0. Alexaスキル開発の概要
Amazon製のスマートスピーカーのAlexaがユーザとの対話で行える行動を"Alexaスキル"といいます。
例えばユーザがスピーカーに向かって"明日の天気を教えて"というと,"明日の○○の天気は○○です"と返すようなスキルがあります。![]()
AlexaスキルはAmazon以外にもユーザが無料で開発することができます。![]()
この記事はAlexaスキル開発をプログラミング言語のPythonとクラウドサービスの1つのAWS Lambdaを使って開発するチュートリアルです。
Pythonの知識が3cmぐらいあれば簡単なものであれば開発できます。 🔰
以下の1つ目のリンクからPythonをウェブ環境で実行できます。また2つ目のリンクからPythonの公式チュートリアルを見ることができます。(3割ぐらい理解できてれば大丈夫なはず)
Amazonが出しているAlexaスキル開発トレーニングページもありますが、それよりもざっくりと説明していきます。またほんとうに簡単なものであればIFTTTを使ってプログラムを書かなくても開発が可能です。

0.0. 概要をつかむ
Alexa のスキルでいったいなにができるの概要がつかめます。
途中"インテント"等よくわからない単語が出てきますが,とりあえず流し見することをお勧めします。![]()
また,時間がない人は倍速で見るのをお勧めします。
- Alexa スキル開発トレーニングシリーズ(第 1 回)
- Alexa スキル開発トレーニングシリーズ(第 2 回)
- Alexa スキル開発トレーニングシリーズ(第 3 回)
- Alexa スキル開発トレーニングシリーズ(第 4 回)
- Alexa スキル開発トレーニングシリーズ(第 5 回)
- Alexa スキル開発トレーニングシリーズ(第 6 回)
全部をみるとわりといろいろなことができることがわかると思います。
以下がAlexaの開発のための"Alexa Skills Kit"の公式リファレンスです。
Alexa Skills Kitによるスキルの作成 | ASK
0.1. Alexaスキル開発のため必要なもの
Alexaスキルはユーザから話しかけられたら以下のような流れで返答をします。
- ユーザがAlexaに話しかける
- 話しかけられた音声データをAlexaサーバに送る
- Alexaサーバ内で音声データを解釈して、ユーザがどのような意図を伝えたかったのか解釈し、その意図の内容を表すテキストデータ(json)を開発者が指定したサーバ(この場合ではLambda)に送る
- サーバでは受け取ったデータからAlexaの返答内容を作成し、テキストデータ(json)をAlexaサーバに戻す
- Alexaサーバは返答内容を読み取り、テキストデータをAlexaが発言する音声データを生成し、生成した音声データをAlexaに戻す
- Alexaは受け取った音声データを再生する
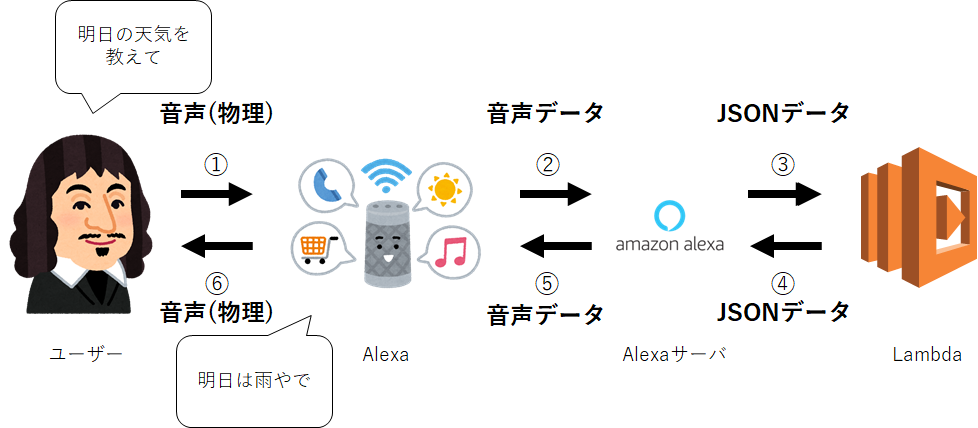
このような背景からスキル開発者はAlexaサーバの設定とAlexaサーバと通信するサーバの設定をする必要があります。
そのため以下のものが必要になります。
- Amazon Developerアカウント (Alexaサーバの設定のため必要)
- AWSアカウント (Lambda(Alexaサーバと通信するサーバ)を使うため)
Amazon Developerアカウントの作成
必要な個人情報を記入する必要があります。
Amazon Developerにはクレジットカード必要ありません。
以下のページから作成できます。
Amazon 開発者ポータル
以下の点を注意してアカウントを作成しないと、開発中のスキルが試せない問題があります。
Alexa 開発者アカウント作成時のハマりどころ : Alexa Blogs
AWSアカウント作成
以下のAmazonの公式のリファレンスからどのように作成すればよいかわかります。
AWS アカウント作成の流れ | AWS
※AWS Lambdaの関数が作成できる権限があるアカウントがあればよいです。
1. スキル開発を行う
今回はAlexaスキル開発のチュートリアルとして好きな動物を覚えさせるスキルを作成します。
非常に簡単で面白みのないスキルですが、基本的なスキル開発を学べます。
スキル開発では開発者は以下の部分の設定・コーディング等を行います。
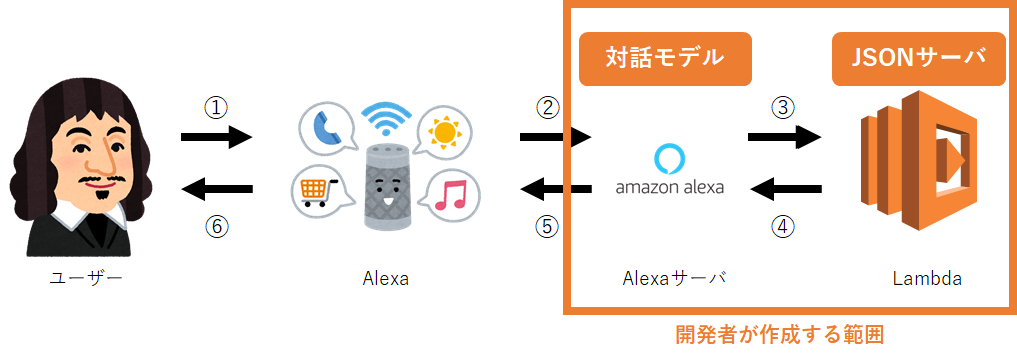
やることは2点あります。
| やること | 作業する場所 | 必要なもの |
|---|---|---|
| 対話モデルの作成 | Alexaのウェブコンソール | Alexa Developerアカウント |
| JSONサーバの作成 | Lambdaの設定ページ等 | Lambdaが使えるAWSアカウント |
だいたい全体像が見えてきたでしょうか?
1.0. スキルの対話モデルを作成
スキルを実装するには現在のページから対話モデルを作成する必要があります。
対話モデルの作成にはAlexaに話しかける内容を定義して、どのように言われたらどの部分をどうとってくるかを設定します。
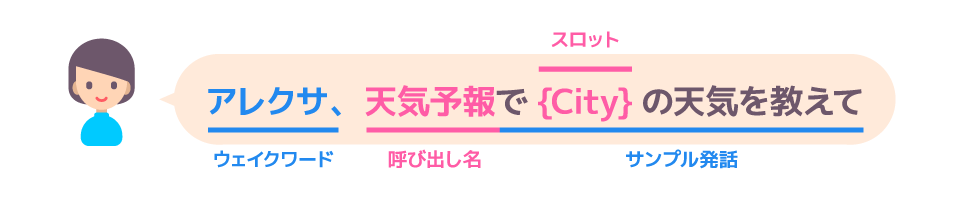
Alexaスキル開発トレーニングシリーズ 第2回 対話モデルとAlexa SDK : Alexa Blogsより
今回のスキルでは以下のようなユーザとの対話を目指します。
![]() 「Alexa, 動物覚えるくんを起動して」
「Alexa, 動物覚えるくんを起動して」
![]() 「あなたの好きな動物はなんですか」
「あなたの好きな動物はなんですか」
![]() 「私の好きな動物はねこです」
「私の好きな動物はねこです」
![]() 「覚えました」
「覚えました」
![]() 「私の好きな動物は」
「私の好きな動物は」
![]() 「あなたの好きな動物はねこです」
「あなたの好きな動物はねこです」
![]() 「私の好きな動物はいぬです」
「私の好きな動物はいぬです」
![]() 「覚えました」
「覚えました」
![]() 「私の好きな動物は」
「私の好きな動物は」
![]() 「あなたの好きな動物はいぬです」
「あなたの好きな動物はいぬです」
![]() 「終了」
「終了」
このような流れを考えた場合、
先ほどの図から「動物覚えるくん」が「呼び出し名」であることはわかります。
また、「ねこ」や「いぬ」がスロットに入ることが考えられます。
スロットは要は変数みたいなやつです。
「ねこ」や「いぬ」が入るスロットをAnimalスロットとします。(動物が入る変数みたいなものです)
するとユーザの発話が以下のようになることが推測できます。
このようなユーザの発話にはそれぞれ意図(インテント)があることがわかります。
そのため、以下のそれぞれをインテントと呼びます。
- 「私の好きな動物は{Animal}です」→好きな動物を覚えされる意図
- 「私の好きな動物は」→覚えされた動物を聞く意図
ここでユーザの発話は多少揺らぐことを考えると2つの文章は以下のような発話パターンが考えられます。
私の好きな動物は{Animal}ですの発話パターン
- 「私の好きな動物は {Animal} です」
- 「好きな動物は {Animal} 」
- 「ぼくは {Animal} は好きです」
私の好きな動物はの発話パターン
- 「私の好きな動物は」
- 「ぼくの好きな動物は」
- 「好きな動物は」
- 「覚えた動物は」
以上のような事柄を対話モデルとしてAlexaのコンソールより定義します。
そうすると対話モデルが完成し、インテントやスロットを理解できるようになります。
1.1. コンソールからスキルの追加をする
以下のウェブコンソールから"スキルの作成"をクリック。
Alexa Skills Kit Developer Console

以下のような画面に遷移します。
今回は
スキル名は**「動物覚えるくん」**
デフォルトの言語は**「日本語(日本)」**
スキルに追加するモデルを選択では**「カスタム」**
を選択します。

そして画面右上の"スキルを作成"をクリック。
こんな画面に遷移します。

このページではAlexaの対話モデルに関する基本的にすべてのことを設定できます。
では実際に設定していきましょう。
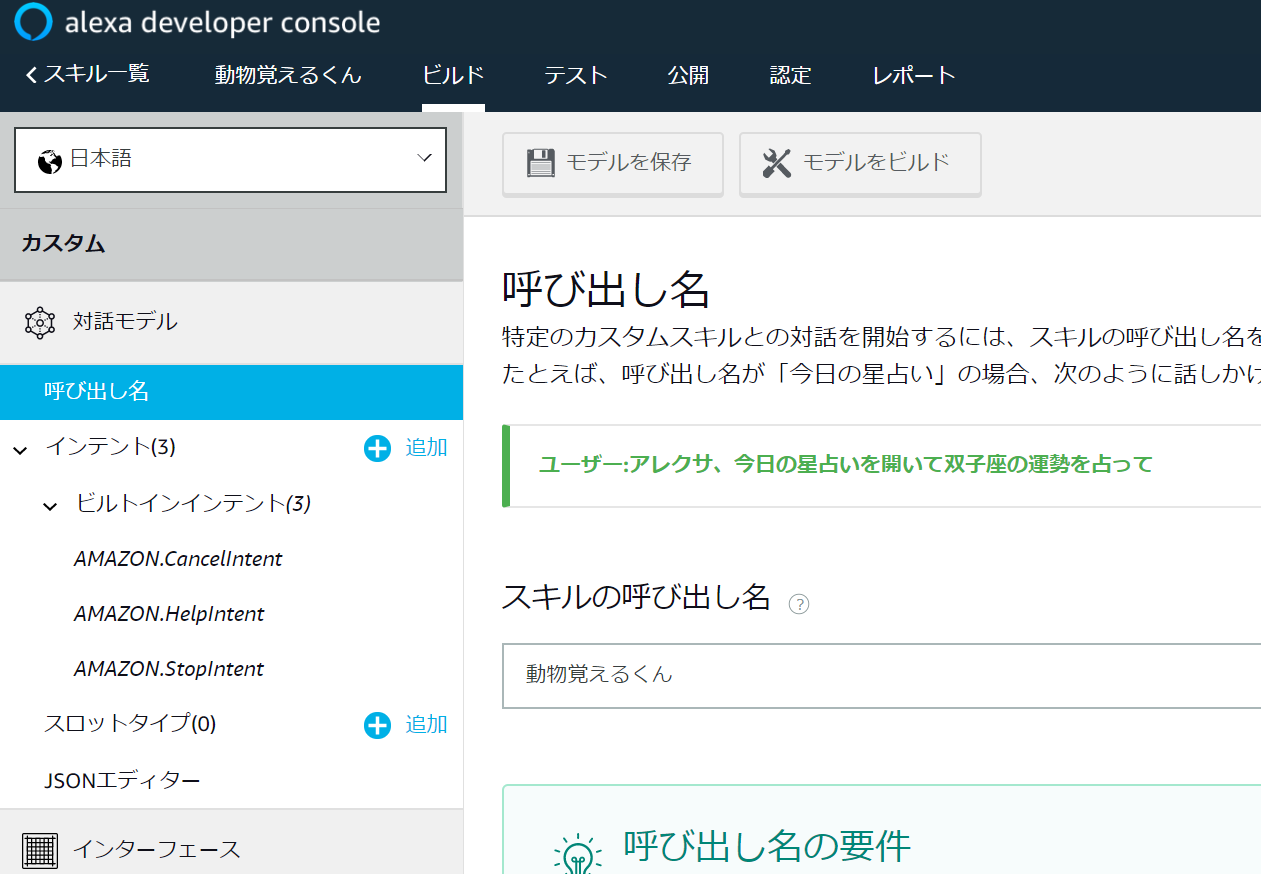
まず以下のように呼び出し名を設定します。
次に変数のようなものであるスロットを設定します。
左のメニューからスロットタイプの追加からAnimalスロットを追加します。
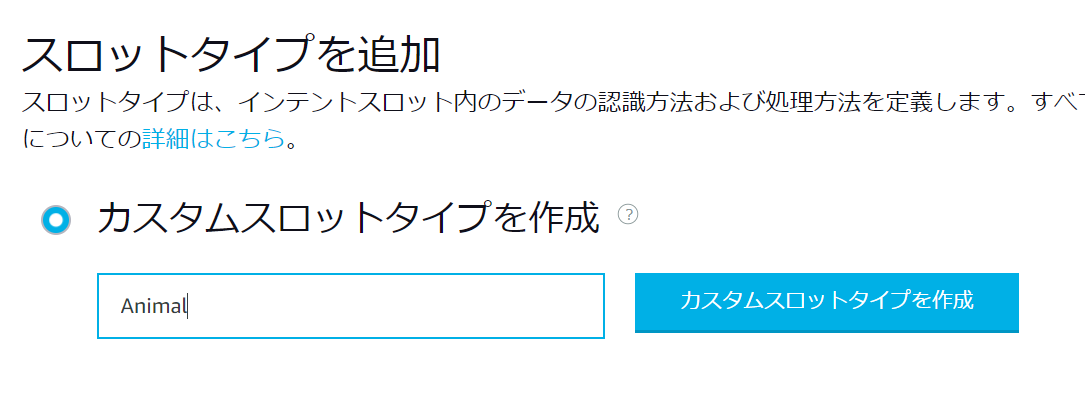
そしてそのスロットに実際に入ることが想定されるものを追記していきます。
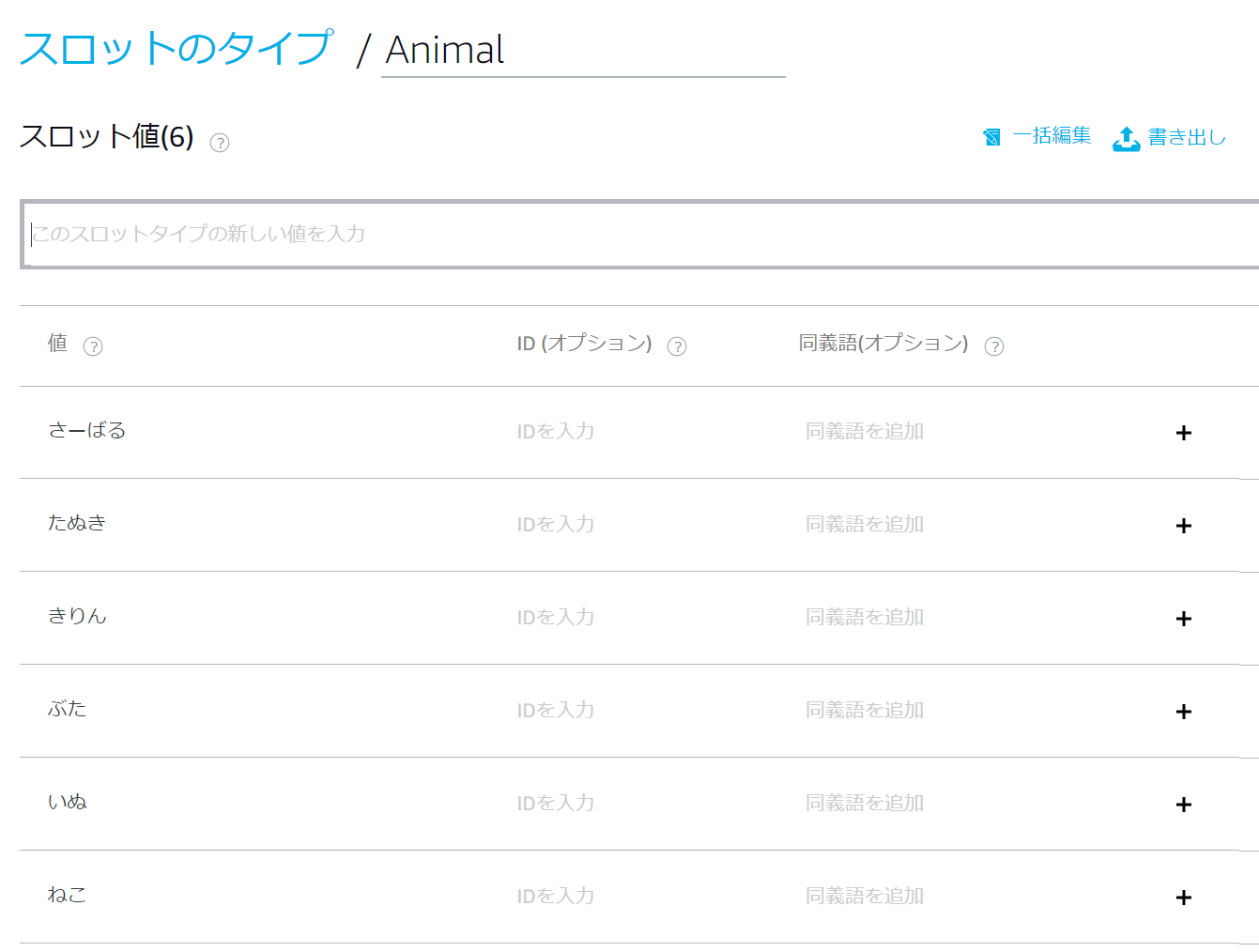
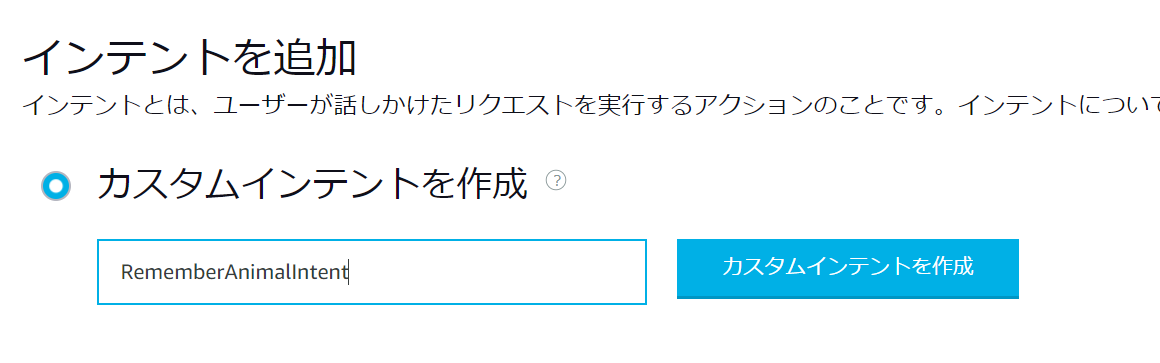
次に対話内容を追加していきます。
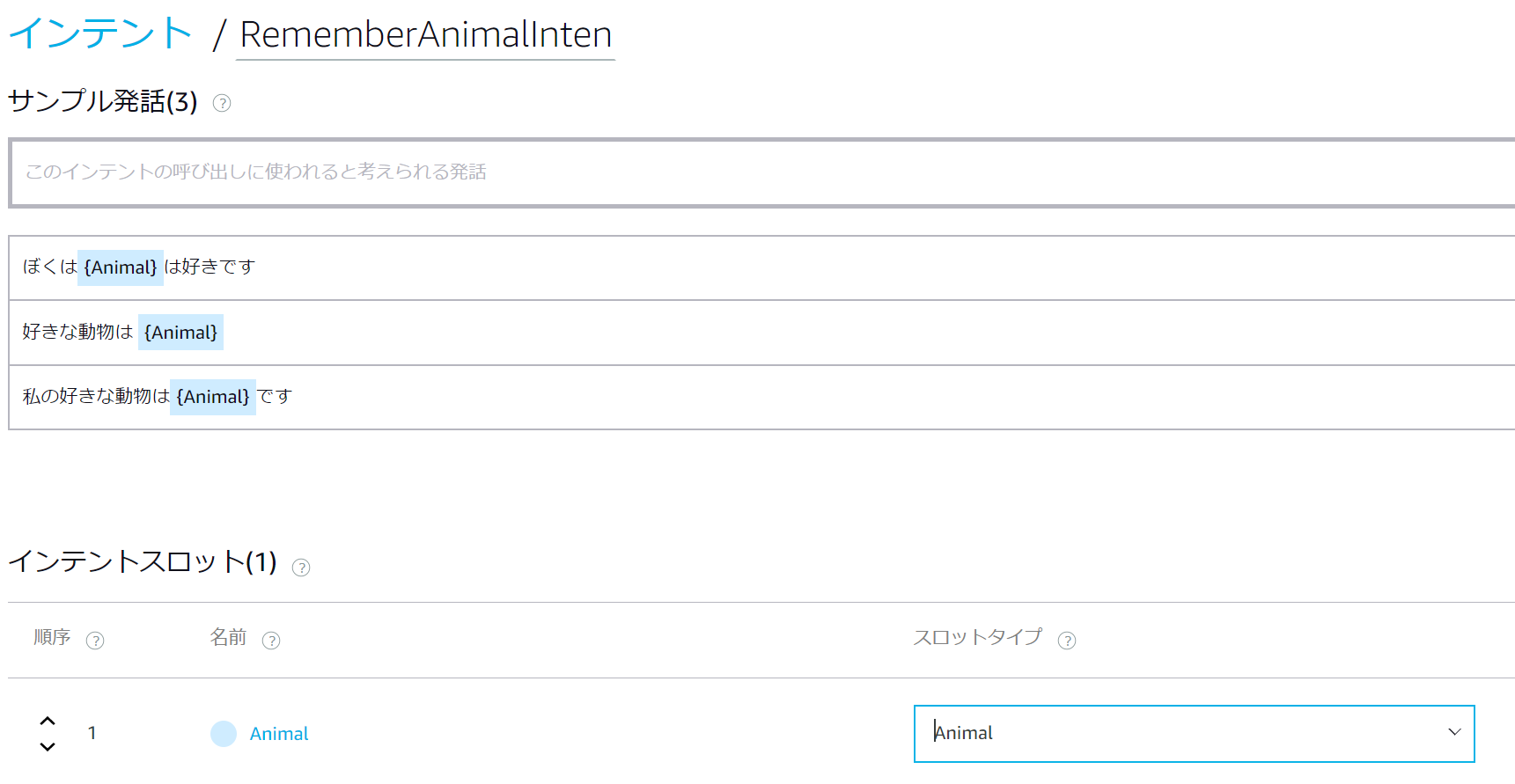
まず動物を覚えさせる意図の対話をRememberAnimalIntentとして新規作成します。
次に動物を覚えさせる意図のサンプル発話を設定します。
また、スロットタイプ(先ほど追加したAnimal)を指定するのを忘れずに。
{Animal}の前後に半角スペースを入れないとビルド時にエラーが発生するので半角スペースをいれてあげましょう
ちなみにAMAZON.Animalというスロットがあります。
こちらはAmazonがあらかじめ用意してくれた動物がいろいろ当てはまるスロットが使えます。(今回作ったAnimalスロットタイプより強力)
このようなAmazonがデフォルトでいろいろなスロットタイプを用意してくれています。(Amazonが用意してくれているインテントもあります)
詳しくはAlexa Skill KitでAmazonが用意したBuilt-In IntentとBuilt-In Slot Typeをひたすらまとめてみる | Developers.IO
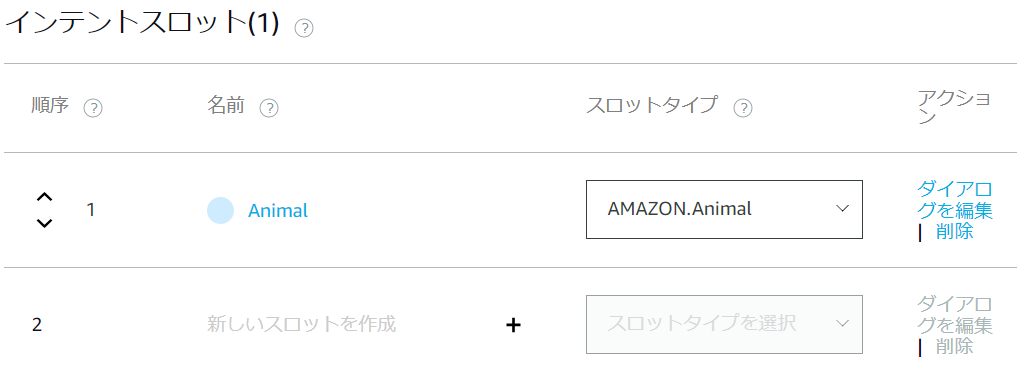
同様に覚えさせた動物を聞くインテントをListenIntentとして以下のように設定します。
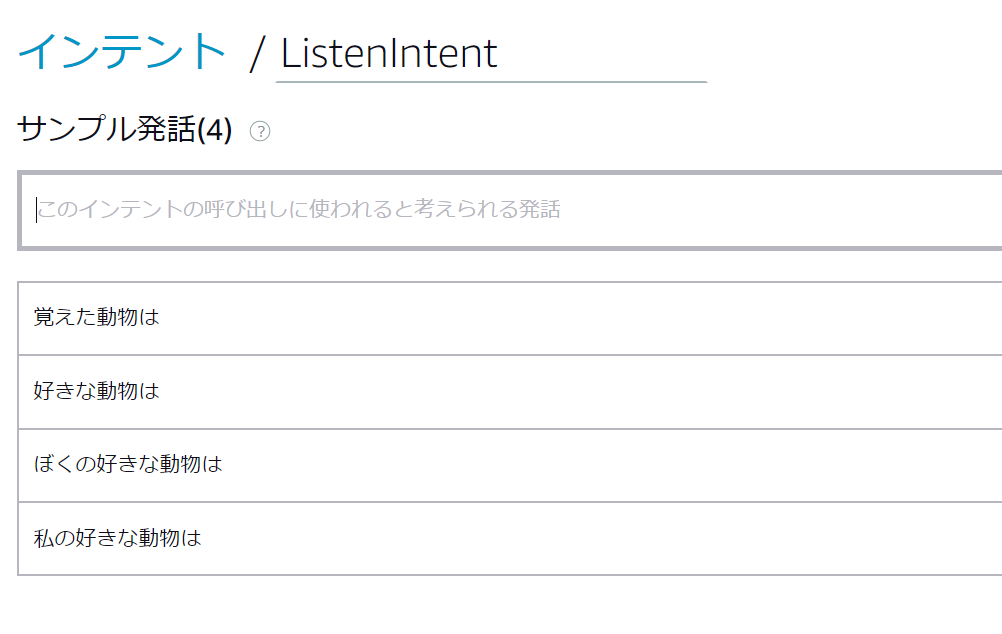
ここではスロットは登場しないので、スロットタイプの指定は必要ありません。
これで対話モデルの設定が終わりました。
画面上部メニューの「モデルの保存」をクリックしておくと良いでしょう。
1.2. スキルのサーバサイドを作成する
1.2.1. Lambdaとは? FaaSとは?
今回はAWSのサービスで、FaaSであるLambdaを使います。
FaaSは簡単に説明すると常時動いているサーバではなく、実行が要求された分だけ動くサーバみたいなものです。
FaaS(Function as a Service)は関数が実行した分の請求のみ発生します、常時動いているサーバよりも圧倒的にコストが低い利点があります。またサーバレスアーキテクチャを考えた場合に、重要な役割を担っています。
AWSのLambdaでは毎月初回の1,000,000回のリクエストは無料で、さらにそれ以降1,000,000回のリクエストにつき0.20USDの請求が発生します。仮にVPSでJSONサーバを立てたら毎月約1000円以上かかるのと比較すると圧倒的に安い!
詳しくは以下の記事をご覧ください。
- FaaS(Function as a Service)とは | 意味・メリット - サーバいらずのクラウドサービス - 開発 | ボクシルマガジン
- 料金 - AWS Lambda(サーバーレスでコードを実行)|AWS
1.2.2. Lambdaを使ってサーバサイドを構築
実際にLambdaを使ってサーバサイドを構築していきましょう。
以下のページから新規にLambdaの関数を作成できます。
Lambda Management Console

![]() Alexaのスキル開発は現在以下のリージョンでしか作成できないので、作成するリージョン(画面右上に表示されている地域)を確認しましょう。
Alexaのスキル開発は現在以下のリージョンでしか作成できないので、作成するリージョン(画面右上に表示されている地域)を確認しましょう。
- アジアパシフィック(東京)
- EU(アイルランド)
- 米国東部(バージニア北部)
- 米国西部(オレゴン)
実際に"関数の作成"ボタンをクリックします。
そして関数の設定をします。
今回はPythonでサーバをコーディングしていくので以下のようになります。
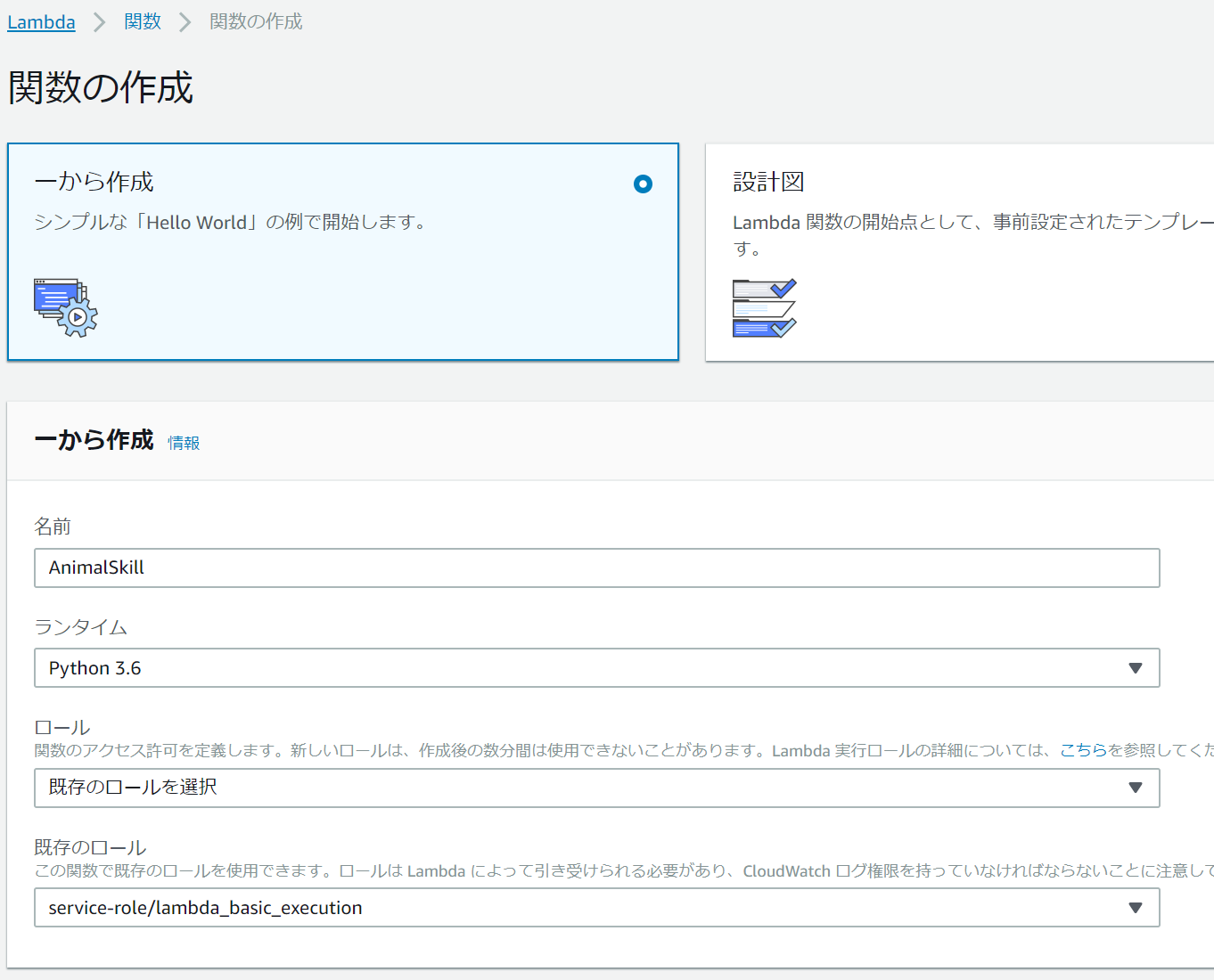
またロールの設定はカスタムロールの作成→以下の画面→許可で設定ができます。

もろもろできたら関数の作成をクリックします。
画面下部に行くとエディタが出てきます。
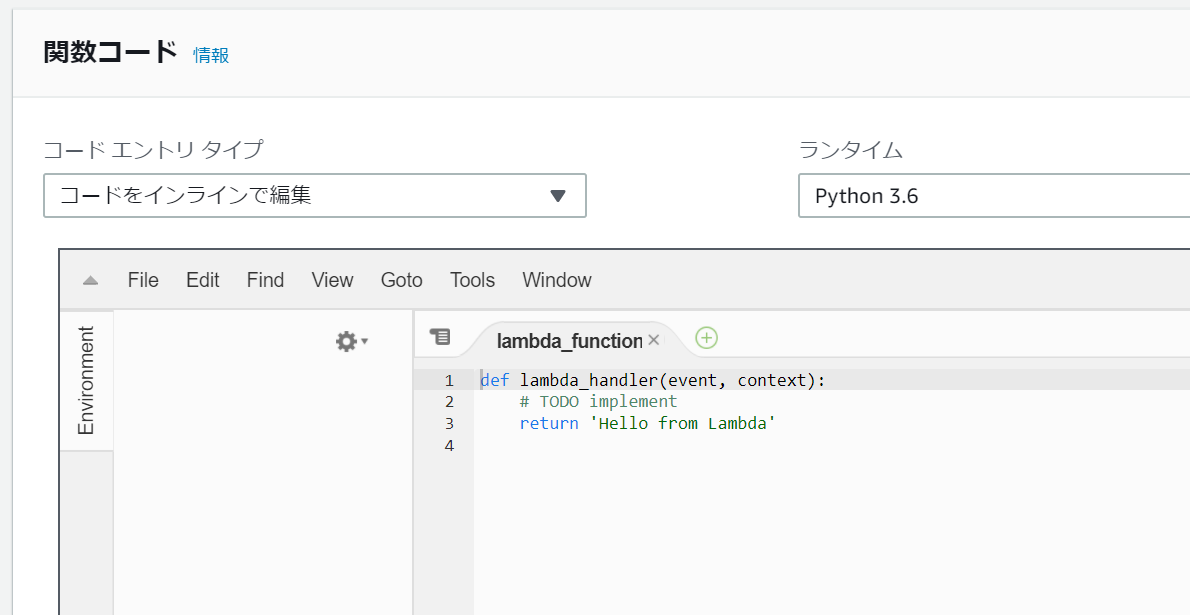
ここにサーバが呼ばれた際の処理を書きましょう。
以下のように記述します。
# coding: utf-8
def lambda_handler(event, context):
"""
始めにここが実行される
eventの中にユーザの発話内容がdictで格納されている
returnでdictを返すとそれがサーバ自体のjsonの返り値になる
"""
if event['session']['new']:
on_session_started({'requestId': event['request']['requestId']}, event['session'])
if event['request']['type'] == "LaunchRequest":
return on_launch(event['request'], event['session'])
elif event['request']['type'] == "IntentRequest":
return on_intent(event['request'], event['session'])
elif event['request']['type'] == "SessionEndedRequest":
return on_session_ended(event['request'], event['session'])
def on_session_started(session_started_request, session):
""" セッションが開始したときに呼び出される """
print("requestId=" + session_started_request['requestId'] + ", sessionId=" + session['sessionId'])
def on_launch(launch_request, session):
""" ユーザーが必要なものを指定せずにスキルを起動したときに呼び出される """
print("on_launch requestId=" + launch_request['requestId'] + ", sessionId=" + session['sessionId'])
return get_welcome_response()
def on_intent(intent_request, session):
""" ユーザがインテントのある発言をしたら呼び出される """
intent = intent_request['intent']
intent_name = intent_request['intent']['name']
if intent_name == "RememberAnimalIntent":
return set_animal_in_session(intent, session)
elif intent_name == "ListenIntent":
return get_animal_from_session(intent, session)
elif intent_name == "AMAZON.HelpIntent" or intent_name == "AMAZON.CancelIntent" or intent_name == "AMAZON.StopIntent":
return handle_session_end_request()
else:
raise ValueError("Invalid intent")
def on_session_ended(session_ended_request, session):
""" セッションが終わったら呼び出される """
print("on_session_ended requestId=" + session_ended_request['requestId'] + ", sessionId=" + session['sessionId'])
def build_speechlet_response(title, output, reprompt_text, should_end_session):
""" 返す発話内容のdictを返す関数 """
return {
'outputSpeech': {
'type': 'PlainText',
'text': output
},
'card': {
'type': 'Simple',
'title': "SessionSpeechlet - " + title,
'content': "SessionSpeechlet - " + output
},
'reprompt': {
'outputSpeech': {
'type': 'PlainText',
'text': reprompt_text
}
},
'shouldEndSession': should_end_session
}
def build_response(session_attributes, speechlet_response):
""" 返す全体のjsonのdictを返す関数 """
return {
'version': '1.0',
'sessionAttributes': session_attributes,
'response': speechlet_response
}
def set_animal_in_session(intent, session):
card_title = intent['name']
session_attributes = {}
should_end_session = False
if 'Animal' in intent['slots']:
favorite_animal = intent['slots']['Animal']['value']
session_attributes = {"favoriteAnimal": favorite_animal}
speech_output = "あなたの好きな動物は " + \
favorite_animal + \
"ですね。 "
reprompt_text = speech_output
else:
speech_output = "動物が分からなかったよ。もういちど言って "
reprompt_text = speech_output
return build_response(session_attributes, build_speechlet_response(
card_title, speech_output, reprompt_text, should_end_session))
def get_animal_from_session(intent, session):
session_attributes = {}
reprompt_text = None
if session.get('attributes', {}) and "favoriteAnimal" in session.get('attributes', {}):
favorite_animal = session['attributes']['favoriteAnimal']
speech_output = "あなたの好きな動物は " + favorite_animal + \
"です。終わります。"
should_end_session = True
else:
speech_output = "私はあなたが好きな動物が分からないです。" \
"好きな動物はいぬですとかって言ってください。"
should_end_session = False
return build_response(session_attributes, build_speechlet_response(
intent['name'], speech_output, reprompt_text, should_end_session))
def get_welcome_response():
session_attributes = {}
card_title = "あなたの好きな動物はなんですか"
speech_output = "あなたの好きな動物はなんですか"
reprompt_text = "あなたの好きな動物はなんですか"
should_end_session = False
return build_response(session_attributes, build_speechlet_response(
card_title, speech_output, reprompt_text, should_end_session))
def handle_session_end_request():
card_title = "おわります"
speech_output = "おわります"
should_end_session = True
return build_response({}, build_speechlet_response(
card_title, speech_output, None, should_end_session))
コードの保存はウェブ上から行えます。
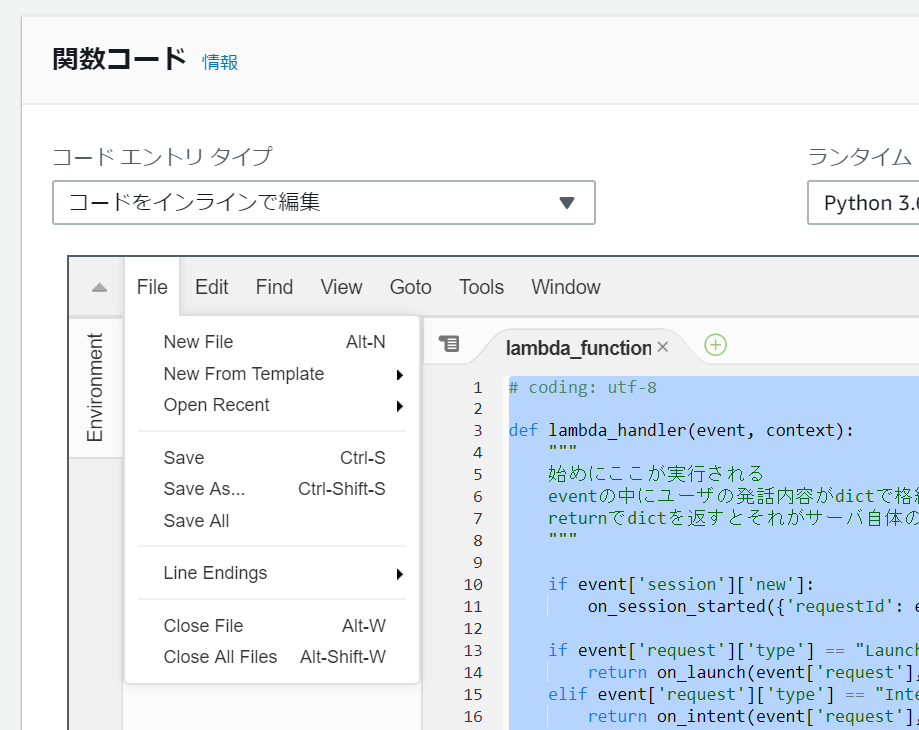
また、Lambda自体も保存しないと反映されないので画面右上から保存しましょう。(オレンジ色になっていれば保存できます)
1.3. 対話モデルとサーバサイドをつなげる
スキルを動かすために以下の2点の設定が必要です。
- 対話モデルからサーバサイドの設定
- サーバサイドから呼ばれる元の設定
途中エラーが出る場合はモデルの保存やビルド,Lambdaの保存をしてから再度設定してみてください。
1.3.1. サーバサイドから呼ばれる元の設定
関数がどこから呼ばれるのか設定します。
LambdaのDesignerの項目の左部から"Alexa Skills Kit"をクリックして追加します。(以下のよう)
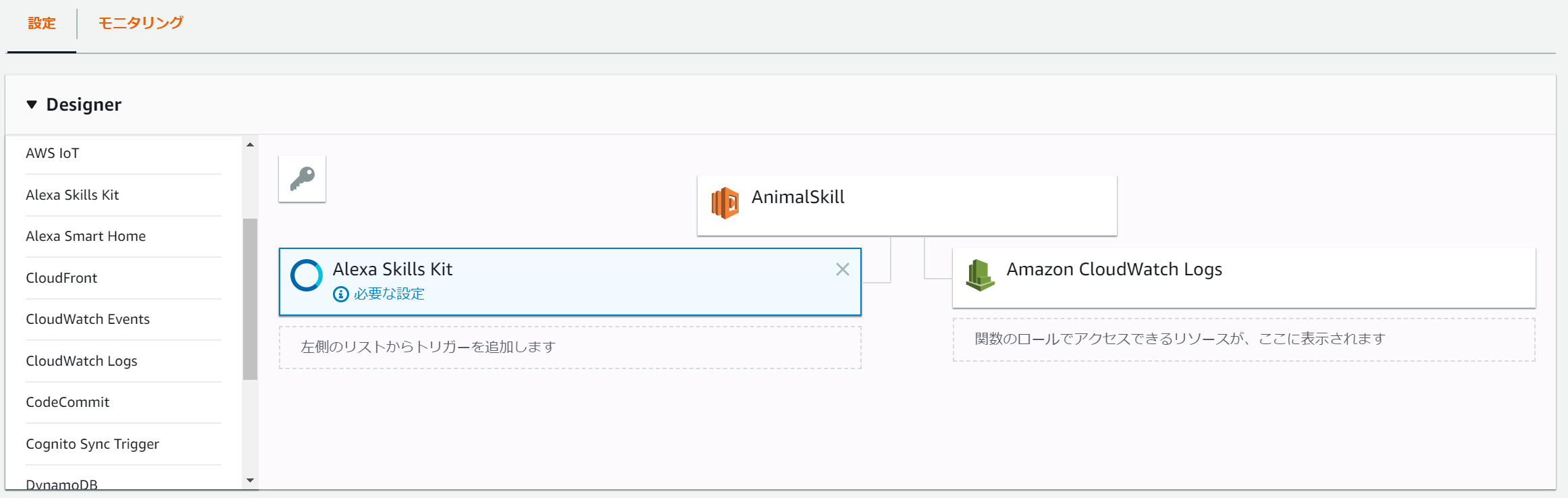
Alexa Skills Kitが左部に出ない場合はリージョンの設定が問題であることが考えられます。
関数を削除して、以下のリージョンであらたに作成しましょう。
- アジアパシフィック(東京)
- EU(アイルランド)
- 米国東部(バージニア北部)
- 米国西部(オレゴン)
追加するとトリガーの設定の項目がページ下部に出現します。
そこでAlexaのスキルIDを指定する必要があります。
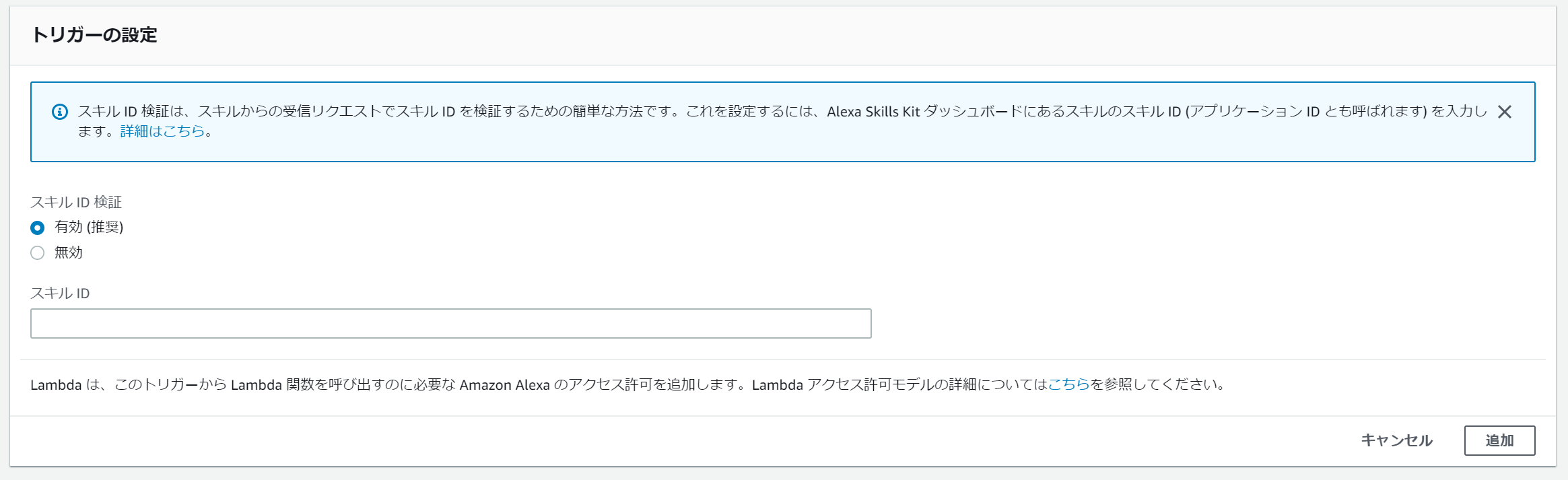
追加ボタンを押して完了。
1.3.2. 対話モデルからサーバサイドの設定をする
Alexaのコンソールから呼び出すサーバの設定をする必要があります。
コンソールのエンドポイントから以下の画面に行きます。
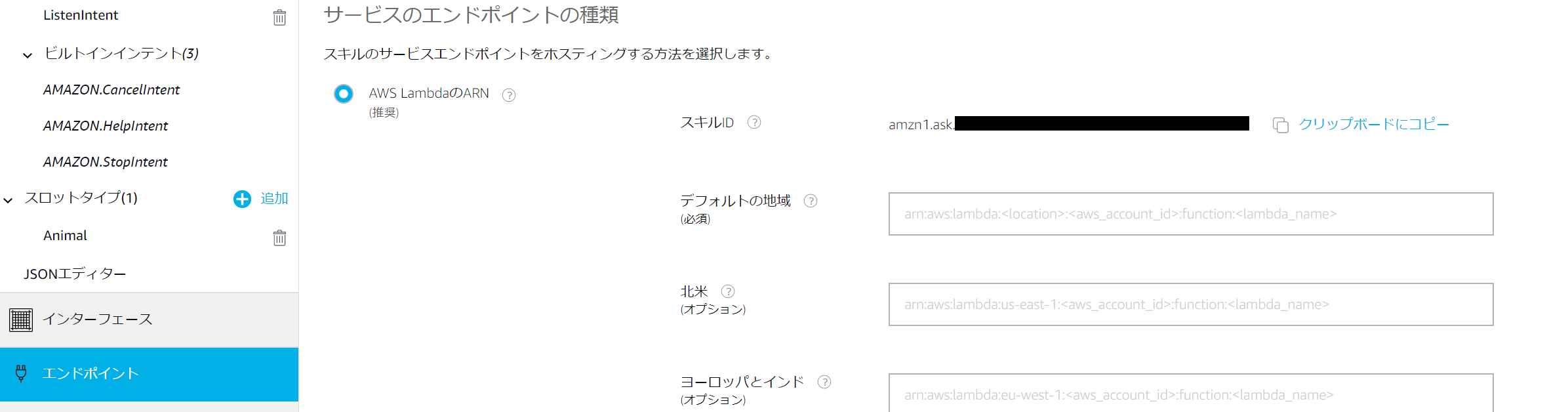
デフォルトの地域にLambdaのコンソールの画面右上(以下の画像)にあるARNを入力します。

入力した後に、対話モデルを保存→ビルドします。
1.4. テストをしてみる
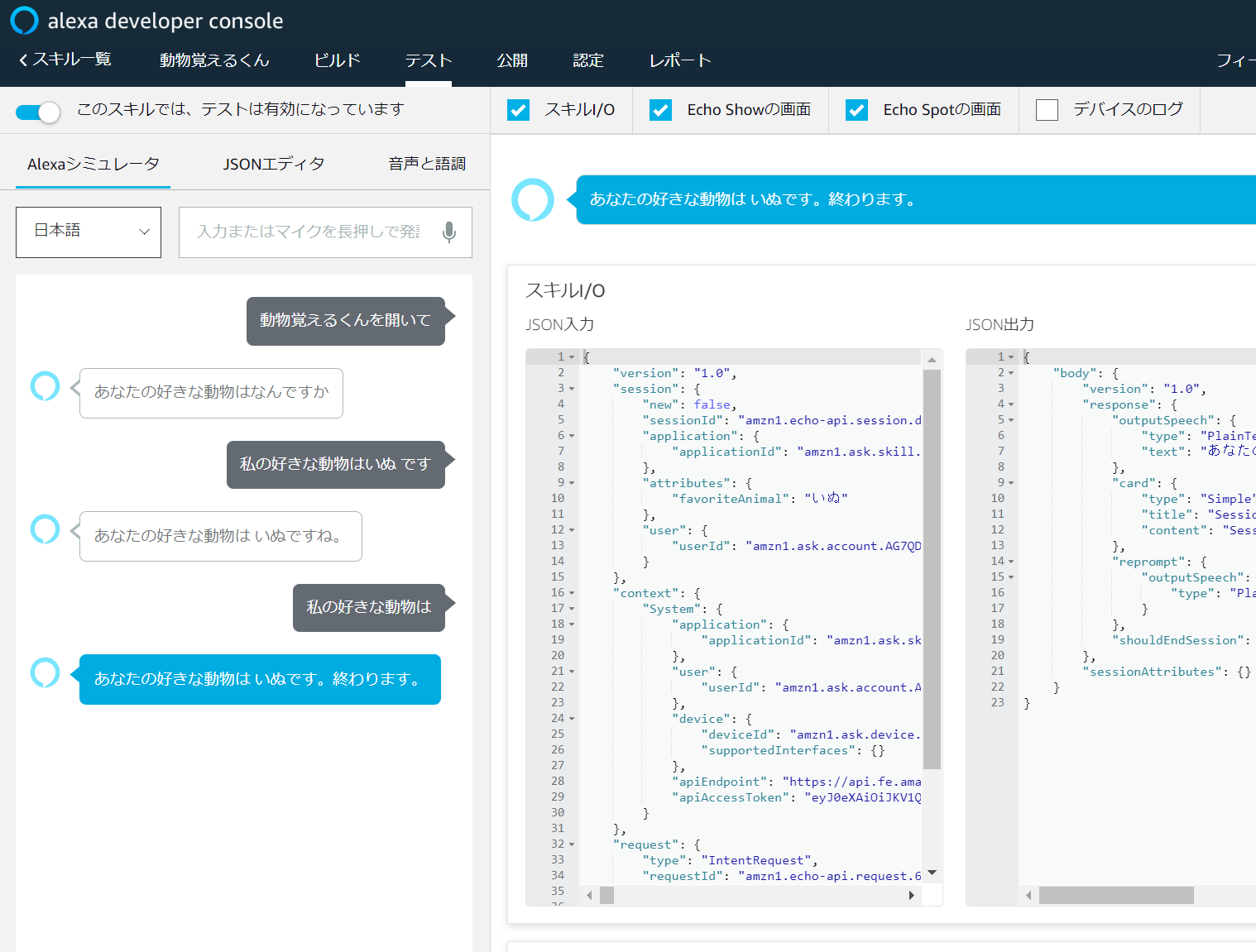
alexa developer consoleからスキルのテストが行えます。
ここでは、実際にAlexaに話しかける内容を入力して、テストが行えます。
また、どのようなjsonがサーバに送られ、どのようなjsonがサーバから返ってくるのか確認できます。
1.5. デバッグ方法
主なデバッグ方法として、1.4.のalexa developer consoleからスキル(対話モデル)のテストが行えます。
また、JSONサーバへのテストとしてalexa developer consoleのJSONエディタからJSONを送信してテストが行えます。

また後述のSSMLのテストも行えます。

またLambdaのログ監視を以下の画面の"モニタリング"→"CloudWatchのログ表示"→"(任意のログストリーム)"より行えます。
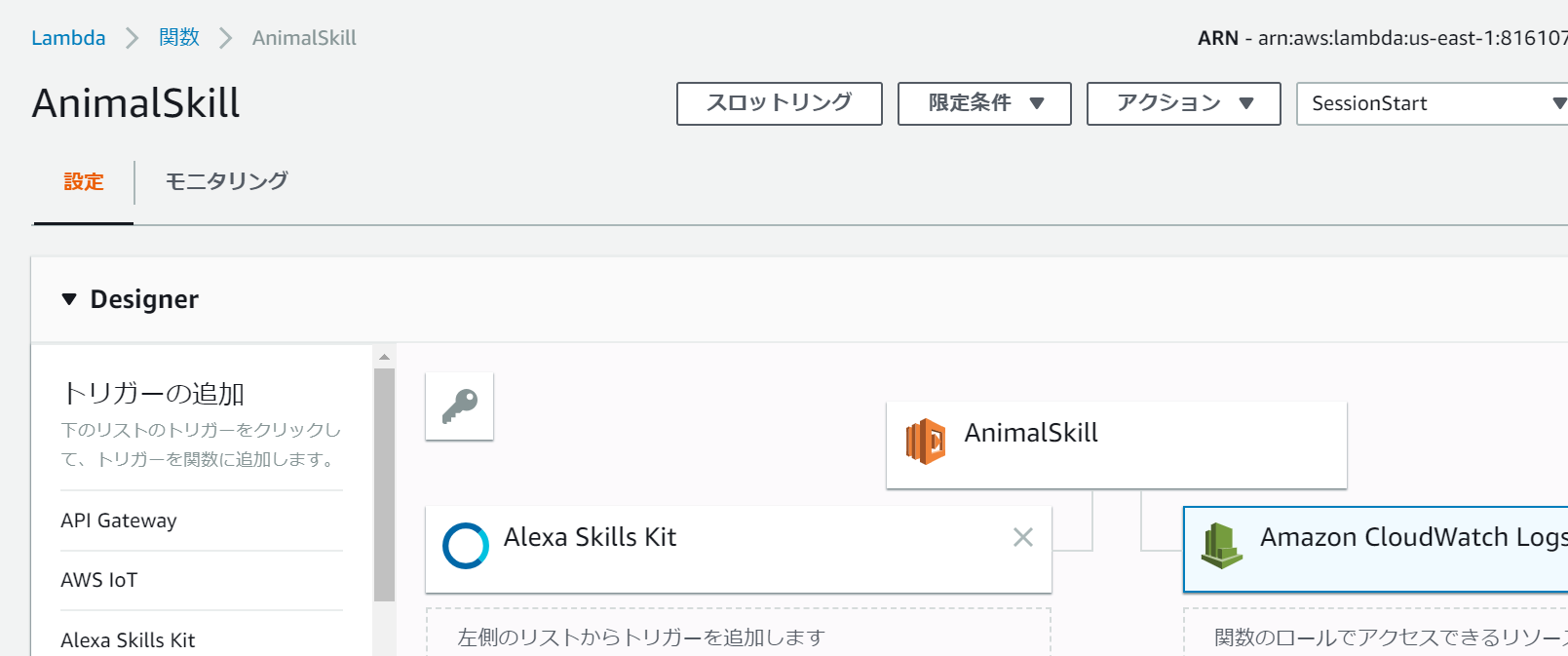

以上のようにLambda上のPythonのエラーやprint()したものの中身を見ることができます。
またLambdaの画面上部よりテストイベントが設定できます。(もちろんそれをテストできます)
デフォルトでAlexaのセッションスタート時のテストイベントが入ってたりしています。それをテストイベントとして設定をしておくとワンクリックでセッションスタート時のテストができてかなり便利です。

1.6. その後...
以上で解説は終了です。
これからAlexaのスキルを実際にストアにあげる(誰でも使えるインストールできるものにする)には以下の手順を踏む必要があります。
-
公開
コンソールの"公開"から公開申請を出す。

-
Amazonから認定をもらい、ストアに出る。
その他
APIを使ってみる
外部のAPIを使ってみるといろいろなことができます。
- #13 フロントエンド制作に華を! 面白いWebAPI 7選 - KAYAC engineers' blog
- 海外・国内の便利なAPI一覧 - API LIST 100+
- MA6 個人的におすすめのAPI・プラットフォーム(17個)を紹介します! | Mashup Award 6 (#MA6) on CREYLE
全体的なシステムは以下のようになります。

AlexaのUI/UX
Alexaはインプットが音声のみ(Spot,Showは除く)なので使いづらくなりがちです。
それを解決するためにAlexaのセリフのベストプラクティスが公式にあります。
Alexaのセリフについて | Amazon Alexa Voice Design Guide
たとえば以下のようなことも
一息テストでセリフの長さをチェックしよう
Alexaのセリフを書く場合、書いた内容を声に出して読み上げてみてください。普通に会話する速度で一息にそのセリフを読み上げることができたら、適切なセリフの長さと考えてよいでしょう。息継ぎが必要な場合はセリフを短くすることを検討してください。
Alexaスキル開発時には一読しといたほうがいいかもしれません。
Alexaの返答
Alexaの声色を変えたりすることができます。
音声合成マークアップ言語(SSML)のリファレンス | Custom Skills
SSMLというマークアップ言語でどのように発言すればいいか記述するとそのように発音してくれるようです。
例えば以下のようなSSMLを返すと"I am not a real human."の部分だけ囁いてくれます。
<speak>
I want to tell you a secret.
<amazon:effect name="whispered">I am not a real human.</amazon:effect>.
Can you believe it?
</speak>
またSSMLのaudioタグを使うと、音声を返すこともできます。
チャットボットの技術と初音ミクさんを組み合わせれば、初音ミクさんと会話ができるようなスキル開発が可能です。
<speak>
Welcome to Car-Fu.
<audio src="https://carfu.com/audio/carfu-welcome.mp3" />
You can order a ride, or request a fare estimate.
Which will it be?
</speak>
ただリファレンスにあるようにさまざまな制約があるので注意が必要です。
その他いろいろなタグがあります。
Alexaのプッシュ通知
「雨が降りそうになってきたら洗濯物をとりこんで!」といきなりAlexaからしゃべってくれたら便利ですよね。
そんなデバイスから能動的に通知が実装できたら開発の幅が広がっていいですよね!
結論から言うと基本的に実装できないです。
以下の記事の通りです。
通知の機能が日本語環境でも利用可能になりました : Alexa Blogs
通知の機能をあなたのスキルに実装したい場合
通知の機能を持ったスキルを開発するための開発環境は現在デベロッパー・プレビューとして一部の開発者のみに公開しています。ご興味のある方はデベロッパー・プレビューの申請フォームから登録を行ってください。申請フォームでは、どのようなユースケースを想定しているか、配信の頻度、配信しようと考えているメッセージの例についてお伺いします。申請内容のレビュー後、一部の開発者の方には、さらに詳しい情報が提供されます。
なので、申請をして通ると使えるようになるようです。
以下のスキルがプッシュ通知の機能があるようです。(2018年2月26日現在)
JR東日本 列車運行情報案内
登録している路線の運行情報に遅れが発生または見込まれる場合に、通知でお知らせします。
Yahoo!天気・災害
デバイスに登録している所在地に雨や雪の予報がある日は、朝7時ごろ通知でお知らせします。
japan taxi
全国タクシー
配車が確定した時に通知でお知らせします。
AlexaとIFTTT
IFTTTを使えば簡単なAlexaスキル(?)が作れちゃったりします。
IFTTTはさまざまなウェブサービスをつなげるサービスです。
例えばAlexaに「~」と話しかけたら、「???」とつぶやくみたいなことがウェブ上でできちゃいます。
簡単なサービスが(ほしい|つくりたい)だけならIFTTTを使うのをおすすめします
IFTTTはAが起きたらBをするを設定することができます。
AとBには既存のさまざまなウェブサービス(Facebook, Twitter, Instagram, LINE等の200以上のサービス)のイベントをとることができます。以下で使えるサービス一覧が公開されています。
例えば、AをWebhooksにしてBを任意のウェブサービスにするとWEB APIっぽいものがつくれます。
アカウント連携が必要なものも簡単に使えるので、個人使用で使うならおすすめです。