はじめに
Webサービスのレスポンス速度が遅くて操作性が悪かったり、バグなどによる予期せぬエラーが発生していると、ユーザーに解約されるリスクが高まります。
- サービスが成長していくに従い、取り扱うデータ量も増大していき、データベースの検索スピードも遅くなり、ユーザー体験が悪化した
- サービスの新機能を他社よりも速くリリースして競合優位性を強化するため、クオリティーよりもデリバリーを優先してしまった結果、エラーが多発してユーザーからの問合せに対応するコストが増大した
上記のような事態に陥る前に、スロークエリやエラーをPrometheusで監視して、いち早く異常状態に気づけるようにしましょう!
前提条件
本記事は、以下について概要レベルの知識を有している読者を想定しています。
- Webアプリケーション開発
- Docker環境構築方法
- Slack APIの発行方法
- Gitコマンドの使い方
本記事で紹介する環境構築は、以下の環境で行いました。
- Windows11 WSL2(Ubuntu 22.04.5 LTS)
- Docker version 27.5.1
- Docker Compose version v2.34.0
本記事では、Prometheusによるモニタリングの中でも、スロークエリやエラーレート等のモニタリングに焦点を当てて紹介します。
PrometheusやGrafana自体の説明や、外形監視や短命ジョブの監視、および、検証のための環境構築方法については以下を参照してください。
Prometheus + Grafana で Webサービス監視環境を構築する - 外形監視編 -
Prometheus + Grafana で Webサービス監視環境を構築する - 短命ジョブ監視編 -
Prometheus + Grafana で Webサービス監視環境を構築する - クライアントライブラリ監視編 -
解説
スロークエリについて
スロークエリとは、文字通り実行に時間がかかるクエリ(SQL)です。
ユーザーが画面上のボタンを押したけど、なかなか処理が進まないで待たされて、イライラがつのっていく。その原因の一つがスロークエリです。
主な発生原因は以下の通りです。
- インデックス設計漏れでテーブルをフルスキャンしている
- JOIN句で多数のテーブルを結合して検索している
- N + 1で大量のクエリを発行している
- トランザクションの粒度が粗く、ロック解除待ちに時間がかかっている
- そもそもデータベースの性能が低い
今回は監視がテーマなので、それぞれの詳細については、また別の機会に説明いたします。
エラーレートについて
エラーレートとは、すべての通信の中でエラーが発生している割合のことです。
HTTPレスポンスのステータスコードを集計することで、エラーの割合を把握できます。
主なステータスコードは以下の通りです。
| ステータスコード | 概要 |
|---|---|
| 200 | OK: リクエスト成功 |
| 304 | Not Modified: キャッシュ済みのレスポンスを利用する |
| 403 | Forbidden: リクエストされたリソースへのアクセス権がない |
| 404 | Not Found: リクエストされたリソースが存在しない |
| 500 | Internal Server Error: サーバー内部でエラーが発生 |
エラーレートは、上記400系・500系のステータスコードの発生率を計算したものです。
なお、400系のエラーは、クライアント側の誤操作等で発生するエラーで、500系のエラーは、サーバー側の問題で発生するエラーです。
400系のエラーが短時間で多発していた場合、DDoS攻撃や脆弱性スキャンをされている可能性もあるため、時間当たりの発生率を監視する必要があります。
500系のエラーは、アプリケーション内部で何らかのバグが発生している可能性もあるため、発生したら即時にアラートを通知して調査・改修対応する必要があります。
監視環境の構成図(再掲)
今回構築する監視環境の構成図は以下の通りです。

環境構築手順
Grafanaのダッシュボード作成
今回は、Grafanaの公式ダッシュボードをインポートするのではなく、自分でパネルを作っていきます。
[Home > Dashboards > New dashboard] の画面で、[Add Visualization]ボタンを押下します。

data sourceにはprometheusを選んでください。

パネルの編集ページが表示されます。

画面下部の[Enter a PromQL query...]の入力欄に、HTTPレスポンスのステータスコードごとの集計をするための以下のPromQLを入力して、[Run queries]ボタンを押下してください。
sum by (status) (rate(nginx_http_response_count_total[1m]))
画面右上のVisualizationのドロップダウンで[Time series]がデフォルト選択されているため、時系列の折れ線グラフが表示されます。

ダッシュボードを忘れずに保存しておきましょう。[Save dashboard]ボタンから保存できます。

画面右上の[Back to dashboard]ボタンを押して、一度ダッシュボードに戻り、画面上部の[Add]ドロップダウンから[Visualizagion]を選びましょう。

エラーレート表示用に、Visualizationから[Gauge]を選び、下記PromQLを入力してください。
sum(rate(nginx_http_response_count_total{status=~"5.*|4.*"}[5m])) / sum(rate(nginx_http_response_count_total[5m]))
エラーが発生していないうちは、ゲージにはNo dataが表示されます。

同様に、ステータスコードの総数を表示するため、Visualizationを追加しましょう。
[Bar chart]を選び、下記PromQLを入力してください。
sum by (status) (nginx_http_response_count_total)

同様に、ステータスコード分布を表示するため、Visualizationを追加しましょう。
[Pie chart]を選び、下記PromQLを入力してください。
sum by (status) (nginx_http_response_count_total)

同様に、スロークエリのTOP5を表示するため、Visualizationを追加しましょう。
[Table]を選び、下記PromQLを入力してください。
avg_over_time(pg_stat_statements_mean_time[1m])
-
pg_stat_statements_mean_time: クエリの平均実行時間 -
avg_over_time: 指定した時間範囲(ここでは1分)にわたる平均値

TOP5だけを出したいので、画面下部の[Transformations]タブを選び、パネル表示内容を編集するため[Add transformation]ボタンを押下します。

Reduceを選びます。
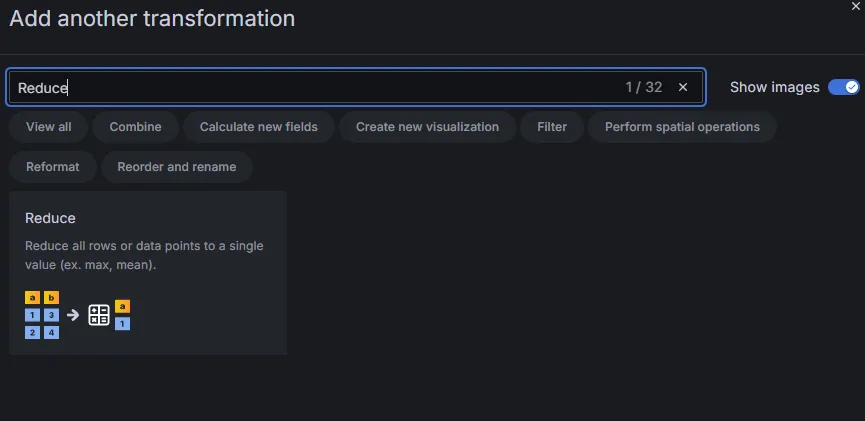
Caluculationsに[Max]を選択して、[Labels to fields]トグルをONにします。

表示するカラムを絞り込むため、Add another transformationからOrganize fieldsを選びます。

表示するカラムをqueryとMaxだけにして、その他のカラムを非表示に設定します。

クエリ実行時間の昇順に並び替えてTOP5を出すため、Add another transformationからSort byを選びます。

FieldにMaxを選び、ReverseトグルをONにします。

5件のみ表示させるため、Add another transformationでLimitを追加します。
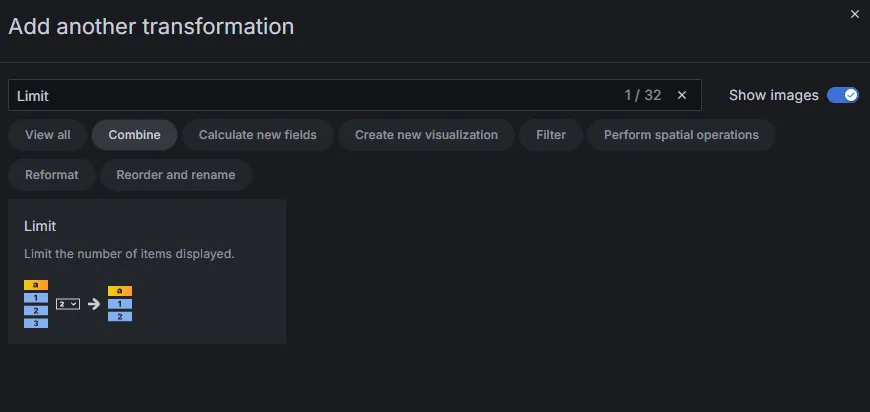
Limitに5を設定します。

作成したパネルは、ダッシュボード上で表示の大きさを替えたり、ドラッグアンドドロップで位置を替えたりできます。わかりやすいようにパネル名を編集するのも良いでしょう。

アラート条件の設定
アラート条件の設定はprometheus/alert_rules.ymlで定義しています。
今回は、以下のアラート条件を設定しました。
- name: nginx_alerts
rules:
- alert: AnyHttp5xxErrorDetected # 5xxエラーが1回でも発生した場合のアラート
expr: |
sum(rate(nginx_http_response_count_total{status=~"5.."}[30s])) > 0
for: 0s
labels:
severity: critical
annotations:
summary: "HTTP 5xx error detected"
description: "At least one HTTP 5xx error occurred in the last 30 seconds."
- alert: HighHttp4xxErrorRate # 4xxエラー率が高い場合のアラート
expr: |
(sum(rate(nginx_http_response_count_total{status=~"4.."}[1m])))
/
(sum(rate(nginx_http_response_count_total[1m])))
> 0.10
for: 1m
labels:
severity: warning
annotations:
summary: "High HTTP 4xx error rate detected"
description: "The HTTP 4xx error rate has exceeded 10% over the past 2 minutes."
- name: postgres_alerts
rules:
# スロークエリを検知するアラート
- alert: PostgresSlowQuery
expr: max_over_time(pg_slow_queries_duration[1m]) > 5 # 過去1分間のうち、5秒以上実行されているクエリを検知
for: 0s # 検知したらすぐにアラート
labels:
severity: warning
annotations:
summary: "Slow PostgreSQL query detected"
description: "Database: {{ $labels.database }}, User: {{ $labels.user }}, Query duration: {{ $value }}s, Query: {{ $labels.query }}"
- AnyHttp5xxErrorDetected
- 500系のエラーが発生したら即時にアラート通知
- HighHttp4xxErrorRate
- 400系のエラー発生率が10%を超えた状態が1分間継続した場合にアラート通知
- PostgresSlowQuery
- 処理時間が5秒を超えるクエリがあった場合にアラート通知
エラーレート・スロークエリのアラート通知検証
自作したWebアプリから、エラーやスロークエリを発生させる

[404エラー][403エラー]ボタンを押して、エラーを発生させてみましょう。


Grafanaのダッシュボード上で、エラーを確認できます。エラーレートが10%を超えていないので、アラート通知されません。

エラーレートが10%を超えた状態を1分間継続させるため、[404エラー][403エラー]ボタンを定期的に押し続けてみましょう。

Prometheusの画面上では、PENDING状態になっています。

1分間継続すると、FIRING状態になり、アラートが通知されます。

Slackにもアラートが連携されます。

次に、500系のエラーのアラート通知も確認しましょう。
[500エラー]ボタンを押下してください。

エラー検知します。


Slackにも通知されます。

スロークエリも試してみましょう。
自作アプリケーションの[ユーザー一覧(Slowクエリ)]ボタンの内部処理は下記のとおり、10秒スリープ後にPostgreSQLのユーザー一覧を返却しています。
// /user → 10秒待ってからユーザー一覧
app.get('/user', async (req, res, next) => {
try {
await client.query('SELECT pg_sleep(10)'); // 10秒待つ(スロークエリ)
const result = await client.query('SELECT usename FROM pg_user');
res.json(result.rows);
} catch (err) {
next(new AppError('Failed to fetch users', 500));
}
});
スロークエリのアラート設定は前述通り、実行時間が5秒を超えるクエリが1分間継続することを条件としているため、[ユーザー一覧(Slowクエリ)]ボタンを1分間の間(計6回)押し続けてみましょう。

そのうち、エラー検知します。

ダッシュボードのスロークエリTOP5では、1位がsleepのクエリ(10秒)になっていることが確認できます。

Slackにもアラート通知します。

まとめ
本記事では、Webサービスの品質劣化を未然に防ぐため、PrometheusとGrafanaを活用してスロークエリやHTTPエラーを監視する方法を解説しました。
サービスの成長に伴い、処理の遅延やエラーは避けがたいものですが、適切な監視体制を整えることで、ユーザー体験の悪化を未然に防ぐことができます。とくにスロークエリやエラーレートといった指標は、サービス運用上のボトルネックや障害の兆候を早期にキャッチするための重要な観測点です。
実際のプロダクトで問題が顕在化してから対応するのではなく、本記事で紹介したようなモニタリング環境を構築して、異常を「先に知る」体制を整えておくことが、信頼性の高いサービス運用につながります。
ぜひ、自社の環境にあわせてカスタマイズしながら、監視の精度と迅速なアラート対応体制を高めていきましょう。
一緒にOSSについて学んでいきたいなど、ご興味を持たれた方は、弊社ホームページからお問い合わせいただければ幸いです。