はじめに
Amazon Bedrock Evaluations は、Amazon Bedrock を使用した RAG システムの精度を評価するためのツールです。RAG の精度を測るには、定量的な評価手法が必要です。
本記事では、Bedrock Evaluations を使って RAG システムの評価を行った際に気づいた点やデータセットの作成方法を紹介します。設定手順の詳細は参考情報に挙げた記事を参照してください。
参考情報
"回答と生成" を使った評価
RAG 評価ジョブの作成
マネジメントコンソールの Amazon Bedrock から、"Access" → "Evaluations" を選択し、"RAG" タブを選択し、"Create" ボタンをクリックします。
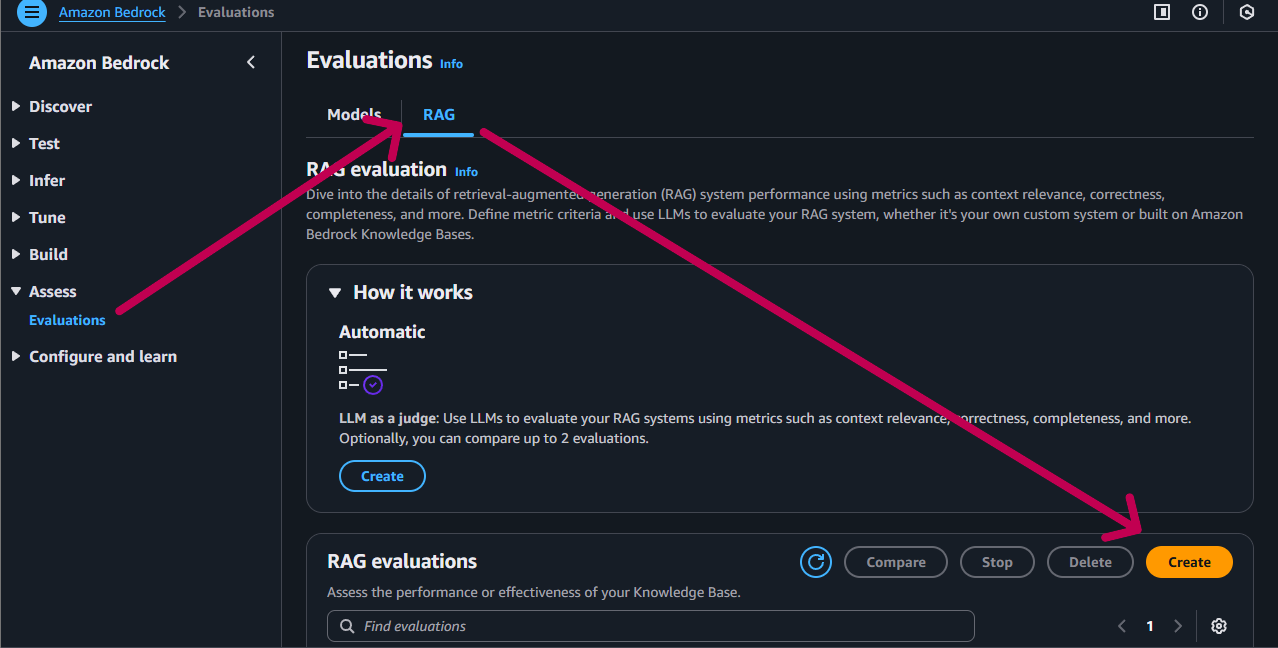
詳細情報入力
RAG の評価ジョブ作成画面では評価モデルを選択します。今回は "回答と生成" の評価を行うので、後述の設定で生成モデルの選択も行います。ここでは、以下のように選択あるいは入力します。
- 評価名: 任意の評価名
- 説明: 任意の説明
- 評価モデル: 選択可能なモデルから選択
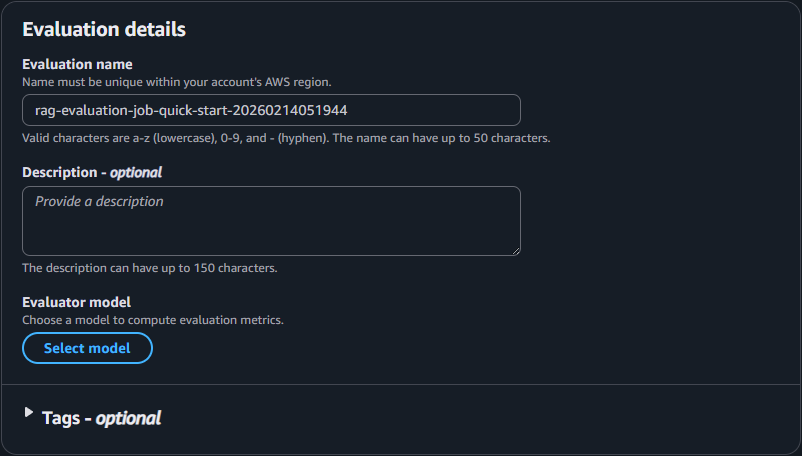
評価モデルの選択肢はあまり多くありません。Amazon のモデルは Nova Pro のみ選択可能です。Anthropic のモデルは Claude 3 / 3.5 / 3.7 シリーズが選択可能です。


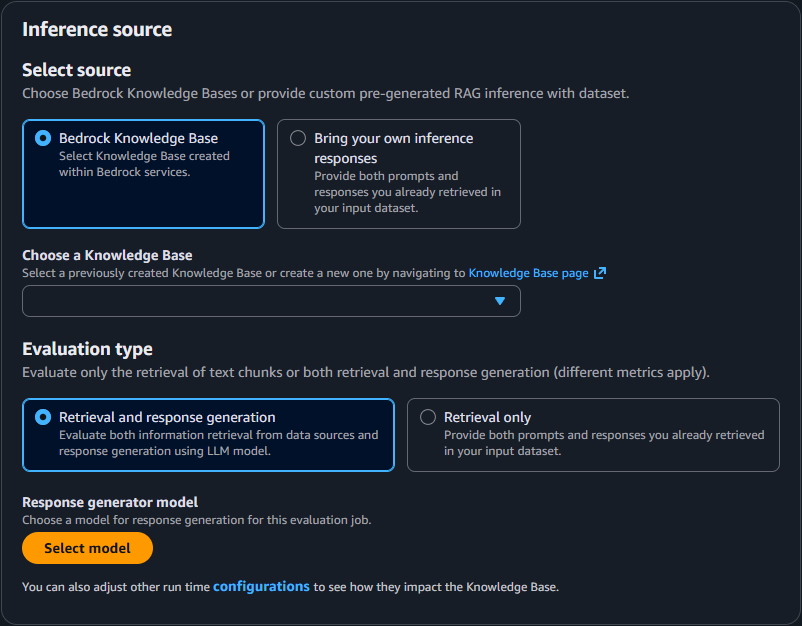
推論ソース
推論ソースのブロックでは、評価対象のソースや評価タイプを選択します。今回は Bedrock Knowledge Bases で構築した RAG を評価するので、以下のように選択します。
- ソース: Bedrock Knowledge Bases
- 評価タイプ: 回答と生成(Retrieval and response generation)
- 生成モデル: 選択可能なモデルから選択します。
生成モデルは、様々なプロバイダーのモデルが選択可能です。Anthropic のモデルには Claude 4 シリーズが列挙されています。しかし、選択には注意が必要です。後述の推論パラメータの設定との組み合わせにより、実質的に選択できないモデルもあります。

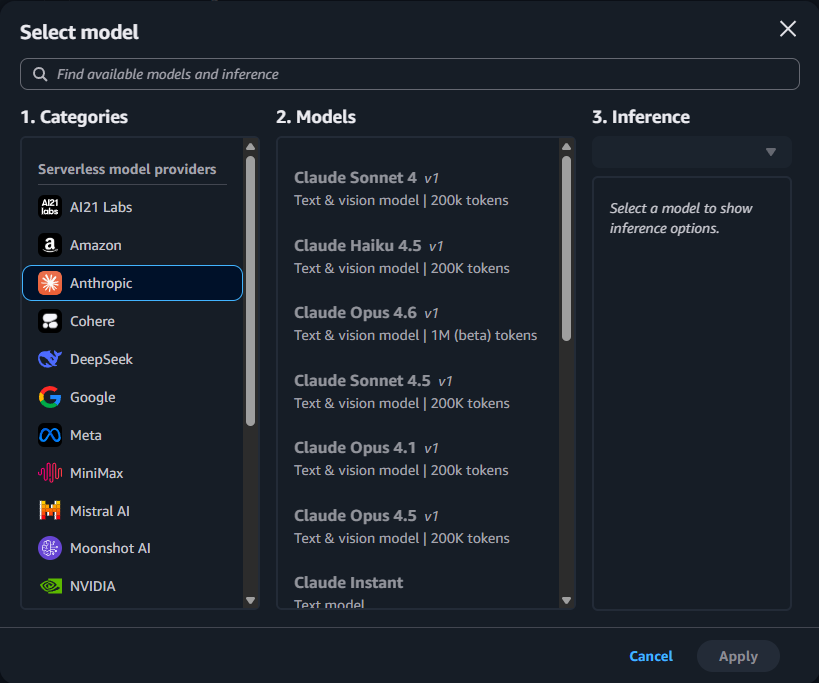
推論ソースブロックの最下部に Configurations リンクがあります。これをクリックすると、推論ソースの設定画面が表示されます。
推論パラメータの設定

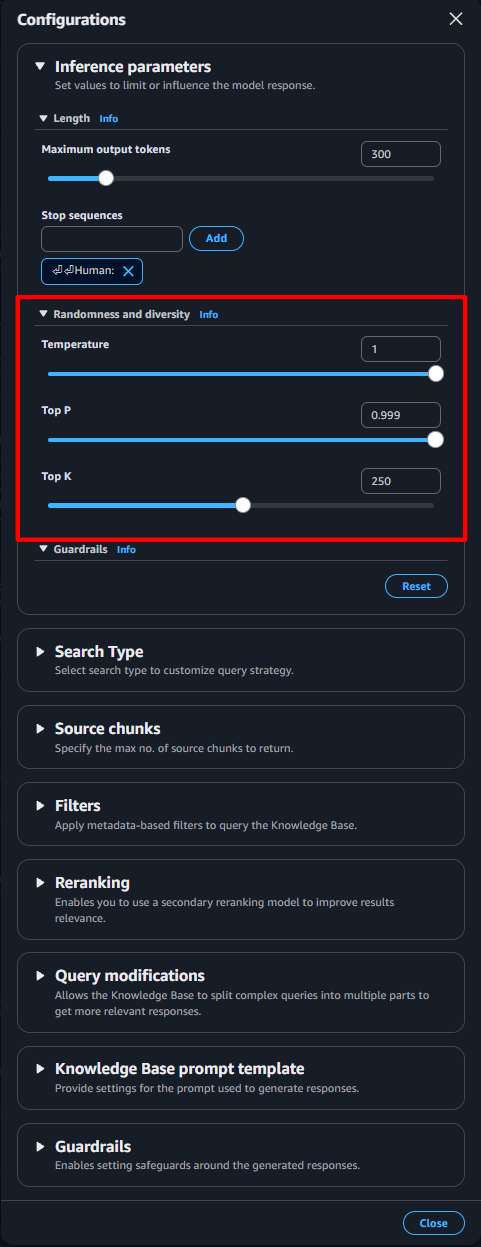
推論タイプに "回答と生成" を選択した場合は、この画面に推論パラメータの設定ブロックが表示されます。ここでは Temperature と Top P、Top K の設定を行います。実装するアプリケーションと同じ設定を行うことで、検索と生成を定量的に評価することが可能です。
この推論パラメータの設定が生成モデルの選択に影響を与えることがあります。AWS 公式ドキュメントによると、Claude Sonnet 4.5 と Claude Haiku 4.5 ではTemperature と Top P を同時に設定することができません。この画面では両方を同時に設定する構成になっているため、片方のみ設定することができません。このまま評価ジョブ作成を進めると、エラーが発生します。
AWS CLIで評価ジョブを作成すると、この制約を回避できるようです。
https://dev.classmethod.jp/articles/bedrock-rag-evaluation-claude-4-5-response-generator/
データセットと結果を配置する S3 バケット
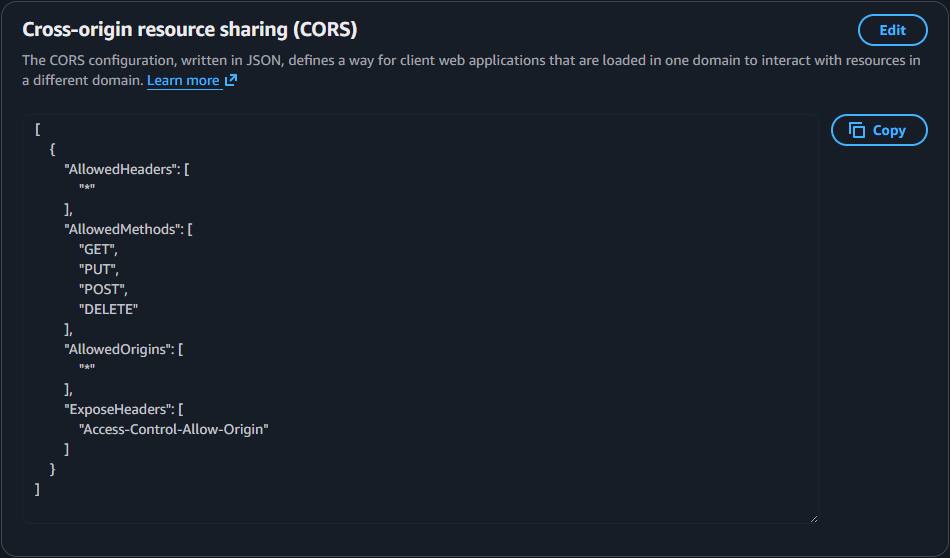
Evaluations で RAG の評価を行うには、質問と正解のペアを持つデータセットや、データセットと評価結果を格納する S3 バケットが必要です。S3 バケットには、Evaluations がデータの読み書きを行えるよう CORS 設定を行います。
CORS 設定は、S3 バケットの Permission タブで行います。
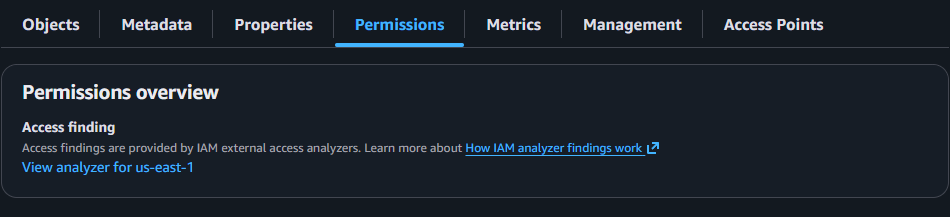
Permission タブの最下部にある Cross-origin resource sharing (CORS) で Edit ボタンをクリックし、設定を編集します。
S3 バケットは、以下のようなフォルダ構成で良いでしょう。
s3://your-bucket/
|-- bedrock_rag_eval.jsonl # データセットファイル
|-- results/ # 評価ジョブの結果を格納するフォルダ
データセットの作成
評価用のデータセットを用意します。データセットの形式は、以下のとおりです。1 行に 1 件のデータセットを格納し、ひとつの評価に最大 1,000 件まで登録できます。
prompt — 以下のタスクの入力を示すのに必要です。
- 一般的なテキスト生成でモデルが応答すべきプロンプト。
- 質問回答タスクタイプでモデルが回答すべき質問。
- テキスト要約タスクでモデルが要約すべきテキスト。
- 分類タスクでモデルが分類すべきテキスト。
referenceResponse — 以下のタスクタイプで、モデルを評価する基準となるグラウンドトゥルースレスポンスを示すのに必要です。
- 質問回答タスクのすべてのプロンプトに対する回答。
- すべての正解率と堅牢性の評価に対する答え。
このような JSON Lines 形式で作成し、.jsonl ファイル拡張子で保存します。このファイルを S3 バケットにアップロードします。
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
今回は LLM に以下のような指示を渡してデータセットを作成しました。対象となるドキュメントは、令和 7 年版情報通信白書 第 1 章 第 2 節 "AI の爆発的な進展の動向" です。
Amazon Bedrock Evaluations でRAGを評価するためのデータセットを作成する。元となるデータを参照し、フォーマットに従ったデータセットを10件作成する。作成したデータセットは、./data 以下に格納する。
元となるデータ:
data/n1120000.pdf
データセットのフォーマット:
JSONL形式で1行JSON
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
prompt : RAGシステムへの質問
referenceResponses: RAG の検索結果に含まれるべき正解(グラウンドトゥルース)です。カバレッジに利用するため、参照してほしいチャンク(ドキュメントの該当部分)をそのまま記載するのではなく、検索結果に含まれるべき「正解」を網羅的に記載します。
Cursor エディタのチャットを使ってデータセットを作成しました。いくつかのやりとりを経て最終的なデータセットが出力されたので、単純に上記の指示を実行した場合は異なる結果になる可能性があります。
{"conversationTurns":[{"prompt":{"content":[{"text":"情報通信白書に基づいて、OpenAIが2020年に発表した大規模言語モデルGPT-3のパラメータ数はおよそ何億ですか?"}]},"referenceResponses":[{"content":[{"text":"OpenAIが2020年に発表した大規模言語モデルGPT-3は、約1,750億パラメータで構成されており、およそ1,750億パラメータとされています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"OpenAIの推論モデルo1は、アメリカ数学オリンピック予選のテスト問題のうち、およそ何パーセントを解くことができたと報告されていますか?"}]},"referenceResponses":[{"content":[{"text":"OpenAIの推論モデルo1は、アメリカ数学オリンピック予選のテスト問題の約83%を解くことができたと報告されており、正答率はおよそ83%です。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"中国のAIスタートアップDeepSeekが開発した推論モデルDeepSeek-R1の開発には、およそ何億円のコストがかかったと情報通信白書では説明されていますか?"}]},"referenceResponses":[{"content":[{"text":"情報通信白書では、DeepSeek社の推論モデルDeepSeek-R1の開発には約560万ドル、円換算で約8億6,000万円(約8.6億円)のコストがかかったと説明されています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"スタンフォード大学HAIのAI活力ランキング2023年版において、日本の総合順位は世界の中で何位に位置付けられていますか?"}]},"referenceResponses":[{"content":[{"text":"スタンフォード大学HAIが公表した2023年のAI活力ランキングでは、日本は総合9位に位置付けられており、米国や中国、英国などに次ぐ9番目の順位とされています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"総務省の2024年度調査によると、日本において何らかの生成AIサービスを「使っている(過去使ったことがある)」と回答した人の割合は全体で何パーセントでしたか?"}]},"referenceResponses":[{"content":[{"text":"総務省の2024年度調査では、日本において何らかの生成AIサービスを使っている(過去使ったことがある)と回答した人の割合は全体で26.7%と報告されています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"人型ロボットの開発事例として紹介されている、Teslaが開発している二足歩行の人型ロボットの名称は何ですか?"}]},"referenceResponses":[{"content":[{"text":"情報通信白書では、Tesla(米国)が開発している人型ロボットとしてOptimus(オプティマス)が紹介されており、産業用途に加えて家事や娯楽など身近な用途でも利用可能なヒューマノイドロボットとして位置付けられています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"富士通とカナダのCohere社が共同で開発した、日本語性能に優れた企業向け大規模言語モデルの名称は何と記載されていますか?"}]},"referenceResponses":[{"content":[{"text":"富士通とCohere社が共同で開発した企業向け大規模言語モデルはTakane(タカネ)と名付けられており、日本語の言語性能が非常に高く、セキュアなプライベート環境で利用可能なモデルとして紹介されています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"AIとロボットの融合によるロボットデータエコシステム構築を目指し、2024年12月に設立された一般社団法人AIロボット協会の略称は何ですか?"}]},"referenceResponses":[{"content":[{"text":"2024年12月に設立された一般社団法人AIロボット協会は、AIとロボットの融合によるロボットデータエコシステム構築を目指す団体であり、その略称はAIRoA(エアロア)と記載されています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Microsoftが2024年12月に公開した小規模言語モデルPhi-4は、およそ何億パラメータのモデルとして紹介されていますか?"}]},"referenceResponses":[{"content":[{"text":"情報通信白書では、Microsoftが公開した小規模言語モデルPhi-4は約140億パラメータのモデルとして紹介されており、同規模の他社モデルよりも高い性能を示したとされています。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"日本企業を対象とした調査によると、生成AI導入に際して最も多く挙げられている懸念事項は何だと示されていますか?"}]},"referenceResponses":[{"content":[{"text":"日本企業を対象とした調査では、生成AI導入に際しての懸念事項のうち最も多く挙げられているのは、効果的な活用方法がわからないという点であり、社内でどのように生成AIを業務に組み込めばよいか分からないことが最大の懸念として示されています。"}]}]}]}
データセットを S3 バケットにアップロードし、Dataset for evaluation の S3 URI にそのパスを指定します。あわせて、Results for evaluation に評価ジョブの結果を配置する S3 バケットのパスを指定します。

最後に Create ボタンをクリックして評価ジョブを作成します。
評価結果
評価ジョブの作成が完了すると、結果が S3 バケットに格納されます。評価名をクリックするとこのようなサマリーが表示されます。

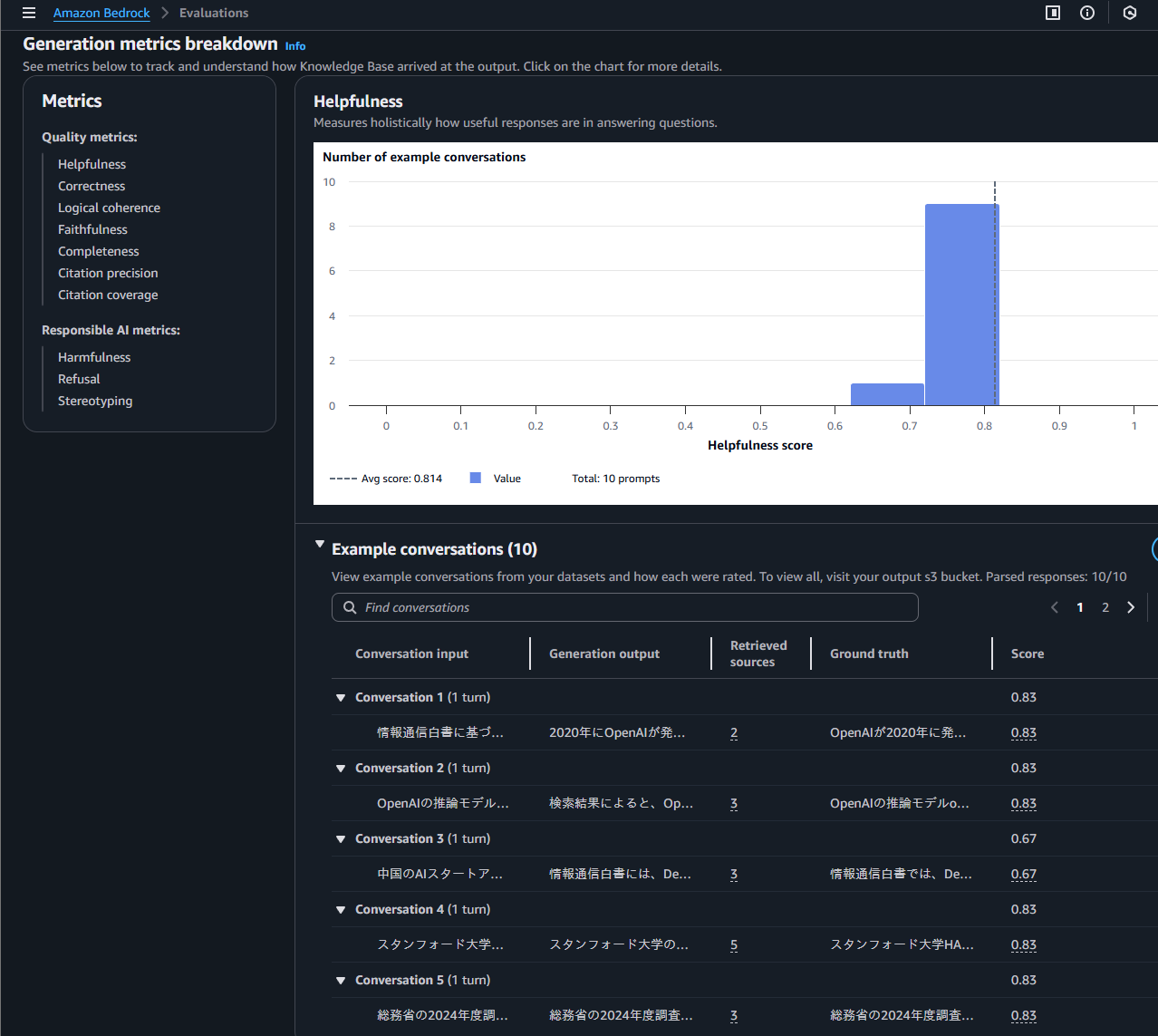
各スコアには、なぜそのような評価となったのかを説明するツールチップが表示されます。これを参考に、クエリやドキュメントの再検討を行うことができます。

このように 2 つの評価サマリーを並べて比較表示できます。検索や推論パラメータを変更した評価結果の比較に活用できます。

既存の評価ジョブの設定を変更して再実行することはできないので、別の設定を用いて再評価を行う場合は新たに評価ジョブを作成します。
生成モデルに Claude Sonnet 4.5 と Claude Haiku 4.5 を選択した場合
生成モデルに Claude Sonnet 4.5 と Claude Haiku 4.5 を選択した場合、評価ジョブの作成でエラーが生じます。これは、前述のとおり Temperature と Top P を同時に設定できない制約があるためです。評価ジョブの作成には数十分かかることがあり、終盤にエラーが生じます。この制約に気づかないと作業時間を無駄にしてしまいます。また、これらのモデルを使用して RAG を構築している場合、Evaluations では評価を行うことができない点に注意が必要です。

Claude Sonnet 4.5 や Claude Haiku 4.5を生成モデルとして使用したい場合は、AWS CLIで評価ジョブを作成する方法があるようです。
まとめ
Bedrock Evaluations を使用して RAG の評価を行う際の注意点やデータセットの作成方法を紹介しました。スコアの抽出や列挙は Retrieve API で行えますが、なぜそのスコアになったのかという具体的な分析や比較を行うことはできません。Bedrock Evaluations を使用することで、定量的な評価分析が容易になります。一方、モデル側の制約により評価ジョブの作成でエラーが生じることがあります。
- 生成モデルに Claude Sonnet 4.5 と Claude Haiku 4.5 を選択した場合、評価ジョブの作成でエラーが生じる。
- データセットの作成は、Cursor エディタのチャットなど生成 AI を活用すると効率的に行える。
- 評価結果には、なぜそのような評価となったのかを説明するツールチップが表示される。
- 2 つの評価を比較して表示できる。