
はじめに
どうも、ボン♡キュッ♡ボンは僕のモノ♡
プラチナ☆みゆきである。
さて、開始早々読者諸氏に断っておきたいことがある。
※本記事は技術記事に見せかけた女性声優考察記事である。
Spotifyとアニソン
さて、突然だがアニソンとSpotifyは相性が良いように思う。
なぜなら、アニオタは比較的箱推しの人が多いというのとアニソンだったらなんでも聞く雑食の人が多いように思えるからだ。
現に私もアニソンは特定の曲を聞くというよりはメドレーで聞くということの方が多い。
そういう用途ではApple等で特定の音楽を聞くよりも、Spotifyでレコメンドされたものや他の人が作ったプレイリストを聞く方が面白かったりするんじゃないかと思う。
Spotifyと女性声優
Spotifyが面白い理由の一つに豊富なAPIを提供している事が挙げられる。
割といろんな機能があるのだが、今回はアーティストの関連アーティストを取得することに関心がいった。
(APIレファレンスに関してはこちらSpotify API Reference)
女性声優の関連アーティストを掘っていったら女性声優の勢力図的なものが出来上がるんじゃないかと思ったのだ。
あとは思い立ったが吉日である。
「APIを叩けば解るんだ。いい加減に始めようぜ、魔術師!」
実施手順
OAuth2によるアクセストークンの発行
まずSpotifyアカウントを持ってない人はアカウントを作ろう。2秒くらいで終わるだろう。
https://www.spotify.com/jp/
次にデベロッパー向けサイトでアプリ登録を行う。登録からアクセストークンの発行まで20秒くらいで終わるから親切である。
https://beta.developer.spotify.com/dashboard/
spotipyによるspotify-apiの活用
次に、spotipyによってspotify-apiを活用していく。
spotipyはpythonでspotify-apiを利用するためのライブラリである。ドキュメントはこちら
まず、pipからspotipyをインストールする。
$ pip install spotipy
次に、発行したアクセストークンで設定ファイルを作成する。"CLIENT_ID"と"CLIENT_SECRET"は各々のものに置換しよう。
import spotipy
client_id = "CLIENT_ID"
client_secret = "CLIENT_SECRET"
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
まずは試しに上坂すみれ女史の情報を取得してみるとしよう。
本題に入る前に、私の上坂すみれ女史に対する入れ込みについて解説しておく。
私が上坂すみれ女史をよく聞くようになったのは2013年1stシングル「七つの海よりキミの海」がリリースされた頃だったように思う。そこからすげえプロパガンダで啓蒙的な人だなあと思いドハマり。
以降は上坂すみれ女史に憧れて大学の第二言語にロシア語を選択するまでになった。
まことにХорошо!
さて、ということで女史の名前は日本語かロシア語で検索したいところだが、あいにく英語名しか対応していないためここは素直に英語名で検索する。
from pprint import pprint
from config import spotify
name = 'Sumire Uesaka'
spotapi_out = spotify.search(q='artist:' + name, type='artist')
artist_items = spotapi_out['artists']['items'][0]
pprint(artist_items)
結果がこちら
{'external_urls': {'spotify': 'https://open.spotify.com/artist/4hRg5l2hXQl3lAzffFF8P8'},
'followers': {'href': None, 'total': 30901},
'genres': ['anime', 'denpa-kei', 'seiyu'],
'href': 'https://api.spotify.com/v1/artists/4hRg5l2hXQl3lAzffFF8P8',
'id': '4hRg5l2hXQl3lAzffFF8P8',
'images': [{'height': 640,
'url': 'https://i.scdn.co/image/7757cd7179ec94ac7f516ee6fe581694d0695ad0',
'width': 640},
{'height': 320,
'url': 'https://i.scdn.co/image/26ffea4fdd66890a3f9a7db53f0b474043a25663',
'width': 320},
{'height': 160,
'url': 'https://i.scdn.co/image/1973d72603d14f24d2bba61000aaf9b32f14b850',
'width': 160}],
'name': 'Sumire Uesaka',
'popularity': 51,
'type': 'artist',
'uri': 'spotify:artist:4hRg5l2hXQl3lAzffFF8P8'}
ジャンル:[アニメ、電波系、声優]とある。
電波系か~。電波系なんだよな~~。
いやーそこが良いんだよな~~~!!!
まったく電波ソングは最高だぜっ!
とまあこんな感じで。
spotify-apiはアーティストやアルバム、あとはリコメンデーションなどの情報が取得できるのだ。
続いて、上坂すみれ女史の関連アーティスト情報を見てみよう。
from config import spotify
name = 'Sumire Uesaka'
spotapi_out = spotify.search(q='artist:' + name, type='artist')
artist_items = spotapi_out['artists']['items'][0]
artist_id = artist_items['id']
spotapi_out_related = spotify.artist_related_artists(artist_id)
atrname_related_list = []
for artname_related in spotapi_out_related['artists']:
atrname_related_list.append(artname_related['name'])
print(atrname_related_list)
結果がこちら。
['Maaya Uchida', 'Yui Ogura', 'Yukari Tamura', 'TrySail', '伊藤美来', '大橋彩香', 'Inori Minase', 'Kaori Ishihara', 'Plasmagica', '悠木 碧', 'Yui Horie', 'Suzuko Mimori', 'Wake Up, Girls!', 'Petit Milady', '亜咲花', 'Shiina Natsukawa', '中島愛', '
田所あずさ', 'fhána', 'DIALOGUE+']
これはSpotifyの関連アーティストと同じ情報なので、本家のUIの検索結果を掲示しておく。
かわいいという意味でまあやたそと関連性があるし、
同じくかわいいという意味で小倉唯ちゃんと関連性があるし、
軍隊を保有するという意味でゆかりんと関連性があるから
妥当な結果だと言えるだろう。
アーティストごとの関係データを作成
上坂すみれ女史に関連するアーティスト情報を取得したところで、次に関連するアーティストの更に関連するアーティストを取得していく。このように関連するアーティストの関連データを作っていくのだ。
関連アーティストの情報はいったんpandasのSeriesとして採取し、DataFrameへと結合していく。
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
from pprint import pprint
from config import spotify
from tqdm import tqdm
def find_artists(name):
""" 最初の探索 """
artist_df = pd.DataFrame(columns=['artist_name', 'artist_ID', 'genres', 'popularity', 'related_artist_names'])
spotapi_out = spotify.search(q='artist:' + name, type='artist')
artist_items = spotapi_out['artists']['items'][0]
artist_id = artist_items['id']
artid_list = [artist_id]
atrname_related_list = []
spotapi_out_related = spotify.artist_related_artists(artist_id)
for artname_related in spotapi_out_related['artists']:
atrname_related_list.append(artname_related['name'])
sr = pd.Series([artist_items['name'], artist_items['id'], artist_items['genres'], artist_items['popularity'], atrname_related_list], index=artist_df.columns)
artist_df = artist_df.append(sr, ignore_index=True)
return artid_list, artist_df
def find_related_artists(depth):
""" depth分類似するアーティストを探索する """
# 名前は英語名でないと正常に返ってこないので注意
artid_list, artist_df = find_artists('Sumire Uesaka')
artid_list_tail = 0
for i in range(depth):
artid_list_head = artid_list_tail
artid_list_tail = len(artid_list)
for artid in tqdm(artid_list[artid_list_head:artid_list_tail]):
spotapi_out = spotify.artist_related_artists(artid)
for artid_related in spotapi_out['artists']:
# 類似のアーティストリストを作成
artname_related2_list = []
spotapi_out_related = spotify.artist_related_artists(artid_related['id'])
for artname_related2 in spotapi_out_related['artists']:
artname_related2_list.append(artname_related2['name'])
artid_list.append(artid_related['id'])
sr = pd.Series([artid_related['name'], artid_related['id'], artid_related['genres'],
artid_related['popularity'], artname_related2_list], index=artist_df.columns)
artist_df = artist_df.append(sr ,ignore_index=True)
return artid_list, artist_df
artid_list, artist_df = find_related_artists(1)
print(artist_df)
得られたDataFrameがこちら。
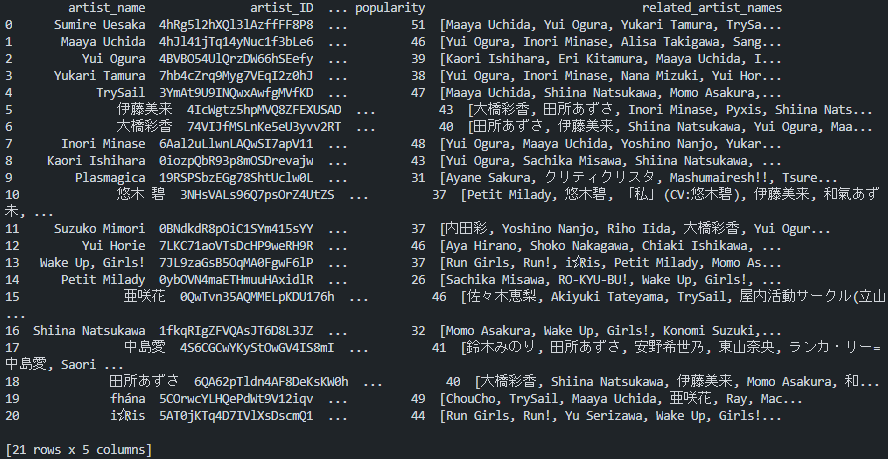
次にDataFrameの中から関連アーティストの情報だけを抽出したdictデータを作る。
######
### 前回のコードの続きに書く
######
# アーティストの関係辞書を作る
artdic = {}
for i in range(len(artid_list)):
artdic[artist_df.iloc[i,0]] = []
for artname_related in artist_df.iloc[i,4]:
artdic[artist_df.iloc[i,0]].append(artname_related)
print(artdic)
結果は長いので一部を以下に記載。
{'Sumire Uesaka': ['Maaya Uchida', 'Yui Ogura', 'Yukari Tamura', 'TrySail', '伊藤美来', '大橋彩香', 'Inori Minase', 'Kaori Ishihara', 'Plasmagica', '悠木 碧', 'Suzuko Mimori', 'Yui Horie', 'Wake Up, Girls!', 'Petit Milady', '亜咲花', 'Shiina Natsukawa', '中島愛', '田所あずさ', 'fhána', 'i☆Ris'], 'Maaya Uchida': ['Yui Ogura', 'Inori Minase', 'Alisa Takigawa', 'Sangatsu no Phantasia', 'mimimemeMIMI', 'Aimi', 'DIALOGUE+', 'Saori Hayami', 'Wake Up, Girls!', 'Yoshino Nanjo', 'i☆Ris', 'Shiina Natsukawa',
'Yui Horie', 'Petit Milady', 'Machico', 'Konomi Suzuki', 'Ayana Taketatsu', '大橋彩香', 'TrySail', 'Yu Serizawa'], 'Yui Ogura': ['Kaori Ishihara', 'Eri Kitamura', 'Maaya Uchida', 'Inori Minase', 'Yukari Tamura', 'Ayana Taketatsu', 'Yoshino Nanjo', 'Aimi', 'Saori Hayami', 'Amamiya Sora', 'Shiina Natsukawa', 'Yui Horie', 'Petit Milady', 'Yu Serizawa', 'Aki Toyosaki', '大橋彩香', 'TrySail', 'Momo Asakura', '伊藤美来', 'Suzuko Mimori'], 'Yukari Tamura': ['Yui Ogura', 'Inori Minase', 'Nana Mizuki', 'Yui
Horie', 'KOTOKO', '栗林みな実', 'Miyuki Hashimoto', 'Petit Milady', '大橋彩香', 'Sphere', "May'n", 'TrySail', 'Maaya Uchida',
'佐咲紗花', '田所あずさ', 'ELISA', '茅原実里', 'ChouCho', 'Eri Kitamura', 'Suzuko Mimori'], ... }
networkxによる女性声優勢力図の可視化
最後に、前項で得たアーティストごとの関係辞書をもとにnetworkxを使って女性声優勢力図を可視化していく。
networkxというのはpythonでグラフを可視化するためのライブラリである。今回はちょっとしか使わないがかなり汎用性の高いライブラリであるように思う。
ドキュメントはこちら
あと、初学者の方はこちらから読むと理解がスムーズかもしれない。
まずはnetworkxをインストール。
$ pip install networkx
それでは上坂すみれ女史を震源にした関連アーティスト20人の関係データ。つまり重複を除かずに400人分のデータを可視化していく(実際には重複するアーティストは一意にするので400人よりは少ない)
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
from pprint import pprint
from config import spotify
from tqdm import tqdm
######
### 前回のコードの続きに書く
######
# nodeとedgeの設定
G = nx.Graph()
G.add_nodes_from(list(artdic.keys()))
for parent in artdic.keys():
relation = [(parent, child) for child in artdic[parent]]
G.add_edges_from(relation)
# sizeとcolorの設定
average_deg = sum(d for n, d in G.degree()) / G.number_of_nodes()
sizes = [1000*d/average_deg for n, d in G.degree()]
colors = [i/len(G.nodes) for i in range(len(G.nodes))]
plt.figure(figsize=(20,20))
nx.draw(G, font_family='Yu Gothic', with_labels=True, node_size=sizes, node_color=colors)
plt.savefig('depth1.png')
plt.show()
得られた結果がこちら。
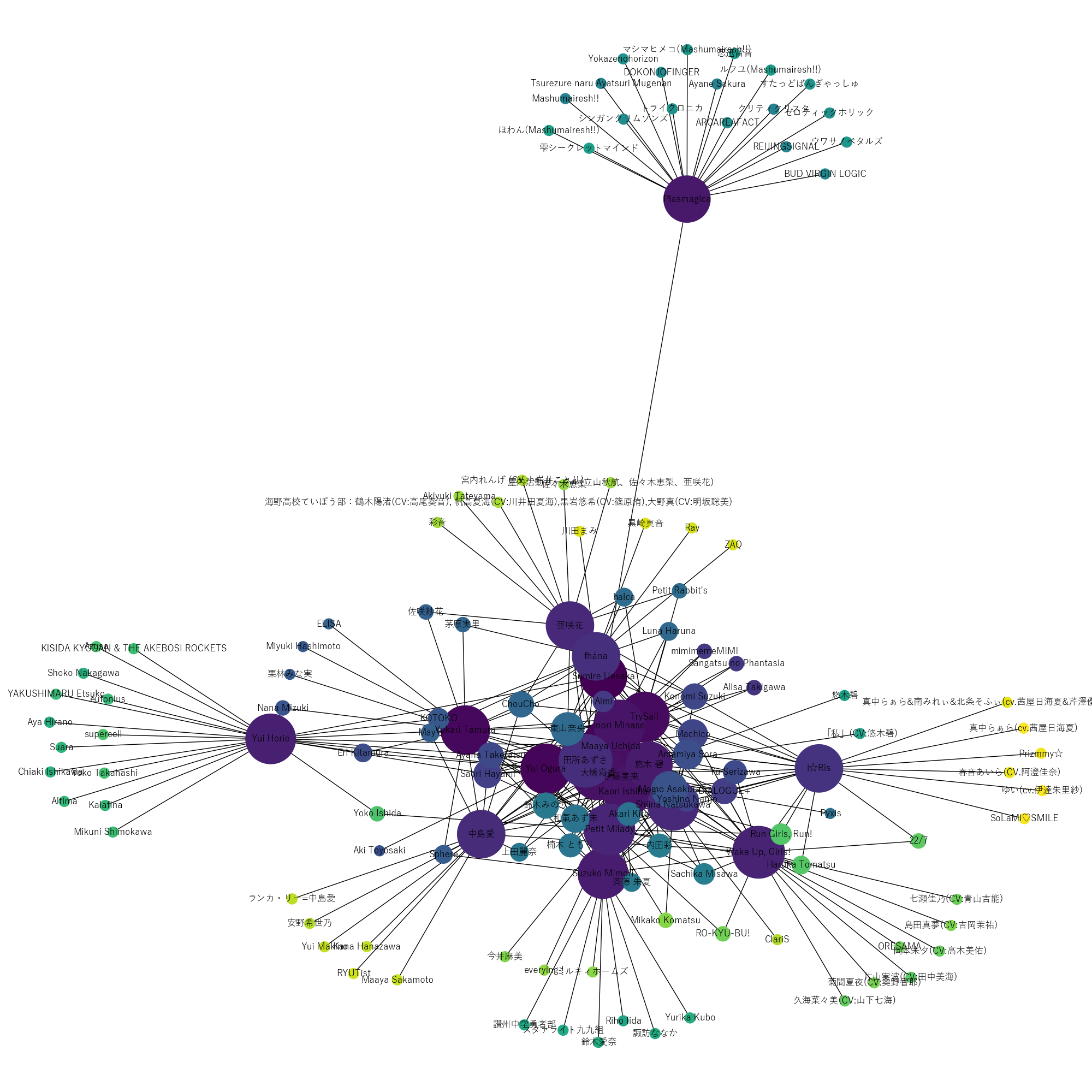
震源地である南の方の本土に女性声優が集まっているのがわかる(ここでは上下左右を東西南北と形容する)
上坂すみれ女史(Sumire Uesaka)は本土の少し上の方に位置している。
上坂すみれ女史を震源にしたが、本土の中心(女性声優の重心)は[内田真礼、大橋彩香、水瀬いのり、小倉唯、悠木碧、伊藤美来]などのいかにも女性声優達で構成されているのは面白い。
まあ、上坂すみれ女史は女性声優的特異点なので当然の帰結だろうか。
あとは関係ネットワークの特徴的に電車の路線図みたいに関係性のハブとなる人物が可視化されているのが面白い。
例えば、北部のSHOW BY ROCK!!島のハブを成すのはPlasmagicaであったり、西部のアニソンシンガーに接続するのは堀江由衣であったり、東部のプリパラ地方に向かうためには芹澤優から所属グループi☆Risを経由する必要があること等が伺える。
では最後に、次数を増やしておよそ8000人(20 ^ 3)規模の女性声優勢力図を確認していこう。
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
from pprint import pprint
from config import spotify
from tqdm import tqdm
def find_artists(name):
""" 最初の探索 """
artist_df = pd.DataFrame(columns=['artist_name', 'artist_ID', 'genres', 'popularity', 'related_artist_names'])
spotapi_out = spotify.search(q='artist:' + name, type='artist')
artist_items = spotapi_out['artists']['items'][0]
artist_id = artist_items['id']
artid_list = [artist_id]
atrname_related_list = []
spotapi_out_related = spotify.artist_related_artists(artist_id)
for artname_related in spotapi_out_related['artists']:
atrname_related_list.append(artname_related['name'])
sr = pd.Series([artist_items['name'], artist_items['id'], artist_items['genres'], artist_items['popularity'], atrname_related_list], index=artist_df.columns)
artist_df = artist_df.append(sr, ignore_index=True)
return artid_list, artist_df
def find_related_artists(depth):
""" depth分類似するアーティストを探索する """
# 名前は英語名でないと正常に返ってこないので注意
artid_list, artist_df = find_artists('Sumire Uesaka')
artid_list_tail = 0
for i in range(depth):
artid_list_head = artid_list_tail
artid_list_tail = len(artid_list)
for artid in tqdm(artid_list[artid_list_head:artid_list_tail]):
spotapi_out = spotify.artist_related_artists(artid)
for artid_related in spotapi_out['artists']:
# 類似のアーティストリストを作成
artname_related2_list = []
spotapi_out_related = spotify.artist_related_artists(artid_related['id'])
for artname_related2 in spotapi_out_related['artists']:
artname_related2_list.append(artname_related2['name'])
artid_list.append(artid_related['id'])
sr = pd.Series([artid_related['name'], artid_related['id'], artid_related['genres'],
artid_related['popularity'], artname_related2_list], index=artist_df.columns)
artist_df = artist_df.append(sr ,ignore_index=True)
return artid_list, artist_df
artid_list, artist_df = find_related_artists(1)
print(artist_df)
# アーティストの関係辞書を作る
artdic = {}
for i in range(len(artid_list)):
artdic[artist_df.iloc[i,0]] = []
for artname_related in artist_df.iloc[i,4]:
artdic[artist_df.iloc[i,0]].append(artname_related)
print(artdic)
# nodeとedgeの設定
G = nx.Graph()
G.add_nodes_from(list(artdic.keys()))
for parent in artdic.keys():
relation = [(parent, child) for child in artdic[parent]]
G.add_edges_from(relation)
# sizeとcolorの設定
average_deg = sum(d for n, d in G.degree()) / G.number_of_nodes()
sizes = [1000*d/average_deg for n, d in G.degree()]
colors = [i/len(G.nodes) for i in range(len(G.nodes))]
# 探索する次数によってfigsizeを変更
plt.figure(figsize=(50,50))
nx.draw(G, font_family='Yu Gothic', with_labels=True, node_size=sizes, node_color=colors)
plt.savefig('depth2.png')
plt.show()
結果がこちら。
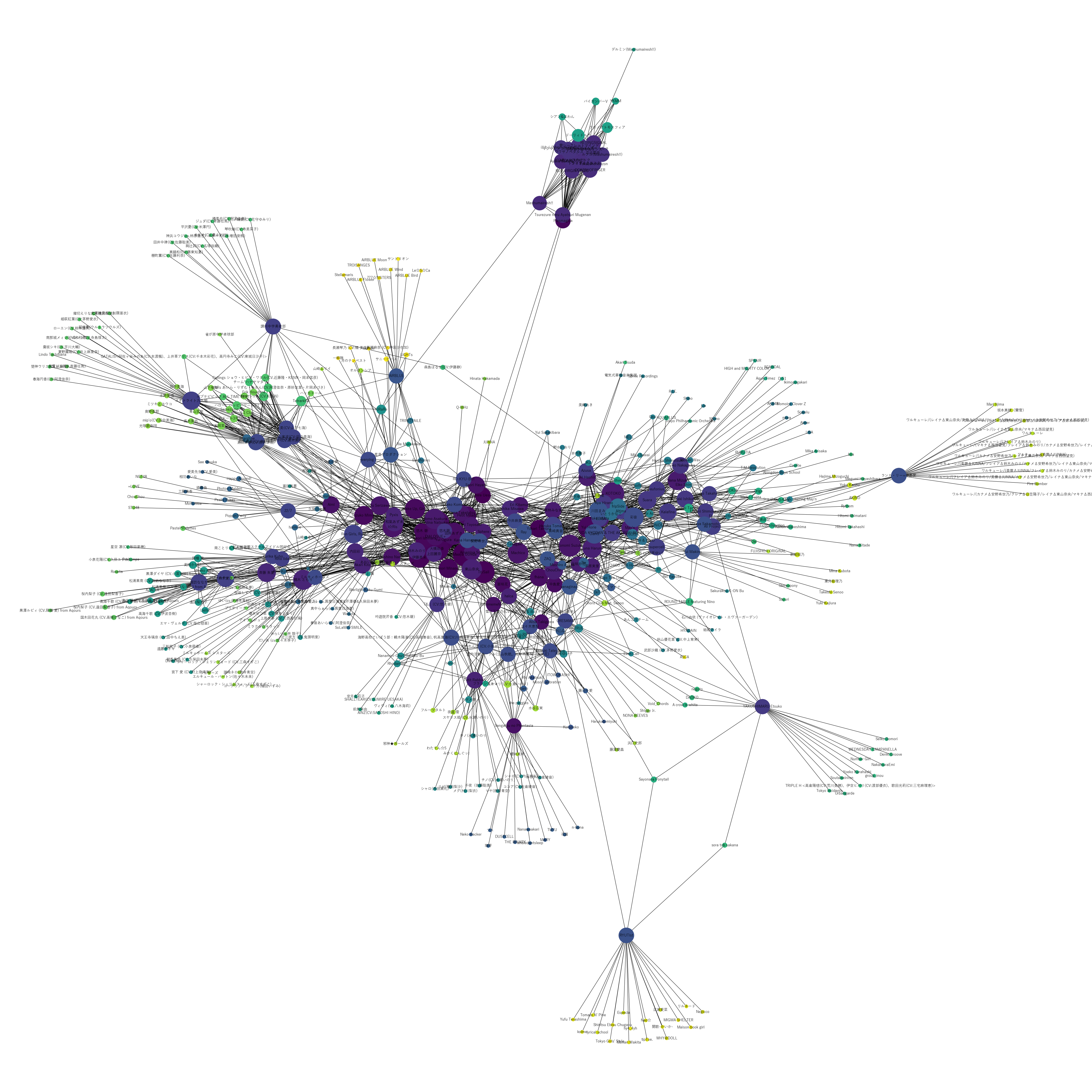
多すぎてよく見えない。
少し拡大しよう。

左の紫色の箇所。ここが女性声優地方である。
中心部にはゆいかおり、悠木碧、田所あずさ、大橋彩香等で構成されているのがわかる。
その中心部に攻め入るように南東の方から女性声優第6世代の水瀬いのり、雨宮天、南西の方から第7世代の伊藤美来、少し離れて鬼頭明里、楠木ともりが位置しているのがわかる。
参考:女性声優における世代分け
参考:女性声優世代一覧

参考:女性声優界の黒船。第7世代から伊藤美来氏
さて、上図の解説に戻るが女性声優地方を左に見て右にあるのがアニソン地方・ゲーソン地方である。
女性声優地方から、今井麻美、田村ゆかり、Machico、亜咲花をハブにしてアニソン地方に接続していることがわかる。
アニソン地方を構成するのは、鈴木このみ、ChouCho、fhana、春奈るな、ClariS等であることがわかる。
そこからゲーソン地方に接続している。
アニソン地方を構成するのは、KOTOKO、川田まみ、fripside、彩音、橋本みゆき等だろうか。
ちなみに、私はゲーソンも大好きである。
ゲーソンは良いゾ~~~
さて、本土の女性声優・アニソン・ゲーソン地方を概観したところで最後に少し離れた地方を分析して終わろう。
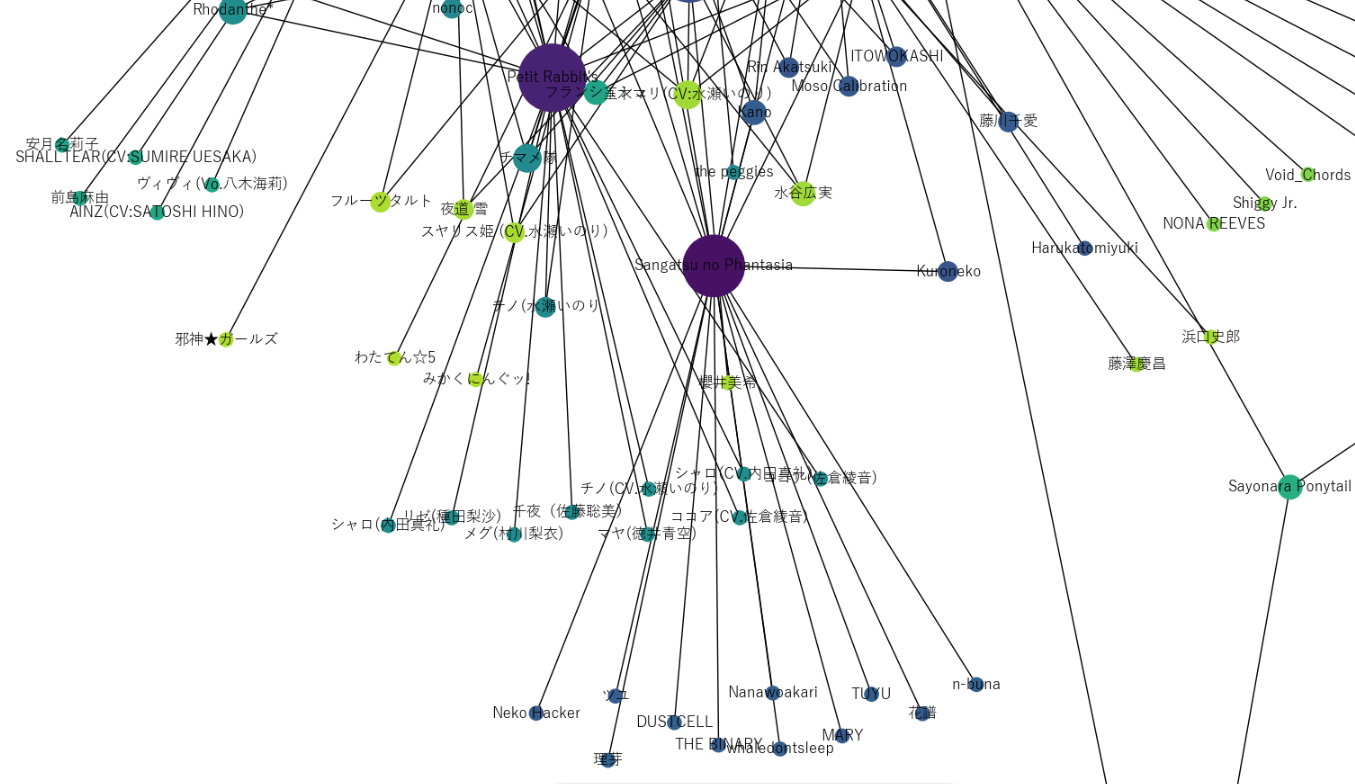
まずは南部。
なんと言っても注目すべきは「Petit Rabbit's」
この世の癒しを全て詰め込んだような楽曲を提供するご存知ごちうさグループである。

参考:ご注文はうさぎですか?
**ご注文はうさぎに決まっている。**なんならうさぎのうさぎ添え、うさぎマシマシまである()
ちなみに、私のおすすめ曲は「魔法少女チノ」
明日も強く生きようという勇気を貰える気がするのだ。
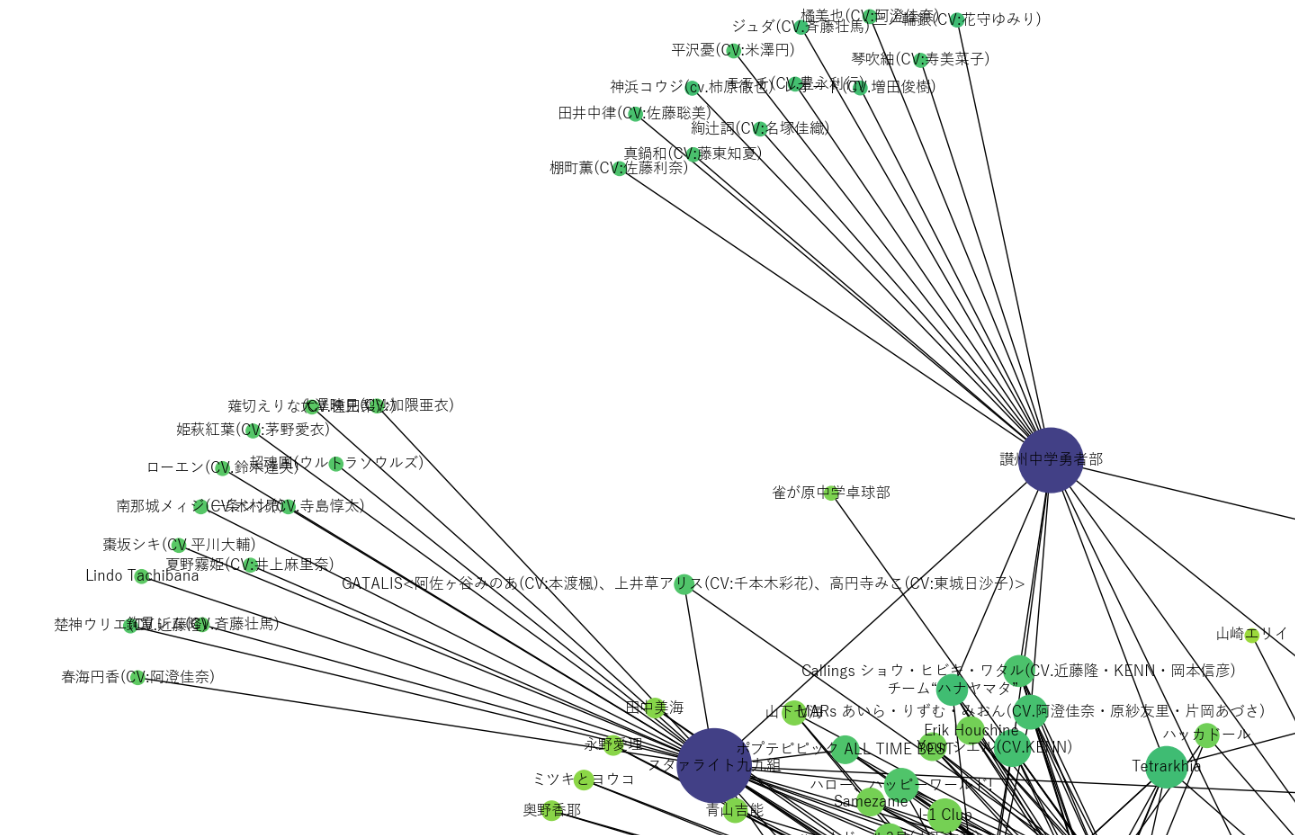
次に北西部。
讃州中学勇者部やスタァライト九九組がハブになっていることがわかるだろう。また、バンドリアーティストも散見される。
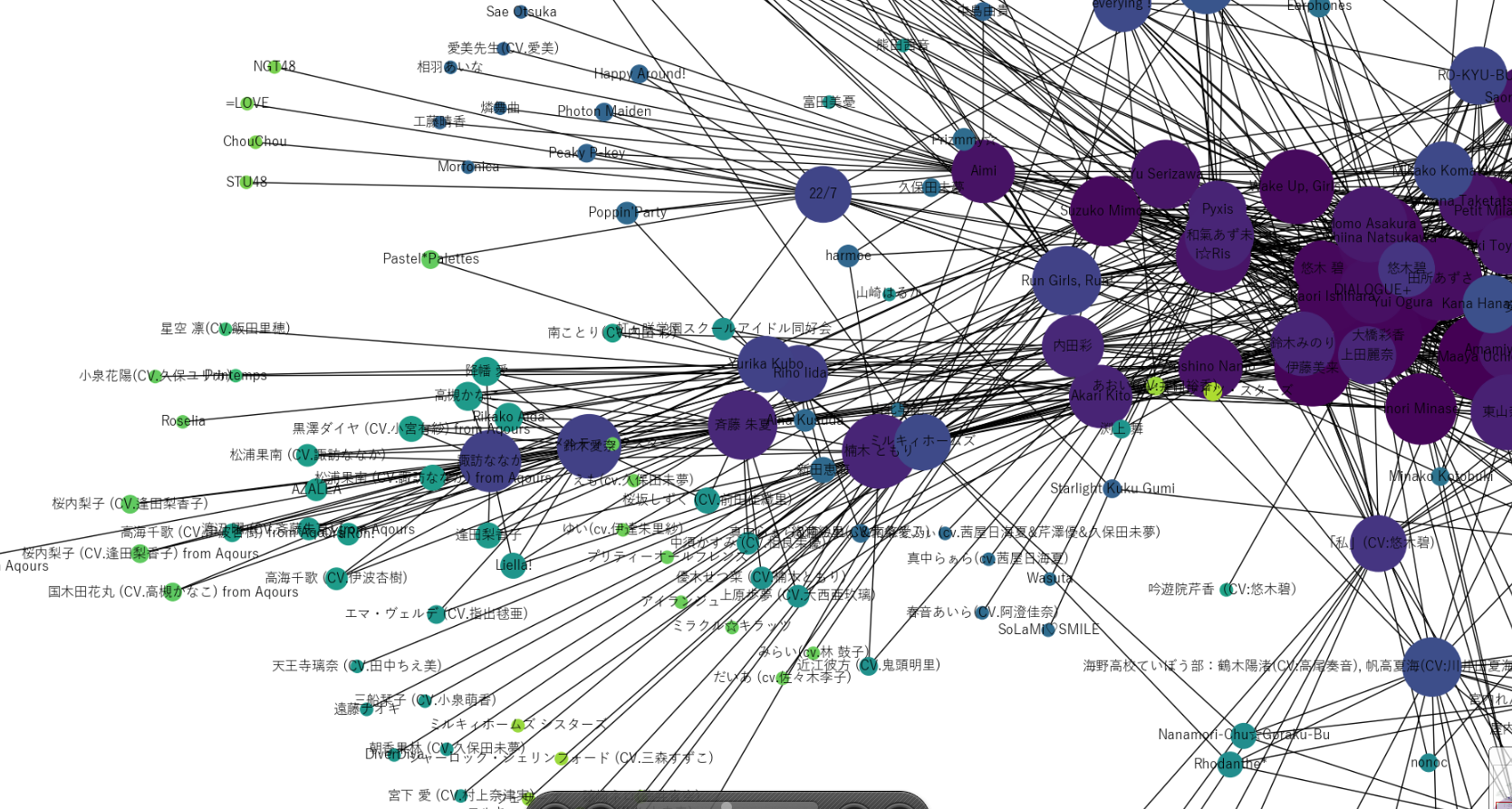
最後にに西部。
ラブライブ!勢力が幅を利かせていることがわかる。
あとラブライブ!の横にミルキィホームズが位置しているのも面白い。ミルキィホームズはラブライブ!声優である三森すずこ、徳井青空が所属していることから実質ラブライブという意見もあった。
あとは、22/7という2.5次元アイドルユニットをハブにしてNGT48などの3次元アイドルに接続している様子も伺える。
おわりに
これにて分析は終わりだが最後に一つ言っておきたいことがある。
北西部、西部。
ほとんど三森すずこじゃねぇか!!!
いや、私は三森すずこ女史大好きだから良いんだけどね。
讃州中学勇者部もスタァライト九九組もラブライブ!もミルキィホームズも私から言わせれば三森すずこなのである。
なんという三森すずこ勢力、さすがはブシ〇ード。
(ちなみに私のおすすめ曲は「ファッとして桃源郷」)

参考:女性声優界の絶対強者。三森すずこ氏
Code
今回のCodeと結果画像はこちらに格納している。
記事では8,000人規模の紹介までに留めたが、160,000人規模のdepth3.pngまで掲載している。