
↑今回使う教師データ
概要
- Google Colabを使うとGPUを無料で使えて,TensorFlowとかを使うのも超簡単!
- pix2pix使って遊んでみようぜ
っていうお話
前提知識
- ある程度Pythonがわかる
→深層学習等の知識はほぼ0でできます
Google Colabとは

別名は「Google Colaboratory」
Google Colabのチュートリアルページでの解説は以下の通り。
チュートリアルページ→Hello, Colaboratory - Colaboratory

箇条書きでまとめると
- Google Drive内でプログラムがかける
- プログラムはJupyterノートブックっぽくも書ける
- ブラウザ上で機械学習の開発環境を使える
- GPUが無料でつかえる(ただし連続使用12時間,マイニング等は禁止)()
- Jupyterノートブックでなく,いわゆる普通の***.pyのようなプログラムも実行できる
- UNIXコマンドが一部使える(
pip等も使えます) - Google Drive内部のファイルの読み書きがプログラム上でできる(要準備)
その他いろいろあるのでチュートリアルページ下部の詳細情報を見てみることをお勧めします。
チュートリアルページ→Hello, Colaboratory - Colaboratory
0. pix2pixで遊んでみよう!
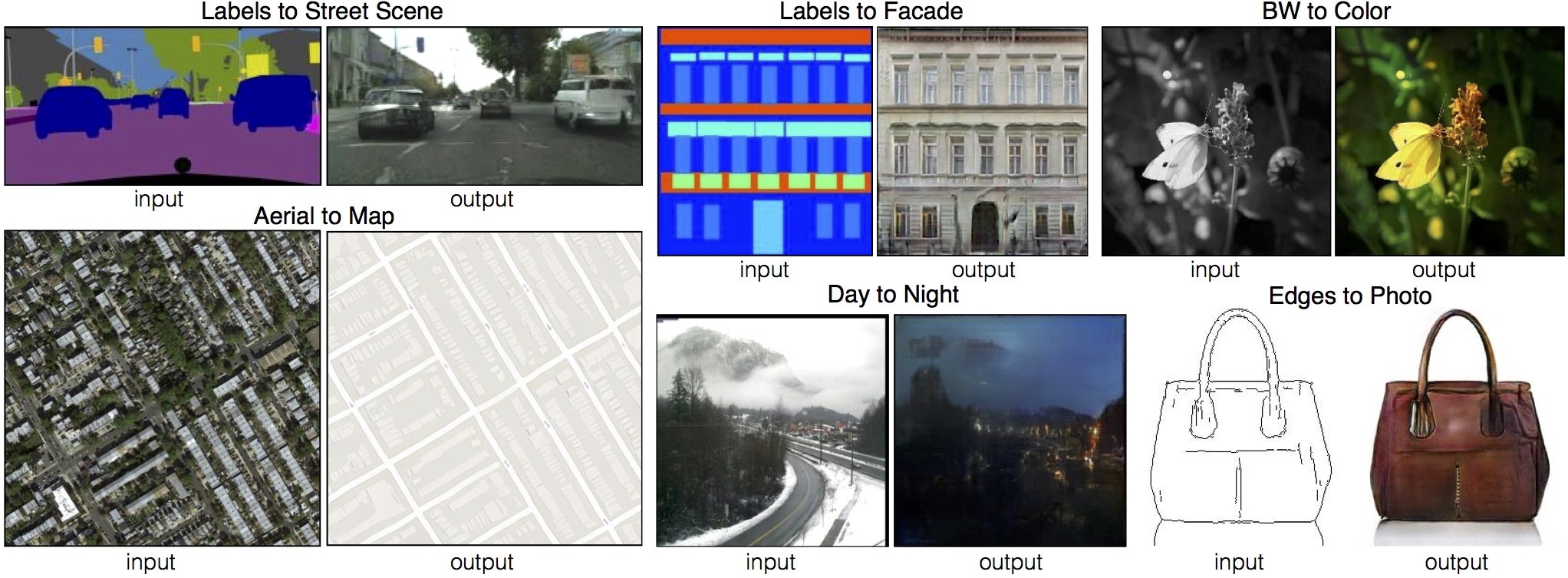
pix2pixとはある画像を入れたらこういう画像に変えるというのを学習してくれる深層学習モデル
例えば、
- 白黒画像を入れたらそれを色を付けた画像変える(BW to Color)
- 線画を書いたらその線画に合わせて色を塗った画像に変える(Edges to Photo)
- どこが屋根とか窓とかを色で塗った画像から実際の建物の表面の画像に変える(Labels to Facade)
他には
「中央を白く切り抜いた画像から切り抜かれた部分を推測して描画した画像に変える」こともできます。

などなどめっちゃ汎用性が高いです。
そんな面白いプログラムを実際に教師データを変えてあげて遊んでみようという話です。
1. 教師データの準備
教師データの仕様
このプログラムの仕様として、教師データとして2枚の正方形画像を横につなげて1枚にした画像を大量に用意する必要があります。2枚の正方形画像はそれぞれこの画像をこんな風に変えてほしい画像です。
例えばこんな感じです。

この画像を例えば以下のようにA,Bとした場合

「中央を白く切り抜いた画像から切り抜かれた部分を推測して描画した画像に変える」モデルを作成するときには「Bの画像をAの画像のようにする」と学習させてあげればいいわけです。
教師データの作成
今回は「眼を切り抜いた画像」から「眼を切り抜く前の画像」に変えてくれるモデルをつくりたいと思います。
そのため画像は「眼を切り抜いた画像」と「眼を切り抜く前の画像」を用意してあげる必要があります。
今回は大量の顔画像に「Labeled Faces in the Wild」のデータセットを使いました。
↑のページの"All images as gzipped tar file"のファイル
そしてOpenCVを用いて顔認識,眼認識をしてあげて自動的に教師データを作成してあげました。
import numpy as np
import cv2
import os
# https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# https://github.com/Itseez/opencv/blob/master/data/haarcascades/haarcascade_eye.xml
eye_cascade = cv2.CascadeClassifier('haarcascade_eye.xml')
TARGET_DIR = "./lfw"
OUTPUT_DIR = "./output"
def create_ab(input_path, output_path):
img = cv2.imread(input_path)
org_img = img.copy()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
if(len(faces) != 1):
return
for (x,y,w,h) in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
if(len(eyes) != 2):
return
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color, (ex, ey), (ex+ew, ey+eh), (255, 255, 255), -1)
out_img = cv2.hconcat([img, org_img])
cv2.imwrite(output_path, out_img)
def main():
for name_dir in os.listdir(TARGET_DIR):
for file_name in os.listdir(os.path.join(TARGET_DIR, name_dir)):
input_image_path = os.path.join(
os.path.join(TARGET_DIR, name_dir),
file_name)
output_image_path = os.path.join(OUTPUT_DIR, file_name)
print(file_name)
create_ab(input_image_path, output_image_path)
if __name__ == "__main__":
main()
実際に作成した教師データは以下の通り。

用意できた教師データは6000枚ぐらい。(顔認識しなかった画像,眼を2個より多く検出したものなどをはじいているため顔画像の数より少ないです)
※眼認識がうまくいっていないものも混じっています。
2. Google Driveに入れる
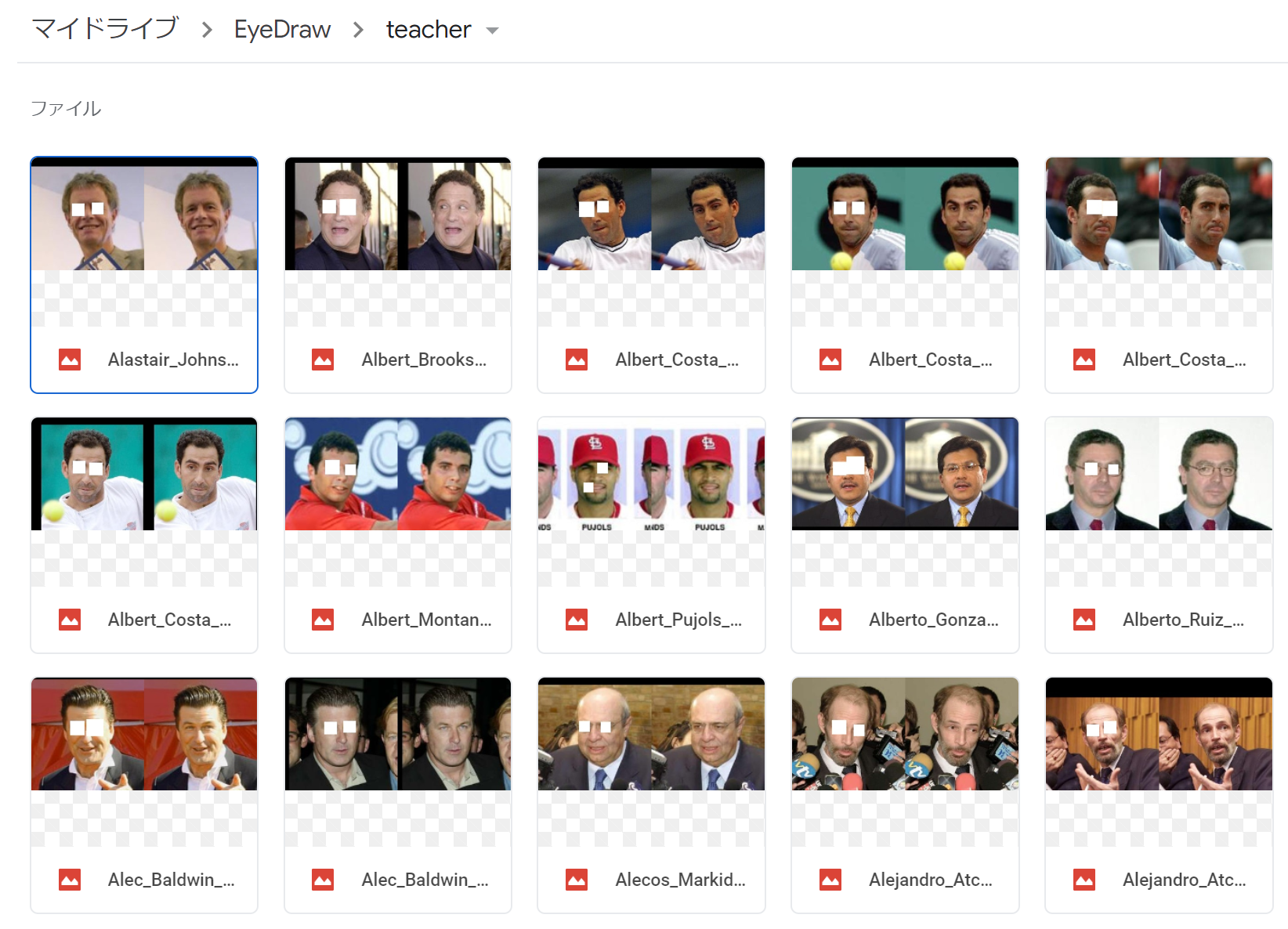
Google Driveに先ほど作成した教師データを入れてあげます。(学習時間的にとりあえず400枚だけ)
Google Driveの直下に作業フォルダ(EyeDrive)を作ってあげてその中に教師データを格納するteacherフォルダを作ってあげました。
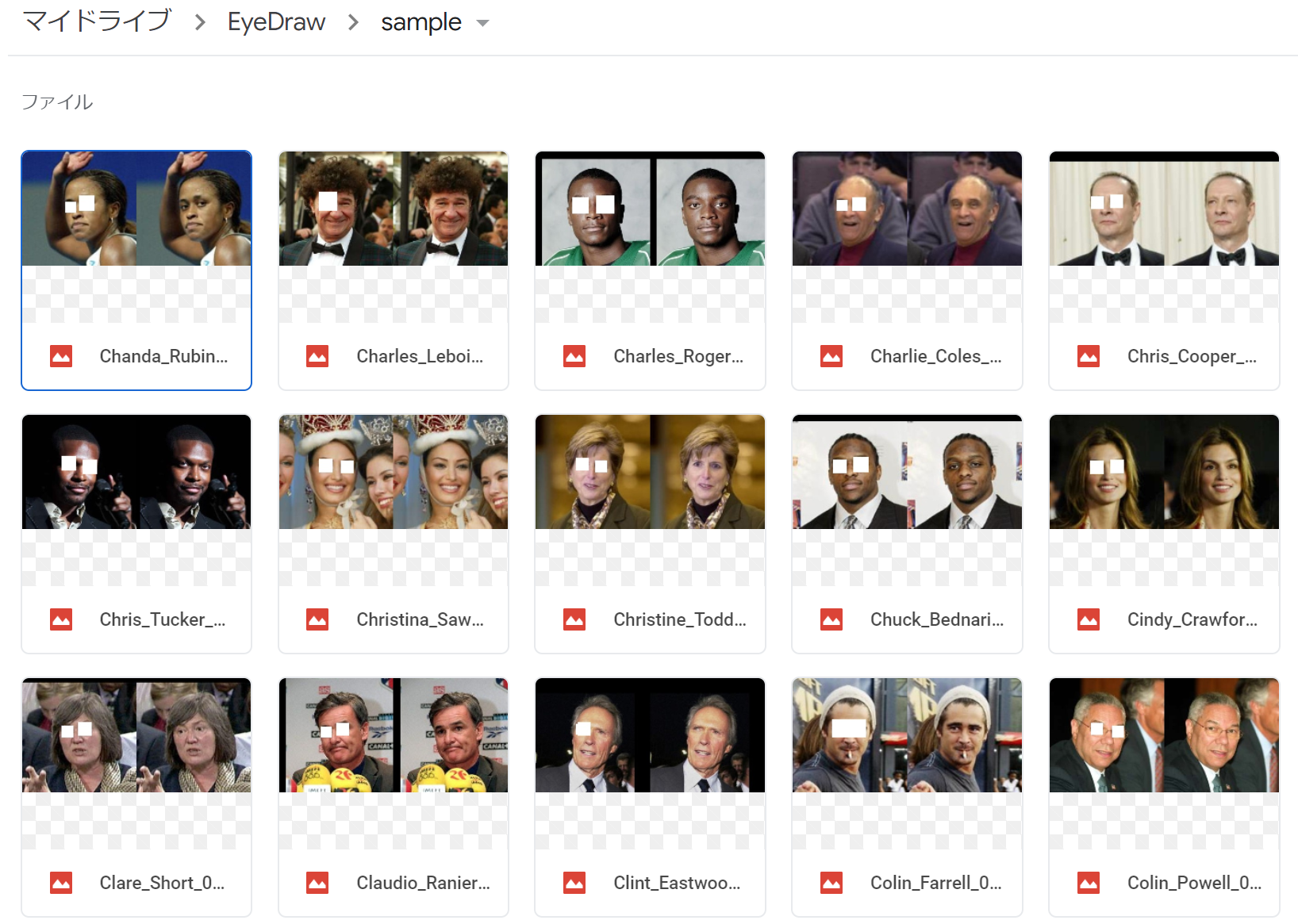
同様にマイドライブ/EyeDrive/sample内に100枚の検証用データをいれてあげます。(この100枚は教師データにないものを使います)
3. Google Driveにプログラムを入れてあげる
affinelayer/pix2pix-tensorflow: Tensorflow port of Image-to-Image Translation with Conditional Adversarial Nets https://phillipi.github.io/pix2pix/をcloneするなりダウンロードするなりして、pix2pix.pyを自分のDriveの中にいれてあげます。
他のファイルは今回は必要ありません。
また学習結果を保存するtrainフォルダ,検証結果を保存するresultフォルダも作成しましょう。
また、プログラム実行するために実行環境.ipynbを作ってあげました。
(フォルダ内右クリック→その他→アプリを追加→Google Colab→再びフォルダ内右クリック→その他→Google Colabで.ipynbファイルを作成できます。)
最終的に作業フォルダ内は以下のようになります。
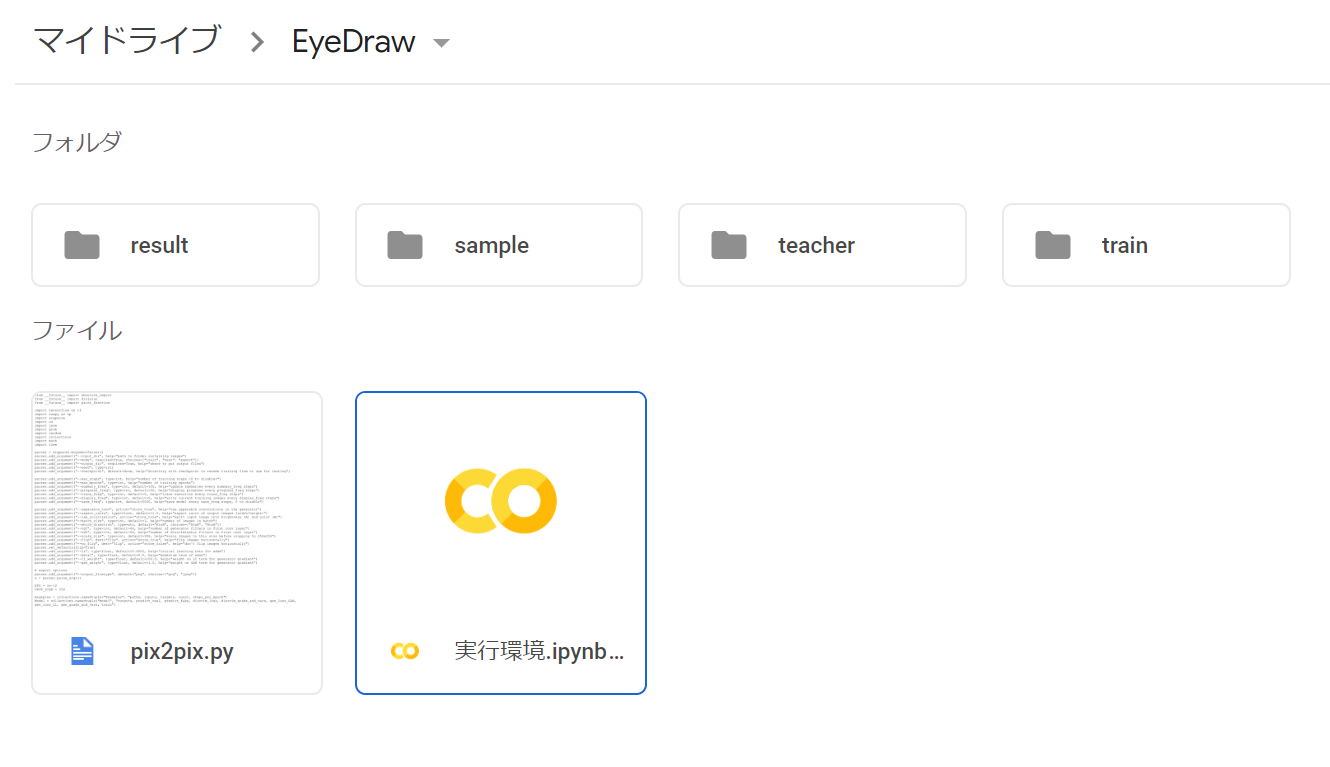
4. Google Driveの中身をプログラムが見れるようにしてあげる
実行環境.ipynbを開いてあげます。
このノートブック内ではPythonのコードを記述して実行したりUNIXコマンドを実行できたりします。
しかし,設定をしないとプログラム上でドライブのフォルダ内を読み込んでくれません。
そこで以下のQiitaの良記事を参考にしてドライブをマウントするように設定してあげます。(driveをディレクトリとしてマウントするの章)
google Colaboratoryでファイルを読み込む方法 - Qiita
まんまコピペして,左の再生ボタンをクリックしてよしなにします。
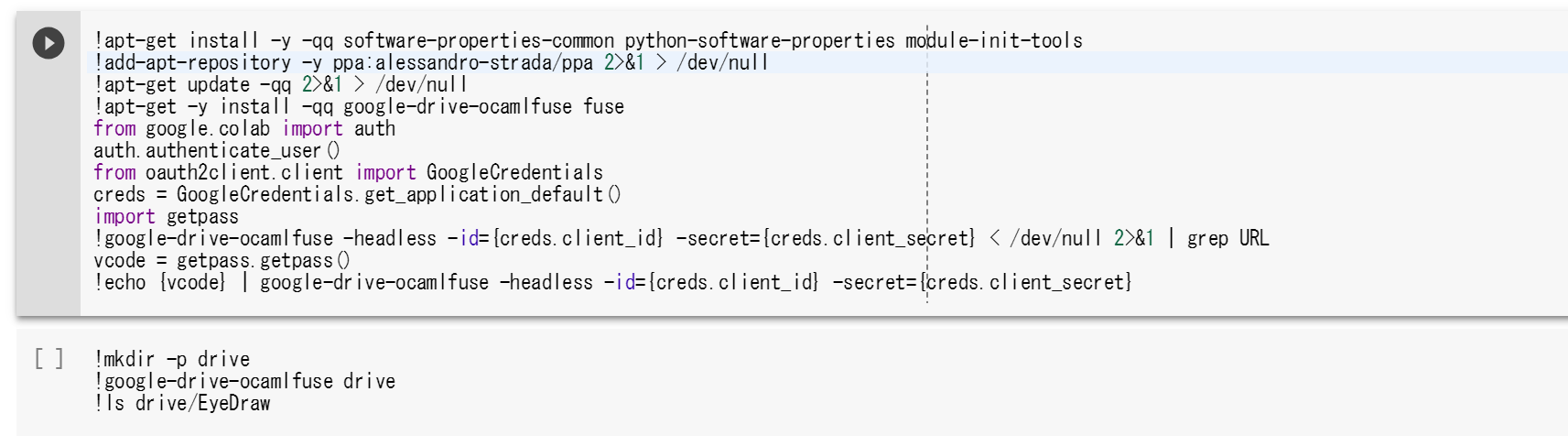
5. pix2pixを実行してみる
これでいつものようにpython ***.pyとしてあげればいいのですが,その前に一点設定が必要です。
ノートブックの編集画面の"編集"→"ノートブックの設定"から,GPUを使用するように設定してあげる必要があります。
(無くても動くはずですが,めちゃくちゃ遅いです)
(GPUを連続で使用すると一時的に使えなくなります)
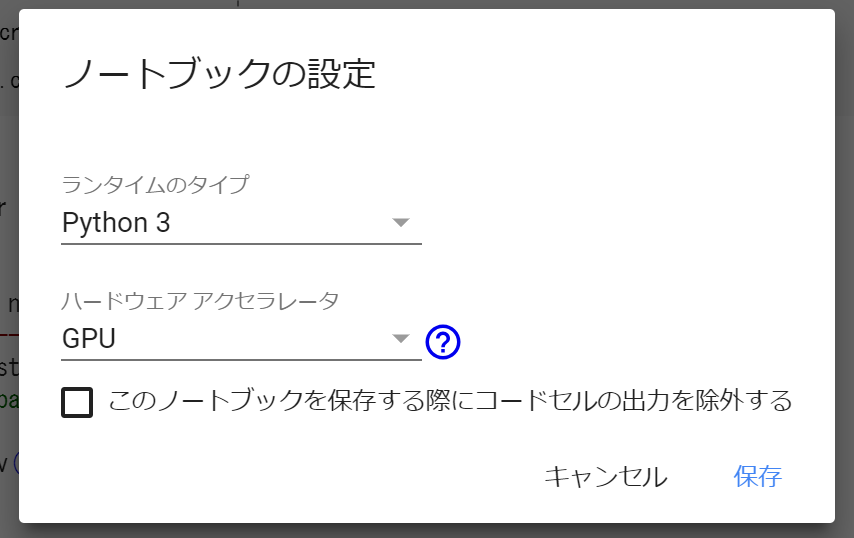
そしてノートブック上でコマンドを実行してあげます。
(ノートブック上でコマンドを実行するには最初に!をつける必要があります)
学習
!python3 drive/EyeDraw/pix2pix.py --mode train --output_dir drive/EyeDraw/train --max_epochs 200 --input_dir drive/EyeDraw/teacher --which_direction AtoB
検証
!python3 drive/EyeDraw/pix2pix.py --mode test --output_dir drive/EyeDraw/result --input_dir drive/EyeDraw/sample --checkpoint drive/EyeDraw/train
6. 結果
精度がすごい良いってわけではないですが,とりあえず400枚の教師データだけを用いたことを考えればまずまずなんじゃないでしょうか。
(左から入力画像, 出力画像, 正解画像)
遠くからみたらまずまずなやつ



全然ダメなやつ

黒い

四角が目立つ

怖い
全部

まとめ
"Google Colabを使うと無料で深層学習のリポジトリ試せる"という話でした。
データ数を増やしたり,顔の向きが同じやつだけで学習させればもっと精度はあがるんじゃないでしょうか?
pix2pixはまだまだ応用例があると思うので,この際なのでなにかデータセットつくってみて遊んでみるというのはどうでしょう?
宣伝
フォローするとこんな感じのクソ記事にすぐリーチできる!
@redshoga