はじめに
こんにちはrilmayerです。
この記事はアドベントカレンダー「Search&Discovery 全部俺」17日目の記事となります。(遅れ・・・
今日は一般的な推薦システムの構成について簡単に説明しつつ、それぞれのコンポーネントが何をやっているか、それぞれのコンポーネントを担う代表的なアプリケーションについて紹介したいと思います。
推薦システムの構成
以下の図は、著者が今まで見たシステムや「推薦システム: 統計的機械学習の理論と実践」や「AIアルゴリズムマーケティング 自動化のための機械学習」、「Building a smart recommender system across LINE services」などをベースに作成しています。
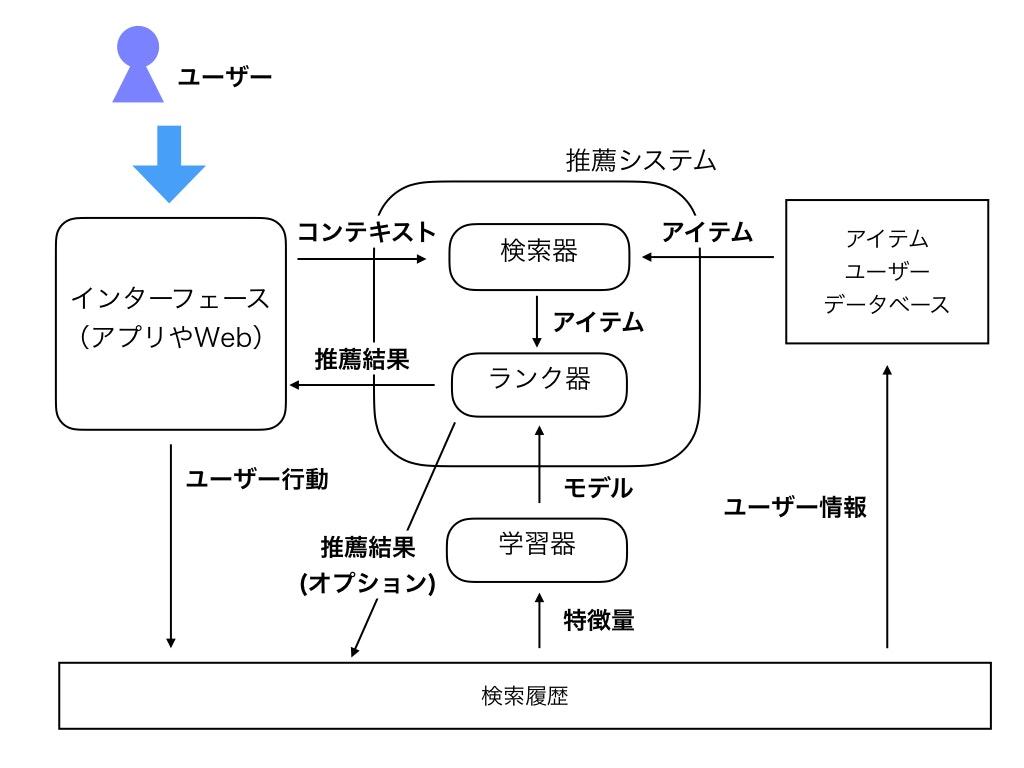
以下、それぞれの部品っぽいものをコンポーネントとして、どんな働きをするかというのと、実際にどんなアプリケーションで実現できるかというのを紹介していきます。
なお、インターフェースは検索の方で紹介しているので割愛します。
全体の流れ
もっとも大きな流れはインターフェースシステムから推薦システムにユーザーの行動情報をコンテクストとしてリクエストを送り、推薦結果であるアイテムリストを受け取るという部分です。
(「コンテクスト」という言葉は一般的に「推薦に到るまでのユーザーの行動」といった意味で使われることが多いですが、ここではアイテム情報、ユーザー行動、いわゆるコンテクストの3つをまとめてコンテクストとしていることにご注意ください。)
推薦システムの中には検索器とランク器があり、最初に検索器で粗くアイテムを取得し、ランク器でコンテクストに適した形のランキングに並び替えるという方法が良く行われています。
これは大量のアイテムに対して初めからランキングを行ってしまうと計算量が多くなってしまい、レスポンスタイムが遅くなったり計算リソースの枯渇に繋がってしまうためです。
ランク器は学習器によってモデル(ランキングのパラメータや、予測モデルなど)が作成されます。
学習器はユーザーの行動ログなどを元にモデルを作成するコンポーネントです。
検索器
ユーザーIDやアイテムID、または何らかの特徴量を元に関連するアイテムを一定数のサイズに絞ります。
このコンポーネントは(以前に紹介した)検索システムやキーバリューストアなどをベースに実現されます。
アイテム・ユーザーデータベースから何らかのクエリで問い合わせることができるような適切な形でアイテムを保持できるようにするアプリケーションが必要です。
また、データを保持するキーバリューストアは以下のようなものがあります。
- ソフトウェア(サーバー上に構築) ... redis、memcachedなど
- フルマネージド ... Amazon DynamoDB、Cloud Datastore
ランク器/学習器(Ranker/Trainer)
ランク器では検索器によって取り出したアイテムを並び替えます。
ランキングには事前に学習したモデルを元に並び替えが行われます。
実際に使われる技術
- 横断的に扱える技術
- Cloud ML Engine、Amazon SageMaker ... モデルの構築から管理デプロイまで一貫して行える
- ストレージ: モデルやデータの格納
- Amazon S3、Cloud Strage ... オブジェクトのストレージとして用いられる
- Dockerイメージをそのままモデルとすることもある
- データベース(大規模データの計算)
- モデル構築
- Pythonの技術スタック ... 現在広く使われているので一部を紹介
- scikit-learn ... 各種の機械学習ライブラリを用いることができる
- PyTorch ... Python用のディープラーニングライブラリ
- その他言語
- Pythonの技術スタック ... 現在広く使われているので一部を紹介
オンライン学習/オフライン学習
モデルの更新は1日に1回や管理者の都度更新(オフライン更新)であったり、ユーザーの行動が即座に反映されるオンライン更新であったりします。
それぞれ使われる技術が異なります。
データパイプライン+モデルの更新処理をどのように構築するかという問題であり、検索システムでどのようにインデックスを行うかという項目が参考になります。
オンライン学習を行う場合は、モデルによっては実現が難しいものもあるため、どのようなモデルを選択するかが非常に重要となります。
おわりに
推薦システムについてはまだ色々な形が生まれているので、これが正解というものはありません。
ですので色々なアーキテクチャを見ながら、自サービスにとって最適な形になるように試行錯誤が必要だと思います。
また、いくつかのコンポーネントは以前の検索システムで紹介したようなものが多かったと思います。
こうして見ると検索と推薦はやはり似ている部分が非常に多いですね。