はじめに
こんにちはrilmayerです。
この記事はアドベントカレンダー「Search&Discovery 全部俺」11日目の記事となります。
今日はよくある一般的な検索システムの構成について簡単に説明しつつ、それぞれのコンポーネントが何をやっているか、それぞれのコンポーネントを担う代表的なアプリケーションについて紹介したいと思います。
検索システムの構成
「AIアルゴリズムマーケティング 自動化のための機械学習」を参考にしていますが、以下のような形が一般的かなと思います。
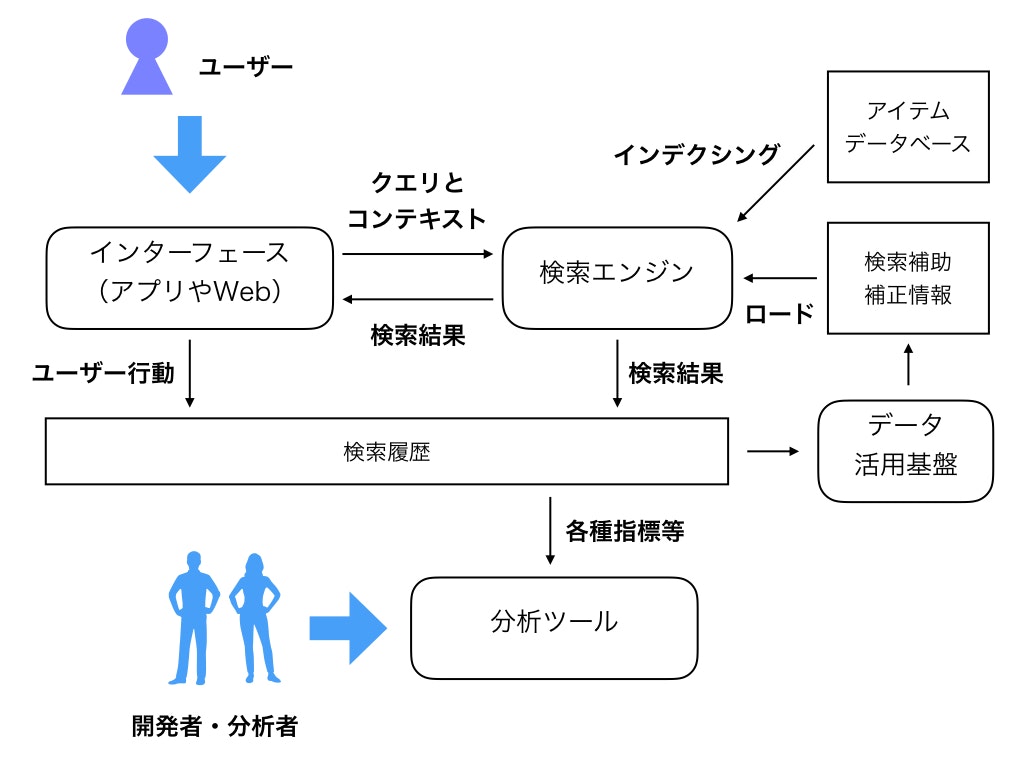
以下、それぞれの部品っぽいものをコンポーネントとして、どんな働きをするかというのと、実際にどんなアプリケーションで実現できるかというのを紹介していきます。
インターフェース
検索システムでユーザーが直接操作して結果を受け取る部分です。
例えば、Googleだと「検索窓のページ」と「検索結果一覧ページ」がインターフェースに当たります。
Googleの場合は検索結果一覧ページの中に「情報をまとめたカード」や「知事情報」等の複数の見せ方が存在しています。
インターフェースを実現する技術
ここはWebアプリだったり、スマホアプリだったり、デスクトップアプリだったりと色々あります。
UI(画面操作)に限らずCUI(文字入力操作)のインターフェースもありえます。
裏側の検索サーバーと通信ができれば、Javascriptなど(Webアプリ)、iOSなど(スマホアプリ)、シェルスクリプトなど(CUI)色々あります。
検索エンジン
ここが検索システムの心臓部です。
インターフェースで入力されたクエリを解釈して、インデックスされたアイテムから適切なアイテムを取得し並び替えてユーザーに提供します。
ランキングを最適化する場合も
検索エンジンを実現する技術
以下のような観点で有名な技術があります。
プログラムに組み込んで使うライブラリと、それ単体でほとんど全ての機能を賄う検索エンジンアプリケーションがあります。また、検索の結果をユーザー行動等の学習に応じて並び替えるランキングを行うためのライブラリなども利用することができます。
- 全文検索ライブラリ
- OSS全文検索エンジン
- Solr ... OSSの全文検索システム
- Elasticsearch ...Elastic社が中心になって開発が進められているOSSの全文検索システム
- Groonga ... オープンソースのカラムストア機能付き全文検索エンジン
- 検索エンジンアプリケーション
- Algolia ... 検索アプリケーションを提供しているWebアプリ。API等で利用できる
- Azure Cognitive Search ... Microsoftが提供する全文検索アプリケーション
ちなみに、ElasticsearchはAWSやAlibaba CloudなどでフルマネージドなSaaSとして提供されていたりします。
インデクシング
アイテムの更新頻度が低かったり、定期的にまとめて更新すれば良い場合バッチシステムなどが利用されます。
図書館など週に1度本が納入されるなどアイテム更新が決まっている場合などがこれに当たります。
また、リアルタイムの更新が必要検索システムの場合は逐次更新のため差分検知によるインデクシングや、データが追加されるたびにオンラインのインデクシングが必要です。
インデクシングを実現する技術
- バッチシステム
- 定期実行 ... crontab、kubernetes cron jobなど
- ワークフローエンジン ... Airflow(GCPだとCloud Composer)、Rundeckなど
- オンラインインデクシング
- ストリーミング処理 ... Apache Beamなど
- データパイプライン(クラウド) ... Cloud pub/sub+Cloud DataflowやAmazon Kinesisなど
- RDMSによるアドアン機能
アイテムデータベース
アイテム情報が入っているデータベースです。
こちらもインターフェース同様に様々な技術が用いられています。
ここでは紹介を省略します。
こちらのデータベースの種類などに関する記事がおすすめです。
https://engineer-club.jp/type-of-database
検索履歴
検索の履歴を管理するシステムです。
このシステムはデータを貯める「ストレージ」と逐次データをストレージに書き込む「データパイプライン」の2つのコンポーネントからなります。
検索履歴管理を実現する技術
- ストレージ
- データベースやファイルストレージが用いられますが、データの特性やクラウド活用の観点から、データベースとしてBigQueryやRedshift、ファイルストレージとしてCloud StrageやAmazon S3などが用いられることが多いです
- 実はElasticsearchは検索履歴等のストレージとして使うことも可能であり、よく使われています
- データパイプライン
- Fluentd ... データパイプライン用のライブラリ
- Amazon Kinesis ... リアルタイムデータのストリーム処理ができる
分析ツール
こちらも検索履歴と同様にパイプラインとストレージに分けられますが、分析ツールの場合通常これにBIツールと呼ばれる可視化ツールが用いられます。
また、分析を行う際に統計解析が行われたりもします。
分析ツールを実現する技術
- データパイプライン
- 基本的に検索履歴と同様です
- ストレージ
- 毎回計算し直すのが大変な分析などは途中集計の結果をストレージなどに保管します
- 分析ツール
データ活用基盤・検索補助補正情報
これらについて主に機械学習等による検索体験の向上を目指すコンポーネントです。
例えば、検索履歴を元に検索サジェストを行ったり、ユーザーの行動履歴を元によりユーザーにとって良いランキングを補助したり、インデクシングの際に重要な単語の重みを上げたりまたは不要な単語を取り除いたりといったことを行います。
そのため、作成したモデルやデータをロードして活用することができる検索エンジンを用意することが必要です。
データ活用基盤・検索補助補正情報を実現する技術
- 検索補助のためのデータ集約
- 各種データ集約アプリケーションなど
- 検索補正のための技術
- 各種機械学習ライブラリなど
おわりに
本日は検索エンジンを作っていく場合にどんな部品が必要になっていくかを考えてみました。
最後にはなりますが検索エンジンの構成で「これが絶対正解!」というものはありませんので、関わるサービスの特徴やコンポーネントのアプリ特性を把握しながら柔軟に構築していけると良いかもしれません。