はじめに
ようやくローカル環境でのリアルタイム文字起こしがいい感じに動作するようになりましたのでまとめました。
情報漏洩のリスクを排除するために、サーバーへの音声送信を必要としない文字起こしを行います。
また、リアルタイムでの文字起こしが可能ですので、生配信の字幕作成や同時翻訳などの機能も実現できる可能性を秘めています。
注意事項
権利で守られている動画・音声を文字起こしを行い公開することは、権利の侵害に繋がる可能性がありますので十分にご注意ください。
2023年06月21日
2023年06月26日 更新
2023年06月29日 更新
処理概要
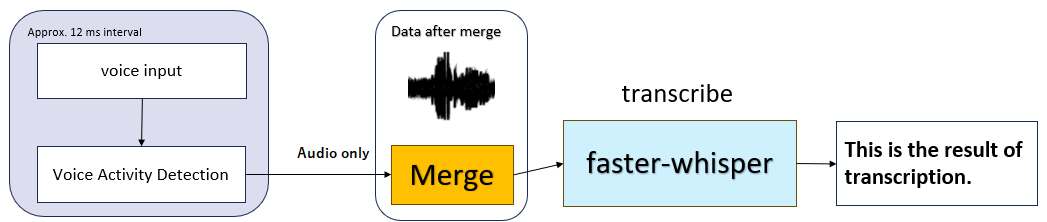
- マイクから繰り返しオーディオストリームを取得
- 音声区間検出(VAD)を行い音声と判断できたものを音声バッファに格納
- 設定した閾値を超える無音区間までを一つの音声バッファとする
- 音声バッファを文字起こしする
faster-whisperとは
faster-whisper は、トランスフォーマーモデルの高速推論エンジンである CTranslate2 を使用した OpenAI の Whisper モデルの再実装です。
この実装は、openai / whisper よりも最大 4 倍高速で、同じ精度で、より少ないメモリを使用します。CPU と GPU の両方で 8 ビット量子化することで、効率をさらに向上させることができます。
実行環境
- Windows11
- Core i7 12700KF
- GeForce RTX 3060 12GB
- VB-CABLE Virtual Audio Device
- Python 3.11.4
- CUDA 11.7
- cuDNN 8.5
文字起こし速度
GPU利用ではあるが、話す時間に対して1/3ぐらいの時間で文字起こしができている。
長文にならなければ1文約1秒前後ですので、処理が間に合わなくなるようなこともないと思われます。

効果音ラボ様の音声を利用しています。
誤変換
完璧ということは難しいですが、サンプルアプリから誤変換が大幅に減少しました。
Youtubeの動画等のBGMが流れるような場面であっても音声のみを文字起こしできるようになった。
改善要因
- 音声バッファサイズが一定以下の場合をノイズとして文字起こしに利用しないようにした。
- 音声のDatatypeをint16からfloat32に変更したことにより繊細な表現が可能となり、音声認識しやすくなった。
リアルタイム文字起こしおすすめ設定
- languageを固定する
- beam_sizeを小さくする
- best_ofを小さくする
- temperatureは0にする
参考: faster-whisperのパラメータを調べてみました
パラメータの設定次第ではもっと誤変換を減らして速く変換できる可能性はありそうです。
追記関連
音声とテキスト連動(2023/06/26 追記)
文字起こし終了後に入力した音声と文字起こしテキストを連動させる機能を追加しました。
入力音声と突き合わせができるようになり、文字起こし結果が確認しやすくなりました。
また、一括で文字起こしすることにより文脈が繋がるようになったと思います。
音声ファイル対応(2023/06/29 追記)
先の音声とテキスト連動を利用する形でブラウザ側から音声ファイルを送信できるようにしました。
faster-whisper/Whisperで本来利用できる機能が使えない状態なのは良くないと思っていました。
後付け機能はどうしてもUI調整が難しかったりや処理が複雑化してしまう。
Demo

ソースコード
下記にソースコードを置いています。(MIT)
https://github.com/reriiasu/speech-to-text