.csvの形式に合わせるために簡単にpythonで後処理をします。
# coding: UTF-8
f = open('predicted_rf_submit.csv', 'r')
lines = f.readlines()
f.close()
f = open('sample_submission.csv', 'r')
fw = open('submission.csv', 'w')
first = f.readline()
fw.write(first)
for line in lines:
i = f.readline().split(",")[0]
v = line.split(",")[1]
arr = [0]*38
arr[int(v)] = 1
arr = map(str, arr)
l = str(i) + "," + ",".join(arr) + "\n"
fw.write(l)
print
f.close()
fw.close()
以上でsubmitファイルが完成となります。
このような形でしっかりとデータが入っています。
"VisitNumber","TripType_3","TripType_4","TripType_5","TripType_6","TripType_7","TripType_8","TripType_9","TripType_12","TripType_14","TripType_15","TripType_18","TripType_19","TripType_20","TripType_21","TripType_22","TripType_23","TripType_24","TripType_25","TripType_26","TripType_27","TripType_28","TripType_29","TripType_30","TripType_31","TripType_32","TripType_33","TripType_34","TripType_35","TripType_36","TripType_37","TripType_38","TripType_39","TripType_40","TripType_41","TripType_42","TripType_43","TripType_44","TripType_999"
1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
2,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
3,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1
6,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1
13,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
ここまで完全にデータの処理だけになっており、機械学習部分はほとんど意識することなくRandom Forestを使うことができました。
結果に関しては今回は全ての特徴量を使用しなかったため、あまり良くありませんでしたが、
まずこの導入からkaggle提出までを一回通しでやって、これから精度向上のために色々と工夫する必要があります。
たとえば、バーコードやより細かいジャンルを使ったり、今回は返品(ScanCountが-1であれば返品)が与えられており、この返品はかなり重要なデータであると考えられるため、色々と改良の余地があると思われます。
まとめ
かなりお手軽に導入することができ、機械学習のアルゴリズムに精通していなくとも一連の流れを体験することができました。
機械学習のまずはじめの第一歩としてHivemallはかなり良い選択であると思われます。
やはりデータの前処理部分をSQLで行うのが少し壁になっている部分があるかと思いますが、新しいUDFなども続々と加わり、障壁が少なくなってきていると思います。逆に普段からSQLに慣れている方はかなり簡単に扱えると思われます。
個人的に、pythonでデータ処理を行っている方が多いかと思いますし私もそうですが、python UDF機能も強い要望があればもしかすると加わるかもしれません。
またkaggleではデータが最初から用意されているのですが、ここ以外の場面ではまずデータを集めることが必要となり、
そういったデータの収集から分析までをいっぺんに面倒を見れるのがTreasure Dataの魅力の一つかと思います。