はじめに
AIエージェントが発達した昨今、頭の中で想像したものを実際にアプリとして落とし込むことは障壁がかなり低くなったと思います。
しかし、一方でこの先エージェント自体を今までのように安易に利用することが難しくなってくるかもしれません。
GitHub Copilotが2026年6月1日より従量課金制へ移行すると発表しました。
これまでの「プレミアムリクエスト」方式が廃止され、「GitHub AIクレジット」という実使用量ベースの課金に切り替わります。GitHubはその背景として、Copilotがエディタ内のアシスタントから複数ステップをこなすエージェント型プラットフォームへ進化したことで計算コストが大幅に増加し、「現行モデルは持続可能ではなくなっている」と明言しています。
プラン基本料金は変わらないものの、クレジットを使い切れば追加利用はできなくなります。
また、LLMを動かすためにかなりの電力が消費されており、電力は石油などの天然資源から作られていますが、昨今の情勢によりそのリソースのコストも高騰しています。
このようにLLMはできることが増え便利になっていく一方で、利用コストも上昇していく流れが見えてきています。
私も一エンジニアとして最新モデルを使って業務効率化に取り組んでいきたいところですが、コストを気にし始めると今まで通りに安易に取り組めなくなりそうです。
対策
では、コスト高騰した際にあまり影響を受けない手段とは何でしょうか。
ここで考える対策として3つあると思っています。
- AI依存度を意図的に下げる
- 低価格モデル×プロンプト最適化
- ローカルLLMでクラウドへの依存を分散する
3つ挙げましたが結局は1が最も根本的な解決で2と3はさらに抑える施策だと思います。
対策1はコスト高騰に関わらずAIを使いこなすために日々意識しておかなければならないと思っています。例として、「ハルシネーションを見極める能力」や「LLM自体を制御する能力」といったものですね。私自身まだ学ぶべきことが多い立場ですが、LLMの進化によって「使いこなす側」に求められる知識も増え続けています。そこで自分なりに意識していることを挙げます。
- 技術学習を継続する - 変化に対応できるように常日頃からキャッチアップに取り組む
- AIの行動を承認する前に必ず確認する — 生成されたコードや提案は「何をしているか自分で説明できる」状態にしてから適用する
- 「理解せずにとりあえずやらせる」をNGルールにする — 動いたからOKではなく、なぜ動くかを言語化できることを基準にする
対策2はとりあえず最新モデルを使えばいいというわけではなくタスクの複雑さによってモデルを変えるということですね。すべてのタスクにGPT-4oやClaude Sonnetは必要ありません。タスクに合ったモデルを選ぶだけで、コストを大幅に削減できます。
モデル選択の目安
| タスク | おすすめモデル | コスト感 |
|---|---|---|
| コード補完・小規模修正 | GPT-4o mini / Claude Haiku | 低コスト |
| 設計相談・中規模実装 | GPT-4o / Claude Sonnet | 中コスト |
| 複雑なアーキテクチャ検討 | o1 / Claude Opus | 高コスト(必要時のみ) |
プロンプト最適化のポイント
- 不要なコンテキストを削る - 関係ないファイルを読み込まない
- 一度の指示で完結させる - 往復回数を減らすほどコストが下がる
- キャッシュを活かす - 同じシステムプロンプトを使い回す
プロンプト最適化については、Zennに優れた解説記事が多数あります。「Claude トークン 削減」「プロンプト最適化」などで検索すると参考になります。
一方、対策3は対策2の「タスクによってモデルを使い分ける」という考え方からさらにローカルLLMへタスクを分散させるという考え方です。
ローカルLLMは性能自体がクラウド上のモデルと比較すると劣っているという理由から使われていないイメージがありますが、久々に試してみると思った以上に性能がよかったので改めて取り上げたいなと思いました。
こちらについて、次の項目で詳しく説明していきます。
ローカルLLMでクラウドへの依存を分散する
そもそもローカルLLMとは、通常ChatGPTやClaudeといった大規模なLLMの軽量版をオンプレマシンに落とし込んできて利用する形態です。
ローカルLLMはOllamaやHuggingFaceなどといったプラットフォームでオープンソースで誰でも利用できるモデルが配布されており、必要に応じて自分の環境で利用することも可能です。
ローカルLLMを利用することによるメリットは以下が挙げられます。
ローカルLLMのメリット
- API従量課金がかからない(ハードウェア・電力コストは別途かかるが、呼び出しごとの課金は発生しない)
- プライバシー保護(コードや機密情報がクラウドに送られない)
- オフライン動作(ネット環境に依存しない)
- レスポンス速度(ネットワーク遅延なし)
ローカルLLMのデメリット
逆にデメリットを挙げると、主に3つあります。
- 回答精度が落ちる(クラウド上のモデルと比較するとモデル性能が落ちてしまう)
- 動かすためのインフラが必要(VRAMを必要とするためGPU付きのPCが必要)
- 安定稼働のためのリソース管理を自前で行う必要がある(クラウドでは保証されていた稼働環境を自社・個人で管理しなければならない)
もちろんデメリットもありますが、コストの急騰で使えない状況になったときにどうしても使いたいならローカルLLMを利用することは有力な候補だといえます。
では、どのように利用するかを以下の項目で紹介します。
Ollamaで始めるローカルLLM
ローカルLLMの導入例としてOllamaを使った方法を紹介します。
Ollama を使えば、手元のPCで高品質なLLMを動かせます。
まずはOllama自体をインストールします。
インストール手順はOllamaのGithubリポジトリのREADMEを参照してください。
https://github.com/ollama/ollama
インストール後はOllama内のコマンドを使うことですぐにモデルをダウンロードできます。
# インストール後、モデルをダウンロード
ollama pull llama3.2
ollama pull qwen2.5-coder # コーディング特化モデル
# モデルを起動(OpenAI互換APIとして使える)
ollama serve
ここまでできると、すぐに使えるようになるので以下、実践例を提示します。
実践例
セットアップが完了したら、ターミナルから直接モデルに問いかけるだけで使えます。
今回は視覚的に分かりやすくするため、n8n上にワークフローとして構築した例を紹介します。
n8nとは
n8nはオープンソースのワークフロー自動化ツールです。
GUIでノードを繋ぐだけで、APIの呼び出し・データ変換・条件分岐などを組み合わせたワークフローを
コードなしで構築できます。ZapierやMake(旧Integromat)に近い存在ですが、
セルフホスティングが可能な点が大きな特徴です。
今回のようにOllamaのAPIをHTTPリクエストで呼び出す構成も、
ノードを数個繋ぐだけで実現できます。
この記事では、あまり取り上げませんがn8nに関するzennの記事は多くあるので参照してみてください。
詳しくは以下の公式サイトをご覧ください。
https://n8n.io/
コード生成
軽量なコーディング特化モデル(qwen2.5-coder)はこういった定型的なコード生成が得意で、クラウドモデルに近い品質で返ってきます。
-
作成したワークフロー
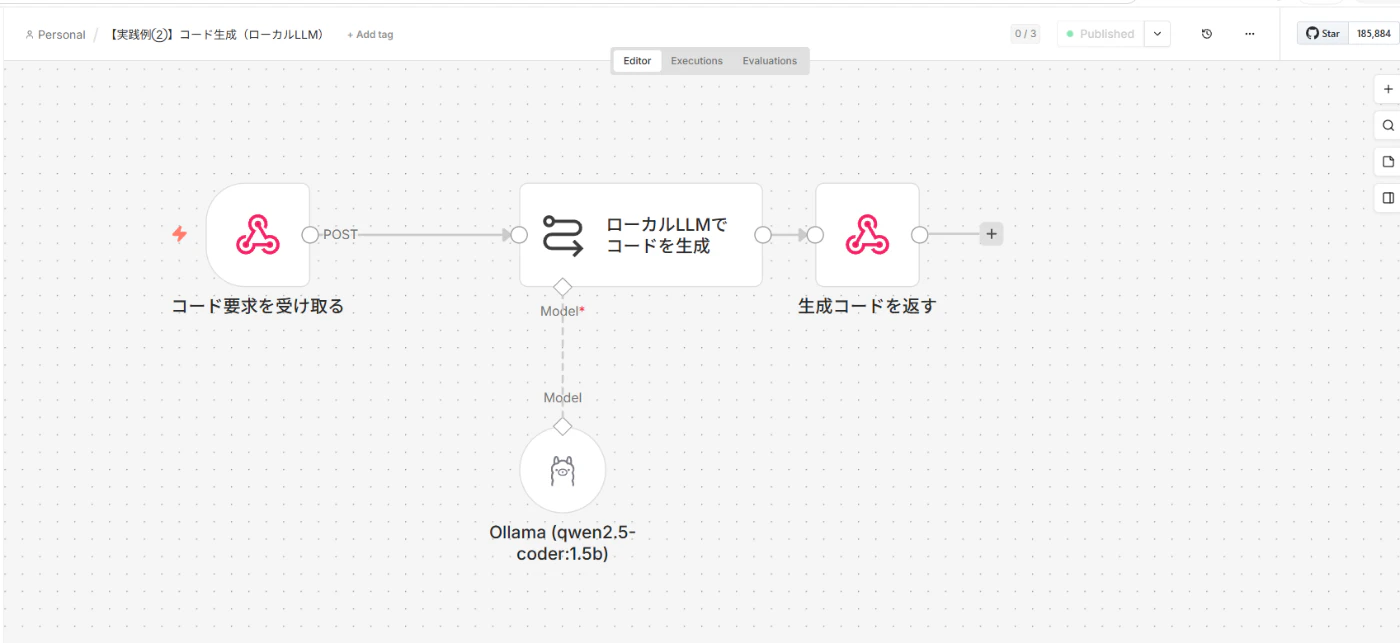
-
入力(リクエストボディ)
{
"request": "Pythonでリストの要素を重複排除して返す関数を書いてください"
}
- 出力(レスポンス)
def list_without_duplicates(input_list):
"""
入力リストから重複した要素を取り除いた新しいリストを作成します。
Args:
input_list (list): 重複した要素を持つ入力リスト
Returns:
list: 重複のない要素のみを持つ新しいリスト
"""
# 集合(set)を使用して重複排除を実行
unique_elements = set(input_list)
# 集合からリストに変換し、結果を返す
result_list = list(unique_elements)
return result_list
# デモ
input_list = [1, 2, 2, 3, 4, 5]
output_list = list_without_duplicates(input_list)
print(output_list) # 出力: [1, 2, 3, 4, 5]
日報自動作成・送信
次は、ローカルLLMをエージェントとして動かした例です。
平日17:30になると自動でGoogleカレンダーを参照し、
その日の予定をもとに日報を作成してGmailで送信します。
-
作成したワークフロー
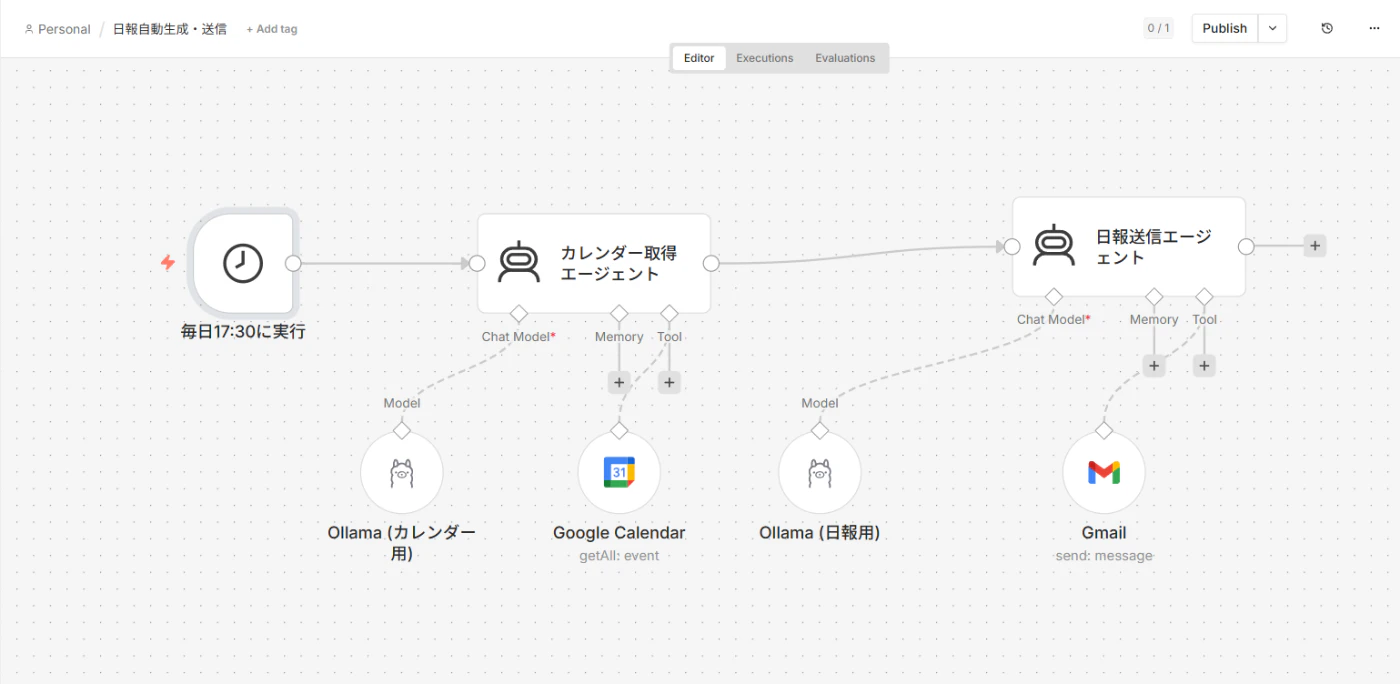
-
LLMの処理
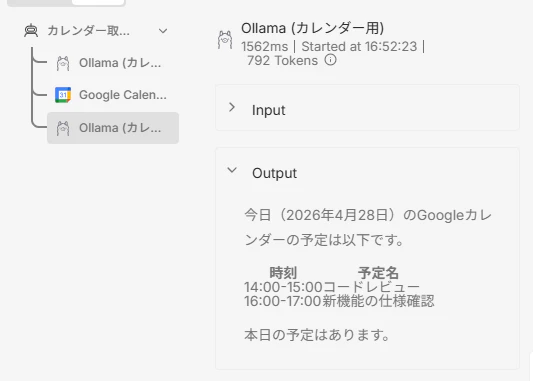
-
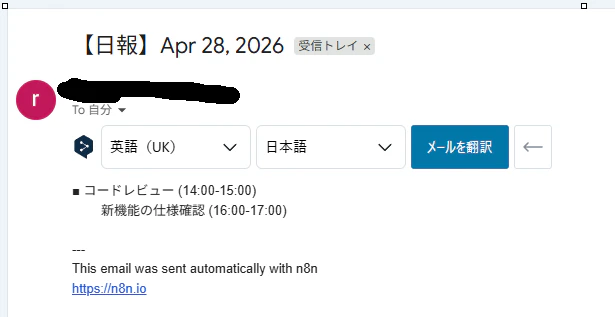
出力(送信されたメール)
2つの例を通して感じたのは、小規模モデルでも実用に耐えうるということです。
今回使用したモデルはいずれも数十億パラメータのSLM(Small Language Model)ですが、
定型的なコード生成から複数ステップにわたるAgentic Workflowまで、
十分な品質で動作することが確認できました。
また、完全オフライン環境で動作するため、社内の機密情報を含むタスクにも安心して適用できます。
なお、今回のn8nワークフロー自体はClaude Sonnetを使ったvibe coding形式で構築しました。
「ローカルLLMに実行させるワークフローをクラウドLLMで組む」という役割分担が、
コストと生産性のバランスをとる上で現実的な選択肢になりそうです。
まとめ
正直なところ、ローカルLLMは「性能が足りない」という理由で
長らく選択肢から外していました。
でも久々に使ってみて、その認識は古いと感じました。
定型的な作業なら、小規模モデルで十分戦えます。
しかもタダで、オフラインで、情報が外に出ない。
クラウドのコストが上がれば上がるほど、この選択肢の価値は上がります。
「全部クラウドに任せる時代」が終わりを迎えつつある今、
ローカルLLMとn8nを組み合わせたワークフローは、
コストと生産性を両立する現実解のひとつだと思っています。
まずはollamaで試してみてください。
思っていたより、ずっと使えます。