はじめに
こんにちは、renkikuです。
この記事は Houdini Advent Calendar 18日目の記事です。
今回はVDBを利用したデータの最適化とVolumeのレンダリング時間の削減の為のデータフロー、というテーマで記事を書かせていただこうと思います。
Houdiniを既にバリバリと仕事で使ってらっしゃる方には物足りない内容かもしれませんが、データ容量の削減というのはVolumeに限らずHoudiniを使っていく上で大事なテーマのひとつでもあるので、少しでも気付きがあるようなら嬉しいなぁ、と思っています。
VDBとは?
Houdiniはかなり前からソフトウェア内部でVolumeを扱える独自のフォーマット(Standard Houdini Volume、便宜的にHoudini Volumeと呼称します)を自前で持っていますが、これは特定のBox内のエリアをボクセル(Voxel)と呼ばれる均等な大きさの小さなキューブに分割してその中に数値を保存するものです(Density, Temperature,等など)。
Fluid Simulationに限らず、シミュレーションのコリジョン(衝突オブジェクト)やFLIP fluidなどの様々な場面で使用されていますが、本来持たなくていい部分のデータを数値として保持していたり、最適化が進んでいない部分が出てきました。そこで登場したのが__VDB__です。
VDBは本来の名前をOpenVDBと言って、元々はDreamworks Animationで開発されたVolume専用のデータフォーマットとそれを操作する為のツールキットをオープンソース化して誰もが使えるようにしたものです。
一番の大きな特徴は__Sparse Volume__と呼ばれるデータ形式でVolumeを保存することによって、データが存在しない部分(正確に言えば定義されたBackGround Valueと同じ値)の情報がメモリー内に保持されないので、Houdini Volumeに比べて__保存時のデータ容量を非常に小さく__出来て、なおかつ__データ読み込み・書き出しのスピードを速くする__ことが出来ることです。
Houdiniには12.5から搭載されていて、その他にもV-RayやArnold、Redshift等の主要レンダラーやFumeFXやPhoenix等の流体シミュレーションソフトからも読み込みや書き出しがサポートされている事実上の業界標準のボリュームフォーマットです。
またHoudiniにも標準で入っているOpenVDBのツールキットを使用することによって様々なVolumeの操作を手軽に出来ることも魅力的な部分です。
ちょっと長い説明になってしまいましたが、この後の説明がスッキリ頭に入ってくるように少しだけ詳しく説明させてもらいました。それでは早速、実際の作業の流れを見ていきましょう!
シミュレーションのデータを最適化しよう!
準備
以下のHIPデータをダウンロードして開いてください。
各部分にはStickies等で注釈が入っていますが、大まかに分けて次の3つになります。

| ノード名 | 説明 |
|---|---|
| Simulation | 今回のメインのシミュレーションとVDBの最適化のデータが入ったツリーです。 |
| Render***_ | レンダリング用ノードです。 |
| VDB | おまけデータ集です。Voxel Sizeの可視化など色々入っていますので、興味ある方は見てみてください。 |
今回の記事の中で主に使うのは__Simulation__なので、まずはその中に入ってみましょう。
最初に

まずは誰もが作るようなシンプルなVolumeシミュレーションを作りました。Sphereを置いてそれをEmitterとしてFuelを出して燃焼させる非常に単純なシミュレーションです。
大してかっこよくありませんが、今回はデータフローを説明するものなのでこれでご勘弁ください… m(_ _)m
ベースはShelfから作るものを少し変えて使用していますが、デフォルトのAutoDopNetworkを使用するものではなく、Object内で完結するようにツリー構造を改変しています。
Houdiniの良い部分の一つがデータの流れを__可視化__できる、ということだと思っているので、データの流れがひと目見てわかるようにツリー構造を作成しました。
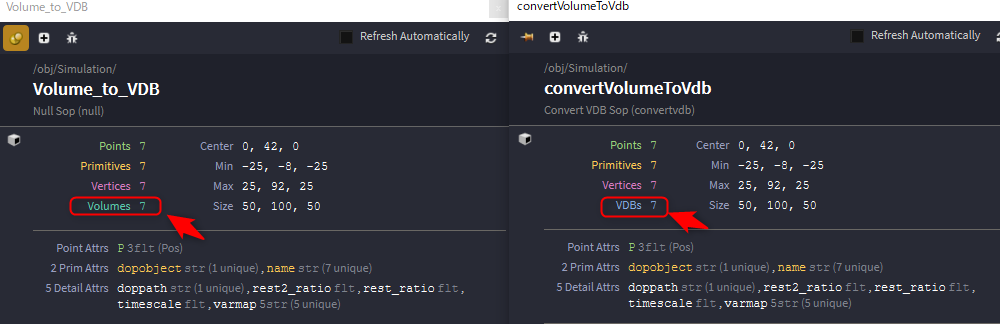
1. VDBに変換する
緑色になっているDopNetworkの直下、DopI/OでDopでシミュレーションされたVolumeのデータをFetchしてきています。
SOP内でのVolume関係のノードはVDBと頭についていない物でも殆どがVDB対応ですが、__DOP内ではHoudini Volumeで計算が行われている__ので(今後のバージョンアップに期待!)、まずはVDBに変換する必要があります。
Convert To を VDB に変えるだけでOKです。
ミドルボタンでノードをクリックして変わっているか確認してみましょう。
2. レンダリングしたいものに合わせていらないデータを消す
基本的には煙のレンダリングに必要なものは__Density__と__Velocity__(モーションブラーが必要であれば)の2種類。
炎や爆発のレンダリングであればそれに加えて__Heat__と__Temperature__が必要になります。
なので、一度それらを要素ごとに独立させてから最終的にMergeすることで整理します。普通にいらないものを選んで消してもいいのですが、いずれはHDA化することも考えて、Switchノードを使って炎・煙・炎&煙を切り替えられるようにしています。
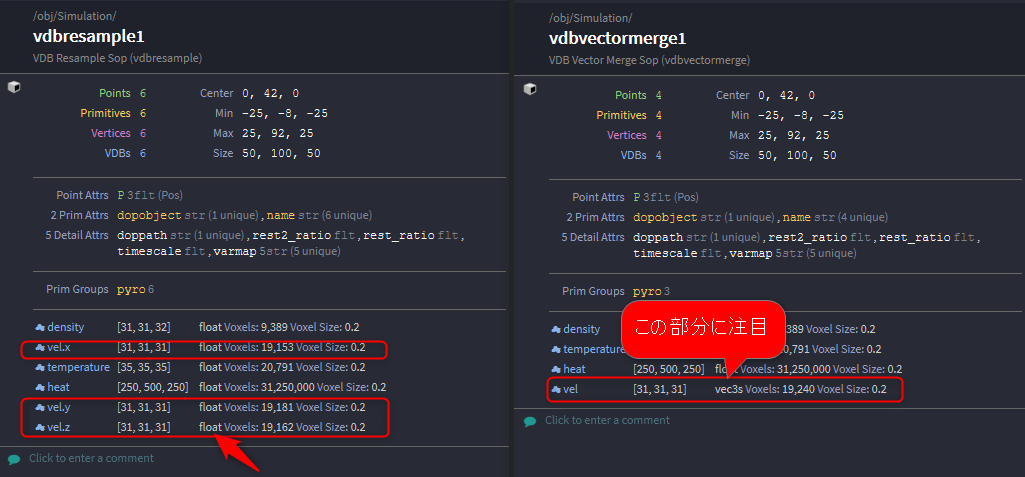
3. データのサンプリングを揃える
Velocityのデータは常に同じ解像度(Resolution)であるとは限らないので、Vector Mergeをする前にVel.xに合わせて他のVel.yとVel.zを変更しています。
そのままMergeしても特に問題があるわけではありませんが、エラーを回避できます。
4. VectorデータをMergeする
Houdini Volumeではスカラでしかデータを保存できませんが、VDBではベクターでデータを保持できるのでVel.x、Vel.y、Vel.zと別れていたものをvelというベクター型に変換します。
後々データをV-RayやArnold等で読み込んでレンダリングする場合は__必須__の手順です。
5. 要らない部分のデータを切り捨てて、BOXのサイズを最適化する。
VolumeでのVelocityはモーションブラーをかけるために必要で、TemperatureはHeatが発光している部分をカラーリングするために必要ですが、Densityのない部分でもVelocityは存在していて、Heatのない部分でもTemperatureが存在しているケースはままあります。
VDB CombineのOperationを__Activity Intersection__にすることによって__inputBのVoxelにデータが存在している部分のみinputAの同じ部分をActiveにする__事ができます。

6. 16bit Floatのデータに変換する
データ最適化の最後に__32bit Float__で保存されているVolumeの各チャンネルのデータを__16bit Float__に変換します。これはデータの圧縮を行う上で非常に有効な手順ですが、同時に自分の場合はレンダリング前の最後の段階で行うようにしています。
なぜ最後なのか、という理由ですが、もしデータを流用して他のシミュレーションなどを行う場合に精度不足によって結果に不具合が出る可能性を出来るだけ排除するためです。
厳密に言えばレンダリング時も__薄く作った煙をMultiplyしてモクモクさせたり、Fit Rangeで狭いエリアを大きく広げて使う__などの場合はバンドが出るなどの弊害はあるかもしれませんが、今まで使用していて目に見える問題が起こった事はありません。

データが16bit化されたかどうかはHoudini Advent Calendar 16日目で@AokTky_doriさんが解説されていたIntrinsic Attributeを参照することで確認できます。


これで最適化されたVDBデータが作成できました。
最後に出来たデータのサイズを最適化前と後で比較してみましょう。
書き出したキャッシュから100フレーム目の値と全部で120フレーム取ったキャッシュの総容量で比較してみます。
| Houdini Volume | Optimized VDB | 削減量 | |
|---|---|---|---|
| Frame 100 | 205.25MB | 83.58MB | 41.32% |
| Frame 1-120 | 14.13GB | 4.42GB | 31.28% |
キャッシュ容量を半分以下に減らすことが出来ました。
ちなみにここまでとはいきませんが、Houdini Volumeも__Volume Compress__ノードなどを使用してデータを圧縮することは出来ます。
レンダリング時にPacked Primitiveで読み込む
最後にレンダリングについて大事なことだけ書きたいと思います。
キャッシュされたデータをレンダリング用に読み込む際は必ず__Packed Disk Primitive__で読み込んでレンダリングするようにします。

こうすることによって__Mantraでレンダリングする際にデータが直接ifdに書き込まれる事を避けられ__ます。
Volumeデータはその性質上、サイズが大きくなりがちなのでせっかく最適化してキャッシュに取ったデータをレンダリング時に再びifdに書き出すのは効率的が悪いのみならず必要がない場合が殆どです。
Packed Disk Primitiveとして読み込まれたデータは__Unpack__ノードを使ってUnpackすることでメモリー内にデータとして展開できるので、もしビューポートなどで確認する必要がある場合はUnpackすれば大丈夫です。
Hipファイル内の__Render_VDB__を参考に見て頂ければどんな感じで普段自分が作業しているか確認できると思います。
本当はレンダリングについてもっと色々と書こうと思っていたのですが、全体が長くなってしまったのでレンダリング時についてはとりあえず手短に…
最後に
後半はかなり駆け足になってしまいましたが、なんとか一通り書けました…
今回のAdvent Calendarは本当にレベルが高くて、他の方々の記事を読んでいるだけで凄く勉強になります。
VFXに限らず、モデリングやデータの可視化、果てはDeep Learningに至るまでHoudiniの懐の深さと奥深さを改めて感じさせられました。
自分自身も最近は今までと少し毛色が違った事をHoudiniでやることが増えてきたので、もしまた同じような機会があれば今度はVFX関連以外での記事も是非書いてみたいところです。
冒頭にも書いたとおり初級者向けの内容でHoudini玄人には当たり前のようなことばかりですが、もし気まぐれにこの記事に目を通して間違っている部分や勘違いしている部分に気づきましたらご指摘頂ければ幸いです m(_ _)m
またもっと効率いい方法知ってる!という方などもぜひぜひ教えてください。同じようなことでも人によって全く違うアプローチをしていることがあるので、そういう部分でもこれを機会に少しでも勉強できたらと思います。
最後までお読み頂きありがとうございました。
明日は本家SideFXの@ikatnekさんです!