ES2024 / ES2023 / ES2022 / ES2021
JavaScriptの仕様は、TC39というところで決められています。
ブラウザベンダや関係者が定期的に会合を行い、様々な新機能について話し合ってどのようにするかを決めています。
ちなみに2023年9月のミーティングは東京で行われました。
ここでは2023年にFinishedになった、すなわち仕様が確定して複数のブラウザで実装がなされたproposalについて紹介してみます。
つまり、主要ブラウザでは既に使用可能です。
なお、2023年2月から2024年1月までにFinishedになったproposalがES2024と呼ばれるみたいです。
ずれているせいでややこしいですね。
年と一致させてくれ。
Finished Proposals
Promise.withResolvers
Promiseを外からresolve/rejectする方法を提供します。
const { promise, resolve, reject } = Promise.withResolvers();
promise
.then((value) => console.log("resolveされた", value))
.catch((reason) => console.error("rejectされた", reason));
if(なんか){
resolve(); // "resolveされた"
}else{
reject(); // "rejectされた"
}
Promise.withResolvers()は{promise, resolve, reject}を返すので、その後はいつでも好きにresolve/rejectできます。
これまでもconst promise = new Promise((res, rej) => { resolve = res; reject = rej; });みたいなかんじに代入することで同じことはできていたのですが、車輪の再発明が過ぎるので実装したとのことです。
便利なシンタックスシュガーですね。
Resizable and growable ArrayBuffers
ArrayBufferをリサイズ可能にします。
ArrayBufferは固定長です。
サイズを変更する場合は新たなArrayBufferを作ってコピーするという運用になっています。
これがWebAssembly等で問題になっていました。
ということで、生成されたArrayBufferを作りなおさずにサイズを変更可能にするオプションが追加されました。
// 初期値8、最大値16
let rab = new ArrayBuffer(8, { maxByteLength: 16 });
rab.resizable; // true
let U32a = new Uint32Array(rab);
U32a.byteLength; // 8
// 16まで変更可能
rab.resize(16);
U32a.byteLength; // 16
// 範囲外
rab.resize(32); // Uncaught RangeError: Invalid length parameter
// 未指定時は変更不可
let rab = new ArrayBuffer(8);
rab.resizable; // false
ArrayBufferのコンストラクタにmaxByteLengthを渡すと、その値までの範囲でArrayBufferのサイズが変更可能になります。
引数を渡さない場合はこれまでどおり変更不可です。
またArrayBufferに読み取り専用プロパティresizable、maxByteLength等が追加されます。
resizableはサイズを変更可能かどうか、maxByteLengthは変更できる最大サイズを取得できます。
あとproposalではSharedArrayBufferにも適用されると書いてあるのですが、こいつはSpectre対策で使用するためには面倒な対応が必要です。
一般的環境ではSharedArrayBuffer is not definedとなって使えないところがほとんどなので、あまり気にする必要はないでしょう。
ちなみにArrayBufferはresize()で任意にサイズの拡縮が可能ですが、SharedArrayBufferはgrow()であり、サイズは増加させることしかできません。
Array Grouping
配列をグルーピングするメソッドObject.groupByとMap.groupByを追加します。
let array = [1, 2, 3, 4, 5];
Object.groupBy(array, (num, index) => {
return num % 2 === 0 ? "even": "odd";
});
/*
{
"odd": [
1,
3,
5
],
"even": [
2,
4
]
}
*/
const odd = { odd: true };
const even = { even: true };
Map.groupBy(array, (num, index) => {
return num % 2 === 0 ? even: odd;
});
/*
new Map([
[
{
"odd": true
},
[
1,
3,
5
]
],
[
{
"even": true
},
[
2,
4
]
]
])
*/
Object.groupByはオブジェクトに、Map.groupByはMapに値をグループ化してくれます。
RFCの例では偶数奇数の2つだけですが、もちろん3つ以上のグループに分けることも可能です。
これを使うことで、たとえば年齢層ごとに集計したりといった分析がやりやすくなることでしょう。
正直自力で実装してもさほどたいした内容ではないのですが、ネイティブで実装されていれば性能も高いし安心ですね。
ちなみに、どうしてarray.groupBy()とかではなくわざわざ静的メソッドになっているのかがproposalで解説されています。
当初Array.prototype.groupByにしようとしていたところ、その名前だとSugarというライブラリが動かなくなることが判明しました。
これで600以上のサイトが影響を受けることがわかったため、名前をArray.prototype.groupに変更しました。
ところが今度はLastPass Password Managerが動かなくなりました。
影響を受けるアプリがひとつだけなら修正してもらうという手もあったかもしれませんが、groupなんて一般的な名前が衝突しないわけもなく、問題が他にも続々と発見されてしまいました。
groupも使えなくなったので次はgroupToObjectにしよう、いやpartitionだと様々な議論が行われた結果、最終的に静的メソッド化したプルリクエストがこれいーじゃんと受け入れられました。
Well-Formed Unicode Strings
与えられた文字列がWell-Formed Unicode Stringであるかどうかをチェックする関数String.prototype.isWellFormed・String.prototype.toWellFormedを追加します。
それでWell-Formed Unicode Stringって何だよという話ですが、サロゲートペアがきちんとペアじゃないといけないということらしいです。
全然わかってないけど、まあ要するにちゃんと正しい文字列であればいいということでしょう、きっと。
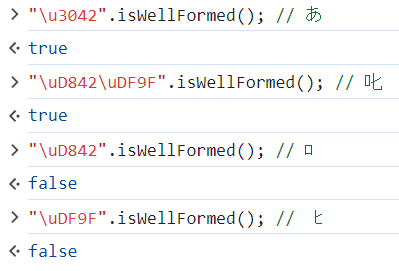
proposal内にもたった1行でのpolyfillが載っているくらい簡単に代替できるのですが、このpolyfillは全文字をスキャンするのでたいへん遅くなってしまいます。
これをネイティブで実装することによって速度が早く、見た目もわかりやすくなるようです。
RegExp v flag with set notation + properties of strings
正規表現にvフラグを追加します。
これは既存のuフラグの拡張版です。
既に詳しい説明をしている人がいるのでそちらを見てください。
私にはさっぱりわかりません。
/^\p{Emoji}$/.test('👨🏾⚕️'); // false
/^\p{RGI_Emoji}$/.test('👨🏾⚕️'); // false
/^\p{Emoji}$/u.test('👨🏾⚕️'); // false
/^\p{RGI_Emoji}$/u.test('👨🏾⚕️'); // Uncaught SyntaxError: Invalid regular expression
/^\p{Emoji}$/v.test('👨🏾⚕️'); // false
/^\p{RGI_Emoji}$/v.test('👨🏾⚕️'); // true
とりあえずなんか合体する絵文字が正しく検索できるようになると認識した。
Atomics.waitAsync
Atomics.waitの非同期版です。
そもそもAtomics.wait自体どういうときに使うのかわかっていないので、さらにその発展形とか言われてもさっぱりだぜ。
感想
私個人としてはあまり使いそうにない機能が多いのですが、これまで無駄な定型文を書いていたところがシンタックスシュガーですっきり書けるようになったり、フロントだけで文字を処理できるようになったりと、フロントエンドエンジニアにとっては有用な機能が揃っていると思います。
それにしても文字コードまわりはいくらドキュメントを読んでもさっぱりわからんな。
やはりさっさとUTF-128化してしまうべきなのでは?