はじめに
今回は、SIGNATEが主催した自動車関連業界対抗データサイエンスチャレンジ2025のビギナーズカップ「自動車の排出ガススコアの予測」に参加し、3位獲得しましたのでその解法を共有します。
※本コンペの詳細ページやデータは参加者のみ閲覧できます。
分析環境
個人のゲーミングPCで以下の環境で分析を行っていました。
- 言語:Python
- メモリ:16GB
- GPU:GeForce GTX 1660 (6GB)
- 助手:ChatGPT
コンペ説明
【コンペの目的】
エンジン排気量や燃料タイプなどから、自動車の排出ガスのクリーンさを1~10定量的に予測することです。
【データセット】
エンジン排気量などの自動車に関するデータが与えられます。これらのデータは、EPA(米国環境保護庁)が公開している燃費データセットで、このデータセットを元に自動車の排出ガスのクリーンさのスコアが算出されます。
燃費データセットには、自動車の種類(EVやHybridなど)、様々な条件下での燃費(MPG)情報や、車のモデル名、エンジン排気量などが含まれております。
変数詳細
| 変数名 | 分類 | タイプ | 説明 |
|---|---|---|---|
| id | 数値 | int | 車両レコードのID |
| barrels08 | 数値 | float | fuelType1 の年間石油消費量(バレル) |
| barrelsA08 | 数値 | float | fuelType2 の年間石油消費量(バレル) |
| charge240 | 数値 | float | 電気自動車の240V充電時間(時間) |
| city08 | 数値 | float | fuelType1 の市街地燃費(MPG) |
| city08U | 数値 | float | fuelType1 の市街地燃費(未調整、MPG) |
| cityA08 | 数値 | float | fuelType2 の市街地燃費(MPG) |
| cityA08U | 数値 | float | fuelType2 の市街地燃費(未調整、MPG) |
| cityCD | 数値 | float | 電力消費モードの市街地ガソリン消費量(ガロン/100マイル) |
| cityE | 数値 | float | 市街地の電力消費量(kWh/100マイル) |
| cityUF | 数値 | float | 市街地ユーティリティファクター |
| co2 | 数値 | float | fuelType1 のCO2排出量(g/mile) |
| co2A | 数値 | float | fuelType2 のCO2排出量(g/mile) |
| co2TailpipeAGpm | 数値 | float | fuelType2 の排気CO2排出量(g/mile) |
| co2TailpipeGpm | 数値 | float | fuelType1 の排気CO2排出量(g/mile) |
| comb08 | 数値 | float | fuelType1 の統合燃費(MPG) |
| comb08U | 数値 | float | fuelType1 の統合燃費(未調整、MPG) |
| combA08 | 数値 | float | fuelType2 の統合燃費(MPG) |
| combA08U | 数値 | float | fuelType2 の統合燃費(未調整、MPG) |
| combE | 数値 | float | 統合電力消費量(kWh/100マイル) |
| combinedCD | 数値 | float | 電力消費モードの統合ガソリン消費量(ガロン/100マイル) |
| combinedUF | 数値 | float | 統合ユーティリティファクター |
| cylinders | 数値 | int | エンジンシリンダー数 |
| displ | 数値 | float | エンジン排気量(リットル) |
| drive | カテゴリ | object | 駆動方式(FWD, RWD, 4WD など) |
| eng_dscr | カテゴリ | object | エンジンの説明 |
| evMotor | 数値 | float | 電気モーターの出力(kWh) |
| feScore | 数値 | int | 燃費スコア |
| fuelCost08 | 数値 | float | fuelType1 の年間燃料コスト($) |
| fuelCostA08 | 数値 | float | fuelType2 の年間燃料コスト($) |
| fuelType | カテゴリ | object | 燃料タイプの統合 |
| fuelType1 | カテゴリ | object | 燃料種別1 |
| fuelType2 | カテゴリ | object | 燃料種別2 |
| ghgScore | 数値 | int | 温室効果ガススコア |
| ghgScoreA | 数値 | int | fuelType2 の温室効果ガススコア |
| 変数名 | 分類 | タイプ | 説明 |
| highway08 | 数値 | float | fuelType1 の高速燃費(MPG) |
| highway08U | 数値 | float | fuelType1 の高速燃費(未調整、MPG) |
| highwayA08 | 数値 | float | fuelType2 の高速燃費(MPG) |
| highwayA08U | 数値 | float | fuelType2 の高速燃費(未調整、MPG) |
| highwayCD | 数値 | float | 電力消費モードの高速ガソリン消費量(ガロン/100マイル) |
| highwayE | 数値 | float | 高速の電力消費量(kWh/100マイル) |
| highwayUF | 数値 | float | 高速ユーティリティファクター |
| hlv | 数値 | float | ハッチバックの荷物容量(立方フィート) |
| hpv | 数値 | float | ハッチバックの乗員容量(立方フィート) |
| lv2 | 数値 | float | 2ドアの荷物容量(立方フィート) |
| lv4 | 数値 | float | 4ドアの荷物容量(立方フィート) |
| make | カテゴリ | object | メーカー名 |
| model | カテゴリ | object | モデル名 |
| mpgData | カテゴリ | bool | My MPG データの有無 |
| phevBlended | カテゴリ | bool | プラグインハイブリッド車の混合燃料モード |
| pv2 | 数値 | float | 2ドアの乗員容量(立方フィート) |
| pv4 | 数値 | float | 4ドアの乗員容量(立方フィート) |
| range | 数値 | float | 航続距離 |
| rangeCity | 数値 | float | 市街地での航続距離 |
| rangeCityA | 数値 | float | fuelType2 の市街地での航続距離 |
| rangeHwy | 数値 | float | 高速での航続距離 |
| rangeHwyA | 数値 | float | fuelType2 の高速での航続距離 |
| trany | カテゴリ | object | トランスミッションの種類 |
| UCity | 数値 | float | fuelType1 の未調整市街地燃費(MPG) |
| UCityA | 数値 | float | fuelType2 の未調整市街地燃費(MPG) |
| UHighway | 数値 | float | fuelType1 の未調整高速燃費(MPG) |
| UHighwayA | 数値 | float | fuelType2 の未調整高速燃費(MPG) |
| VClass | カテゴリ | object | 車両クラス |
| year | 数値 | int | 製造年 |
| youSaveSpend | 数値 | float | 平均車両との5年間の燃料コスト差 |
| baseModel | カテゴリ | object | ベースモデル名 |
| trans_dscr | カテゴリ | object | トランスミッションの詳細 |
| atvType | カテゴリ | object | 代替燃料または先進技術車のタイプ |
| rangeA | 数値 | float | fuelType2 の航続距離 |
| evMotor | 数値 | float | 電気モーターの出力(kWh) |
| mfrCode | カテゴリ | object | メーカーコード |
| c240Dscr | カテゴリ | object | 240V充電器の説明 |
| charge240b | 数値 | float | 240Vの代替充電時間(時間) |
| c240bDscr | カテゴリ | object | 代替240V充電器の説明 |
| createdOn | カテゴリ | object | レコード作成日 |
| modifiedOn | カテゴリ | object | レコード更新日 |
| startStop | カテゴリ | object | アイドリングストップ機能(Y: あり, N: なし, 空白は不明) |
| phevCity | 数値 | float | 市街地走行時のPHEV複合燃費(MPGe) |
| phevHwy | 数値 | float | 高速走行時のPHEV複合燃費(MPGe) |
| phevComb | 数値 | float | 統合走行時のPHEV複合燃費(MPGe) |
| mean_emissions_score | 数値 | float | 排出ガスのクリーンさスコア |
【目的変数】
1~10となる自動車の排出ガスのクリーンさスコア「mean_emissions_score」
【評価指標】
MSE(Mean Squared Error)が使用されます。
MSEは平均二乗誤差と呼ばれ、予測値と実測値の二乗誤差を平均した指標です。
スコアの範囲は0〜♾️となり値が小さいほど精度が高くなります。
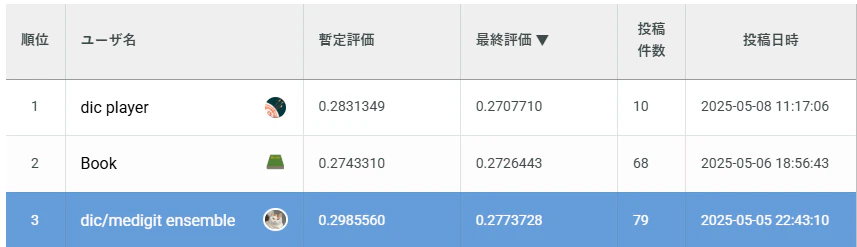
3rd Place Solutionの得点
Public LBは0.29台で8位ぐらいだったが、まさか最終結果として、Private LBでは0.27台になり、3位を獲得できました。
ではこれから解法を説明していきマス!!
EDA
探索的なデータ分析には時間をかけすぎずに、何点かだけ確認しました。
- 燃料タイプ(atvType)とその平均スコア(mean_emissions_score)
FCV(水素)の車は必ず10点なのと、EVはほぼ10点、Bifuel(CNG)は1点なのがわかる。

- trainデータとtestデータの分布比較
いくつかの説明変数において、trainデータとtestデータの分布を比較してみた結果、分布は近似しておいり、データは均衡的に分けられたことがわかる。
| 凡例 | 説明 |
|---|---|
| 1 | trainデータ |
| No value | testデータ |
| 図 | 比較する説明変数 |
|---|---|
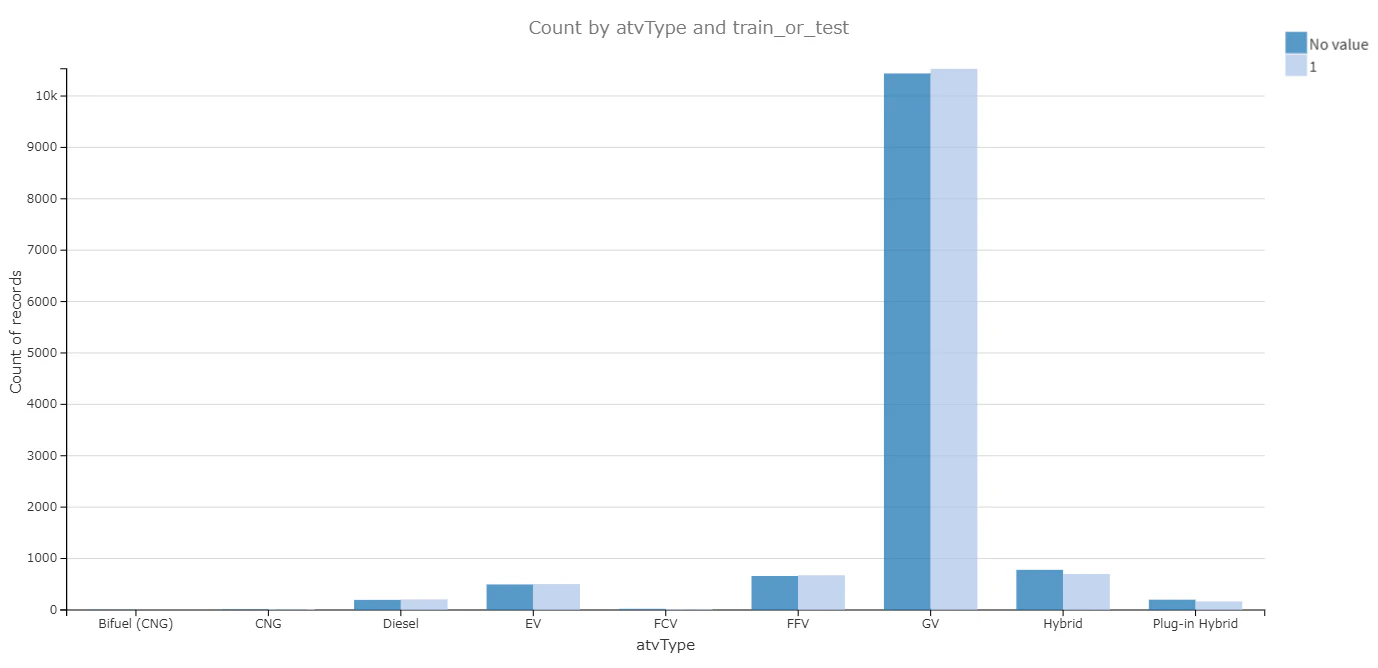 |
車タイプ(atvType) |
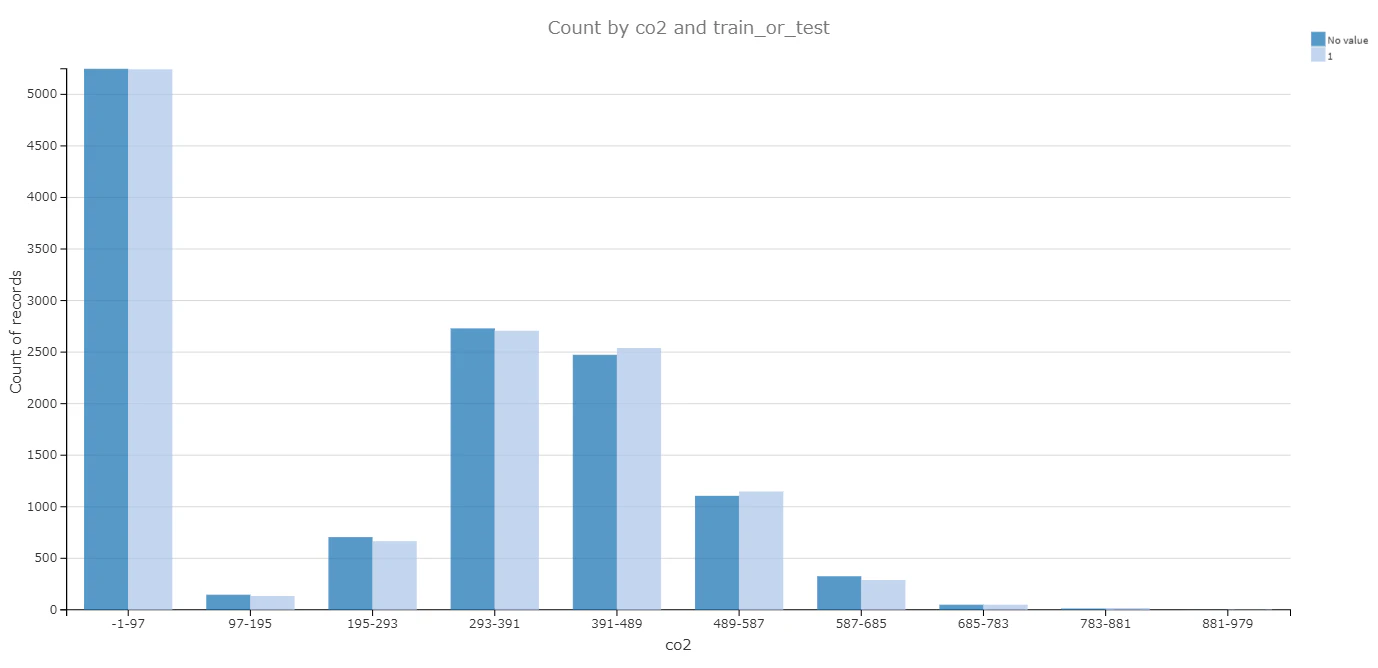 |
fuelType1 のCO2排出量(co2) |
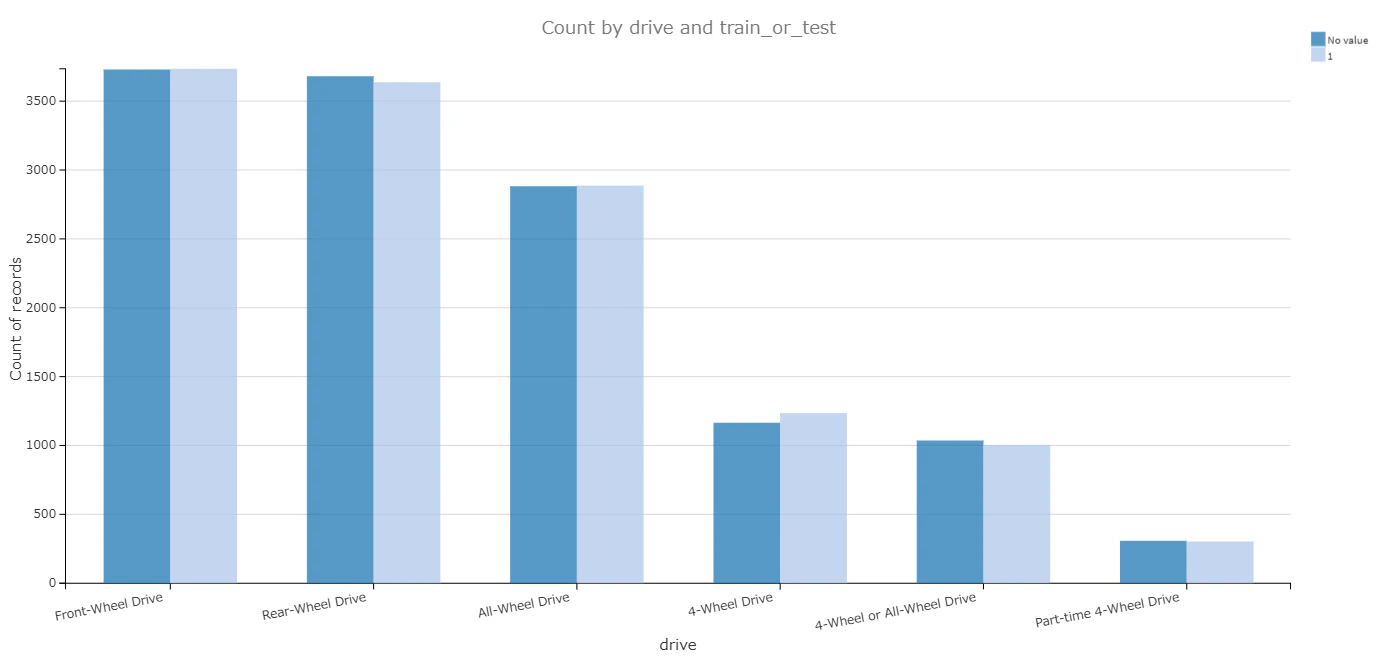 |
駆動方式(drive) |
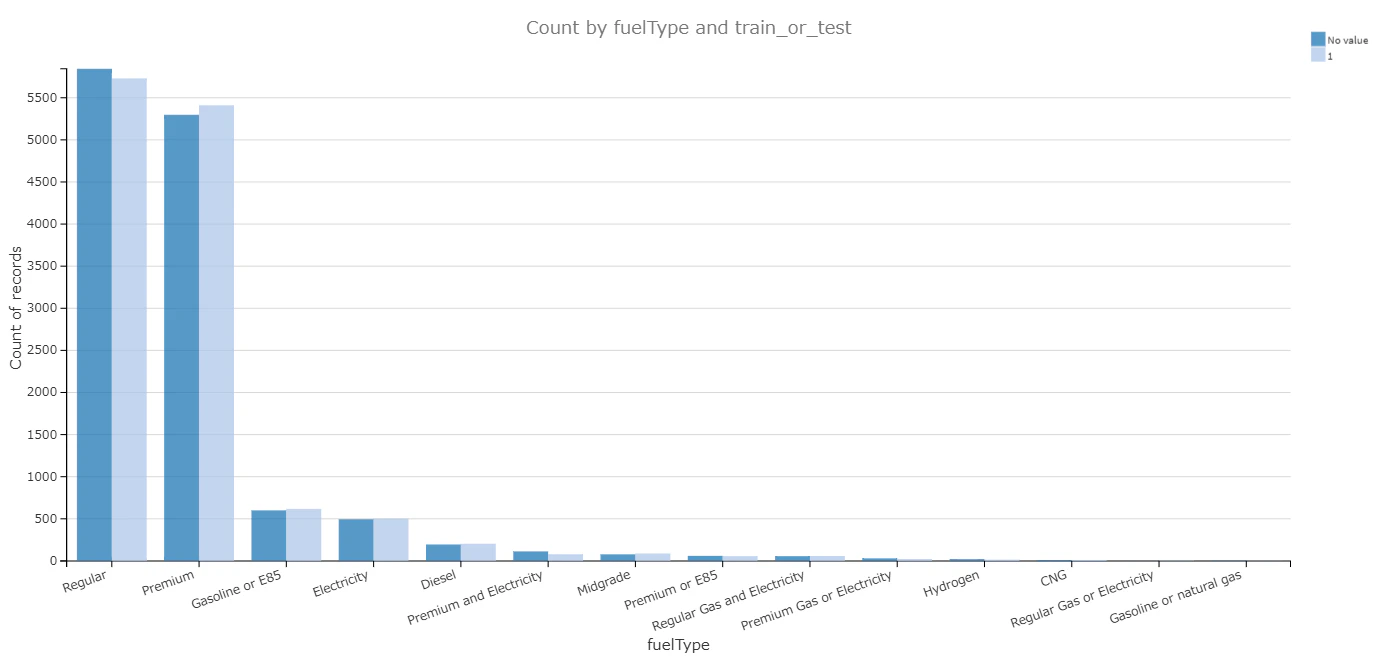 |
燃料タイプ(fuelType) |
 |
メーカー(make) |
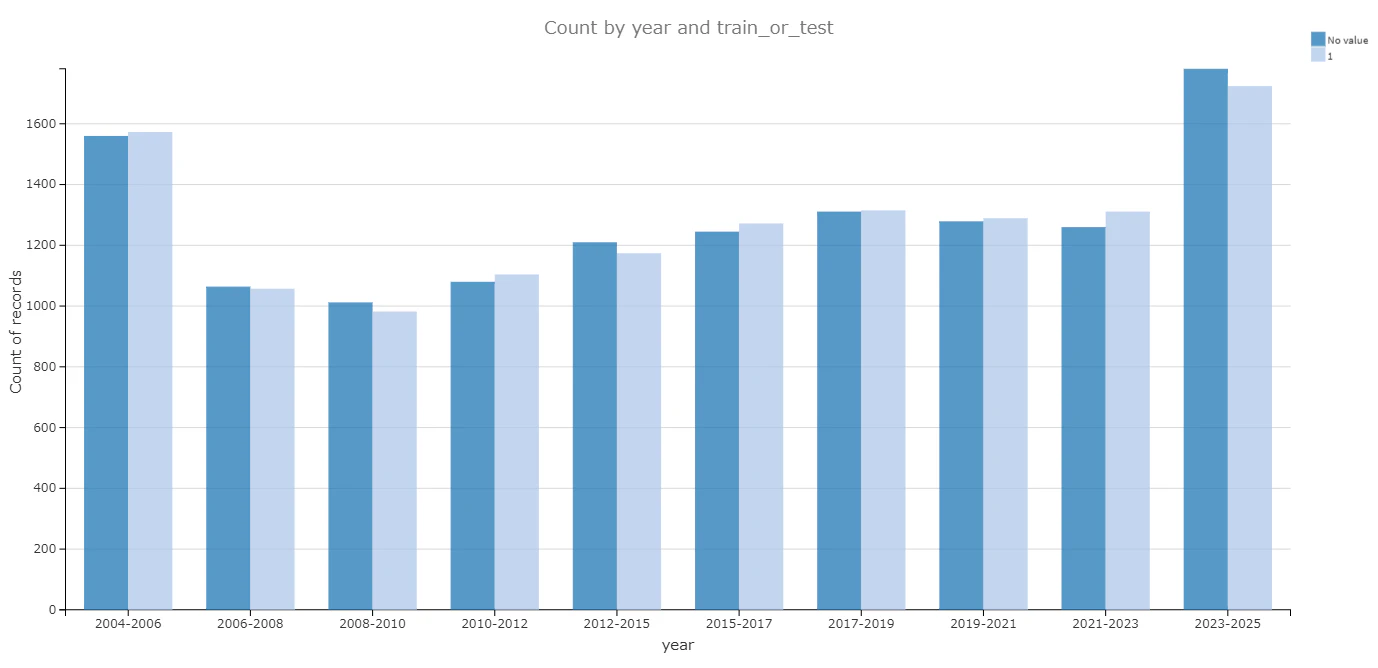 |
年式(year) |
解法全体像
今回の解法をまとめると、異なる前処理(特徴量エンジニアリング)やモデリングを組み合わせて、学習モデルを5つ構築しました。さらにその5つの予測結果を重み付けアンサンブルして、最終結果として提出しました。
なお、5つともそこそこのPublic LB点数を果たしています。
各予測結果の点数を以下通りに示す。
| 番号 | Public LB | Private LB |
|---|---|---|
| 1 | 0.3021662 | 0.2822900 |
| 2 | 0.3074729 | 0.2868888 |
| 3 | 0.3175393 | 0.2932733 |
| 4 | 0.3301958 | 0.3059331 |
| 5 | 0.3374862 | 0.3091291 |
※Submission5に関してはDataikuを利用しましたので、Submission5の解法は以下の記事をご覧ください。
以降は、Submission1~4の詳細を説明していきます。
前処理
各前処理で実施したことを以下のテーブルにまとめました。詳細は下方のコードでご参照ください。
ポイントとしてはとりあえず異なる前処理で予測モデルを構築しました。
| 番号/項目 | 前処理1 | 前処理2 | 前処理3 |
|---|---|---|---|
| 特徴量エンジニアリング | ・各種特徴量の組み合わせ(加減乗除)ver3 ・いらない特徴量削除 ・値が「-1」になっているのものを欠損とする |
・各種特徴量の組み合わせ(加減乗除)ver2 | ・各種特徴量の組み合わせ(加減乗除)ver3 |
| カテゴリ変数のエンコード | Label Encoding + One-hot併用 (カテゴリ変数のユニーク数が5以上の場合はラベルエンコーディングに、それ以外はone-hotエンコーディング)l |
〃 | 〃 |
| 欠損値対処 | 各特徴量に対して、atvTypeごとの平均値で欠損を埋める | なし | なし |
# 📚 ライブラリ読み込み
import matplotlib.pyplot as plt
import seaborn as sns
# 📥 データ読み込み
train = pd.read_csv("input/train.csv")
test = pd.read_csv("input/test.csv")
前処理1
# 数値変数をカテゴリ変数に層化
def mpg_to_rating(mpg):
if mpg >= 121:
return 10
elif mpg >= 66:
return 9
elif mpg >= 45:
return 8
elif mpg >= 34:
return 7
elif mpg >= 28:
return 6
elif mpg >= 22:
return 5
elif mpg >= 18:
return 4
elif mpg >= 16:
return 3
elif mpg >= 14:
return 2
else:
return 1
def co2_to_rating(co2):
if co2 <= 74:
return 10
elif co2 <= 136:
return 9
elif co2 <= 200:
return 8
elif co2 <= 265:
return 7
elif co2 <= 323:
return 6
elif co2 <= 413:
return 5
elif co2 <= 508:
return 4
elif co2 <= 573:
return 3
elif co2 <= 658:
return 2
else:
return 1
#特徴量エンジニアリング
def add_features(df):
# -1のものを欠損とする
df["co2"] = df["co2"].apply(lambda x: np.nan if x == -1 else x)
df["co2A"] = df["co2A"].apply(lambda x: np.nan if x == -1 else x)
df["feScore"] = df["feScore"].apply(lambda x: np.nan if x == -1 else x)
df["ghgScore"] = df["ghgScore"].apply(lambda x: np.nan if x == -1 else x)
df["ghgScoreA"] = df["ghgScoreA"].apply(lambda x: np.nan if x == -1 else x)
# 対象の特徴量列(atvTypeを除く)
# df['atvType'] = df['atvType'].fillna('GV')
features = df.select_dtypes(include=["number"]).columns.difference(['atvType', 'mean_emissions_score'])
# print(features)
# 各特徴量に対して、atvTypeごとの平均値で欠損を埋める
for col in features:
mean_dict = stack_df.groupby('atvType')[col].mean().to_dict()
df[col] = df.apply(
lambda row: mean_dict[row['atvType']] if pd.isna(row[col]) and row['atvType'] in mean_dict else row[col],
axis=1
)
# 1. 燃費/コスト効率
df["mpg_per_dollar"] = df["comb08"] / (df["fuelCost08"] + 1)
df["mpgA_per_dollar"] = df["combA08"] / (df["fuelCostA08"] + 1)
# 交互作用の組み合わせ例
df["displ_per_cylinder"] = df["displ"] / (df["cylinders"] + 1)
df["barrels_per_mpg"] = df["barrels08"] / (df["comb08"] + 1)
df["co2_per_mpg"] = df["co2"] / (df["comb08"] + 1)
# 2. 年間CO2排出量(燃料消費 × 単位CO2)
df["annual_co2"] = df["co2"] * df["barrels08"]
df["annual_co2A"] = df["co2A"] * df["barrelsA08"]
# 3. 燃費差分
df["mpg_diff_city"] = df["city08"] - df["cityA08"]
df["mpg_diff_highway"] = df["highway08"] - df["highwayA08"]
df["mpg_diff_comb"] = df["comb08"] - df["combA08"]
# 4. EV充電効率(距離 ÷ 時間)
df["electric_efficiency"] = df["range"] / (df["charge240"] + 1)
df["electric_efficiency_b"] = df["range"] / (df["charge240b"] + 1)
# 5. 平均ユーティリティファクター
df["avg_utility_factor"] = df[["cityUF", "highwayUF", "combinedUF"]].mean(axis=1)
# 6. 排気量 × シリンダー数
df["power_metric"] = df["displ"] * df["cylinders"]
# 7. 総石油使用量
df["total_barrels"] = df["barrels08"] + df["barrelsA08"]
# 8. 車内容量の合計
volume_cols = ["hpv", "hlv", "pv2", "pv4", "lv2", "lv4"]
df["total_volume"] = df[volume_cols].sum(axis=1)
# 9. カテゴリ交差特徴量
df["fuel_vclass"] = df["fuelType1"].astype(str) + "_" + df["VClass"].astype(str)
df["drive_trany"] = df["drive"].astype(str) + "_" + df["trany"].astype(str)
df["fuel_vclass_drive"] = df["fuel_vclass"].astype(str) + "_" + df["drive"].astype(str)
# 10. モデル年齢(最新年からの差)
df["model_age"] = df["year"].max() - df["year"]
# 11. いらない特徴量削除
df = df.drop(['city08U', 'cityA08U' ,'comb08U', 'combA08U', 'highway08U', 'highwayA08U',
'baseModel', 'trans_dscr', 'c240Dscr', 'c240bDscr',
'createdOn', 'modifiedOn'], axis=1)
# 3. 燃費合計
df["mpg_add_city"] = df["city08"] + df["cityA08"]
df["mpg_add_highway"] = df["highway08"] + df["highwayA08"]
df["mpg_add_comb"] = df["comb08"] + df["combA08"]
# 4. 排出co2合計
df["add_co2"] = df["co2"] + df["co2A"]
df["add_co2TailpipeGpm"] = df["co2TailpipeGpm"] + df["co2TailpipeAGpm"]
# 数値変数をカテゴリに変更の適用(MPG列名とCO2列名は適宜変更)
df['city08_rating'] = df["city08"].apply(mpg_to_rating)
df['cityA08_rating'] = df["cityA08"].apply(mpg_to_rating)
df['highway08_rating'] = df["highway08"].apply(mpg_to_rating)
df['highwayA08_rating'] = df["highwayA08"].apply(mpg_to_rating)
df['comb08_rating'] = df["comb08"].apply(mpg_to_rating)
df['combA08_rating'] = df["combA08"].apply(mpg_to_rating)
df['co2_rating'] = df['co2'].apply(co2_to_rating)
df['co2A_rating'] = df['co2A'].apply(co2_to_rating)
df['co2TailpipeGpm_rating'] = df['co2TailpipeGpm'].apply(co2_to_rating)
df['co2TailpipeAGpm_rating'] = df['co2TailpipeAGpm'].apply(co2_to_rating)
return df
# 特徴量追加の適用
train = add_features(train)
test = add_features(test)
前処理2
#特徴量エンジニアリング
def clean_rangeA(x):
try:
if isinstance(x, str) and '/' in x:
parts = x.split('/')
return (float(parts[0]) + float(parts[1])) / 2
else:
return float(x)
except:
return np.nan
def add_features(df):
df["rangeA"] = df["rangeA"].apply(clean_rangeA)
# 10. モデル年齢(最新年からの差)
df["model_age"] = df["year"].max() - df["year"]
# 8. 車内容量の合計
volume_cols = ["hpv", "hlv", "pv2", "pv4", "lv2", "lv4"]
df["total_volume"] = df[volume_cols].sum(axis=1)
# 1. 燃費/コスト効率
df["mpg_per_dollar"] = df["comb08"] / (df["fuelCost08"] + 1)
df["mpgA_per_dollar"] = df["combA08"] / (df["fuelCostA08"] + 1)
df["fuel_cost_ratio"] = (df["fuelCost08"] + 1) / (df["fuelCostA08"] + 1)
# 交互作用の組み合わせ例
df["displ_per_cylinder"] = df["displ"] / (df["cylinders"] + 1)
df["barrels_per_mpg"] = df["barrels08"] / (df["comb08"] + 1)
df["co2_per_mpg"] = df["co2"] / (df["comb08"] + 1)
df["mpg_per_model_age"] = df["comb08"] / (df["model_age"] + 1)
df["co2_per_volume"] = df["co2"] / (df["total_volume"] + 1)
# 2. 年間CO2排出量(燃料消費 × 単位CO2)
df["annual_co2"] = df["co2"] * df["barrels08"]
df["annual_co2A"] = df["co2A"] * df["barrelsA08"]
# 3. 燃費差分
df["mpg_diff_city"] = df["city08"] - df["cityA08"]
df["mpg_diff_highway"] = df["highway08"] - df["highwayA08"]
df["mpg_diff_comb"] = df["comb08"] - df["combA08"]
# 4. EV充電効率(距離 ÷ 時間)
df["electric_efficiency"] = df["range"] / (df["charge240"] + 1)
df["electric_efficiency_b"] = df["range"] / (df["charge240b"] + 1)
df["charge_range_efficiency"] = df["rangeA"].astype(float) / (df["charge240"] + 1)
# 5. 平均ユーティリティファクター
df["avg_utility_factor"] = df[["cityUF", "highwayUF", "combinedUF"]].mean(axis=1)
# 6. 排気量 × シリンダー数
df["power_metric"] = df["displ"] * df["cylinders"]
# 7. 総石油使用量
df["total_barrels"] = df["barrels08"] + df["barrelsA08"]
# 9. カテゴリ交差特徴量
df["fuel_vclass"] = df["fuelType1"].astype(str) + "_" + df["VClass"].astype(str)
df["drive_trany"] = df["drive"].astype(str) + "_" + df["trany"].astype(str)
df["fuel_vclass_drive"] = df["fuel_vclass"].astype(str) + "_" + df["drive"].astype(str)
# 異常検知用:極端値フラグ
# 燃費が極端に良いor悪い車、異常なco2排出車
df["high_co2_flag"] = (df["co2"] > df[df["co2"]!=-1]["co2"].quantile(0.95)).astype(int)
df["low_mpg_flag"] = (df["comb08"] < df["comb08"].quantile(0.05)).astype(int)
return df
# 特徴量追加の適用
train = add_features(train)
test = add_features(test)
前処理3
#特徴量エンジニアリング
def add_features(df):
# 1. 燃費/コスト効率
df["mpg_per_dollar"] = df["comb08"] / (df["fuelCost08"] + 1)
df["mpgA_per_dollar"] = df["combA08"] / (df["fuelCostA08"] + 1)
# 交互作用の組み合わせ例
df["displ_per_cylinder"] = df["displ"] / (df["cylinders"] + 1)
df["barrels_per_mpg"] = df["barrels08"] / (df["comb08"] + 1)
df["co2_per_mpg"] = df["co2"] / (df["comb08"] + 1)
# 2. 年間CO2排出量(燃料消費 × 単位CO2)
df["annual_co2"] = df["co2"] * df["barrels08"]
df["annual_co2A"] = df["co2A"] * df["barrelsA08"]
# 3. 燃費差分
df["mpg_diff_city"] = df["city08"] - df["cityA08"]
df["mpg_diff_highway"] = df["highway08"] - df["highwayA08"]
df["mpg_diff_comb"] = df["comb08"] - df["combA08"]
# 4. EV充電効率(距離 ÷ 時間)
df["electric_efficiency"] = df["range"] / (df["charge240"] + 1)
df["electric_efficiency_b"] = df["range"] / (df["charge240b"] + 1)
# 5. 平均ユーティリティファクター
df["avg_utility_factor"] = df[["cityUF", "highwayUF", "combinedUF"]].mean(axis=1)
# 6. 排気量 × シリンダー数
df["power_metric"] = df["displ"] * df["cylinders"]
# 7. 総石油使用量
df["total_barrels"] = df["barrels08"] + df["barrelsA08"]
# 8. 車内容量の合計
volume_cols = ["hpv", "hlv", "pv2", "pv4", "lv2", "lv4"]
df["total_volume"] = df[volume_cols].sum(axis=1)
# 9. カテゴリ交差特徴量
df["fuel_vclass"] = df["fuelType1"].astype(str) + "_" + df["VClass"].astype(str)
df["drive_trany"] = df["drive"].astype(str) + "_" + df["trany"].astype(str)
df["fuel_vclass_drive"] = df["fuel_vclass"].astype(str) + "_" + df["drive"].astype(str)
# 10. モデル年齢(最新年からの差)
df["model_age"] = df["year"].max() - df["year"]
return df
# 特徴量追加の適用
train = add_features(train)
test = add_features(test)
カテゴリ変数エンコード
from sklearn.preprocessing import LabelEncoder
# 🔍 カテゴリ変数を抽出(object型、bool型)
cat_cols = X.select_dtypes(include=["object", "bool"]).columns.tolist()
# 👀 カテゴリ変数のユニーク数を確認して分ける
onehot_cols = [col for col in cat_cols if X[col].nunique() <= 5]
labelencode_cols = [col for col in cat_cols if X[col].nunique() > 5]
print("One-Hot Encoding対象列:", onehot_cols)
print("Label Encoding対象列:", labelencode_cols)
# ✏️ Label Encoding
for col in labelencode_cols:
le = LabelEncoder()
# 🧱 結合してfit
combined = pd.concat([X[col], X_test[col]], axis=0).astype(str)
le.fit(combined)
# ✅ それぞれにtransform
X[col] = le.transform(X[col].astype(str))
X_test[col] = le.transform(X_test[col].astype(str))
# 🔥 One-Hot Encoding(get_dummies)
X = pd.get_dummies(X, columns=onehot_cols)
X_test = pd.get_dummies(X_test, columns=onehot_cols)
# 🔁 Train/Testでカラムのズレを揃える
X, X_test = X.align(X_test, join='left', axis=1, fill_value=0)
print("X shape:", X.shape)
print("X_test shape:", X_test.shape)
モデリング
| 番号/項目 | モデリング1 | モデリング2 | モデリング3 | モデリング4 |
|---|---|---|---|---|
| INPUT | 前処理1 | 前処理2 | 前処理3 | 前処理3 |
| クロスバリデーション | KFold(n_splits=5, shuffle=True, random_state=42) | 〃 | 〃 | 〃 |
| アルゴリズム | XGBoost, LightGBM,CatBoost | 〃 | 〃 | 〃 |
| ハイパーチューニング | Optunaによるパラメータ探索 | 〃 | 〃 | 〃 (左記と異なるパラメータ範囲で探索) |
| POSTモデル: StackingModel |
メタモデル1 | メタモデル1 | メタモデル2 | メタモデル2 |
- ハイパーチューニング
Optunaを利用して各アルゴリズムに対してそれぞれ最適なパラメータを探索しました。
ポイントとしては、パラメータの範囲を調整したり、探索回数を増やしたりしました。余談ですが、長時間かかるから、GWの旅行前に探索回数を100にしてプログラムを走らせ、帰宅したら結果を確認することもありました。当たり前のように見えるが、パラメータ範囲調整のコツに関しては以下通りです。
①最適のパラメータの近くで範囲を絞って再探索する
②まったく異なるパラメータ範囲で再探索する
以下はOptunaのサンプルコードです。
Optunaサンプルコード
import optuna
from sklearn.model_selection import cross_val_score, KFold
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import StackingRegressor
from lightgbm import LGBMRegressor
from xgboost import XGBRegressor
from catboost import CatBoostRegressor
# 共通設定
cv = KFold(n_splits=5, shuffle=True, random_state=42)
N_trials=50
# ------------------------------------------
# LightGBM 最適化
# ------------------------------------------
def objective_lgbm(trial):
params = {
"n_estimators": trial.suggest_int("n_estimators", 800, 1000),
"learning_rate": trial.suggest_float("learning_rate", 0.1, 0.2),
"max_depth": trial.suggest_int("max_depth", 8, 15),
"num_leaves": trial.suggest_int("num_leaves", 60, 100),
"min_child_samples": trial.suggest_int("min_child_samples", 1, 100),
"reg_alpha": trial.suggest_float("reg_alpha", 0.0, 1.0),
"reg_lambda": trial.suggest_float("reg_lambda", 0.0, 1.0),
"random_state": 42
}
model = LGBMRegressor(**params)
score = -cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=cv).mean()
return score
study_lgbm = optuna.create_study(direction="minimize")
study_lgbm.optimize(objective_lgbm, n_trials=N_trials)
best_lgbm = LGBMRegressor(**study_lgbm.best_trial.params)
# ------------------------------------------
# XGBoost 最適化
# ------------------------------------------
def objective_xgb(trial):
params = {
"n_estimators": trial.suggest_int("n_estimators", 900, 1200),
"learning_rate": trial.suggest_float("learning_rate", 0.04, 0.1),
"max_depth": trial.suggest_int("max_depth", 8, 15),
"subsample": trial.suggest_float("subsample", 0.8, 1.0),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.6, 0.8),
"reg_alpha": trial.suggest_float("reg_alpha", 0.0, 1.0),
"reg_lambda": trial.suggest_float("reg_lambda", 0.0, 1.0),
"random_state": 42
}
model = XGBRegressor(**params)
score = -cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=cv).mean()
return score
study_xgb = optuna.create_study(direction="minimize")
study_xgb.optimize(objective_xgb, n_trials=N_trials)
best_xgb = XGBRegressor(**study_xgb.best_trial.params)
# ------------------------------------------
# CatBoost 最適化
# ------------------------------------------
def objective_cat(trial):
params = {
"iterations": trial.suggest_int("iterations", 700, 1000),
"learning_rate": trial.suggest_float("learning_rate", 0.1, 0.3),
"depth": trial.suggest_int("depth", 6, 12),
"l2_leaf_reg": trial.suggest_float("l2_leaf_reg", 1.0, 10.0), # CatBoost専用の正則化
"random_state": 42,
"verbose": 0
}
model = CatBoostRegressor(**params)
score = -cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=cv).mean()
return score
study_cat = optuna.create_study(direction="minimize")
study_cat.optimize(objective_cat, n_trials=N_trials)
best_cat = CatBoostRegressor(**study_cat.best_trial.params)
- スタッキングモデル
今回のコンペでは三つのアルゴリズムをさらにStackingModelに適応した方が、効果が良かったです。スタッキングモデルのメタモデルを変えてみて精度を確認するのも役に立ちました。ElasticNetはRidgeより精度が上がったのですが、LightGBMは逆に精度が下がる結果になっていました。
なお、メタモデルについてもOptunaすれば最適メタモデルを見つけるのですが、時間に対して効果が低そうなので今回は実施していません。
メタモデル1
#メタモデル1
meta_model = ElasticNet(alpha=0.01, l1_ratio=0.5, random_state=42)
メタモデル2
#メタモデル2
meta_model = Ridge(random_state=42)
StackingModel
# ------------------------------------------
# スタッキングモデル構築
# ------------------------------------------
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
stack_model = StackingRegressor(
estimators=[
# ('tabnet', best_tab),
("lgbm", best_lgbm),
("xgb", best_xgb),
("cat", best_cat)
],
final_estimator=meta_model,
cv=cv,
# n_jobs=-1,
n_jobs=1,
verbose=0
)
# 学習&予測
stack_model.fit(X, y)
pred = stack_model.predict(X_test)
後処理
提出する前に必ず予測値に対して、以下の後処理を行いました。効果はわずかですが精度は上がります。
- mean_emissions_score を 1 ~ 10 の範囲に制限
- atvType が 'FCV' の行の mean_emissions_score を 10 に調整
- atvType が 'EV' で mean_emissions_score が quantile0.05 以上の値を 10 に調整
後処理サンプルコード
# submission と test を id カラムで結合
# submission = pd.read_csv("output/submission_.csv")
merged_df = submission.merge(test[['id', 'atvType']], on='id', how='left')
# 1. mean_emissions_score を 1 ~ 10 の範囲に制限
merged_df['mean_emissions_score'] = merged_df['mean_emissions_score'].clip(1, 10)
# atvType が 'FCV' の行の mean_emissions_score を 10 に調整
merged_df.loc[merged_df['atvType'] == 'FCV', 'mean_emissions_score'] = 10
# atvType が 'EV' で mean_emissions_score が quantile0.05 以上の行を 10 に調整
q = merged_df[merged_df['atvType'] == 'EV']['mean_emissions_score'].quantile(0.005)
merged_df.loc[(merged_df['atvType'] == 'EV') & (merged_df['mean_emissions_score'] >= q), 'mean_emissions_score'] = 10
# 必要なカラムだけ残す
final_submission = merged_df[['id', 'mean_emissions_score']]
# 保存する(例えばCSVに)
final_submission.to_csv('output/submission_noheader_post.csv', index=False, header=False)
最後に
コンペの感想
大変やさしく設計されたコンペと実感し、大変勉強になりましたし、GW中にも頑張った価値があったと感じます。あとはChatGPTに頼りことが多く、時代が変わったと実感しました。