1. はじめに
阿澄佳奈さんは言わずと知れた人気の声優さんです。僕は世界一好きです。詳しく書くと長くなるのでWiki見たり星ひなとかキミまち!を聞こう(ひだまらーなので、ランティスネットラジオがなくなってもひだまりラジオがまだ聞けるのが本当にありがたいです)。聞けばわかるが、阿澄佳奈さんは疲れた月曜の夜や日曜の朝に私達を元気づけてくれます。女神かな?
井口裕香さんはそんな阿澄さんの親友です。彼女も月曜の夜にラジオをやっています。癒やしです。
しかし、声優に詳しくない人はもしかしたら声で判別することができないかも知れない。きっと「どんな人?」とか言いながら写真を検索するでしょう。その時、もしも違う人の写真を見て阿澄佳奈と勘違いしてしまったら?その人はずっとよくわからない誰かを阿澄さんだと思いながら生活するのでしょうか?考えるだけでゾッとします。せっかく調べる程度には興味を持ってくれたんだから、ちゃんと知ってほしいと思ってしまいます。
なので、とりあえず阿澄佳奈さんとその親友たる井口裕香さんを分類する畳み込みニューラルネットワークを構築し、学習を行いました。プログラミングも機械学習も初心者過ぎて話にならないのですが、やってみました。
2. 画像の取得
画像をスクレイピングで取ってきたいのですが、イマイチわかっていないので大変お手軽に画像を拾ってこれる、icrawlerを使いました。この記事を大変参考にさせてもらいました。この場で感謝申し上げます。ソースコードは以下のようになります。
2.1 icrawlerのインストール
pipで簡単にインストールできます。
~$ pip install icrawler
# 実行する時は
# ~$ python crawler.py 保存したいディレクトリ 画像のキーワード
# 実行後に最大取得枚数を聞かれます
from icrawler.builtin import GoogleImageCrawler
import sys
import os
argv = sys.argv
if __name__ == "__main__":
if not os.path.isdir(argv[1]):
os.makedirs(argv[1])
max_num = int(input("max_num:"))
crawler = GoogleImageCrawler(storage = {"root_dir" : argv[1]})
crawler.crawl(keyword = argv[2], max_num = max_num)
これで阿澄さんと井口さんの画像を収集します。結果として大体300枚ずつくらい集めました。
3. 顔の切り出し
実際にいろんなサイズの画像から阿澄さんと井口さんを認識するのは難しそうだったので、顔をOpenCVのhaarcascades/haarcascade_frontalface_alt.xmlで認識して$100\times100$にリサイズしました。なお、一緒に写った人とかスタバのコーヒカップの女神とかを顔として認識してしまっていたので、これは手作業で消しました(一番大変だった)。
import os
import numpy as np
import cv2
# 入力ファイルのパスを指定
in_jpg = "asumi/" #icrawlerで取ってきた阿澄さんの画像があるディレクトリ
out_jpg = "out_asumi/" #切り出した阿澄さんの画像を保存するディレクトリ
# リストで結果を返す関数
def get_file(dir_path):
filenames = os.listdir(dir_path)
return filenames
pic = get_file(in_jpg)
for i in pic:
# 画像の読み込み
image_gs = cv2.imread(in_jpg + i)
# 顔認識用特徴量ファイルを読み込む --- (カスケードファイルのパスを指定)
cascade = cv2.CascadeClassifier("///home/~path~/haarcascades/haarcascade_frontalface_alt.xml")
# 顔認識の実行
face_list = cascade.detectMultiScale(image_gs,scaleFactor=1.1,minNeighbors=1,minSize=(1,1))
# 顔だけ切り出して保存
no = 1;
for rect in face_list:
x = rect[0]
y = rect[1]
width = rect[2]
height = rect[3]
dst = image_gs[y:y + height, x:x + width]
save_path = out_jpg + '/' + 'out_{}_no{}'.format(i, no)
#認識結果の保存
a = cv2.imwrite(save_path, dst)
print(no)
no += 1
"""顔写真を100×100にリサイズする"""
in_jpg = "out_asumi/" #阿澄さん以外の顔は削除しておく
out_jpg = "resize_asumi/" #リサイズした画像を入れるディレクトリ
pic = get_file(in_jpg)
for i in range(len(pic)):
img = cv2.imread(in_jpg + pic[i])
resize_img = cv2.resize(img, (100, 100))
save_path = out_jpg + 'out_{}.jpg'.format(i+1)
print(save_path)
cv2.imwrite(save_path, resize_img)
こんな感じで顔だけの画像を取得しました。しかしこれで集められたのは全部で500枚程度の画像しかなく、テストようにいくらか抜くことを考えると心もとない…。
なので、水増ししました。
正直画像処理とかまだまだ勉強中でわからないことだらけだったので、こちらを参考にさせていただきました。テスト用の画像も水増しするのは良くないと思ったので、40枚くらいあらかじめ画像を抜いておいてコントラスト調整で枚数を2倍にしました。さて、いよいよ学習に入ります。
4. CNNのモデル構築と評価
シンプルなCNNを構築しました。Kerasは簡単にニューラルネットが組めるので好き。というか今の所これしか使えないので…。
# coding: utf-8
import numpy as np
import pandas as pd
import keras
from keras.models import Sequential
from keras.layers import Dense, Convolution2D, MaxPooling2D, Dropout, Flatten, Activation
model = Sequential()
model.add(Convolution2D(16, 3, 3, border_mode="same", input_shape=(100, 100, 3, )))
model.add(Activation("relu"))
model.add(Convolution2D(16, 3, 3, border_mode="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Dropout(0.5))
model.add(Convolution2D(32, 3, 3, border_mode="same"))
model.add(Activation("relu"))
model.add(Convolution2D(32, 3, 3, border_mode="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Dropout(0.5))
model.add(Convolution2D(64, 3, 3, border_mode="same"))
model.add(Activation("relu"))
model.add(Convolution2D(64, 3, 3, border_mode="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D())
model.add(Dropout(0.5))
model.add(Convolution2D(128, 3, 3, border_mode="same"))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(100))
model.add(Activation("relu"))
model.add(Dropout(0.3))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss="binary_crossentropy", metrics = ["accuracy"], optimizer = "adam")
model.summary()だとこんな感じです。

これで50エポックほど学習させました。結果はこんな感じ。
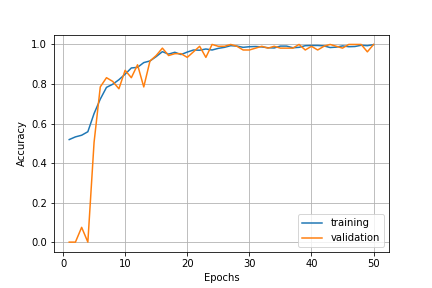
かなりうまく収束しているように見えます。実際ほぼ100%の精度でした。これにテストデータを読み込ませると・・・。
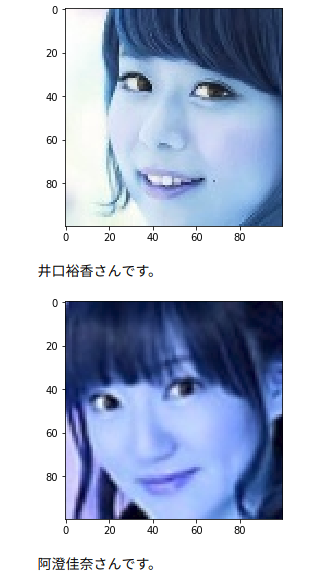
こんな感じで阿澄さんと井口さんを判別できていました(画像の下に誰かを出力するようにした)。精度は82%くらい。
とりあえずそれなりの精度で阿澄さんと井口さんを見分けるモデルができました!やったね!
5. まとめ
今回は、icrawlerで阿澄さんと井口さんの画像を収集し、OpenCVによって顔のみを切り出し、データの不足を水増しによってカバー、そしてKerasで構築したCNN(畳み込みニューラルネットワーク)で学習させるという流れで進みました。今まで書籍等でインプットしてきたことを最大限アウトプットすることができたと思っています。
反省としては、訓練データでは100%近く出したモデルでしたが、テストデータでは80%台まで落ちてしまいました。これはひとえに画像が少なく、訓練データに過剰に適合してしまったためだと考えられます。これがさらなる水増しによって改善されるかどうかはまだ試していませんが、ある程度は改善するでしょう。
6. その他
[1] コード全体(GitHub) …いろいろ試しながら作ったので汚い&ipynbファイルで見れない時ある&なんかエラー吐いてるけどそれでもよろしければ。というかipynbをGitHubに上げると、見えるやつと見えないやつがあるのわけわからない。誰か違いを教えてください。
[2]阿澄日和…阿澄佳奈さんのブログ。更新は控えめ。