初めまして、Takaと申します。
Aidemyで画像認識について学んだので、学習成果物として投稿してみました。
今回行ったのはアニメ「けいおん!」の画像認識です。
けいおん!が放送されてからもう9年経っているなんて感慨深いものですね。
ちなみに僕が好きなのは秋山澪さんです。
※書かれているコードには、コメントアウトが多くあります。これは自分が一目で理解できるように書いていますのでご了承ください。
目次
0.環境
1.使用ライブラリ
2.画像収集
3.顔抽出
4.画像をキャラクターごとに分類する
5.訓練用データとテストデータに分ける
6.画像の水増し
7.学習
8.学習結果
9.モデルの適用
10.おわりに
11.参考にしたサイト
0.環境
AidemyのGPU仮想環境(Jupyter notebook)
python 3.6.3 : プログラミング言語
1.使用ライブラリ
numpy 1.13.3 : 数値計算ライブラリ
OpenCV 3.3.0 : 画像処理ライブラリ
Pandas 0.20.3 : データ解析用ライブラリ
matplotlib 2.0.2 : グラフ描写用ライブラリ
Keras 2.0.8 : ディープラーニング用ライブラリ
2.画像収集
アニメを流してひたすらスクリーンショットします。
今回スクリーンショットしたのは映画「けいおん!」と、けいおん!2期の15話までの一部を抜粋してます。
1話で大体150枚ほど集まりました。
こんな感じ👇
これをzipファイルにして、Aidemyの仮想環境に送るというのを繰り返します。
3.顔抽出
次に、集めた画像から顔だけを抜き取ります。
カスケード分類器(顔の特徴量が入ったデータセット)を用いて、顔検出をするメソッドcascade.detectMultiScaleを行うことで顔だけを取り出すことができます。
分類器は様々あるので、自分で行う場合にはデータに合ったものを使ってみてください。今回はアニメ顔なので、lbpcascade_animeface.xmlというアニメ顔検出用の分類器を使いました。
(lbpcascade_animeface.xmlについてはこちら)
import cv2
import numpy as np
import os
import glob
# 顔を切り取る関数
def cut_face(origin_path ="./origin_add" ):
#oringin_pathディレクトリの全てのファイルを開く
img_path_list=glob.glob(origin_path + "/*")
for img_path in img_path_list:
#ディレクトリ名を取得
base_name = os.path.basename(img_path)
#os.path.splitext - 拡張子を取得
name,ext = os.path.splitext(base_name)
if (ext != '.jpg') and (ext != '.jpeg') and (ext != '.png'):
print("not a picture")
continue
#第2引数はカラータイプを表す。1はRGB、0はグレースケール、-1はRGBA
img_src = cv2.imread(img_path, 1)
#BGRからグレースケールへの変換
img_gray=cv2.cvtColor(img_src, cv2.COLOR_BGR2GRAY)
#顔認識の実行
#cascade.detectMultiScaleは顔検出するメソッド
#scaleFector - 各画像スケールにおける縮小量を表す
#minNeighbors - 物体候補となる矩形(くけい)は、最低でもこの数だけの近傍矩形を含む必要がある
#矩形:4内角がすべて等しい四辺形
#minSize - 物体がとり得る最小サイズ。これよりも小さい物体は無視される。
faces=cascade.detectMultiScale(img_gray, scaleFactor=1.2, minNeighbors=1, minSize=(10,10))
#顔があった場合
if len(faces)>0:
i = 0
#顔の座標を取り出す
for (x,y,w,h) in faces:
face = img_src[y:y+h, x:x+w]
#ディレクトリ名指定
dirname = "face"
#ディレクトリがなかったら作る
if not os.path.exists(dirname):
os.mkdir(dirname)
#ファイル名
a = dirname + name+ "_" + str(i) + ext
#ディレクトリ名とファイル名を結合
#ディレクトリに直接入れられる
file_name = os.path.join(dirname, a)
print(file_name)
cv2.imwrite(file_name, resize_face)
集めた顔画像はこんな感じになりました。
そして、画像をディープラーニングしやすいように64×64サイズにして別のディレクトリに入れます。
import cv2
import glob
import os
# 切り取った顔写真が入ったフォルダを開く
faces = glob.glob("./face/*")
i = 0
for face in faces:
f = cv2.imread(face, 1)
resize_face = cv2.resize(f, (64, 64))
i += 1
#ディレクトリ名指定
dirname = "resize"
#ディレクトリがなかったら作る
if not os.path.exists(dirname):
os.mkdir(dirname)
#ファイル名
a = "face_resize" + str(i) + ".png"
file_name = os.path.join(dirname, a)
print(file_name)
#保存
cv2.imwrite(file_name, resize_face)
4.画像をキャラクターごとに分類する
次に、集めた顔画像をキャラクターごとのディレクトリに移します。これだけは手動で行わないといけないので非常につらいです。全体の6~7割くらいの時間を割いた気がします。画像認識を行うときは自分が好きな画像でやるべきです!
僕は澪の画像が出るたびに元気になりました かわいい!!
この時、顔でない画像(木など)や、画像認識しなくていいキャラクター(生徒Aなど)の顔も混じっていたりするので、削除しました。
これで総数が大体3000枚になりました。
5.訓練用データとテストデータに分ける
画像をあらかじめ訓練用データとテストデータのディレクトリに分けるのも面倒なので、Pandas__を用いてデータを分割しました。
大まかな流れはこんな具合です。
1.ファイルごとに画像を取り出し、ラベルはインデックス番号にする
2.画像は次元を1つ増やしてどんどん結合する(こうすることで(画像サイズ, 画像サイズ, 色)→(枚数,画像サイズ, 画像サイズ, 色)__とすることができる)
3.Dataframeに変換
4.画像とラベルを結合して、シャッフル
5.DataFrameから取り出し、numpy配列にして再びつなげて訓練データにしたい枚数分取り出す
以下コードです。
import numpy as np
import glob
import cv2
from keras.utils.np_utils import to_categorical
import pandas as pd
names = ["azusa", "yui", "ritsu", "mio", "tsumugi"]
image_list = []
label_list = []
# インデックスと名前を1つずつ取り出す
for index, name in enumerate(names):
faces = glob.glob("resize/" + name + "/*")
for face in faces:
a = cv2.imread(face, 1)
#列方向に次元を追加する
b = np.expand_dims(a, axis=0)
#listに画像の配列をすべて格納する
image_list.append(b)
#画像ごとに番号で分類
#すべてを一つのリストに格納
label_list.append(index)
# pandasに変換する
X_pd = pd.Series(image_list)
y_pd = pd.Series(label_list)
# 結合
Xy_pd = pd.concat([X_pd, y_pd], axis= 1)
# 行方向でシャッフルする
sf_Xy = Xy_pd.sample(frac=1)
# シャッフル後に取り出す
# df.values - numpy array配列を取得
image_list = sf_Xy[0].values
label_list = sf_Xy[1].values
# ばらして(tuple)から結合
X= np.r_[tuple(image_list)]
# to_categorical - バイナリ(2進法)行列に変換する
Y = to_categorical(label_list)
# trainの割合
train_rate = 0.8
# 整数表示
# 分類画像ごとのtrain_dataの数
train_n = int(X.shape[0] * train_rate)
# スライスで一部を取り出す
train_X = X[:train_n]
test_X = X[train_n:]
train_y = Y[:train_n][:]
test_y = Y[train_n:][:]
6.画像の水増し
訓練用データは大体2400枚になりましたが、これでは少々学習データの量に不安が残ります。
そこで、__画像の水増し__を行います。
ここで全体の画像枚数を増やしてしまうと、正解率は上がるけれど、オリジナルデータには弱くなるので訓練データのみを水増しするようにします。
左右反転、コントラスト調整、ぼかし、γ変換を行い、1枚につき2^4枚増える計算になります。これで訓練データが4万枚ほどになりました。
import numpy as np
import matplotlib.pyplot as plt
import cv2
import glob
'''水増し関数'''
# 左右反転
def flip(img):
#第二引数を正でy軸対象
flip_images = cv2.flip(img, 1)
return flip_images
# コントラスト
def cont(img):
#ハイコントラストのみ
#ルックアップテーブルの生成
'''ルックアップテーブル - ある値の答えが必ず1つの値になるとき、あらかじめ答えを計算し配列に格納することで、毎回の計算を省略できる'''
min_table=50
max_table=205
diff_table=max_table - min_table
LUT_HC = np.arange(256, dtype = "uint8")
#ハイコントラストLUT作成
for i in range(0, min_table):
LUT_HC[i] = 0
for i in range(min_table, max_table):
LUT_HC[i] = 255 * (i - min_table) / diff_table
for i in range(max_table, 255):
LUT_HC[i] = 255
#変換
#cv2.LUTで適用
high_cont_imgs = cv2.LUT(img, LUT_HC)
return high_cont_imgs
# ぼかし
def blur(img):
blur_images = cv2.GaussianBlur(img, (5, 5), 0)
return blur_images
# γ変換
def gamma(img):
# ガンマ変換ルックアップテーブル
gamma1 = 0.75
LUT_G1 = np.arange(256, dtype="uint8")
for i in range(256):
LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1)
#変換
gamma1_images = cv2.LUT(img, LUT_G1)
return gamma1_images
# 実行
all_img = []
for x in train_X:
#1枚の画像のみ処理する
images =[x]
#mapは関数の名前だけでよい
#extendでリスト同士をつなげられる
images.extend(list(map(flip, images)))
images.extend(list(map(cont, images)))
images.extend(list(map(blur, images)))
images.extend(list(map(gamma, images)))
#処理した全ての画像を格納する
all_img.extend(images)
# 次元を増やし、all_imgに適用させる
img_expand = list(map(lambda x:np.expand_dims(x, axis=0),all_img))
# リストから取り出して(tuple)、つなげる
train_X_scratch = np.r_[tuple(img_expand)]
labels = []
# lable - 行の数
for label in range(train_y.shape[0]):
lbl = []
#増やした枚数分繰り返す
for i in range(16):
lbl.append(train_y[label, :])
labels.extend(lbl)
label_expand = list(map(lambda x:np.expand_dims(x, axis=0), labels))
train_y_scratch = np.r_[tuple(label_expand)]
7.学習
いよいよ学習です!
from keras.applications import VGG16
from keras.models import Model,Sequential
from keras.layers import Dense, Activation, Flatten, Input, Dropout
from keras import optimizers
import matplotlib.pyplot as plt
# input_tensorの定義
input_tensor = Input(shape=(64,64,3))
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
top_model=Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(64, activation="sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(32, activation="sigmoid"))
top_model.add(Dropout(0.5))
top_model.add(Dense(5, activation="softmax"))
model=Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# modelの15層までがvggのモデル
for layer in model.layers[:15]:
layer.trainable = False
# コンパイル
model.compile(loss="categorical_crossentropy",optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),metrics=["accuracy"])
# historyの取得
history = model.fit(train_X_scratch, train_y_scratch, epochs=100, batch_size=32, validation_data=(test_X, test_y))
score = model.evaluate(test_X, test_y, verbose=0)
print(score)
# modelの保存
model.save("my_model.h5")
# acc, val_accのプロット
plt.plot(history.history['acc'], label='acc', ls='-')
plt.plot(history.history['val_acc'], label='val_acc', ls='-')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
8.学習結果
学習の経過は以下のようになります。青線が訓練データに対する正解率で、オレンジ線がテストデータに対する正解率です。
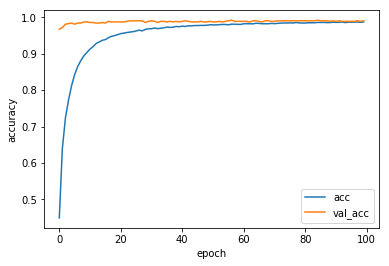
訓練データの精度と、テストデータの精度が同じになったので、イイ感じのモデルになりました![]()
枚数が多かったので学習させるのに3時間くらいかかってます。(長い!)
9.モデルの適用
それでは、待ちに待ったモデルの適用です。
データに使っていない写真に適用させてみます。けいおん!はエンディングでキャラクターの雰囲気が変わるのでそこにも注目ですね。
import os
import keras
import cv2
import matplotlib.pyplot as plt
from keras.models import load_model
import numpy as np
import glob
%matplotlib inline
# ディレクトリを作成
if not os.path.exists("result"):
os.mkdir("result")
dirname = "./result/"
# modelの読み込み
model = load_model("my_model.h5")
# 適用する画像があるディレクトリを開く
img_path_list = glob.glob("img_k-on/*")
num = 0
for img_path in img_path_list:
img = cv2.imread(img_path, 1)
name,ext = os.path.splitext(img_path)
num += 1
file_name = dirname + "pic" + str(num) + str(ext)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cascade_path = "./lbpcascade_animeface.xml"
cascade = cv2.CascadeClassifier(cascade_path)
#顔認識を実行
faces=cascade.detectMultiScale(img_gray, scaleFactor=1.2, minNeighbors=1, minSize=(68,68))
Labels=["azusa", "yui", "ritsu", "mio", "tsumugi"]
Threshold = 0.95
#顔が検出されたとき
if len(faces) > 0:
for fp in faces:
# 学習したモデルでスコアを計算する
img_face = img[fp[1]:fp[1]+fp[3], fp[0]:fp[0]+fp[2]]
img_face = cv2.resize(img_face, (64, 64))
score = model.predict(np.expand_dims(img_face, axis=0))
# 最も高いスコアを書き込む
score_argmax = np.argmax(np.array(score[0]))
#閾値以下で表示させない
if score[0][score_argmax] < Threshold:
continue
#文字サイズの調整
fs_rate= 0.008
text = "{0} {1:.1f}% ".format(Labels[score_argmax], score[0][score_argmax]*100)
#文字を書く座標の調整
text_rate = 0.22
#ラベルを色で分ける
#cv2なのでBGR
if Labels[score_argmax] == "yui":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0, 0, 255), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)),cv2.FONT_HERSHEY_DUPLEX,(fp[3])*fs_rate, (0,0,255), 2)
if Labels[score_argmax] == "azusa":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0, 255, 0), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)),cv2.FONT_HERSHEY_DUPLEX,(fp[3])*fs_rate, (0,255,0), 2)
if Labels[score_argmax] == "tsumugi":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (152, 145, 234), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (152, 145, 234), 2)
if Labels[score_argmax] == "ritsu":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]), (0,255,255), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (0,255,255), 2)
if Labels[score_argmax] == "mio":
cv2.rectangle(img, tuple(fp[0:2]), tuple(fp[0:2]+fp[2:4]),(255,0,0), thickness=3)
cv2.putText(img, text, (fp[0],fp[1]+fp[3]+int(fp[3]*text_rate)), cv2.FONT_HERSHEY_DUPLEX, (fp[3])*fs_rate, (255,0,0), 2)
plt.figure(figsize=(8, 6),dpi=200)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.show()
cv2.imwrite(file_name, img)
# 顔が検出されなかったとき
else:
print("no face")
実行結果
理想的なのが返ってくるとこんな感じです。


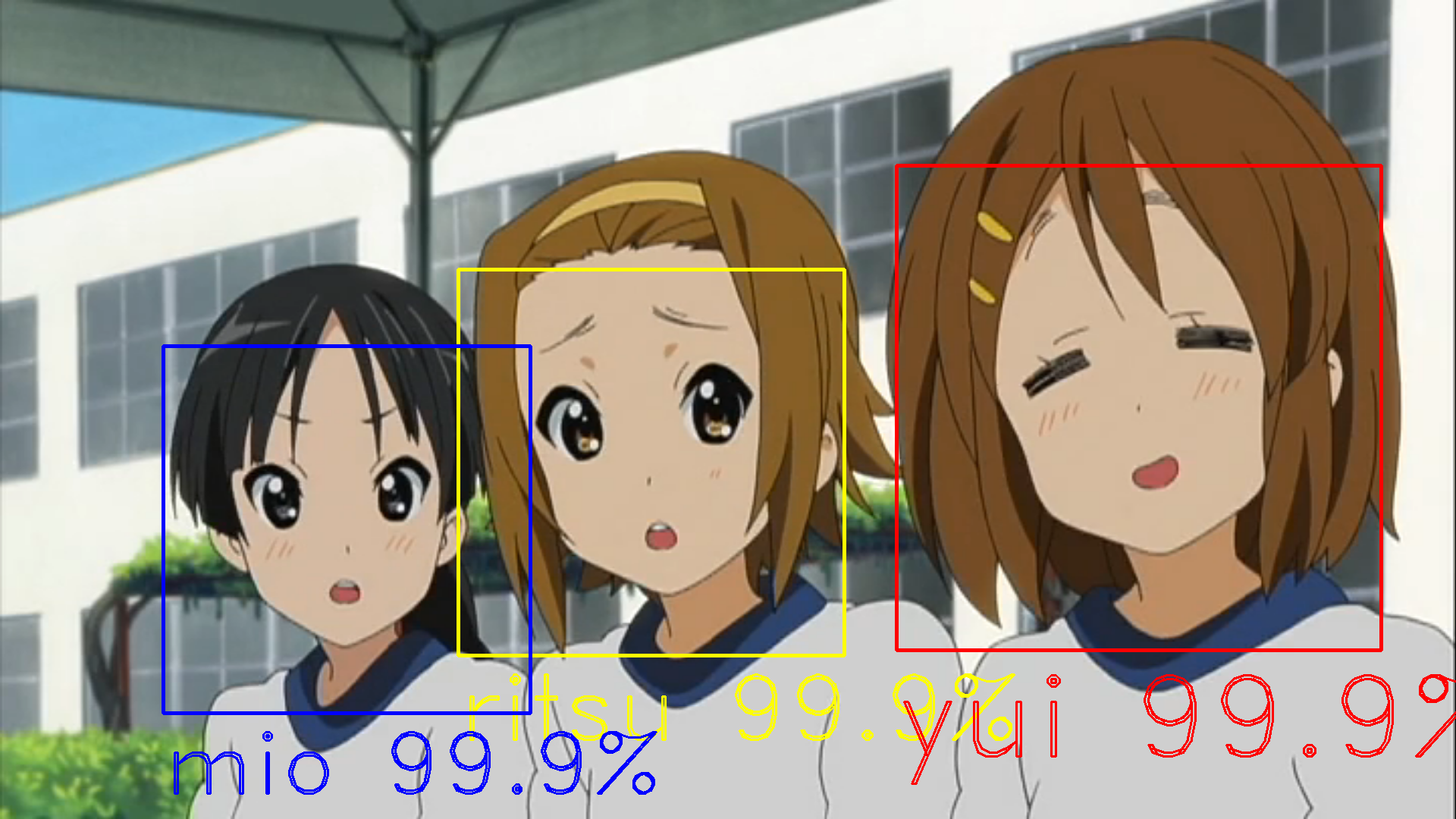
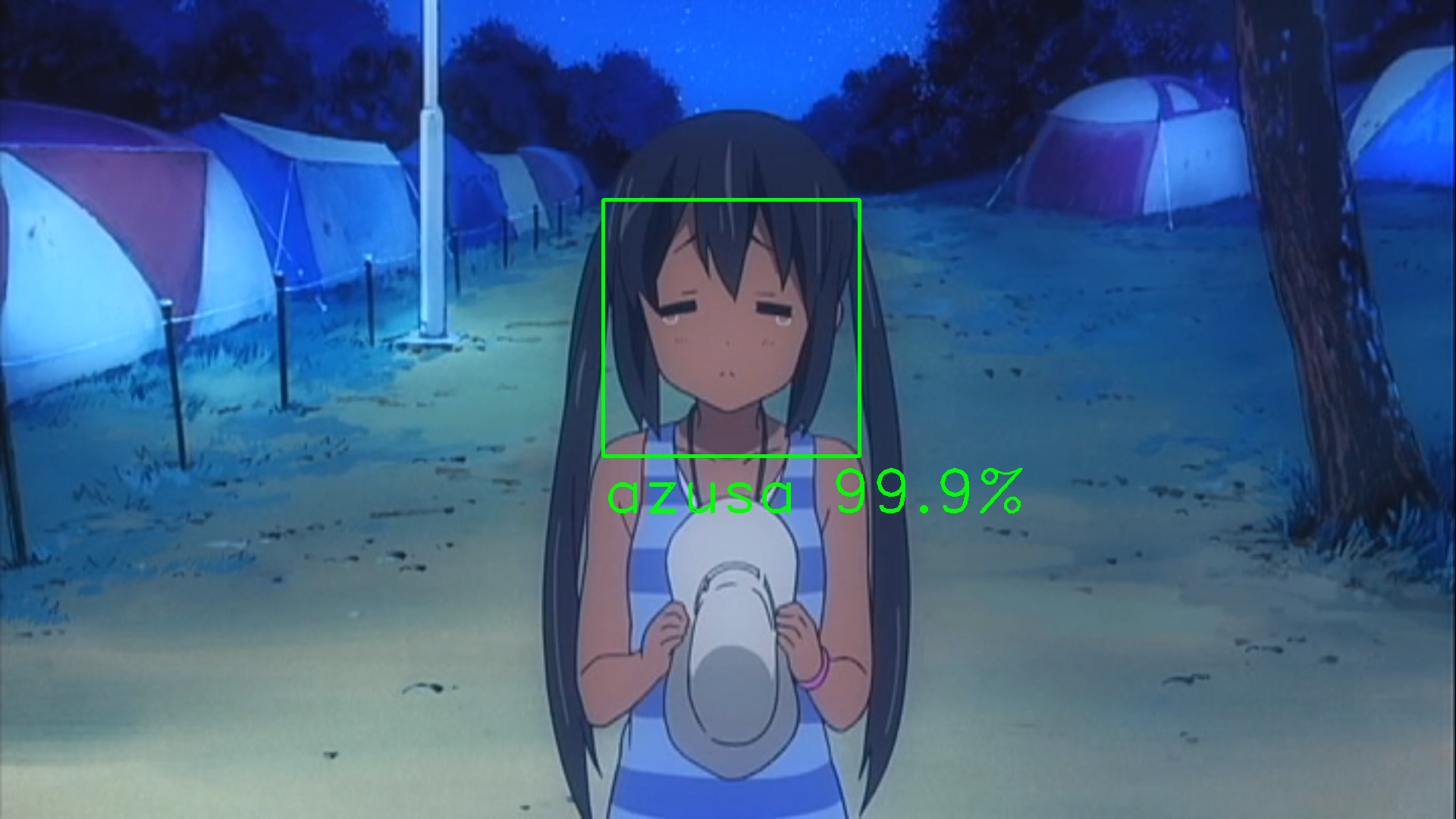
小麦色あずにゃんを認識するとは流石です!
ここからは誤認識したパターンです![]()

惜しい!逆にこの画像でここまで判別できたのはすごいと思う![]()

光の加減で髪色が白く見えてますね。確かに色だけ見たら紬の髪色に似ています。



おでこが見えてるかでスコアが大幅に変わりました。
おでこある=律って感じなのかな...
ちなみに遠めだと唯は正しく判別されました。

おでこが強調されると誤認識するのかも...
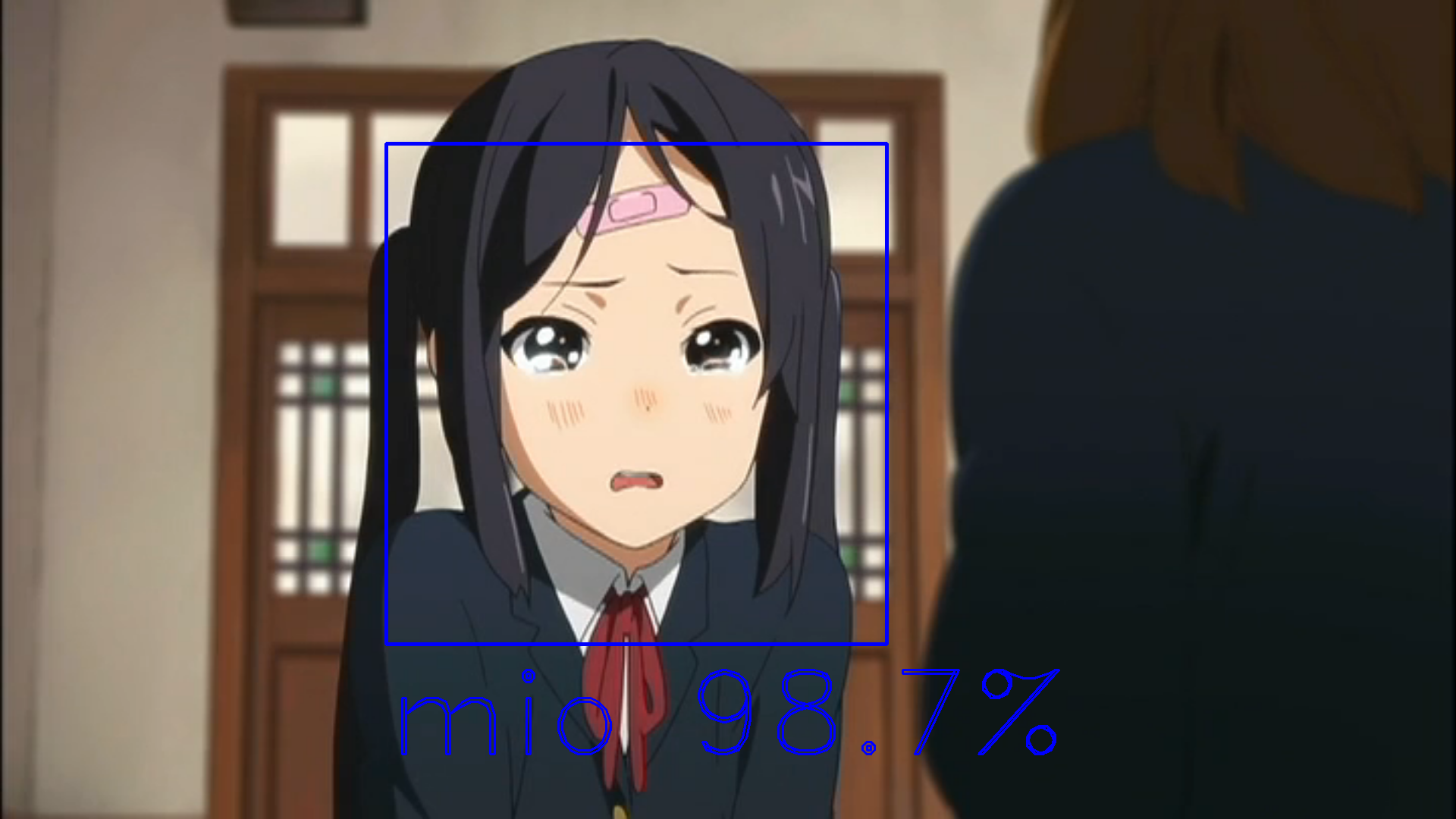
やっぱりおでこなの!?
おまけ
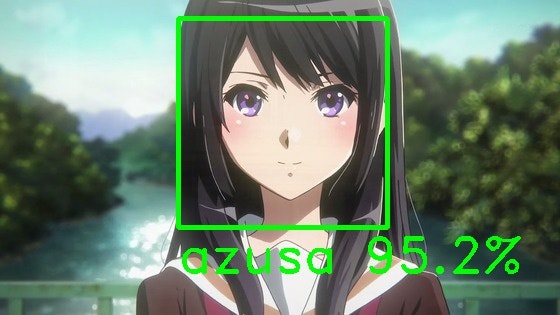
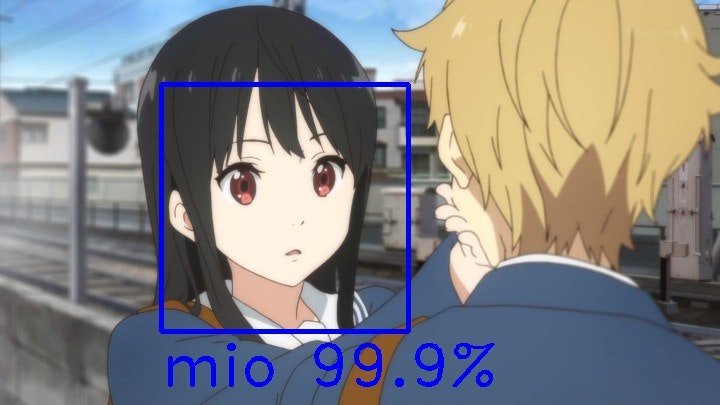
「けいおん!」のアニメ会社「京都アニメーション」の黒髪少女たちにも適用してみました。
どの画像もあずにゃんか澪のスコアが高いので名前の横に[azusa,mio]の順で貼っておきます。
植野直花(聲の形)[9.98962760e-01, 5.25652256e-04]

高坂麗奈(響け!ユーフォニアム) [9.51799333e-01, 4.39170152e-02]
名瀬美月(境界の彼方)[6.99239899e-04, 9.98552501e-01]
北白川たまこ(たまこまーけっと) [9.98300374e-01, 9.85255116e-04]

千反田える(氷菓)[7.46613950e-01, 9.97939169e-01]

京アニの似ているキャラクターたちで検証してみました。全部みおだと思ったら意外にもあずさのほうがスコアが高い結果になりました。
反省
誤認識してるのにスコアが異常に高すぎる気がしました。やはりオリジナルの画像データが少なかったからでしょうか。
加えて、けいおん以外のキャラクターも判別できるように、別のアニメの画像をスクレイピングして大量に集められればもっと良いモデルができたと思います。
あと、スコアの位置を四角の内側にしとけばごちゃごちゃしなかったので修正したほうがいいですね。
最後にコードに関してですが、複数回同じ処理をしていたのでコードを関数化して簡略化すべきでした。
10.おわりに
実は、2か月前までProgateでPythonコースをやったくらいのプログラミング初心者でした。そんな僕ですがAidemyを通じて最終的に成果物までたどり着くことができ、とてもうれしいです。これも、Aidemyのチューターさんのご指導がなければ達成できなかったと思います。2か月間本当にありがとうございました!
11.参考にしたサイト
[OpenCVによるアニメ顔検出ならlbpcascade_animeface.xml]
(http://ultraist.hatenablog.com/entry/20110718/1310965532)
TinderAPIで女の子の顔写真を集めて、加工アリorナシを自動で判定してみた
ディープラーニングでおそ松さんの六つ子は見分けられるのか? 〜準備編〜
機械学習のデータセット画像枚数を増やす方法