はじめに
プログラミング学習を続けていると、チュートリアルを終えた後に何をすれば分からなくなることがないだろうか(私はあります)
言語の構文は理解できたのだけど、その次に何をすればよいか分からない。そんな状況が、ビギナーの方にはあるんじゃないだろうかと思う。
ということで、今回はQiitaの上位記事やタグを取得・分析することで次に何を作ればいいかのアタリをつけたい。
やったこと
- 特定のワードからQiitaの上位記事のタイトルを取得
- 特定のワードに関連するタグを取得・分析
要は上位記事を参考に自分が作るものの参考にするのと、どんなジャンルが多いかをタグから考察してみました。
※基本的にスクレイピングをするだけですが
環境
Python 3.9.0
1. 特定のワードからQiitaの上位記事のタイトルを取得
例えば、『Python』で検索した時の上位記事を10ページ分取得してみた。
import requests
from bs4 import BeautifulSoup as bs
query = input('please input words : ')
with open(query + '_qiita.txt', 'wb') as outfile:
for i in range(1,11):
url = 'https://qiita.com/search?page=' + str(i) + '&q=body%3A' + query + '+tag%3A' + query + '&sort=like'
res = requests.get(url)
soup = bs(res.text, 'html.parser')
titles = soup.find_all('h1', class_="searchResult_itemTitle")
for i in titles:
s = i.get_text()
outfile.write(s.encode('utf-8'))
outfile.write(b'\n \n')
実行結果:検索ワード = python
プログラミングでよく使う英単語のまとめ【随時更新】
【まとめ】これ知らないプログラマって損してんなって思う汎用的なツール 100超
イマドキのJavaScriptの書き方2018
新人プログラマに知っておいてもらいたい人類がオブジェクト指向を手に入れるまでの軌跡
AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~
~以下略。
といった感じでqiitaの上位記事のタイトルだけ抜き出して次に何を作れば良いか参考にできる。
ちなみに、個人的に面白そうだと思ったのはこの辺り。
Djangoを最速でマスターする part1
ブロックチェーンを作ることで学ぶ 〜ブロックチェーンがどのように動いているのか学ぶ最速の方法は作ってみることだ〜
「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語
ディープラーニングさえあれば、競馬で回収率100%を超えられる
技術書ランキングサイトをQiita記事の集計から作ったら、約4000冊の技術本がいい感じに並んだ
私もランキングサイトとか作ってみたいものですね~
2. 特定のワードに関連するタグを取得・分析
今度は上位記事の関連タグを取得・分析することで、検索ワードにおいてどのようなことをするのが妥当かを判断する。
import requests
from bs4 import BeautifulSoup as bs
import csv
query = input('please input words : ')
lists = []
for i in range(1,11):
url = 'https://qiita.com/search?page=' + str(i) + '&q=body%3A' + query + '+tag%3A' + query + '&sort=like'
# url = 'https://qiita.com/search?page=1' + '&q=body%3A' + query + '+tag%3A' + query + '&sort=like'
res = requests.get(url)
soup = bs(res.text, 'html.parser')
tags = soup.find_all('li', class_="tagList_item")
for i in tags:
lists.append(i.get_text())
print("\n /// result is below /// \n")
print(lists, '\n')
unique_tags = set(lists)
with open('./csv/'+query+'_tags.csv', 'w', newline='') as f:
for i in unique_tags:
writer = csv.writer(f)
writer.writerow([str(i), lists.count(i)])
先と同様に、pythonで検索した記事のタグをcsvに抽出してみた。それをソートしてみたのが以下(1列目がタグ、2列目が登場回数(全記事数 = 100記事))
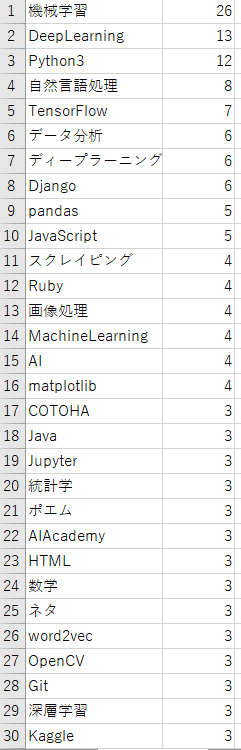
こうして見ると『機械学習』、『深層学習』、『データ処理』が多くやはりデータを処理する言語だと言うことが分かる。
次に、『Django』、『スクレイピング』、『Ruby』等も多く見られることからWeb系の需要もあることが分かる。これはpythonがWeb系に用いられるというより、Web開発をしている人の母数が多いのでそれに伴いWeb系のタグも増えているんじゃないかと考える(知らんけど)
おわりに
と、いうことでpythonは機械学習のようなデータ処理に強い言語であることが分かった(前から分かっていたことである)
さておき、私自身せっかくpythonを学んでいるのにまだ機械学習童貞なので、次回記事あたりで触れてみたいと思う