TensorFlow v1.0での目玉の1つにHigh Level APIがあります。v1.0の発表から何故かギョームが忙しくなり、しっかり追いかけきれていませんでしたが、現時点で日本語のまとめ記事っぽいのがなかったので雑感付きでサンプルコードを添えて書いてみようと思います。雑感は、まあ個人の意見ということで、Kerasはちょっと、という方が結構いるのも事実かと思います。
サンプルコードは以前書いた記事同様にirisデータに対して適当なDNNを作ってみたらどうなるか、という感じにしています。厳密にそれぞれの条件を揃えているわけではないのでその辺りはご容赦を。
TensorFlowの基本
まずは改めてTensorFlowの基本的な記述方法です。細かく言い出すとキリがないので、ざっくり言うと以下のような感じでしょうか。
- 入力用にplaceholderを用意
- 重みやバイアス用にVariableを用意
- 活性化関数を使って層を定義
- ロス値を定義
- 最適化の方法を定義
- セッションを定義して学習を実行
生TF辛い問題
TensorFlow自体は比較的低レベルなAPIを提供しているために、特にアルゴリズムの実装に集中したい人にとっては、学習コストが高い状態でした。
んー、何か覚えることが多そうだぞ、ということで、いわゆるデータサイエンティストの人にとっては敷居が高いものとなっていました。
import tensorflow as tf
import numpy as np
from sklearn import cross_validation
# データの準備
iris = tf.contrib.learn.datasets.base.load_iris()
train_x, test_x, train_y, test_y = cross_validation.train_test_split(
iris.data, iris.target, test_size=0.2
)
# 指定されたバッチサイズでデータをランダムに取得
def next_batch(data, label, batch_size):
perm = np.arange(data.shape[0])
np.random.shuffle(perm)
return data[perm][:batch_size], label[perm][:batch_size]
# 入力層
x = tf.placeholder(tf.float32, [None, 4], name='input')
# 第1層
W1 = tf.Variable(tf.truncated_normal([4, 10], stddev=0.5, name='weight1'))
b1 = tf.Variable(tf.constant(0.0, shape=[10], name='bias1'))
h1 = tf.nn.relu(tf.matmul(x,W1) + b1)
# 第2層
W2 = tf.Variable(tf.truncated_normal([10, 20], stddev=0.5, name='weight2'))
b2 = tf.Variable(tf.constant(0.0, shape=[20], name='bias2'))
h2 = tf.nn.relu(tf.matmul(h1,W2) + b2)
# 第3層
W3 = tf.Variable(tf.truncated_normal([20, 10], stddev=0.5, name='weight3'))
b3 = tf.Variable(tf.constant(0.0, shape=[10], name='bias3'))
h3 = tf.nn.relu(tf.matmul(h2,W3) + b3)
# 出力層
W4 = tf.Variable(tf.truncated_normal([10, 3], stddev=0.5, name='weight4'))
b4 = tf.Variable(tf.constant(0.0, shape=[3], name='bias4'))
y = tf.nn.softmax(tf.matmul(h3,W4) + b4)
# 理想的な出力値
labels = tf.placeholder(tf.int64, [None], name='teacher_signal')
y_ = tf.one_hot(labels, depth=3, dtype=tf.float32)
# 理想的な出力値との比較
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# 最適化方法の指定
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# 学習処理
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(2000):
# 学習処理
batch_size = 100
batch_train_x, batch_train_y = next_batch(train_x, train_y, batch_size)
sess.run(train_step, feed_dict={x: batch_train_x, labels: batch_train_y})
# 学習結果の評価
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: test_x, labels: test_y}))
TensorFlowの高レベルAPIの歴史
TensorFlowをもっと使いやすく、ということで、当然高レベルAPI的なアプローチはいろいろありました。この辺りはけっこう混沌としていて、逆にTensorFlowは今使い始めるとヤバそうだな、という雰囲気を醸し出す一因でもありました。
これまでの生TF辛い問題の解決法
私が知っているだけでもいろいろありましたが、大きなものでは以下のようなものがありました。
- tf.contrib.learn
- Keras
- その他いろいろ
- TFLearn
- slim
tf.contrib.learn
もともとはSkFlowという、Scikie-learnライクにTensorFlowを使えるように、というコンセプトのライブラリがありました。これがv0.8でTensorFlow本体に取り込まれ、tf.contrib.learnとなりました。恐らく、v1.0からの高レベルAPIの基礎的な考え方になっているものだと思います。
先程の生TFと比較するとびっくりするくらい簡単にDNNを実行することができます。
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.ERROR)
# カラムの情報を設定
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# 3層のDNN
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="./iris_model")
# モデルのフィッティング
classifier.fit(x=train_x,
y=train_y,
steps=2000,
batch_size=50)
# 精度評価
print(classifier.evaluate(x=test_x, y=test_y)["accuracy"])
非常に簡単な一方で、自由度が低すぎるという意見もあり、そこまで流行っていないというのが正直なところでしょう。
Keras
KerasはTensorFlowとTheanoのラッパーライブラリです。
モデルの記述のし安さに特徴があり、データサイエンティストと呼ばれている方たちからは人気がある印象です。
import keras
from keras.models import Sequential
from keras.layers.core import Dense, Activation
num_classes = 3
train_y = keras.utils.to_categorical(train_y, num_classes)
test_y = keras.utils.to_categorical(test_y, num_classes)
# モデルの定義
model = Sequential()
# ネットワークの定義
model.add(Dense(10, activation='relu', input_shape=(4,)))
model.add(Dense(20, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(3, activation='softmax'))
# モデルのサマリの確認
model.summary()
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
# 学習
history = model.fit(train_x, train_y,
batch_size=100,
epochs=2000,
verbose=1,
validation_data=(test_x, test_y))
# 学習モデルの評価
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
ネットワークの記述部分に注目してください。かなり直感的に記述できていると思います。また、Kerasっぽい書き方を覚えれば良い、と割り切れるのも好評な理由かと思います。
その他いろいろ
TFLearnやslimなどいろいろありまして、正直私も追いきれていません。かなり混沌としている印象です。TFLearnはまわりではかなり評判は良かったのですが私は触っていません。また、TensorFlowのexampleでslimが使われていたりしましたので、TensorFlow開発チームの中でも混沌としている感じだったのでしょうか。
v1.0で整理されたこと
と、ここまで見てきたようにけっこうごちゃごちゃしていて、どうなることやら、でしたが、v1.0ではしっかり整理されていくようです。
Youtubeで公開されているTensroFlow Dev SummitのHigh Level APIより
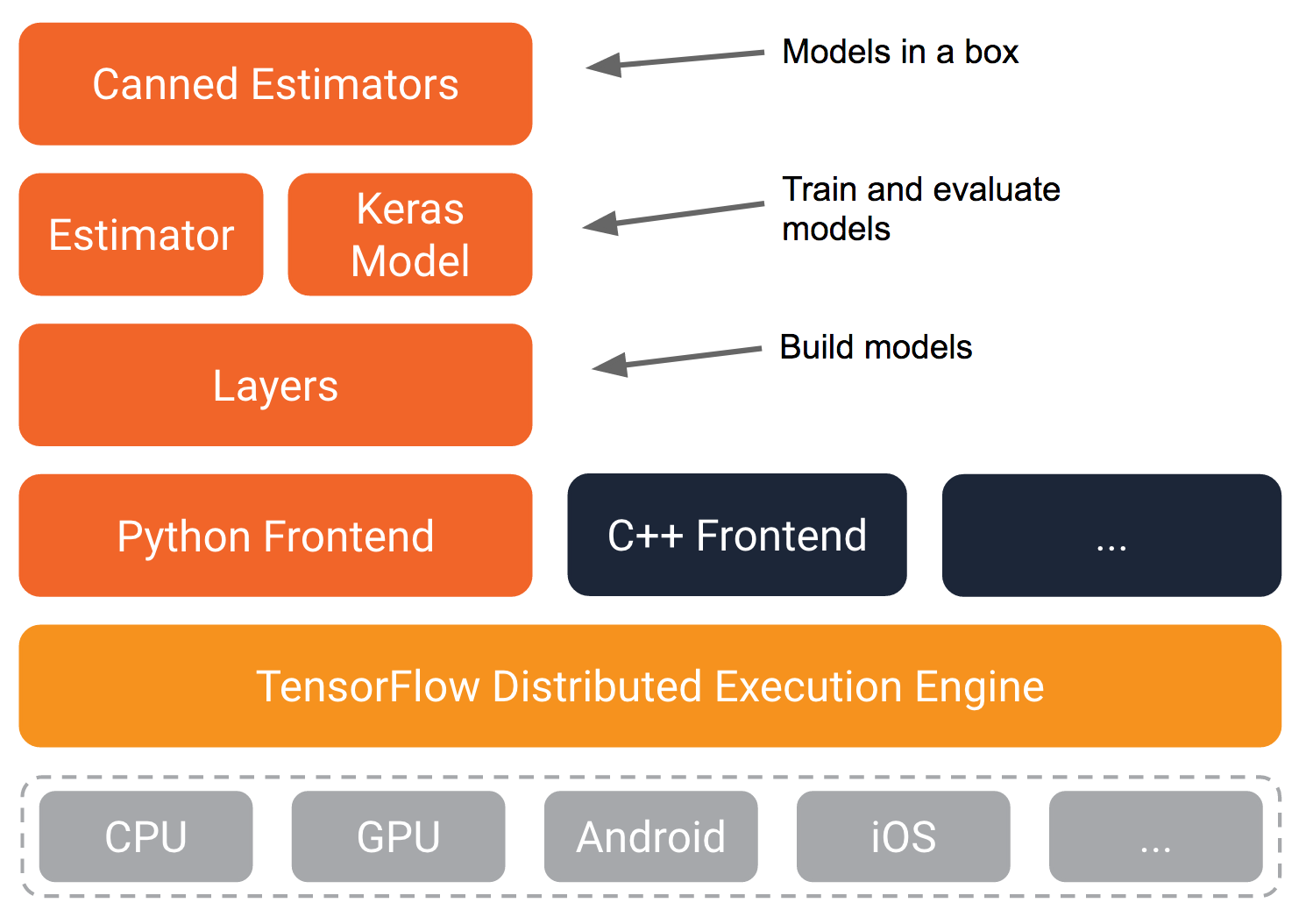
図を見ても分かりにくい部分があるのでもう少し詳しく見ていきましょう
Layers
Layersはモデルを記述するためのAPI群です。
Youtubeでは例としてCNNのネットワークの記述が挙げられています。
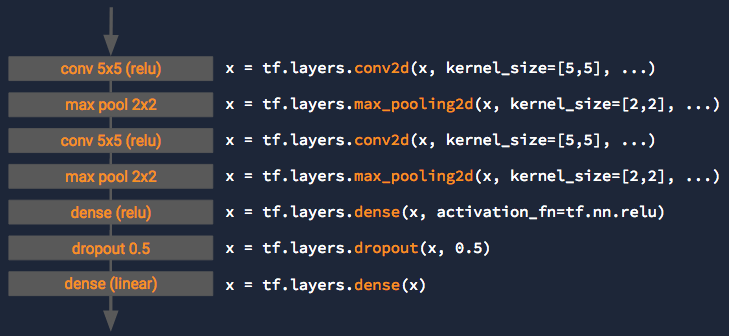
Variableの概念はうまく隠蔽されていますので、直感的にモデルを記述できそうです。
※以下ご指摘頂いたとおり修正:当初Placeholderも隠蔽していると記述していましたが、LayersではPlacehodlerまでは隠蔽されていません。Layers自体はEstimatorを使わずとも利用可能であり、その場合はコメントでご指摘いただいた通りPlaceholder経由で入力をfeedすることになります。ちなみに、この場合は、生TFの中のモデルの記述部分のみが変わるイメージです。
import tensorflow as tf
import numpy as np
from sklearn import cross_validation
# データの準備
iris = tf.contrib.learn.datasets.base.load_iris()
train_x, test_x, train_y, test_y = cross_validation.train_test_split(
iris.data, iris.target, test_size=0.2
)
# 指定されたバッチサイズでデータをランダムに取得
def next_batch(data, label, batch_size):
perm = np.arange(data.shape[0])
np.random.shuffle(perm)
return data[perm][:batch_size], label[perm][:batch_size]
# 入力層
x = tf.placeholder(tf.float32, [None, 4], name='input')
# 隠れ層1
hidden1 = tf.layers.dense(inputs=x, units=10, activation=tf.nn.relu)
# 隠れ層2
hidden2 = tf.layers.dense(inputs=hidden1,units=20, activation=tf.nn.relu)
# 隠れ層3
hidden3 = tf.layers.dense(inputs=hidden2, units=10, activation=tf.nn.relu)
# 出力
y = tf.layers.dense(inputs=hidden3, units=3, activation=tf.nn.softmax)
# 理想的な出力値
labels = tf.placeholder(tf.int64, [None], name='teacher_signal')
y_ = tf.one_hot(labels, depth=3, dtype=tf.float32)
# 理想的な出力値との比較
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# 学習処理と呼ばれているもの
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(2000):
# 学習処理
batch_size = 100
batch_train_x, batch_train_y = next_batch(train_x, train_y, batch_size)
sess.run(train_step, feed_dict={x: batch_train_x, labels: batch_train_y})
# 学習結果の評価
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: test_x, labels: test_y}))
Estimator
Estimatorは記述したモデルを使って、学習や評価、推論などのタスクを行うための標準的なインターフェースを提供するAPI群です。
モデルを使うタスクについての具体的なイメージとしてはYoutubeにある以下のようなイメージです。
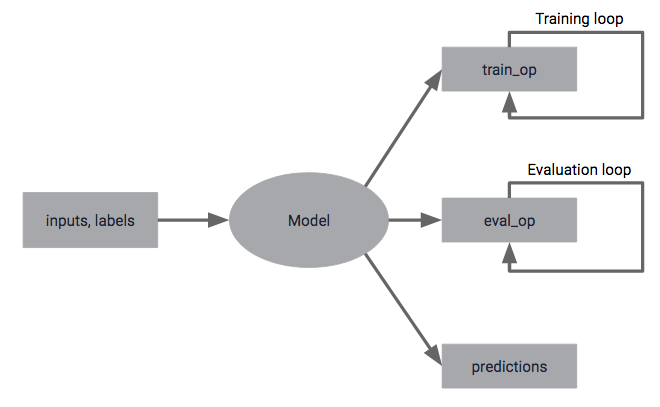
最初の生TFの例で見ていただくと分かる通り、TensorFlowの流儀では、構築したモデルを使った学習、評価、推論などを定義して実行する必要があります。学習のループ部分(epoch)なども自前で定義していきます。ここをうまく抽象的に定義できるといいよね、というアプローチです。
上述した種々のタスクはEstimator内に押し込んで、標準的なインターフェースとして学習にはfit()、評価にはevaluate()、推論にはpredict()を提供しようという設計となります。
具体的なイメージとしてはYoutubeにある以下のようなイメージです。
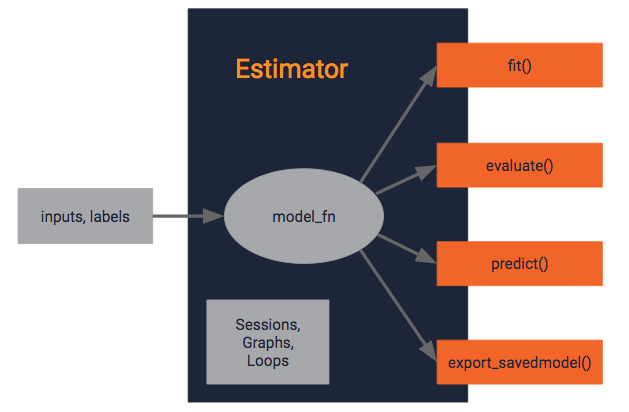
という感じです。
Canned Estimator
さて、Estimatorによって標準的なインターフェースが提供されたので、後は、様々なモデルを実装してEstimatorとして提供していけますね、ということです。今後は様々なアルゴリズムがTensorFlow上で実装され、提供されていくようです。
あれ、Estimatorといい、fit()、predict()、、、これはScikit-learnではないですか、と思ったあなた、多分正解です。この流れ自体がScikit-learを意識したSkFlowから来ていますし、機械学習のライブラリということで成功しているSckit-learnをけっこう見習っているのではないかと勝手に推測しています。
サンプルコード
ということで、まだ色々調べていますが、とりあえず動くレベルにしたv1.0版の高レベルAPIのサンプルコードも載せておきます。
このへんとかこのへんとかをいろいろ見つつなので、本当に理想的なコードなのかは分かりませんが、、、
import tensorflow as tf
from sklearn import cross_validation
from tensorflow.contrib.learn.python.learn.estimators import model_fn as model_fn_lib
# データの準備
iris = tf.contrib.learn.datasets.base.load_iris()
train_x, test_x, train_y, test_y = cross_validation.train_test_split(
iris.data, iris.target, test_size=0.2
)
# モデルの定義
def iris_dnn_model_fn(features, labels, mode):
# 入力層
input_layer = tf.reshape(features, [-1, 4])
# 隠れ層の第1層
hidden1 = tf.layers.dense(
inputs=input_layer,
units=10,
activation=tf.nn.relu
)
# 隠れ層の第2層
hidden2 = tf.layers.dense(
inputs=hidden1,
units=20,
activation=tf.nn.relu)
# 隠れ層の第3層
hidden3 = tf.layers.dense(
inputs=hidden2,
units=10,
activation=tf.nn.relu)
# 出力層
logits = tf.layers.dense(
inputs=hidden3,
units=3)
loss = None
train_op = None
# ロス値の計算
if mode != tf.contrib.learn.ModeKeys.INFER:
onehot_labels = tf.one_hot(indices=tf.cast(labels, tf.int32), depth=3)
loss = tf.losses.softmax_cross_entropy(
onehot_labels=onehot_labels, logits=logits)
# 学習周りの設定
if mode == tf.contrib.learn.ModeKeys.TRAIN:
train_op = tf.contrib.layers.optimize_loss(
loss=loss,
global_step=tf.contrib.framework.get_global_step(),
learning_rate=0.001,
optimizer="SGD"
)
# Predictionsの設定
predictions = {
"classes": tf.argmax(
input=logits, axis=1),
"probabilities": tf.nn.softmax(
logits, name="softmax_tensor")
}
# return
return model_fn_lib.ModelFnOps(
mode=mode, predictions=predictions, loss=loss, train_op=train_op)
def main(unused_argv):
# Estimatorの生成
iris_classifier = tf.contrib.learn.Estimator(
model_fn=iris_dnn_model_fn, model_dir="./iris_dnn_model")
# ログの設定
tensors_to_log = {"probabilities": "softmax_tensor"}
logging_hook = tf.train.LoggingTensorHook(
tensors=tensors_to_log, every_n_iter=50)
# fit()を使って学習
iris_classifier.fit(
x=train_x,
y=train_y,
batch_size=100,
steps=2000,
monitors=[logging_hook]
)
metrics = {
"accuracy":
tf.contrib.learn.MetricSpec(
metric_fn=tf.metrics.accuracy, prediction_key="classes",
)
}
# evaluate()を使って評価
eval_results = iris_classifier.evaluate(
x=test_x, y=test_y, metrics=metrics
)
print(eval_results)
if __name__ == "__main__":
tf.app.run()
感じとしては、モデル関数をLayersで用意してあげて、その関数には学習、評価、推論それぞれの場合の処理も書いてあげる。その関数をEstimatorのオブジェクトを作る時に与えてあげると、あとは提供されているAPI経由で利用者側は簡単に処理を書けるという感じみたいです。
細かい部分でインターフェースが統一されるのと、割と実装にブレが出そうな細かい処理の部分はTF側が受け持ってくれるようで、個人的にはけっこう好感触です。
Kerasの正式サポート
で、もう一つのv1.0での目玉だったのがTensorFlowがKerasを正式にサポートし、TensorFlowとKerasが統合されるというものです。Youtubeによると以下のようです。

Layers、つまりモデルの記述部分にKerasと互換性を持たせることで、KerasでもEstimatorでも互換性があるような状態になるようです。また、tf.kerasというものが導入され、TF内でKerasのコードが動くとか。まだその辺りはよくイメージできていないですが、今後に注目でしょう。
ロードマップ
ここまでの話はv1.0で全てTensorFlowのコア部分に取り込まれているわけではなく、まだLayersのみとなります。その他の機能に関しては、ロードマップが提示されています。Youtubeによると以下の通りとなります。

まとめ
という話を【臨時開催】Recap of TensorFlow DEV SUMMIT 2017でしようと思っていて、それなりに有益そう、かつ参加希望に全て応えられない状態だったため、素振りも兼ねて書いてみました。個人的には今回高レベルAPIが整理されたことによって、実験的に作られたモデルをどう本番環境向けに実装していくか、について1つの指針が出てきたのは非常に良いのではないかな、と思いました。あと、Kerasと統合してくれると、データサイエンティストとの分業が捗る気がします。