はじめに
前回の投稿では、不必要な行動を制限することで強化学習の効率を向上させた事例を紹介しました。
しかし、環境の複雑さが増すにつれ、学習の難易度は指数関数的に上昇します。前回扱った1対1のPvP環境ではアクションマスキング(Action Masking)で対応が可能でしたが、敵モンスターの数が増えたり、フィールドが広大になったりする状況では、この手法だけでは限界が明らかです。
そこで本記事では、こうした複雑性を解決するために、既存のルールベース(Rule-based)アルゴリズムと強化学습을 組み合わせた「ハイブリッド方式」について詳しく解説していきます。
状態空間の拡張:1対1のPvPを超え、大規模な環境へ
映像でご覧いただけるように、状態空間(State Space)が急激に拡張される場合、アクションマスキングを適用したとしても、学習の収束速度が著しく低下したり、あるいは学習が全く進まなくなったりする可能性が高まります。これは、マスキングだけでは、探索すべき状態の組み合わせが指数関数的に増大し、対応しきれなくなるためです。
数日間にわたり昼夜を問わず学習にリソースを投入しましたが、結果は期待を下回るものでした。敵の近くに寄ることすらままならないエージェントの姿を見守るのは、エンジニアとして非常に歯がゆいプロセスでした。単に学習時間を増やすだけでは解決できない、構造的な問題に直面していることを痛感した瞬間でした。
ここで、根本的な疑問が湧きました。「これほど広大なマップにおいて、敵に接近する経路までエージェントが一つひとつ学習する必要があるのだろうか?」という点です。むしろ、エージェントには「どの敵を攻撃するか」という核心的な意思決定のみを任せ、目標地点までの移動は検証済みのルールベース(Rule-based)アルゴリズムに委ねる方が、はるかに効率的ではないかと考え始めたのです。
強化学習とビヘイビアツリー(BT)の結合:ハイブリッドAI設計戦略
現在もゲーム業界で最も広く使われているAI設計手法は、ビヘイビアツリー(以下BT)に基づいたルールベースのアプローチです。BTは多様な構成要素を持っていますが、特にセレクター(Selector)とシーケンサー(Sequence)ノードをどのように配置し階層化するかによって、エージェントの意思決定体系を非常に精緻かつ知的に構築することができます。
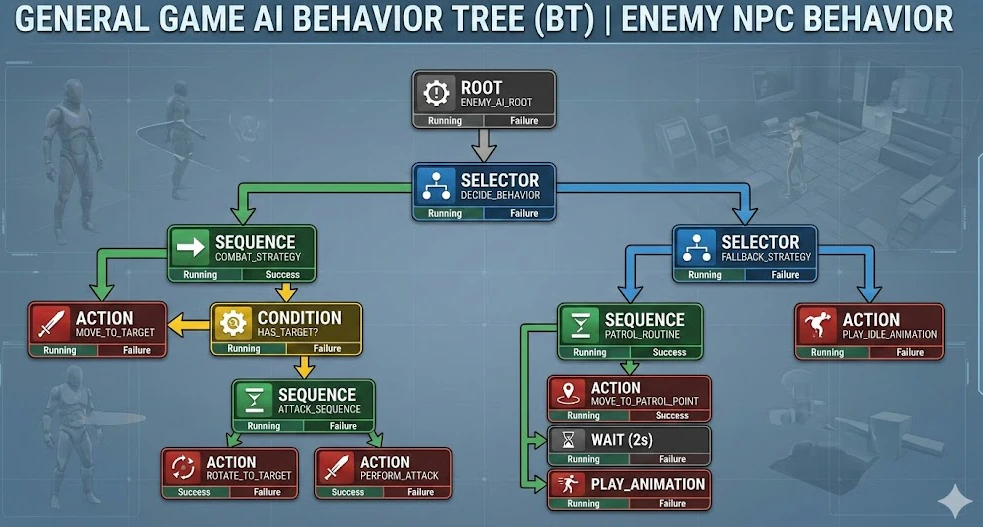
ここで注目すべき核心的なポイントは「役割の分離」です。ビヘイビアツリーの赤い末端ノード(Action Nodes)は既存の検証済みルールベースロジックで処理し、「どの行動を選択するか」という上位の意思決定権限を、従来のセレクターやシーケンサーではなくRL(強化学習)エージェントに任せる方式です。つまり、実行はルールベースが、判断は強化学習が担当するハイブリッド設計を試みました。
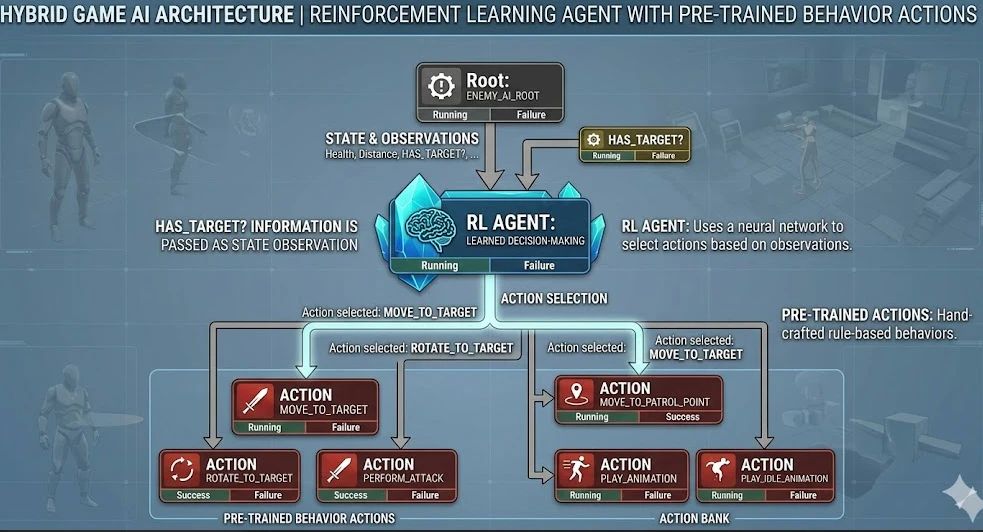
このような設計に修正して学習を行った結果、数日間の試行でも進展がなかったケースが、わずか8時間で正常に学習されました。これにより、エージェントには「判断」という高次元の意思決定のみを任せ、実際の「行動」は検証済みのルールベースを活用する手法が非常に有効であることを確認しました。すなわち、安定した枠組みの中でエージェントが最適戦略を効率的に探索できることを立証した結果です。
成功の最大の要因は、経路探索のような膨大な探索負荷を下位システムに委任することで、「次元の呪い(Curse of Dimensionality)」を効果的に解消したことにあります。これにより、学習効率を画期的に引き上げることができました。「温故知新」という言葉があるように、むやみに最新の技法だけを追うのではなく、既存の堅牢な技術といかに調和させて融合させるかを悩む過程が、エンジニアにとっていかに重要であるかを改めて実感したプロジェクトでした。
ベイズ的視点から見たハイブリッド設計:強力な事前分布(Prior)の力
このような設計は、統計学のベイズ推論(Bayesian Inference)の観点からも非常に興味深い解釈が可能です。ベイズ的な視点において「学習」とは、私たちが既に知っている「事前分布(Prior)」が新しいデータ(Evidence)に出会い、「事後分布(Posterior)」へと更新される過程を指します。
$P(\theta |D)\propto P(D|\theta )P(\theta )$
-
無情報事前分布(Uninformative Prior)の限界
従来の一般的な強化学習は、エージェントが環境について何の知識も持たない状態、つまりすべての行動の可能性が均等に開かれている「Flat」な状態からスタートします。これはベイズ的な視点では「無情報事前分布」を使用していることと同義です。探索すべき状態空間が広大であるほど、エージェントは有意義な情報を見つけ出すために膨大な時間を浪費してしまいます。 -
ビヘイビアツリー(BT)による強力な事前分布の付与
私が試みたハイブリッド方式は、ビヘイビアツリーの構造を通じて、エージェントに「この環境ではこのような行動が有効である」という強力な事前分布を付与したことになります。エージェントが経路探索や基礎的な動きといった低次元の行動を一から学習する必要はなく、既に検証済みのルールベースという枠組みの中でのみ動くように制限したためです。 -
学習効率の極大化
結局のところ、エージェントが学習すべき「仮説空間(Hypothesis Space)」がルールベースの許容範囲内に絞り込まれたことが、次元の呪いを解決する決定的な手がかりとなりました。わずか8時間で学習に成功した秘訣は、エージェントが全く新しい知識を創造する代わりに、あらかじめ定められた有効な範囲内で「最適の組み合わせ」を見つけることだけに集中できた「事前知識の力」にあります。
結論:判断はエージェントへ、実行はシステムへ
数日かけても足踏み状態だった学習が、構造の変化だけでわずか8時間で成功する過程を目の当たりにし、改めて「設計の重要性」を実感しました。エージェントに最初からすべてを教えようとしてはいけません。代わりに、エージェントが最も得意とする「戦略的選択」だけに集中できるよう、適切な土俵を整えてあげることがエンジニアの核心的な役割であることを再確認した時間でした。
今回は固定されたルールベースのアクションを活用しましたが、次の段階では、これらのアクションそのものも状況に応じて微細にチューニング(Fine-tuning)できるような構造を検討しています。安定性と柔軟性、その間の最適点を探る旅はこれからも続いていくでしょう。同じような悩みを抱えているエンジニアの方々にとって、このハイブリッドなアプローチが小さなヒントになれば幸いです。