はじめに
こんにちは佐藤です。
機械学習プロジェクトではプロトタイプを作成して他の人に使ってもらい FB を得たいケースがあると思います。
普段、データ分析やモデル開発に marimo を使用しているのですが WebAssembly Notebooks という機能を使うとノートブックを Web アプリのようにブラウザ上で動かすことができます。
今回はこの機能を使用して CPU で稼働するベクトル検索のプロトタイプを作ってみようと思います。
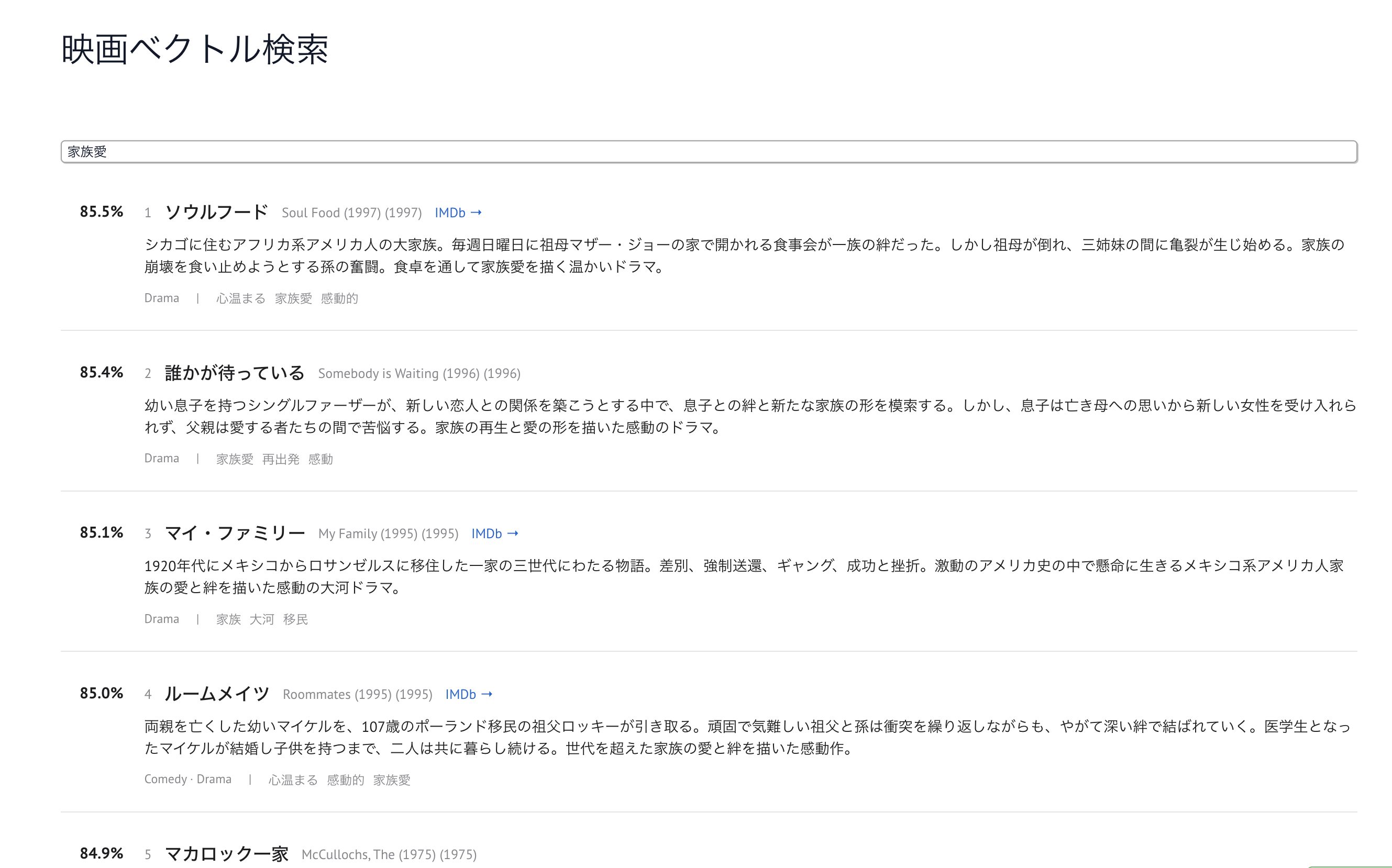
最終的に完成したアプリは以下のリンクから使用可能です。
*初回起動時のみモデルのロードに30秒ほど時間がかかります。
1. データ準備
データがないので、映画データセットである MovieLens からデータをダウンロードして映画のタイトルやジャンルなどを確認します。
▼ イメージ
MovieID::Title (Year)::Genres
1::Toy Story (1995)::Animation|Children's|Comedy
タイトルは取得できたものの検索に必要なメタデータがないので、上記の映画タイトルから LLM で日本語メタデータを生成します。5000件以内に作品を絞ってローカルの Claude Code を使って以下の形式の json を作品数分作成します。
▼ イメージ
{
"id": 1,
"title": "Toy Story (1995)",
"title_ja": "トイ・ストーリー",
"year": 1995,
"genres": ["Animation", "Children's", "Comedy"],
"synopsis_ja": "おもちゃのカウボーイ、ウッディは少年アンディの一番のお気に入り。しかしある日、最新のおもちゃバズ・ライトイヤーがやってきて...",
"mood_tags": ["感動", "友情", "冒険", "コメディ", "家族向け"],
"description": "ピクサー初の長編CGアニメーション。おもちゃたちの視点から描かれる友情と成長の物語。"
}
2. ベクトルの生成
ベクトル検索を行うために、1 で作成した自然言語からベクトルを生成します。
ベクトル検索では、「事前に生成したベクトル」と「ブラウザ上でユーザーが入力したクエリから生成されたベクトル」の類似度計算を行う必要があります。
事前のベクトル生成に CPU でも高速動作する intfloat/multilingual-e5-small を使用します。
一方でブラウザ環境では PyTorch は動作しないため transformers.js を使用します。
transformers.js は ONNX Runtime Web 上で Transformer モデルを実行するライブラリでブラウザ上の推論が可能です。
最終的にブラウザ環境では intfloat/multilingual-e5-small を ONNX 形式に変換した Xenova/multilingual-e5-small を使用します。
事前計算(PyTorch)と検索時(ONNX/quantized)でモデル形式が異なるため、厳密には出力が微妙に異なる可能性があります。
▼ イメージ
from transformers import AutoTokenizer, AutoModel
model_name = "intfloat/multilingual-e5-small"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
def create_search_text(movie):
title_ja = movie.get('title_ja', movie['title'])
synopsis = movie.get('synopsis_ja', '')
tags = ' '.join(movie.get('mood_tags', []))
description = movie.get('description', '')
return f"query: {title_ja} {synopsis} {tags} {description}"
# mean pooling + L2 正規化
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
3. marimo WebAssembly Notebooks
次に上記で作成したベクトルを使用して marimo notebook を作成し、WebAssembly にエクスポートする準備を行います。
▼ イメージ
import marimo as mo
import micropip
await micropip.install("numpy")
import numpy as np
from pyodide.http import pyfetch
from transformers_js_py import import_transformers_js
# モデル読み込み(初回は30秒ほど)
transformers = await import_transformers_js()
extractor = await transformers.pipeline(
"feature-extraction",
"Xenova/multilingual-e5-small",
{"dtype": "q8"} # 量子化で軽量化
)
# 検索
query = f"query: {search_input.value}"
output = await extractor(query, {"pooling": "mean", "normalize": True})
query_embedding = np.array(output.tolist()[0], dtype=np.float32)
# コサイン類似度(正規化済みなので行列積で OK)
similarities = embeddings @ query_embedding
top_indices = np.argsort(similarities)[::-1][:10]
marimo コード
import marimo
__generated_with = "0.18.4"
app = marimo.App(width="full")
@app.cell
def _():
import marimo as mo
return (mo,)
@app.cell
def _(mo):
mo.md("# 映画ベクトル検索\n<br>")
return
@app.cell
async def _():
import json
import micropip
await micropip.install("numpy")
import numpy as np
return (np,)
@app.cell
async def _(mo, np):
from pyodide.http import pyfetch
base_url = str(mo.notebook_location()).rstrip("/")
movies_response = await pyfetch(f"{base_url}/public/movies_enriched.json")
movies = await movies_response.json()
embeddings_response = await pyfetch(f"{base_url}/public/embeddings.json")
embeddings_data = await embeddings_response.json()
embeddings = np.array(embeddings_data, dtype=np.float32)
return embeddings, movies
@app.cell
async def _(mo):
with mo.status.spinner("モデルを読み込み中...<br>初回は30秒程度かかります"):
from transformers_js_py import import_transformers_js
transformers = await import_transformers_js()
pipeline = transformers.pipeline
extractor = await pipeline(
"feature-extraction",
"Xenova/multilingual-e5-small",
{"dtype": "q8"}
)
return (extractor,)
@app.cell
def _(mo):
search_input = mo.ui.text(
value="",
placeholder="家族で楽しむ冒険映画",
full_width=True,
debounce=200
)
search_input
return (search_input,)
@app.cell
async def _(embeddings, extractor, mo, movies, np, search_input):
mo.stop(not search_input.value)
query = f"query: {search_input.value}"
output = await extractor(query, {"pooling": "mean", "normalize": True})
query_embedding = np.array(output.tolist()[0], dtype=np.float32)
similarities = embeddings @ query_embedding
top_indices = np.argsort(similarities)[::-1][:30]
results = [
{**movies[i], "score": float(similarities[i])}
for i in top_indices
]
return (results,)
@app.cell
def _(mo, results):
def render_movie_card(movie, rank):
tags = movie.get("mood_tags", [])
genres = movie.get("genres", [])
title_ja = movie.get('title_ja', movie['title'])
year = movie.get('year', '')
score = movie['score']
imdb_id = movie.get('imdb_id', '')
imdb_url = f"https://www.imdb.com/title/tt{imdb_id}/" if imdb_id else ""
tag_badges = "".join([
f'<span style="color:#86868b;font-size:12px;margin-right:8px;">{t}</span>'
for t in tags[:3]
])
genre_text = " · ".join(genres[:3])
imdb_link = f'<a href="{imdb_url}" target="_blank" style="color:#06c;font-size:13px;text-decoration:none;">IMDb →</a>' if imdb_url else ""
return mo.Html(f'''
<div style="
background:#fff;
padding:20px 0;
border-bottom:1px solid #e5e5e5;
">
<div style="display:flex;align-items:flex-start;gap:20px;">
<div style="min-width:60px;text-align:right;">
<span style="font-size:15px;font-weight:600;color:#1d1d1f;">{score:.1%}</span>
</div>
<div style="flex:1;">
<div style="display:flex;align-items:center;gap:12px;margin-bottom:8px;">
<span style="color:#86868b;font-size:13px;font-weight:500;">{rank + 1}</span>
<h3 style="margin:0;font-size:17px;font-weight:600;color:#1d1d1f;">{title_ja}</h3>
<span style="color:#86868b;font-size:13px;">{movie['title']} ({year})</span>
{imdb_link}
</div>
<p style="font-size:14px;color:#1d1d1f;line-height:1.5;margin:0 0 8px 0;">{movie.get('synopsis_ja', '')}</p>
<div style="display:flex;align-items:center;gap:16px;">
<span style="color:#86868b;font-size:12px;">{genre_text}</span>
<span style="color:#86868b;font-size:12px;">|</span>
<div>{tag_badges}</div>
</div>
</div>
</div>
</div>
''')
mo.stop(not results)
mo.vstack([render_movie_card(r, i) for i, r in enumerate(results)])
return
if __name__ == "__main__":
app.run()
- transformers.js のラッパーである transformers_js_py を使用します
- pip が使えないので
micropipで numpy をインストールします - json を HTTP で取得するために
pyodide.http.pyfetchを使用します
4. アプリとして公開
marimo の WASM エクスポートを使って Cloudflare Pages にデプロイします。
uv run marimo export html-wasm movie_search_wasm.py -o dist/ --mode run
公開したアプリのリンクは以下です。
*初回起動時のみモデルのロードに30秒ほど時間がかかります。
おわりに
今回は marimo でベクトル検索アプリを作成しました。着手開始から約4時間でプロトタイプを公開できました。今回のユースケースに限らずプロトタイプをサクッと作りたい場面では marimo WebAssembly Notebooks を使ってみると良いかもしれません。最後まで読んで頂きありがとうございました。