はじめに
そろそろ「五等分の花嫁」も終盤に近づきつつある気がしています。
そこで、花嫁が三玖であることを証明してみようと思います。
今回は顔の画像のみを学習データとします。他のデータも使えるじゃんという意見は無視します。あと機械学習の推論は全く証明にならないという意見も無視します。
ライブラリは TensorFlow + Keras を利用します。

の画像に対してラベルを求めることを目標とします。
データセットを用意する
はじめはWEBからスクレイピングでデータセットを用意することを考えましたが、実際にやると漫画とアニメの画像が混じったり、二次創作の画像が混じったりして、必要な枚数を満たすのが大変で断念しました。
今回は漫画の画像を判別できれば良いので、漫画の画像から顔部分を抜き出してそれに手動でラベルをつけることにします。
lbpcascade_animeface.xmlを利用した顔範囲抽出
lbpcascade_animefaceというアニメイラストからの顔の部分を抽出するライブラリがあるのでこれを利用しました。
import cv2
import sys
import os.path
from pathlib import Path
cascade_file = "./lbpcascade_animeface.xml"
cascade = cv2.CascadeClassifier(cascade_file)
filename = "xxxxxxx.jpg"
image = cv2.imread(filename, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = cv2.equalizeHist(image)
faces = cascade.detectMultiScale(image,
scaleFactor = 1.01,
minNeighbors = 5,
minSize = (128, 128))
for j, (x, y, w, h) in enumerate(faces):
cv2.imwrite("./detect/{}.jpg".format(j), image[y:y+h, x:x+w])
学習データに合わせてcascade.detectMultiScaleのオプションを変えると良いです。正解ラベルを付与するために後で取捨選択は行うので多少誤検知を行うぐらいのパラメータで良いと思います。
特にminSizeはこれ以下の画像は切り取らないので注意してください。
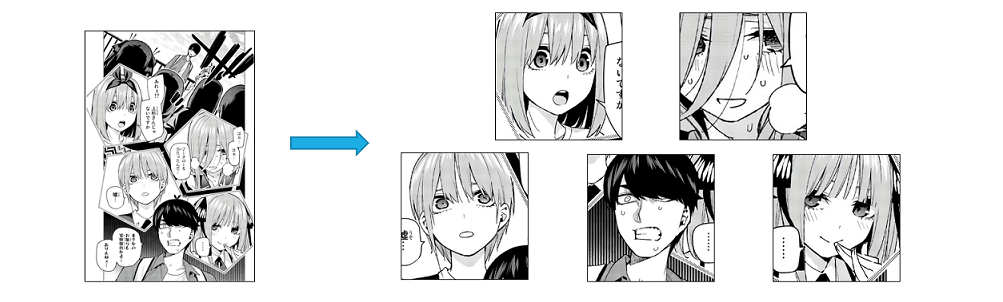
これで画像のように顔範囲を抜き出すことができました。
この時点で1~7巻のデータから2,627枚の画像が抽出できました。
ラベルを付ける(手動)
収集した画像には、上杉風太郎くんなどの顔やそもそも顔ではないのに切り取られてしまったものがあります。また、五つ子の中でもどのラベルかを正解ラベルとして付ける必要があります。当然これらのラベルはまだ自動でつけることはできないので、手動でラベルを付与します。
とはいえ、さすがに一つ一つ表示してラベルを作るのは大変なので、連続で画像を表示してキー入力でラベルを付与できるようなプログラムを作成して作業を簡略化しました。
下記のような感じで書けばOpenCVだけで表示&フォルダ分けができるかと思います。
image = cv2.imread(filepath)
cv2.imshow("image", image)
key = cv2.waitKey(0)
if key == ord("q"):
break
elif key == ord("1"):
shutil.copy(filepath, 'path/to/1/{}'.format(savename))
elif key == ord("2"):
shutil.copy(filepath, 'path/to/2/{}'.format(savename))
elif key == ord("3"):
shutil.copy(filepath, 'path/to/3/{}'.format(savename))
elif key == ord("4"):
shutil.copy(filepath, 'path/to/4/{}'.format(savename))
elif key == ord("5"):
shutil.copy(filepath, 'path/to/5/{}'.format(savename))
この時点でラベルが付いた1,449枚のデータセットができました。
さらに、この時点で各ラベル50枚の250枚をテストデータとして取り分けておきます。
データセットの水増しをする
実は先んじて学習を行ったのですが、期待した正解率を出すことはできませんでした。
そこで、画像を水増しして精度を上げることを試みました。
水増しの方法はいくつかありますが、今回はTensorFlowで利用できるAPIを使ってみました。
# 画像の読み込み
file = tf.read_file(filepath)
image = tf.image.decode_jpeg(file, channels=3)
# コントラストの調整
image = tf.image.random_contrast(image, lower=0.6, upper=1.6)
# トリミング
shape = cv2.imread(filepath).shape
image = tf.random_crop(p_image, [int(shape[1]/1.1), int(shape[0]/1.1), 1])
# 反転
image = image[:, ::-1]
元データが白黒の画像であるため彩度などの調整は行いません。

これで上記のような水増し画像が生成できました。
書きながら思いましたが、五つ子全員が左右対象なわけではないので反転処理は余計だったかもしれません。
これで10,791枚のデータセット(テストデータ除く)が用意できました。
学習する
それでは学習を行ってみます。
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, 3, 3, input_shape=SIZE+(1,), activation='relu', padding='same'),
tf.keras.layers.Conv2D(64, 3, 3, activation='relu', padding='same'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Conv2D(128, 3, 3, activation='relu', padding='same'),
tf.keras.layers.Conv2D(256, 3, 3, activation='relu', padding='same'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Conv2D(256, 3, 3, activation='relu', padding='same'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=EPOCH, batch_size = 5)
result = model.predict(x_test)
データセットの読み込みは省略します。入力の正規化は忘れないようにしましょう。
畳み込みを行った後で全結合しそのまま出力します。batch_sizeはPCのスペックがネックでこれ以上あげられませんでした。
全然関係ないですが、ラベルが5個の場合の出力は0~4で五つ子の名前と一つずれるので混乱します。
結果
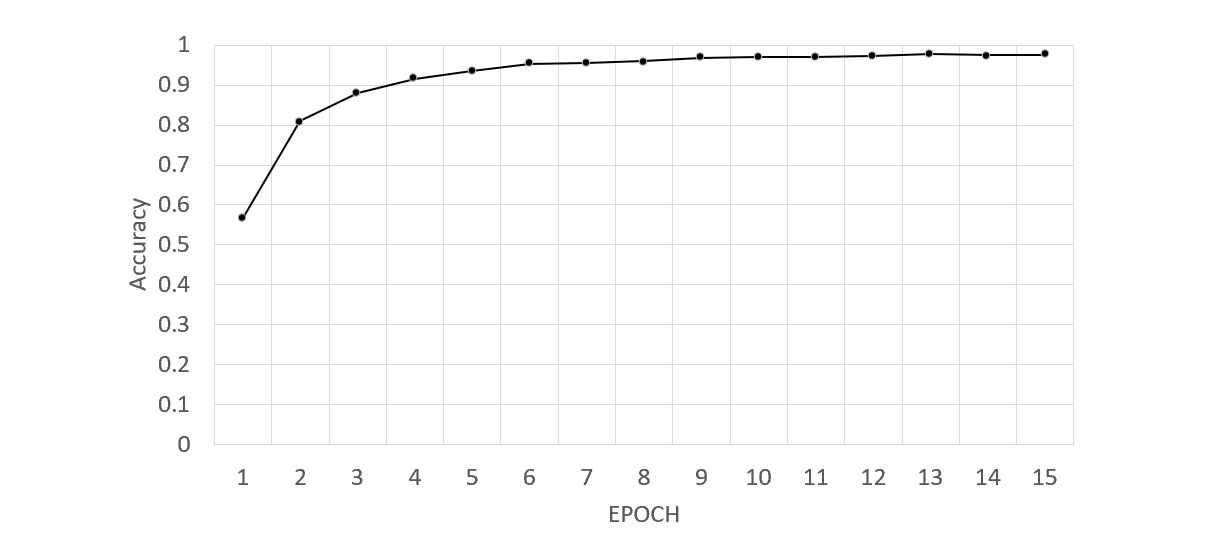
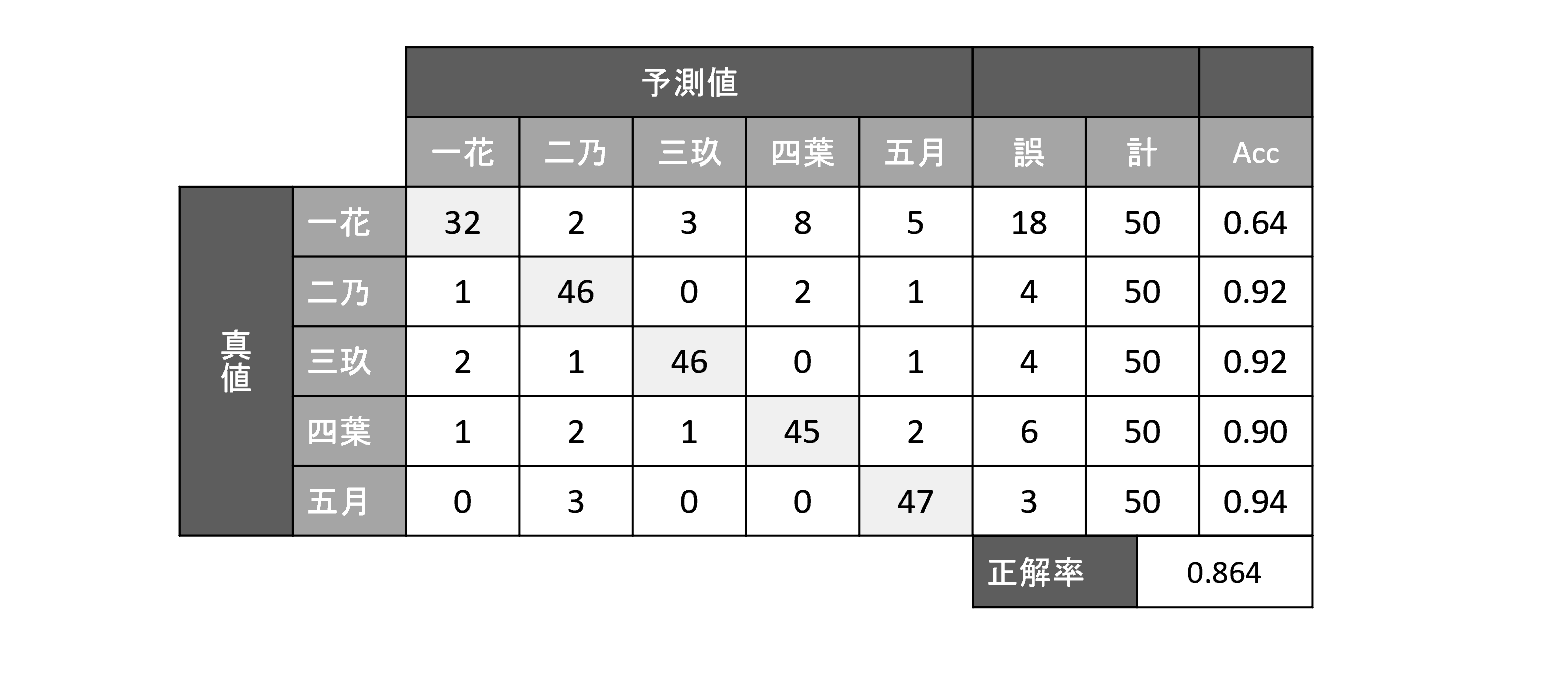
全体の正解率は86%ですね。手でラベルを付けているときに人間でも迷う場合はあったので、まだ伸ばせる余地はあるとは思いますがとりあえずこんなものではないかという感想です。
一花を他の子と推論していることが多いのが目立ちますね。髪留めやアクセサリーがないのはやはり判定しにくいのではないかとおもいます。
五つ子変装に対する上杉風太郎くんの正答率を考えても十分に戦える数字ではないでしょうか。
本題
本題に戻ります。
それでは、花嫁の画像を入力して誰と推定するのか見てみましょう。

生成したモデルに上の花嫁の画像を入力します。
花嫁は……

「🎉三玖🎉」でした。
(忖度なしで本当にこの結果でした)
実際の花嫁もおそらく三玖なので今回の学習はうまくいったようです。