ChatGPT や Claude を毎日使っていると、地味に増えていくものがあります。
text noise です。
例えば:
- 壊れた bullet
- duplicated line
- invisible char
- weird spacing
- PDF コピペ由来の崩れ
- 微妙に壊れた Markdown
内容自体は正しいのに、そのまま貼るには微妙につらい。
最初は普通に ChatGPT に:
「内容は変えずに整形だけしてください」
と頼んでいました。
でも、これが結構 unstable でした。
- 昨日と今日で結果が違う
- 句読点が変わる
- たまに勝手に要約する
- bullet 構造まで変わる
もちろん LLM が悪いというより、あれは「生成」の道具なので、そもそも用途が違うんですよね。
欲しかったのは:
input X
→ output Y
が毎回固定されること。
つまり:
deterministic
な post-processing でした。
そこで作ったのが kiln
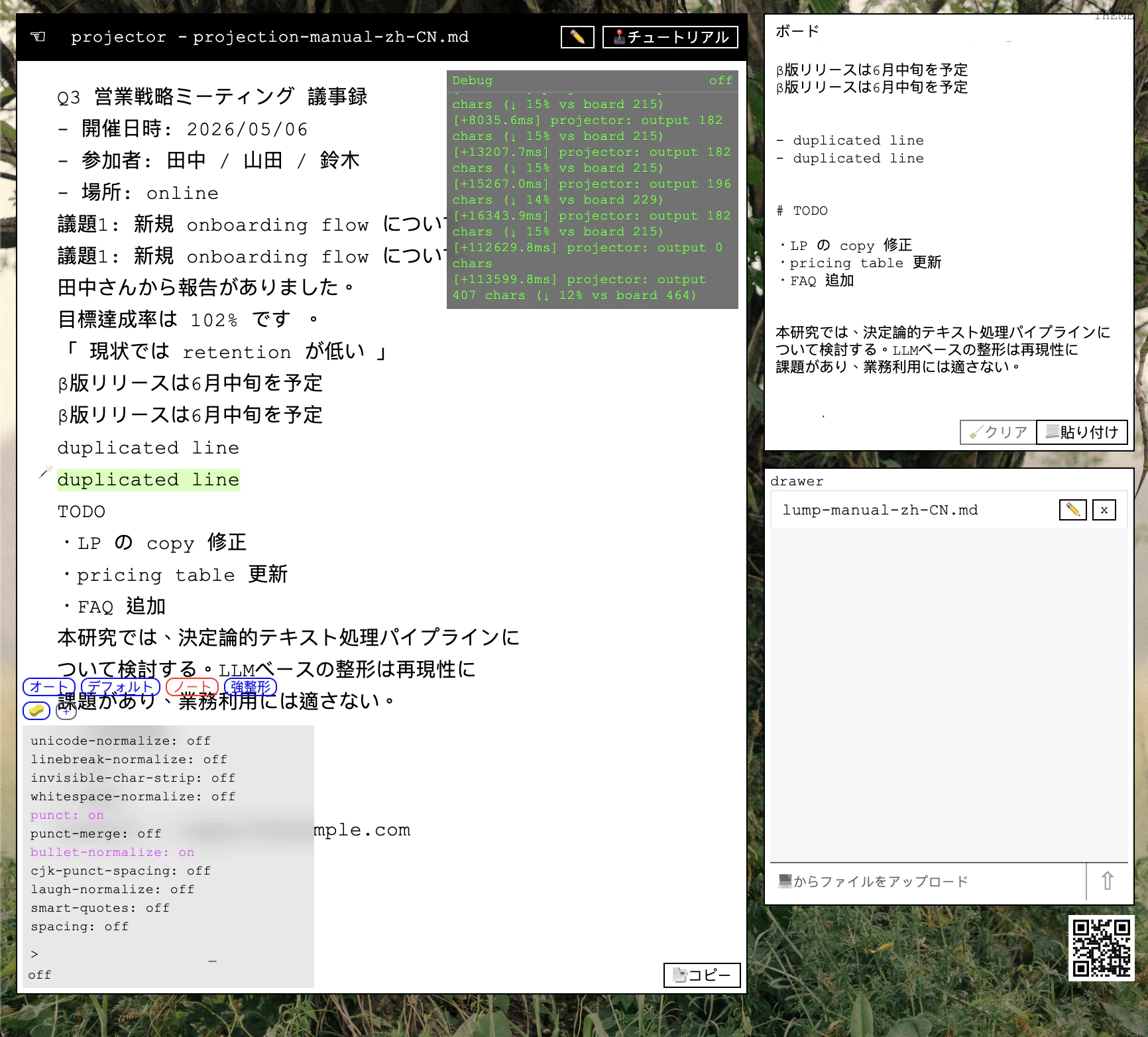
ブラウザだけで動く text-cleanup pipeline です。
内部はかなり単純で、
input
→ parse
→ normalize
→ transform
→ render
→ output
という、小さい module の直列 pipeline になっています。
TeX、Unix pipe、sed / awk、compiler pass pipeline あたりの影響がかなり強いです。
例えば:
unicode-normalizebullet-normalizespacingdedupedropempty
みたいな module が順番に text を変換していく。
AI 的な「いい感じに整形する」というより、
small deterministic transforms
を積み上げる方向です。
observable pipeline
kiln でちょっと気に入っているのが、pipeline trace を console に全部出しているところです。
例えば:
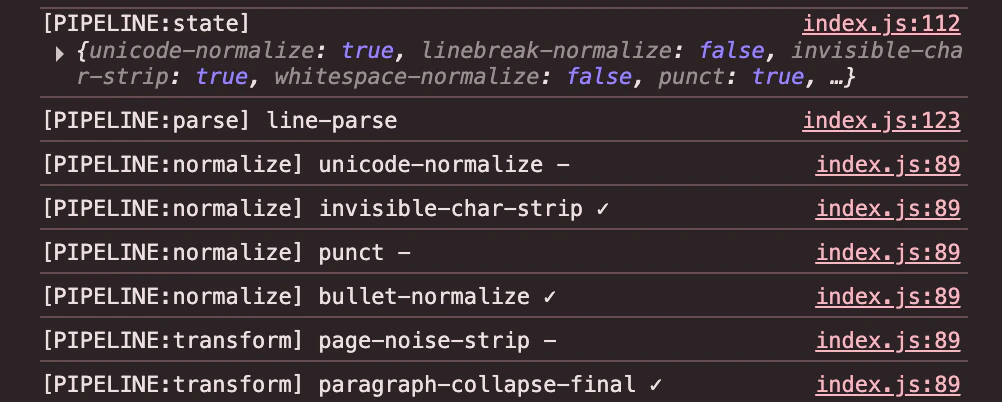
✓
→ 実際に text を変更した
-
→ module は走ったが変更はなかった
という意味です。
最初は debug 用だったんですが、使っているうちに:
「どの transform が何をやったか見える」
のがかなり重要だと気付きました。
例えば:
-
dedupe ✓
→ 重複検出は走ってる -
dedupe -
→ module は動いたが比較条件に引っかからなかった -
module 自体が出てない
→ preset / state 側の問題
みたいに、問題位置を trace から追える。
この辺は compiler pass trace や ffmpeg filter chain にかなり近い感覚があります。
実際に流している text
今の kiln では、こういうかなり雑な text をそのまま投入しています。
- • ripgrep
• - jq
* • sed
- duplicated line
- duplicated line
目標達成率は 102% です 。
「 こんにちは 」
# Q3 営業戦略会議 議事録
* 参加者: 田中・山田・鈴木
- 議題1: 売上目標について
- 議題1: 売上目標について
田中さんから報告がありました。
β版リリースは6月中旬を予定
β版リリースは6月中旬を予定
clean preset を通すと:
- ripgrep
- jq
- sed
duplicated line
目標達成率は 102% です。
「こんにちは」
Q3 営業戦略会議 議事録
参加者: 田中・山田・鈴木
議題1: 売上目標について
田中さんから報告がありました。
β版リリースは6月中旬を予定
みたいな形になります。
やっていること自体は地味です。
- duplicated line を潰す
- bullet 記号を統一
- invisible char を除去
- weird spacing cleanup
- CJK punctuation 周りを normalize
ただ、この「地味な崩れ」、LLM を毎日触っていると本当に永遠に発生します。
normalize と transform を分けている
kiln の内部でかなり意識しているのが、
normalize
≠
transform
を分離することです。
例えば:
normalize
- spacing
- unicode normalization
- invisible-char cleanup
- punctuation cleanup
みたいな、
non-semantic cleanup
層。
transform
- dedupe
- regroup
- paragraph collapse
- limit
みたいな、
structure rewrite
層。
これを混ぜると module の責務が崩れやすいので、かなり分けています。
「賢い」より「決定論的」
LLM 系 tool と kiln の一番大きな違いは、多分ここです。
| LLM wrapper | kiln | |
|---|---|---|
| 出力 | stochastic | deterministic |
| 内部 | opaque | observable |
| debugging | prompt 調整 | pipeline trace |
| transform | heuristic | explicit ops |
kiln は:
predictability > intelligence
寄りです。
同じ入力なら毎回同じ結果が返ってきて、
しかも「どの module が text を変えたか」が見える。
地味なんですが、業務の “配管” 層って、結局このくらい deterministic なほうが扱いやすいんですよね。
UI も pipeline として設計している
ちなみに UI もかなり pipeline 的です。
- drawer
- board
- projector
を分けています。
- drawer → source
- board → working text
- projector → transformed output
みたいな役割。
単なる UI 分割というより、
execution surface
として設計しています。
まとめ
最初は単純に:
ChatGPT の出力がちょっと汚い
というところから始まりました。
でも作っているうちに、
observable deterministic text pipeline
みたいな方向にどんどん寄っていきました。
今でもやっていること自体はかなり地味です。
- weird spacing
- duplicated line
- bullet sludge
- invisible char cleanup
ただ、LLM 時代の text workflow だと、この辺の “配管” が毎日発生する。
なので今は、
LLM に生成させる
↓
deterministic pipeline で post-process する
という分離がかなりしっくり来ています。
🔥 kiln
https://kiln.ooo/
kiln.rec.ooo by Rec Dungeons
ブラウザだけで動きます。
PDF / DOCX / HTML / EPUB もそのまま投入できます。
現在、kiln の boundary testing 用に weird text corpus を収集中です。
broken bullet / invisible char / PDF collapse / Unicode horror など歓迎です 😭