この記事は MICIN Advent Calendar 2022 の14日目の記事です。
前回は原さんの医療におけるプロダクトづくりのチャレンジあるあるでした。
プラットフォームチーム所属の竹内です。
主にビデオ通話基盤の開発を行なっています。
MICINのプロダクトにはビデオ通話機能を持ったプロダクトが複数存在しますが、プロダクトごとにビデオ通話機能を開発するのは効率が悪くなります。
そのため、プラットフォームチームでは、ビデオ通話機能を共通基盤システムとして提供しています。
ビデオ通話のクライアント実装においては、複雑な非同期イベントのハンドリングが要求されます。
この問題に対して、手続き的な手法で対処しようとすると、イベントの発生順に依存したアルゴリズムになりがちです。
その結果、開発環境とステージング環境のネットワークの差異によって、数回に一回正常に動作しないということが起こります。
そういったことを何度か経験し、もっと宣言的に書く方法はないか模索していました。
そこで、今注目しているのがFRPです。
Functional Reactive Programming(関数型リアクティブプログラミング)とはプログラミングパラダイムの1つで、関数型プログラミングとリアクティブプログラミングの両方の特徴を持ちます。
一言でいうと、FRPでは関数合成によって入力に対する振舞としてプログラムを表現します。
FRPのプログラムは原則としてステートを持ちません。
しかし、ローカルストレージの読み書きやHTTP通信のステーフルロジックなど、副作用を生じることを避けられない場面も存在します。
このような外界とのやりとりを I/O(入出力) と呼びます。
アプリケーションを開発する上で、必ずしもFRPだけでプログラムが完結するわけではなく、他のパラダイムと併用することになります。
そのような場合も、FRPと他のパラダイムを分離し境界を設けることで、FRPのメリットを十分に享受できます。
まずは、関数型プログラミングについて紹介し、その後RxJSを利用したFRPの具体的な実践例を紹介します。
関数型プログラミングの作法
JavaScriptは関数型とオブジェクト指向の両方の機能を備えた言語です。
特に意識することなく、両者を使っているかもしれません。
オブジェクト指向プログラミングで出来上がるのは、オブジェクトに対する操作です。
一方、関数型プログラミングで出来上がるのは、宣言的に表現した式です。
これらの違いが分かると、より良いコードを書けるようになるはずです。
プログラムの副作用
皆さんはアプリケーションが期待通りに動作しないとき、何を試しますか?
おそらく、多くの方はアプリケーションの再起動を行うでしょう。
それでもダメならOSごと再起動を試すかもしれません。
つまり、我々は再起動することによって異常なステートがクリアされることを経験的に理解しています。
では、そもそもなぜ、そのようなひどい状態になるのでしょうか。
それは、プログラムがステートに対して意図しない副作用を与えているからです。
至る所で複雑にステート管理されたプログラムはもはや人の手には負えません。
副作用を与える原因の一つとして値の再代入が挙げられます。
var や let を使って変数を宣言すると、再代入が可能となります。
let a = 'Hello';
function foo() {
a = 'Hi';
}
foo();
console.log(a); // "Hi"
一方で、 const で宣言された変数は再代入されず、基本的には値が一定です。
const a = 'Hello';
function foo() {
a = 'Hi'; // TypeError: Assignment to constant variable.
}
foo();
console.log(a);
ただし、 const で宣言してもオブジェクトの場合、そのプロパティを上書きすることは出来てしまうため、注意が必要です。
const a = { key: 'Hello' };
function foo() {
a.key = 'Hi';
}
foo();
console.log(a.key); // "Hi"
処理の中で副作用を発生させず、同じ入力に対して同じ出力を返すような関数は純粋であると言われ、このような性質のことを参照透過性と言います。
// 参照透過性のない関数
let count = 0;
function nonTransparent() {
count += 1;
return count;
}
console.log(nonTransparent()); // 1
console.log(nonTransparent()); // 2
// 参照透過性のある関数
function transparent(count) {
return count + 1;
}
console.log(transparent(0)); // 1
console.log(transparent(0)); // 1
オブジェクト指向ではメンバ変数に副作用を与えて状態を保持させるセッターなどのメソッドが多用されます。
そのため、参照透過性のないコードになりがちで、プログラマーはオブジェクトの状態を意識しながらコードを書く必要があります。
コラム: リトライ処理を入れればいい?
再起動すれば元に戻るという発想は度々人々をリトライ処理の実装へと向かわせます。
原因分析をしないまま闇雲に「リトライ処理を入れてくれ」という類の発言には注意を払う必要があります。
「変数が未定義かどうか」で条件分岐してリトライして、値が出揃うのを待つというその場凌ぎを繰り返していてはコードが無駄に複雑化することは避けられません。
動作原理不明なフランケンシュタインのようなプログラムからは既存のコードを削除することができず、そのダークマターはどんどん膨張していきます。
過剰な防衛はせず、根本的な原因を明確化し、リトライ処理は最小限に収めましょう。
フォールトトレラントは結構ですが、耐える必要のないフォールトに寛容なシステムは堅牢とは言えません。
関数合成
通常、プログラムは複数のモジュールによって構成され、適切に分割されたモジュールは凝集度が高く、疎結合です。
関数型プログラミングでも、あるタスクを実行するために単一の関数が全責務を担うのではなく、複数の関数に分割し関心を分離します。
そして、分割した関数を合成することで、複雑なタスクを単純な関数の組み合わせで実現することが出来ます。
関数合成は元々数学的な概念で、学生時代に習った方もいらっしゃると思いますが、ここで簡単におさらいしてみましょう。
例えば、次のような集合 A, B, C と写像 f, g があります。

\displaylines{
f(x) = x + 1,\ g(x) = 2x^2のとき、合成関数は \\
\begin{eqnarray}
(g \circ f)(x) &=& g(f(x)) \\
&=& 2(x + 1)^2 \\
\end{eqnarray} \\
となる。 \\
A = \{1,2,3\}, a \in A,\ b \in B,\ c \in Cとすると、\\
\left\{
\begin{array}{l}
A = \{ a\ |\ 1,2,3 \} \\
B = \{ b\ |\ b = f(a) \} \\
C = \{ c\ |\ c = (g \circ f)(a) \}
\end{array}
\right.
}
これを手続き型プログラミングで表現すると、次のようになります。
const A = [1, 2, 3];
const B = [];
const C = [];
for (let i = 0; i <= A.length; i++) {
B.push(A[i] + 1);
C.push(2 * B[i] ** 2);
}
これを関数型プログラミングで表現すると、次のようになります。
const f = x => x + 1;
const g = x => 2 * x ** 2;
const A = [1, 2, 3];
const B = A.map(f);
const C = A.map(x => g(f(x)));
このように関数型では数学に近い形で表現できることが分かります。
C の変数宣言に着目してみると、手続き型では一番下まで読まないとどのような要素が格納されるのか分かりません。
一方、関数型では変数宣言の行を読むだけで、C は f と g の合成関数を A の各要素に適用した配列であることが分かります。
これが関数型が宣言的である所以です。
関数型の方が問題の本質を捉えており、バグの混入を防げそうです。
コラム: アロー関数はなぜ美しいのか?
JavaScriptの言語仕様は度々批判の的となりますが、アロー関数のシンタックスについては受け入れられているように感じます。
アロー関数のシンタックスが支持されるのは数学的意味を端的に矢印で表現できているからだと思います。
例えば、次のような集合 P = { 1, 2, 3 }, Q = { q | q = p², p ∈ P }、写像 f があります。
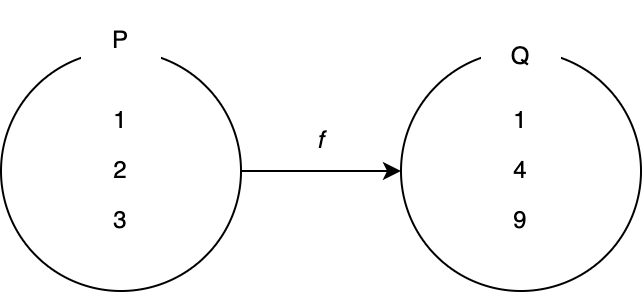
これをアロー関数を用いて表現すると次のようになります。
const P = [1, 2, 3];
const f = x => x ** 2;
const Q = P.map(f);
mapは日本語で写像という意味です。
つまり、集合のオブジェクト(Array)の写像というメソッド(map)にその振る舞いを決定する関数を引数として与える形です。
=> で左から右へ入力と出力の関係が分かりやすく表現されています。
アロー関数は関係ないですが、関数が写像に内包される構造も数学的で美しいです。
RxJSとは
RxJSはJavaScriptでリアクティブプログラミングを実現するためのライブラリです。
MicrosoftによってC#用に開発されたRx.NETというライブラリが元となっています。
複数の言語に移植されており、言語を跨いで統一的なAPIが実装されています。
RxJSを学んで、まず疑問に思うのが「で、これってどこで使うの?」という点ではないでしょうか。
UIのステート管理の問題であればReactやVueが十分実用的な答を提示していますし、非同期処理もPromiseを使えば大抵シンプルに表現できます。
要するに、「RxJSはオワコンなんじゃないか」、と。
私見ですが、基本的にはUIのステート管理はUIフレームワークに任せて、複雑な非同期イベントハンドリング(バッファリングやマージなど)が必要な場合に有用だと考えています。
コラム: FRP関連ライブラリ
もしも、UIの実装にもRxJSを使ってFRPを実践したい場合なら、Cycle.jsというフレームワークもあります。
Cycle.jsはFluxに課題を感じていた André Staltz 氏を中心として開発されました。
Node.jsでRxJSベースのサーバーアプリケーションを構築したいなら、Marble.jsというフレームワークがあります。
関数型プログラミングで利用されるユーティリティ関数を提供するライブラリ。
lodashと同様にユーティリティライブラリですが、設計思想が異なります。
lodashは比較的パフォーマンスを重視しているのに対して、RamdaはシンプルなAPIで副作用が生じないことを重視します。
RxJSよりも一貫性を重視したFRPライブラリ。
エラーハンドリングの手法も異なります。
速度と省メモリを重視した後発のリアクティブ・プログラミングライブラリ。
パイプ
ピュアなJavaScriptで関数合成を行うと、ネスト構造になってしまいます。
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const result = divideByThree(addOne(timesTwo(1)));
console.log(result); // 1
内側から外側へ解釈する必要があり、これは不自然で読みづらいです。
この問題に対して、メソッドチェーンは可読性に優れた方法です。
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const [result] = [1].map(timesTwo).map(addOne).map(divideByThree);
console.log(result); // 1
これで左から右へ順番に読むことが出来て、自然な順序で解釈が可能です。
しかし、4行目で不必要に配列化している点で、違和感があります。
メソッドというものは必然的にオブジェクトの型と密結合であるため、合成可能な関数に制約が生まれます。
例えば、次のようにチェーンの途中で型が変わる場合も、メソッドチェーンでは対応できません。
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const plus = (a: number, b: number) => a + b;
const [result] = [1, 2.5].map(timesTwo).map(addOne).reduce(plus).map(divideByThree); // Error: Property 'map' does not exist on type 'number'.
RxJSでは pipe を使って、値をObservableという一貫した型で扱うことが出来ます。
of という関数はObservable型のデータを静的に生成する関数です。
subscribe については次節で説明します。
import { of, map } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const observable = of(1).pipe(map(timesTwo), map(addOne), map(divideByThree));
observable.subscribe((result: number) => console.log(result)); // 1
途中で型が変わっても1、同じように書けます。
import { of, map, reduce } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const plus = (a: number, b: number) => a + b;
const observable = of(1, 2.5).pipe(map(timesTwo), map(addOne), reduce(plus), map(divideByThree));
observable.subscribe((result: number) => console.log(result)); // 3
Observableはこういった性質からモナドっぽいと言われます。
パイプを利用することで型と関数が疎結合になり、より柔軟な合成が可能となりました。
パイプラインの中の関数は引数の数と入出力の型が一致していれば、交換可能です。
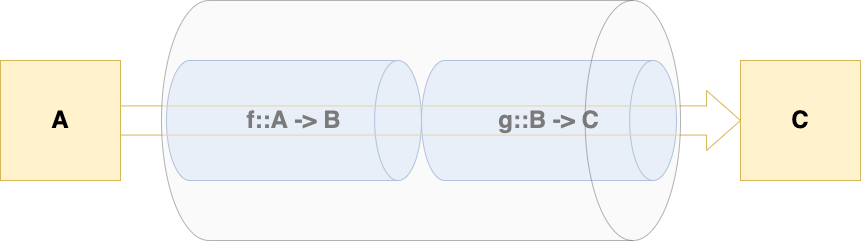
コラム: パイプライン演算子
F#にはパイプが演算子として標準的に存在します。
JavaScriptでもTC39のプロポーザルとして挙がっており、現在はStage2となっています。
当初はF#と同じ書き方 |> という演算子が提案されていました。
しかし、async/awaitとの仕様が競合したことから、Stage2ではHack Styleという仕様が採用されています。
ColdとHot
RxJSにはColdとHotという概念があります。
言葉で説明するより、コードを見てもらうのが早そうです。
Cold Observableは subscribe が呼び出されると一連の関数を実行します。
前節の例はCold Observableにあたります。
import { of, map } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const observable = of(1).pipe(map(timesTwo), map(addOne), map(divideByThree));
observable.subscribe((result: number) => console.log(result)); // 1
Hot Observableは subscribe が呼び出されて、次のイベントが発生した際に一連の関数を実行します。
import { fromEvent, map } from "rxjs";
fromEvent(document, "mousedown")
.pipe(map(({ clientX, clientY }) => clientX * clientY))
.subscribe((result: number) => console.log(result));
Observer
RxJSにおいて、ObserverはObservableが送る値を受け取るコンシューマーで、コールバック関数のセットです。
import { of, map, Observer } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const observable = of(1).pipe(map(timesTwo), map(addOne), map(divideByThree));
const observer: Observer<number> = {
next: (result: number) => console.log(result),
error: (message: string) => console.error(message),
complete: () => console.log("complete"),
};
observable.subscribe(observer); // 1, complete
通常は next が呼び出され、エラーが発生した場合は error が呼び出されます。
実行が完了したら最後に complete が呼び出されます。
各メソッドは省略可能で、次のように next のみでも正常に動作します。
import { of, map, Observer } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const observable = of(1).pipe(map(timesTwo), map(addOne), map(divideByThree));
const observer: Observer<number> = {
next: (result: number) => console.log(result),
};
observable.subscribe(observer); // 1
また、上記の next のみのサンプルは次のように更に省略して書くこともできます。
import { of, map, Observer } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const observable = of(1).pipe(map(timesTwo), map(addOne), map(divideByThree));
const observer = (result: number) => console.log(result)
observable.subscribe(observer); // 1
前節までのサンプルコードはこの形式ですね。
コラム: RxJSにおけるエラーハンドリング
FRPの例外処理においては、基本的にtry-catchやthrow文は使いません。
関数内でキャッチされ、戻り値に変換される分には問題ありませんが、FRPを正しく機能させるためには例外を外部に投げることは出来ません。
例外を投げると出口のパスが増えて参照透過性を失ってしまいます。
RxJSではエラーはObservableにラップされた値となっています。
throwError オペレーターや error メソッドによってエラーを送出します。
エラー発生時にObserverの error プロパティが省略されている場合、グローバルに例外が投げられます。
catchError オペレーターを利用して、エラーを抑制することも出来ます。
Subject
SubjectはObservableとObserverの両方の性質を持ちます。
Observableは subscribe で流れてくる値を取得できるのみですが、Subjectは任意のタイミングで next を呼び出して値を流すことができます。
import { Subject, map } from "rxjs";
const divideByThree = (x: number) => x / 3;
const addOne = (x: number) => x + 1;
const timesTwo = (x: number) => x * 2;
const subject = new Subject<number>();
subject
.pipe(map(timesTwo), map(addOne), map(divideByThree))
.subscribe(console.log);
subject.next(1); // 1
subject.next(2.5); // 2
様々な非同期通信
ここからはRxJSを使ったFRPの実践例として、様々な非同期通信のパターンを考えてみたいと思います。
順次HTTP通信
サービスAから必要なデータを取得してから、サービスBにリクエストするパターンです。
これはCold Observableの例です。
import { mergeMap } from "rxjs";
import { fromFetch } from "rxjs/fetch";
const getFrom = (baseUrl: string) => (path: string) =>
fromFetch(`${baseUrl}${path}`, {
selector: (response) => response.json(),
});
const serviceA = "http://localhost:8080";
const serviceB = "http://localhost:8081";
const getFromA = getFrom(serviceA);
const getFromB = getFrom(serviceB);
getFromA("/user")
.pipe(
mergeMap(({ barUserId }: { barUserId: number }) =>
getFromB(`/user/${barUserId}`)
)
)
.subscribe(console.log);
ちなみに、このように多項関数をネストされた単項関数に分割することをカリー化と言います。
カリー化した関数を部分適用することで関数の再利用性が高まります。
並列HTTP通信
サービスAとサービスBに並列的にリクエストするパターンです。
これもCold Observableの例です。
forkJoin を使うと、Promise.allのように複数のリクエストを並列処理できます。
import { forkJoin } from "rxjs";
import { fromFetch } from "rxjs/fetch";
const getFrom = (baseUrl: string) => (path: string) =>
fromFetch(`${baseUrl}${path}`, {
selector: (response) => response.json(),
});
const serviceA = "http://localhost:8080";
const serviceB = "http://localhost:8081";
const getFromA = getFrom(serviceA);
const getFromB = getFrom(serviceB);
forkJoin([getFromA("/users"), getFromB("/users")]).subscribe(console.log);
並列WebSocket通信
最後に応用的な例として、複数のサービスに依存したチャットルームのようなアプリケーションを考えてみます。
サービスAとサービスBに並列的なWebSocket通信を行うパターンで、これはSubjectの例です。(例としてはやや特殊な状況ですが、実際に直面した問題です。)
入室時に両方のサービスに JOIN イベントを送信し、入室処理が完了すると JOINED イベントを受信します。
他のユーザーが入室したことも JOINED イベントで受信されます。
このとき、自分自身の入室イベントだけでなく、通信相手の入室イベントもハンドリングする必要があり、下図のようにユーザーイベントとサービスが多対多の関係にあります。
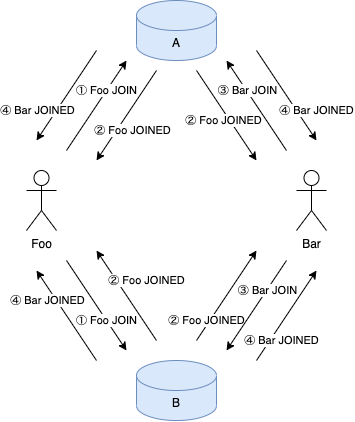
「ユーザーFooがサービスAとサービスBからJOINEDを受け取ったとき」というように、複数サービスから送られてくるイベント処理をユーザーごとにまとめて履行する必要があるとします。
最初に思いつくのがRxJSが提供している combineLatest というオペレーターを使う方法です。
combineLatest は複数のObservableから値を受け取るたびに最新の値のセットとして結合します。
公式ドキュメントのサンプルコードを掲載します。
import { timer, combineLatest } from 'rxjs';
const firstTimer = timer(0, 1000); // emit 0, 1, 2... after every second, starting from now
const secondTimer = timer(500, 1000); // emit 0, 1, 2... after every second, starting 0,5s from now
const combinedTimers = combineLatest([firstTimer, secondTimer]);
combinedTimers.subscribe(value => console.log(value));
// Logs
// [0, 0] after 0.5s
// [1, 0] after 1s
// [1, 1] after 1.5s
// [2, 1] after 2s
combineLatest を使って、2つのWebSocketメッセージを結合してみます。
気になると思うので先に補足しておくと、Observableを表すために変数名の最後に $ を付ける慣習があったりします。
import { combineLatest, filter, map } from "rxjs";
import { webSocket } from "rxjs/webSocket";
type Payload = {
uid: number;
};
type Message = {
type: "JOIN" | "JOINED";
payload: Payload;
};
const MY_UID = 123;
const wsA$ = webSocket<Message>("http://localhost:8080");
const wsB$ = webSocket<Message>("http://localhost:8081");
wsA$.next({ type: "JOIN", payload: { uid: MY_UID } });
wsB$.next({ type: "JOIN", payload: { uid: MY_UID } });
const joinedA$ = wsA$.pipe(filter(({ type }) => type === "JOINED"));
const joinedB$ = wsB$.pipe(filter(({ type }) => type === "JOINED"));
const joined$ = combineLatest([joinedA$, joinedB$]).pipe(
map(([msgA, msgB]) => ({ msgA, msgB }))
);
const localJoined$ = joined$.pipe(
filter(
({ msgA, msgB }) =>
msgA.payload.uid === MY_UID && msgB.payload.uid === MY_UID
)
);
const remoteJoined$ = joined$.pipe(
filter(
({ msgA, msgB }) =>
msgA.payload.uid !== MY_UID && msgB.payload.uid !== MY_UID
)
);
localJoined$.subscribe(({ msgA, msgB }) =>
console.log("Local Joined", msgA, msgB)
);
remoteJoined$.subscribe(({ msgA, msgB }) =>
console.log("Remote Joined", msgA, msgB)
);
一見、問題なさそうですし、一定の条件下では期待通り動作します。
しかし、combineLatest から取得できるメッセージのペアはあくまで最新メッセージのペアであって、2つのメッセージが同一ユーザーに関するものであることは保証されていません。
例えば、ユーザーFooとユーザーBarが同じタイミングで入室した際に、msgA はFooのイベントで、 msgB はBarのイベントであるという、あべこべな状況が起こり得ます。
そのとき、上記のコードでは正常にイベントを検知することが出来ません。
combineLatest ではメッセージの同一性が担保できないのであれば、メッセージ内のユーザーIDをキーとしてイベントを結合出来ると良さそうです。
WebSocketのようにいつやってくるか分からない双方向通信のイベントを結合するには、先に受信したイベントをステートとしてメモリ上に保持せざるを得ません。
しかし、本稿の冒頭でも述べた通りFRPでは基本的にステートを保持すべきではありません。
FRPのロジックからステートを分離するために、次のように innerJoin という combineLatest を拡張したカスタムオペレーターを作成します。(innerJoin はSQLのINNER JOIN句から着想を得ています。)
工夫した点としては、パフォーマンスを最適化するため、ステート管理にはMapを利用しています。2
また、二重ループ部分の可読性を高めるため、Generatorを利用しています。3
import { combineLatest, Observable, Subject } from 'rxjs';
type Relation = <T>(keyA: T, keyB: T) => boolean;
class State<T, U, V> {
source: Map<V, T>;
target: Map<V, U>;
constructor() {
this.source = new Map();
this.target = new Map();
}
setSource(key: V, val: T) {
this.source.set(key, val);
}
setTarget(key: V, val: U) {
this.target.set(key, val);
}
*join(relation: Relation): Generator<[T, U, V, V]> {
for (const [sKey, sVal] of this.source) {
for (const [tKey, tVal] of this.target) {
if (relation(sKey, tKey)) {
yield [sVal, tVal, sKey, tKey];
this.source.delete(sKey);
this.target.delete(tKey);
}
}
}
}
}
/**
* 内部結合
* @param target 結合先
* @param on 結合条件
*/
export const innerJoin =
<T, U, V = any>(
target: Observable<U>,
on: (a: T, b: U) => [V, V, Relation]
) =>
(source: Observable<T>) => {
const state = new State<T, U, V>();
const subject = new Subject<[T, U, V, V]>();
combineLatest([source, target]).subscribe((vals: [T, U]) => {
const [sourceKey, targetKey, relation] = on(...vals);
state.setSource(sourceKey, vals[0]);
state.setTarget(targetKey, vals[1]);
for (const nextVals of state.join(relation)) {
subject.next(nextVals);
}
});
return subject;
};
重要なことは次のようにFRPの世界で表示的意味論の合成性が損なわれないことです。
ステートを持っているのはFRPの外の世界であると捉えます。
import { filter, map } from "rxjs";
import { webSocket } from "rxjs/webSocket";
import { innerJoin } from "./inner-join";
type Payload = {
uid: number;
};
type Message = {
type: "JOIN" | "JOINED";
payload: Payload;
};
const MY_UID = 123;
const wsA$ = webSocket<Message>("http://localhost:8080");
const wsB$ = webSocket<Message>("http://localhost:8081");
wsA$.next({ type: "JOIN", payload: { uid: MY_UID } });
wsB$.next({ type: "JOIN", payload: { uid: MY_UID } });
const joinedA$ = wsA$.pipe(filter(({ type }) => type === "JOINED"));
const joinedB$ = wsB$.pipe(filter(({ type }) => type === "JOINED"));
const joined$ = joinedA$.pipe(
innerJoin(joinedB$, (a, b) => [
a.payload.uid,
b.payload.uid,
(keyA, keyB) => keyA === keyB,
]),
map(([msgA, msgB, uid]) => ({ msgA, msgB, uid }))
);
const localJoined$ = joined$.pipe(filter(({ uid }) => uid === MY_UID));
const remoteJoined$ = joined$.pipe(filter(({ uid }) => uid !== MY_UID));
localJoined$.subscribe(({ msgA, msgB }) =>
console.log("Local Joined", msgA, msgB)
);
remoteJoined$.subscribe(({ msgA, msgB }) =>
console.log("Remote Joined", msgA, msgB)
);
これで、メッセージの順番が入れ替わっても正常に動作するようになりました。
オペレーター自体は純粋でなくとも、オペレーターに渡される関数は純粋であることで、FRPロジック内に副作用による不具合が含まれていないことが保証されます。
カスタムオペレーターは汎用的に作り過ぎると必要以上に技巧的になり、具体的に作り過ぎると再利用性が損なわれるので、さじ加減がなかなか難しいですね。
Marble Test
FRPロジックのユニットテストは容易で、パイプラインに組み込まれた関数について入出力のテストをすれば十分です。
副作用の考慮は必要ありませんし、わざわざユニットテストを書く必要もない場合も多いでしょう。
一方、カスタムオペレーターに対してはRxJSが提供するMarble Testというユニークな仕組みを使ってテストを書くことが出来ます。
Marble DiagramというDSLで対象のObservableの振る舞いを視覚的に表現します。
簡単な例を次に示します。
import { combineLatest } from 'rxjs';
import { TestScheduler } from 'rxjs/testing';
describe('combineLatest', () => {
it('should be sum of the set', () => {
const scheduler = new TestScheduler((actual, expected) =>
expect(actual).toEqual(expected)
);
scheduler.run(({ hot, expectObservable }) => {
const t1 = hot(' a----b-----c---|', { a: 1, b: 2, c: 3 });
const t2 = hot(' -----e------f--------|', { e: 1, f: 2 });
const t3 = hot(' -------------h-----i---------|', { h: 1, i: 2 });
const expected = '-------------y-----z---------|';
const combined = combineLatest(t1, t2, t3, (a, b, c) => a + b + c);
expectObservable(combined).toBe(expected, { y: 6, z: 7 });
});
});
});
このアスキーアートのような記法を初めて見る方は面食らうと思います。
左から右にフレームという単位で仮想的な時間が流れていると考えてください。
各字には次のような意味があります。
-
アルファベット: Observable -
スペース: 垂直位置を合わせて見やすくするためのフィラー -
-: 1フレーム経過 -
|: ストリームの終了
これはHot Observableを利用したテストで、hot関数の第一引数にMarble Diagramが渡されています。
hot関数の第二引数に渡されているのが、各アルファベットにバインドされる値です。
他にもシンタックスはありますが、長くなるためここでは割愛します。
これで、イベント発生順の違いによる振る舞いのテストも容易です。
副作用がカスタムオペレーターに閉じられていることで、集中的に効果的なテストが可能となります。
おわりに
ここまで読んでいただき、ありがとうございます。
FRPの雰囲気をなんとなくご理解いただけたでしょうか?
当初はステートを一切持たずにアプリケーションを実装することが本当に可能なのか、という疑問がありました。
「I/Oを分離する」というコンセプトを理解することで、FRPが机上の空論ではなく、現実的な解であることが確信に変わってきました。
まだまだ勉強中の身ですが、複雑な非同期処理を要するアプリケーションの実装において、大きな可能性を感じることが出来ました。
なんとなくRxJSを使うのではなく、FRPを意識しながら、更なる実践を繰り返して理解を深めていきたいと思います。
圏論と型の関係などについても言及したかったのですが、記事に書くほど理解が及んでいないため、次の機会にしたいと思います。
参考資料
- オペレーターが機能別・重要度別に分類されていて公式リファレンスより探しやすい
- サンプルコードがわかりやすい
- 各オペレーターの違いがビジュアルで分かりやすく表現されている
- Illustrated RxJSというサイトにもっと豊富なコンテンツがあるが、お値段が高い
- 用語の定義がまとまっている公式ドキュメント
- リクルートのブログ記事
- wakamshaさんがいくつかFRPの記事を書いている
- 前半部分のリストモナドの説明が分かりやすい
- 何となくモナドの雰囲気がJavaScriptで分かる
- モナドの記事の作者と同じ方の著作
- 賛否両論ありますが、個人的には示唆的な内容も多かった
- FRPとは何か、具体的に書かれている
- Javaで書かれてあるが、Javaが分からなくてもサンプルコードは読める
- RxJSについても少しだけ書かれている
- JavaScriptで関数型プログラミング
- RxJSについても少しだけ書かれている
MICINではメンバーを大募集しています。
「とりあえず話を聞いてみたい」でも大歓迎ですので、お気軽にご応募ください!
MICIN採用ページ:MICIN 採用情報