はじめに
我々の身の回りで日々発生するデータを収集し、分析することで、業務を効率化したり、下記に挙げたような課題を解決することができます。
- 売り上げを伸ばすため、顧客にリーチする広告を打ちたい。
- サービスを解約しそうな顧客を引き止める施策を打ちたい。
- クレジットカードの不正利用をリアルタイムに検知したい。
- 渋滞情報や荷物量を考慮し、最も効率的なルートを算出したい。
- 勤怠データや面談記録から、離職リスクの高い社員を早期に発見したい。
データアナリストは、データという『生の情報』を、ビジネスの意思決定に役立つ『価値ある知見』に翻訳することを生業としていますが、その元となるデータは彼らにどのように届けられるのでしょうか。
実際のところ、データ分析基盤を構築して裏方で支えるデータエンジニアの存在があってこそ、表舞台でデータアナリストが活躍できるのです。
今回は、データエンジニアに焦点を当て、その仕事の中でも重要な、データパイプラインの構築方法を紹介します。
前提条件
- WSLのUbuntu上にDockerでデータ分析基盤を構築するため、Dockerについて概要を理解している人を対象とします。
- データパイプラインには、Apache Airflowを利用します。Airflowの詳細な設定方法は割愛します。
解説
データアナリストとデータエンジニアの職域
データアナリストは、データを集計、可視化し、経営層がビジネス的な意思決定を行うためのサポートを行います。
データエンジニアは、データアナリストが迅速かつ正確にデータ分析を行うためのデータ分析基盤を構築する役割を担います。
データの欠損や誤りがあったり、必要な時にタイムリーにデータが入手できなかったり、フォーマットがばらばらで扱いづらい場合、正確な分析ができません。
データの正確性、可用性を担保するのは、データエンジニアの役割です。
主な職域の違いは以下の通りです。
| 比較項目 | データアナリスト (DA) | データエンジニア (DE) |
|---|---|---|
| 主な目的 | ビジネス上の意思決定を支援する | データの「流れ」と「基盤」を構築・維持する |
| 注力ポイント | データの活用・解釈 (現状把握と予測) | データの収集・加工 (安定性と効率) |
| 主な成果物 | ダッシュボード、分析レポート、施策提案 | データパイプライン、DWH、データマート |
| 得意なツール | SQL, Tableau, Power BI, Python (Pandas/Scikit-learn) | SQL, Python, Airflow, dbt, Spark, クラウドインフラ (AWS/GCP) |
| 向き合う相手 | 企画、マーケ、営業などのビジネス部門 | データアナリスト、サイエンティスト、SRE |
| 主な問い | 「なぜ売上が下がったのか?」「次はどうすべきか?」 | 「データは欠損なく届いているか?」「処理速度は最適か?」 |
データパイプラインについて
データパイプラインとは、データの発生源から分析環境まで、自動的に流れるための一本道のことです。
以下の4つのステップを通じて、生のデータから分析可能なデータに変換し、活用できるようにします。
-
収集 (Ingestion):
- アプリのログ、データベース、外部APIなどからデータを集めてきます。
-
加工・変換 (Transformation):
- 重複を消す、型を揃える、個人情報を伏せる、計算して新しい項目を作るなど、データのクレンジングや名寄せなどの加工を行います。
-
保存 (Storage):
- 綺麗になったデータを「データウェアハウス(DWH)」などの倉庫に溜めます。
-
活用 (Analysis/Visualization):
- 分析ツール(BIツール)や機械学習モデルでデータを利用します。
データレイク、データウェアハウス、データマート
データパイプライン上で扱うデータ保管場所は、大きく分けて以下の3つに分類されます。
-
データレイク (Data Lake)
- 形式を問わずあらゆるデータをそのままの形で保管する、大きな泉のような場所です。
- Excel、アプリケーションログ、画像ファイル、SNSの投稿など、将来データ分析に利用できる可能性のあるものを、非構造化、未整理の状態でため込んでおきます。
- 形式を問わずあらゆるデータをそのままの形で保管する、大きな泉のような場所です。
-
データウェアハウス (Data Warehouse / DWH)
- データレイクから必要なデータを取り出し、計算や分析がしやすいように形を整えて保管する倉庫です。
- 重複を消したり、型を揃えたりして、加工して構造化したデータを格納します。
- データレイクから必要なデータを取り出し、計算や分析がしやすいように形を整えて保管する倉庫です。
-
データマート (Data Mart)
- DWHの中から、特定の部署や目的(営業部用、マーケティング用など)に必要なデータだけを切り出した小規模な保管庫です。
- 特定の業務で使用するために、要約・加工しているため、データ量は比較的少なくなり、素早くデータを取り出すことができます。
- DWHの中から、特定の部署や目的(営業部用、マーケティング用など)に必要なデータだけを切り出した小規模な保管庫です。

データレイクには、S3やクラウドストレージなどのオブジェクトストレージが使われることが多いです。
また、DWHやデータマートには、BigQueryやAmazon Redshiftなどのカラムナー指向データベースが使われることが多いです。
分析に利用するBIツールには、TableauやRedash、Looker Studioなどが用いられます。
ETL vs ELT
データパイプライン上で、データレイクからデータ抽出し、加工し、DWHに格納する際に、ETL/ELTツールが使われます。ETLとELTの違いは、データの加工(Transform)をどのタイミングで行うかです。
主な相違点は以下の通りです。
| 比較項目 | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| 加工のタイミング | DWHに格納する前に加工 | DWHに格納した後に加工 |
| 主なメリット | ・DWH側の負荷が低い ・データ保存容量を節約できる |
・生データを残せるため再分析に強い ・ロードが圧倒的に速い |
| 主なデメリット | ・加工用の専用サーバーが必要 ・データ形式変更時の修正に時間がかかる |
・大量の生データを保存するストレージが必要 ・加工時にDWHの計算コストがかかる |
| データの状態 | 加工済みのきれいなデータのみを保存 | 未加工(RAW)の状態でまず保存 |
| 柔軟性 | 低い(事前に設計が必要) | 高い(後からSQLで自由に加工可能) |
昔はストレージが高価で計算能力も低かったため、「必要な分だけ小さくして入れる(ETL)」がが正解でした。
しかし、現在はクラウドの進化で「大量に安く保存でき、超高速で計算できる」ようになったため、「全部放り込んでから後で考える(ELT)」ほうが、ビジネスのスピードに合わせやすく、主流になってきました。
また、ELTでは、「データを運ぶツール(EL)」と「DWH内で加工するツール(T)」を組み合わせて使うのが一般的です。
- データを運ぶツールの例
- TROCCO(トロッコ):日本発のSaaS型ツール。100種類以上のコネクタを使って、バラバラなデータをDWHへ運ぶ。
- データを加工するツールの例
- dbt (data build tool):SQLで加工処理を書くことができ、バージョン管理(Git)やテストを自動化できる。
TROCCOでBigQueryに格納したデータをdbtで加工して、データマートに格納する事例もよく耳にします。
データ加工について
データレイクに溜まったデータを加工する方法として、代表的な処理は以下の通りです。
SQLで加工したり、Pythonスクリプトや専用のツールを用いてデータを編集し、分析しやすい形式にしてDWHに登録します。
| 項目 | 内容・定義 | 主な目的 | 具体例 |
|---|---|---|---|
| クレンジング | データの誤記、重複、欠損、表記揺れを修正・削除する。 | データの正確性を高め、分析のノイズを除去する。 | 「東京都」と「東京都 」(末尾スペース)を統一する。 |
| 名寄せ | 異なるシステムやDBにある「同一人物・企業」のデータを一つに統合する。 | 顧客の重複を排除し、正しい1顧客としての動きを把握する。 | 住所と電話番号が同じ「田中太郎」と「タナカ タロウ」を同一IDで紐付ける。 |
| フォーマット合わせ | 日付、数値、単位などの形式を特定のルールに統一する。 | システム連携をスムーズにし、計算可能な状態にする。 | 「2026/03/04」と「R8.3.4」を「2026-03-04」に統一する。 |
| マスキング | 個人情報などの機密情報を、特定のルールで別の文字列に置き換える。 | セキュリティを確保し、個人を特定せずに分析に利用する。 | 「yamada@example.com」を「y****@example.com」にする。 |
データマートの登録例
前述の通り、データマートには特定の目的に合わせた形式にデータを加工して登録します。
例えば、サービスの利用者数の増減を月毎にグラフで可視化したい要件があった場合、会員情報の入会年月日ごとに人数を集計して、ユーザー数推移用のスナップショットテーブルに登録します。
この例の場合だと、ユーザー数推移スナップショットには合計人数のみで、利用者の性別や年齢などの属性情報が欠落するため、データマート上のデータを利用しづらくなります。
例)
DWHのユーザー情報テーブル。集計元テーブル。
| ユーザーID (user_id) | 入会年月日 (joined_at) | 性別 (gender) | 年代 (age) | 居住地 (pref) | ステータス (status) |
|---|---|---|---|---|---|
| U001 | 2026-01-05 | 男性 | 24 | 東京都 | 有効 |
| U002 | 2026-01-12 | 女性 | 29 | 大阪府 | 有効 |
| U003 | 2026-01-28 | 男性 | 31 | 福岡県 | 退会 |
| U004 | 2026-02-03 | 女性 | 22 | 東京都 | 有効 |
| U005 | 2026-02-15 | 男性 | 38 | 愛知県 | 有効 |
ユーザー情報テーブル年月ごとのユーザー数の推移を可視化するため、ステータスが有効なユーザー数だけを集計したデータマート。
性別や年齢などの属性は落とされているため、F1層(20~34歳の女性)、M1層(20~34歳の男性)などの分析には不向き。
| ログ月 (log_month) | ユーザー数 (user_count) |
|---|---|
| 2026-01 | 2 |
| 2026-02 | 2 |
性別や年代の属性を残して、有効なユーザー数を集計したデータマート。
| ログ月 (log_month) | 性別 (gender) | 年代 (age_group) | ユーザー数 (user_count) |
|---|---|---|---|
| 2026-01 | 男性 | 20-34代 | 1 |
| 2026-01 | 女性 | 20-34代 | 1 |
| 2026-02 | 女性 | 20-34代 | 1 |
| 2026-02 | 男性 | 35-49代 | 1 |
パイプラインの監視
正確なデータ分析を行うためには、パイプラインを通してデータが正しくデータマートに登録されていることが前提です。
- データの発生源である対向システムから、毎日定刻に届くはずのデータが届いていない
- 対向システムの仕様変更で、送られてくるデータのフォーマットが変わって、DWHに正常に取り込みできない
- 想定以上のデータ量が送られて、データマートに格納するまでに時間がかかり、データ分析者が利用開始する時刻までに間に合わない
など、何かしらの問題が発生して、データマートにデータが届かない事態になった場合に、迅速に復旧するためには、パイプラインの監視が必要です。
エラーが発生した場合に、自動でリトライしたり、メールやSlackなどで担当者に通知する仕組みは、今どきのパイプライン用サービスには標準で組み込まれています。
不正データ起因で発生したエラーについては、AIエージェントにデータ解析させて原因を取り除いて復旧させる方法もあるかもしれませんが、個人情報を含むデータをAIエージェントに読み込ませるのはセキュリティのリスクもあります。AIエージェントによる完全な自動復旧は課題も多いため、現時点では人間が判断する必要があります。
パイプライン上でAIを使うの一案としては、データ型としては正常でも、突発的なスパイク値や、ノイズ、外れ値など、統計分析に影響があるデータをAIで摘出し、データアナリストに通知する仕組みがあれば、データの正確性を担保できるようになるでしょう。
Apache Airflow
ワークフロー・オーケストレータのAirflowは、Airbnb社が作ったOSSで、データパイプラインの運行を管理するツールとして利用され、AWSやGoogle Cloudでもマネージドサービスとして提供されています。
Airflowのアーキテクチャ

DAG(Directed Acyclic Graph:有向非巡回グラフ)
DAGは、タスクの実行順序、依存関係を定義したもので、Pythonで記載されます。例えば、「タスクA→タスクB→タスクCの順で実行」のように、タスクの実行順を定義できるだけでなく、エラー時のリトライ数、リトライ間隔、DAGの実行スケジュールを定義できます。
# DAG実行順の定義例
start >> [op-1, op-2] >> some-other-task >> [op-3, op-4] >> end
Webserver
「具体的に何をするか」というタスクのテンプレートです。クラウドサービスやプログラミング言語ごとに「部品」が用意されています。以下に挙げる他にも、様々なオペレーターが用意されています。PythonOperator
DAGから別ファイル、または、DAG内に直書きしたPythonスクリプトを呼び出す際に利用する。
# 1. 実行したい処理を「関数」として定義する
def my_python_function(name, **kwargs):
print(f"こんにちは、{name}さん!")
print(f"今日の実行日付は {kwargs['ds']} です。")
return "処理完了"
with DAG(
dag_id='example_python_operator',
start_date=datetime(2026, 3, 1), # 2026-03-01 から起動する
schedule_interval='@daily', # 日次バッチ
catchup=False # 過去に未実行だったスケジュールは実行しない
) as dag:
# 2. PythonOperatorで関数を呼び出す
run_python_task = PythonOperator(
task_id='execute_logic',
python_callable=my_python_function, # 実行する関数名を指定
op_kwargs={'name': 'データエンジニア'}, # 関数に渡す引数を辞書で指定
)
BashOperator
DAGから別ファイルで定義したBashスクリプトを呼び出す際に利用する。
# 1. シンプルなコマンド
print_hello = BashOperator(
task_id='print_hello',
bash_command='echo "Hello, Airflow! 実行日は {{ ds }} です"'
)
# 2. 複数のコマンドを連続実行
# カレントディレクトリを確認し、ファイルを生成する
run_multi_commands = BashOperator(
task_id='run_multi_commands',
bash_command="""
pwd && \
ls -al && \
echo "作成完了" > /tmp/test_file.txt
"""
)
BigQueryExecuteQueryOperator
DAGから別ファイル、または、DAG内に直書きしたSQLをBigQueryに対して発行する際に利用する。
# BigQueryでクエリを実行するタスク
run_query = BigQueryExecuteQueryOperator(
task_id='run_my_sql',
sql="""
SELECT
user_id,
COUNT(*) as action_count
FROM `my_project.my_dataset.user_logs`
WHERE date = '{{ ds }}'
GROUP BY user_id
""",
use_legacy_sql=False, # 標準SQLを使用
destination_dataset_table='my_project.my_dataset.summary_table', # 結果をテーブルに保存する場合
write_disposition='WRITE_TRUNCATE', # 上書き設定(他にはWRITE_APPENDなど)
gcp_conn_id='google_cloud_default' # Airflowで設定した接続ID
)
AirflowのDAG内で、Pythonスクリプトを使って複雑な処理を並行で行うと、マシンリソースを消費してメモリー不足になりタスクが異常終了したり、CPU100%になりタスクが反応しなくなりAirflowが該当タスクを強制終了させるため、パイプラインが不安定になります。
大量データの加工処理はDAGで実行するのではなく、BigQuery上でSQLを発行して実行することをお勧めします。
Airflowは、パイプラインの交通整理役であり、重い荷物を運ぶトラック役は外部の専門基盤に委譲し、タスクの開始と終了を見守る役に徹することが、安定的な運用につながります。
Metadata Database(メタデータDB)
Airflowの全情報を保存するデータベース(PostgreSQLやMySQL)です。DAGの定義、過去の実行結果(成功・失敗)、現在のタスクの状態、ユーザー設定、変数(Variables)などが保存されます。
これが壊れると、Airflowは「自分がいま何をすべきか」「過去に何をしたか」をすべて忘れてしまいます。
メタデータDBへのデータ登録、更新はWebUIやスケジューラ、ワーカーが行います。
Scheduler(スケジューラ)
スケジューラはAirflowの司令塔であり、「Metadata DB(過去と現在の状態)」と「DAGファイル(未来の予定)」を常に突き合わせ続け、ギャップがあれば埋めるという動作を繰り返しています。「毎日深夜1:00に実行」などのスケジュールや、「タスクDとタスクEの終了を待って、タスクFを実行」などの実行指示を出します。
実行条件が揃ったタスクをキューに登録し、メタデータDBを更新して実行待ち状態にします。なお、実行待ちになったタスクは、エクゼキュータが取り出し、ワーカーに処理を実行させます。ワーカーが実行中のタスクについて、スケジューラはハートビートを送り生死を監視します。タスクの生存が確認できなかった場合は、ゾンビタスクとして扱い、強制終了させてリトライさせます。
その他、DAGの定義を定期的にチェックし、新規登録や変更があった場合はメタデータDBを更新します。
Executor(エグゼキュータ)
スケジューラに組み込まれている機能で、タスクの実行先ワーカーの振り分け役を担います。「自分の同じマシンの中で、サブプロセスとして動かそう」、「タスクをキューに投げて、遠くにいるWorkerたちに拾わせよう」、「タスクごとに、コンテナを新しく1個作ってそこで動かそう」などの判断を行います。
スケジューラが「脳」、ワーカーが「体」であれば、エグゼキュータは脳と体を繋ぐ「神経」のような役割を果たします。
Google Cloudの Cloud Composer を使うなら、内部では KubernetesExecutor(またはCeleryとK8sのハイブリッド)が動いており、ユーザーは「神経」の管理をあまり意識せずに済むようになっています。
Worker(ワーカー)
ワーカーは、指示されたタスクを、指定された環境で実行し、結果を報告します。タスクに定義されているオペレーター(PythonOperator、BigQueryOperatorなど)を動かします。
タスクの開始時、完了時(成功/失敗)に、その状態をMetadata DBに書き込みます。
タスクがあまりに重く、ワーカーのマシンリソースを使い果たしてしまうと、ワーカー自身がフリーズしてしまうことがあります。
「ワーカーがどこでどう動くか」は、どのExecutorを使うかで大きく変わります。
| Executor | ワーカーの実体 | 特徴 |
|---|---|---|
| LocalExecutor | スケジューラと同じマシン | 1台のマシン内で、複数のPythonプロセスとして動く。小規模・開発向け。 |
| CeleryExecutor | 独立したサーバー群 | 複数の専用サーバー(Workerノード)を常時立ち上げておく。中〜大規模向け。 |
| KubernetesExecutor | 使い捨てのPod(コンテナ) | タスクが実行される時だけ、Kubernetes上に新しいコンテナが立ち上がり、終わると消える。モダンな標準。 |
ハンズオン
Docker Compose で、以下のデータパイプラインを構築します。
- データレイク:S3(MinIO)
- DWH/データマート:PostgreSQL
- データ分析ツール:Metabase
- パイプラインの基盤:Airflow
プロジェクト構成
project/ # データ分析 PoC プロジェクト
├── README.md # プロジェクト説明
├── docker-compose.yml # Docker 構成(Airflow, DB, Metabase 等)
├── pyproject.toml # Python プロジェクト設定
├── .env / .env.example # 環境変数
│
├── dags/ # Airflow DAG 定義
│ ├── etl_raw_to_dwh.py # Raw → DWH の ETL DAG
│ ├── etl_dwh_to_mart.py # DWH → Mart の ETL DAG
│ ├── transforms/ # 変換ロジック
│ │ ├── raw_to_dwh.py # Raw → DWH 変換
│ │ └── dwh_to_mart.py # DWH → Mart 変換(MRR集計等)
│ └── tests/ # ユニットテスト
│ ├── test_raw_to_dwh.py
│ └── test_dwh_to_mart.py
│
├── db/ # データベース初期化
│ └── init/
│ ├── 01_create_schemas.sql # スキーマ作成
│ ├── 02_create_tables.sql # テーブル作成
│ └── 001_seed.sql # シードデータ
│
├── data/ # サンプルデータ
│ ├── generate_sample.py # データ生成スクリプト
│ └── sample/
│ ├── users.csv
│ ├── subscriptions.csv
│ └── orders.csv
│
├── metabase/ # Metabase ダッシュボード定義
│ └── dashboards/
│ ├── revenue-dashboard.json # MRR 分析ダッシュボード
│ └── churn-dashboard.json # 解約分析ダッシュボード
│
└── scripts/ # ユーティリティスクリプト
├── init-s3.sh # S3 (MinIO) 初期化
├── setup-metabase.py # Metabase セットアップ
└── setup-metabase.sh
docker-compose.yml
# データ分析基盤 PoC: Docker Compose 定義
# 全サービスを docker compose up -d で起動可能
# サービス起動順序: postgres → minio → data-init → airflow-init → airflow-* → metabase
services:
# === PostgreSQL(DWH/Mart/Airflow メタデータ DB)===
postgres:
image: postgres:16
container_name: poc-postgres
environment:
POSTGRES_USER: ${POSTGRES_USER:-analytics}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-analytics}
POSTGRES_DB: ${POSTGRES_DB:-analytics_db}
ports:
- "5435:5432"
volumes:
- postgres_data:/var/lib/postgresql/data
- ./db/init:/docker-entrypoint-initdb.d
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER:-analytics} -d ${POSTGRES_DB:-analytics_db}"]
interval: 5s
timeout: 5s
retries: 10
# === MinIO(S3 互換オブジェクトストレージ / データレイク)===
minio:
image: minio/minio:latest
container_name: poc-minio
environment:
MINIO_ROOT_USER: ${MINIO_ROOT_USER:-minioadmin}
MINIO_ROOT_PASSWORD: ${MINIO_ROOT_PASSWORD:-minioadmin}
ports:
- "9000:9000"
- "9001:9001"
volumes:
- minio_data:/data
command: server /data --console-address ":9001"
healthcheck:
test: ["CMD-SHELL", "mc ready local || exit 1"]
interval: 5s
timeout: 5s
retries: 10
# === data-init(S3 バケット作成 + サンプル CSV アップロード)===
data-init:
image: amazon/aws-cli:latest
container_name: poc-data-init
depends_on:
minio:
condition: service_healthy
postgres:
condition: service_healthy
environment:
AWS_ACCESS_KEY_ID: ${MINIO_ROOT_USER:-minioadmin}
AWS_SECRET_ACCESS_KEY: ${MINIO_ROOT_PASSWORD:-minioadmin}
AWS_DEFAULT_REGION: ${AWS_DEFAULT_REGION:-ap-northeast-1}
S3_ENDPOINT_URL: http://minio:9000
S3_BUCKET_NAME: ${S3_BUCKET_NAME:-data-lake}
volumes:
- ./scripts/init-s3.sh:/scripts/init-s3.sh:ro
- ./data/sample:/data/sample:ro
entrypoint: ["/bin/sh", "/scripts/init-s3.sh"]
restart: "no"
# === Airflow 初期化(DB マイグレーション + 管理者ユーザー作成)===
airflow-init:
image: apache/airflow:2.9.3-python3.11
container_name: poc-airflow-init
depends_on:
postgres:
condition: service_healthy
environment:
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://${POSTGRES_USER:-analytics}:${POSTGRES_PASSWORD:-analytics}@postgres:5432/${POSTGRES_DB:-analytics_db}
AIRFLOW__CORE__DAGS_FOLDER: /opt/airflow/dags
AIRFLOW__CORE__LOAD_EXAMPLES: "False"
_AIRFLOW_DB_MIGRATE: "true"
_AIRFLOW_WWW_USER_CREATE: "true"
_AIRFLOW_WWW_USER_USERNAME: ${AIRFLOW_ADMIN_USER:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${AIRFLOW_ADMIN_PASSWORD:-airflow}
entrypoint: /bin/bash
command:
- -c
- |
airflow db migrate
airflow users create \
--username $${_AIRFLOW_WWW_USER_USERNAME} \
--password $${_AIRFLOW_WWW_USER_PASSWORD} \
--firstname Admin \
--lastname User \
--role Admin \
--email admin@example.com || true
# Airflow Connection: MinIO S3
airflow connections delete aws_default 2>/dev/null || true
airflow connections add aws_default \
--conn-type aws \
--conn-extra '{"endpoint_url": "http://minio:9000", "aws_access_key_id": "minioadmin", "aws_secret_access_key": "minioadmin", "region_name": "ap-northeast-1"}'
# Airflow Connection: PostgreSQL DWH
airflow connections delete postgres_dwh 2>/dev/null || true
airflow connections add postgres_dwh \
--conn-type postgres \
--conn-host postgres \
--conn-port 5432 \
--conn-login $${POSTGRES_USER:-analytics} \
--conn-password $${POSTGRES_PASSWORD:-analytics} \
--conn-schema $${POSTGRES_DB:-analytics_db}
echo "=== Airflow 初期化完了 ==="
restart: "no"
# === Airflow Webserver(UI + REST API)===
airflow-webserver:
image: apache/airflow:2.9.3-python3.11
container_name: poc-airflow-webserver
depends_on:
airflow-init:
condition: service_completed_successfully
environment:
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://${POSTGRES_USER:-analytics}:${POSTGRES_PASSWORD:-analytics}@postgres:5432/${POSTGRES_DB:-analytics_db}
AIRFLOW__CORE__DAGS_FOLDER: /opt/airflow/dags
AIRFLOW__CORE__LOAD_EXAMPLES: "False"
AIRFLOW__API__AUTH_BACKENDS: airflow.api.auth.backend.basic_auth
AIRFLOW__WEBSERVER__EXPOSE_CONFIG: "True"
AIRFLOW__WEBSERVER__SECRET_KEY: ${AIRFLOW_SECRET_KEY:-a1b2c3d4e5f6a1b2c3d4e5f6}
# DAG で使用する追加パッケージ
_PIP_ADDITIONAL_REQUIREMENTS: "pandas>=2.0 boto3>=1.28 psycopg2-binary>=2.9"
# S3 接続用(DAG 内で boto3 直接使用時 → MinIO)
AWS_ACCESS_KEY_ID: ${MINIO_ROOT_USER:-minioadmin}
AWS_SECRET_ACCESS_KEY: ${MINIO_ROOT_PASSWORD:-minioadmin}
AWS_DEFAULT_REGION: ${AWS_DEFAULT_REGION:-ap-northeast-1}
S3_ENDPOINT_URL: http://minio:9000
S3_BUCKET_NAME: ${S3_BUCKET_NAME:-data-lake}
# DB 接続用(DAG 内で psycopg2 直接使用時)
POSTGRES_USER: ${POSTGRES_USER:-analytics}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-analytics}
POSTGRES_DB: ${POSTGRES_DB:-analytics_db}
ports:
- "8081:8080"
volumes:
- ./dags:/opt/airflow/dags
command: webserver
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8080/health || exit 1"]
interval: 10s
timeout: 10s
retries: 12
start_period: 30s
# === Airflow Scheduler(DAG スケジューリング・タスク実行)===
airflow-scheduler:
image: apache/airflow:2.9.3-python3.11
container_name: poc-airflow-scheduler
depends_on:
airflow-init:
condition: service_completed_successfully
environment:
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://${POSTGRES_USER:-analytics}:${POSTGRES_PASSWORD:-analytics}@postgres:5432/${POSTGRES_DB:-analytics_db}
AIRFLOW__CORE__DAGS_FOLDER: /opt/airflow/dags
AIRFLOW__CORE__LOAD_EXAMPLES: "False"
AIRFLOW__WEBSERVER__SECRET_KEY: ${AIRFLOW_SECRET_KEY:-a1b2c3d4e5f6a1b2c3d4e5f6}
# DAG で使用する追加パッケージ
_PIP_ADDITIONAL_REQUIREMENTS: "pandas>=2.0 boto3>=1.28 psycopg2-binary>=2.9"
# S3 接続用(DAG 内で boto3 直接使用時 → MinIO)
AWS_ACCESS_KEY_ID: ${MINIO_ROOT_USER:-minioadmin}
AWS_SECRET_ACCESS_KEY: ${MINIO_ROOT_PASSWORD:-minioadmin}
AWS_DEFAULT_REGION: ${AWS_DEFAULT_REGION:-ap-northeast-1}
S3_ENDPOINT_URL: http://minio:9000
S3_BUCKET_NAME: ${S3_BUCKET_NAME:-data-lake}
# DB 接続用(DAG 内で psycopg2 直接使用時)
POSTGRES_USER: ${POSTGRES_USER:-analytics}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-analytics}
POSTGRES_DB: ${POSTGRES_DB:-analytics_db}
volumes:
- ./dags:/opt/airflow/dags
command: scheduler
healthcheck:
test: ["CMD-SHELL", "airflow jobs check --job-type SchedulerJob --hostname $(hostname) || exit 1"]
interval: 15s
timeout: 10s
retries: 5
start_period: 30s
# === Metabase(BI ダッシュボード)===
metabase:
image: metabase/metabase:latest
container_name: poc-metabase
depends_on:
postgres:
condition: service_healthy
environment:
MB_DB_TYPE: h2
MB_JETTY_PORT: 3000
ports:
- "3000:3000"
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:3000/api/health || exit 1"]
interval: 10s
timeout: 10s
retries: 12
start_period: 30s
# === Metabase 初期化(データソース登録 + ダッシュボード自動作成)===
metabase-init:
image: python:3.11-slim
container_name: poc-metabase-init
depends_on:
metabase:
condition: service_healthy
postgres:
condition: service_healthy
environment:
METABASE_URL: http://metabase:3000
METABASE_ADMIN_EMAIL: ${METABASE_ADMIN_EMAIL:-admin@example.com}
METABASE_ADMIN_PASSWORD: ${METABASE_ADMIN_PASSWORD:-password}
DB_HOST: postgres
DB_PORT: "5432"
POSTGRES_DB: ${POSTGRES_DB:-analytics_db}
POSTGRES_USER: ${POSTGRES_USER:-analytics}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-analytics}
volumes:
- ./scripts/setup-metabase.py:/scripts/setup-metabase.py:ro
entrypoint: ["python3", "/scripts/setup-metabase.py"]
restart: "no"
volumes:
postgres_data:
minio_data:
Dockerを起動して、各種コンテナを起動します。
| サービス | 用途 | URL |
|---|---|---|
| MinIO S3 | データレイク(API: http://localhost:9000 / Console: http://localhost:9001) | http://localhost:9001 |
| PostgreSQL | DWH / データマート | localhost:5435 |
| Airflow | ETL オーケストレーション | http://localhost:8081 |
| Metabase | BI ダッシュボード | http://localhost:3000 |
$ docker compose up -d
[+] Running 9/9
✔ Network tun-202603_default Created 0.0s
✔ Container poc-minio Healthy 6.3s
✔ Container poc-postgres Healthy 7.2s
✔ Container poc-airflow-init Exited 43.5s
✔ Container poc-data-init Started 6.6s
✔ Container poc-metabase Healthy 48.5s
✔ Container poc-metabase-init Started 48.6s
✔ Container poc-airflow-webserver Started 43.6s
✔ Container poc-airflow-scheduler Started
MinIO

Airflow

Metabase
データソース→データレイク
Dockerコンテナ起動時にシェルスクリプトを実行し、AWS のAPIを使ってS3に以下のCSVファイルをアップロードします。
- users.csv : ユーザーデータ
- orders.csv : 注文データ
- subscriptions.csv : 購読データ
init-s3.sh
#!/bin/bash
# MinIO S3 初期化スクリプト
# バケット作成 + サンプル CSV アップロード(べき等)
set -euo pipefail
ENDPOINT_URL="${S3_ENDPOINT_URL:-http://minio:9000}"
BUCKET_NAME="${S3_BUCKET_NAME:-data-lake}"
REGION="${AWS_DEFAULT_REGION:-ap-northeast-1}"
DATA_DIR="/data/sample"
echo "=== S3 初期化開始 ==="
# バケット作成(既存の場合はスキップ)
echo "バケット作成: ${BUCKET_NAME}"
aws --endpoint-url "${ENDPOINT_URL}" \
s3 mb "s3://${BUCKET_NAME}" 2>/dev/null || echo "バケットは既に存在します"
# CSV アップロード
for file in "${DATA_DIR}"/*.csv; do
filename=$(basename "${file}")
echo "アップロード: ${filename} → s3://${BUCKET_NAME}/raw/${filename}"
aws --endpoint-url "${ENDPOINT_URL}" \
--region "${REGION}" \
s3 cp "${file}" "s3://${BUCKET_NAME}/raw/${filename}"
done
# アップロード確認
echo ""
echo "=== アップロード結果 ==="
aws --endpoint-url "${ENDPOINT_URL}" \
--region "${REGION}" \
s3 ls "s3://${BUCKET_NAME}/raw/"
echo "=== S3 初期化完了 ==="
CSVがアップロードされたMinIOのバケットは以下の通りです。

データレイク→DWH
AirflowのDAGを使って、MinIOバケット上のCSVファイルをDWHにロードします。ロード前にデータのバリデーションチェックを行い、不正データを検出します。
etl_raw_to_dwh.py
"""ETL DAG: S3 (raw) → DWH
S3 から CSV を取得し、変換ロジックで DWH レコードに変換後、
PostgreSQL の dwh スキーマに TRUNCATE + INSERT する。
"""
import os
from datetime import datetime
import boto3
import psycopg2
from airflow import DAG
from airflow.operators.python import PythonOperator
from transforms.raw_to_dwh import (
parse_orders_csv,
parse_subscriptions_csv,
parse_users_csv,
)
# 環境変数から接続情報を取得
S3_ENDPOINT_URL = os.environ.get("S3_ENDPOINT_URL", "http://minio:9000")
S3_BUCKET_NAME = os.environ.get("S3_BUCKET_NAME", "data-lake")
AWS_REGION = os.environ.get("AWS_DEFAULT_REGION", "ap-northeast-1")
DB_HOST = os.environ.get("DB_HOST", "postgres")
DB_PORT = os.environ.get("DB_PORT", "5432")
DB_NAME = os.environ.get("POSTGRES_DB", "analytics_db")
DB_USER = os.environ.get("POSTGRES_USER", "analytics")
DB_PASSWORD = os.environ.get("POSTGRES_PASSWORD", "analytics")
def _get_s3_client():
"""MinIO S3 クライアントを取得する。"""
return boto3.client(
"s3",
endpoint_url=S3_ENDPOINT_URL,
aws_access_key_id=os.environ.get("AWS_ACCESS_KEY_ID", "minioadmin"),
aws_secret_access_key=os.environ.get("AWS_SECRET_ACCESS_KEY", "minioadmin"),
region_name=AWS_REGION,
)
def _get_db_conn():
"""PostgreSQL 接続を取得する。"""
return psycopg2.connect(
host=DB_HOST,
port=DB_PORT,
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD,
)
def _fetch_csv_from_s3(key: str) -> str:
"""S3 から CSV テキストを取得する。"""
s3 = _get_s3_client()
response = s3.get_object(Bucket=S3_BUCKET_NAME, Key=key)
return response["Body"].read().decode("utf-8")
def load_users(**kwargs):
"""S3 から users.csv を取得し、dwh.users に TRUNCATE + INSERT する。"""
csv_text = _fetch_csv_from_s3("raw/users.csv")
records = parse_users_csv(csv_text)
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE dwh.users CASCADE")
for r in records:
cur.execute(
"""INSERT INTO dwh.users
(user_id, name, plan, registered_at, churn_date, segment)
VALUES (%s, %s, %s, %s, %s, %s)""",
(r["user_id"], r["name"], r["plan"],
r["registered_at"], r["churn_date"], r["segment"]),
)
conn.commit()
print(f"dwh.users: {len(records)} 件ロード完了")
finally:
conn.close()
def load_orders(**kwargs):
"""S3 から orders.csv を取得し、dwh.orders に TRUNCATE + INSERT する。"""
csv_text = _fetch_csv_from_s3("raw/orders.csv")
records = parse_orders_csv(csv_text)
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE dwh.orders CASCADE")
for r in records:
cur.execute(
"""INSERT INTO dwh.orders
(order_id, user_id, amount, category, ordered_at)
VALUES (%s, %s, %s, %s, %s)""",
(r["order_id"], r["user_id"], r["amount"],
r["category"], r["ordered_at"]),
)
conn.commit()
print(f"dwh.orders: {len(records)} 件ロード完了")
finally:
conn.close()
def load_subscriptions(**kwargs):
"""S3 から subscriptions.csv を取得し、dwh.subscriptions に TRUNCATE + INSERT する。"""
csv_text = _fetch_csv_from_s3("raw/subscriptions.csv")
records = parse_subscriptions_csv(csv_text)
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE dwh.subscriptions CASCADE")
for r in records:
cur.execute(
"""INSERT INTO dwh.subscriptions
(sub_id, user_id, plan, started_at, ended_at, monthly_fee)
VALUES (%s, %s, %s, %s, %s, %s)""",
(r["sub_id"], r["user_id"], r["plan"],
r["started_at"], r["ended_at"], r["monthly_fee"]),
)
conn.commit()
print(f"dwh.subscriptions: {len(records)} 件ロード完了")
finally:
conn.close()
# DAG 定義
with DAG(
dag_id="etl_raw_to_dwh",
description="S3 raw CSV → DWH テーブル(TRUNCATE + INSERT)",
schedule="0 1 * * *",
start_date=datetime(2026, 1, 1),
catchup=False,
tags=["etl", "raw-to-dwh"],
) as dag:
# users を先にロード(orders, subscriptions が FK 参照するため)
t_users = PythonOperator(
task_id="load_users",
python_callable=load_users,
)
t_orders = PythonOperator(
task_id="load_orders",
python_callable=load_orders,
)
t_subscriptions = PythonOperator(
task_id="load_subscriptions",
python_callable=load_subscriptions,
)
# users → (orders, subscriptions) の順序依存
t_users >> [t_orders, t_subscriptions]
DAGのトグルスイッチをONにすると、DAGが実行開始します。

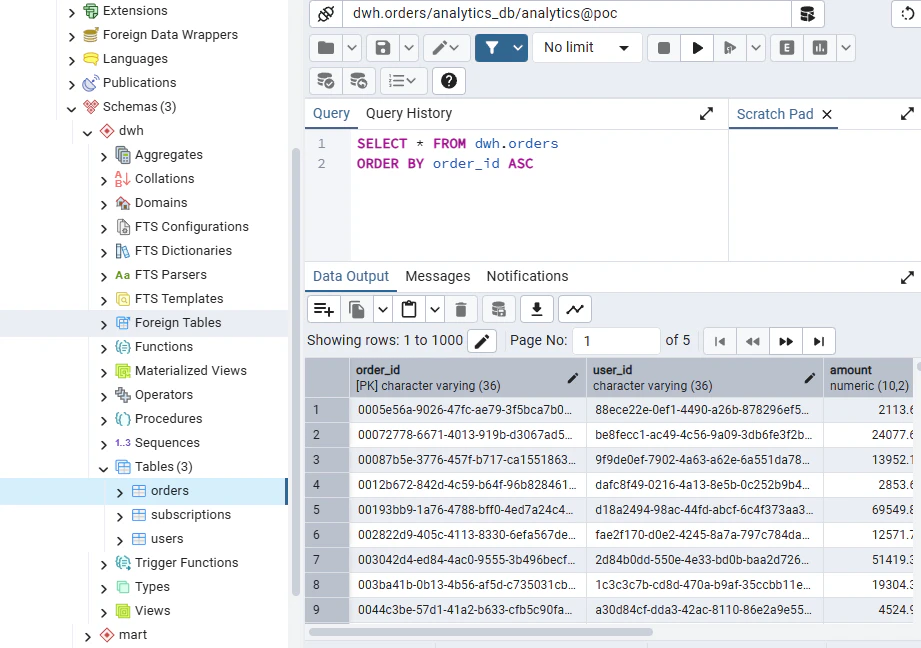
DAGが正常終了したら、PostgreSQLのdwhスキーマに定義したテーブルにCSVがロードされていることを確認しましょう。
DWH→データマート
AirflowのDAGを使って、DWHのテーブルを集計して、データマートに登録します。
etl_dwh_to_mart.py
"""ETL DAG: DWH → データマート
DWH テーブルからデータを取得し、集計ロジックで変換後、
mart スキーマに TRUNCATE + INSERT する。
"""
import os
from datetime import date, datetime
from decimal import Decimal
import psycopg2
from airflow import DAG
from airflow.operators.python import PythonOperator
from transforms.dwh_to_mart import calc_churn_summary, calc_mrr_summary, calc_revenue_summary
# 環境変数から接続情報を取得
DB_HOST = os.environ.get("DB_HOST", "postgres")
DB_PORT = os.environ.get("DB_PORT", "5432")
DB_NAME = os.environ.get("POSTGRES_DB", "analytics_db")
DB_USER = os.environ.get("POSTGRES_USER", "analytics")
DB_PASSWORD = os.environ.get("POSTGRES_PASSWORD", "analytics")
# 集計対象期間(2024-01 〜 2025-12 の 24 ヶ月)
YEAR_MONTHS = [f"{y:04d}-{m:02d}" for y in range(2024, 2026) for m in range(1, 13)]
def _get_db_conn():
"""PostgreSQL 接続を取得する。"""
return psycopg2.connect(
host=DB_HOST,
port=DB_PORT,
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD,
)
def _fetch_users() -> list[dict]:
"""dwh.users からレコードを取得する。"""
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute(
"SELECT user_id, name, plan, registered_at, churn_date, segment FROM dwh.users"
)
columns = [desc[0] for desc in cur.description]
return [dict(zip(columns, row)) for row in cur.fetchall()]
finally:
conn.close()
def _fetch_orders() -> list[dict]:
"""dwh.orders からレコードを取得する。"""
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute(
"SELECT order_id, user_id, amount, category, ordered_at FROM dwh.orders"
)
columns = [desc[0] for desc in cur.description]
rows = []
for row in cur.fetchall():
record = dict(zip(columns, row))
# psycopg2 が返す amount を Decimal に変換
record["amount"] = Decimal(str(record["amount"]))
rows.append(record)
return rows
finally:
conn.close()
def _fetch_subscriptions() -> list[dict]:
"""dwh.subscriptions からレコードを取得する。"""
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute(
"SELECT sub_id, user_id, plan, started_at, ended_at, monthly_fee FROM dwh.subscriptions"
)
columns = [desc[0] for desc in cur.description]
rows = []
for row in cur.fetchall():
record = dict(zip(columns, row))
record["monthly_fee"] = Decimal(str(record["monthly_fee"]))
rows.append(record)
return rows
finally:
conn.close()
def build_churn_summary(**kwargs):
"""チャーン率サマリーを計算し mart.churn_summary に格納する。"""
users = _fetch_users()
results = calc_churn_summary(users, YEAR_MONTHS)
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE mart.churn_summary")
for r in results:
cur.execute(
"""INSERT INTO mart.churn_summary
(year_month, plan, active_start, churned, churn_rate)
VALUES (%s, %s, %s, %s, %s)""",
(r["year_month"], r["plan"], r["active_start"],
r["churned"], float(r["churn_rate"])),
)
conn.commit()
print(f"mart.churn_summary: {len(results)} 件ロード完了")
finally:
conn.close()
def build_revenue_summary(**kwargs):
"""売上サマリーを計算し mart.revenue_summary に格納する。"""
users = _fetch_users()
orders = _fetch_orders()
results = calc_revenue_summary(orders, users, YEAR_MONTHS)
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE mart.revenue_summary")
for r in results:
cur.execute(
"""INSERT INTO mart.revenue_summary
(year_month, plan, total_revenue, order_count)
VALUES (%s, %s, %s, %s)""",
(r["year_month"], r["plan"], float(r["total_revenue"]),
r["order_count"]),
)
conn.commit()
print(f"mart.revenue_summary: {len(results)} 件ロード完了")
finally:
conn.close()
def build_mrr_summary(**kwargs):
"""MRR サマリーを計算し mart.mrr_summary に格納する。"""
subscriptions = _fetch_subscriptions()
results = calc_mrr_summary(subscriptions, YEAR_MONTHS)
conn = _get_db_conn()
try:
with conn.cursor() as cur:
cur.execute("TRUNCATE TABLE mart.mrr_summary")
for r in results:
cur.execute(
"""INSERT INTO mart.mrr_summary
(year_month, plan, active_subs, total_mrr, new_mrr, churned_mrr, net_new_mrr)
VALUES (%s, %s, %s, %s, %s, %s, %s)""",
(r["year_month"], r["plan"], r["active_subs"],
float(r["total_mrr"]), float(r["new_mrr"]),
float(r["churned_mrr"]), float(r["net_new_mrr"])),
)
conn.commit()
print(f"mart.mrr_summary: {len(results)} 件ロード完了")
finally:
conn.close()
# DAG 定義
with DAG(
dag_id="etl_dwh_to_mart",
description="DWH → データマート(チャーン率・売上集計、TRUNCATE + INSERT)",
schedule="0 2 * * *",
start_date=datetime(2026, 1, 1),
catchup=False,
tags=["etl", "dwh-to-mart"],
) as dag:
t_churn = PythonOperator(
task_id="build_churn_summary",
python_callable=build_churn_summary,
)
t_revenue = PythonOperator(
task_id="build_revenue_summary",
python_callable=build_revenue_summary,
)
t_mrr = PythonOperator(
task_id="build_mrr_summary",
python_callable=build_mrr_summary,
)
# チャーン・売上・MRR は独立して実行可能
[t_churn, t_revenue, t_mrr]
DAGを実行します。

DAGが正常終了したら、PostgreSQLのmartスキーマに定義したテーブルにCSVがロードされていることを確認しましょう。

データマート→データ分析ツール
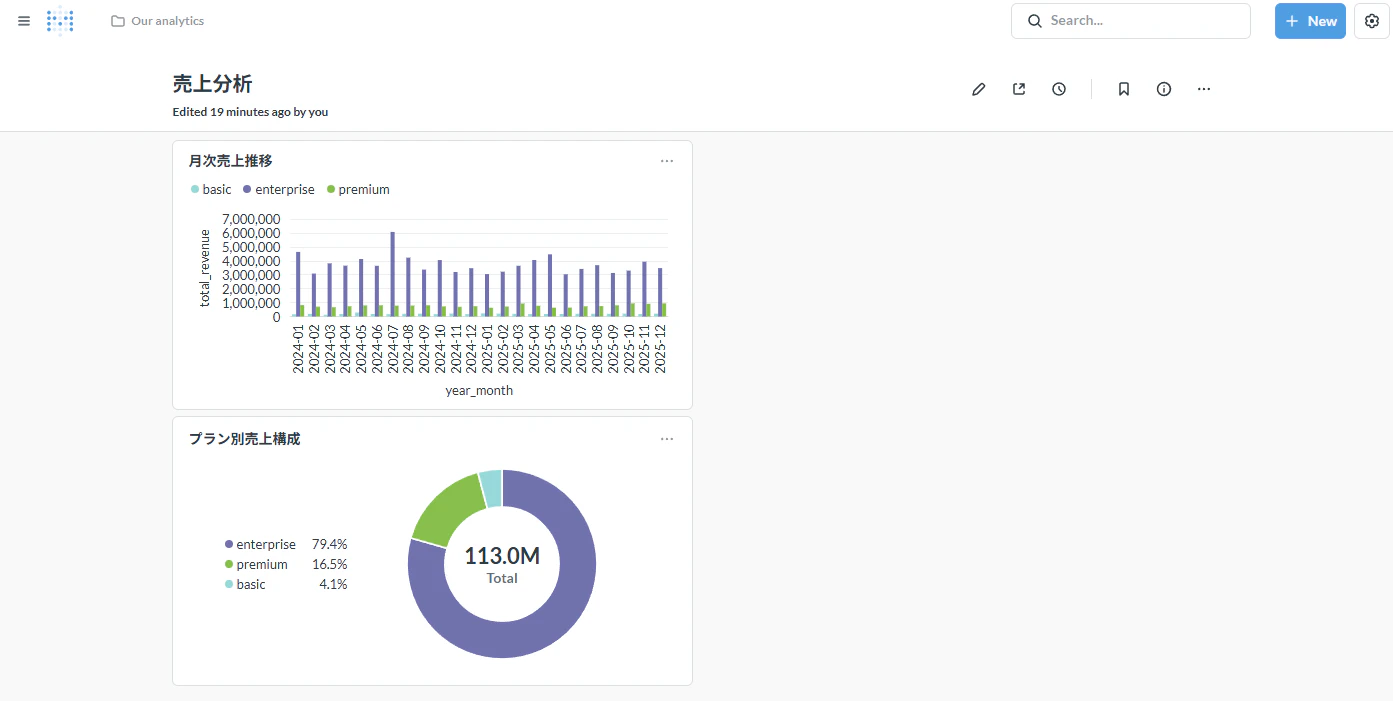
データマートのテーブルを、データ分析ツールのMetabase で読み込み、以下のダッシュボードを作成します。
チャーン率分析

売上分析
MRR分析

まとめ
今回は、データ分析の裏側で動く“データパイプライン”の全体像と、その設計・運用を担うデータエンジニアの役割について、実践的な視点で解説しました。
データ分析は、正確でタイムリーなデータがあってこそ価値を生み出せます。
つまり、分析の成果はパイプラインの品質に大きく依存します。データが正しく流れ、整い、蓄積され、活用されるまでの一連の仕組みを理解することは、分析者・エンジニア双方にとって重要です。
自分の業務で扱っているデータが、どのような流れで届いているのかを一度棚卸ししてみると、どこにボトルネックがあるか、どこを自動化できるかが見えてくるでしょう。
今回紹介したAirflowなどのツールを試しに触ってみて、パイプライン設計を体感してみてください。
一緒にデータパイプラインについて学んでいきたいなど、ご興味を持たれた方は、弊社ホームページからお問い合わせいただければ幸いです。