はじめに

ラブコメの良し悪しはエンディングで決まると言っても過言ではない。
そして、ラブコメのエンディングは実に多様なものが存在する。特定の一人を選ばないハーレムエンド。ヒロイン一人一人のエンディングを用意するマルチエンド。特定の一人とだけ成就する個別エンド。
どのエンディングを迎えても必ずファンによる論争が繰り広げられるラブコメであるが、やはり一番議論が紛糾するのはなんといっても個別エンドではなかろうか。
中でもエンディングに関して紛糾した最近のラブコメといえば、そう、『五等分の花嫁』である。
本作のエンディングは四葉エンドだと言われている。
だが、他のヒロインとのifエンドを妄想するのもラブコメの一種の楽しみ方であるに違いない。
本記事はアニメ1期の画像を学習させた後AIに正妻を判定させ、他のヒロインとのあったかもしれないエンディングの可能性に、少しだけ思いを馳せてみるものとなっている。
実施したこと
アニメ1期の結婚式に登場した女性を正妻と見なし、五つ子とそれ以外の画像の多クラス分類で正妻を判定した。
機械学習フレームワークはKerasを用いる。
また、学習画像は全てアニメ1期のものとし、判定する画像は以下のものとする。

ちなみに私は三玖推しなのでなんとか頑張って三玖が選ばれることを期待する。
環境
Python : 3.9.0
conda version : 4.9.1
CPU : Intel(R) Core(TM)i5-6500
GPU : Intel(R) HD Graphics 530
keras : 2.3.1
実施手順
- 画像の収集
- 顔画像の抽出
- ラベリング
- データの分類
- データの水増し
- モデルの学習
- 正妻判定
1. 画像の収集
まずは画像の収集である。opencvを使えば動画からフレームを指定して自動で画像をキャプチャすることもできるそうだが、保存している動画がなかったので今回はアニメを垂れ流してキャプチャすることにした。
方法として、アニメ1期分を垂れ流しながら5秒おきにキャプチャを取るプログラムを作成した。
モジュールはpyautoguiを選択。本モジュールは他にも様々なGUI操作を自動化してくれるのでとても有用である。
import os
import pyautogui
import time
start = time.time()
for l in range(1,13):
for i in range(275):
im = pyautogui.screenshot('./capture_data/' + str(l) +'_'+ str(i) + '.png', region=(1050,50,800,450))
time.sleep(5)
end = time.time()
print('result time is :', end - start)
私の場合、デスクトップを四分割した右上の画面でアニメを垂れ流していたのでregion=(1050,50,800,450)とデスクトップの右上をキャプチャするプログラムとなっている。
だいたい5時間くらいかけて合計3300枚の画像をキャプチャした。
キャプチャした画像はこんな感じ。
焼肉定食焼肉抜きという注文が今でも忘れられない。
ちなみに、動画からフレーム指定でキャプチャする場合は以下が参考になる。
2. 顔画像の抽出
次に、opencvでキャプチャした画像から顔画像を抽出する。
顔画像のカスケード分類器として、アニメ画像で有名なこちらを用いた。
こちらのxmlファイルを作業ディレクトリにコピーして、先のキャプチャ画像から顔を検出後、抽出。
また、深層学習のモデルにVGG16を使う都合上、画素数は64 x 64ピクセルとする。
import cv2
def face_cut(img_path, save_path):
img = cv2.imread(img_path)
cascade = cv2.CascadeClassifier('lbpcascade_animeface.xml')
facerect = cascade.detectMultiScale(img)
for i, (x,y,w,h) in enumerate(facerect):
face_img = img[y:y+h, x:x+w]
face_img = cv2.resize(face_img, (64, 64))
cv2.imwrite(save_path, face_img)
for l in range(1,13):
for i in range(275):
face_cut('capture_data/'+str(l)+'_'+str(i)+'.png', 'cut_data/'+str(l)+'_'+str(i)+'.png')
抽出された画像は以下。学食のおばちゃんまで一応抽出してくれているようである。
また、キャプチャ画像3300枚のうち、顔検出された画像は1365枚であった。つまり、全体の1/3強で顔の抽出をすることができたということになる。
3. ラベリング
ここで1365枚を手作業でそれぞれのヒロインのディレクトリに仕分けを行う。1365枚程度であれば大した時間はかからなかったが、画像数が万のオーダーになると流石にそうはいかなさそうだ。
# がんばれ!!!
仕分け結果が下表
| 分類 | 枚数 |
|---|---|
| 一花 | 206 |
| 二乃 | 168 |
| 三玖 | 152 |
| 四葉 | 172 |
| 五月 | 204 |
| その他 | 463 |
一花が首位で206枚、僅差で五月が追いかけるような形となった。最大枚数の一花と最小枚数の三玖では54枚差となり、厳密を期す場合は学習枚数を同数にする必要があるのかもしれないが、今回はそこまで厳密性を問わないのでこのまま続行することとする。
4. データの分類
ここでは先の顔画像をpandasに変換し、0~5のラベルを付与する。また、trainとtestの枚数比は8:2とした。
# split.py
import numpy as np
import glob
import cv2
from keras.utils.np_utils import to_categorical
import pandas as pd
import matplotlib.pyplot as plt
names = ['other', 'ichika', 'nino', 'miku', 'yotsuba', 'itsuki']
img_list = []
label_list = []
# append index
for index, name in enumerate(names):
face_img = glob.glob('data/'+name+'/*.png')
for face in face_img:
# imread RGB
a = cv2.imread(face, 1)
b = np.expand_dims(a, axis=0)
img_list.append(b)
label_list.append(index)
# convert pandas
X_pd = pd.Series(img_list)
y_pd = pd.Series(label_list)
# merge
Xy_pd = pd.concat([X_pd, y_pd], axis=1)
# shuffle
sf_Xy = Xy_pd.sample(frac=1)
# shuffle後にlistとして再取得
img_list = sf_Xy[0].values
label_list = sf_Xy[1].values
# tuple化して結合
X = np.r_[tuple(img_list)]
# convert binary
Y = to_categorical(label_list)
train_rate = 0.8
train_n = int(len(X) * train_rate)
train_X = X[:train_n]
test_X = X[train_n:]
train_y = Y[:train_n][:]
test_y = Y[train_n:][:]
5. データの水増し
次に学習枚数が1000枚強では心もとないないので、train画像のみに対して水増しを行った。水増し項目として、左右反転とぼかし、γ変換を行い、train画像を2**3倍に水増しした。
これで総枚数はだいたい1万枚程度となる。
※便宜上、コードを分けているが実際には4と5のコードは一つのファイルである。
## define scratch_functions
# 左右反転
def flip(img):
flip_img = cv2.flip(img, 1)
return flip_img
# ぼかし
def blur(img):
blur_img = cv2.GaussianBlur(img, (5,5), 0)
return blur_img
# γ変換
def gamma(img):
gamma = 0.75
LUT_G = np.arange(256, dtype = 'uint8')
for i in range(256):
LUT_G[i] = 255 * pow(float(i) / 255, 1.0 / gamma)
gamma_img = cv2.LUT(img, LUT_G)
return gamma_img
total_img = []
for x in train_X:
imgs = [x]
# concat list
imgs.extend(list(map(flip, imgs)))
imgs.extend(list(map(blur, imgs)))
imgs.extend(list(map(gamma, imgs)))
total_img.extend(imgs)
# add dims to total_img
img_expand = list(map(lambda x:np.expand_dims(x, axis=0), total_img))
# tuple化して結合
train_X_scratch = np.r_[tuple(img_expand)]
labels = []
for label in range(len(train_y)):
lbl = []
for i in range(2**3):
lbl.append(train_y[label, :])
labels.extend(lbl)
label_expand = list(map(lambda x:np.expand_dims(x, axis=0), labels))
train_y_scratch = np.r_[tuple(label_expand)]
6. モデルの学習
最後に、用意した画像を用いてモデルを学習する。深層学習のモデルは特に意味はないがVGG16を選択した。
エポック数を100にしたのとGPUがよわよわなせいで学習に半日程度かかってしまったのは正直意外だった。
from keras.applications import VGG16
from keras.models import Model, Sequential
from keras.layers import Dense, Activation, Flatten, Input, Dropout
from keras import optimizers
import matplotlib.pyplot as plt
from split import *
# define input_tensor
input_tensor = Input(shape=(64,64,3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(64, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation='sigmoid'))
top_model.add(Dropout(0.5))
top_model.add(Dense(6, activation='softmax'))
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg_model apply to 15layers
for layer in model.layers[:15]:
layer.trainable = False
# compile
model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])
history = model.fit(train_X_scratch, train_y_scratch, epochs=100, batch_size=32, validation_data=(test_X, test_y))
score = model.evaluate(test_X, test_y, verbose=0)
print(score)
# save model
model.save('my_model.h5')
# plot acc, val_acc
plt.plot(history.history['acc'], label='acc', ls='-')
plt.plot(history.history['val_acc'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
精度こそあまり良くないが、一応五人のヒロインを分類するモデルが完成した。

7. 正妻判定
さぁ、いよいよ待ちに待った正妻判定である!(なんやかんやここまで1日程度かかった)
AIが判定する正妻とは、いったい誰だったのか――!!!
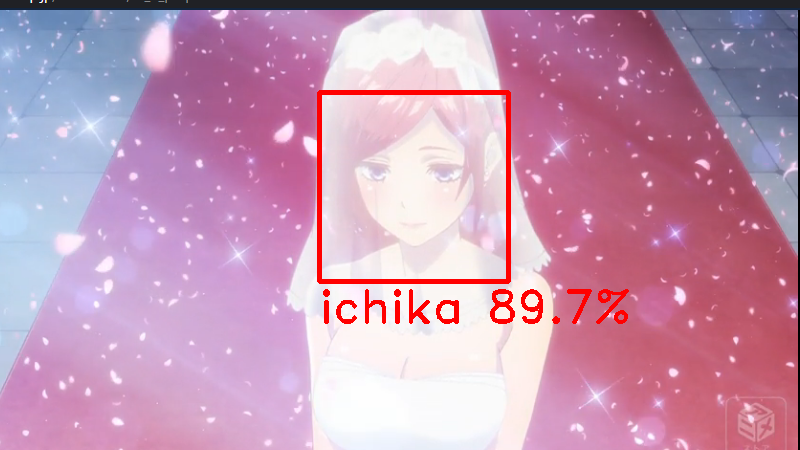
――選ばれたのは、一花でした。
いやー、やっぱり髪の長さでしたかね~。色彩的には五月もワンチャンあるかと思ったんですが。
三玖は、三玖はな~、オーディオテ〇ニカっぽいヘッドホンでも合成させれば良かったですかねー笑
まぁ、アニメ1期では一花以外のヒロインが髪を上げるシーンなんてほとんどなかったわけですし、そりゃあ一花が選ばれたのは妥当かもしれませんね。
人間の顔を決定づける特徴として髪以上に大事なものとして眼がありますが、五つ子の場合はみんな青系統の色なので見分けがつきませんでした。
結果的に髪の短さで一花が選ばれた気がします。髪色は五月っぽいんですけどね。
おまけ
せっかくなので、他の画像も分類してみました。
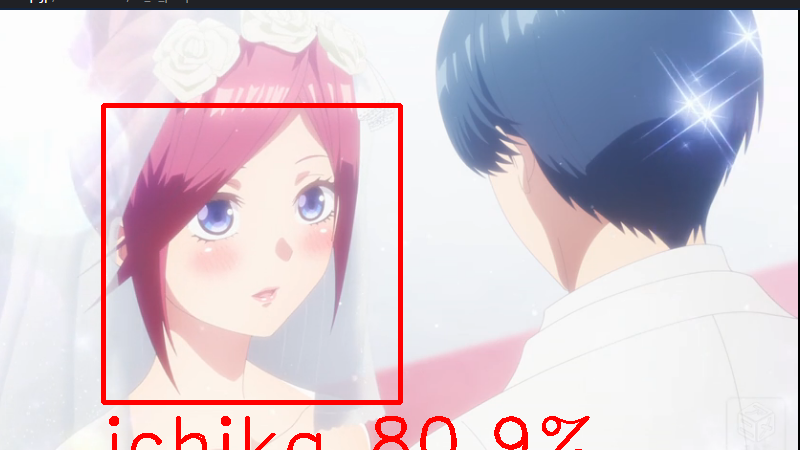
先のシーンの誓いの場面です。これも一花と分類されていました。やはりショートカットに見えるんでしょうね。

まぁ、これも一花かな~~
そして、最後に8話のラストシーン。風太郎が昔、恋に落ちた女の子の写真です。

え!これも一花なの!??
今度は髪色が一花っぽかったんでしょうけど、ちょっと一花さん強すぎませんかねぇ……
結論
ということで、AI的には結婚式で花嫁として出てきたヒロインも昔好きだった女の子も総じて一花さんであるということになりました。
これでアレですね。なにかと不遇な姉属性ヒロイン一花推しの人が「いや、ほら、アレだから。AI的には一花が正妻だから……」
とか言えるかもしれませんね。多分。
参考
Kerasでアニメ 「けいおん!」を画像認識させてみた
opencvで動画からアニメキャラクターの画像を集めてみよう!
OpenCVによるアニメ顔検出ならlbpcascade_animeface.xml