「世話やきキツネの仙狐さん」というアニメに登場する仙狐さんのAIスピーカーを作ってみました。
家に仙狐さんがいると癒やされるかなと思って作りました。
デモ
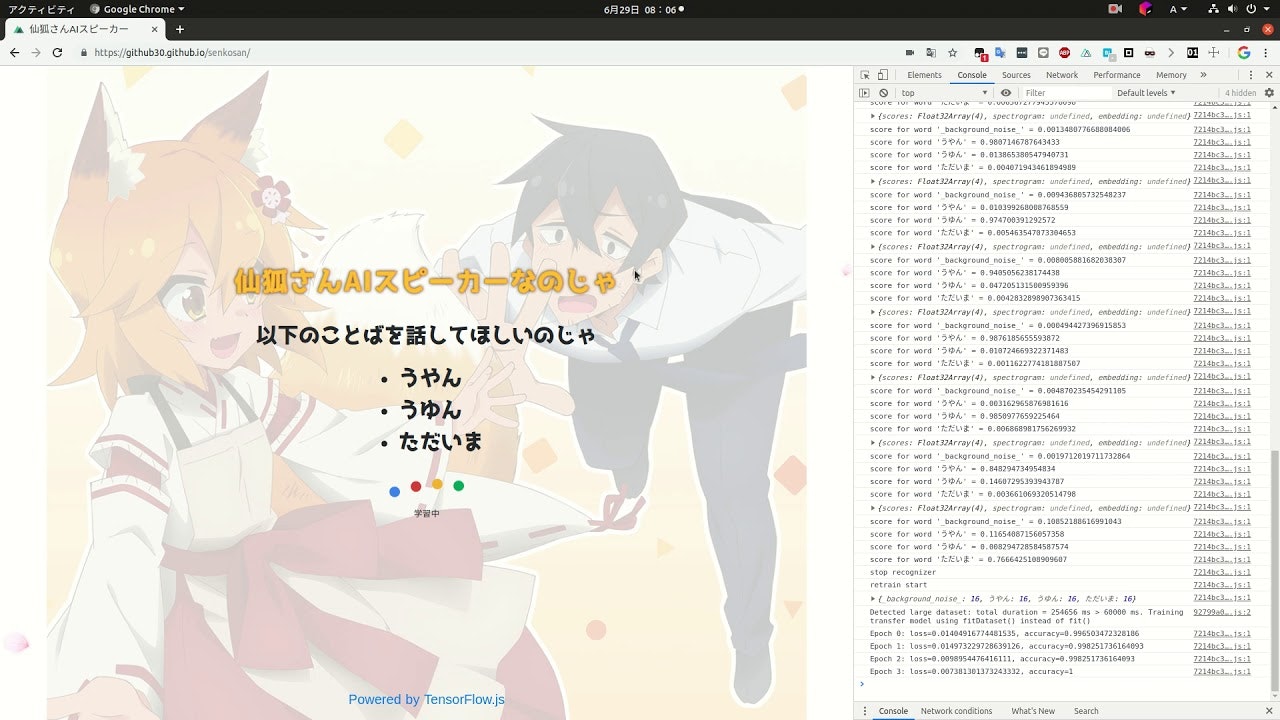
スピーカーとマイクがハウリングしてうまくいっていない部分もありますが、精度はほぼ100%です。(過学習?)転移学習も可能です。
以下のサイトから試せます
https://github30.github.io/senkosan/
ソースコード
https://github.com/GitHub30/senkosan
しくみ
マイクの音声をブラウザで推論して、WebAudio APIで喋らせています。
以前、作った仙狐さんAIスピーカーではブラウザで動かせず、誰でも動かせなかったのですが、ブラウザで学習も推論もできるとすごく便利です。
仙狐さんAIスピーカー作ったのじゃ
https://docs.google.com/presentation/d/1huH7WleWujPH_cNNIlSNS87MHOx1lATSHPSwZuL8jCA/edit#slide=id.p
今回は、TensorFlow.jsのSpeech Command Recognizerを使いました。
データセットの作成
データセットの作成はとても簡単で専用のAPIが用意されています。
例えば、「red」「green」「blue」であれば、collectExampleメソッドを使ってアドホックにデータの作成ができます。collectExampleメソッドのオプションで音声の長さやスペクトログラムを出力するかどうか調節できます。1サンプルあたり8回録音すれば、良い精度がでるのでとても楽です。
// Call `collectExample()` to collect a number of audio examples
// via WebAudio.
await transferRecognizer.collectExample('red');
await transferRecognizer.collectExample('green');
await transferRecognizer.collectExample('blue');
await transferRecognizer.collectExample('red');
// Don't forget to collect some background-noise examples, so that the
// trasnfer-learned model will be able to detect moments of silence.
await transferRecognizer.collectExample('_background_noise_');
await transferRecognizer.collectExample('green');
await transferRecognizer.collectExample('blue');
await transferRecognizer.collectExample('_background_noise_');
// ... You would typically want to put `collectExample`
// in the callback of a UI button to allow the user to collect
// any desired number of examples in random order.
データセットの保存
serializeExamplesメソッドを呼ぶと、ArrayBufferのデータセットが返ってくるので、
例えば、クラウドにアップロードしたり、ローカルPCにダウンロードすることがとても簡単にできます。
const serialized = transferRecognizer.serializeExamples();
データセットのリストア
loadExamplesメソッドを呼ぶと、上記のArrayBufferのデータセットから簡単にリストアできます。
const clearExisting = false;
newTransferRecognizer.loadExamples(serialized, clearExisting);
学習
学習も簡単で何エポック回すか指定するだけです。10エポックぐらいで十分な精度が出ます。データオーギュメンテーションも自動で行ってくれるため、前処理をすることはありません。
// Start training of the transfer-learning model.
// You can specify `epochs` (number of training epochs) and `callback`
// (the Model.fit callback to use during training), among other configuration
// fields.
await transferRecognizer.train({
epochs: 25,
callback: {
onEpochEnd: async (epoch, logs) => {
console.log(`Epoch ${epoch}: loss=${logs.loss}, accuracy=${logs.acc}`);
}
}
});
モデルの保存・リストア
以下のライブラリをみると、model.jsonとmetadata.jsonで管理していくようです。仕様はまだ定かではありませんが、
Teachable Machine Library - Audio
https://github.com/googlecreativelab/teachablemachine-libraries/tree/master/audio
推論
推論もすごく簡単でリッスンするだけで、結果が返ってきますが、scoresを自分でMath.max(...scores)してラベルのどのインデックスかという処理を書かないと正解ラベルがわかりません。
// After the transfer learning completes, you can start online streaming
// recognition using the new model.
await transferRecognizer.listen(result => {
// - result.scores contains the scores for the new vocabulary, which
// can be checked with:
const words = transferRecognizer.wordLabels();
// `result.scores` contains the scores for the new words, not the original
// words.
for (let i = 0; i < words; ++i) {
console.log(`score for word '${words[i]}' = ${result.scores[i]}`);
}
}, {probabilityThreshold: 0.75});
簡単に試せるデモ
また、公式の発表はありませんが、音声認識のカスタムモデルをブラウザで学習して、テストできるデモがあります。
とても面白いのでぜひ触ってみてください。
デモの解説もする予定です。(するとはいってない)
TensorFlow.js Speech Commands
https://storage.googleapis.com/tfjs-speech-model-test/2019-04-18a/dist/index.html
まとめ
以前のTeachable Machineでは、画像分類しかできませんでしたが、
これからは音声認識や姿勢推定もブラウザで完結する時代が来そうです。
楽しみですね。
おーけーグーグルとかアレクサとかヘイSiriとか毎回言ってで疲弊してた人は、カスタム音声認識モデルを作ると捗りそうですね。