はじめに
AIモデルを一度作ってみたかったので、
WSL2環境でPyTorchを使って「手書き数字を認識するAIモデル」を動かしてみました。
モデル構築から推論(予測)まで、一通りの流れをまとめています。
初心者視点での備忘録です。
環境
- OS: Windows 11 + WSL2 (Ubuntu)
- Python: 3.x 系
- PyTorch: 2.x 系
- GPU: なし(CPU環境)
ステップ①:WSL2での準備
① Ubuntu を開いて、pip と Python を最新化
sudo apt update && sudo apt upgrade -y
sudo apt install python3-pip -y
python3 -m pip install --upgrade pip
② PyTorch のインストール
GPUがない環境なので、今回はCPU版をインストール。
pip install torch torchvision torchaudio
GPU対応マシンの場合は以下。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CUDA対応チェックは以下で確認できます。
nvidia-smi
③ インストール確認
python3 -c "import torch; print(torch.__version__, torch.cuda.is_available())"
出力例:
2.4.1 False
TrueならGPU利用可、Falseでも問題なし。
ステップ②:動くAIモデルを実行
以下を mnist.py として保存して実行。
python3 mnist.py
内容:
import torch
## nnはニューラルネットワークの略
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# データ準備
transform = transforms.ToTensor()
## MNISTは手書き文字の画像データセット
train_data = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
# モデル定義
model = nn.Sequential(
## 画像(28×28の数字)を1列に並べる
nn.Flatten(),
## 重み付き変換
### 数字の形から〇〇っぽい特徴を拾うイメージ
nn.Linear(28*28, 128),
## マイナスをすべて0にする
### ノイズ除去
nn.ReLU(),
## 最終判定
nn.Linear(128, 10)
)
# 学習設定
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学習ループ
for epoch in range(3): # 短めに3エポックだけ
for images, labels in train_loader:
preds = model(images)
loss = criterion(preds, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}: loss={loss.item():.4f}")
print("学習完了!")
torch.save(model.state_dict(), "mnist_model.pth")
出力例:
Epoch 1: loss=0.0838
Epoch 2: loss=0.0917
Epoch 3: loss=0.0348
学習完了!
-
data/フォルダにMNIST(手書き数字データ)が自動ダウンロードされる -
lossが減少していれば学習成功
ステップ③:自分で描いた数字を予測させる
① 画像を準備
条件:
- 白背景に黒文字
- サイズ 28×28 px
- PNG形式
例(自作した画像):
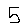
② 推論スクリプト(predict.py)
import torch
import torch.nn as nn
from torchvision import transforms
from PIL import Image, ImageOps
# モデル構築
model = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
# 学習済みモデルを読み込み
model.load_state_dict(torch.load("mnist_model.pth", weights_only=True))
model.eval()
# 前処理
transform = transforms.Compose([
transforms.Grayscale(),
transforms.Resize((28, 28)), # サイズをMNISTと合わせる
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
img_path = "my_digit.png"
img = Image.open(img_path)
img = ImageOps.invert(img.convert("L")) # ④ 白黒反転後の再実行時に追加
img_tensor = transform(img).unsqueeze(0)
# 推論
with torch.no_grad():
outputs = model(img_tensor)
predicted = torch.argmax(outputs, 1)
print(f"予測された数字は → {predicted.item()} です!")
③ 実行結果
$ python3 predict.py
予測された数字は → 3 です!
ChatGPTに画像を確認してもらうと「5」と認識されていたため、
学習データ(MNIST)が「黒地に白文字」である点に気づきました。
④ 白黒反転後の再実行
python3 predict.py
結果:
予測された数字は → 4 です!
精度はまだ低めですが、学習データとの形式差を理解する良いきっかけになりました。
まとめ
| 概念 | 内容 |
|---|---|
| 学習 | AIがデータからルールを学ぶ |
| 推論(予測) | 学んだルールを使って新しい入力に答える |
| モデルの保存/読み込み | 学習結果を再利用できる |
おわりに
PyTorchを実際に動かしてみると、
AIが「データを見て学び、答えを出す」流れがよく理解できました。
今回は単純なモデルでしたが、
次はWebアプリ連携などを試して、もう少し“AIっぽい”ものを作ってみたいです。