はじめに#
深層学習で動物の身体をトラッキングするdeeplabcutをgoogle colaboratoryで走らせます。マニュアルはこちら。

※Marvinに日本語解説が出ています→
ディープラーニングによるマーカーレス動物追跡:様々な実験動物で利用可能なDeepLabCut
トラッキングの結果の動画を以下で見ることができます。
https://www.youtube.com/watch?v=-SqlNx7wr0w
https://www.youtube.com/watch?v=Mv6wdF9Jt6k
https://www.youtube.com/watch?v=GFLGUO0wDIw
Deeplabcutは革命的なツールで、少なくとも神経科学の運動野・体性感覚野の業界では大騒ぎになっています。日本でもかなり多くの人が使っているはずです。Userがやるのはラベリングだけなので、本来はもっとずっと簡単に使えるはずです(いずれそうしたプラットフォームも整うと思います)が、現状では環境構築がやや面倒です。ここでは普通の人が持っている普通のラップトップの空きスペースと無料のGoogle colaboratoryを使ってDeeplabcut(バージョン2.0.4)を走らせる方法をざっと説明します。
ラベリング用の環境構築#
まず環境構築はここを参考にします。
ラベリングはgoogle colaboratoryではできないのでローカルにDeepLabCut用のPython環境を構築する必要がありました。Windows10+Anacondaで構築しようとするとNumpyのバージョン関連等よくわからないエラーが続出して数日費やしましたが解決しませんでした。このエラーはDeepLabCutのSlack(このSlackはMackenzie Mathisの承認が必要)でも報告されていますのでそのうち解決すると思いますが諦めてUbuntuを使うことにしました。ラップトップに100Gbのパーティションを作ってデュアルブートします。バージョンはお勧めされているUbuntu16.04 LTSです。ラベリングはどんなコンピュータを使っても大丈夫です。
Ubuntuを立ち上げて、Anacondaをインストールします。Terminalを開いてPython3.6の仮想環境を構築します。
conda create -n <nameyourenvironment> python=3.6
source activate <nameyourenvironment>
その後仮想環境上でdeeplabcutをpip installします。
pip install deeplabcut
さらにwxPython(pythonからラベルのために使うGUI)をpip installします。
pip install https://extras.wxpython.org/wxPython4/extras/linux/gtk3/ubuntu-16.04/wxPython-4.0.3-cp36-cp36m-linux_x86_64.whl
ここまで来たら最後にtensorflowをインストールします。ローカルでは訓練しないのでGPU環境は必要ありません。したがってこれだけでOKです。
pip install --ignore-installed tensorflow==1.10
何かエラーメッセージが出ていましたが適当に対処します。
ipythonを開いて、
import deeplabcut
これでエラーメッセージが出なければOKです。
動画の前処理#
どんな動画でも構いませんが、コーデックの問題でうまく処理されない可能性があります。私はXMedia Recordで映像だけのRaw video(AVI)に変換したのちImageJで確認しながら必要なフレーム、場所をクロップし、AVI(JPEG)で保存します。ちなみに私の環境ではAVI(PNG)だとエラーが出ました。
動画は、120 x 160 pix, 約10万フレームのグレースケールで、だいたい300MBくらいです。これをGoogle driveに保存します。Google driveはタダでも15Gb使えますが、訓練時に10Gbくらいかそれ以上費やすようでしたので200GBまで容量を増やしました。費用はだいたい3ドル/月くらいです。ゴミ箱に訓練途中のデータがたまっていくので定期的にごみ箱を空にする必要があります。
ここからはUbuntuマシーンで行います。まずGoogle driveから前処理した動画をダウンロードし、Ubuntuマシン上でのパスをチェックしてください。
ラベリングはMackenzie Mathisのこの動画を見るとわかりやすいと思います。一応ざっと説明します。
仮想環境をActivateして、ipython上でimport deeplabcutしたのちに実行するのはたったの4行です。
deeplabcut.create_new_project('日付','名前',['ファイル名.avi'])
path_config = "Generated の後のconfig.yamlのパス"
deeplabcut.extract_frames(path_config, 'automatic', 'kmeans')
deeplabcut.label_frames(path_config)
私はそれぞれの動画に対して100枚くらいラベルしています。config.yamlでラベルの枚数とターゲットの数を指定することができます(動画に説明があります)。
deeplabcut.extract_framesを実行する直前に、path_configで指定したconfig.yamlを開いて、ターゲットの名前とラベルの数を変更し、再度保存します。
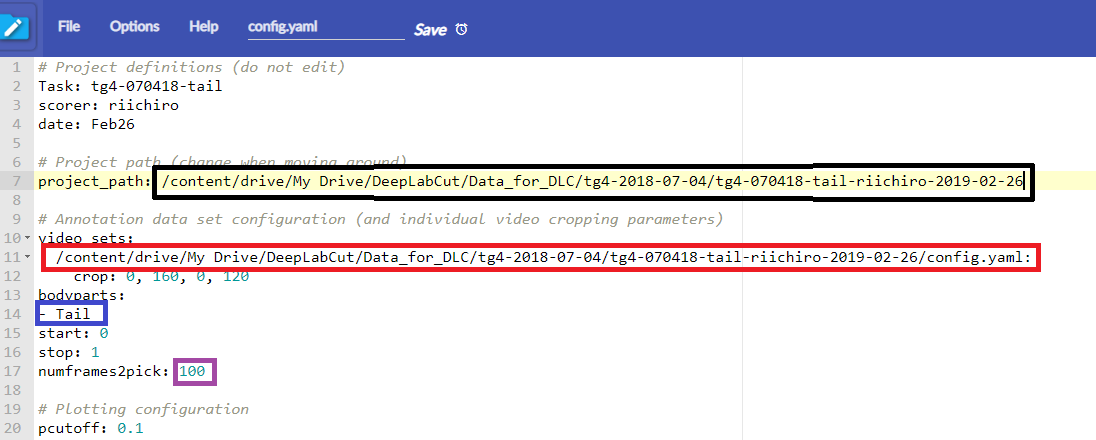
デフォルトだと、4つのターゲット、20枚のラベル数で自動的にラベル用のフレームが指定されますが、ここでは1つのターゲットの名前をTailにして(青)、ラベル数を100にしています(紫)。このファイル上のパスはUbuntu上で変更する必要はありません。あとでGoogleDrive上で変更しますので今は無視してください。
右クリックでサクサクラベリングしていきます。最後にSaveボタンを押したら終了です。
※ここでラベルの位置が保存されたh5ファイルがUbuntuだと出るのですが、Windows10でやったときはどうしてもこれが出ませんでした。
さて、ラベリングが終わったら出力された4つのFolder(dlc-model, laveled-data, training-datasets, videos)とconfig.yamlをGoogleDriveの新しいフォルダにコピーします。この後はgoogle colaboratoryとGoogleDriveを使った作業ですので、Ubuntuである必要はありません。私はこれ以降は通常使用のWindowsマシンのブラウザ上で処理しています。もちろんWindowsマシンもGPUは要りません。
GoogleColabのGPUを使って訓練#
google colaboratoryのGPUを使いたいので、これを利用します。
この動画がとても分かりやすいですが、一応説明します。
最初の数行は無視して、「Link your Google Drive」まで行きます。GoogleDriveとgoogle colaboratoryを関連付けるために
from google.colab import drive
drive.mount('/content/drive')
を実行します。パスワードをコピーして□にペーストします。マウントできたら、deeplabcut等を!pip installしていきます。途中でランタイムを再開する必要がある場合はそうします。
import deeplabcut
まで来てエラーが出なければOKです。
次にパスを設定します。
path_config_file = '/content/drive/My Drive/DeepLabCut/Reaching-Mackenzie-2018-08-30/config.yaml'
のところですが、ここは自分のパスに変える必要があります。Ubuntu上で作ったconfig.yamlのパスを使います。
さて、このconfig.yamlですが、この中にdeeplabcutが参照するパスの情報が2つ入っていますので、これを修正するためにconfig.yamlをGoogleDriveから開きます。Anyfile NotepadというChrome上のアプリを使ってyamlファイルを編集しています(あんまり使いやすくないですが)。もう一度同じ写真を貼ります。
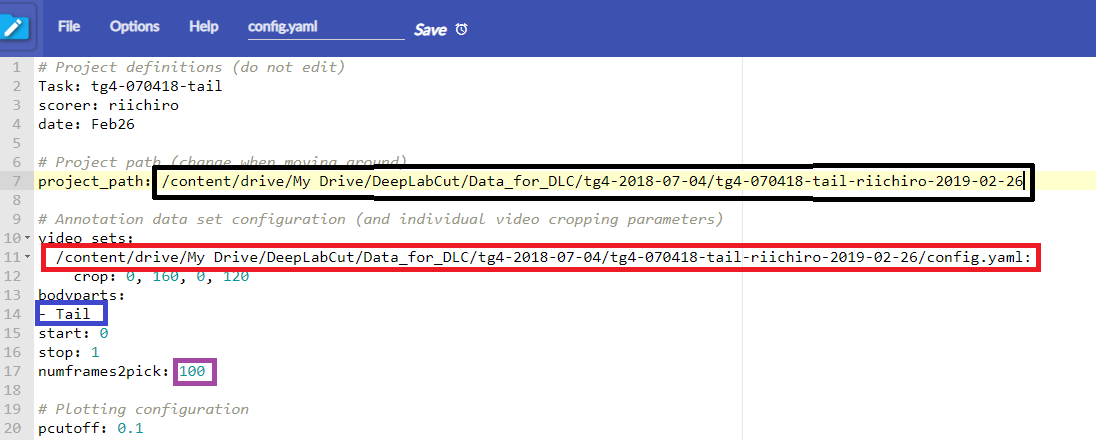
google colaboratoryの左パネルの右上にあるFileからあたらしく作った4つのフォルダとconfig.yamlを置いたフォルダを探し、右クリックでパスをコピーして、config.yaml内にある二つのフォルダ名のうち一つ目(黒)を置き換えます。さらにvideosフォルダ内のaviファイルのパスをコピーし、config.yaml内のもう一つのパス(赤)を置き換えます。これでGoogleColabがGoogleDriveからフォルダと動画にアクセスできるようになりました。

訓練データを作って、
deeplabcut.create_training_dataset(path_config_file)
訓練を開始します。
deeplabcut.train_network(path_config_file, shuffle=1, displayiters=10,saveiters=500)

訓練では、500回繰り返すたびに新しいネットワークモデルがGoogleDrive上に保存されます。iteration: の次に来る数字がこの繰り返し数です。20万回くらい繰り返すとだいたいうまくいくようですが、google colaboratoryは油断すると途中で止まってしまいますので注意しましょう。私の場合は1万回くらいでもうまくいくものと50万回でもうまくいかない動画があります。平均10万回くらいでしょうか。体感ですが3時間くらいかな。lossが減ってきて、だいたいいいかなと思ったら、強制終了ボタンを押します。うまくいかないと言っても人間が見ても難しいと思えるような動画でのミスであることがほとんどです。印象ですが、トラッキングの精度は非常に高く、隔世の感があります。
さて、あとは順番に実行して結果を見るだけですが、ビデオのパスを自分のAVIファイルのパスに修正するのだけ忘れないようにしてください。
videofile_path = ['/content/drive/My Drive/DeepLabCut/examples/Reaching-Mackenzie-2018-08-30/videos/MovieS2_Perturbation_noLaser_compressed.avi'] #Enter the list of videos to analyze.
修正したら順番に実行します。このあたりなぜかよくフリーズするのですが、結果はGoogleDriveに保存されていることが多いです。中断しても途中から再開できます。ただし、再開するときは再度Diskをマウントしたりdeeplabcutをpip install したりしないといけません。
出力を確認する#
Create labeled videoを実行すると、ラベル付きのMPEG動画がGoogleDriveのvideosフォルダのもとに作られます。また、座標のデータもvideosフォルダの"XXX.h5"に格納されています。Matlabで開いて解析するには、Matlab上で
data=h5read('ファイル名.h5','/df_with_missing/table');
などとすると取り出せます。
うまくいかなかった場合、再度ラベルを付けなおして訓練しなおすオプションがありますが、それはまたの機会に書きます。
最後にもう一度DeepLabCutで出力されたデモ動画を貼っておきます。
https://www.youtube.com/watch?v=-SqlNx7wr0w
https://www.youtube.com/watch?v=Mv6wdF9Jt6k
https://www.youtube.com/watch?v=GFLGUO0wDIw
追記(1) Colaboratoryを複数同時に使う#
Colaboratoryはブラウザ上で走りますので2つ以上同時に使えます。ただし、アカウント1つにつきメモリの制限があって、Deeplabcutの訓練は途中でメモリオーバーで停止します。そこでGoogleアカウントを2つ使うのはどうでしょうか。データをGoogleDriveで共有してそれぞれのアカウントでColaboratoryを開き、独立に実行してみると、少なくとも2つのGPUマシンを並列して使うことができることがわかりました。GoogleDriveの有料の追加容量200Gbに対し、Family共有設定をしていたので、特にDriveの方の容量を気にすることなく2つ同時に走らせることができました。スピードも見た目ではそれほど変わらないようです。したがって、このやり方でGPUマシンをいくつか同時に使うことができるようです。
追記 (2)
データファイルの解析の際、
deeplabcut.analyze_videos(path_config_file,videofile_path, save_as_csv=True)
などのオプションをつかえば、Excel やGoogle スプレッドシートにとりこめる、CSV形式で結果を取り出すことができます。