はじめに
AWS Blog "Build and deploy an automatic sync solution for Amazon Bedrock Knowledge Bases" では、Amazon Bedrock ナレッジベース向けの自動同期ソリューションを構築およびデプロイする方法を紹介しています。
この AWS Blog 記事は、2026年4月27日に公開されました。検証を行った2026年5月時点では、EventBridge 経由の S3 イベントが適切に処理されない事象や、Knowledge Base への取り込み処理が完了してもステータスが更新されない事象が発生しました。
そこで、本記事ではこれらの事象を解消するための修正と動作検証を行い、運用上の注意点を紹介します。
参考情報
サンプル実装の概要
AWS Blog で紹介されているサンプル実装の概要
構成図
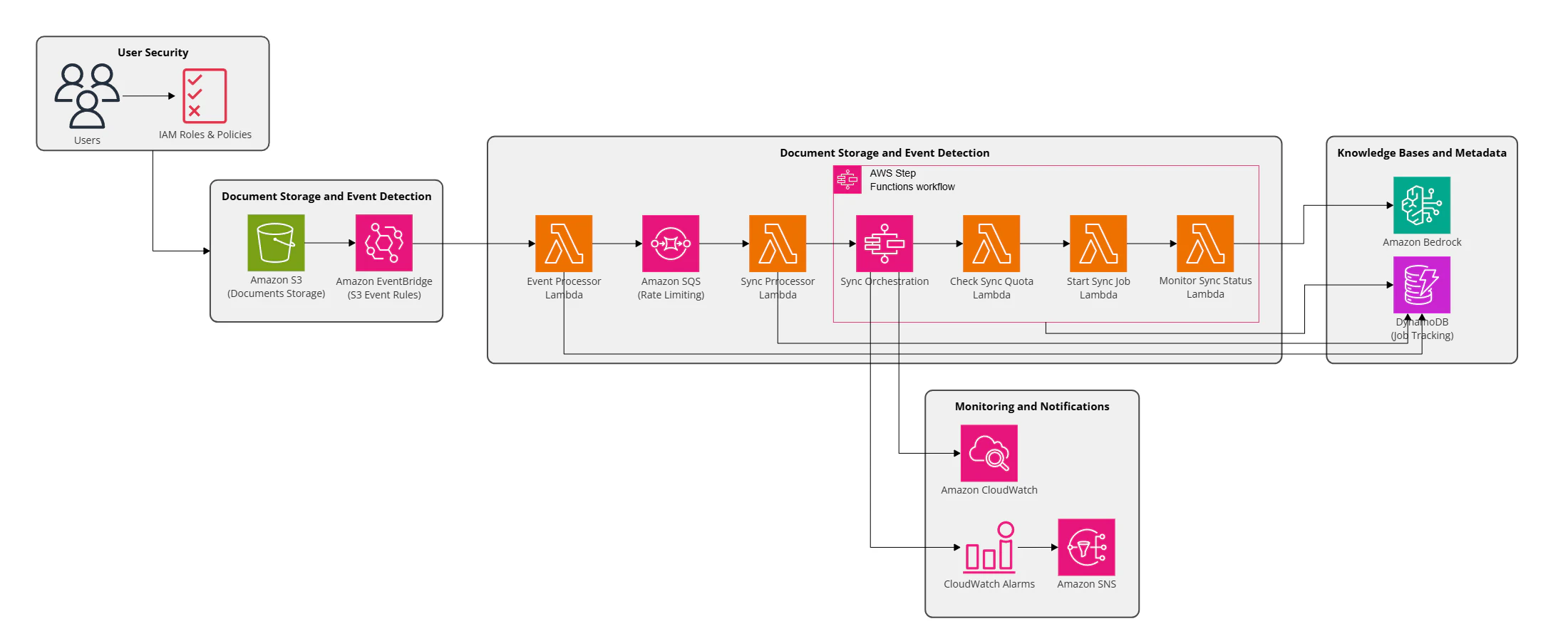
AWS Blog で紹介されているサンプル実装の全体構成図の画像解像度が低く拡大しても見辛いため、上記の図を再作成しました。元の記事にある図では Event Processor Lambda と Sync Processor Lambda から DynamoDB につながる線がなかったため、追記しました。
AWS Blog で紹介されているサンプル実装では、以下のワークフローが実行されます。AWS Blog にも書かれているとおり、このソリューションはクォータ制限を考慮し、超過時の再実行性を高めるための設計となっています。
Phase 1: ドキュメント変更の検知
- ユーザーが Amazon S3 にドキュメントをアップロード/更新/削除
- Amazon EventBridge が S3 イベントを捕捉し Event Processor Lambda にルーティング
- Event Processor Lambda が変更タイプ(create / update / delete)を判別し、change_id 付きで Amazon DynamoDB(TRACKING_TABLE)に変更レコードを記録
- Event Processor Lambda が Amazon SQS に変更通知メッセージを送信
Phase 2: キューイングとレートリミット
- Amazon SQS が変更通知メッセージをバッファし、StartIngestionJob のクォータ(10秒に1リクエスト)に合わせて流量を制御
- Sync Processor Lambda が SQS メッセージを 1 件ずつ受信
- ジョブ追跡用のメタデータを Amazon DynamoDB(METADATA_TABLE)に作成し、AWS Step Functions ワークフローを起動
Phase 3: Step Functions によるオーケストレーション
- Check Quota Lambda がサービスクォータ(アカウント5同時/データソース1同時/ナレッジベース1同時)を確認
- クォータ超過時は 5 分待機してリトライ、問題なければ次へ進行
- Start Sync Lambda が StartIngestionJob API を呼び出し同期ジョブを開始、ジョブ ID をメタデータに記録
- Monitor Sync Lambda が GetIngestionJob でステータスを定期確認(未完了なら 60 秒待機して再チェック)
- 終了時は成功/失敗の分岐で後続処理を制御
Phase 4: ナレッジベース側の同期処理
- Amazon Bedrock Knowledge Base がデータソース全体を取り込み
- ドキュメントをベクトル埋め込みに変換しベクトルストアに格納
- セマンティック検索可能な状態で利用可能に
Phase 5: 完了処理・通知・モニタリング
- Monitor Sync Lambda がジョブ完了を検知し、メタデータのステータスを更新
- TRACKING_TABLE の対象変更レコードに ingestion_job_id を設定し処理済みとしてマーク
- Amazon SNS 経由で完了/失敗通知をメールでサブスクライバーに配信
- Amazon CloudWatch ダッシュボードでメトリクスを可視化、アラームで異常を検知
具体例:50 ファイルを一括アップロードした場合
README.mdの例に従うと、以下のようにワークフローが進みます。
- 50 個の S3 イベントが発生 → Event Processor がそれぞれ DynamoDB に変更記録、SQS にメッセージ送信
- SQS が 10 秒間隔でメッセージを Sync Processor に配送
- Sync Processor が Step Functions を起動 → クォータが許せば取り込みジョブ開始。1 ジョブで 50 ファイルすべて(実際にはデータソース全体)を一括取り込み
- 完了後、Monitor Sync Lambda が DynamoDB を更新し SNS 通知
同じくREADME.mdのImportant Note About Amazon Bedrock Knowledge Base Ingestionにもあるとおり、取り込みジョブ(StartIngestionJob)はスコープがデータソース全体のため、変更のあったファイルだけでなくデータソース全体をスキャンします。特定のファイル単位で取り込みを行うには別のAPIを使うことになります。しかし、Knowledge Base のマネージド同期処理が各ファイルの新規/差分/削除を判断して適切に処理するため、このような設計となっていると考えられます。
このように、このソリューションは変更を即座にトラッキングしつつ、サービス制限を守ってまとめて効率的に取り込む設計となっています。
サンプル実装の前提条件と制約
Knowledge Base 配下のデータソースが 1 つだけであること
この実装は、Knowledge Base 配下のデータソースが 1 つだけであることを想定しています。データソースが複数ある場合、list_data_sources API の返却リストの先頭が使用されますが、順序は保証されないため、意図しないデータソースが同期対象になる可能性があります。以下のコードでは、maxResults=10 を設定していますが、dataSourceSummaries[0] で先頭のデータソースを取得しています。
Bedrock Knowledge Base のデータソース同期範囲
StartIngestionJob が実際にスキャンし Bedrock Knowledge Base に同期する範囲は、samconfig.toml の S3KeyPrefix パラメータではなく、Bedrock Knowledge Base のデータソースで設定した S3 URI によって決まります。以下のコードでは、S3KeyPrefix は EventBridge ルールのフィルターとしてのみ使用されます。つまり、Bedrock Knowledge Base のデータソースが s3://example-bucket/ 全体を参照している場合、S3KeyPrefix に documents/ を指定していても、documents/ 以下で発生したイベントを契機に StartIngestionJob が s3://example-bucket/ 以下の全ドキュメントをスキャンします。
これを回避するには、データソース構築時に S3 URI と S3KeyPrefix を一致させる必要があります。
サンプル実装の修正点
EventBridge 経由の S3 イベントが適切に処理されない事象の解消
このサンプル実装は、Event Processor Lambda のトリガーに EventBridge ルールを使用しています。しかし、get_change_type() 関数では、S3 イベント通知を直接利用する実装になっています。
また、この関数の引数 event_name は detail.name というフィールドを参照していますが、AWS のドキュメントによると、EventBridge のペイロードにはそのようなフィールドは存在しません。正しくは、detail-type を参照する必要があります。
これらを解消するために、ペイロードの参照と get_change_type() 関数を修正します。具体的な修正内容はこちらです。
Sync Processor Lambda のメタデータ更新が適切に行われない事象の解消
Event Processor Lambda は change_id を生成して DynamoDB の autosync-tracking テーブルに保存しています。しかし、change_id が SQS メッセージには含まれていません。
Monitor Sync Status Lambda は取り込みジョブが COMPLETE になったときだけ、message の change_ids フィールドを参照して、autosync-tracking テーブルを更新します。
Monitor Sync Status Lambda は取り込みジョブが COMPLETE になったときのみ mark_changes_as_processed() 関数を呼び出します。この関数では、change_ids フィールドを参照して、autosync-tracking テーブルの processed を更新します。しかし、SQS メッセージには change_ids フィールドも含まれていません。そのため、autosync-tracking テーブルの processed は常に False になります。
これを解消するために、SQS メッセージに change_id を含め、Monitor Sync Status Lambda で change_id と change_ids フィールドを参照するように修正します。もともとの設計意図がわからないので、両方に対応するようにします。具体的な修正内容はこちらです。
Concurrent ingestion jobs per account のクォーター数が5であることの確認
README.mdやコード内には、Concurrent ingestion jobs per accountのクォーター数が55と記載されていますが、AWS公式ドキュメント上のクォーター数は5となっています。
これを解消するために、Concurrent ingestion jobs per accountのクォーター数を5に設定します。具体的な修正内容はこちらです。
環境構築
本記事で使用するコードを GitHub に公開しています。
以降、すべての AWS リソースを us-east-1 リージョンで作成することを前提とします。他のリージョンを使用する場合は、記事内のリージョン指定を使用するリージョン名に読み替えてください。
S3 バケットと Bedrock Knowledge Base は手動で作成し、それ以外のリソースは AWS SAM CLI を使用して作成します。
S3バケットの作成
ここでは、3つの S3 バケットを作成します。
- Bedrock Knowledge Base のドキュメント格納用
- S3 サーバーアクセスログ格納用
- マルチモーダル RAG の画像から抽出したテキスト格納用 (任意で作成)
S3 サーバーアクセスログ格納用のバケットも必須ではありませんが、README の Amazon S3 Bucket Security Requirementsに記載されているように、監査用にS3 サーバーアクセスログを有効にすることが推奨されています。
ここでは、Bedrock Knowledge Base のドキュメント格納用バケットの作成手順を紹介します。
Bedrock Knowledge Base のドキュメント格納用の S3 バケット
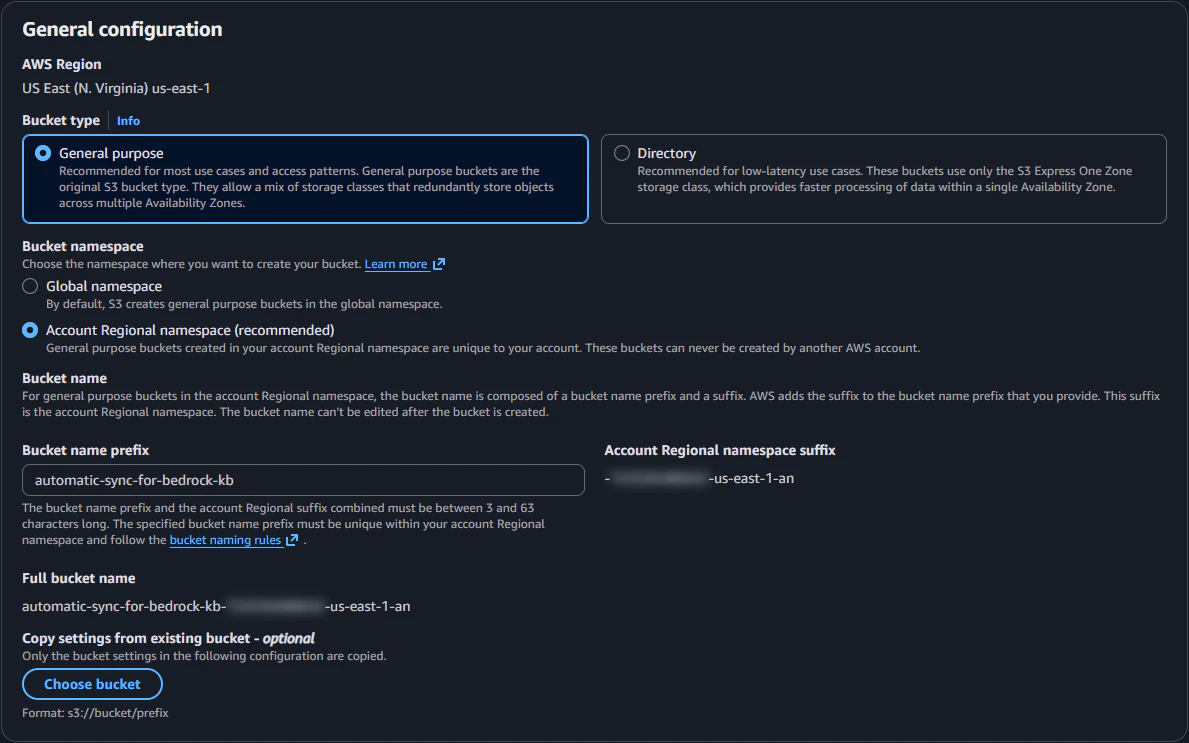
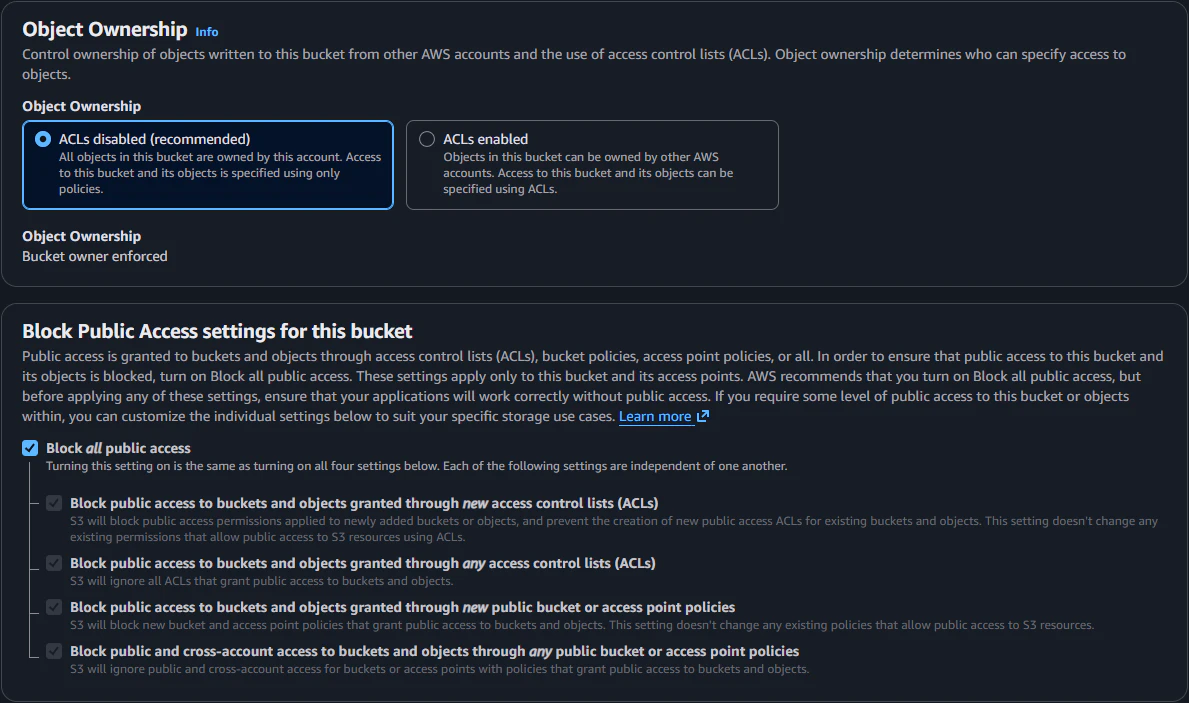
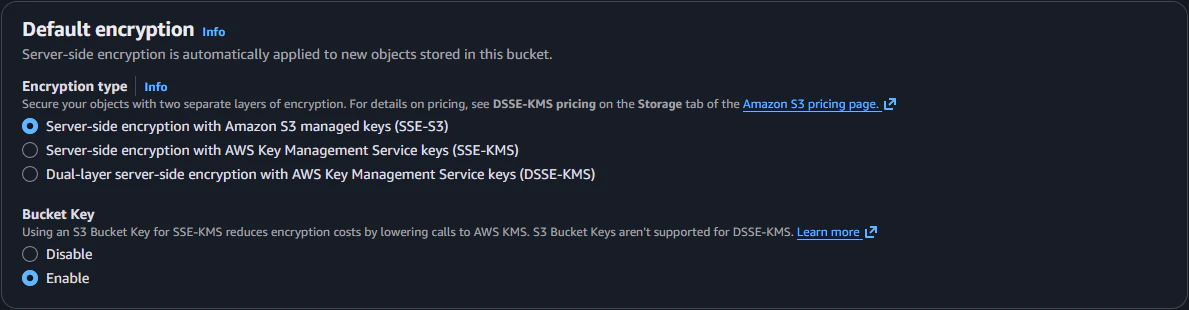
Bedrock Knowledge Base のドキュメント格納用の S3 バケットを作成します。さきほどの README に従い、ブロックパブリックアクセス設定、デフォルトの暗号化、バージョニングを有効にします。
| 項目 | 値 |
|---|---|
| Bucket type | General purpose |
| Bucket namespace | Account Regional namespace |
| Bucket name prefix | automatic-sync-for-bedrock-kb |
| Block public access settings for this bucket | Block all public access |
| Bucket Versioning | Enable |
| Default Encryption | Server-side encryption with Amazon S3-managed keys (SSE-S3) |

S3 バケットを作成し、バケットの Properties タブ内にある Server access logging のブロックで編集画面を開き、Server access logging を Enable にします。また、Destination には、S3 サーバーアクセスログ格納用の S3 バケットを指定します。
同じく Properties タブ内にある Amazon EventBridge のブロックで編集画面を開き、 Send notifications to Amazon EventBridge for all events in this bucket を On にします。

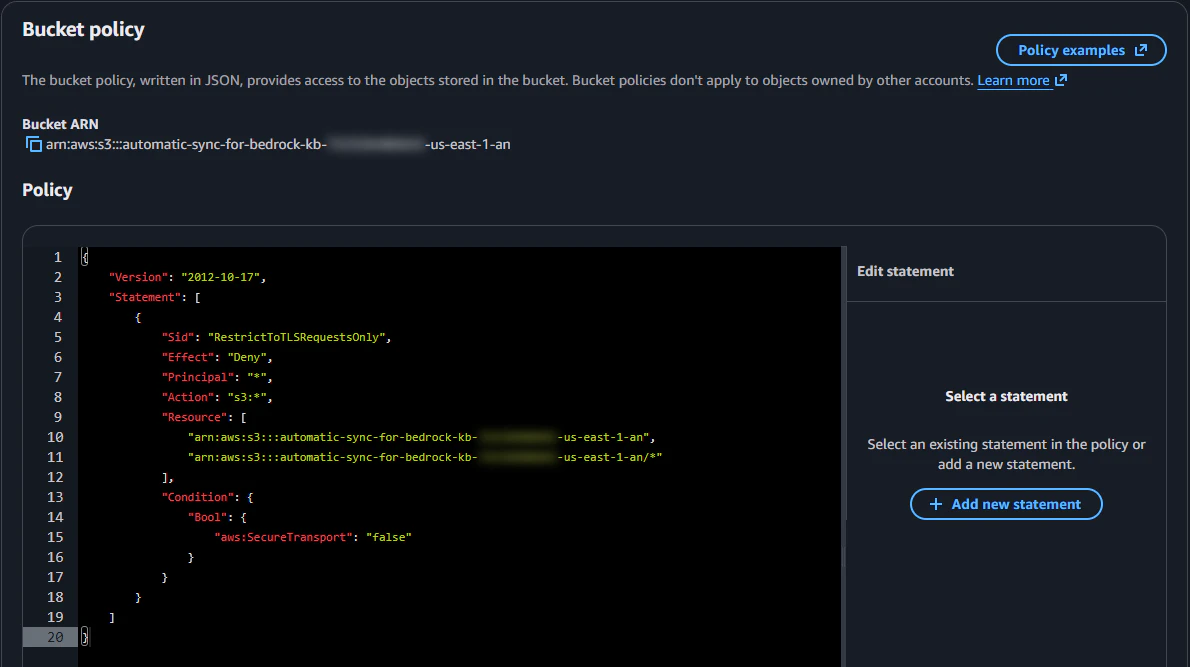
次に、バケットの Permissions タブ内にある Bucket Policy のブロックで編集画面を開き、Bucket Policy を以下のように設定します。Resource には、Bedrock Knowledge Base のドキュメント格納用バケットの ARN を指定します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RestrictToTLSRequestsOnly",
"Effect": "Deny",
"Principal": "*",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::automatic-sync-for-bedrock-kb-<YOUR_ACCOUNT_ID>-us-east-1-an",
"arn:aws:s3:::automatic-sync-for-bedrock-kb-<YOUR_ACCOUNT_ID>-us-east-1-an/*"
],
"Condition": {
"Bool": {
"aws:SecureTransport": "false"
}
}
}
]
}
このバケットには、ドキュメントをアップロードするためのフォルダ documents を作成します。
Bedrock Knowledge Base の作成
ここでは Parsing strategy や Embedding models の選択などを行っていますが、自動同期ソリューションを検証する本質的な部分ではありません。データソース設定のS3バケットを正しく設定できていれば、その他はデフォルト設定でも動作します。コストの観点から、Vector store type は S3 Vectors を選択することをおすすめします。
ナレッジベースの新規作成手順に沿ってナレッジベースを作成します。ベクトルストアを使うため、Knowledge Base with vector store を選択します。

ナレッジベース名を sample-automatic-sync-for-bedrock とします。

データソースタイプは、Amazon S3 を選択します。

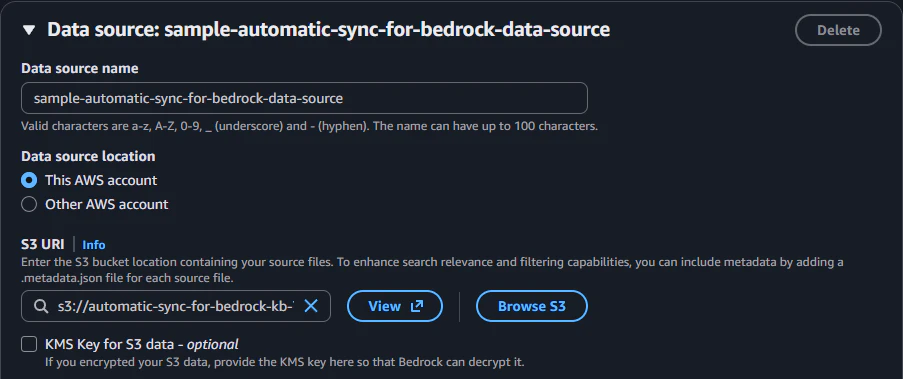
データソース名を sample-automatic-sync-for-bedrock-data-source とします。S3 URI には、先ほど作成した Bedrock Knowledge Base のドキュメント格納用バケットのパスを指定します。
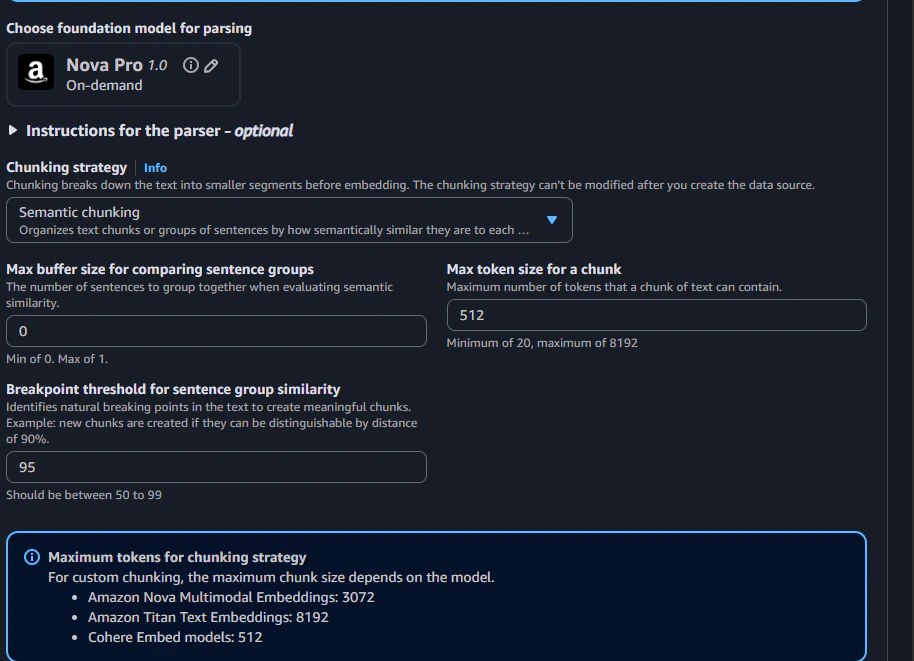
Parsing strategy は、PDF やリッチドキュメントを扱えるよう Foundation models as a parser を選択します。

パーサーモデルは、Nova Pro 1.0 を選択します。モデル選択画面には様々なモデルが表示されますが、選択可能なモデルは On-demand プロファイルのみです。クロスリージョン推論プロファイルやグローバル推論プロファイルでは選択できません。選択しても、ナレッジベース作成時にエラーが発生します。
Chunking strategy は、Semantic chunking を選択します。Max tokens size for a chunk は 512 を指定します。Cohere Embed Multilingual v3 の最大入力トークン数は 512 トークンです。チャンクサイズがこれを超えると埋め込み時にテキストが切り捨てられるため、Max tokens size for a chunk は 512 以下に設定する必要があります。
埋め込みモデルは、Cohere Embed Multilingual v3 を選択します。日本語の埋め込み精度に優れているとうたわれているモデルです。
Vector store は Quick create a new vector store、Vector store type は Amazon S3 Vectors をそれぞれ選択します。
Multimodal storage destination は、マルチモーダル RAG の画像から抽出したテキスト格納用の S3 バケットを指定します。ここは任意のため、設定なしでも構いません。
デプロイ
GitHub リポジトリをクローンします。
git clone https://github.com/revsystem/sample-automatic-sync-for-bedrock-knowledge-bases.git
リポジトリのルートディレクトリに移動します。
cd sample-automatic-sync-for-bedrock-knowledge-bases
samconfig.toml をコピーします。
cp samconfig.example.toml samconfig.toml
vi samconfig.toml
| 項目 | 値 |
|---|---|
| KnowledgeBaseId | 作成した Bedrock Knowledge Base の ID |
| S3BucketName | ドキュメント格納用バケットの名前(例: automatic-sync-for-bedrock-kb--us-east-1-an) |
| S3KeyPrefix | ドキュメント格納用バケット内のフォルダ名(例: documents) |
| NotificationsEmail | 通知を受け取るメールアドレス(任意) |
| LambdaMemorySize | Lambda のメモリサイズ(任意) |
| LambdaTimeout | Lambda のタイムアウト時間(任意) |
# Example samconfig.toml.
version = 0.1
[default.deploy.parameters]
stack_name = "autosync"
resolve_s3 = true
s3_prefix = "autosync"
region = "us-east-1"
confirm_changeset = true
capabilities = "CAPABILITY_IAM"
disable_rollback = true
parameter_overrides = "KnowledgeBaseId=\"<your-knowledge-base-id>\" S3BucketName=\"<your-s3-bucket-name>\" S3KeyPrefix=\"<optional-prefix>\" NotificationsEmail=\"<optional-email>\" LambdaMemorySize=\"256\" LambdaTimeout=\"60\""
image_repositories = []
デプロイします。
sam build
sam deploy --guided --profile {YOUR_PROFILE} --region {YOUR_REGION}
--guided オプションを付けると、以下のようなガイドを表示します。
Setting default arguments for 'sam deploy'
=========================================
Stack Name [autosync]:
AWS Region [us-east-1]:
Parameter KnowledgeBaseId [<YOUR_KNOWLEDGE_BASE_ID>]:
Parameter S3BucketName [<YOUR_S3_BUCKET_NAME>]:
Parameter S3KeyPrefix [<YOUR_S3_KEY_PREFIX>]:
Parameter NotificationsEmail [<YOUR_EMAIL_ADDRESS>]:
Parameter LambdaMemorySize [256]:
Parameter LambdaTimeout [60]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [Y/n]: Y
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]: Y
#Preserves the state of previously provisioned resources when an operation fails
Disable rollback [Y/n]: Y
Save arguments to configuration file [Y/n]: Y
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]:
デプロイに成功すると、以下のようなメッセージがターミナルに表示されます。
Successfully created/updated stack - autosync in us-east-1
AWS SAM CLI を使用したデプロイやトラブルシューティングについては、README-SAM.md を参照してください。
SNS のサブスクリプション
デプロイの途中で、SNS のサブスクリプションが作成されます。このサブスクリプションは、ドキュメントのアップロードや削除時に通知を受け取るためのものです。
サブスクリプションが作成されると、NotificationEmail に指定したメールアドレスに以下のようなメッセージが送信されます。
Subject: AWS Notification - Subscription Confirmation
You have chosen to subscribe to the topic:
arn:aws:sns:us-east-1:<YOUR_ACCOUNT_ID>:autosync-notifications
To confirm this subscription, click or visit the link below (If this was in error no action is necessary):
Confirm subscription
Please do not reply directly to this email. If you wish to remove yourself from receiving all future SNS subscription confirmation requests please send an email to sns-opt-out
Confirm subscription をクリックすると、SNS のサブスクリプションが有効になります。勢い余って unsubscribe のリンクをクリックしないように注意します。
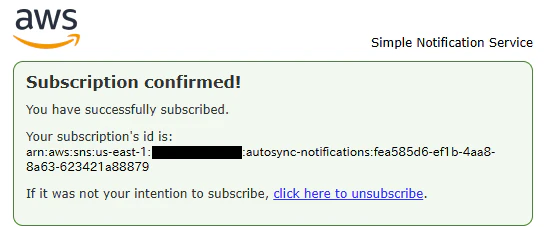
SNSのサブスクリプション確認メールに unsubscribe のリンクが含まれている場合があります。このリンクは、クリックすると即座にサブスクリプションが解除されます。企業のメールセキュリティやスパムフィルターなど自動システムによって、意図せず購読解除操作が行われる場合があります。これらの自動システムは受信メール内のリンクを開いて検査する際に、意図せず購読解除リンクを踏んでしまうことがあります。
これを防ぐためには、以下の記事に紹介されているようにマネジメントコンソールもしくはAWS CLI で SNS のサブスクリプションの確認操作を行う必要があります。
動作確認
ドキュメントのアップロード
ドキュメントをアップロードします。aws s3 cp コマンドを使用するか、S3 のマネジメントコンソールからドキュメントをアップロードします。
aws s3 cp {YOUR_DOCUMENT_PATH} s3://{YOUR_S3_BUCKET_NAME}/{YOUR_S3_KEY_PREFIX}/
ドキュメントの同期確認
ドキュメントの同期確認は、Bedrock Knowledge Base のダッシュボードから行います。データソースの Sync history に同期の履歴が表示されます。

SNS のサブスクリプションが有効となっている場合、取り込みジョブの完了時に以下のようなメッセージが送信されます。
Subject: Bedrock KB Sync Job COMPLETE
{
"knowledge_base_id": "<YOUR_KNOWLEDGE_BASE_ID>",
"job_id": "<YOUR_JOB_ID>",
"status": "COMPLETE",
"statistics": {
"numberOfDocumentsDeleted": 0,
"numberOfDocumentsFailed": 0,
"numberOfDocumentsScanned": 1,
"numberOfMetadataDocumentsModified": 0,
"numberOfMetadataDocumentsScanned": 0,
"numberOfModifiedDocumentsIndexed": 0,
"numberOfNewDocumentsIndexed": 1
},
"processed_changes": 1
}
DynamoDB のデータ確認
DynamoDB のテーブル名は、autosync-tracking と autosync-metadata です。
aws dynamodb scan --table-name autosync-tracking --profile {YOUR_PROFILE} --region {YOUR_REGION}
aws dynamodb scan --table-name autosync-metadata --profile {YOUR_PROFILE} --region {YOUR_REGION}
autosync-tracking テーブルの例です。change_typeにデータの削除や新規追加が記録されています。
{
"Items": [
{
"knowledge_base_id": {
"S": "<YOUR_KNOWLEDGE_BASE_ID>"
},
"event_time": {
"S": "2026-05-10T17:14:43Z"
},
"ingestion_job_id": {
"S": "KGF5YGBN2P"
},
"processed": {
"BOOL": true
},
"timestamp": {
"N": "1778433285.169089"
},
"bucket": {
"S": "<YOUR_S3_BUCKET_NAME>"
},
"change_type": {
"S": "delete"
},
"key": {
"S": "documents/n1120000.pdf"
},
"change_id": {
"S": "4bc82a1e-56da-4f13-8d0e-a2db399aca8b"
}
},
{
"knowledge_base_id": {
"S": "<YOUR_KNOWLEDGE_BASE_ID>"
},
"event_time": {
"S": "2026-05-10T17:15:32Z"
},
"ingestion_job_id": {
"S": "YGYDOSMKQR"
},
"processed": {
"BOOL": true
},
"timestamp": {
"N": "1778433333.72125"
},
"bucket": {
"S": "<YOUR_S3_BUCKET_NAME>"
},
"change_type": {
"S": "create"
},
"key": {
"S": "documents/n1120000.pdf"
},
"change_id": {
"S": "07b7b739-d44f-4a35-aa5c-8bc1fa104b01"
}
},
...(中略)
],
"Count": 10,
"ScannedCount": 10,
"ConsumedCapacity": null
}
ログの確認
CloudWatch Logs でログを確認します。/aws/lambda/autosync-* のロググループにログが出力されます。
その他、EventBridge や Step Functions、Lambda の各マネジメントコンソールでもリソース毎のステータスやメトリクスを確認できます。
まとめ
AWS Blog で紹介されているサンプル実装を検証し、動作確認を行いました。
このサンプル実装では、S3 にファイルがアップロード・更新・削除されると、自動的に Knowledge Base の同期 API (StartIngestionJob) が呼び出され、サービスクォータを尊重しながら確実に取り込みが行われます。
EventBridge によるS3 イベントの検知、SQS によるメッセージのバッファリングと配信、Step Functions によるオーケストレーションが非常に効率的な設計となっています。DynamoDB による変更のトラッキングが行われるため、状態の管理も容易です。
実装が仕様と異なっていたためいくつかの修正が必要でしたが、サンプル実装を通して自動同期の流れを理解することができました。