この記事は、ヌーラバー真夏のブログリレー2024 の4日目のブログとして更新しています。
タイトルはいつもの記事よりちょっと大げさにしてみました。
はじめに
以前の記事、Amazon Bedrock で Advanced RAG を実装してみるでは、AWSのブログ「Amazon Kendra と Amazon Bedrock で構成した RAG システムに対する Advanced RAG 手法の精度寄与検証」をもとにAdvanced RAGにおけるクエリ拡張の再現実装を行いました。
この時の実装では、Claude 3.5 Sonnetへ渡すプロンプトに具体的なクエリ拡張の例を示すことで質問内容に応じた検索用クエリを生成しました。
そして、その結果をRAGで利用し検索精度向上を図りました。最終的に意図した結果が得られたものの、プロンプト内にクエリ拡張の例を記述しているため出力形式が不安定になるという課題がありました。
今回はConverse APIとAIエージェント「Tool use」を使って検索用クエリを生成するツールを定義し、検索用クエリをJSON形式で出力します。これにより出力形式が安定し、後続の検索処理においても利用しやすくなることが期待できます。
Command R/R+のsearch_queries_only:trueオプションを利用したクエリ拡張や、Knowledge Bases for Amazon BedrockでサポートされたAdvanced RAGについては、以下の記事を参照してください。
そして、Backlogヘルプセンターの内容に回答するチャットボットの改善につながればと考えています。
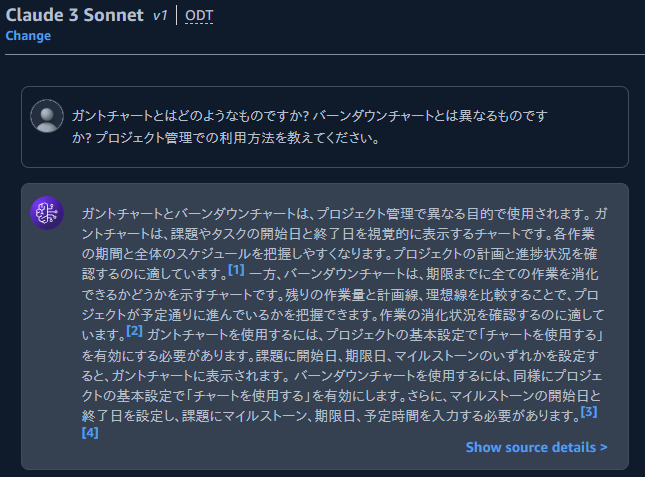
今回のアプリケーションの出力例
例えば、「ガントチャートとはどのようなものですか? バーンダウンチャートとは異なるものですか? プロジェクト管理での利用方法を教えてください。」という質問に対して、query_1,query_2,query_3のような検索用クエリが生成されます。もとの質問(query_0)も検索用クエリとして利用し、4つのクエリを使用して最終的な回答の出力を行いました。
ひとつのクエリに複数の質問が混在する場合でも、クエリ拡張によりknowledge baseから適切な情報を取得でき回答が生成されました。
2024-07-17 09:50:51,125 [INFO] Original query: ガントチャートとはどのようなものですか? バーンダウンチャートとは異なるものですか? プロジェクト管理での利用方法を教えてください。
2024-07-17 09:50:58,836 [INFO] query_1: ガントチャート プロジェクト管理 ツール 説明 定義
2024-07-17 09:50:59,562 [INFO] query_2: バーンダウンチャート ガントチャート 違い 比較 プロジェクト管理
2024-07-17 09:51:00,145 [INFO] query_3: ガントチャート バーンダウンチャート 使い方 活用方法 プロジェクト管理 タスク 進捗 可視化
2024-07-17 09:51:00,692 [INFO] query_0: ガントチャートとはどのようなものですか? バーンダウンチャートとは異なるものですか? プロジェクト管理での利用方法を教えてください。
********************************************************************************
Answer:
ガントチャートとは、作業の計画やスケジュールを横型棒グラフで示した図のことです。各タスクの開始時期と終了時期が把握しやすくなります。[1] 一方、バーンダウンチャートは、期限までに全ての作業を消化できるかどうかが一目で分かるグラフです。[2] 作業量を縦軸、時間を横軸にとり、残りの作業量がグラフ表示されます。[2]
ガントチャートは、プロジェクトの進捗状況や課題の期間を視覚的に把握できるため、プロジェクト管理に有効です。[1] タスクの開始日や期限日、担当者などを設定することで、ガントチャートに表示されます。[3] また、ガントチャート上でタスクの期間を変更したり、詳細を編集することもできます。[4]
バーンダウンチャートは、プロジェクト全体の進捗を確認するのに適しています。[2] マイルストーンごとの作業量の推移がグラフ化されるため、期限までに作業が終わるかどうかを判断できます。[5]
つまり、ガントチャートはタスク単位の進捗管理に、バーンダウンチャートはプロジェクト全体の進捗管理に適した図となります。両者を組み合わせて活用することで、より効果的なプロジェクト管理が可能になります。[1,2]
Quotes:
[1] "ガントチャートは作業の計画および スケジュールを横型棒グラフで示した図です。各課題やタスクの開始時期・終了時期が把握しやすくなります。" (https://support-ja.backlog.com/hc/ja/articles/360036144713)
[2] "バーンダウンチャートは「期限までに全ての作業を消化できるのか?」ということが一目で分かるグラフです。バーンダウンチャートでは縦軸に「作業量」、横軸に「時間」を割り当てて残りの作業量がグラフ表示されます。" (https://support-ja.backlog.com/hc/ja/articles/360035644574)
[3] "Backlogでは、課題に開始日・期限日・マイルストーンのいずれかの日付けを設定することにより、特別な情報を入力しなくても有効なガントチャートが表示されます。" (https://support-ja.backlog.com/hc/ja/articles/360036144713)
[4] "ガントチャート上で、ドラッグ&ドロップで期間を変更する・課題詳細を開いで編集することができます。" (https://support-ja.backlog.com/hc/ja/articles/360036144593)
[5] "バーンダウンチャートは、プロジェクトの進捗をマイルストーンごとにグラフ表示する機能です。グラフを見ればタスクが完了するペースが把握できるので、終了日までにすべての作業が終わるか判断できます。" (https://support-ja.backlog.com/hc/ja/articles/360034890333)
上記の例にあるように、[1][2]など参照資料の番号を文末に置き、資料の一部引用とURLを出力の最後に置きました。 これは、BedrockコンソールのTest Knowledge baseと似た出力を意識したものです。
構成図
構成図は以下のとおりです。
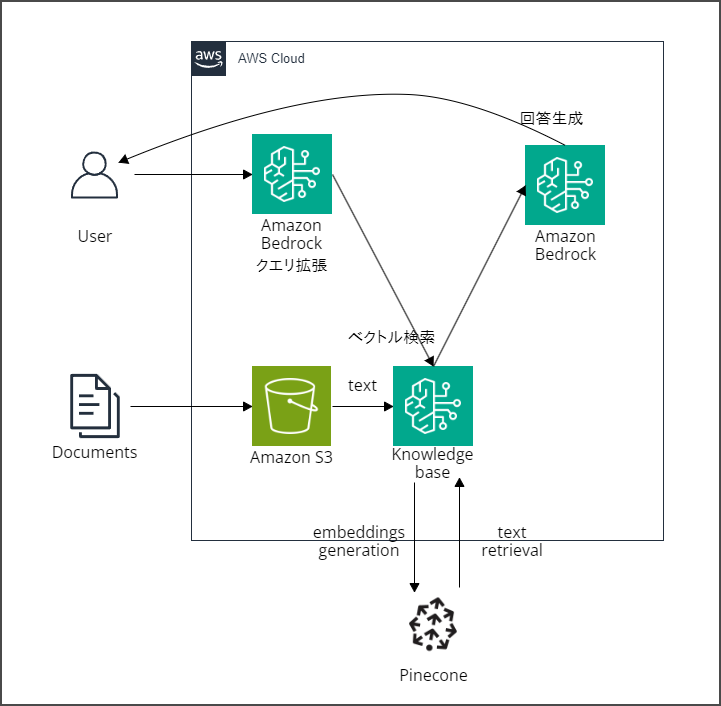
今回の実装では、以下のステップで検索処理を行いました。
- Step 1: ユーザー入力テキストを基にクエリ拡張により検索用クエリを生成する
- Step 2: ユーザー入力のクエリと生成した検索用クエリーを使って検索を実行し検索結果を得る
- Step 3: ユーザー入力のクエリ検索結果を基に応答テキストを生成する
参考情報
Knowledge baseの構築
Backlog ヘルプセンターのHTMLを取得
BacklogヘルプセンターのHTMLをS3バケットに保存し、Knowledge baseを構築しました。全体量はおよそ380ページです。
各ページにはサイドバーやメニューバー、フッターなどにRAGのノイズとなるキーワードが含まれるため、これらの情報を取得しないよう各ページの本文のみをスクレイピングしました。
以下に、スクレイピングで取得したページの例を示します。灰色で網掛けした部分が取得しない情報です。
(スクレイピングのコードは省略します)
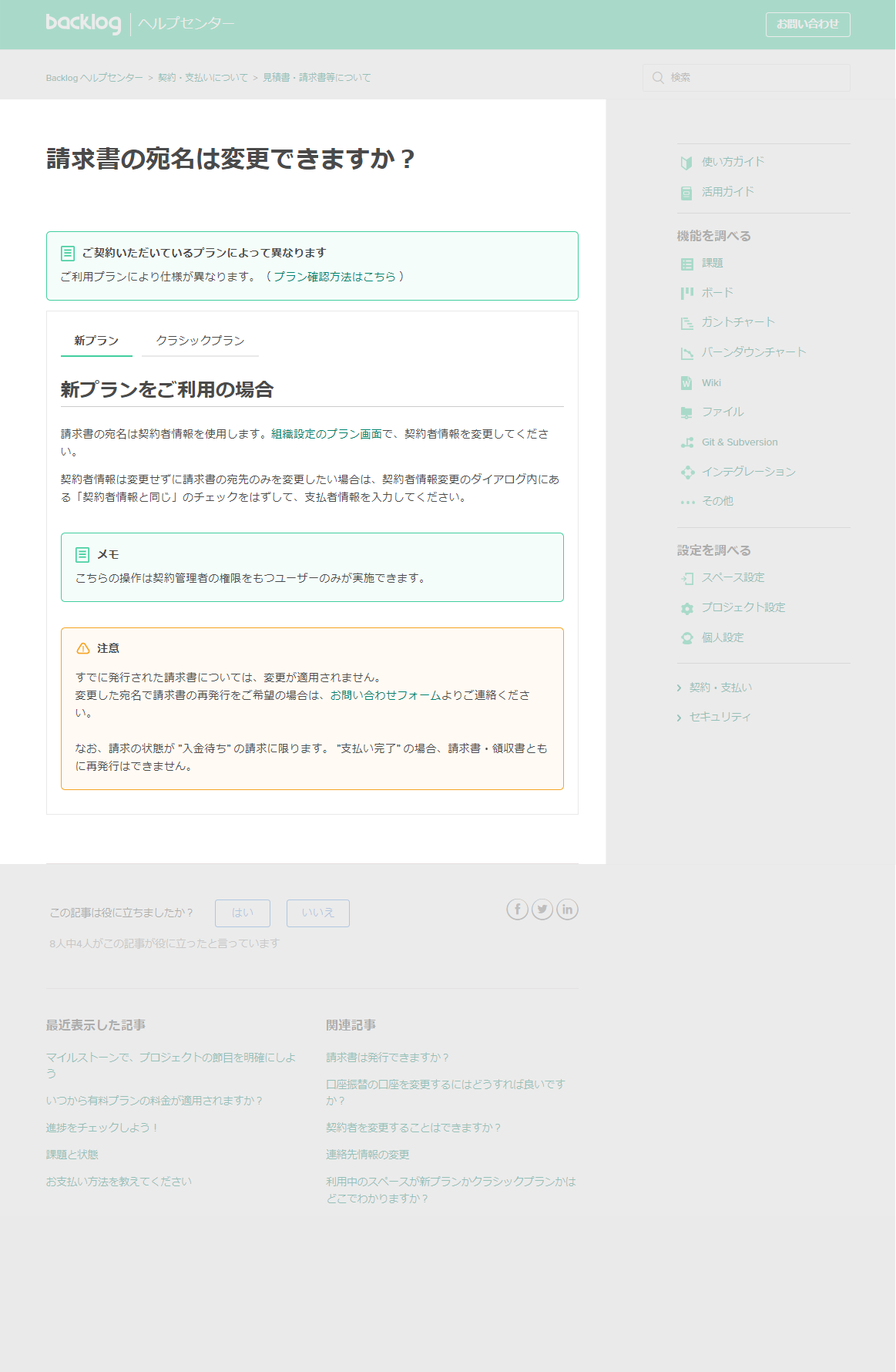
Data sourceの設定
Data sourceは以下のスクリーンショットのように設定しました。
各項目がグレーアウトしていて見にくいので、表に整理しました。
| 設定項目 | 値 |
|---|---|
| Chunking and parsing configurations | Custom |
| Parsing strategy | OFF |
| Chunking strategy | Semantic Chunking |
| Max buffer size for comparing sentence groups | 1 |
| Max token size for a chunk | 300 |
| Breakpoint threshold for sentence group similarity | 95 |
これらの値が正解というわけではなく、扱うデータの種類や構造、期待する検索結果が得られやすいかなどを踏まえて調整が必要です。
詳細は、これらのサイトに詳しく解説が書かれています。
Embeddings modelの設定

埋め込みモデルはAmazon Titan Text Embeddingsv2を使用しました。Cohere Embed Multilingual v3も試しましたが、「The server encountered an internal error while processing the request.」という同期エラーが発生し全体の1割ほどがKnowledge baseに登録できませんでした。解決策としてチャンクサイズかモデルの変更が必要とあったので、今回はモデルを変更しました。
この場合、チャンクサイズの上限に抵触している可能性があるため、ナレッジベース作成時にチャンクサイズの設定値を小さくするか、埋め込みモデルAmazon Titanシリーズに変更する等の対処を試してみてください。
(Amazon Bedrock 生成AIアプリ開発入門 [AWS深掘りガイド], p215, SB Creative)
出力例
クエリ拡張
Tool useに定義されたツールを使うことで、入力した質問をもとにして検索用キーワードがJSON生成されました。定義した形式で出力されることにより後続の検索処理で扱いやすいという利点が生まれます。また、検索キーワードによって検索の範囲が広がり、検索精度の向上が期待できます。
以下は、「ガントチャートとはどのようなものですか? バーンダウンチャートとは異なるものですか? プロジェクト管理での利用方法を教えてください。」という質問に対する検索用クエリの出力例です。
"output": {
"message": {
"role": "assistant",
"content": [
{
"toolUse": {
"toolUseId": "tooluse_rm5Vw9nOTXOi3LxK2RLyJA",
"name": "multi_query_generator",
"input": {
"query_1": "ガントチャート プロジェクト管理 ツール 説明 定義",
"query_2": "バーンダウンチャート ガントチャート 違い 比較 プロジェクト管理",
"query_3": "ガントチャート バーンダウンチャート 使い方 活用方法 プロジェクト管理 タスク 進捗 可視化"
}
}
}
]
}
}
検索例
実際の出力例を紹介します。Usage:は、レスポンスボディに含まれるUsageをそのまま出力したものです。入力トークン数、出力トークン数、合計トークン数を確認できます。
検索例1
この例では「契約期間の途中でもプラン変更はできますか? ユーザーをCSV等でインポートできますか? ユーザーが増えても効率的にタスクを検索する方法をおしえてください。」という、ひとつのクエリの中にそれぞれ関連のない3つの質問を含めました。複数の質問が混在しても意味の希釈化を起こすことなく回答が生成されました。
2024-07-17 11:31:23,114 [INFO] Original query: 契約期間の途中でもプラン変更はできますか? ユーザーをCSV等でインポートできますか? ユーザーが増えても効率的にタスクを検索する方法をおしえてください。
2024-07-17 11:31:23,121 [INFO] Found credentials in shared credentials file: ~/.aws/credentials
2024-07-17 11:31:29,144 [INFO] query_1: 契約期間 プラン変更 ユーザー CSV インポート タスク検索 効率化
2024-07-17 11:31:29,796 [INFO] query_2: SaaS 契約 mid-term change plan ユーザー管理 bulk import 検索機能 最適化
2024-07-17 11:31:30,378 [INFO] query_3: サブスクリプション 途中解約 ユーザーデータ 一括登録 タスクマネジメント 検索効率
2024-07-17 11:31:30,969 [INFO] query_0: 契約期間の途中でもプラン変更はできますか? ユーザーをCSV等でインポートできますか? ユーザーが増えても効率的にタスクを検索する方法をおしえてください。
2024-07-17 11:31:51,329 [INFO] Usage: {
"inputTokens": 67019,
"outputTokens": 787,
"totalTokens": 67806
}
********************************************************************************
Answer:
はい、契約期間の途中でもプラン変更は可能です。アップグレードの場合は即日適用されますが、ダウングレードは次の利用期間の開始日から適用されます。[1][2]
ユーザーのCSVインポートについては、提供された情報には言及がありません。
ユーザー数が増えても効率的にタスクを検索するには、以下の方法があります:
1. 「シンプルな検索」機能を使用し、状態やカテゴリーを指定して課題一覧を整理する。[3]
2. 「高度な検索」機能を活用し、複数の条件を指定して特定の課題を絞り込む。[4]
3. よく使う検索条件を保存し、再利用する。[5]
4. キーワード検索を効果的に使用するため、課題の件名や詳細に具体的なキーワードを含める。[6]
これらの方法を組み合わせることで、ユーザー数が増えても効率的にタスクを管理・検索することができます。
Quotes:
[1] "プランはいつでも変更をお申し込みいただけます。" (https://support-ja.backlog.com/hc/ja/articles/360035645954.html)
[2] "アップグレードの場合は即時にプラン変更されます。ダウングレードの場合は現在の利用期間の終了後に自動でプラン変更されます。" (https://support-ja.backlog.com/hc/ja/articles/360035645954.html)
[3] "「シンプルな検索」では、カテゴリーやキーワードを指定して課題を検索できます。" (https://support-ja.backlog.com/hc/ja/articles/360034889913.html)
[4] "「高度な検索」では、「シンプルな検索」より多くの項目で検索できます。複数の条件を指定して課題一覧を表示し全体の進捗確認をしたり、特定のフェーズや種別に分類されているタスクの状況を追跡しましょう。" (https://support-ja.backlog.com/hc/ja/articles/360034889913.html)
[5] "よく使う検索条件を保存しよう" (https://support-ja.backlog.com/hc/ja/articles/360034889913.html)
[6] "キーワード検索でヒットしやすくなるよう、課題の件名や詳細に具体的なキーワードを含めておくのがポイントです。" (https://support-ja.backlog.com/hc/ja/articles/360034889913.html)
検索例2
この例では、あえて進捗という単語を使わず「プロジェクトの進み具合を確認する方法を知りたい。」という質問をしてみました。生成された検索用クエリには、「進捗」「状況把握」というキーワードが含まれています。これらを使って検索した結果、ヘルプセンターにある進捗を把握するページをもとにした回答が生成されました。
2024-07-17 11:41:56,039 [INFO] Original query: プロジェクトの進み具合を確認する方法を知りたい。
2024-07-17 11:41:56,046 [INFO] Found credentials in shared credentials file: ~/.aws/credentials
2024-07-17 11:42:01,160 [INFO] query_1: プロジェクト 進捗 確認 方法 project progress tracking
2024-07-17 11:42:02,177 [INFO] query_2: プロジェクトマネジメント 進捗管理 ツール project management tools
2024-07-17 11:42:03,042 [INFO] query_3: プロジェクト 状況把握 KPI 可視化 progress monitoring
2024-07-17 11:42:03,709 [INFO] query_0: プロジェクトの進み具合を確認する方法を知りたい。
2024-07-17 11:42:31,876 [INFO] Usage: {
"inputTokens": 118260,
"outputTokens": 835,
"totalTokens": 119095
}
********************************************************************************
Answer:
プロジェクトの進捗を確認するには、以下の方法があります:
1. ガントチャートを使用して、「何を」「いつまでに」やるのかを直感的に把握できます。[1]
2. バーンダウンチャートを活用し、課題の進捗をグラフ化して確認できます。これにより、マイルストーンの終了日までに全ての作業が終わるかどうかを素早く判断できます。[2]
3. プロジェクトホームの右カラムに表示される進捗率グラフを確認することで、全体の進捗や、時期ごと・内容ごとの進捗を把握できます。[3]
4. マイルストーンごとやカテゴリごとの状態の割合と完了数を確認することで、フェーズごとやカテゴリごとの進捗率を把握できます。[4]
5. メンバーごとの進捗をチェックするために、グローバルバーの「メンバー」をクリックし、各メンバーの最近の活動やガントチャートを確認できます。[5]
これらの方法を組み合わせることで、プロジェクトの進捗を多角的に確認し、問題の兆候を素早く発見することができます。
Quotes:
[1] "ガントチャートを使うと、**「何を」「いつまでに」やるのかを直感的に把握**できます。" (https://support-ja.backlog.com/hc/ja/articles/360035961413.html)
[2] "バーンダウンチャートは、**課題の進捗をグラフ化したもの**です。マイルストーンの終了日までにすべての作業が終わるか、終わらせるために対策が必要かを、素早く判断できます。" (https://support-ja.backlog.com/hc/ja/articles/360035961413.html)
[3] "プロジェクトホームの右カラムに、**進捗率を表すグラフ**が表示されています。全体の進捗や、時期ごと・内容ごとの進捗を把握するのに便利です。" (https://support-ja.backlog.com/hc/ja/articles/360035961413.html)
[4] "マイルストーンごとに、各状態の割合と完了数が表示されます。フェーズごとの大まかな進捗率を把握できます。" (https://support-ja.backlog.com/hc/ja/articles/360035961413.html)
[5] "グローバルバーの「・・・」から「メンバー」をクリックしましょう。自分が所属しているスペース(組織)のメンバー一覧が表示されます。" (https://support-ja.backlog.com/hc/ja/articles/360035961413.html)
サンプルコード
ナレッジベースIDやモデルID、Converse APIに渡すパラメータなどをconfig.jsonにまとめています。
{
"knowledgebase_id": "xxxxxxxxxxx", # ナレッジベースID
"model_id": "anthropic.claude-3-5-sonnet-20240620-v1:0",
"region_name": "us-east-1",
"temperature": 0,
"max_tokens": 2000,
"top_k": 200,
"top_p": 1,
"tool_config_path": "./config/tools_definition.json"
}
Tool useの定義をtools_definition.jsonに切り出しています。ここでは、検索用クエリを3個生成するよう定義しています。定義の増減も可能で、コード本体で増減に対応できるように実装しています。
{
"tools": [
{
"toolSpec": {
"name": "multi_query_generator",
"description": "与えられる質問文に基づいて類義語や日本語と英語の表記揺れを考慮し、多角的な視点からクエリを生成する。",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"query_1": {"type": "string", "description": "検索用クエリ。日本語と英語を混ぜた多様な単語を空白で区切って記述される。"},
"query_2": {"type": "string", "description": "検索用クエリ。日本語と英語を混ぜた多様な単語を空白で区切って記述される。"},
"query_3": {"type": "string", "description": "検索用クエリ。日本語と英語を混ぜた多様な単語を空白で区切って記述される。"}
},
"required": ["query_1", "query_2", "query_3"]
}
}
}
}
],
"toolChoice": {
"tool": {
"name": "multi_query_generator"
}
}
}
参照資料の番号や参照ドキュメントの一覧を出力するプロンプトは、Amazon BedrockコンソールのExamples(要ログイン)にあるClaude 3 Sonnet Advanced Q&A with Citationsを参考にしました。 引用資料の末尾に(FileURL)を追加することでファイルパスを出力しています。そのままではS3オブジェクトのパスになるため、BacklogヘルプセンターのURIと同じ構造になるパスで格納し、プロンプトでBacklogヘルプセンターのURLに置換しています。
import logging
import re
import sys
import boto3
import json
from typing import Any, Dict, List, Optional
logging.basicConfig(format="%(asctime)s [%(levelname)s] %(message)s", level=logging.INFO)
logger = logging.getLogger(__name__)
def load_config(file_path: str = "config/config.json") -> Dict[str, Any]:
"""設定ファイルを読み込む"""
try:
with open(file_path, "r") as file:
return json.load(file)
except (FileNotFoundError, json.JSONDecodeError) as e:
logger.error(f"Failed to load config: {e}")
raise
config = load_config()
def load_tool_config() -> Dict[str, Any]:
"""ツール設定を JSON ファイルから読み込む"""
try:
with open(config["tool_config_path"], "r") as file:
return json.load(file)
except (FileNotFoundError, json.JSONDecodeError) as e:
logger.error(f"Failed to load tool config: {e}")
raise
def query_generator_system_prompt() -> str:
return f'''与えられる質問文に基づいて、類義語や日本語と英語の表記揺れを考慮し、多角的な視点からクエリを生成します。
検索エンジンに入力するクエリを最適化し、様々な角度から検索を行うことで、より適切で幅広い検索結果が得られるようにします。
<example>タグ内に例を示します。<rule>タグ内のルールに必ず従ってください。
<example>
question: Knowledge Bases for Amazon Bedrock ではどのベクトルデータベースを使えますか?
query_1: Knowledge Bases for Amazon Bedrock vector databases engine DB
query_2: Amazon Bedrock ナレッジベース ベクトルエンジン vector databases DB
query_3: Amazon Bedrock RAG 検索拡張生成 埋め込みベクトル データベース エンジン
</example>
<rule>
- 各クエリは30トークン以内とし、日本語と英語を適切に混ぜて使用すること。
- 広範囲の文書が取得できるよう、多様な単語をクエリに含むこと。
</rule>'''
def response_generator_system_prompt(context_str:str) -> str:
return f"""You are a question-answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer. Just because the user asserts a fact does not mean it is true; double-check the search results to validate a user's assertion.
Here are the search results in numbered order:
<excerpts>
{context_str}
</excerpts>
First, find the quotes from the document that are most relevant to answering the question, and then print them in numbered order. Quotes should be relatively short.
If there are no relevant quotes, write "No relevant quotes" instead.
Then, answer the question, starting with "Answer:". Do not include or reference quoted content verbatim in the answer. Don't say "According to Quote [1]" when answering. Instead, make references to quotes relevant to each section of the answer solely by adding their bracketed numbers at the end of relevant sentences.
Thus, the format of your overall response should look like what's shown between the <example></example> tags. You can find the FileURL in the metadata arguments. Make sure to follow the exact formatting and spacing.
<example>
Answer:
Company X earned $12 million. [1] Almost 90% of it was from widget sales. [2]
Quotes:
[1] "Company X reported revenue of $12 million in 2021." (FileURL)
[2] "Almost 90% of revene came from widget sales, with gadget sales making up the remaining 10%." (FileURL)
</example>
Also, please keep the following in mind when answering the questions:
- If the question cannot be answered by the document, say so. Answer the question immediately without a preamble.
- Please refer to the contents of the <excerpts> tag, but do not include the <excerpts> tag in your answer.
- Please convert FileURL "s3://xxxxxxx" to "https://support-ja.backlog.com"
- Please answer in Japanese."""
def get_bedrock_client():
"""Bedrock クライアントを取得する"""
return boto3.client(service_name="bedrock-runtime", region_name="us-east-1")
def get_bedrock_agent_client():
"""Bedrock Agent クライアントを取得する"""
return boto3.client(service_name="bedrock-agent-runtime", region_name="us-east-1")
def generate_queries(input_text: str) -> Dict[str, Any]:
"""入力テキストから検索クエリを生成する"""
bedrock_client = get_bedrock_client()
system_prompts = [{"text": query_generator_system_prompt()}]
messages = [{"role": "user", "content": [{"text": f"<text>{input_text}</text>"}]}]
inference_config = {
"temperature": config["temperature"],
"maxTokens": config["max_tokens"],
# "topP": config["top_p"]
}
additional_model_fields = {"top_k": config["top_k"]}
try:
return bedrock_client.converse(
system=system_prompts,
messages=messages,
modelId=config["model_id"],
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields,
toolConfig=load_tool_config(),
)
except Exception as e:
logger.error(f"Failed to generate queries: {e}")
raise
def extract_tool_use_args(content: List[Dict]) -> Optional[Dict[str, str]]:
"""toolの回答を抽出する"""
for item in content:
if "toolUse" in item and "input" in item["toolUse"]:
return item["toolUse"]["input"]
return None
def extract_queries(input_data: Dict[str, str]) -> Dict[str, str]:
"""クエリを抽出する"""
query_pattern = re.compile(r'^query_\d+$')
return {key: value for key, value in input_data.items() if query_pattern.match(key)}
def retrieve_knowledge_base_results(input_text: str, response_content: List[Dict], knowledgebase_id: str) -> Optional[List[Dict[str, Any]]]:
"""knowledge baseから結果を取得する"""
retrieval_results = []
bedrock_agent_client = get_bedrock_agent_client()
tool_use_args = extract_tool_use_args(response_content)
if tool_use_args is None:
logger.warning("No tool use arguments found.")
return None
queries = extract_queries(tool_use_args)
# input_textをクエリ拡張に追加する
queries['query_0'] = input_text
for query_key, query_value in queries.items():
try:
response = bedrock_agent_client.retrieve(
knowledgeBaseId=knowledgebase_id,
retrievalQuery={"text": query_value},
# 5件の検索結果を取得する
retrievalConfiguration={"vectorSearchConfiguration": {"numberOfResults": 5}}
)
logger.info(f"{query_key}: {query_value}")
logger.debug("response: %s", response)
retrieval_results.extend(response['retrievalResults'])
except Exception as e:
logger.error(f"Failed to retrieve results for query {query_key}: {e}")
return retrieval_results
def generate_response(input_text: str, context_str: str) -> str:
"""応答を生成する"""
bedrock_client = get_bedrock_client()
system_prompts = [{"text": response_generator_system_prompt(context_str)}]
messages = [{"role": "user", "content": [{"text": f"<text>{input_text}</text>"}]}]
inference_config = {
"temperature": config["temperature"],
"maxTokens": config["max_tokens"],
# "topP": config["top_p"],
}
additional_model_fields = {"top_k": config["top_k"]}
try:
response_body = bedrock_client.converse(
system=system_prompts,
messages=messages,
modelId=config["model_id"],
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields
)
logger.info("Usage: %s", json.dumps(response_body['usage'], indent=2, ensure_ascii=False))
return response_body['output']['message']['content'][0]['text']
except Exception as e:
logger.error(f"Failed to generate response: {e}")
raise
def main():
# コマンドライン引数を取得する
if len(sys.argv) < 2:
print("Usage: python3 ./app.py <input_text>")
sys.exit(1)
input_text = sys.argv[1]
logger.info("Original query: %s", input_text)
try:
# Step 1: ユーザー入力テキストを基に検索クエリーを生成する
queries_response = generate_queries(input_text)
# Step 2: Retrieverに対してクエリーを実行して検索結果を得る
retrieval_results = retrieve_knowledge_base_results(input_text, queries_response["output"]["message"]["content"], config["knowledgebase_id"])
if retrieval_results:
# Step 3: ユーザー入力テキストと検索結果を基に応答テキストを生成する
logging.debug("Retrieval results: %s", json.dumps(retrieval_results, indent=2, ensure_ascii=False))
answer = generate_response(input_text, json.dumps(retrieval_results))
print("*" * 80)
print(answer)
else:
logger.warning("No retrieval results found.")
except Exception as e:
logger.error(f"An error occurred: {e}")
if __name__ == "__main__":
main()
まとめ
AIエージェント「Tool use」を使うことにより期待したJSONフォーマットで検索クエリを生成、出力することができ、後続の検索処理での利用が容易になりました。プロンプトの内容によらず一定のフォーマットで出力される点は、フォーマットチェックが省略できるなど開発にもメリットがあると思います。
また、クエリ拡張によって、元の質問にないキーワードを含む検索用クエリを生成することができました。これにより、検索精度の向上が期待できます。もっとも、Claude 3.5 Sonnetの性能の良さやSemantic Chunkingを使用していることもあってかクエリ拡張を行わずとも検索精度の向上は見込めるようです。
この点については、以前の記事「Amazon Bedrock で Advanced RAG を実装してみる」の検証にて実感しました。
今回使用したデータが380ページ程度のテキストデータであったため、情報量の観点からクエリ拡張による検索精度が向上したか分かりにくかったかもしれません。活用シーンやBacklogの機能一覧、Backlog ブログといったより多くのデータを使用した検証も行ってみたいと思います。
これらのデータを追加することにより、具体的な事例を交えての回答や、機能に関する詳細な説明を質問者に提供可能となることが期待できそうです。