はじめに
こんにちは。
普段業務でシステムの開発・運用をしていて、「なんかやりにくいな。」、「もっと良い方法ないかな。」と思ったことはありませんか?
自分はめっちゃあります。
日々モヤモヤしながら(どうにかならんかなぁ・・・)と思っていたところ、昨今流行りのDevOpsという考え方に出会い「これだ・・・!」となったので、ざっくりまとめて共有したいと思い、記事を書くことにしました。
自分の予想以上に長くなってしまいましたが、お付き合いいただけると幸いです。
また、全体を俯瞰できるよう注意して記事を書いているものの、ツールや概念など網羅的に書くことは難しいので、「何でアレがないの!?」などの感想はコメントいただけると嬉しいです。
1. 概要
この記事の目的
- DevOpsにまつわる一通りの知識を俯瞰して、DevOpsというのがどういうものなのかをざっくり知ることができる
- さらに詳しく知りたと思った事柄に関して、どんな情報に当たれば良いかの検討がつくようになる
なお、この記事は以下の内容を元に書かれています。
- 研修:速習 DevOpsエッセンシャルズ(全体構成) → 少々値は張りますがオススメ
- 書籍:The DevOps ハンドブック 理論・原則・実践のすべて(個々の手法など)
- 書籍:Effective DevOps ―4本柱による持続可能な組織文化の育て方(devopsの気持ち)
書いてたらめっちゃ長くなってしまったので、目次を付けます。
目次
-
- 概要 ← 今ここ!
-
- devopsの背景
- 2-1. ITサービスの問題
- 2-2. 運用チームと開発チームのコンフリクト
- 2-3. 顧客の要望に対してスピーディーに対応したい
-
- devopsとは
- 3-1. 発端と歴史
- 3-2. devopsとは
-
- devopsを取り巻く用語や概念
- 4-1. 継続的インテグレーション(CI)、継続的デリバリー(CD)
- 4-2. 小さなチャンク
- 4-3. 実用最小限の製品(MVP: Minimum Viable Product)
- 4-4. マイクロサービスアーキテクチャ
- 4-5. アジャイル
- 4-6. サービスレベル要件(SLR: Service Level Requirement)
- 4-7. リーンソフトウェア開発
- 4-8. カンバンフレームカワーク
- 4-9. 技術的負債
- 4-10. Infrastructure as Code
- 4-11. ペットと家畜
-
- フロー改善
- 5-1. デプロイパイプライン
- 5-2. ツールとオートメーション
-
- カルチャーと人材
- 6-1. チームの組織構成
- 6-2. チームのスキルとトレーニング
- 6-3. devopsで求められるリーダーシップの特性
- 6-4. ジャストカルチャー
-
- devopsの始め方
- 7-1. まずは計測より始めよ
- 7-2. チームとプロジェクトの選択
- 7-3. devopsのフェーズごとの重要要素
- 7-4. スクラムのスケーリング
DevOps理解度チェック項目
本記事を読み終えると、以下のチェック項目に答えられるようになると良いカモです。
このチェック項目自体が長いので、チェック項目に興味がない人は飛ばしてもOKです。
- DevOpsとは何か概要を説明できる
- 以下の用語の意味が分かる
- 継続的インテグレーション(CI)
- 継続的デリバリー(CD)
- 実用最小限の製品(MVP:Minimum Viable Product)
- ユーザーストーリー
- リーン
- カンバンフレームワーク
- 技術的負債
- IaC(Infrastructure as Code)
- A/Bテスト
- カナリアリリース
- デプロイパイプラインの概念と大まかな流れが分かる
- アジャイル開発の概要が分かる
- スクラム開発の概要と、一般的なプロセスを資料に基づいて説明できる
- SLR(Service Level Requirement) の概要と、プロダクトバックログで運用面の要件が必要な理由が分かる
- 仮想マシンとコンテナの違いが分かる
- ソースコード管理の方法についてGithubを用いた例で概要を説明できる
- 構成管理に使用する「Puppet」、「Chef」、「Ansible」の概要が分かる
- 機能横断型組織の利点が分かる
- コンウェイの法則と現実の例をあげることができる
- フォロー型とサーバント型それぞれのリーダーシップの元でメンバーの態度の変化が分かる
- 「非難のない」事後分析がなぜ重要か説明できる
- 開発・運用組織改善を目指したセルフアセスメント(計測)の重要性と具体的な指標が3つ以上言える
- DevOps習熟度のモデルを引用して、今の自組織がどの段階にあるのか説明できる
- DevOpsを適用するプロジェクトの選択とチームの編成についてどのような指針を持つべきか分かる
- DevOpsを成功させるために必要な重要な要素を3つ以上あげることができる
- スクラム開発をスケーリングさせるフレームワークを1つ以上説明できる
ということで、以下本編です。
2. devopsの背景
「devopsとは何か」についてのバシッとした定義は存在していません。
(以下、『Effective DevOps』著者のJennifer、Rynに合わせて devopsと表記します。)
devopsとは文化であり、哲学であり、ムーブメントです。
まずは、devopsという言葉が生まれた背景から見ていきましょう。
2-1. ITサービスの問題
顧客や市場はスピードを求めるにも関わらず、IT組織の動きが遅くなってしまうことがあります。
ビジネスから新たな機能が要求されてから、実際に使用できるまでに大変長い時間がかかることがあります。
作った機能や変更された機能の管理が困難だったり、サービスに対するフィードバックを受けてもそれをうまく活用できなかったり・・・。
その他にも、以下のような「運用」と「開発」のコンフリクトといった問題もいたるところで見受けられます。
2-2. 運用チームと開発チームのコンフリクト
運用チームと開発チームはそれぞれ目的が以下のように異なっている場合が往々にしてあります。
- 開発チーム:最大限の変更を求める
- コードを変更してサービスを市場に適応させる
- 運用チーム:最小限の変更を求める
- 変更を監視、障害のリスクを防ぎ、可用性を維持する
そのため、しばし利害が一致せずにコンフリクトが起きることがあります。
2-3. 顧客の要望に対してスピーディーに対応したい
上記のような問題はウォーターフォール開発を採用しているような、ある程度大きな組織なら多く見られる事象かと思われます。
しかし、現代は「VUCA」の時代に入り、顧客の要望に対してスピーディーに対応していく必要があると言われています。
※VUCA(ブーカ): Volatility(変動性・不安定さ)、Uncertainty(不確実性・不確定さ)、Complexity(複雑性)、Ambiguity(曖昧性・不明確さ)の頭文字
3. devopsとは
3-1. 発端と歴史
devopsとは開発(Develop)と運用(Operation)の混成語です。
devopsの発端はPatrick Deboisがカンファレンスで発表したAgile Infrastructure & Operationsと言われています。
彼は運用と開発の間で非常に苦労し業務の中で試行錯誤をしておりました。
そこで得た知見や考えを発表したところ、同様の課題意識を持つ人たちが声を上げ始め、devopsのムーブメントが始まりました。
また、devopsはLean Thinkingや、Scrum、XP、Agileといった開発手法が源流となっています。
この辺りの話はDevOpsの起源とOpsを巡る対立でよくまとまっているので、気になる方はこちらを参照すると良いかもしれません。
3-2. devopsとは
上記で述べているように、定義は存在しませんが世の中では以下のようなCALMSというフレームで説明されることがあります。
それぞれの項目を重要視していくことでdevopsを進めていくことができます。
- カルチャー(Culture)… 開発、運用、QAチームで協力して目的を達成するのだという本質的な組織文化の転換を目指す
- 自動化(Automation)… 自動化できるものは全て自動化する
- リーン(Lean)… ミーティングやチームの規模、ツールの数などに関する無駄を排除する
- 測定(Measurement)… あらゆるものに関するデータを収集し、確認できるようにする
- 共有(Sharing)… 開発チームと運用チームの継続的なコミュニケーションを推進する
4. devopsを取り巻く用語や概念
ここでは、devopsで登場する重要な用語や概念をザッと見ていきます。
4-1. 継続的インテグレーション(CI)、継続的デリバリー(CD)
継続的インテグレーションの根底にある考え方は開発者が何週間、何ヶ月もかけたコードを確認(テスト)するよりも、日々のコードの差分を確認(テスト)する方が良いというものです。
そのために重要なのが、「細かなコードの更新をすぐにテストでき、失敗した場合は直ちに検知できる仕組み」です。
このような仕組みをより一般化したものをデプロイパイプラインといい、以下のようなイメージで表現されます。
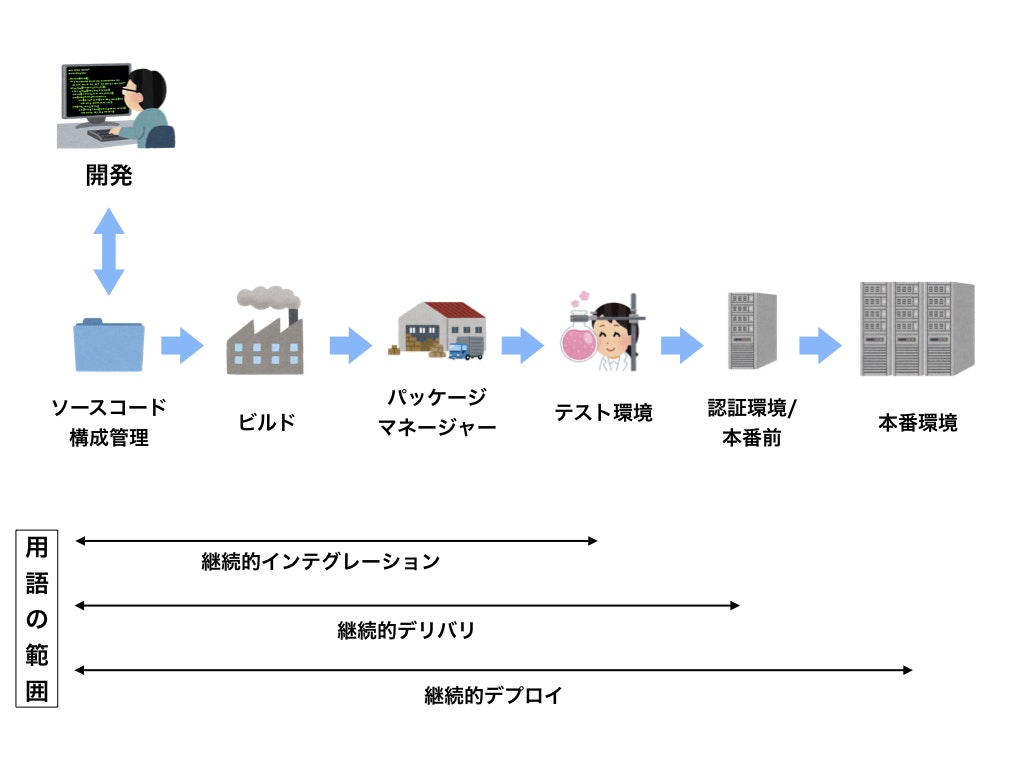
こうした仕組みを用いて、以下のように継続的(Continuous)にコード全体が機能するようにする(Integration)ことをCIと言います。
- コードの細かな変更をすぐに確認して最新バージョンをビルドする
- 一連の単体テストを実行する
- テストが成功した場合
- テスト環境にデプロイする
- テストが失敗した場合
- テストの失敗がチームに通知される
- ビルドを壊した開発者はすぐに修正が求められる
ここでテストが通った場合、本番環境へのデプロイ(デリバリー)も自動で行ってしまおうというのが、継続的デリバリーとなります。
実際にどうやるか?について 5. フロー改善 で紹介します。
4-2. 小さなチャンク
チャンクというのは、ビジネスにとって有用なかたまりのことを指します。
ベースとなる考え方は小さなインクリメント(機能の増分)ごとにコードを頻繁にデプロイできればイノベーションやサービス品質の妥当性確認が安易になるというものです。
そこで、作り物に関して開発者が「小さなチャンク(ユーザーストーリ)」に分解して細かくデプロイしていくことが重要となります。
4-3. 実用最小限の製品(MVP: Minimum Viable Product)
MVPとはチームが最小限の労力で顧客からの有効なフィードバックを最大限に収集できるようにする新製品のバージョンのことです。
システムを開発する際に「あれもこれも」と機能や要件が膨れ上がることが良くあります。
しかし、たくさんの機能を追加しても使われなければあまり意味がありません。
そのため、最低限の機能を素早く実装し、最短の期間で顧客にデリバリーすることによって、より素早くフィードバックのループを回すことが重要です。
そうした開発の思想をMVPと言います。
4-4. マイクロサービスアーキテクチャ(MSA)
マイクロサービスアーキテクチャとは、モジュール式のアプリケーション構造を構築するソフトウェアアーキテクチャの一つの手法です。
モノリシックな一枚岩の巨大なシステムで起こる様々な問題(一つの変更による影響が分からないためコードへの変更が困難、障害ポイントの解明ができないなど)に対処するために、考案されたものです。
MSAを用いると、システムの拡張が安易であり、小規模なチームがそれぞれ異なるサービスに対応可能などのメリットがあります。
一方で複雑さの増大や全体管理が困難になるなどのデメリットもあります。
マイクロサービスアーキテクチャについては、マイクロソフトの解説記事が分かりやすくまとまっています。
4-5. アジャイル開発手法
アジャイル開発手法とはソフトウェア開発を行うための開発手法群の総称です。
アジャイル開発手法では重視される原則について、アジャイルソフトウェア開発の世界で著名な17人の開発者によってまとめられています。
以下、内容を引用します。
私たちは、ソフトウェア開発の実践
あるいは実践を手助けをする活動を通じて、
よりよい開発方法を見つけだそうとしている。
この活動を通して、私たちは以下の価値に至った。プロセスやツールよりも個人と対話を、
包括的なドキュメントよりも動くソフトウェアを、
契約交渉よりも顧客との協調を、
計画に従うことよりも変化への対応を、価値とする。すなわち、左記のことがらに価値があることを
認めながらも、私たちは右記のことがらにより価値をおく。
ここではアジャイル開発手法として、特に有名な手法の一つであるスクラム開発について説明していきます。
なお、アジャイル開発手法に関してはそれだけで、一冊の本になってしまうほど多くの内容が含まれております。
スクラムの概要
スクラム開発手法については、スクラムガイドで全てまとまっていますが、以下に概要をざっくり説明していきます。
スクラム開発では「スプリント」と呼ばれる短期(通常2〜4週間)の開発期間を繰り返すことによって、開発を行います。
一回のスプリントは以下のようなイベントが発生し、このスプリントを繰り返すのがスクラム開発のイメージです。
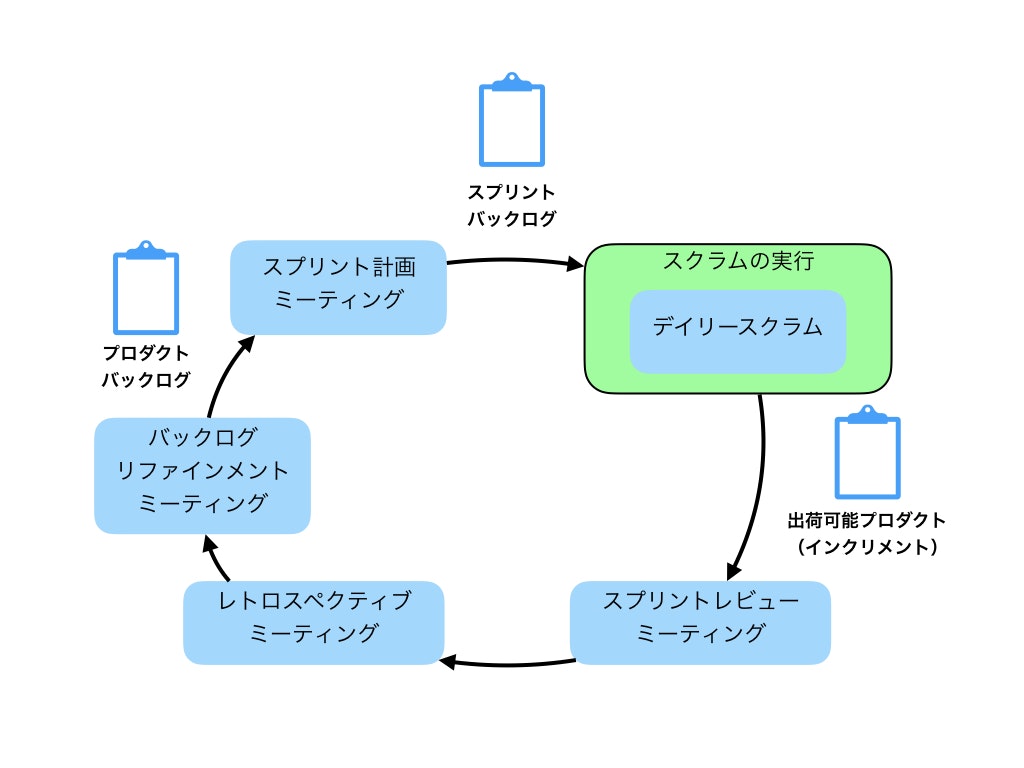
スクラム開発メンバーの3つの役割
スクラム開発では以下3つの役割のメンバーがいます。
ちなみに、プロダクトオーナーの必要性は直感的に認識できますが、スクラムマスターについては本当に必要なのかと思う方がいるかもしれません。
スクラムマスターがいないとスクラム開発の風をしたよくわからない開発になってしまう危険があります。
もしスクラム開発を行いたく、組織内に知見がない場合は必ずチームにスクラムマスターを配置しましょう。
- プロダクトオーナー
- 全体的な結果に責任を追い、プロダクトバックログの優先度付けや承認・却下やインクリメントの出荷判断などを行う
- スクラムマスター
- 全体のプロセスを促進して、適切なプラクティスを推進する
- チームメンバー
- 成果物の協議やシステムのビルドなどを行う
スクラムミーティング
スクラム開発では上記の図のようなミーティングを設定します。
以下、それぞれのミーティングの概要と目的などを説明します。
-
スプリント計画(プランニング)ミーティング
- スプリント内で取り組むアイテムリスト(スプリントバックログ)をプロダクトバックログ(ビジネス的要件からなるTODOリスト)から決定するミーティングです
-
デイリースクラムミーティング
- 日々の進捗確認のミーティングです
- 完了したタスクや現在の課題などを共有します
-
スプリントレビューミーティング
- スプリント内で完成したプロダクト(インクリメント)についての出荷判断や追加のタスクなどを特定します
-
スプリントレトロスペクティブミーティング
- スプリント内の行動や成果について振り返ることにより、チームやプロセスそのもののアップデートを行います
-
バックログリファインメントミーティング
- 次のスプリント計画ミーティングに向けてプロダクトバックログを整理します
ユーザーストーリーと完成の定義
スクラム開発のスプリントでは、重厚長大な要件定義がなされることは通常ありません。
その代わりに利用するのが「ユーザーストーリー」です。
ユーザーストーリーは要件を明らかにして関係者間で共有するために、ユーザーがそのシステムを使ってやりたいことを分かりやすくまとめます。
ユーザーストーリーの書き方はアジャイル開発とユーザーストーリーという記事で分かりやくまとまっています。
これらのユーザーストーリーを元にスプリントごとに、「何をもって完成とするか」という基準を明確に定義する必要があります。
これをスクラムでは**「完成」の定義**と言い重要視されます。
4-6. サービスレベル要件(SLR: Service Level Requirement)
運用面の要件に関して開発者が運用チームに丸投げの場合はあまり考慮されませんが、devopsではサービスレベルについても要件として組み込みます。
例えば、「高速に文章を検索できるようにする」という要件は曖昧なので、「25MBのドキュメントで4文字の文字列を750ミリ秒以内に検索できるようにする」と言った測定可能な要件にすることが求められます。
SLRの洗い出しに関しては以下の6つのカテゴリが用いられることがあります。
- 可用性
- パフォーマンス
- 継続性
- キャパシティ
- セキュリティ
- サポート
4-7. リーンソフトウェア開発
リーンソフトウェア開発は、トヨタ生産方式(TPS)を参考に考案された開発手法のひとつです。
なお、リーンソフトウェア開発についても、アジャイル開発と同様に一冊の本になってしまうほど多くの内容が含まれております。
リーンソフトウェア開発についてはトヨタに学ぶ!リーンソフトウェア開発の7つの原則が参考になります。
リーン開発 7つの原則
リーン開発では以下の7つの原則が重要であるとされています。
- 原則1:ムダを排除する
- 原則2:知識を作り出す
- 原則3:決定をできるだけ遅らせる
- 原則4:できるだけ早く提供する
- 原則5:権限を移譲する
- 原則6:全体を最適化する
- 原則7:品質を作りこむ
「無駄」とは
上記の中でも「ムダを排除する」という原則は非常に重要です。
(ちなみに英語でも「MUDA」で通じます)
ソフトウェア開発におけるムダの例は以下のような部分で発生します。
- 未完成の作業(テストされていないコード、開発待ちの仕様)
- 使われないコードや余分な機能(使わないドキュメント)
- 余分なプロセス(不要な承認作業)
- 作業の切り替え(スタッフが複数のプロジェクトを担当することによるコンテキストスイッチの発生)
- 欠陥(要件の欠陥、ソフトウェアのバグ)
- などなど…
無駄を洗い出して排除することが重要です。
バリューストリーミングマップ
バリューストリーミングマップを用いることによって、現状の整理することができます。開発の工程をプロセスに分解してその中のタスクを洗い出し「価値を生むタスク」、「価値を生まないタスク」に分けることによって、ムダを排除することができます。
実際の開発で試している例として、「バリューストリームマッピングをやってみた」が参考になります。
4-8. カンバンフレームワーク
カンバンは作業の見える化を行い効率化を目指す開発手法です。
タスクの状態を「TODO」、「Wok in Progress(WIP)」、「DONE」などに分類し、ボード上タスクの状態を表す列を用意して、でタスクをそれぞれの状態に移動させるなどをしてタスクを管理します。
カンバンフレームワークでは以下4つの原理に従います。
- 作業を可視化する
- 処理中の作業を制限する
- 作業の流れをスムーズにする
- 継続的に改善する
4-9. 技術的負債
技術的負債とは、設計の妥協などが原因となり理想状態から離れたシステムの状態を負債という比喩で表した言葉です。
以下のような例が挙げられます。
- 非効率なコード
- カバレッジの低いテスト
- ドキュメントの不足
- 古すぎるバージョンの言語やフレームワーク
- 開発環境と本番環境の差異
- などなど
こうした、技術的負債について避けるのは非常に難しく、通常業務の中でこうした技術的負債の返済に当てる時間を用意するなどの対処が必要と言われています。
また、技術的負債を残しにくい設計をするなどの対処をすることも重要です。
この辺りは、以前「機械学習使っても技術的負債を残しにくいAWSのインフラ構成」という記事を書いたので、もしよかったら参考にしてみてください。
4-10. Infrastructure as Code
この考えの元ネタは冒頭で紹介したDeboisがカンファレンスで発表したAgile Infrastructure & Operationsという発表です。
IaCは「ソフトウェアがコードで管理してCIできるんだから、インフラだってそうしよう」的な考えがベースになっています。
つまり、Infrastructure as Code(IaC)は運用チームが手動のプロセスをしようする代わりにコードを通じて自動的に管理やプロビジョニングすることを指します。
4-11. ペットと家畜
サーバーをどのように捉えているかを表した「ペットと家畜」という考え方があります。
あなたが、丁寧に設定をしてチューニングを行ったサーバーはペットに例えられます。
しかし、そのペットが死んでしまったらどうなるでしょうか。
一方、一台一台のサーバーはただのサーバーであり、調子が悪ければ落とすし、すぐに同様の状態にすることができるという考え方のサーバーは家畜に例えられます。
クラウド全盛の時代においては、上記のように、サーバーをペットのように可愛がらずに家畜のようにみることも重要だろうというのが「ペットと家畜」という考え方です。
なお、ペットと家畜という考え方については、「ペットと家畜 [和訳]」に詳細がまとまっています。
5. フロー改善
ここでは、開発から運用へのフローを早くし、それを維持するために必要な考え方や手法について触れていきます。
5-1. デプロイパイプライン
4-1. 継続的インテグレーション(CI)、継続的デリバリー(CD) で触れましたが、ここではもう一度詳しく説明していきます。
以下は先ほどの図です。
このような図で表される「開発」から「本番デプロイ」までに通過するステップ・ステージで構成された流れをデプロイパイプラインと言います。
ステップは組織やアプリケーションによって異なり、自動化のレベルも様々です。
上記の図は一般的なデプロイパイプラインを示したものなので、上記の図にそってそれぞれのステージ関連する概念等の説明をしていきます。
開発(デプロイパイプラインのステージ)
アプリケーション開発は開発者がコードを書いたりテストしたりするツールを提供できる開発環境で行われます。
このステップではIDE以外にも協働を可能にするプロジェクト管理ツール(JIRAなど)や単体テストツールなどが用いられます。
ソースコード管理(デプロイパイプラインのステージ)
開発者が作成したコードを管理するために、バージョン履歴を維持したり、同じコードの2つのバージョンを区別したりする機能が必要です。
Gitを使う方法が一般的かと思います。
また、ソースコード管理の方法として「Gitflow」が大変便利なため、その方法を使っているところが多いです。
Gitflowをどう行うかについては「A successful Git branching model を翻訳しました」という記事が分かりやすくて良いと思います。
ビルド(デプロイパイプラインのステージ)
このステージではコードをコンパイルするステップです。
通常ビルドサーバーを用意して、多数のビルドを安易にできるようにします。
原則として、テストの再現性などの観点から、デプロイパイプラインにおいてビルドが行われるのは一回のみです。
パッケージング(デプロイパイプラインのステージ)
アプリケーション開発では、リソース、コンポーネント、コードなどのアーティファクトを再利用して、効率性、信頼性、保守性を向上させる必要があります。
そこで開発チーム内で共有できるようなライブラリが必要となります。
具体的なツール(アーティファクトリポジトリマネージャ)としてNeXus、Archivaなどが利用できます。
それぞれを比較した「アーティファクトリポジトリマネージャの比較 Nexus/Archiva/Artifactory」という記事が分かりやすいです。
なお、Webアプリの開発者などは、自社のライブラリというよりも、RubyのgemやPythonのpipなどが使われており、ピンと来ない方はライブラリ管理の自社専用ツールのようなものを想像していただけると良いかもしれません。
テスト(デプロイパイプラインのステージ)
デプロイパイプラインの一部として自動化されたテストを実行するプロセスを「継続的テスト」と言います。
コードの修正と共にテストが自動で行われるようにしてお来ましょう。
一般に自動テストは以下の分類がなされます。
それぞれの観点で重要なテストをあらかじめ自動化しておくことによってスムーズな開発ができるようになります。
- ユニットテスト … 1つのメソッド、クラス、関数を他から切り離しコードが設計通りに動作していることを確認します
- 受け入れテスト … アプリケーション全体をテストして講師順の機能が設計通りに動作していることやリグレッションエラー(以前正しく動作していたのに、コードの更新でおかしくなる)が入り込んでいないことを確認します
- インテグレーションテスト … 本番稼働している他のアプリケーションやサービスと正しくやりとりできることを確認します
ブルーグリーンデプロイメント / カナリアリリース
デプロイはできるだけ安全に行わなければなりません。
できるだけ安全なデプロイを行うために広く行われている方法をここでは紹介します。
ブルーグリーンデプロイメント
以下のような特徴を持ったデプロイ方法です。
- 同一の環境(インフラ)を2組み用意して、片方の環境を本番環境に当てます(こちらの環境を「グリーン」と言います)
- 新しく更新されたアプリケーションをもう一つの環境にデプロイします(こちらの環境を「ブルー」と言います)
- ブルー環境が整ったら、トラフィックをグリーンからブルーに移し変えて、ブルー環境とグリーン環境を入れ替えます
- トラブルが起こった場合はすぐさま元の環境に戻し、問題なければ入れ替えた環境で新たな開発を行います
カナリアリリース
カナリアリリースではアプリケーションの新バージョンを本番環境の一部のトラフィックで試して問題がないかを確認する方法です。
一部のトラフィックで実験することで被害を最小限に抑えると共に、本番でのテストを行うことができます。
A/Bテスト
A/Bテストは機能要件の確認というよりは、「リリースした機能がビジネスにとって有用かどうか」を確認するための手法です。
A/BテストではAとB、2つの機能を本番環境に展開しますが、AとBでそれぞれ無作為にユーザーが割り振られるようにロードバランサー等を設定します。
実験期間の後でAとBのパターンでKPI等の指標に変化が生じるかをみて、どちらの機能を採用するかを確認します。
セキュリティ
セキュリティに関してはマストで対応する必要があります。
以下のような項目に注意して対応していきましょう。
- セキュリティをチーム全員の職務とする
- デプロイパイプラインの要件にセキュリティを入れる
- ユニットテストで脆弱性を見つけるテストを入れる
- ログインの成功/失敗などセキュリティ関連の指標を定義し測定する
- などなど
devopsにおけるセキュリティの対応に関しては『The DevOps ハンドブック 理論・原則・実践のすべて』の第6部「情報れキュリティ、変更管理、コンプライアンスを統合するための技術的実践」(p.396-438)が実践的で大変参考になります。
5-2. ツールとオートメーション
ここではdevopsを実現するために必要なツールについて触れていきます。
1つで全てをこなせる魔法のツールは存在しないので、複数のツールを使い分けるのが良いと思われます。
仮想化とコンテナ
1つのサーバーのリソースを分割して、複数の個別独立したサーバのように機能させる「サーバ仮想化」という技術があります。
こうした技術を用いることによって「隔離されたアプリケーション実行環境」を用意することができますが、現在では主に以下の2つの技術が用いられています。
- 仮想マシン
- オペレーティングシステムからメモリとストレージに至るまで、コンピュータ全体を抽象化
- 仮想マシンごとにプロセッサやメモリを消費しストレージも必要
- 十分に発達し成熟したソリューション
- メジャーなツール:vagrant
- コンテナ
- コンテナは、既存のマシンの一部を占有するように設計されており、ホスト上のカーネルをシステム上で実行されている他のコンテナと共有
- 仮想マシンに比べ仮想マシンに比べて起動時間が短く、多くのコンテナを同時に動かすことができる
- 比較的新しい技術
- メジャーなツール:Docker
それぞれの詳細な特徴については「コンテナ化するのか、あるいはコンテナか仮想マシンかは、果てしない議論です」という記事に詳しく書かれているので、詳細がきになる方はそちらを参考にしてください。
ソースコード/バージョン管理
ソースコードを管理するに当たって、個人的にはよっぽどのことがない限りGit、Githubで良いかなと思っていますが、その他にも色々ツールがあります。
ソースコード管理のアプリについては「Git、Mercurial、Subversion、Perforce、どれを使う?」という記事で比較されています。
継続的インテグレーション(CI)
継続的インテグレーションを実現するためには、それを実現する中枢となるツールが必要です。
以下の図はCIを実現するための一例を表しています。
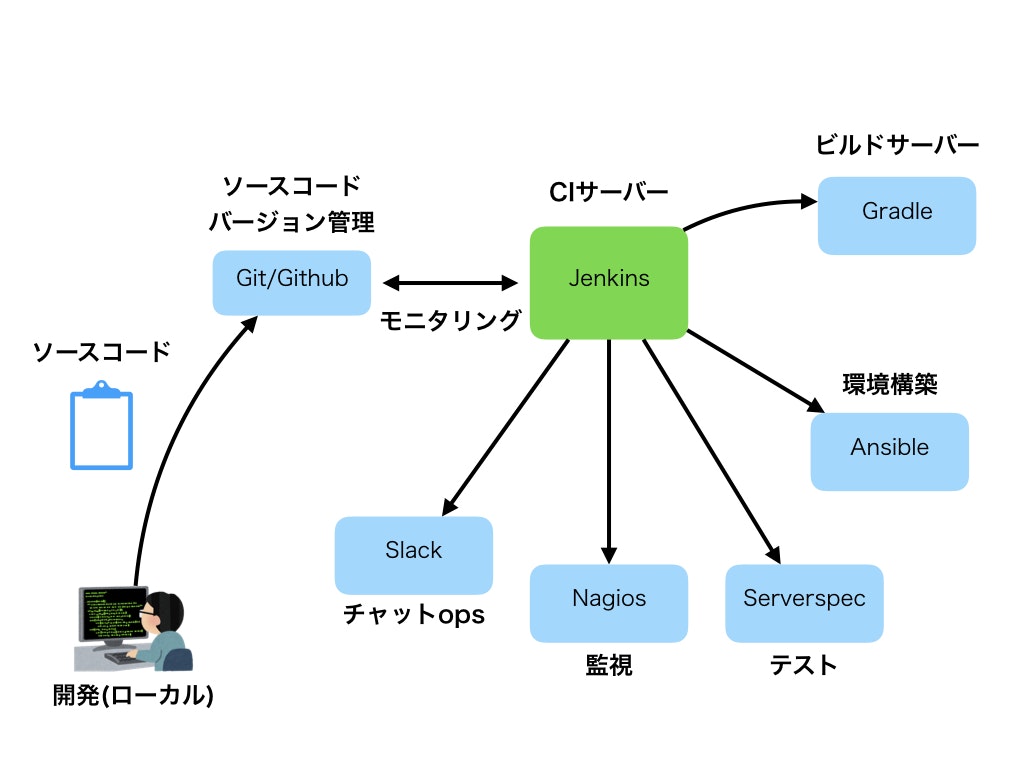
上記のようにCIツールは非常に重要で自前でサーバーを立てることができればJenkinsが使われることが多いです。
Jenkinsの他には以下のようなツールが使われており、それぞれSaaSであるかなどの特徴があるため、組織の状況に応じて使い分けることが重要です。
- Travis CI
- TeamCity
- CircleCI
- Drone.io
コード解析/テスト
テスト自動化ツールについては以下のようなツールがあります。
ここではざっくり分類して列挙していますが、それぞれ異なる特徴があるので目的にあったツールを選びましょう。
- インフラ環境のテスト
- Serverspec
- TestKitchen
- Infrataster
- 受け入れテスト自動化
- Cucumber
- RSpec
- selenium
- Capybara
- コード解析
- Coverity
構成管理(IaC)
インフラの様々な構成要素をデプロイするのに有用なツールとして以下のようなものがあります。
- Pupet
- Chef
- Ansible
それぞれを開発スタート時期や基本構成方法などを横並びで比較すると以下のようになります。
| Pupet | Chef | Ansible | |
|---|---|---|---|
| 開発スタート | 2005 | 2009 | 2012 |
| 基本構成方法(更新方法) | Pull | Pull | Push |
| 対象サーバーへのAgentインストール | 必要 | 必要 | 不要 |
| 記述方法 | 独自 | Ruby | YAML |
詳細な比較は「AnsibleとChefとPuppetの比較」という記事に詳しいです。
コミュニケーション/コラボレーション
コミュニケーションをコラボレーションを促進するために以下のようなツールがあります。
Slackを導入しているところが多い印象があります。
- Slack
- Microsoft Teams
監視、モニタリング
サーバーの状態や、アプリケーションのログなどを監視するために様々なツールがあります。
以下の記事でメジャーなツールについて比較を行ってくれています。
6. カルチャーと人材
ここではdevopsで重要とされるカルチャーと人材に関する項目をみていきます。
6-1. チームの組織構成(コンウェイの法則)
「システムを設計する組織は、その組織とそっくりの構造のシステムを作る」
これはコンウェイの法則と呼ばれる有名な法則です。
devopsを推進していくに当たっても組織の構成は非常に重要な要素となります。
意思決定科学の分野では組織構造には職能、マトリックス、市場からなる3種類のタイプがあるとされており、それぞれ以下のような特徴があります。
-
職能志向
- 専門能力の育成、活用、分業、コスト削減に適していまる組織
- サーバー管理、ネットワーク管理、データベース管理などのチームになる
-
市場志向
- 顧客のニーズに素早く呼応することを意図して作られる組織
- 複数の職能横断的なメンバーから構成されている(クロスファンクショナルチーム)
-
マトリックス志向
- 職能志向と市場志向の2つのタイプを統合することを意図した組織
- 1人の作業者が複数の上司に使えるなど、組織構造が複雑になってしまい職能志向、市場志向どちらの目標も達成できないことがある
devopsを推進していくに当たっては、職能志向の影響を抑えて市場志向を実現していくことが重要です。
なぜなら、独力で安全に仕事を進められるチーム編成の場合、より素早く顧客に価値を届けることができるからです。
6-2. チームのスキルとトレーニング
devopsを進めるに当たってメンバーに必要なスキルなどを確認していきます。
現在そのスキルがなくとも、これから身につけていくことが重要です。
必要なスキル
メンバーの望ましいスキルとして、以下のような例があります。
- 上級レベルのシステム管理
- 仮想化の経験
- 幅広い技術的バックグラウンド
- スクリプト作成(自動化ができる)
- Chef、Puppet、その他オートメーションツールの経験
- Git-flowをはじめとするソースコード管理の知識
- 顧客サービス
- クラウドの経験(AWS、GCP、Azure)
- コラボレーションやビジネスプラクティスに関する包括的な知識
- コミュニケーションスキル
- 問題解決能力
そのほか、「変化に挑戦できる」、「オープンな心」、「協調的」といったスタンスなども重要です。
個別ストーリーですが「DevOpsを知ったかぶりしていた私が、チームの人とつまづきながらカイゼン・ジャーニーしている話。」という記事を読むことで、どのようなスタンスを持つことが重要かを考えることができます。
また、『Effective DevOps ―4本柱による持続可能な組織文化の育て方』という書籍ではそうした文化を個別ストーリを通して学ぶことができます。
6-3. devopsで求められるリーダーシップの特性
リーダーシップの種類として、以下の2種類について言及されることがよくあります。
- 支配型リーダーシップ … トップダウン方式のリーダーシップ
- サーバント型リーダーシップ … 支援方式のリーダーシップ
支配型リーダーシップの元では受身的なメンバーが育つのに対して、サーバント型リーダーシップの元では主体的なメンバーが育つと言われています。
なお、ソフトウェアデザイナーのDes Nnorchiri氏のDevOpsのリーダーに必要な素養も参考になります。
devopsを進めていくに当たって、メンバーの主体性は非常に重要なため、サーバント型リーダーシップが求められます。
6-4. ジャストカルチャー
継続的な改善をするために、組織の中にラーニングカルチャー(学習する文化)を築くことが重要です。
そのために必要と言われている要件の一つに事故が起きた時に(事故は必然的に起こります)その対処方法が公正(ジャスト)に見えるようにすることです。
Sidney Dekkerはこの考え方に対してジャストカルチャーという用語を与えています。
「非難のない」事後分析(ポストモーテム, John Allspaw)によって学習する組織となっていきます。
やり方については「非難なき事後分析と公正な企業文化」という記事が詳しいです。
7. devopsの始め方
ここでは自分の組織でdevopsを始める際に、「何から始めたら良いか」、「どのようなことに注意したら良いか」といった疑問に対して、ある程度の指針を与えることを目的とします。
なお、「DevOpsを企業が効果的に実践するための8つのステップ」という記事も、組織にdevopsを導入する上での参考になります。
7-1. まずは計測より始めよ
私自身の経験からも、まず計測から始めることがとても重要だと言えます。
devopsに対して興味があるということは、システムや組織に対して何らかのモヤモヤや課題意識を感じているのではないかと思います。
計測をすることによって、現状を正確に把握することができ、次にやるべきことが明確になっていきます。
現状の把握
以下のような観点で現状をチェックしましょう。
- チームの構成
- アジャイル開発の経験豊富なメンバーはいるか
- デプロイプロセス
- どのようなプロセスでデプロイをしているか
- 自動化されている部分はあるか
- テクノロジー・ツール
- 現状開発や運用で導入されている技術・ツールはあるか
- 定量指標
- プロセスタイム(バックログのタスク実行宣言から本番投入までの時間)
- 市場投入までの時間(TTM: Time To Market)
- デリバリ頻度(1日に1回?1週間に1回?1ヶ月に1回?・・・)
- リリース安定化期間(デプロイしてから「問題ないな」と思えるまでの時間)
- デプロイプロセス期間(カットオーバー計画期間)
- コードに対する変更によるインシデント数(エラーの割合)
- 1日に行われる安全なデプロイ件数
- 新しい機能の利用率
- インシデントからの平均復旧時間(MTTR: Mean Time To Recovery)
- 可用性
- パフォーマンス
- などなど・・・
これらの項目を測ると徐々に組織やシステムの状態が明らかになっていきます。
また、定量的に測れる項目に関してはある程度の期間計測を続けると「悪化している部分」、「変わらない部分」、「良くなっている部分」などが見えてきます。
これらの計測結果から、どのように進めるかの方針を立てていくことが重要となります。
また、ヒューレットパッカード社が提唱しているDevOps成熟度モデルを用いて、自組織がどの段階にいるのかなどを当てはめてみて、次にすべきアクションの指針を立てるのも良いかと思います。
7-2. チームとプロジェクトの選択
実際に会社でdevopsを始めたいと思ってもとっかかりがないとやりにくいかもしれません。
ここではそのとっかかりとして、プロジェクトの選択とチームの選択(編成)について見ていきます。
プロジェクトの選択
まずは、以下のようなポイントに注意して重要なアプリケーションを1つか2つ選びます。
- 社内の注目を集めるもの
- 実稼働やインシデントなど問題について既知の事実があるもの(良くダウンするなど)
- 開発と運用に人間関係の問題があるもの
- 致命的問題や甚大なビジネスリスクに関わらないもの
チームの選択や編成
チームは先に述べた「市場志向」になるように注意しましょう。
そのために必要な分野(開発、テスト、運用など)を全て統合したチームを形成することが重要です。
チームの編成後はチームが自己組織化できるように、トレーニングやコミュニケーション、学習などを促し支援します。
7-3. devopsのフェーズごとの重要要素
devopsを進めるに当たって、フェーズごとに重要な要因を列挙していきます。
プロジェクトのキックオフ
- 意欲的なメンバーを中心にプロジェクトを構築れている
- 必要な環境とサポートが提供される
- プロダクトオーナーがプロジェクトのビジョンを説明できる
開始時
- ビジネス要件に基づいてプロダクトバックログが評価され優先度がつけられている
- 継続的インテグレーションのプロセスの準備が整っており、少なくとも一部が自動化されている
- 開発/テスト環境が準備できている
- ビジョンがクリアになっている
スプリント
- 出荷準備が整った製品となるようなインクリメントがビルドできる
- ビジネスのGoが出た時点でデプロイできるようCDが構築できている
- プロセス自体の振り返りやそれに基づく改善ができている
7-4. スクラムのスケーリング
以下で紹介するのは大規模な開発になった時に、いかにスクラムをスケールさせるかという話です。
通常、スクラムは4〜8人くらいの規模のチームですが、それ以上のアウトプットを出したい時に使えるフレームワークを以下で紹介します。
なお、以下のフレームワークではないですが、Spotifyのアジャイルをスケールさせた「Spotifyのスケーリングアジャイル – 部隊、分隊、支部やギルドと共に歩む」が非常に参考になります。
Scaled Agile Framework: SAFe
以下に示すようなフレームにより複数チームで開発を進めます。
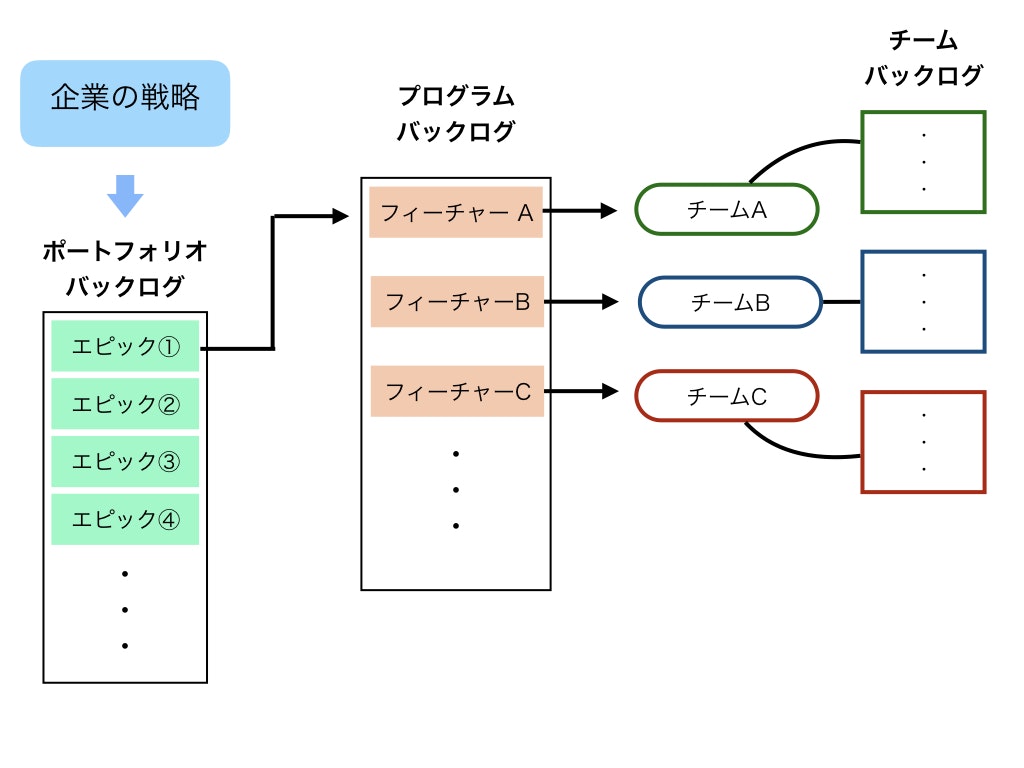
SAFeでは最上位の企業戦略から、プロダクトやシステムに対するニーズとそれを解決するソリューションである「エピック」を複数バックログに入れて、エピックから導き出される最上位の要求である「フィーチャー」という単位に分割します。
そして、チームごとにフィーチャーが割り当てられ、チームごとにユーザーストーリーに分解して開発を行なっていきます。
SAFeについては「SAFe (Scaled Agile Framework) 3.0 入門 (第4回)」が詳しいので、そちらを参考にしていただけると良いかと思います。
Nexus
Nexsusフレームワークでは複数チームが連携するために、チーム間を取り持つNexus統合チームを編成するとう特徴があります。
詳しく知りたい方は「Nexus(大規模スクラム開発)の概要」という記事を参照すると分かりやすいです。
度々アップデートがなされるので、最新のものはこちらの情報をチェックするのが良いと思います。
終わりに
自分でもびっくりするくらい長くなってしまって、非常にびっくりしています。
こまめなデプロイ思想に全くそぐわない記事になってしまいましたが、全体俯瞰するのには使えるかと思います。
ここまでお付き合いいただきありがとうございました。