どうも、Qiitaで芸人やらさせてもらってます白金御行<プラチナみゆき>です。
アドベントカレンダーも終わりに近づきいよいよクリスマスイブということで、IT界の皆さまは自分へのプレゼントとしてMacのM1チップを購入している方も多いのではないかと思います。
一方で、同じくM1と言えば、人間界的には12月20日(日)に日本一の芸人を決める大会であるところのM1グランプリ2020が開催されました。
私も過去にR1グランプリの出場を考えたこともあって(芸名と2分間のネタを考えたところで出場せずに終わった)、M1グランプリを毎年楽しみにさせて頂いております。
しかし、今回大会であるM1グランプリ2020は技巧派の和牛やかまいたちの欠場であったり、コロナ禍による芸人の劇場公演の減少などもあり、平時では決勝戦で見ない芸人も多く登場していたのではないかと思いました。
そんなM1グランプリですが、毎年審査員間の得点の付け方や審査員と視聴者間の評価の乖離で議論が紛糾しています。
本記事では、これらの乖離についてデータの観点から考察していこうと思います。
コンテンツ
- 審査員得点の標準化
- 相関係数による類似する審査員の分類
- Twitterでの視聴者ツイート統計
それでは、はじめに本大会の出場芸人、審査員について紹介します。
出場者
※決勝ネタ(1本目)は勝手にタイトルを振らさせてもらってます。
以下、ネタ順に記載します。
1.インディアンス
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2010年 | 吉本興業 | ヤンキーだった昔 |
2.東京ホテイソン
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2015年 | グレープカンパニー | 謎解き |
3.ニューヨーク
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2010年 | 吉本興業 | 軽犯罪 |
4.見取り図
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2007年 | 吉本興業 | マネージャー |
5.おいでやすこが
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2019年 | 吉本興業 | 歌ネタ |
6.マヂカルラブリー
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2007年 | 吉本興業 | 高級フレンチ |
7.オズワルド
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2014年 | 吉本興業 | 改名 |
8.アキナ
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2012年 | 吉本興業 | 好きな子 |
9.錦鯉
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2012年 | ソニー・ミュージックアーティスツ | パチンコ |
10.ウエストランド
| 結成 | 事務所 | 決勝ネタ |
|---|---|---|
| 2008年 | タイタン | 復讐 |
審査員
1.オール巨人
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 69歳 | 吉本興業 | 大阪府大阪市 |
2.サンドウィッチマン富澤
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 46歳 | グレープカンパニー | 宮城県仙台市 |
| ※出身に関して、生まれは東京であるが育ちの大半が仙台なので出身は仙台とする。 |
3.ナイツ塙
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 42歳 | マセキ芸能社 | 佐賀県佐賀市 |
| ※出身に関して、生まれは千葉であるが育ちの大半が佐賀なので出身は佐賀とする。 |
4.立川志らく
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 57歳 | ワタナベエンターテインメント | 東京都世田谷区 |
5.中川家礼二
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 48歳 | 吉本興業 | 大阪府守口市 |
6.松本人志
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 57歳 | 吉本興業 | 兵庫県尼崎市 |
7.上沼恵美子
| 年齢 | 事務所 | 出身 |
|---|---|---|
| 65歳 | 上沼事務所 | 兵庫県三原郡 |
1.審査員得点の標準化
まずは本大会の得点表を見ていきます。
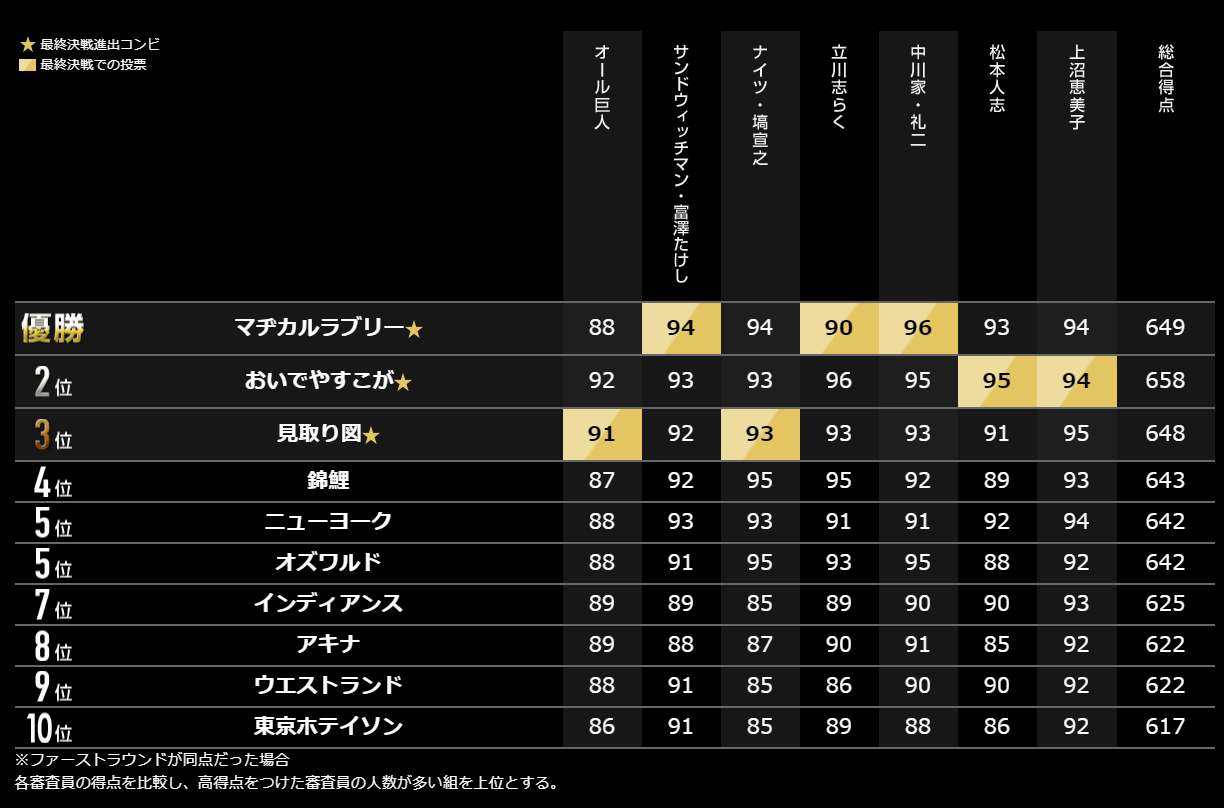
結果から見れば優勝はマヂカルラブリー、最下位は東京ホテイソンということになるのですが、この得点表では一つ疑問が生じます。それが審査員間の得点の乖離です。
例えば、ナイツ塙さんは最少得点と最大得点で10点の差がありますが、上沼恵美子さんですと3点しか差がありません。
これでは、同じ1点でも個々人によって重みが違うことになります。この得点の差を標準化していくために上表の基本統計量を算出していきます。
データが少量なのでエクセルで簡単にまとめた表が以下となります。
表1.得点表
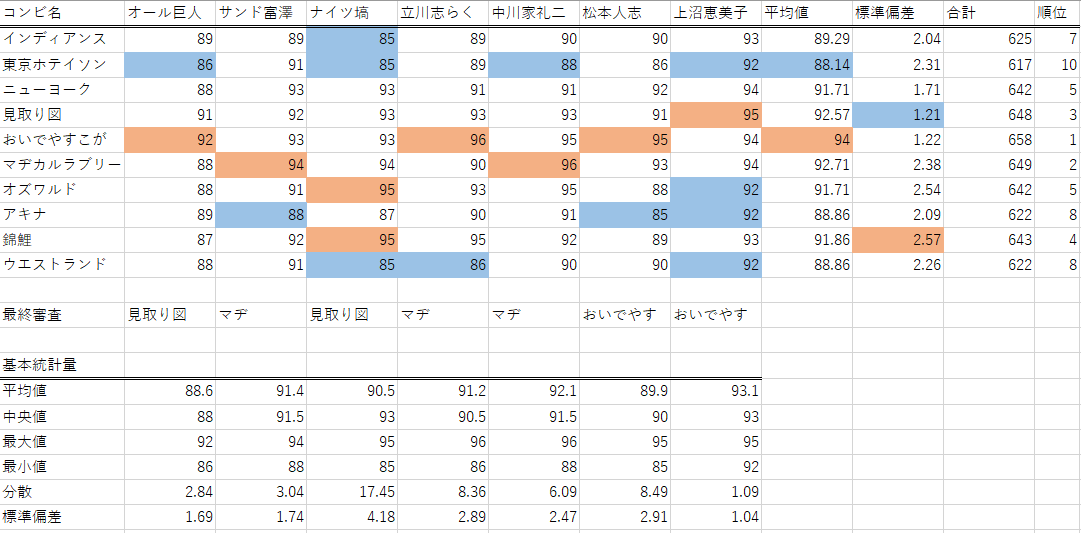
ナイツ塙さんは最大標準偏差の4.18
上沼恵美子さんが最小標準偏差の1.04
となっていることが分かります。では、これを標準化して順位に差があるかを確認しましょう。
※平均値を0、標準偏差を1として標準化します。
表2.標準化した得点表
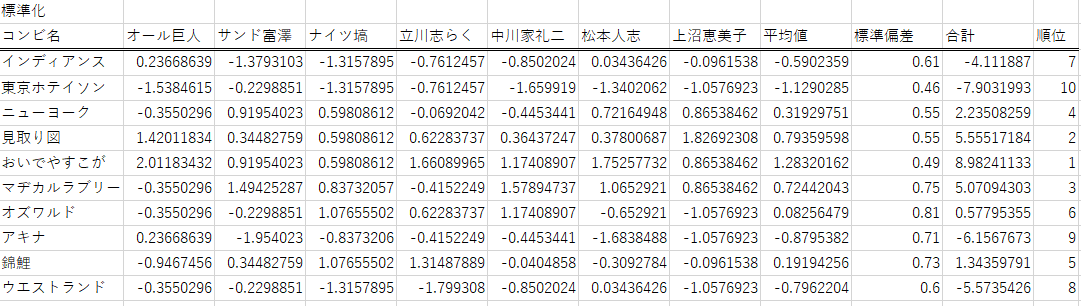
少し分かりづらいですが右の順位を見て頂ければと思います。順位に少し変動があります。
それでは、順位差分がある箇所を確認しましょう。
1.見取り図:3位→2位
マヂカルラブリー:2位→3位
ファイナルラウンドの進出こそ変わりないものの、上位3位間で変動がありました。上沼恵美子さんの最高評価が見取り図なのが起因したのだと思います。見取り図は巨人師匠の評価も高いことから、やはり関西系の審査員は話芸による漫才に強い愛着を感じるのだと思います。
2.ニューヨーク:5位→4位
オズワルド:5位→6位
錦鯉:4位→5位
ニューヨークが錦鯉を抜いて4位に浮上しました。
オズワルド、錦鯉はナイツ塙さんの最高評価なのでそこが標準化されたことで中間層の順位が変動したようです。来年のネクストブレイクが強く期待される錦鯉まさのりさんの、まさに鯉のぼりのような勢いについては後で詳しく見ていきます。(略してまさのり)
3.アキナ:8位→9位
ウエストランド:8位→8位
最後は下位層の変動です。同率であるアキナ、ウエストランドでは標準化するとアキナの方が低得点ということになりました。私はアキナは好きなんですが、控え目に言ってもスベリ散らかしたなぁといった感がありました。いつもはもっと面白いんですけどね。
これで、もしアキナとウエストランドどっちが面白かったという話で友達と口論になった時に、あなたがウエストランド推しの場合は、
「得点が同率でも統計があるから!審査員と統計じゃ統計が勝つから!審査員・統計・統計。統計ー!ってなるから!統計は誰にも止められないんだよ!!」
ってマウント取れるでしょう(統計が勝つのは自覚と自我くらい自明)
ネタ順問題
メインコンテンツでは解析しておりませんが、M1のネタ順には明確な有意差が生じます。この問題について解析した記事があり結果部分を以下に引用します。
・ネタ見せ前半のコンビは後半のコンビに比べてほぼ順位2つ分損する
・前半不利&後半有利の傾向は2007年以降特に顕著になっており,特にネタ見せ最後の組(≒敗者復活組)のアドバンテージは圧倒的である.
(中略)
そう考えると今年から導入された笑神籤(えみくじ)システムはかなり良い試みであったと思われる.ネタ見せ前半が不利な点は全く改善していないが,敗者復活によるアドバンテージを無くし,公平にしている.
前半のコンビは順位2つ分損するというのはとても大きいですね。そう考えるとインディアンス、ニューヨークは順番が後ならファイナルラウンド進出のチャンスも多分にあったのだと考えられます。
ネタ順問題は以前からずっと議論されており、トップバッターで優勝を果たしたのは第1回大会の中川家だけであるということを考慮しても、前半のコンビが上位層に食い込むのがどれだけ難しいかということがお分かり頂けたかと思います。
先の引用でもありますが、このネタ順の不公平を運によって均一化したのが笑神籤(えみくじ)ですね。
まさに、運も実力のうちということでしょう。
ネタ順問題について、詳しくは以下の記事をご参考ください。
M-1グランプリ2017の審査に対する数学的な反論「1点の格差」「トップバッターは不利」
2.相関係数による類似する審査員の分類
さて、1章の続きではありますが、審査員がつけた得点から相関係数によって嗜好が似ている審査員を分類してみました。
こちらもデータが少量なのでエクセルでさっと算出しています。
表3.審査員間の相関係数表
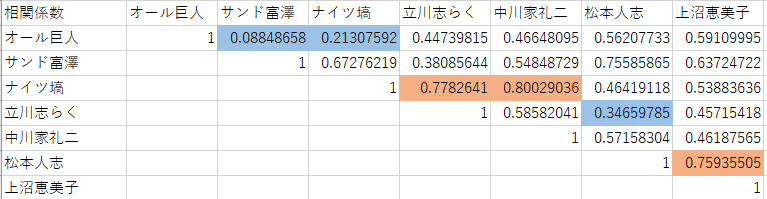
相関係数の表は組み合わせなので半分は同値なので割愛しています。相関係数が高かった3組を赤でマークし、低かった3組を青でマークしました。
まず高かった組み合わせですが、高い方から順に以下のようになりました。
1.[ナイツ塙、中川家礼二]
2.[ナイツ塙、立川志らく]
3.[松本人志、上沼恵美子]
次に、低い順に低かった組み合わせ。
1.[オール巨人、サンド富澤]
2.[オール巨人、ナイツ塙]
3.[立川志らく、松本人志]
この結果からやはり大まかに関西系と関東系で評価が分かれるということが言えそうです。
よく「関西の笑いは東京では通用せん」とか「お笑いは関西弁が有利だ」とか言われますよね。
上記組み合わせでは、高い組み合わせに関東系の[ナイツ塙、立川志らく]、関西系の[松本人志、上沼恵美子]があり、低い組み合わせに東西別の[オール巨人、ナイツ塙]、[立川志らく、松本人志]が見られますね。
これらは東西で感性が違うことをよく表していると思います。
また、全体的にはオール巨人さんとサンド富澤さんが比較的誰とも相関しない得点をつけています。サンド富澤さんは生まれが仙台なので東西の区分ない評価なのかなという予想がつきますが、オール巨人さんが関西系の人と相関が薄いのは意外ですね。
3.Twitterでの視聴者ツイート統計
最後に、審査員と視聴者の評価の乖離に関して、Twitterのツイート統計によって考察していきましょう。
TwitterAPIを用いた統計に関して、同様の内容の記事が過去にありましたのでこちらを参考にしております。
参考:データで見るM1グランプリ2017 〜本当に一番面白かったのはどの漫才だったのか〜
さて、ツイート分析をはじめる前にGYAOが開催直前の各芸人の人気や三連単の組み合わせを調査をしていたのでこちらを見ていきましょう。

事前の人気としては、ニューヨークに見取り図、アキナという比較的メディア露出が多い芸人が人気なことが分かります。皆さま事前人気1位のニューヨークが爆笑エピソードを話してくれることにさぞ期待されたことでしょう。
逆に不人気としては、ウエストランドにマヂカルラブリー、錦鯉と続いております。ウエストランドも錦鯉も事務所が吉本ではないのでその点もメディア露出の少なさにつながってきたのでしょうか。マヂカルラブリー(以下、マヂラブ)に関しては3年前の大会で上沼恵美子さんにボコボコにされて最下位だった実績から事前の期待値が低かった等の憶測ができると思います。
それでは、事前人気を確認したところで本題に戻りましょう。
はじめに、作業環境やCodeを以下に示します。
環境
言語:Python 3.9.0
データの整形:Pandas 1.1.5
描画:Matplotlib 3.3.3
Codeについては全て以下リポジトリに格納してありますので興味がある方はご覧ください。
github.com/KamiHitoe/m12020
3-1.大会実施時間中のツイート量による分析
視聴者の評価を測定する手法として、まずM1グランプリ2020終了時点の12月20日22時5分時点から1週間分、各芸人の名前が入ったツイートを取得します(TwitterAPIの仕様でワード検索での取得は過去1週間分が上限となる)
取得したツイートはcsvファイルとして格納しておきます。
from requests_oauthlib import OAuth1Session
import json
import datetime, time, sys
from abc import ABCMeta, abstractmethod
import pandas as pd
from pandas import Series, DataFrame
from dateutil.parser import parse
import config
from tqdm import tqdm
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
class TweetsGetter(object):
__metaclass__ = ABCMeta
def __init__(self):
self.session = OAuth1Session(CK, CS, AT, ATS)
@abstractmethod
def specifyUrlAndParams(self, keyword):
'''
呼出し先 URL、パラメータを返す
'''
@abstractmethod
def pickupTweet(self, res_text, includeRetweet):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
@abstractmethod
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
def collect(self, total = -1, onlyText = False, includeRetweet = False):
'''
ツイート取得を開始する
'''
#----------------
# 回数制限を確認
#----------------
self.checkLimit()
#----------------
# URL、パラメータ
#----------------
url, params = self.specifyUrlAndParams()
params['include_rts'] = str(includeRetweet).lower()
# include_rts は statuses/user_timeline のパラメータ。search/tweets には無効
#----------------
# ツイート取得
#----------------
cnt = 0
unavailableCnt = 0
while True:
res = self.session.get(url, params = params)
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
tweets = self.pickupTweet(json.loads(res.text))
if len(tweets) == 0:
# len(tweets) != params['count'] としたいが
# count は最大値らしいので判定に使えない。
# ⇒ "== 0" にする
# https://dev.twitter.com/discussions/7513
break
for tweet in tweets:
if (('retweeted_status' in tweet) and (includeRetweet is False)):
pass
else:
if onlyText is True:
yield tweet['text']
else:
yield tweet
cnt += 1
if cnt % 100 == 0:
print ('%d件 ' % cnt)
if total > 0 and cnt >= total:
return
params['max_id'] = tweet['id'] - 1
# ヘッダ確認 (回数制限)
# X-Rate-Limit-Remaining が入ってないことが稀にあるのでチェック
if ('X-Rate-Limit-Remaining' in res.headers and 'X-Rate-Limit-Reset' in res.headers):
if (int(res.headers['X-Rate-Limit-Remaining']) == 0):
self.waitUntilReset(int(res.headers['X-Rate-Limit-Reset']))
self.checkLimit()
else:
print ('not found - X-Rate-Limit-Remaining or X-Rate-Limit-Reset')
self.checkLimit()
def checkLimit(self):
'''
回数制限を問合せ、アクセス可能になるまで wait する
'''
unavailableCnt = 0
while True:
url = "https://api.twitter.com/1.1/application/rate_limit_status.json"
res = self.session.get(url)
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
remaining, reset = self.getLimitContext(json.loads(res.text))
if (remaining == 0):
self.waitUntilReset(reset)
else:
break
def waitUntilReset(self, reset):
'''
reset 時刻まで sleep
'''
seconds = reset - time.mktime(datetime.datetime.now().timetuple())
seconds = max(seconds, 0)
print ('\n =====================')
print (' == waiting %d sec ==' % seconds)
print (' =====================')
sys.stdout.flush()
time.sleep(seconds + 10) # 念のため + 10 秒
@staticmethod
def bySearch(keyword):
return TweetsGetterBySearch(keyword)
@staticmethod
def byUser(screen_name):
return TweetsGetterByUser(screen_name)
class TweetsGetterBySearch(TweetsGetter):
'''
キーワードでツイートを検索
'''
def __init__(self, keyword):
super(TweetsGetterBySearch, self).__init__()
self.keyword = keyword
def specifyUrlAndParams(self):
'''
呼出し先 URL、パラメータを返す
'''
url = 'https://api.twitter.com/1.1/search/tweets.json?'
params = {'q':self.keyword, 'count':100}
return url, params
def pickupTweet(self, res_text):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
results = []
for tweet in res_text['statuses']:
results.append(tweet)
return results
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
remaining = res_text['resources']['search']['/search/tweets']['remaining']
reset = res_text['resources']['search']['/search/tweets']['reset']
return int(remaining), int(reset)
keyword_list = ['アキナ','オズワルド','見取り図','おいでやすこが','錦鯉']
for keyword in keyword_list:
# キーワードで取得
getter = TweetsGetter.bySearch(keyword+' AND until:2020-12-20_22:05:00_JST')
# ユーザーを指定して取得 (screen_name)
#getter = TweetsGetter.byUser('AbeShinzo')
cnt = 0
created_at = []
text = []
for tweet in getter.collect(total = 1000000):
#cnt += 1
#print ('------ %d' % cnt)
#print ('{} {} {}'.format(tweet['id'], tweet['created_at'], '@'+tweet['user']['screen_name']))
#print (tweet['text'])
created_at.append(tweet['created_at'])
text.append(tweet['text'])
created_at = Series(created_at)
text = Series(text)
#各シリーズをデータフレーム化
m1_df = pd.concat([created_at, text],axis=1)
#カラム名
m1_df.columns=['created_at','text']
#csvファイルとして保存
m1_df.to_csv('data/m12020_'+keyword+'.csv', sep = '\t',encoding='utf-16')
次に、得られたcsvファイルから大会時間中(19:00-22:05)のツイートを取り出して、各芸人ごとにグラフ化します。
import codecs
import shutil
import pandas as pd
import time
import datetime
import pytz
from matplotlib import pyplot as plt
from matplotlib import dates as mdates
from matplotlib.dates import date2num
from matplotlib.dates import DateFormatter
from matplotlib import rcParams
rcParams['font.family'] = 'sans-serif'
rcParams['font.sans-serif'] = ['Hiragino Maru Gothic Pro', 'Yu Gothic', 'Meirio', 'Takao', 'IPAexGothic', 'IPAPGothic', 'VL PGothic', 'Noto Sans CJK JP']
keyword_list = ['インディアンス','東京ホテイソン','ニューヨーク','見取り図','おいでやすこが','マヂカルラブリー','オズワルド','アキナ','錦鯉','ウエストランド']
# str -> datetime
def typechange(x):
st = time.strptime(x, '%a %b %d %H:%M:%S +0000 %Y')
utc_time = datetime.datetime(st.tm_year, st.tm_mon,st.tm_mday, st.tm_hour,st.tm_min,st.tm_sec, tzinfo=datetime.timezone.utc)
jst_time = utc_time.astimezone(pytz.timezone('Asia/Tokyo'))
# str_time = jst_time.strftime('%a %b %d %H:%M:%S +0900 %Y')
return jst_time
# return datetime.datetime.strptime(x, '%a %b %d %H:%M:%S +0000 %Y')
def make_df_re(keyword):
df = pd.read_csv('data/m12020_'+keyword+'.csv', encoding='utf-16', sep='\t', header=0)
df['count'] = 1
df['datetime'] = df['created_at'].map(typechange)
# 分ごとにresampleしたdetaの取得
df_date = pd.concat([df['datetime'], df['count']], axis=1)
df_re = df_date.reset_index().set_index('datetime').resample('T').sum()
# df_re.to_csv('data/re_'+keyword+'.csv', encoding='utf-16', sep='\t')
df_re = df_re.reset_index()
return df_re
df_list = []
for keyword in keyword_list:
df_re = make_df_re(keyword)
df_list.append(df_re)
# グラフ作成
with plt.style.context('seaborn-darkgrid', after_reset=True):
plt.rcParams['font.family'] = 'Noto Sans CJK JP'
figure = plt.figure(1, figsize=(8,4))
axes = figure.add_subplot(111)
x0 = df_list[0]['datetime']
x1 = df_list[1]['datetime']
x2 = df_list[2]['datetime']
x3 = df_list[3]['datetime']
x4 = df_list[4]['datetime']
x5 = df_list[5]['datetime']
x6 = df_list[6]['datetime']
x7 = df_list[7]['datetime']
x8 = df_list[8]['datetime']
x9 = df_list[9]['datetime']
y0 = df_list[0]['count']
y1 = df_list[1]['count']
y2 = df_list[2]['count']
y3 = df_list[3]['count']
y4 = df_list[4]['count']
y5 = df_list[5]['count']
y6 = df_list[6]['count']
y7 = df_list[7]['count']
y8 = df_list[8]['count']
y9 = df_list[9]['count']
start_time = datetime.datetime(2020, 12, 20, 10, 0)
end_time = datetime.datetime(2020, 12, 20, 13, 0)
axes.plot(x0, y0, color='#d52f25')
axes.plot(x1, y1, color='#691c0d')
axes.plot(x2, y2, color='#fff000')
axes.plot(x3, y3, color='#f0821e')
axes.plot(x4, y4, color='#00a0dc')
axes.plot(x5, y5, color='#ff2599')
axes.plot(x6, y6, color='#ffcc00')
axes.plot(x7, y7, color='#193278')
axes.plot(x8, y8, color='#9944cc')
axes.plot(x9, y9, color='#d3c1af')
axes.set_xlim(
date2num([
start_time,
x9.max()])
)
axes.set_ylabel('ツイート数 / 分')
xticks = [datetime.datetime(2020, 12, 20, 10, 0), datetime.datetime(2020, 12, 20, 10, 30), datetime.datetime(2020, 12, 20, 11, 00), datetime.datetime(2020, 12, 20, 11, 30), datetime.datetime(2020, 12, 20, 12, 00), datetime.datetime(2020, 12, 20, 12, 30), datetime.datetime(2020, 12, 20, 13, 00)]
xaxis = axes.xaxis
xaxis.set_ticklabels(['19:00', '19:30', '20:00', '20:30', '21:00', '21:30', '22:00'])
plt.legend(('インディアンス','東京ホテイソン','ニューヨーク','見取り図','おいでやすこが','マヂカルラブリー','オズワルド','アキナ','錦鯉','ウエストランド'),
bbox_to_anchor=(1, 1), loc='upper left', borderaxespad=0, fontsize=10)
# axes.xaxis.set_major_formatter(DateFormatter('%H:%M'))
plt.savefig('data/fig.png')
plt.show()
こうして作成されたグラフが以下のようになります。
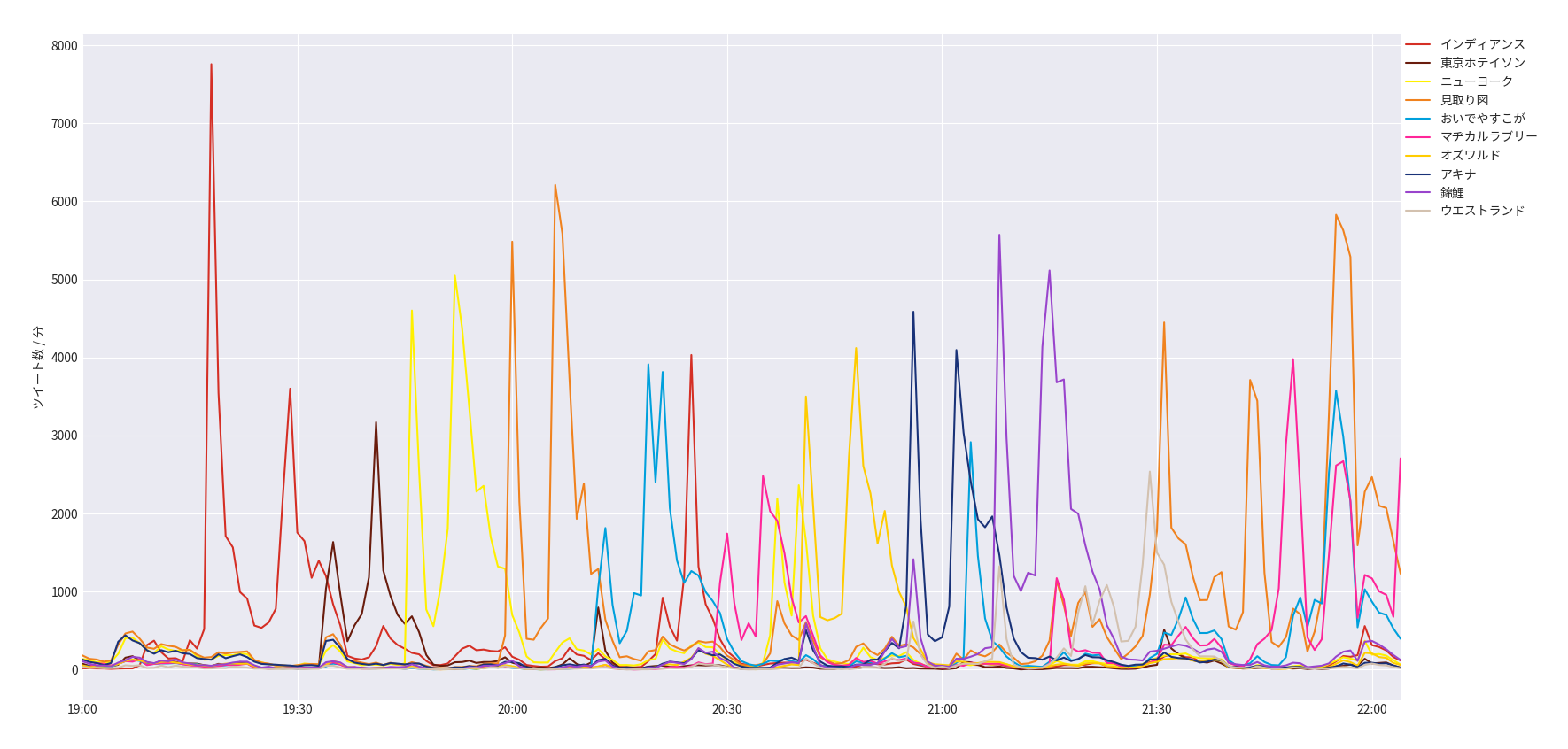
図1.12/24 19:00-22:05の各芸人の名前を含んだツイート数
※単位は分単位となります。
さあ、どうでしょう。
この結果からいろいろなことが見えてくると思います。
まずは瞬間最大ツイート数に関して、19:20前後のインディアンスは敗者復活組が決定した時間ですので、こちらは外れ値として除外します。
上記を除外して一番多い瞬間最大ツイート数を記録したのはファーストラウンド4番手の見取り図となります。
事前予想では2番人気であった見取り図ですが、本番中は一番注目されていたということが分かります。
さて、問題なのはその次です。
瞬間最大ツイート数の2位は、なんと錦鯉となります。
まさかの、錦鯉。
そして、圧倒的な錦鯉。
事前8番人気とはなんだったのかという程の注目度です。
9番人気のマヂラブ、10番人気のウエストランドがともに瞬間最大ツイート数2,500程度であったのに対して、錦鯉はその倍以上の5,500を記録しています。
まさに、鯉のぼり。
略して、まさのり。

図2.錦鯉ボケ担当 長谷川まさのり氏
「さすがまさのりさん!」
「おれたちにできない事を平然とやってのけるッ そこにシビれる!あこがれるゥ!」
さて、上記グラフは錦鯉以外は概ね事前人気通りの注目度となっており、見取り図、錦鯉の次には事前人気のニューヨーク、アキナが続きます。
このグラフを見ると、錦鯉が決勝ファイナルラウンドまであとわずかの4位となったことは偶然ではないように思えますね。
もしかしたら、本当に雅紀さんがパチンコ台になる日も近いのでしょうか?CRまさのりのリリースが待ち遠しいですね。
3-2.ポジティブワードによる疑似支持率の算出
さて、ツイート数の絶対量による注目度は分かりましたが、視聴者が本当に面白いと思った、あるいは好んでいる芸人がまだ分かりません。
では、その値をポジティブワードの比率として疑似支持率のような形で計測していきましょう。
まずポジティブワードについて、ポジティブワードとは視聴者が芸人の名前を含んだツイートの中に含まれる好意的な単語群であるし、今回の場合は以下の単語をポジティブワードと定義しました。
ポジティブワード:面白かった|おもしろかった|おもろかった|良かった|よかった|笑った|好き|すき
これらのポジティブワードが決勝ファーストラウンド中にどれだけ見られたか大会時間中のツイートの全体数からの比率でグラフ化します。
import pandas as pd
import time
import datetime
import pytz
from matplotlib import pyplot as plt
from matplotlib import rcParams
import matplotlib.ticker as ticker
rcParams['font.family'] = 'Noto Sans CJK JP'
rcParams['font.sans-serif'] = 'Noto Sans CJK JP'
keyword_list = ['インディアンス','東京ホテイソン','ニューヨーク','見取り図','おいでやすこが','マヂカルラブリー','オズワルド','アキナ','錦鯉','ウエストランド']
def typechange(x):
st = datetime.datetime.strptime(x, '%a %b %d %H:%M:%S +0000 %Y')
# utc_time = datetime.datetime(st.tm_year, st.tm_mon,st.tm_mday, st.tm_hour,st.tm_min,st.tm_sec, tzinfo=datetime.timezone.utc)
# jst_time = utc_time.astimezone(pytz.timezone('Asia/Tokyo'))
# str_time = jst_time.strftime('%a %b %d %H:%M:%S +0900 %Y')
return st
def replace(x):
y = x.replace(tzinfo=None)
return y
sum_list = []
rate_list = []
for keyword in keyword_list:
# def make_df_re(keyword):
df = pd.read_csv('data/m12020_'+keyword+'.csv', encoding='utf-16', sep='\t', header=0)
df['count'] = 1
df['datetime'] = df['created_at'].map(typechange)
# print(df.info())
from_dt = datetime.datetime(2020, 12, 20, 10, 20)
to_dt = datetime.datetime(2020, 12, 20, 12, 40)
df = df[from_dt <= df['datetime']]
df = df[df['datetime'] <= to_dt]
df_cut = pd.concat([df['datetime'], df['text'], df['count']], axis=1)
# df_cut.to_csv('data/cut_'+keyword+'.csv', encoding='utf-16', sep='\t')
df_result = df[df_cut.text.str.contains('面白かった|おもしろかった|おもろかった|良かった|よかった|笑った|好き|すき')]
sum = len(df_result)
print('sum :', keyword, len(df_result))
rate = round(len(df_result)/(len(df_cut)), 2)
print('rate', keyword, rate)
sum_list.append(sum)
rate_list.append(rate)
# グラフ作成
with plt.style.context('seaborn-darkgrid', after_reset=True):
plt.rcParams['font.family'] = 'Noto Sans CJK JP'
figure = plt.figure(1, figsize=(8,4))
axes1 = figure.add_subplot(111)
s0 = 1
s1 = 2
s2 = 3
s3 = 4
s4 = 5
s5 = 6
s6 = 7
s7 = 8
s8 = 9
s9 = 10
axes1.bar(s0, width=0.5, height=sum_list[0], color='#d52f25')
axes1.bar(s1, width=0.5, height=sum_list[1], color='#691c0d')
axes1.bar(s2, width=0.5, height=sum_list[2], color='#fff000')
axes1.bar(s3, width=0.5, height=sum_list[3], color='#f0821e')
axes1.bar(s4, width=0.5, height=sum_list[4], color='#00a0dc')
axes1.bar(s5, width=0.5, height=sum_list[5], color='#ff2599')
axes1.bar(s6, width=0.5, height=sum_list[6], color='#ffcc00')
axes1.bar(s7, width=0.5, height=sum_list[7], color='#193278')
axes1.bar(s8, width=0.5, height=sum_list[8], color='#9944cc')
axes1.bar(s9, width=0.5, height=sum_list[9], color='#d3c1af')
axes2 = axes1.twinx()
r0 = rate_list[0]
r1 = rate_list[1]
r2 = rate_list[2]
r3 = rate_list[3]
r4 = rate_list[4]
r5 = rate_list[5]
r6 = rate_list[6]
r7 = rate_list[7]
r8 = rate_list[8]
r9 = rate_list[9]
# axes2.axis('off')
axes2.plot(s0, r0, 's', ms=7, color='#7acbe1')
axes2.plot(s1, r1, 's', ms=7, color='#7acbe1')
axes2.plot(s2, r2, 's', ms=7, color='#7acbe1')
axes2.plot(s3, r3, 's', ms=7, color='#7acbe1')
axes2.plot(s4, r4, 's', ms=7, color='#7acbe1')
axes2.plot(s5, r5, 's', ms=7, color='#7acbe1')
axes2.plot(s6, r6, 's', ms=7, color='#7acbe1')
axes2.plot(s7, r7, 's', ms=7, color='#7acbe1')
axes2.plot(s8, r8, 's', ms=7, color='#7acbe1')
axes2.plot(s9, r9, 's', ms=7, color='#7acbe1')
axes1.set_ylabel('ツイート数合計')
axes2.set_ylabel('ポジティブ比率')
axes1.set_axisbelow(True)
axes2.set_axisbelow(True)
xticks = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
xaxis = axes1.xaxis
xaxis.set_major_locator(ticker.FixedLocator(xticks))
xaxis.set_ticklabels(['インディアンス','東京ホテイソン','ニューヨーク','見取り図','おいでやすこが','マヂカルラブリー','オズワルド','アキナ','錦鯉','ウエストランド'], rotation=45)
# xaxis.set_ticklabels(['インディアンス','東京ホテイソン','ニューヨーク','見取り図','おいでやすこが','マヂカルラブリー','オズワルド','アキナ','錦鯉','ウエストランド'], rotation=45)
# axes1.legend(('インディアンス','東京ホテイソン','ニューヨーク','見取り図','おいでやすこが','マヂカルラブリー','オズワルド','アキナ','錦鯉','ウエストランド'),
# bbox_to_anchor=(1, 1), loc='upper left', borderaxespad=0, fontsize=10)
# plt.savefig('data/fig.png')
plt.show()
得られたグラフが以下のようになります。
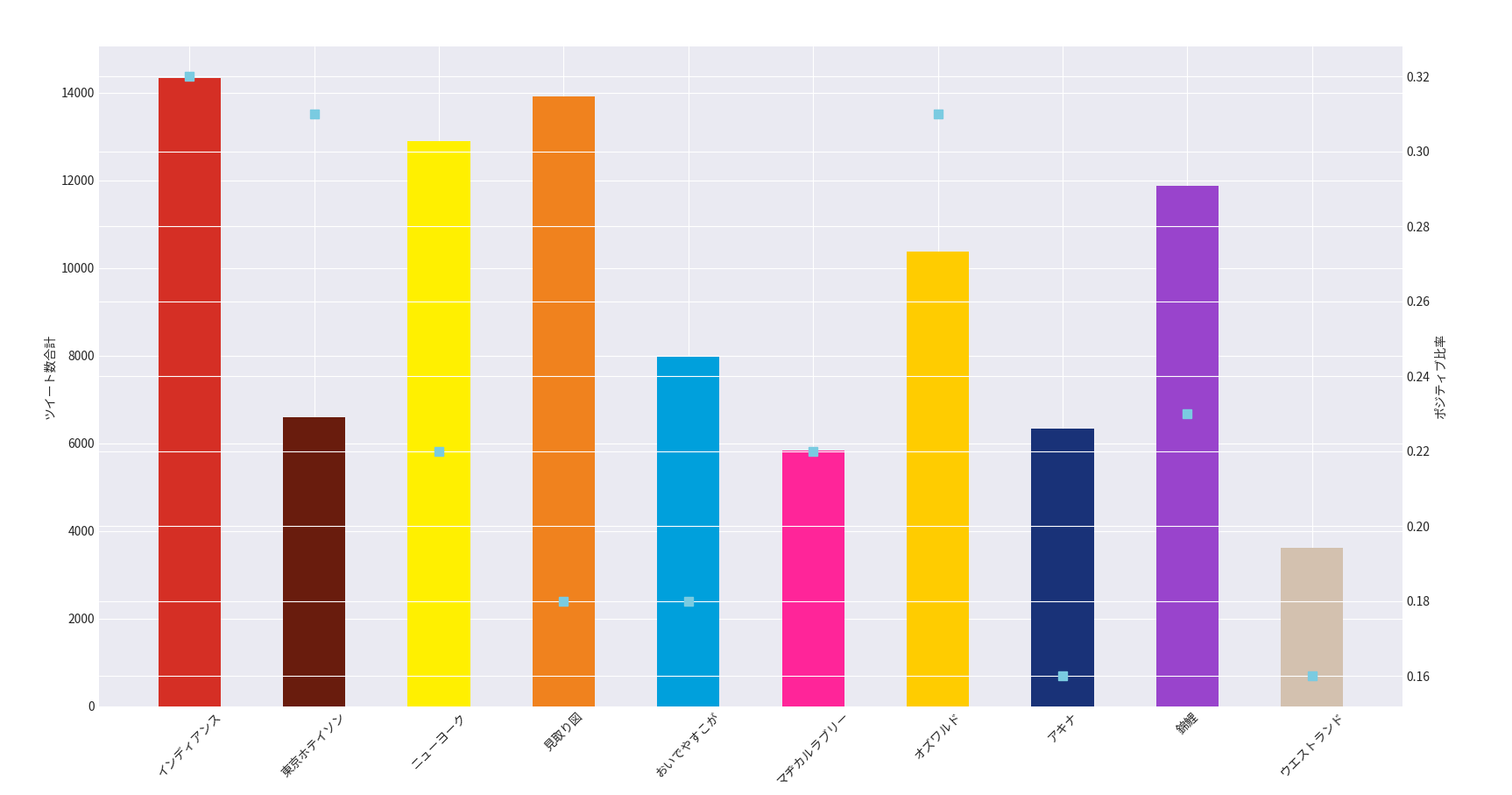
図3.12/24 19:20-21:40のツイート数合計と疑似支持率
棒グラフが大会時間中でのツイート数の合計を表しており、水色の点グラフがポジティブワードの比率、つまり疑似支持率を表しております。
さて、どうでしょう。
ここでもまた、インディアンスのデータは公平なデータかどうかが分かりませんね。結果だけ見るとインディアンスが疑似支持率1位の視聴者愛され芸人ということになりますが、インディアンスはなにぶん敗者復活組ゆえ単純に面白ったのか敗者復活での感想が流れてきているのかが正確に読めません。
ということで、今回も申し訳ないですがインディアンスは一旦保留させて頂きます(これだけ除外していると、ヤンキーたらちゃんにしめられそうですが)
インディアンスを省くと、抜きんでている2組が目立ってきますね。それが東京ホテイソンとオズワルドです。
東京ホテイソンはネタ順も悪く順位も残念ながら最下位となりましたが視聴者は案外面白くなかったとは思っていないのではないでしょうか?
また、錦鯉が本大会最年長であるのに対して、東京ホテイソンは本大会最年少となります。結成も5年と歴も浅いのでこれからの活躍に期待できますね。
次に、オズワルド。
事前人気7番手でどことなくニューヨークや見取り図の影に隠れてしまっている印象を受けますが、データは意外にも好意的な反応が多いです。
かくいう私も改名というテーマを深々と掘り下げるスタイルは好印象でした。
ということで、みんな実はニューヨークや見取り図よりも意外とオズワルドのことが好きなんじゃね?という疑問を、
ここではオズワルドのこと好き仮説と呼びます。
このオズワルドのこと好き仮説については、後々違うデータで見ていきましょう。
3-3.Youtube再生数の事後観察
ところで、M1グランプリ2020の決勝ネタは全てYoutubeに上がっております。
M-1グランプリチャンネル
せっかくなので最後に12月24日時点のYoutubeでの再生数を見て、これまでの分析がどれくらい正しそうか答え合わせしてみましょう。
では、早速集計結果を見ていきましょう。
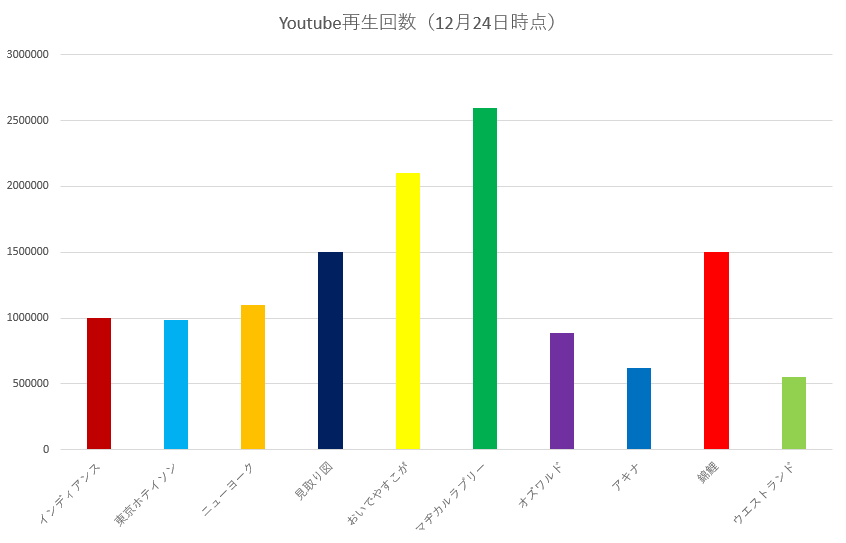
図4.Youtube再生回数(12月24日時点)
まず、1,2,3位をM1ファイナルラウンド進出者が占めているのがわかります。
ですが、見てください。
同率3位として、あの関西では怖いもの知らずの見取り図と並んでいるのは誰でしょう?
そう、錦鯉です!
ツイート数で圧倒的だった錦鯉のYoutube再生回数は、同様に圧倒的でした。これは来年のネクストブレイク間違いなしといえるんじゃないでしょうか。
そして、5位以下の中間層としてニューヨーク、インディアンス、東京ホテイソン、オズワルドが並びます。
東京ホテイソンが事前人気1位のニューヨークに並んでいます。やはり、東京ホテイソンにM1最下位の烙印を押すのはまだ早いということを示唆していますね。
さて、一方のオズワルドですが。。。
Youtube再生回数現在8位です。
8位
あれ?疑似支持率はどこいった?
まさか、オズワルドへのポジティブワードは芸人のオズワルド兄ではなく、女優のオズワルド妹に送られていた言葉だった??
見取り図盛山「あと、オズワルドのこと好き仮説ってなにぃ!?」

図5.オズワルドツッコミ担当の妹であり女優 伊藤沙莉氏
おわりに
くぅ~疲れましたw これにて完結です!
そこそこ分析じみたことができたのではないでしょうか?
この記事が皆さまにとってM1グランプリ2020を二度楽しめるものになっていましたら筆者冥利に尽きます。
また、来年に向けては視聴者の出身地、年齢、性別も加えて分析できたら面白いとは思いますが、個人情報なのでちょっと難しそうですね。
あとは、今回の集計期間M1終了の22時としてしまいましたが、疑似支持率に関しては開催日の翌日くらいまでは集計してみると本当の支持率が得られそうだなと思いました。
それでは、長々と最後までお付き合いいただきありがとうございました。
どこぞの素敵なサンタさんが私にMacのM1チップをプレゼントしてることを祈りながら、クリスマスをゆっくり過ごさせて頂こうと思います。
それでは皆さま、良いお年を――
了
参考
[1] M-1グランプリ2017の審査に対する数学的な反論「1点の格差」「トップバッターは不利」
[2] データで見るM1グランプリ2017 〜本当に一番面白かったのはどの漫才だったのか〜
[3] 主成分分析で振り返るM-1グランプリ
TL;DR おまけ
ここからは私が徹夜で朝までぼーっと取得したツイートを眺めていて、特に気に入ったものをご紹介します。
・アキナ
「アキナは山名を見てほっこりした」
「アキナ以降明らかに空気重くなってない?」
・インディアンス
「決勝のインディアンスさんは、勢いが凄かった。M-1の事前番組で「敗者復活組は失うものがない」っていう表現されてたけど今年のインディアンスさんはまさにそれだったし、かっこよかったな」
「アドリブ、テンポ、ボケ、笑顔すべてが推しです。インディアンスしか勝たん」
・おいでやすこが
「おいでやすこが、なんか奇跡起こしてー」
・オズワルド
「そういえばオズワルドは決勝で寿司出さないといけない呪いでもあるんすかね」
「オズワルド伊藤みたいな人、友達の友達にいがち」
・ニューヨーク
「ニューヨーク彼女の実家に挨拶行くネタやったらいけてたかもしれんな」
「考えてみて、キース
僕たちあと数時間でホモになれるんだ!
革パンでK MARTに入っても誰も気づきやしない!
ニューヨークで革パン履いてたらゲイ決定だけど、あそこにはホットなカウボーイ達が皆革パンだからね…」
・マヂラブ
「脱衣ストリートファイターからマヂカルラブリー推し」
「マヂカルラブリーは掴みで「漫才王です」って言ってほしい」
・錦鯉
「トレンドに錦鯉だけさん付けで入ってるのちょっとおもしろい」
「錦鯉は見た目で損してるから仕方ない」
「錦鯉まさのり、一文無し参上の口上使ってるけど
実際に100万の借金作って自己破産経験してるから本当に面白いんだよな」
・見取り図
「見取り図はの片方はロン毛でラップが凄いイメージ」
「ところで何で見取り図って名前なん?見取り図でもかいたん」
・東京ホテイソン
「小池推しは東京ホテイソン大好きだもんな」
「アンミカドラゴンが注目され、BEAMSのシャツが売り切れたのに、何で東京ホテイソンが最下位に」
・ウエストランド
「ウエストランドいいなぁ
面白さで言うと8位だけど自我で言うと1位」