はじめに
初めてQiitaに投稿する、これまでアウトプットに縁の無かった40代エンジニアです。これまでのキャリアは規制業種でもある金融のユーザー系システム子会社のSE一本なので、正直GitHubやPython、スマホアプリ開発やUnityなど、情報・知識としては知りつつも「何それ美味しいの('ω')」状態で生きてきました。
そんな私が縁あってプロトアウトスタジオに入学し、「いくら素晴らしいものを作っても、伝えなければ無いのと同じ」、「アウトプットする人が結局最強」説を聞き、「自分もアウトプットできる人になりたい('ω')」(←イマココ)と心に誓い、まずは行動あるのみです。
この記事の概要
JacaScriptでQiitaAPIを使って各種情報を取得するインプットを受けたので、この仕組みで色々とデータを取得して分析・考察してみようというものです。
- JavaScript + QiitaAPIで記事数上位20件のタグ情報を取得する
- せっかくなのでCSV出力に対応させてみる
- plotlyを使って散布図で表示させる(Jupyter Notebook)
環境は以下の通りです。
| Module | Version |
|---|---|
| Node.js | 15.13.0 |
| npm | 7.7.6 |
| axios | 0.21.1 |
| csv | 5.5.0 |
| plotly | 4.14.3 |
まだJavaScriptやNode.js、HTML/CSSのProgateオンライン学習(無償)をしている程度のレベルです。ありがたく先人達の記事を参考にさせて頂き、コピペ→トライ&エラーです('ω')
動きはしても、その書き方はイマイチだよ!などありましたら、是非ともツッコミお願いします。
JavaScript + QiitaAPIで記事数上位20件のタグ情報を取得する
後ほどコード全体は表示するので、ここではリクエストだけですが、こんな感じですね。
let response = await axios.get("https://qiita.com/api/v2/tags?page=1&per_page=20&sort=count");
初心者がQiitaのタグ情報を取得しTOP10を可視化し考察する。
せっかくなのでCSV出力に対応させてみる
先ほどのURL指定で、記事数上位20件のタグ情報は取得できますが、コンソールログの表示だけだと使い難いですよね。完成形のコードがコチラです。
//package require
const axios = require("axios");
const fs = require("fs");
const csvStr = require("csv-stringify/lib/sync");
const csvParse = require('csv-parse/lib/sync');
//認証情報(直接・・)
const token = "(個人用アクセストークン)"
//QiitaAPIでデータ取得・csvに出力
async function getArticle(query) {
//csvに変換する用list
let outcsv = [];
//csvのヘッダー設定
let columns = ["タグ","記事の数","フォロワー数"];
outcsv.push(columns);
//URLを作っておく
var url = "https://qiita.com/api/v2/tags?page=1&per_page=20&sort=count";
let response
//リクエストが失敗した時の処理
response = await axios.get(url
, {
headers: {
Authorization: `Bearer ${token}`,
}
}
).catch(err => {
return err.response
});
if (response.status != 200) {
console.log("たぶんAPIエラー")
}
//欲しい要素
for (let i = 0; i < 20; i++) {
//listに格納
let record = [];
record.push(response.data[i].id,response.data[i].items_count,response.data[i].followers_count);
outcsv.push(record);
}
// csvとして出力
fs.writeFileSync("./following_tag_list.csv", csvStr(outcsv));
}
//情報の取得
var query = "node.js";
getArticle(query);
これで、取得結果がカレントディレクトリにCSV形式で出力されるようになりました!
こちらの記事(Qiita初心者がまずタグ付けしたらよい言葉とは?)を参考にコード修正を行わせて頂きましたが、ちょっと苦戦しました。コーデイングが久しぶり過ぎて括弧の階層構造を見失いそうになったり、こんなエラーが表示されて焦ったり・・。
Error: Cannot find module 'csv-stringify/lib/sync'
code: 'MODULE_NOT_FOUND'
インストールできてないものは宣言しても使えませんよね・・。まだまだ慣れてないのがバレバレです。(インストールしましょう)
npm install csv
plotlyを使って散布図で表示させる(Jupyter Notebook)
最後に数字の羅列よりも可視化した方が分析・考察し易いに違いないということで、最初に参考にした記事を頼りにロクに触ったことの無いJupyter Notebookでplotlyとやらを使って散布図表示にチャレンジです('ω')

参考記事のコピペだけでは動作せず、以下二点の対応をしています。(参考:【Plotly】jupyter notebook上でofflineで使う方法)
- 事前にplotlyのインストール(
pip install plotly) - 宣言にplotlyをオフラインでおまじない(from plotly.offline~のところ)
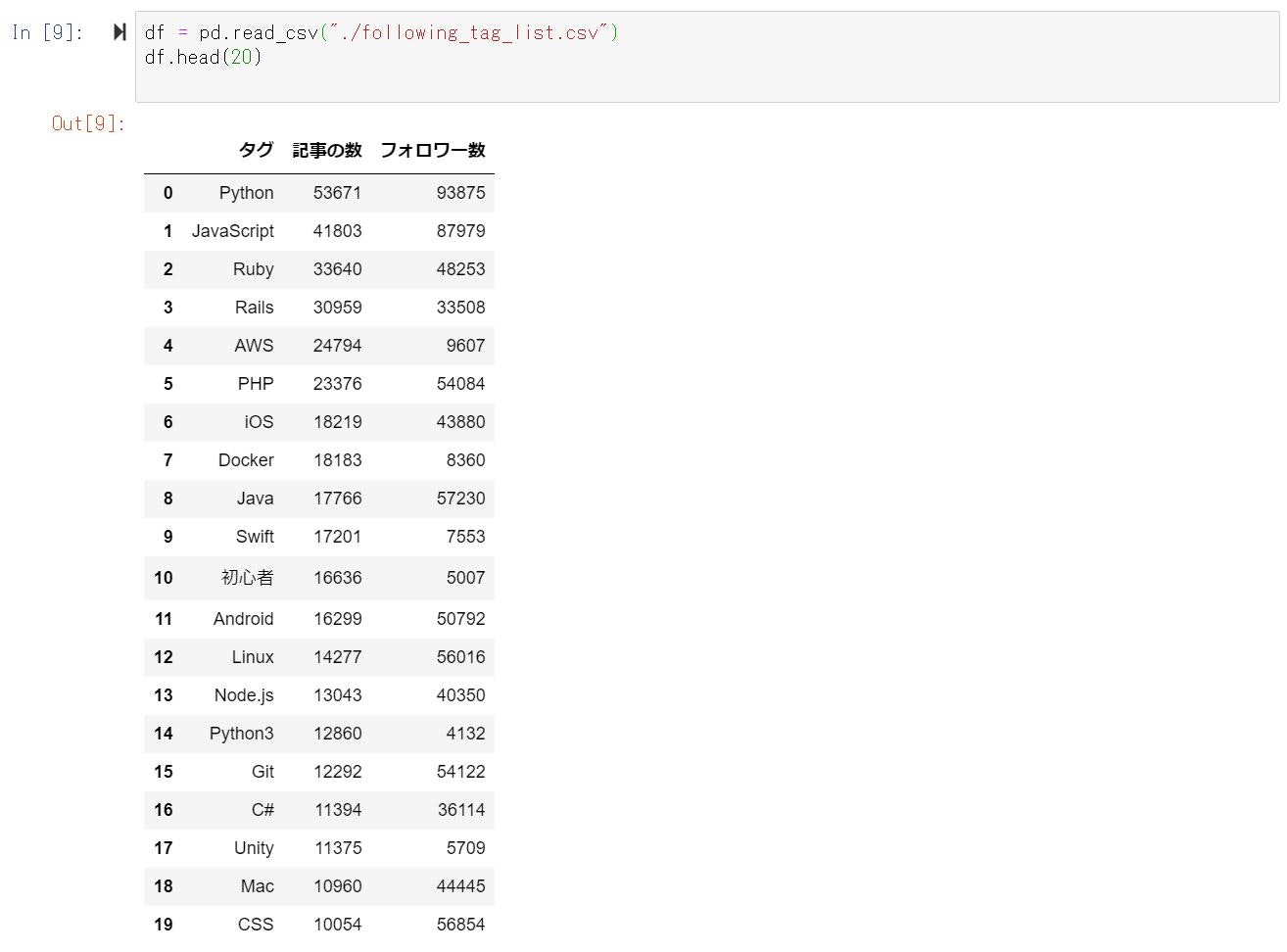
続けて、CSVファイルを読み込んで内容確認します。
最後に、plotlyで散布図表示です。
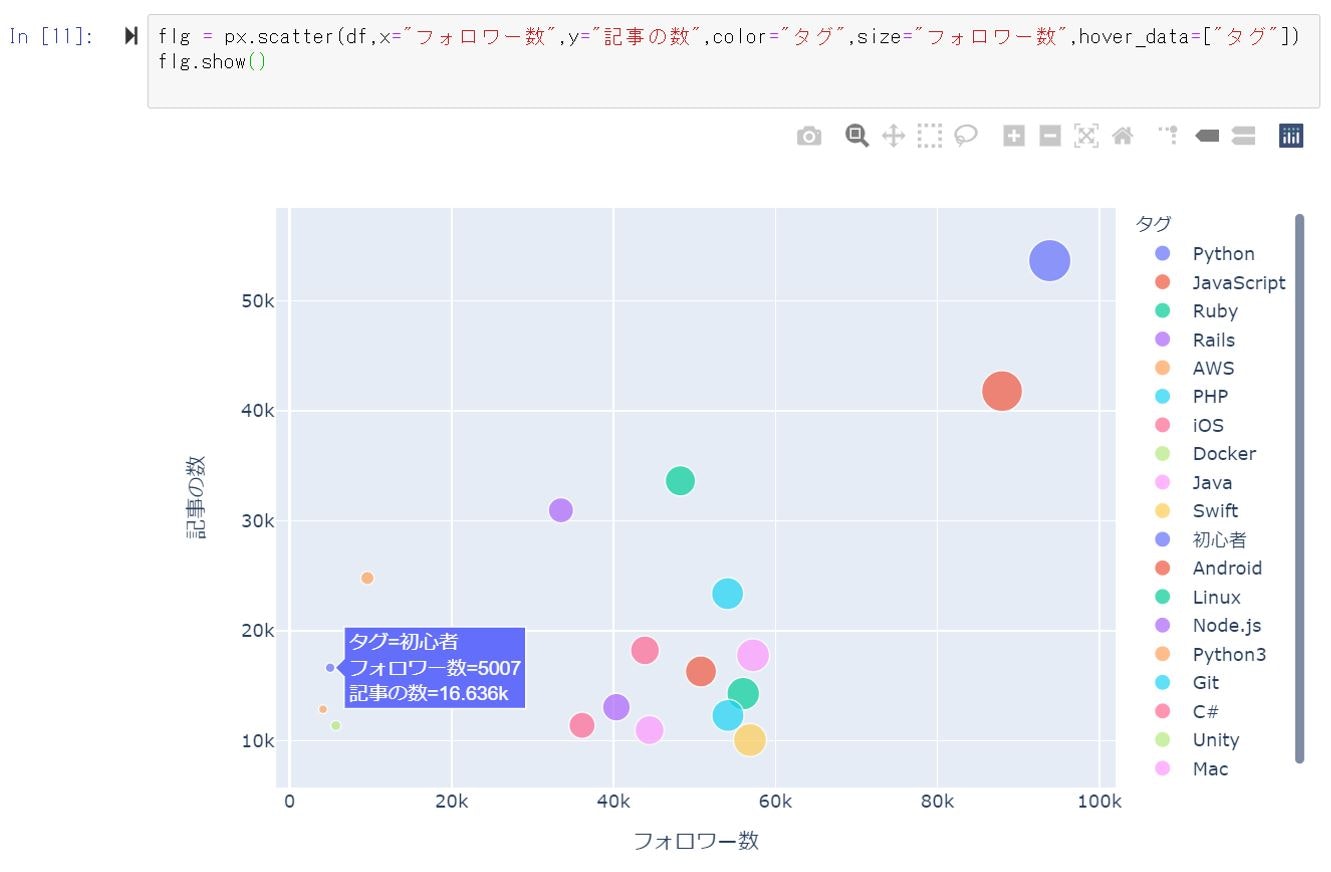
おぉ、映えるグラフがこんなに簡単に('ω')
ほとんどコピペで進めてきてこんなこと言うのはダメですが、本当に便利な機能が簡単に使える時代になっているんだなーとしみじみ感じました。
考察
- PythonとJavaScriptが、記事数・フォロワー数とも多いのは納得ですね
- 初心者タグは、フォロワー数の割には記事数が多いのは、皆さん初心者を巣立って、助ける側になっていくのでしょうね
- 意外だったのは、記事数の割にフォロワー数がとても多いカテゴリの存在です(Java、Git、Linux、C#など)
- この辺りは変化・新規情報の頻度はさておき、良質な情報を求めるユーザー数が多いカテゴリなのかなぁと勝手に解釈しました
終わりに
本当はこの辺りの基本操作を学んだ上で、「他にはどんなデータが取れるんだろう」、「面白い尖った分析をしてみたい」などと企んではいたものの、予想以上につまづきポイントが発生し、他の方の記事を参考に動きをトレースするので精一杯となってしまいました・・。Qiitaユーザーのプロフィール情報を取得して、居住地や組織情報、ブログやっているかなどのマップや相関など出せたらなーなどと妄想していましたが、考えてみれば自分も全項目は入力していない訳で・・。処理も上手く組める目途が立たず見送りとなりました。今度はデータを蓄積して、時系列の推移にも手を出してみたいと思っています。
ただ、やっぱりQiitaは自分にとってもモチロンですが、困っている誰かの学びになったり、問題解決の役に立つ魅力がある訳で、私も自分のレベルの低さにためらいを覚えることなく、つまづきポイントと解決策こそ積極的に記録していき、誰か一人でもお役に立てれば・・の気持ちで、Qiitaの投稿を続けて行きたいと思います('ω')