はじめに
みなさん、サービスの運用監視してますか?
私はソフトウェアエンジニアで、日常業務では監視ツールはメインでは扱っておらず、サービスに障害が発生した場合にSlackで通知を受けたり、原因調査のためにログ解析する程度です。
一般的に、予算が潤沢なプロジェクトであれば、Datadog、New Relic、Splunkなどの商用監視サービスを惜しげもなく使えるとは思います。ただ、サービスの立ち上げ初期など監視にそこまでコストをかけられない場合、OSSを利用してサービス監視を行うこともあるでしょう。
今回、所属会社でOSS「Prometheus」勉強会を開催した際に調査した情報を、みなさまのご参考までに共有いたします。
前提条件
本記事は、以下について概要レベルの知識を有している読者を想定しています。
- Webアプリケーション開発
- Docker環境構築方法
- Slack APIの発行方法
- Gitコマンドの使い方
本記事で紹介する環境構築は、以下の環境で行いました。
- Windows11 WSL2(Ubuntu 22.04.5 LTS)
- Docker version 27.5.1
- Docker Compose version v2.34.0
本記事では、Prometheusによるモニタリングの中でも、外形監視に焦点を当てて紹介します。
スロークエリやエラーレート、短命ジョブのモニタリングについては、以下の記事を参照してください。
Prometheus + Grafana で Webサービス監視環境を構築する - スロークエリ・エラーレート監視編 -
Prometheus + Grafana で Webサービス監視環境を構築する - 短命ジョブ監視編 -
Prometheus + Grafana で Webサービス監視環境を構築する - クライアントライブラリ監視編 -
解説
最初に、モニタリングやPrometheusについての概要について説明し、その後で監視環境の構築方法について説明します。
モニタリングについて
モニタリングには、以下の3つの要素が存在します。
| # | 要素名 | 目的 | 主な監視項目 | 代表的な製品 |
|---|---|---|---|---|
| 1 | メトリクス | 傾向の把握。現在発生していることをリアルタイムに確認する。 | CPU使用率, リクエスト数 | Prometheus, Zabbix |
| 2 | ログ | 詳細な事実確認。すでに発生した事象について、事後に原因を確認する。 | syslog, アクセスログ | ELK Stack, Fluentd |
| 3 | トレース | サービスのボトルネックの発見。どのサービスのどの部分に問題があるかを確認する。 | マイクロサービス間の通信フロー, 呼び出し順序・依存関係 | Datadog, Splunk |
外形監視について
外形監視とは、ユーザー視点でサービスやシステムの「外側」からアクセスし、正常に動作しているかを定期的に確認する方法です。
HTTPリクエストやPing通信などを使い、Webサイトの応答速度やステータスコード、接続可否をチェックします。
実際の利用者に近い観点で問題を早期発見できるのが特徴です。
今回は、後述する外形監視用のExporterからWebサービスに対して定期的にリクエストを送り、サービス生存確認や応答速度の計測を行います。
Prometheusについて
Prometheusは、Kubernetes環境のデファクトスタンダード監視基盤として、多くの企業やプロジェクトで採用されています。
Prometheusの特徴を以下に挙げます。
- プル型(scrape型)でメトリクスを収集
- 時系列データベース(TSDB)を内蔵
- シンプルなクエリ言語(PromQL)
- アラート管理機能(Alertmanager連携)
監視ツールの中には、監視対象のサーバー上の監視エージェントから送りつけられるメトリクスを収集するプッシュ型のツールもありますが、PrometheusはExporterと呼ばれる監視エージェントが公開するHTTPのエンドポイントに対して定期的にリクエストを送って、自らメトリクスを収集するプル型のツールです。
CPU使用率やエラーレートなどの数値データを時系列に保持しているため、観測点間での数値の変化量やばらつきについてPromQLを使って分析できます。
また、Prometheus自体はアラートを検知するだけで、外部へのアラート通知機能を持っていません。予め定義していたメトリクスの閾値を超えた場合は、アラート通知機能を持つOSSのAlertmanagerに対してAPI連携します。
Grafanaについて
Prometheus自体にも標準のWebUIが用意されていますが、単一メトリクスのグラフ表示しかできないなどの制約もあるため、多彩なビジュアライゼーションやダッシュボード機能を持つOSSのGrafanaと組み合わせて使うことが多いです。
単純なグラフ表示だけではなく、ヒートマップやゲージなどでメトリクスを可視化できます。
また、PrometheusのExporter用の公式ダッシュボードも用意されています。
監視環境の構成図
今回構築する監視環境の構成図は以下の通りです。

監視環境のDockerコンテナについて
監視環境はすべてDockerコンテナで構成されます。各コンテナの役割は以下の通りです。
| # | コンテナ名 | 役割 |
|---|---|---|
| 1 | prometheus | Prometheus 本体 |
| 2 | grafana | Visualization の Grafana |
| 3 | nginx_server | Nginx Web Server |
| 4 | nodejs_webapp | Node.js App Server |
| 5 | postgres_server | PostgreSQL DB Server |
| 6 | pushgateway | Pushgateway。短命JOBがメトリクスをPushする。 |
| 7 | alertmanager | Alertmanager。Prometheusから受信したアラートを通知先に送信する。 |
| 8 | node_exporter | ノードのCUP使用率等のメトリクスを収集する。 |
| 9 | nginx_exporter | Nginxの接続数等を収集する。 |
| 10 | nginx_log_exporter | Nginxのアクセスログをもとにステータスコード等のメトリクスを収集する。 |
| 11 | postgres_exporter | PostgreSQLのスロークエリ等のメトリクスを収集する。 |
| 12 | blackbox_exporter | 外形監視でサービスの生存確認やエンドポイントごとのレイテンシ等のメトリクスを収集する。 |
プロジェクトの構成
監視環境のプロジェクトはGitHubで公開しています。
各ディレクトリ、ファイルの主な目的は以下の通りです。
docker-compose.yml : 各種Dockerコンテナを定義
alertmanager/ : Alertmanager用
alertmanager.yml : アラートメッセージやSlackの通知先定義
app/ : Node.jsコンテナ(App Server)用
app.js : 疑似的に用意したWebサービス(処理内部でカスタムメトリクス収集)
Dockerfile : Node.jsコンテナビルド用
package.json : Webサービスで利用するライブラリ等定義
grafana/data/ : Grafanaコンテナのデータ格納用
nginx/ : Nginxコンテナ(Web Server)用
Dockerfile : Nginxコンテナビルド用
nginx.conf : リバースプロキシ定義
logs/ : アクセスログ格納用
nginx_log_exporter/ : Nginxのアクセスログ収集用のExporter用
config.yaml : アクセスログのパース定義、メトリクス公開用のエンドポイント定義
postgres/ : PostgreSQLコンテナ(DB Server)用
postgresql.conf : スロークエリログの出力条件など定義
initdb/ : クエリ実行状況分析用の拡張モジュールのCREATE文を初回起動時に実行用
01_create_pg_stat_statements.sql
postgres_exporter/ : PostgreSQLのメトリクス収集用のExporter用
queries.yaml : スロークエリ抽出用のSQL定義
prometheus/ : Prometheus本体のコンテナ用
alert_rules.yml : PromQLでアラートの閾値を定義
prometheus.yml : メトリクス収集対象のExporterを定義
pushgateway/ : Pushgatewayコンテナ用
metrics.prom : curlコマンド(短命JOBの代替)でPushgatewayに送るメトリクス
環境構築手順
GitHubからプロジェクトをクローン
$ git clone https://github.com/tech-ult/public-tufn-202504.git
$ cd public-tufn-202504
Slack API、通知先チャネルのカスタマイズ
alertmanager/alertmanager.ymlについて、通知先のSlack APIのWebhookのURL、および、通知先のSlackチャネル名を編集してください。
# Slackの設定(SlackのIncoming Webhook URLを設定)
slack_api_url: 'https://hooks.slack.com/services/TXXXXXXXX/BXXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXX'
: 途中省略
# 通知先のチャネル名設定
slack_configs:
- channel: '#alert'
Dockerコンテナのビルドと起動
下記コマンドを実行し、Dockerコンテナのプロセスが12個立ち上がるのを確認してください。
お使いのマシン性能により、CPU使用率超過等のアラートが発報される可能性もあります。
# nginxとwebappのコンテナビルド
$ docker compose build --no-cache
# コンテナ立ち上げ
$ docker compose up -d
# 12プロセス起動確認
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cbd7def12724 nginx/nginx-prometheus-exporter:latest "/usr/bin/nginx-prom…" 11 seconds ago Up 9 seconds 0.0.0.0:9113->9113/tcp, :::9113->9113/tcp nginx_exporter
d67ba5ee2867 quay.io/martinhelmich/prometheus-nginxlog-exporter:v1 "/prometheus-nginxlo…" 11 seconds ago Up 9 seconds 0.0.0.0:9114->4040/tcp, [::]:9114->4040/tcp nginx_log_exporter
13a2eb7f6296 public-tufn-202504-nginx "bash -c '/usr/local…" 11 seconds ago Up 9 seconds 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp nginx_server
bc555c4d5888 public-tufn-202504-webapp "docker-entrypoint.s…" 11 seconds ago Up 9 seconds 0.0.0.0:3001->3001/tcp, :::3001->3001/tcp nodejs_webapp
553bfd5b0052 grafana/grafana "/run.sh" 11 seconds ago Up 9 seconds 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp grafana
821f0c379d7c prom/pushgateway "/bin/pushgateway" 11 seconds ago Up 10 seconds 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp pushgateway
22dd5896e696 prom/node-exporter "/bin/node_exporter …" 11 seconds ago Up 10 seconds 0.0.0.0:9100->9100/tcp, :::9100->9100/tcp node_exporter
42a1dd9013a0 prom/alertmanager "/bin/alertmanager -…" 11 seconds ago Up 10 seconds 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp alertmanager
8023234ce6f1 prom/blackbox-exporter "/bin/blackbox_expor…" 11 seconds ago Up 10 seconds 0.0.0.0:9115->9115/tcp, :::9115->9115/tcp blackbox_exporter
96db652de4ce prom/prometheus "/bin/prometheus --c…" 11 seconds ago Up 10 seconds 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus
b7f3e4a19890 postgres:latest "docker-entrypoint.s…" 11 seconds ago Up 10 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp postgres_server
fada8e698e17 prometheuscommunity/postgres-exporter "/bin/postgres_expor…" 11 seconds ago Up 10 seconds 9187/tcp postgres_exporter
各コンテナのWebUI確認
コンテナが立ち上がったら、ブラウザで以下のコンテナのURLを開き、画面が表示されることを確認してください。
Prometheus本体
http://localhost:9090
Alertmanager
http://localhost:9093

Grafana
http://localhost:3000

※初期ユーザー名・パスワードはともに「admin」です。初回ログイン時にパスワード変更を実施します。
Pushgateway
http://localhost:9091

自作Webアプリケーション
http://localhost

Grafanaのダッシュボード作成
データソースの追加
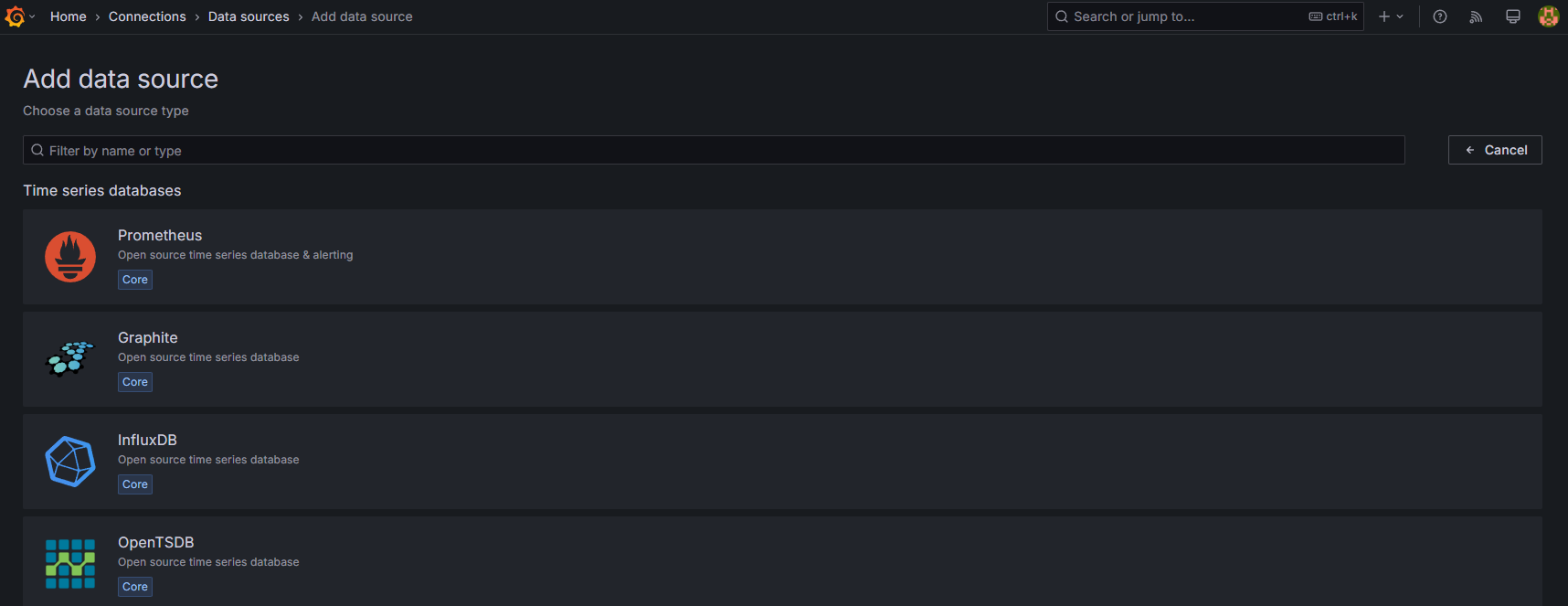
[Home > Connection > Data sources > Add data source] の画面で、Prometheusのデータソースを選択してください。
[Home > Connection > Data sources > Prometheus] の画面で、Connectionの入力欄に http://prometheus:9090を入力してください。
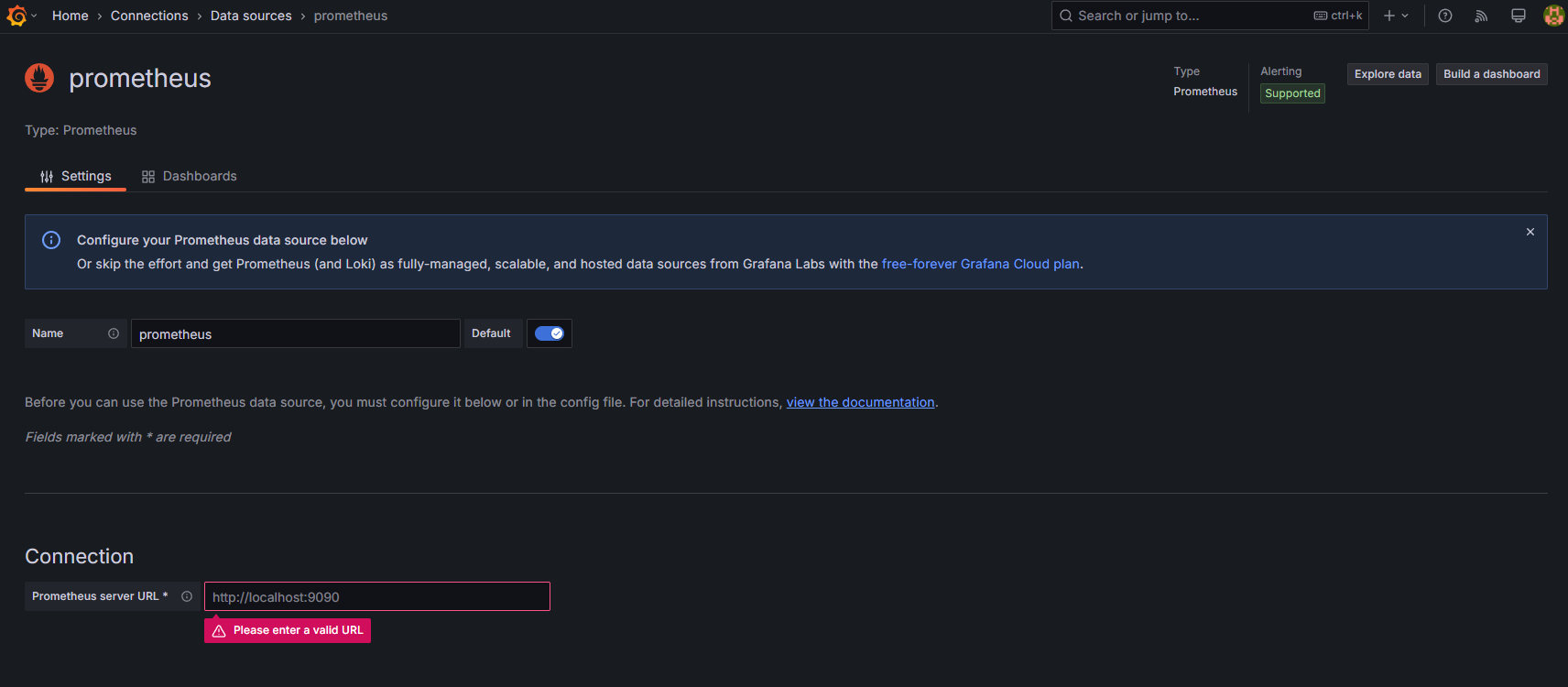
画面下部の[Save & test]ボタンを押して、Prometheusに接続成功することを確認してください。

公式ダッシュボードのインポート
[Home > Dashboards > Import dashboard] の画面で、Grafana.com dashboard URL or ID の入力欄に、外形監視用のExporterの「Prometheus Blackbox Exporter」のDashboardIDの7587を入力して[Load]ボタンを押してください。

signcl-prometheus のドロップダウンリストでprometheusを選択して、[Import]ボタンを押してください。
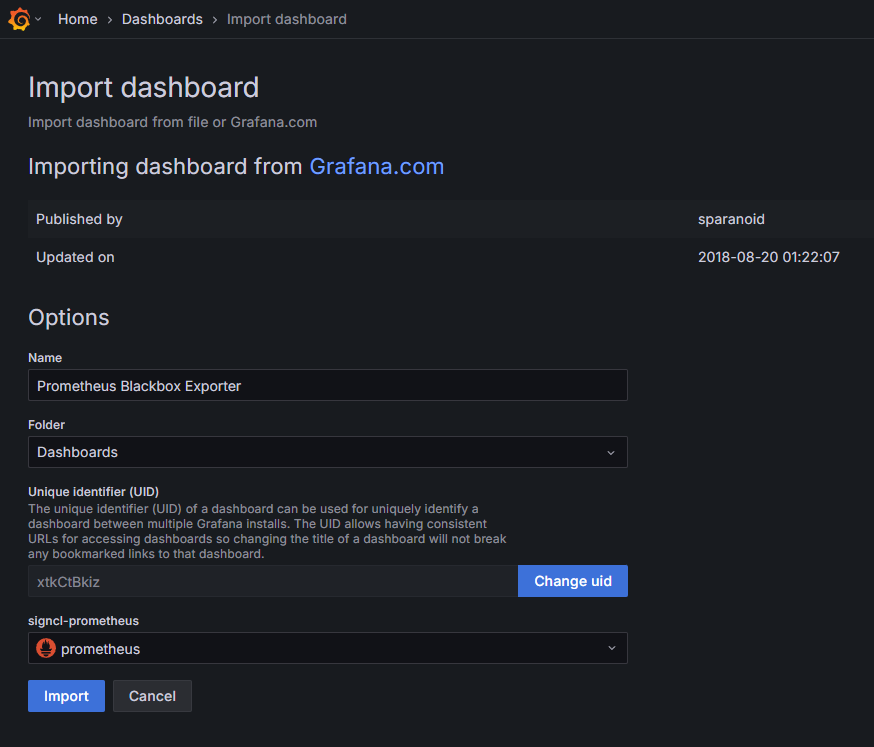
ダッシュボードが追加されれば完了です。
参考までに、その他のExporterのDashboard IDは以下の通りです。
| Dashboard名 | Dashboard ID |
|---|---|
| NGINX Prometheus Exporter Dashboard | 17452 |
| Node Exporter Full | 1860 |
| Node.js Exporter Quickstart and Dashboard | 14058 |
| PostgreSQL Database Dashboard | 9628 |
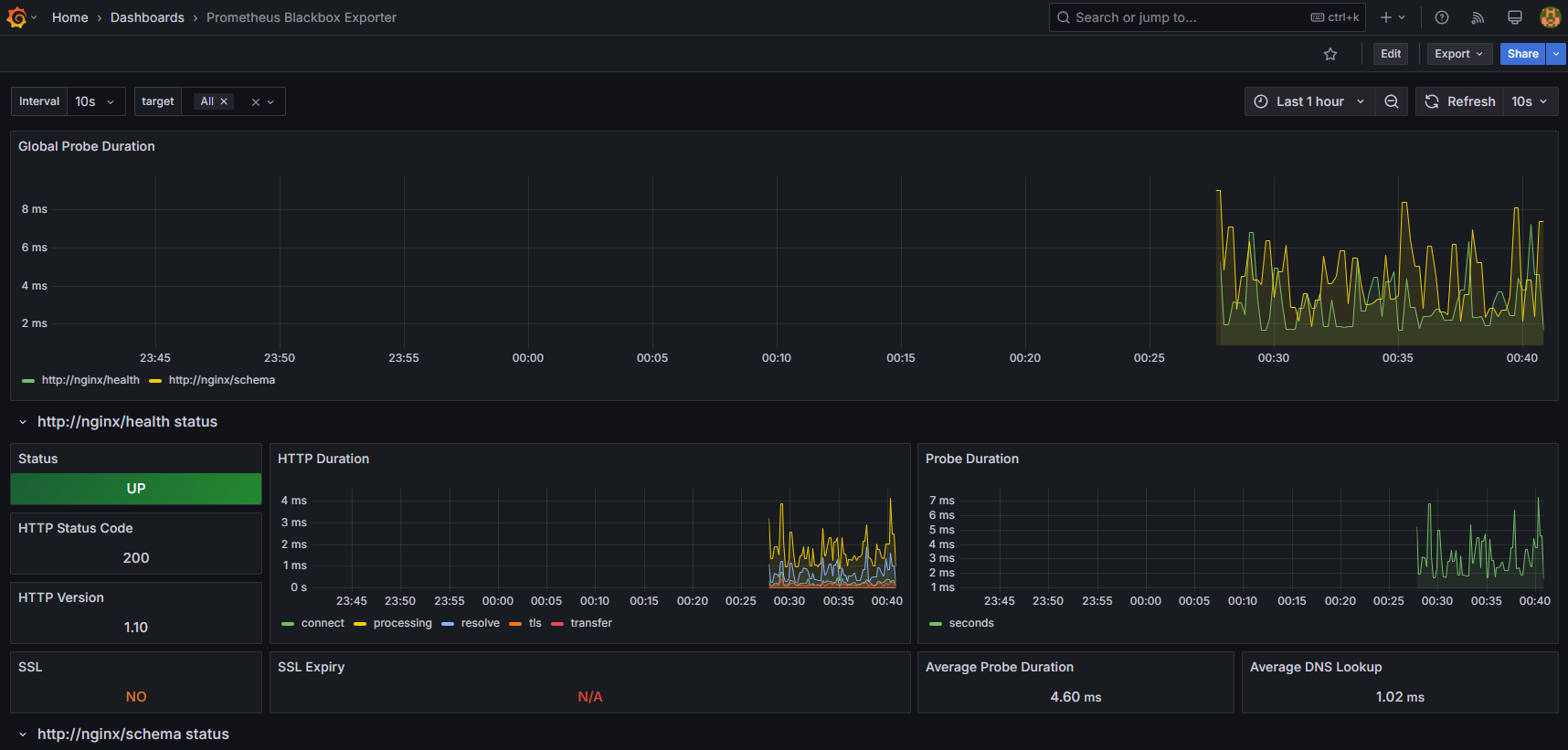
Prometheus Blackbox Exporter ダッシュボードの説明
Global Probe Duration
外形監視をしているエンドポイントのDurationを選択して表示することができます。どのエンドポイントのレイテンシがどのタイミングで遅く(速く)なっているのかを視認することができます。

個別のエンドポイント毎のダッシュボード
エンドポイントの疎通(死活)状態や、HTTP通信の内部で行われているDNS解決・TCP接続・TLSハンドシェイク・サーバーサイドの処理・レスポンスデータの転送処理などの所要時間、リクエストの平均レイテンシ、SSL/TLS証明書の有効期限などを視認できます。

今回外形監視用のエンドポイントとして定義したのは、「/health」「/schema」です。
監視対象のエンドポイントは、prometheus/prometheus.ymlで定義します。
具体的には、static_configsのtargetsに、リクエストを送るURLを設定します。
# Blackbox Exporter(外部プローブ監視)
- job_name: 'blackbox_http_2xx'
metrics_path: /probe
params:
module: [http_2xx] # 使うプローブモジュール(デフォルトで http_2xx が入ってる)
static_configs:
- targets:
- http://nginx/schema
- http://nginx/health
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox_exporter:9115 # Blackbox Exporterに問い合わせる
「/health」エンドポイントは、Webサーバー・Appサーバー・DBサーバーの連携確認を行うことを目的にしていて、DBサーバー(PostgreSQL)に接続して、SELECT 1のSQLを実行するだけの処理を行っています。
// --- /health チェックエンドポイント ---
app.get('/health', async (req, res, next) => {
try {
const result = await client.query('SELECT 1'); // シンプルに"SELECT 1"だけ
res.json({
status: 'ok',
postgres: result.rowCount > 0 ? 'connected' : 'no rows',
});
} catch (err) {
console.error('Health check failed:', err.stack);
res.status(500).json({
status: 'error',
message: 'Database connection failed',
});
}
});
「/schema」エンドポイントは、PostgreSQLのスキーマ一覧を取得する処理を行っています。詳細は割愛します。
アラート条件の設定
アラート条件の設定はprometheus/alert_rules.ymlで定義しています。
今回は、以下のアラート条件を設定しました。
- 「/health」エンドポイントからのレスポンスのステータスコードについて、success(200)が返ってこない状態が1分間継続
- 「/health」エンドポイントの処理時間が5秒を超える状態が1分間継続
- name: blackbox_alerts
rules:
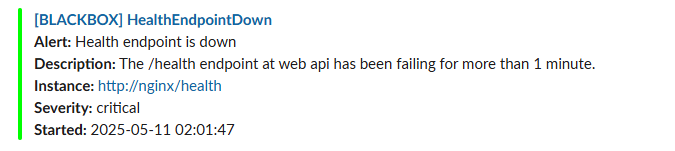
- alert: HealthEndpointDown
expr: probe_success{instance="http://nginx/health"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Health endpoint is down"
description: "The /health endpoint at web api has been failing for more than 1 minute."
- alert: HealthEndpointHighLatency
expr: probe_duration_seconds{instance="http://nginx/health"} > 5
for: 1m
labels:
severity: warning
annotations:
summary: "High latency detected on health endpoint"
description: "The /health endpoint at web api is taking more than 5 seconds to respond."
外形監視アラート通知の検証
App サーバーのコンテナを停止して、疑似的に障害を発生させる
Appサーバーに何らかの障害が発生して停止した場合に、HealthEndpointDownのアラートが通知されるかを検証してみます。
以下のコマンドを実行して、Appサーバーのコンテナを停止します。
$ docker stop nodejs_webapp
Grafanaのダッシュボード上では、すぐに異常検知を確認できます。

PrometheusのWebUIでも異常検知できますが、エラー状態がまだ1分間継続していないので、HealthEndpointDownのステータスはPENDINGになっています。この状態ではまだアラート通知されません。
一方で、Webサーバー側のアラート定義AnyHttp5xxErrorDetectedは、エラーが発生したら即時アラート通知を出す定義にしていたため、FIRING状態になっています。

1分経過したら、HealthEndpointDownのステータスもFIRING状態になりました。

FIRINGになると、PrometheusからAlertmanagerにアラートが連携されます。

Alertmanagerから、Slackにアラート通知が送られます。
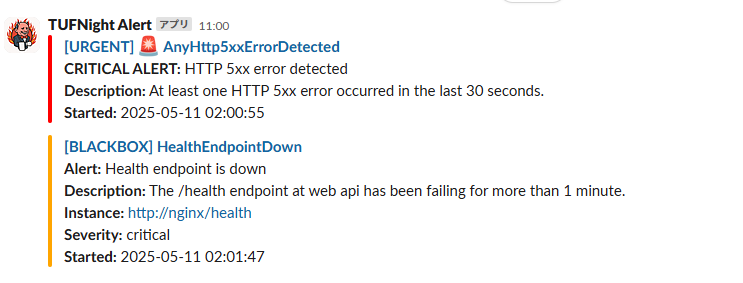
無事、アラート通知されることを確認できたので、Appサーバーのコンテナを起動します。
$ docker start nodejs_webapp
Grafanaで、ステータスが正常になったことを確認できます。

Prometheusでも、FIRINGだった状態がINACTIVEに戻っています。

Alertmanager上でもアラートが消えました。

Slackにも、異常状態が回復した通知が飛びます。
なお、今回はHealthEndpointHighLatencyのアラート通知検証については割愛しますが、サーバーの負荷が高くなり処理速度が遅くなっている状態を疑似的に作り出すことで検証可能です。
まとめ
今回は、OSSのPrometheusとGrafanaを使った外形監視環境の構築方法をご紹介しました。
本記事で紹介した構成を活用すれば、商用監視サービスを使わずとも、コストを抑えながら本格的なサービス監視を始めることができます。
特に、外形監視は「ユーザー視点」で問題を素早く検知できるため、サービス品質を守る上でとても重要です。
もちろん、今回紹介したのは監視の一部分に過ぎません。
次回以降で、スロークエリ監視やエラーレート監視など、さらに深いモニタリング手法にもご紹介していく予定です。
一緒にOSSについて学んでいきたいなど、ご興味を持たれた方は、弊社ホームページからお問い合わせいただければ幸いです。