E2E RLの可能性とメリット
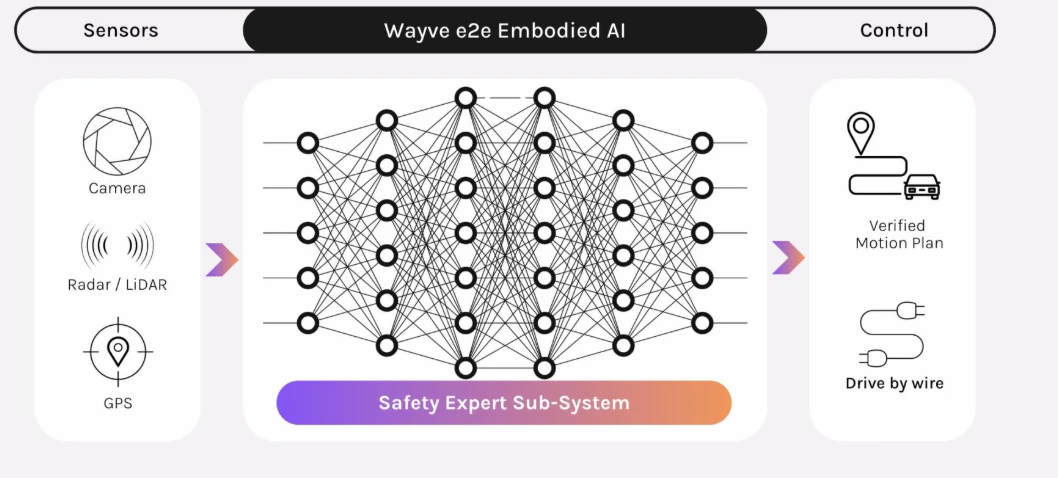
- 非定型環境での柔軟性: 精緻な数学的モデリングが困難な複雑な接触(Contact-rich)作業や非定型オブジェクトを扱う際、データ自体が最適な経路を見つけ出す能力に優れています。
- エンジニアリングパイプラインの簡素化: 認知(Perception)、計画(Planning)、制御(Control)へと続く従来のモジュール型構造で生じる累積誤差(Error Propagation)の問題を理論的に克服できます。
- 創発的行動(Emergent Behavior):人間のエンジニアが予想できなかった効率的で変則的な動きを自ら学習し、性能の限界を突破することもあります。
しかし、実際の物理世界(Physical World)では、E2E RLは非常に難しく、時には危険です。

単なる性能の問題を超え、純粋なE2E方式が現場で直面する厳しい限界は以下の通りです。
- モーションプランニングレベルでのRLが持つリスク(Risks at the Motion Planning Level)特にモーションプランニングレベルまでRLで実行する場合、問題はさらに複雑になります。幾何学的制約や衝突回避に関する明確なガイドラインなしでニューラルネットワークの判断のみに依存すると、ロボットの動作は予測不可能となり、これはハードウェアの致命的な故障や破損に直結します。
- ハードウェア破損リスク:学習過程や初期推論段階で発生する予測不可能な動作は、ロボットの関節可動範囲を逸脱させたり、機械的過負荷を引き起こします。これは数億円規模に達するハードウェアの致命的故障につながる可能性があります。
- ブラックボックスの不透明性:ロボットが「なぜ」危険な動作を行ったのかを論理的に説明したり、事後分析できない場合、実際の産業現場での信頼性を保証することは困難です。
- 安全制約(Safety Constraints)の不在:ニューラルネットワークの出力値だけで物理的なすべての安全制約を100%制御することはほぼ不可能です。
現在の標準的アプローチ:IL to RL
これらのリスクを克服するため、現在のロボティクス現場では「Imitation Learning(IL)による初期学習の後にRLへ移行する」手法が標準となっています。
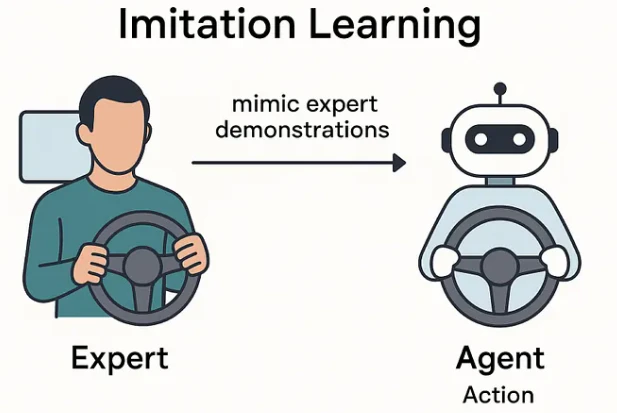
- 専門家のデータを用いて安全な基本動作をまず学習(Warm-start)し、
- その上でRLを通じて性能を微調整(Fine-tuning)することで、ハードウェアの安定性を確保しつつ、AIの最適化能力を活用する方式です。
- しかし、モーションプランニングレベルでのリスクは依然として存在します。
解決策:ハイブリッドRL(The Solution: Hybrid RL)
既存のルールベース(Rule-based)システムと学習ベース(Learning-based)を組み合わせた「Hybrid RL」を検討することが、最も妥当であると判断します。
- ルールベース:物理的な安全制約とハードウェアの限界値を厳密に制御(Safety & Constraints)
- 学習ベース:複雑な環境に対応する柔軟な最適化を実行(Adaptability & Optimization)
Physical AIの真の革新は、華やかなモデルそのものではなく、ハードウェアを保護しながら性能を極大化できる「堅牢なシステムアーキテクチャ」にあります。
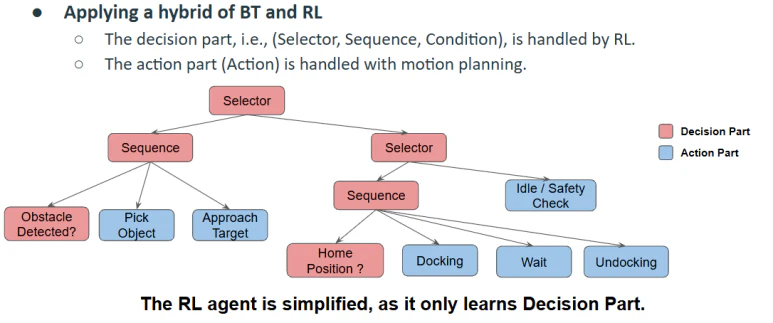
-
意思決定の知能化 (High-level: RL):
既存のBehavior Tree (BT) における Selector や Sequence が担っていた複雑な状況判断および戦略策定の領域に、強化学習 (RL) を適用します。これにより、非定型な環境下においても柔軟かつ最適化された意思決定が可能となります。 -
実行の安定性確保 (Low-level: Rule-based):
実際のロボットの動きを生成するモーションプランニングの段階では、従来のルールベース (Rule-based) 方式を維持します。学習ベース制御特有の「不確実性 (Uncertainty)」を排除することで、ハードウェアの破損を防止し、予測可能な動作を保証します。 -
結論および期待効果:
モーションプランニング・レベルを直接学習によって制御することは、非効率であるだけでなくリスクも非常に大きいです。したがって、「RL(戦略策定)+ ルールベース(動作遂行)」のハイブリッド構造を通じて、AIの柔軟性と伝統的な制御の堅牢性を両立させることが、現時点で最も妥当なソリューションであると考えます。
Contact & Discussion
- もし、この「ハイブリッドRL」の具体的な実装方法や、システムアーキテクチャについてより詳細な情報をご希望の方がいらっしゃいましたら、いつでもお気軽にご連絡ください。技術的なディスカッションやフィードバックも大歓迎です。