AIエージェントの「記憶」ってどう作る?Memory / State / Artifact の設計と実装から見えてきたこと 🧠
最近、AIエージェントを実装するためのSDKが次々と登場しています。
Googleからも4月9日に「ADK(Agent Development Kit)」が登場し、5月20日にはバージョン1.0.0として正式リリースされ、6月12日時点ではバージョン1.2.1まで進化しています。
私自身もAIエージェントの開発を進める中で、ネット上の情報を参考にしていますが、多くの記事は「とりあえず触ってみた」といった内容が中心で、実際にエージェントを細かく構築する方法や設計上の考慮点を深掘りした記事は、まだほとんど見当たりません。
特に「エージェントの記憶をどう実装すべきか」という課題には悩まされました。
本記事では、そうした課題に直面しながらも試行錯誤を重ねて得た理解や設計・実装のプロセスを、備忘録としてまとめています。
はじめに
本記事は、2025年6月11日時点でのGoogle ADK Python ver1.2.1の内容を参考に実装しています。
ADK Python ver1.2.1
今後のアップデートにより、実装内容や定義が変更される可能性があります。その場合、本記事とは異なる挙動や実装になる可能性がありますのでご注意ください。
それでは、エージェントの記憶について見ていきましょう!
🗂 1. エージェントの記憶システムをどう分類するか
AIエージェントにおける「記憶」は、以下の3つに分類して考えると整理しやすくなります。
 長期記憶(Memory)
長期記憶(Memory)
- 永続的にデータを保存するタイプ
- エージェントが「何を知っているか」「どう成長していくか」みたいな知識や履歴を保持
- セッションをまたいで継続的に利用可能
 短期記憶(State)
短期記憶(State)
- エージェント内で保持される一時的な状態やコンテキスト
- 会話や操作の流れをその場で維持するための仕組み
- プログラムにおける「変数」に近い扱い
 一時記憶(Artifact)
一時記憶(Artifact)
- 外部とのやりとりで得たデータを一時的に保存する記憶領域
- MCP(Model Context Protocol)などから取得した情報を保持し、後続処理で活用
- ファイル形式のデータや構造化された結果を、外部ストレージのように取り扱える
長期記憶(Memory)の実装
Google ADKでは MemoryService を使って、エージェントが「知っていること」を永続化できます。セッションをまたいで使えるため、「このユーザーは〇〇が好き」といった情報を記憶するのに適しています。
class LocalBaseMemoryService(InMemoryMemoryService):
"""
BaseMemoryServiceのローカルストレージ実装。
SessionやEventをpickleでシリアライズして保存する。
"""
@override
async def add_session_to_memory(self, session: Session):
user_key = _user_key(session.app_name, session.user_id)
self._session_events[user_key] = self._session_events.get(
_user_key(session.app_name, session.user_id), {}
)
self._session_events[user_key][session.id] = [
event
for event in session.events
if event.content and event.content.parts
]
@override
async def search_memory(
self, *, app_name: str, user_id: str, query: str
) -> SearchMemoryResponse:
user_key = _user_key(app_name, user_id)
if user_key not in self._session_events:
return SearchMemoryResponse()
words_in_query = set(query.lower().split())
response = SearchMemoryResponse()
for session_events in self._session_events[user_key].values():
for event in session_events:
if not event.content or not event.content.parts:
continue
words_in_event = _extract_words_lower(
' '.join([part.text for part in event.content.parts if part.text])
)
if not words_in_event:
continue
if any(query_word in words_in_event for query_word in words_in_query):
response.memories.append(
MemoryEntry(
content=event.content,
author=event.author,
timestamp=_utils.format_timestamp(event.timestamp),
)
)
return response
このMemoryにsessionのEvnetを保存する場合は、明示的に指定する必要があります。
以下のようにRunner内でadd_memoryを呼ば出したタイミングでMemoryに保存されます。
if runner.memory_service:
session = await session_service.get_session(
app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID
)
await runner.memory_service.add_session_to_memory(session)
 長期記憶(Memory)の実装における検討事項
長期記憶(Memory)の実装における検討事項
例として、InMemoryMemoryServiceのadd_session_to_memoryメソッドの実装を詳しく見てみると、以下のような問題点が見えてきます。
async def add_session_to_memory(self, session: Session):
user_key = _user_key(session.app_name, session.user_id)
self._session_events[user_key] = self._session_events.get(
_user_key(session.app_name, session.user_id), {}
)
self._session_events[user_key][session.id] = [
event
for event in session.events
if event.content and event.content.parts
]
問題点:保存すべきデータを個別で実装する必要性がある
sessionのEventには以下のような保存対象のデータが含まれています。
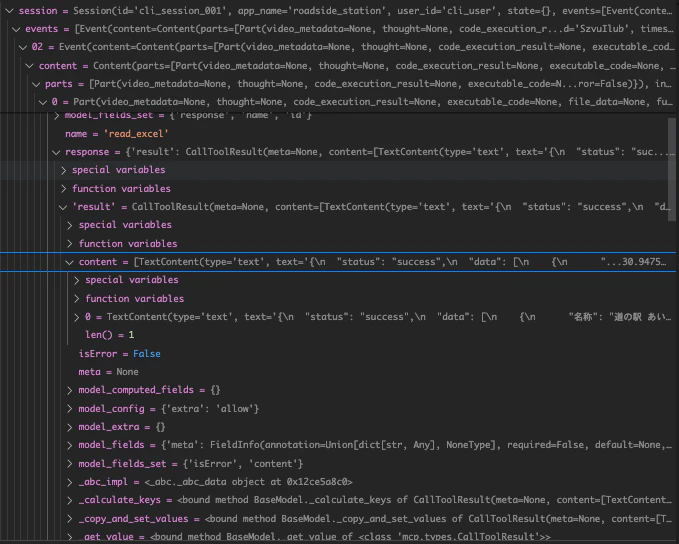
これだと記憶すべき内容に不必要なデータも含まれており、記憶を再現する際に必要な情報が何なのか不明瞭になってしまう問題があります。なので以下のような検討が必要です。
本格的な実装時に検討すべきポイント
- Memoryの保存構造:どのような形式でデータを保存するべきか
- 情報の取捨選択:EventからMemoryに保存すべき情報をどう選択するか
上記を検討する際は、InMemoryMemoryServiceのsearch_memoryメソッドの実装も参考にして検討する必要があります。
async def search_memory(
self, *, app_name: str, user_id: str, query: str
) -> SearchMemoryResponse:
user_key = _user_key(app_name, user_id)
if user_key not in self._session_events:
return SearchMemoryResponse()
words_in_query = set(query.lower().split())
response = SearchMemoryResponse()
for session_events in self._session_events[user_key].values():
for event in session_events:
if not event.content or not event.content.parts:
continue
words_in_event = _extract_words_lower(
' '.join([part.text for part in event.content.parts if part.text])
)
短期記憶(State)の実装
State はエージェントの「今この瞬間の状態」を保持する仕組みです。ADKではセッション内でsession.state として利用できます。
from google.adk.sessions import InMemorySessionService
session_service = InMemorySessionService()
session = session_service.create_session(app_name="my_app", user_id="u1", session_id="s1")
# 状態の保存
session.state["user:lang"] = "ja"
session.state["booking_step"] = "confirm_date"
# 状態の取得
lang = session.state.get("user:lang")
ADKの状態管理:4つの名前空間
ADKでは状態データを4つの名前空間に分類して管理します
1.アプリ状態 (app:プレフィックス): 全ユーザー間で共有される状態
2.ユーザー状態 (user:プレフィックス): 特定ユーザーの全セッション間で共有される状態
3.セッション状態 (プレフィックスなし): 特定セッション内でのみ有効な状態
4.一時状態 (temp:プレフィックス): 永続化されない一時的な状態
この状態管理システムは、会話の文脈を維持し、エージェントが過去のやり取りを記憶できるようにする重要な仕組みです。
一時記憶(Artifact)の実装
Artifactは、ファイルやバイナリ、構造化データなどを一時的に保存して再利用できる仕組みです。大容量の画像データやPDF、レスポンスの一部などを保持したいときに便利です。
class LocalStorageArtifactService(BaseArtifactService):
"""
BaseArtifactServiceのローカルストレージ実装。
Args:
storage_path (str): アーティファクト保存先のルートディレクトリ
"""
def __init__(self, storage_path: str):
"""
LocalStorageArtifactServiceのコンストラクタ。
Args:
storage_path (str): アーティファクト保存先のルートディレクトリ
"""
self.storage_path = storage_path
async def save_artifact(
self,
*,
app_name: str,
user_id: str,
session_id: str,
filename: str,
artifact: types.Part
) -> int:
"""
アーティファクトをローカルストレージに保存する。
Args:
app_name (str): アプリ名
user_id (str): ユーザーID
session_id (str): セッションID
filename (str): ファイル名
artifact (types.Part): 保存するデータ
Returns:
int: リビジョンID(現状は常に0)
Note:
ディレクトリが存在しない場合は自動作成される。
"""
file_path = os.path.join(
self._get_artifact_dir(app_name, user_id, session_id), filename
)
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, 'wb') as f:
f.write(artifact)
return 0 # Revision ID can be managed differently if needed
async def load_artifact(
self,
*,
app_name: str,
user_id: str,
session_id: str,
filename: str,
version: int = None
) -> types.Part:
"""
ローカルストレージからアーティファクトを読み込む。
Args:
app_name (str): アプリ名
user_id (str): ユーザーID
session_id (str): セッションID
filename (str): ファイル名
version (int, optional): バージョン番号(未使用)
Returns:
types.Part: 読み込んだデータ(application/jsonとして返却)
Raises:
FileNotFoundError: ファイルが存在しない場合
"""
file_path = os.path.join(
self._get_artifact_dir(app_name, user_id, session_id), filename
)
with open(file_path, 'rb') as f:
data = f.read()
return types.Part.from_bytes(data=data, mime_type="application/json") # Adjust mime_type as needed
Artifactを活用することで、StateやMemoryに詰め込まずに一時保存・活用できます。ツール間でデータを受け渡す用途にも適しています。

 一時記憶(Artifact)実装における検討事項
一時記憶(Artifact)実装における検討事項
load_artifactメソッドでは、バイト配列として保存されているデータをそのまま読み込み、types.Part.from_bytesでラップしてmime_typeを付与して返しています。そのため、保存するデータに応じて適切なmime_typeを指定する必要があります。
改善案:動的なMIMEタイプ判定の実装
以下のような実装により、保存するデータの種類に関わらず柔軟に対応できます。
import mimetypes
# ...省略...
async def load_artifact(
self,
*,
app_name: str,
user_id: str,
session_id: str,
filename: str,
version: int = None
) -> types.Part:
file_path = os.path.join(
self._get_artifact_dir(app_name, user_id, session_id), filename
)
with open(file_path, 'rb') as f:
data = f.read()
mime_type, _ = mimetypes.guess_type(filename)
if mime_type is None:
mime_type = "application/octet-stream"
return types.Part.from_bytes(data=data, mime_type=mime_type)
 おまけ(VertexAI RAG Memory Service)について
おまけ(VertexAI RAG Memory Service)について
今回は実装していませんが、Memoryの中で、VertexAI RAG Memory Serviceがあるので紹介します。
VertexAI RAG Memory Serviceは、セマンティック検索が出来るので費用や外部へのデータ通信に制約が無ければこちらを利用するのが簡単そうです。
VertexAI RAG Memory Serviceとは
VertexAiRagMemoryServiceは、Google Cloud Vertex AI RAGを使用してSessionデータを保存・検索するMemoryServiceの実装です。開発・テスト段階ではInMemoryMemoryServiceを使用し、本番運用時にVertexAiRagMemoryServiceに切り替えることが推奨されています。
詳細なコードは以下で確認できます。
https://github.com/google/adk-python/blob/main/src/google/adk/memory/vertex_ai_rag_memory_service.py
実装の概要
1.データ変換処理
SessionをMemoryに保存する際、まずSessionのイベントをテキストファイルに変換します(vertex_ai_rag_memory_service.py:67-91)
- Sessionの各イベントを順次処理
- テキスト部分のみを抽出(改行を空白に置換)
- JSON形式でauthor、timestamp、textを保存
- 一時ファイルに書き出し
2.RAGコーパスへのアップロード
変換されたテキストファイルをVertex AI RAGコーパスにアップロードします(vertex_ai_rag_memory_service.py:93-105)
3.Memory検索の仕組み
- RAG検索の実行(vertex_ai_rag_memory_service.py:107-120)
- 検索結果の処理(vertex_ai_rag_memory_service.py:122-173)
検索処理では:
- RAG検索を実行してコンテキストを取得
- app_nameとuser_idでフィルタリング
- JSONデータを解析してEventオブジェクトに復元
- 重複を除去し、タイムスタンプでソート
- MemoryEntryとして結果を返却
VertexAiRagMemoryServiceとInMemoryMemoryServiceの比較
| 項目 | VertexAiRagMemoryService | InMemoryMemoryService |
|---|---|---|
| 保存方法 | RAGコーパスへのファイルアップロード | メモリ内辞書 |
| 検索方法 | セマンティック検索 | キーワードマッチング |
| 永続性 | 永続的 | 一時的(プロセス終了で消失) |
| 用途 | 本格運用 | プロトタイピング・開発用 |
| スケーラビリティ | 大規模データに対応 | メモリ容量に制限 |
| レイテンシ | API呼び出しによる遅延あり | 高速(メモリアクセスのみ) |
| コスト | API使用料が発生 | 無料(メモリのみ使用) |
| 実装API例 |
corpus.upload_file(), rag_retrieval()
|
dict.update(), dict.get()
|
実装まとめ
🗂 エージェントの記憶システム 3分類
| 種類 | 用途 | 実装API例 |
|---|---|---|
| 長期記憶(Memory) | セッションを超える永続的な知識・履歴 |
add_session_to_memory(), search_memory()
|
| 短期記憶(State) | セッション中の一時的な状態・文脈 | session.state["key"] = value |
| 一時記憶(Artifact) | ファイルや構造化データの一時保存 |
save_artifact(), load_artifact()
|
📋 各記憶システムの特徴
🟢 長期記憶(Memory)
- ユーザーの好みや過去の会話履歴を永続化
- セッションをまたいで情報を保持
- 注意点: sessionのEvent全体を保存するため、保存構造と検索対象の設計が重要
🟠 短期記憶(State)
- 4つの名前空間で状態を管理
-
app:全ユーザー共有 -
user:ユーザー固有 - プレフィックスなし: セッション固有
-
temp:非永続化
-
- 会話の文脈維持に活用
🔵 一時記憶(Artifact)
- 画像、PDF、JSONなど多様なデータ形式に対応
- Tool間でのデータ受け渡しに便利
- 注意点: mime_typeの適切な設定が必要
💡 実装時の重要ポイント
- Memory: EventからどのPartを保存/検索対象にするか設計が必要
- State: 名前空間の使い分けで効率的な状態管理
- Artifact: ファイルタイプに応じたmime_type自動判定の実装推奨
AIエージェントの記憶システムは、人間らしい対話を実現するための重要な要素です。それぞれの記憶タイプの特性を理解し、適切に使い分けることで、より自然で文脈を理解したエージェントを開発できると思います。