この記事の見どころ
プロンプトの調整って意外と面倒くさいんだよな...
そんな自分に刺さったものが今回紹介する『Agentic Context Engineering(ACE)』です。
自分でプロンプトの善し悪しを判断し、戦略を改善していく手法です。
人間の介入なし/モデルの重みの更新なしにエージェントが自己改善するというこの発想は、手間を省きながらプロンプトエンジニアリングを新しい段階に押し上げるでしょう。
参考論文
今回は
"Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models"
(エージェント的コンテキスト設計:自己改善する言語モデルのための文脈進化)という論文をもとに記事を作成しています。
論文の内容
ACEの概要
ACEは、LMが自律的にプロンプトを進化させるための新しい枠組です。
従来のLLMはモデルの重みを変更するファインチューニングによって再学習するものが主でしたが、この論文は重みの変更なしに性能向上を実現しています。
ファインチューニング自体は性能向上に寄与する重要な技術でしたが下記のような課題がありました。
- コストと継続性の問題
- 忘却と過適合
- フィードバックループの欠如
ACEはそのような課題を解決するために生まれた技術で下記のような特徴があります。
- 文脈(context)を更新対象にすることで、重みを再学習せずに"軽量な学習"を実現している
- 反省機能によって、「何を学ぶか/何を保持すべきか」を文脈レベルで制御しており、Grow-and-Refine機能によって古いルールを統合しながら進化可能
- Reflector機能で失敗原因を自然言語で特定。Curatorがそれをプレイブックに統合することでモデル自身が反省→改善のループを持つ
論文内では、ファインチューニングとの直接比較はされていないものの、『ACEは再学習を行わずに、同党もしくはそれ以上のタスク性能向上を実現し、汎用性を損なわない』と結論付けられています。
ACEの原理
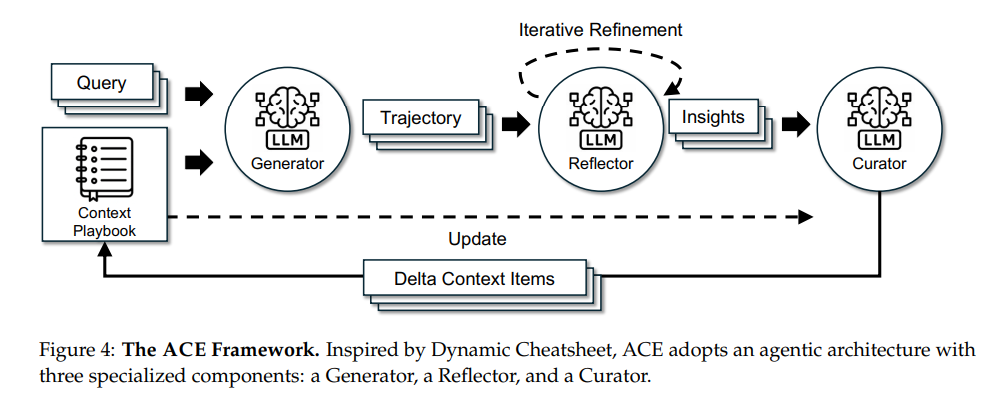
冒頭にも載せている図が本論文の肝となる部分です。
ここを中心にACEがどのように動いているかを整理していきます。
先に流れを説明すると、Queryを受けたGeneratorがタスクを実行し、Reflectorがその過程を分析して改善点を抽出、Curatorがそれを『Delta Context』としてPlaybookに統合しています。
このループを繰り返すことによってモデルは重みを更新せずに自ら学習を続ける仕組みとなっています。
さらにACEでは、Incremental Delta Update(差分更新)とGrow-and-Refine機構によって、文脈崩壊や冗長化を防ぎながら進化を続けることができます。
下記においてそれぞれの要素を解説していきます。
Query
ユーザーの入力です。
普段ChatGPTに何かを聞くように、ユーザーから多様な問い・指示が入力される想定です。
Generator
ChatGPTのように応答を生成するLLMモジュールです。
Playbookをシステムプロンプトとして受け取り、ユーザーからの問いに答えます。
ユーザーのQuery、生成結果のResultのほかに、Generatorが生成した"plan-execution-result"という一連のTrajectory(行動軌跡)をReflectorに渡す役割も担っています。
Reflector
Generatorが出した回答や思考過程を振り返り、成功失敗の要因を分析し、次回の改善に使えるinsight(知見)を言語化するモジュールです。
システム自体のメタ認知モジュールとして使われており、ここで出力されたinsightがCuratorを介してPlaybookに統合されることによりエージェント全体の学習と成長に寄与しています。
Curator
Reflectorから得たinsightからplaybookを生成・統合する役割を担うモジュールです。
ここで重要なのがplaybookの生成方法で、直接生み出しているわけではありません。
既存playbookの中身を埋め込みベクトル空間にマッピングしており、新しく入ってきたinsightも埋め込み処理されます。
そして冗長性削減や過去知見との矛盾解消などを行って最適化された埋め込みベクトルを自然言語に戻すことでplaybookを生成しています。
また、incremental delta updatesという機構を持っており、Reflectorが抽出した学びをCuratorが差分としてPlaybookに統合するという処理になっています。
この構造によって、高精度な意味統合を低コストで行いつつ、LLMが活用できる形式で出力しているのです。
Playbook
Curatorによって生みだされGeneratorのシステムプロンプトとして使用される継続学習メモリです。
システムの長期記憶として活用されており、成功例と失敗例どちらからも学習するため、回数を重ねるごとに精度が高まっていくことが期待できます。
成功例を繰り返すべきプラス要因、失敗例を避けるべきマイナス要因として学習しているため、勾配降下法のような最適化を自然言語で表現しているといえるでしょう。
まとめると、ACEはエージェント的構造を採用したLLMにおける自己改善フレームワークであり、クエリへの出力を成功・失敗で評価し、それぞれの要因を埋め込み処理で学習/統合することによって継続学習を実現しています。
論文の内容がどのような価値を生み出すか
主たる効果は『既存システムのプロンプト最適化』があげられると考えています。
AIエージェントを作成する際プロンプトエンジニアリングにも力を入れていたのですが、何度も変更しているうちに以前試した内容を繰り返してしまったり、意味のない変更をすることが多かったです。
そういった労力を減らしつつ、成功からも失敗からも学ぶことができるACEは、AIエージェントなどの同じ処理を何度も繰り返すシステムと相性がよさそうです。
将来的な話をすると、AGIの一部として活躍できそうな技術だと考えています。
汎用的タスクをこなす際に、環境の変化への適応が課題の一つにあると考えています。
ACEを用いて1つの環境に適応することはもちろん、Playbookの共有による別環境・別タスクへの応用と即時適応が期待されます。
他にも、EUのGDPR、一般データ保護規制などに記載されている削除権(Right to Erasure)への対応も可能な点が大きいと感じています。
Playbookが自然言語で箇条書きされているため、申し立てがあった情報を削除することができます。
この特性のおかげで汎用的な機能の一部として普及することが見込まれます。
この論文の課題
完ぺきに思えるACEですが、論文内で課題にも言及されています。
1つが反省の質に関する限界です。
反省の質は基盤LLMの評価能力に依存しているため、LLM自体がタスク理解を誤っていた場合はReflectorも誤った反省をしてしまいます。
結果として過学習に陥ったり、Playbookそのものが使い物にならなくなる可能性が示唆されています。
2つ目がPlaybookの肥大化です。
いくら知識を統合し整備するCuratorがあるとしても、多様なタスクをこなす中で意味合い的に遠い内容が多くなるとその分Playbookの内容が増加します。
それらが積み重なるとうまく整備できず、冗長性が増えてPlaybookがノイズ化する可能性があります。
3つ目が評価メトリクスの曖昧さです。
ACEは自己改善を主張してはいるものの、その成果をどう定量評価するかはまだ発展途上です。
自己改善をしたといえる基準もなく、タスク間の一般化性能を図る方法も確立していないのが実情のようです。
4つ目がAGI的自律性とのギャップです。
ACEは自分で改善目標を決めているわけではなく、外部からのクエリや評価に基づきます。
AGIにおいては目標設定、価値判断、論理的整合性を合わせた自律的な判断が求められるため、ACE単体ではAGIと程遠い存在と言えそうです。
感想
AGI実現にはまだまだ課題が多そうです。
AIエージェント開発を通じて、AIシステムに関する性能評価や目標設定の自動化の難しさを実感していたところだったこともあり、課題を見てやっぱりむずかしいよなぁと呟いてしまいました。
とはいえAGI実現に近づいている感覚はあるので、次回は目標設定の自動化や価値の判断をどのようにAIにやらせるのかを調べていきたいと思います。