目次
はじめに
今回は、SIGNATEが主催した自動車関連業界対抗データサイエンスチャレンジ2025のビギナーズカップ「自動車の排出ガススコアの予測」に参加し、3位獲得しました。
普段からDataikuを利用しており、中盤までDataikuで頑張っていたので、Dataikuで実施したことやDataikuの利用方法を共有します。
※本コンペの詳細ページやデータは参加者のみ閲覧できます。
Dataikuとは?
Dataikuはデータ収集から加工、可視化、ML、LLM、アプリケーション開発まで一元的に行える強力なプラットフォームです。
有料のクラウド版と無料インストール版があり、今回共有する解法は無料インストール版の機能で十分実現できますので、ぜひDataikuを使ってみてください!
Dataikuを使用した解法の最高得点について
投稿した結果からみるとDataikuを使った最終最高得点は0.3091291であり、リーダーボードで18位ぐらい獲得できるはずです。

コンペ説明
【コンペの目的】
エンジン排気量や燃料タイプなどから、自動車の排出ガスのクリーンさを1~10定量的に予測することです。
【データセット】
エンジン排気量などの自動車に関するデータが与えられます。これらのデータは、EPA(米国環境保護庁)が公開している燃費データセットで、このデータセットを元に自動車の排出ガスのクリーンさのスコアが算出されます。
燃費データセットには、自動車の種類(EVやHybridなど)、様々な条件下での燃費(MPG)情報や、車のモデル名、エンジン排気量などが含まれております。
【目的変数】
1~10となる自動車の排出ガスのクリーンさスコア「mean_emissions_score」
【評価指標】
MSE(Mean Squared Error)が使用されます。
MSEは平均二乗誤差と呼ばれ、予測値と実測値の二乗誤差を平均した指標です。
スコアの範囲は0〜♾️となり値が小さいほど精度が高くなります。
全体フロー

以下はDataikuの生成AIを用いた「Explain Flow」機能により自動生成された説明文です。
このデータ処理フローは、車両の燃費と排出量に関するデータを効率的に管理し、分析するための包括的なプロセスです。最初に、「stack」ゾーンでは、重複データを排除し、トレーニングデータとテストデータを統合して、ユニークで包括的なデータセットを作成します。次に、「preprocess_1」と「preprocess_2」ゾーンで、データのクリーニングと変換を行い、モデルのトレーニングとテストに適した形式に整えます。
「modeling_1」と「modeling_2」ゾーンでは、トレーニングデータを用いて予測モデルを構築し、精度を向上させるための最適化を行います。「predict」と「predict_2」ゾーンでは、異なる機械学習モデルを用いてテストデータをスコアリングし、予測結果を生成します。
「stacking」ゾーンでは、トレーニングされたモデルを用いてテストデータに予測スコアを生成し、車両の環境性能を評価します。「postprocess」ゾーンでは、複数のモデルから得られた予測データを統合し、最終的な「mean_emissions_score」を算出します。
最後に、「colab」ゾーンでは、異なるデータセットを結合し、車両の詳細情報に基づいて排出スコアを調整します。これにより、環境への影響を最小限に抑えるためのより正確な車両評価が可能となります。このフロー全体は、データの一貫性と信頼性を確保しつつ、企業が持続可能性の目標を達成するためのデータ駆動型の意思決定をサポートします。
どーん、複雑にみえるが、整理して簡略化すると、要するに下図のようなことを実施しました。
重複内容になるため、今回は「データ前処理2」とその「モデリング2」のみを紹介します。
データ前処理
最高得点解法となった「データ前処理2」のみを紹介します。

欠損値補完
まずはtrainデータとtestデータをスタックしたデータ「train_test_stacked」に対して、python recipeを作成。

下記codeで変数'model'のグループごとに変数'eng_dscr'最頻値を計算し、'eng_dscr'の欠損値を埋める。ただし、欠損値しかない場合はUnknownにする。
サンプルコード
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
# Read recipe inputs
train_test_stacked = dataiku.Dataset("train_test_stacked")
train_test_stacked_df = train_test_stacked.get_dataframe()
# Compute recipe outputs from inputs
# TODO: Replace this part by your actual code that computes the output, as a Pandas dataframe
# NB: DSS also supports other kinds of APIs for reading and writing data. Please see doc.
#エンジンモデル
# グループごとに最頻値を計算し、欠損値を埋める。ただし、欠損値しかない場合はUnknownにする
def fill_missing_with_mode(group):
# 欠損値以外の値が存在するかを確認
if group['eng_dscr'].notna().any():
# 欠損値を最頻値で埋める
return group['eng_dscr'].fillna(group['eng_dscr'].mode()[0])
else:
# 欠損値しかない場合はUnknownでうめる
return group['eng_dscr'].fillna("Unknown")
# グループごとに処理を適用
train_test_stacked_df['eng_dscr'] = train_test_stacked_df.groupby('model', group_keys=False).apply(fill_missing_with_mode)
train_test_fill_startStop_df = train_test_stacked_df # For this sample code, simply copy input to output
# Write recipe outputs
train_test_fill_startStop = dataiku.Dataset("train_test_fill_startStop")
train_test_fill_startStop.write_with_schema(train_test_fill_startStop_df)
その他処理
次に、前ステップで欠損値補完したデータ「train_test_fill_startStop」に対して「Prepare Recipe」を用意する。

- 日時カラム「createdOn」と「modifiedOn」の分割(Tokenize text)→月と曜日だけ残しておく(Delete/Keep columns by name)
カラム「createdOn」を例にして↓
①「createdOn」の分割
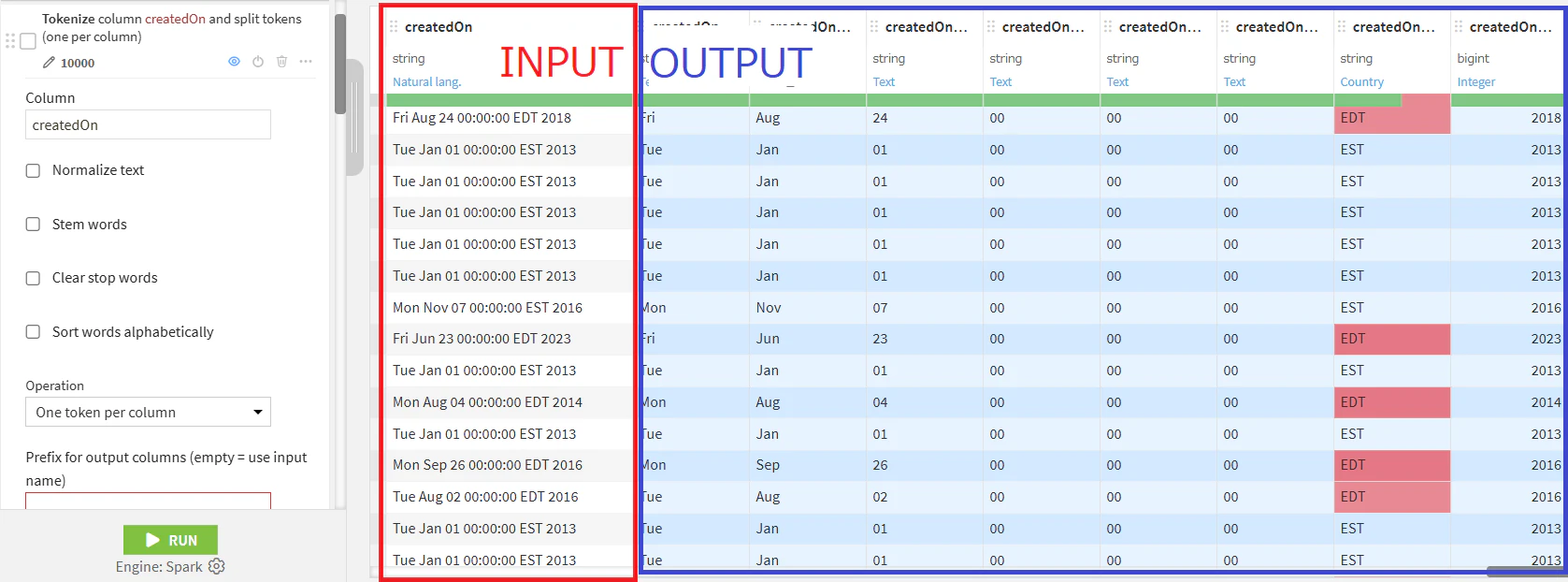
②月と曜日だけ残しておく
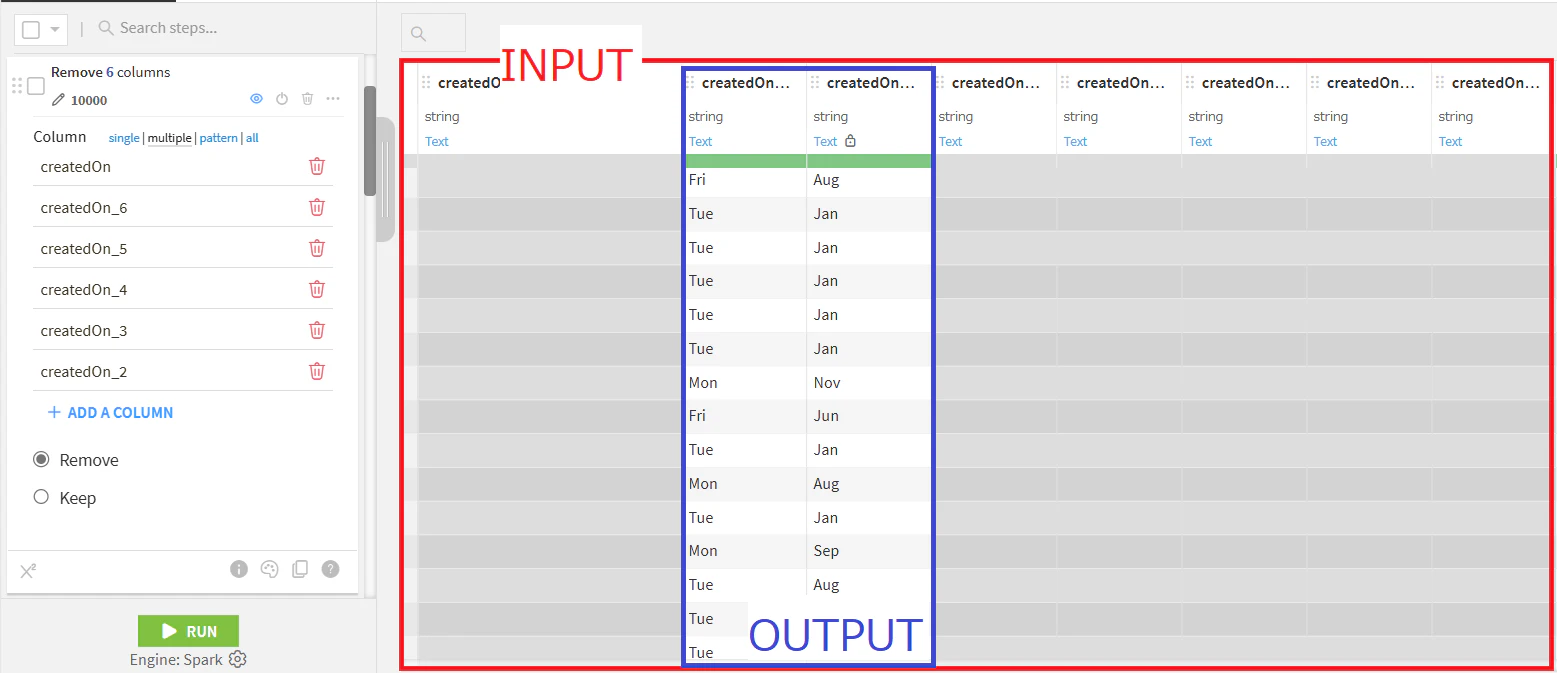
- 特徴量組み合わせ(Generate numerical combinations):
city08U+cityA08、Ubarrels08+barrelsA08、co2TailpipeAGpm+co2TailpipeGpmなど類似な特徴量を合算する。(詳細は以下参照)
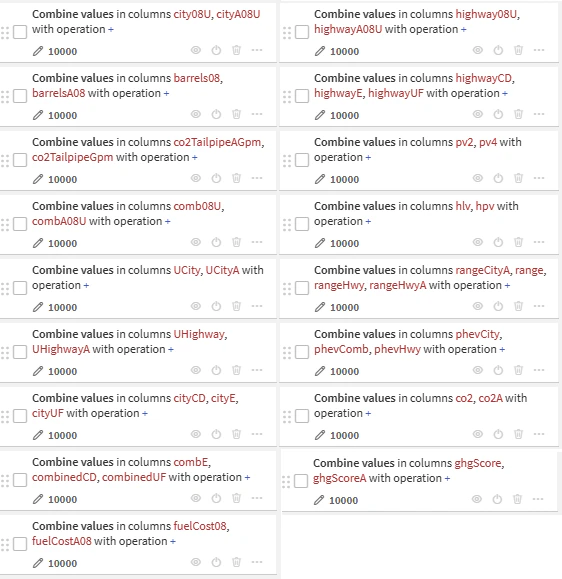
「city08U+cityA08」を例にして↓

モデリング
データ前処理されたtrainデータに対して「AutoML Prediction」機能を使って、予測モデルを構築します。
Visual ML(Analysis)の作成
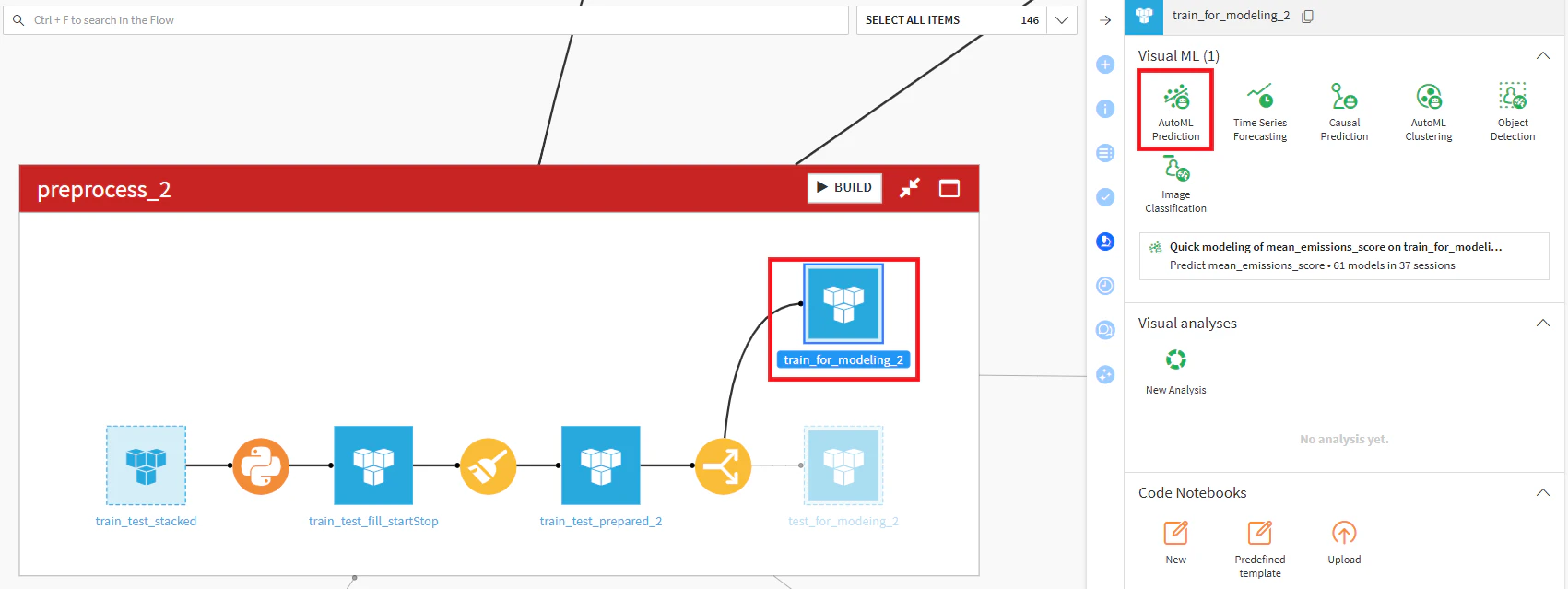
target変数をスコア「mean_emissions_score」を指定し、Visual MLを「create」します。
モデルデザイン
Visual ML(Analysis)のデザインタブに入り、左側のメニューにある設定を行っていく。
BASIC
Train/Test Set
K-fold cross-testにチェックを入れ、fold数を5、random seedを42に指定します。
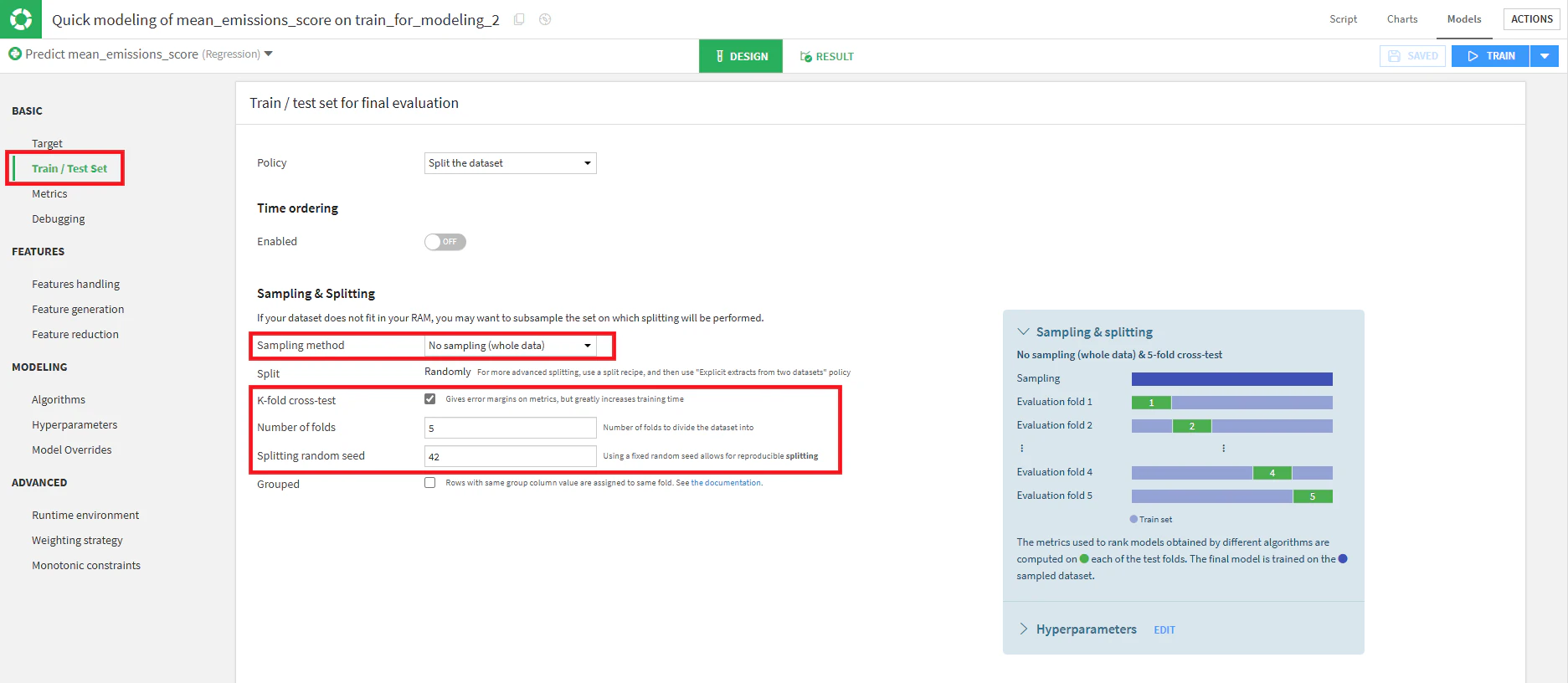
Metrics
本コンペの評価指標であるMSE(Mean Squared Error)を指定します。

FEATURES
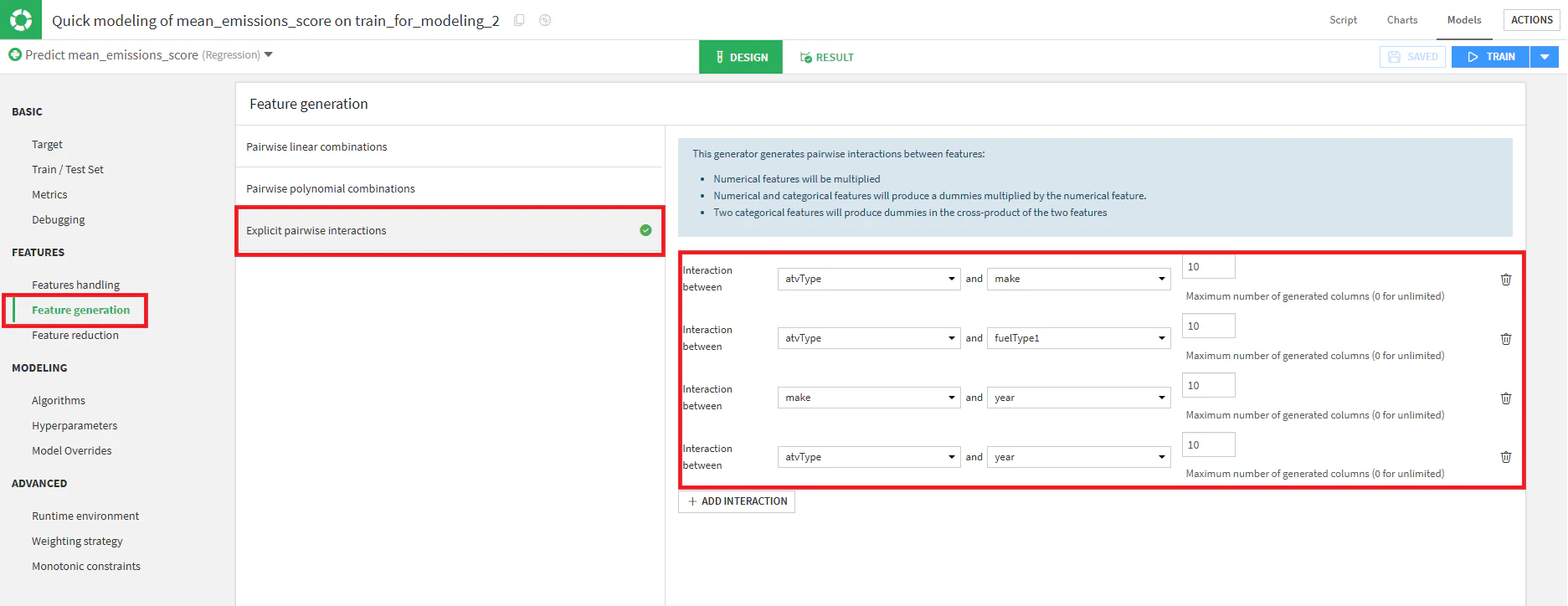
Feature generation
これは特徴量を組み合わせて新しい特徴量を自動生成してくれるDataikuのとても便利な機能だと思います。今回は、Explicit pairwise interactionsを利用しました。下図通り、組み合わせ4ペアを指定し、生成される新カラム最大数を10に指定します。
MODELING
今回は、Dataikuに入っているXGBoostとLightGBM、あとはCUSTOM PYTHON MODELを利用してcatboostで学習を行いました。
Algorithms
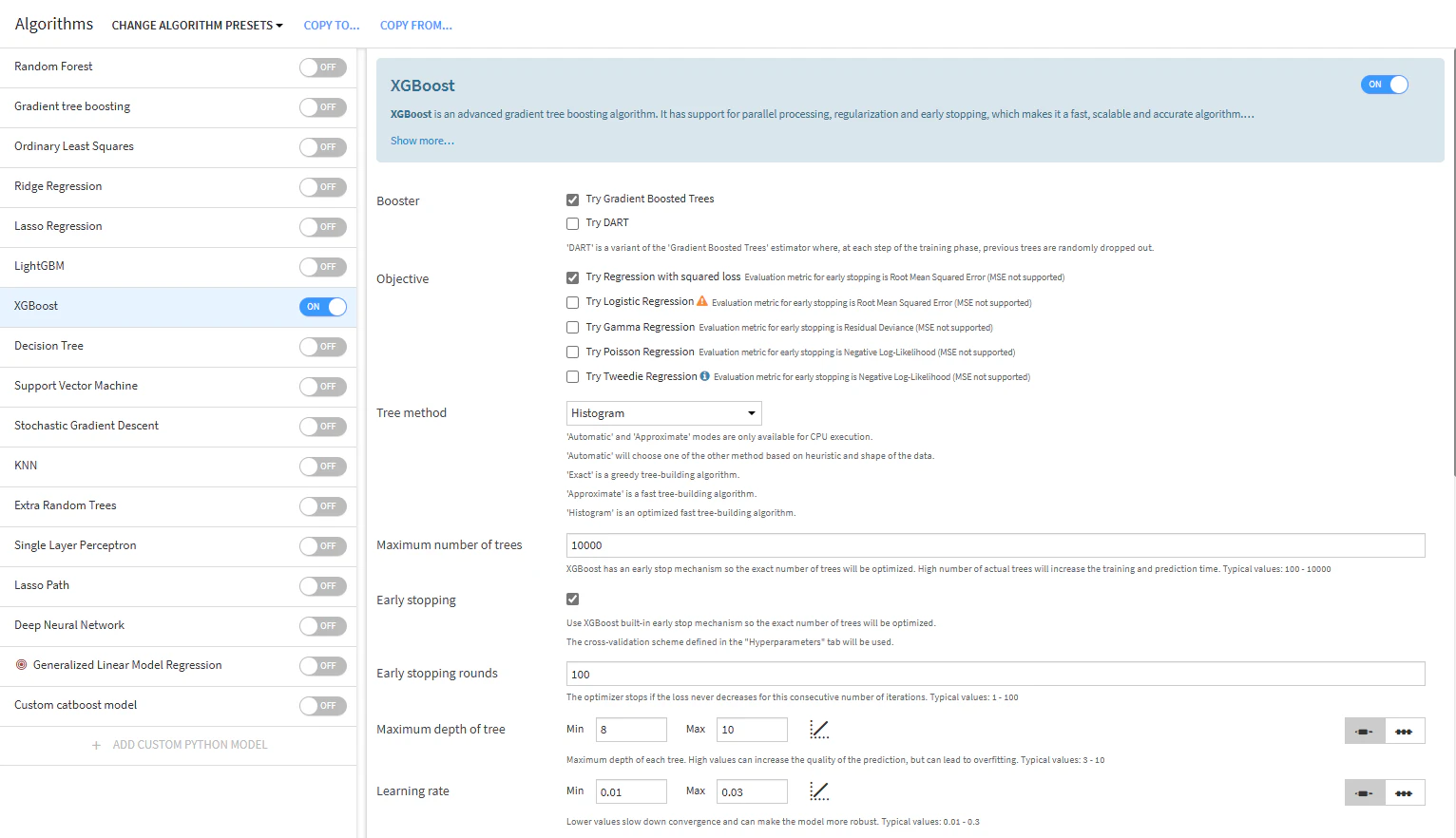
- XGBoost(★最高得点)
ポイント:maximum number of treesをとにかく大きめに指定する

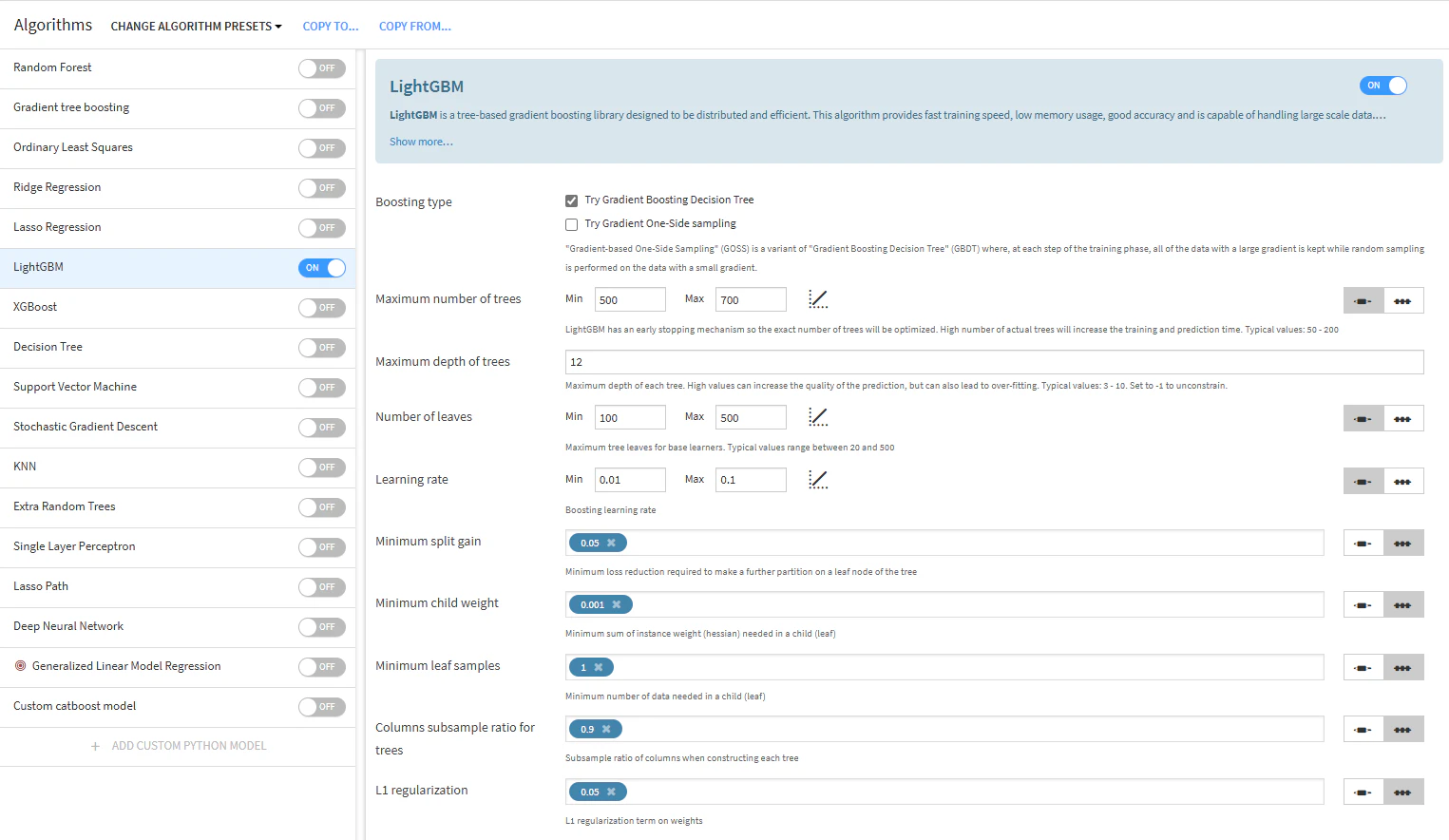
- LightGBM
ポイント:maximum number of treesをとにかく大きめに指定する

- CatBoost
ポイント:ハイパーチューニングの方法がわからずとりあえずパラメータを固定に
「+ ADD CUSTOM PYTHON MODEL」をクリックし、python codeを右側に貼り付ける。

コード
# Dataiku import
import dataiku
import pandas as pd
from dataiku import pandasutils as pdu
from catboost import CatBoostRegressor, Pool
from sklearn.base import BaseEstimator
import numpy as np
class MyRandomRegressor(BaseEstimator):
def __init__(self, **CatBoost_Params):
self.params = CatBoost_Params
self.model = None
def fit(self, X, y):
self.model = CatBoostRegressor(**self.params)
self.model.fit(X, y)
return self
def predict(self, X):
return self.model.predict(X).flatten()
CatBoost_Params = {'iterations': 5870,
'learning_rate': 0.15948258747305225,
'depth': 5,
# 'l2_leaf_reg': 0.4609778108407022,
# 'subsample': 0.788826023331594,
# 'colsample_bylevel': 0.6935167425118375,
'random_seed': 42
}
# CatBoostモデルの設定
clf = MyRandomRegressor(**CatBoost_Params)
Hyperparameters
「Search Strategy」は「Random search」を選択し、モデルによって探索回数を設定していました。
-
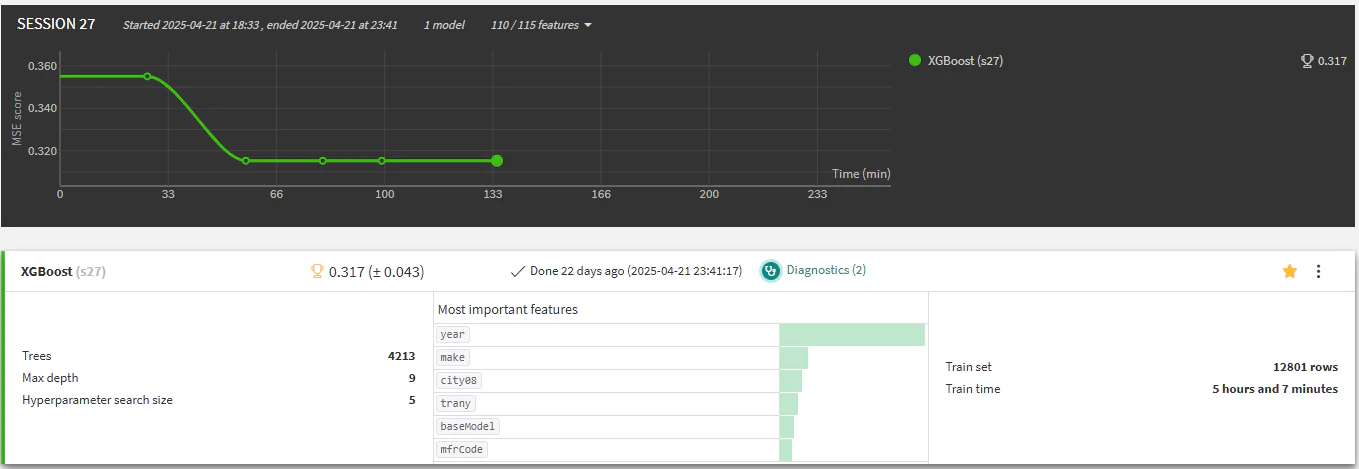
XGBoostのような学習時間が長い場合は「Search space limit」を「5」に、「Time limit」を「0」に指定し(つまり5回パラメータ探索してくれる)、2時間弱かかりました
-
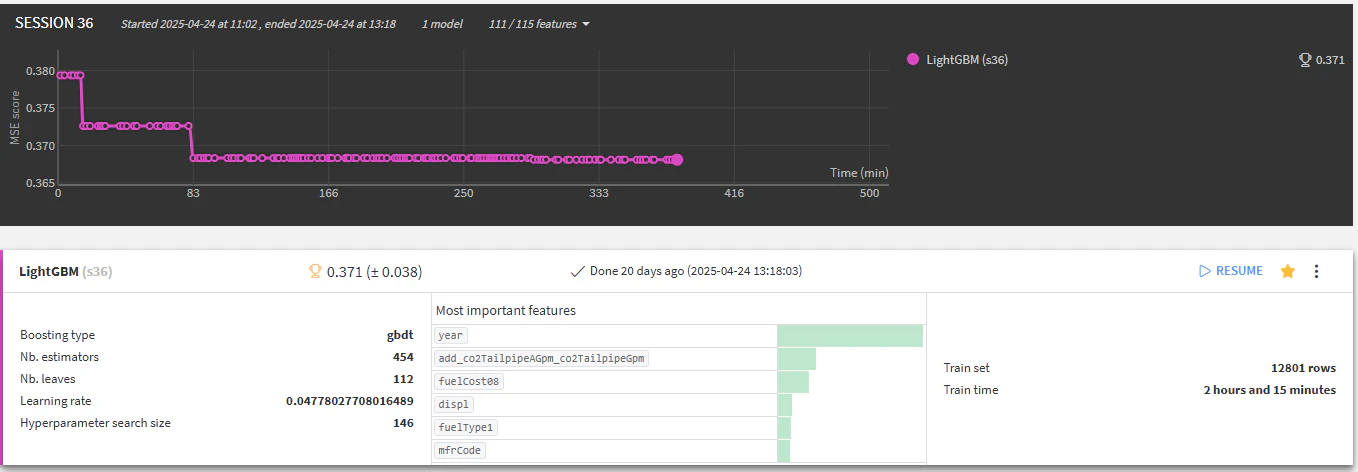
LightGBMのような学習が早い場合は「Search space limit」を「50」に、「Time limit」を「0」に指定し(つまり50回パラメータ探索してくれる)、5時間以上かかりました
Catboostのようなカスタムアルゴリズムは、Hyperparametersでの設定は適応されません。Custom Python Codeのほうで実装できるはずですが、今回は余裕がなく、実装方法をわからないままでした。
アンサンブル
最高得点ではないが、それまでに各種モデルの予測結果を「Join recipe」でJoinし、さらに「Prepare Recipe」を用意し、「Formula」で重み付けアンサンブルを行いました。
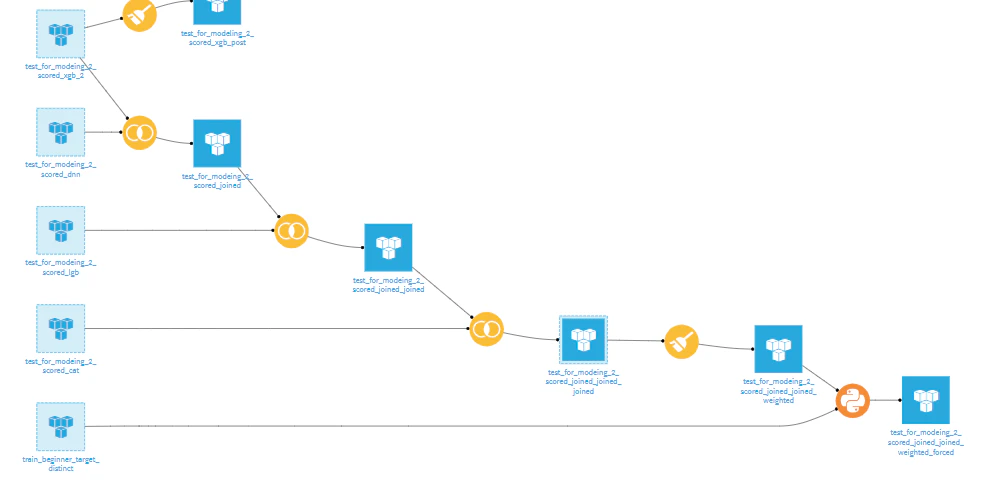
実はJoinレシピ1個で複数のデータを1回でJoinできます!
以下重み付けアンサンブルのFormula例です。

Formula文
prediction_xgb*0.8+prediction_lgb*0.1+prediction_cat*0.05+prediction_dnn*0.05
データ後処理
最後に、予測結果に対して「Prepare Recipe」を用意し、後処理を行う。
- 予測値を1~10にする(Force numerical range)
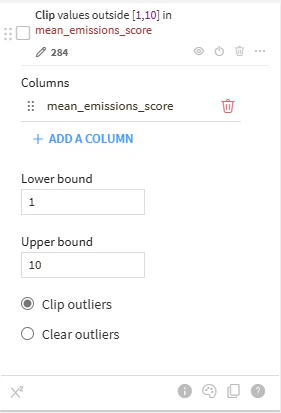
- 特定のatvTypeの予測値を強制的に矯正(Formula)
Formula文
・カラム「atvType」が"Bifuel (CNG)"になっている行の予測値を1にする
if(atvType=="Bifuel (CNG)", 1, prediction)
・カラム「atvType」が"FCV"/"EV"、かつ予測値が9.6以上になっている行の予測値を10にする
if((atvType=="FCV"||atvType=="EV")&& mean_emissions_score>9.6, 10, mean_emissions_score)
予測結果の提出
今回のコンペのサンプル提出物を見ると、ヘッダーがないので、Dataikuから提出用のcsvファイルをダウンロードする際は、「With header」のチェックを外しましょう。
各アルゴリズムのCV得点
| アルゴリズム | CV | 備考 |
|---|---|---|
| XGBoost | 0.317 | これ単体でPublic LB点数 0.3091291。 3位を取れた解法にもアンサンブルされており、 予測結果の6.25%を占める。 |
| LightGBM | 0.371 | |
| CatBoost | 0.519 |
最後に
コンペの感想
大変やさしく設計されたコンペと実感し、大変勉強になりましたし、GW中にも頑張った価値があったと感じます。
Dataikuを活用した感想
Dataikuの既存機能はローコードであり、初心者にとっても簡単に機械学習モデルを構築できるようなツールだと便利さを実感しました。また、もっと作りこめばDataikuも確実にもっと高い点数を出せると実感しました。
DataikuにもCatBoostやOptuna、StackingModelを機能として実装してもらえたら最強な気がします!