始めに
今回の投稿では、MARL(Multi-Agent Reinforcement Learning、以下MARL)のもう一つの手法であるLIIRについて取り扱いたいと思います。この手法は前回扱ったCOMA手法の拡張版なので、まずCOMAについて理解しておくのが良いでしょう。
https://qiita.com/raptorjung/items/7268850e518903ded99a
LIIRに関する論文は以下のリンクで見ることができます。このアルゴリズムはかなり複雑な部類に入ります。後ほど説明しますが、規模が大きくなると性能の保証が難しいアルゴリズムです。したがって、適用する際の考え方だけ理解しておけば十分だと思います。
LIIR
前回の投稿と同様に、以下の制約条件で進めます。
1, すべてのエージェントは部分観測情報(partial-observation)を使用する。
2, 各エージェントの部分観測情報は共有しない。
3, 報酬は個々のエージェントではなく、チーム全体に対して与えられる。
COMA手法を振り返ると、IAC(Independent Actor-Critic)手法から出発しています。ここでは、すべての情報を収集して各エージェントのポリシーにAdvantageを適用するためにCentralized Criticを導入しました。また、Advantageを算出するために報酬値が必要ですが、与えられる報酬はチーム報酬のため、各エージェントの行動に対する報酬の推定が必要でした。そこでReward Shapingを導入し、より効率的な計算のためにcountfactor baselineとcritic representationも併せて導入しました。
しかし、COMAの限界は、学習されるエージェントがホモジニアス(同種)の場合はある程度の性能を発揮しますが、ヘテロジニアス(異種)の場合はあまり良い性能を出せない点にあります。これはReward Shapingの限界を示しています。
そこで今回紹介するLIIRは、既存のCOMAなどのReward Shapingを踏襲しつつ、各エージェントに対する内的報酬(Intrinsic Reward)を追加しました。各エージェントの報酬関数をニューラルネットワークで構成し、その報酬関数自体も学習させる仕組みになっています。
下の図はLIIRのアーキテクチャです。
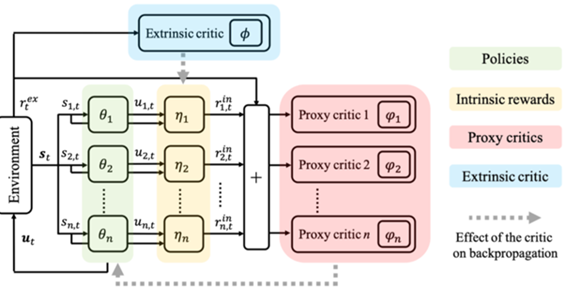
- θ:エージェントのポリシー
- η:エージェントの内的報酬関数
上の図において、Extrinsic Criticは以前扱ったCOMAと類似した役割を果たします。そこに各エージェントの内的報酬を通じてProxy Criticが計算されます。この結果、各エージェントのポリシーが更新される仕組みとなっています。
したがって、それに伴うCentralized Criticのニューラルネットワーク構造は以下の通りです。
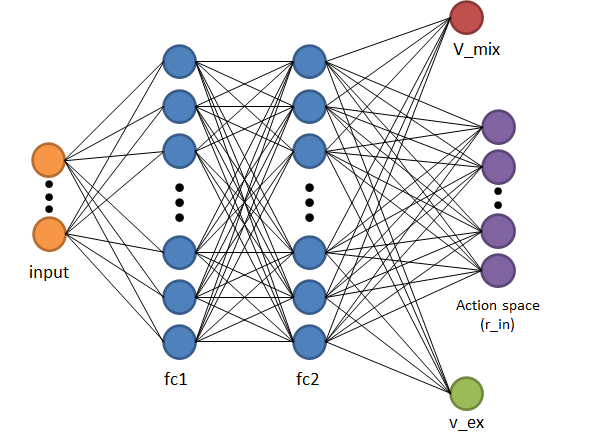
上記の構造を見ると、出力にV_MIX(赤色)の部分だけであれば従来のCOMA手法に相当します。そこにr_in(内的報酬)とV_ex(外的報酬)が追加され、それぞれを最適化することでCentralized Learningを行っています。
これを用いて各エージェントのポリシー更新の数式は以下の通りです。
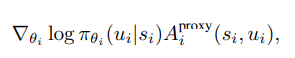
- i : i番目のエージェント
- u_i : エージェント i のジョイントアクション(joint-action)
Proxy CriticのAdvantageは以下の通りであり、これに基づいて各エージェントのポリシー更新が行われます。

ここまでは各エージェントの内的報酬に対するポリシー更新の部分です。
次からは目的関数に関する内容になります。この部分を内的報酬との関係で簡単に表すと以下のようになります。

この式を見ると、内的報酬と目的関数を最適化するプロセスが段階的に構成されていることが分かります。互いに影響を与え合う関係のため、目的関数は次のように変形できます。
- チェインルールを適用した目的関数

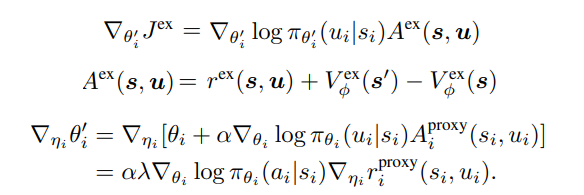
目的関数を内的報酬に対する影響度を計算する偏微分の形に変形してアプローチする方法です。つまり、目的関数を各エージェントのポリシーに基づいて影響度を計算し、そのポリシーを内的報酬によって評価する仕組みです。
以下は内的報酬に基づく行動の結果を示す図です。図の中でagent1に注目してください。図(a)を見ると、時刻 t=6 から内的報酬が減少していることが確認できます。図(b)ではagent1の体力がほぼゼロになっているのがわかります。この時点で回避行動を取らずに戦闘を続け、最終的に倒れてしまいました。その結果として内的報酬が減少したのです。

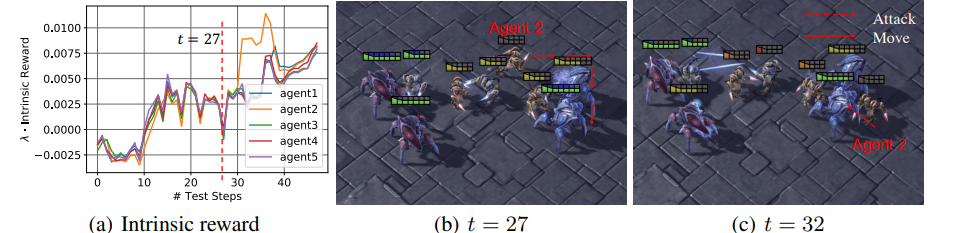
次に、別の例を示す以下の図を見てみましょう。今回はagent2に注目します。図(a)を見ると、時刻 t=27 から内的報酬が増加していることが確認できます。図(b)では前回と同様に体力がほぼゼロになっていますが、その際、図(b)の矢印の通り敵の背後に回り込み、図(c)のように攻撃を行いました。 これにより、それぞれの状態や役割に応じて柔軟に行動するように学習されていることが確認できました。
上記の事例を見ると、良好な性能を持つアルゴリズムに見えますが、一つの弱点があります。それはエージェントの個体数が増えると、それに伴い内的報酬に関するニューラルネットワークの規模が大きくなり、より多くのエピソードの実行が必要になることです。これはLIIRが抱える限界点であり、長期間エピソードを進めても性能向上が保証されない点もあります。しかし、各エージェントに対して内的報酬を別々に与えるという試みは非常に意義深いと思います。
ここまでLIIRについて整理しましたが、簡単にまとめます。既存のCOMAと同様にReward Shapingとcounterfactual baselineを維持しつつ、各エージェントに内的報酬を付与しました。また、その内的報酬の付与により、各エージェントが状況に応じて柔軟に行動するように学習されることが確認できました。しかし、規模が大きくなるほど性能が低下し、実験のエピソード数が増えるという点が課題です。
以下のリンクはLIIR手法で学習させた動画です。