特徴量エンジニアリングはすごく大事なのでここにまとめておきます
説明が短いけど多分日本語の特徴量エンジニアリングの記事で一番種類がたくさん載ってます
Label encoding
全てのカテゴリに数値によるIDを割り当てる
Count encoding
カテゴリの出現回数を特徴量とする
LabelCount encoding
カテゴリの出現回数の順位を特徴量とする
One-hot encoding
カテゴリごとにBooleanで表現
X-meansで新しいクラスタを作り分類に落とす
X-meansはk-meansの拡張で、k-meansを繰り返して最適なクラスタを見つけてくれる
target encoding
カテゴリカルな変数をサンプルのratioでエンコーディングするらしい。要勉強。

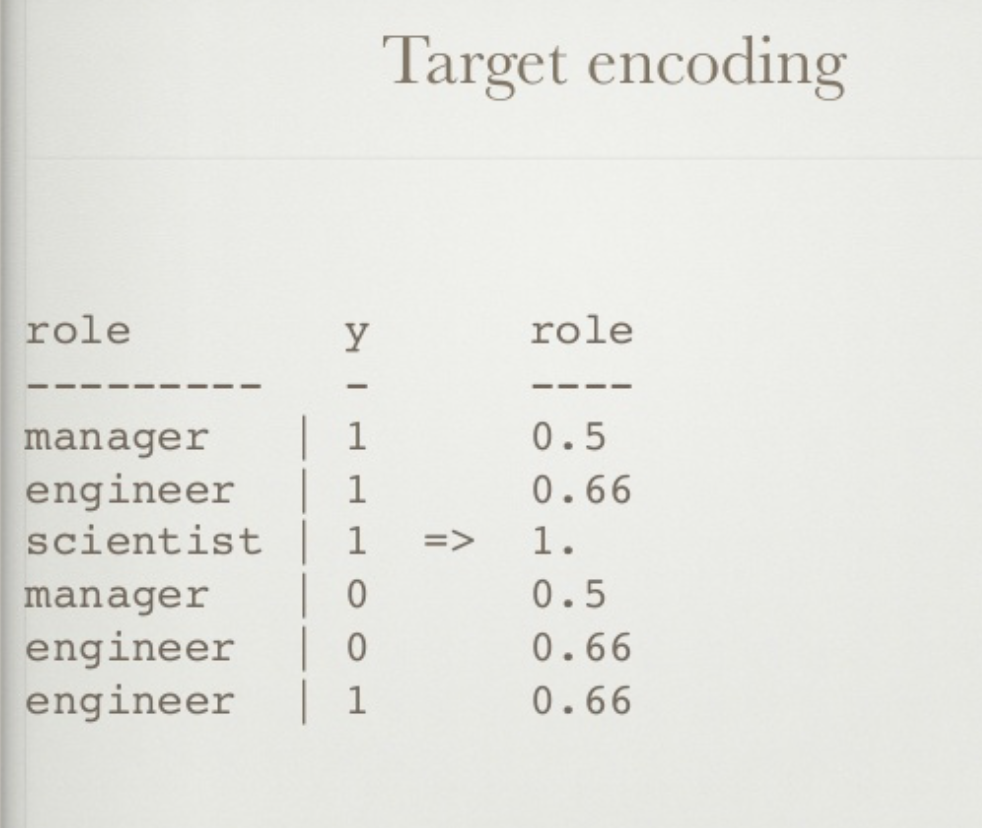
出典: https://www.slideshare.net/HJvanVeen/feature-engineering-72376750
NaN encoding
いつもは適当に補完するNaN値も、NaNという一つのbooleanの特徴量として扱う
Polynominal encoding
カテゴリ変数同士の関係を元に作るらしい。XORですね

expansion encoding
一つの特徴量からカテゴリカル変数を作る手法。
例えば、ユーザーの使用しているバージョンを示す特徴量があったとしたら、
「ユーザーは最新のバージョンを使っているか?」→1(使用している) 0(使用していない)
とかそんな感じです。
Consolidation encoding
これは実際にありがちな問題で、何気なく使っている手法。例えば、会社の名前っていう変数があるとする。「shell」「Shell」「SHELL」「shEll」これらは一つの「Shell」という変数として扱わなきゃいけないから、適当にpythonで辞書でも作ってmapかreplaceする必要がある。これは特徴量エンジニアリングより、データクリーニングって感じですね。
Rounding
連続値の場合は、ある程度のところで四捨五入するのも良いみたいです。あまりに細かい小数点◯位とかの数値はただのノイズだったりして、ちょうどいいところで数値を四捨五入することで、最も顕著なデータを得られるらしいです。Log変換する前にRoundingを入れるといいらしいですよ、
binning
連続値の場合に、ある特定のレンジを決めて、レンジごとにカテゴリを分ける手法です
例えば、年齢という特徴量なら、「20歳以下」→分類0 「21歳から40歳」→分類1, 「40歳から60歳」→分類2...などこんな感じです。
scaling
numericalな特徴量をある特定の範囲にスケーリングする手法です。Standard(Z) Scaling, MinMax Scaling, Root Scaling, Log scalingなどがあります
imputation
これは欠損値補完のことです。平均やメジアンで補完するのが一般的ですよね、時系列なら線形補間かspline補完が一般的です。欠損を無視するのは他の問題を引き起こす可能性があるのでやめましょう
Interaction
特徴量同士の関係を新しい特徴量にする手法です。例えば特徴量同士をかけたり、足したり、引いたり、割ったりするのがそれです。
例えば、1年前のある特徴量と現在の同じ特徴量があります。この2つを引き算すれば、「1年での変化量」の特徴量になりますし、割れば「1年での伸び率」の特徴量になります。
Trendlines
例えば、「売上総額」を特徴量にするのではなくて「先週の売上」「先月の売上」「過去10年の売上」など「傾向」をモデルに与えてあげましょうねっていうやつです
Box-Cox transformation
ロングテイルなデータを持っている場合はログ変換してあげると良い感じになりますよってやつです
sigmoid / tanh / log transformations
Deeplearningのときだけじゃなくて他のモデル特徴量エンジニアリングでも使うんですね!
model stacking
複数の予測モデルのアンサンブルを行う。(ライブラリあり) これは特徴量エンジニアリングなのか??
Random Feature Elimination
RFEで特徴量の数を減らすとき、AUCで評価してあげると良いです
参考: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6101392/
Downsampling/ Upsampling
不均衡データの場合、データが多い方に合わせてカサ増しするか、少ない方に合わせて切り捨てるか、という手法です。
出典
【Kaggle】特徴量エンジニアリングとパラメータチューニングで、titanic 上位10%に入りました。https://qiita.com/jami291/items/2c1a230698ee19be7dee
特徴量エンジニアリングの手法としてのクラスタリング(とX-meansによる最適なクラスタ数の導入) https://qiita.com/sakabe/items/470b7c72c535de477f7c
Feature-Engineeringのリンク集めてみた https://qiita.com/squash/items/667f8cda16c76448b0f4
Feature Engineering
https://www.slideshare.net/HJvanVeen/feature-engineering-72376750