はじめに
「テストコードが昨日まで動いていたのに、UIが少し変わっただけでテスト結果がすべて失敗してしまった(レポート画面が真っ赤になるほどに)…」
こんな経験、ありませんか?
Webアプリの自動テストは、本来なら変更検知と品質保証を助けてくれるはずなのに、実際には UI のちょっとした修正に振り回され、テストコードのメンテナンスに膨大な時間を奪われてしまいます。
セレクタが変わっただけで壊れるテスト、リファクタリングのたびに更新が必要になるスクリプト…。気づけば「テストを書くより修正すること」に追われていませんか?
そこで登場するのが AI駆動の自動テストフレームワーク「AgentiTest」 です。
テストケースを自然言語で記述し、LLM が画面を理解して実行することで、UIが変わっても柔軟に追従できます。つまり「ちょっとしたUI変更で全部のテスト結果のレポートが赤くなる」あの悪夢から解放されるのです。
この記事では、実際に サイトが大幅に変更されたケース を例に取りながら、AgentiTest がどのように問題を解決し、従来の Selenium や Playwright ベースのテストでは実現できなかった“次世代の自動テスト体験”をお見せします。
AndroidアプリのAI駆動の自動テストフレームワーク はこちら
従来のテスト自動化が抱える根本的な課題
「ボタンのIDがちょっと変わっただけでテスト全滅…」
「リリース前にテスト修正で徹夜…」
そんな “あるある” に心当たりはありませんか?
従来の Selenium や Playwright ベースの自動テストは、特定の CSS ID やセレクターに強く依存しているため、UI が少し変わるだけで簡単に壊れてしまいます。結果として、テストが守るべき開発スピードを逆に遅らせてしまうのです。
よくある課題
-
セレクター依存の脆さ
DOM構造がちょっと変わるだけでテストが失敗する -
メンテナンスコストの高さ
UI変更のたびに修正作業が発生し、開発の足かせになる -
ビジネス要件との乖離
「#search-input-123」のようなセレクターは、非エンジニアには意味が分かりづらく、テスト仕様との対応も不明瞭 -
スケールしにくい
画面数や機能が増えるほど、テストの保守が雪だるま式に複雑化
AgentiTestとは?
AgentiTestは、自然言語でテストケースを記述し、LLM(大規模言語モデル)がその意味を理解して実際にテストを実行してくれる次世代フレームワークです。
従来の「セレクター指定」に縛られた fragile なテストとは違い、画面の変化に柔軟に追従できるのが大きな特徴です。
AgentiTestを支える3つの技術
-
browser-use
自然言語をブラウザ操作に変換するエンジン。AIエージェントが人間の代わりに画面をクリックしたり入力したりする。 -
pytest
Python界隈では定番のテストフレームワーク。テストの構造化、パラメータ化、実行管理を担う。 -
Allure Report
単なる「成功 / 失敗」ではなく、ステップごとのスクリーンショットやLLMの思考プロセスまで見える化してくれるレポートツール。
✍️ 自然言語で書くテスト例
従来のように「IDやクラスを指定」する必要はもうありません。
以下のように、人間が書く指示そのままでテストを実行できます。
task = "find the search bar, type 'BigQuery', and press enter"
AgentiTestの環境構築と基本的な使い方
AgentiTestは 数ステップで環境構築が完了します。
環境構築
オリジナル版(Google Gemini 2.5を利用)
git clone https://github.com/kweinmeister/agentitest.git
cd agentitest
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python -m playwright install chromium
# .env ファイルに GOOGLE_API_KEY を設定
cp .env.example .env
OpenAI対応版
git clone https://github.com/aRaikoFunakami/agentitest.git
cd agentitest
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
python -m playwright install chromium
pip install -U langchain-openai openai
export OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
テストの実行
テストの起動はシンプル。コマンド一発でOKです。
pytest
テスト結果の確認
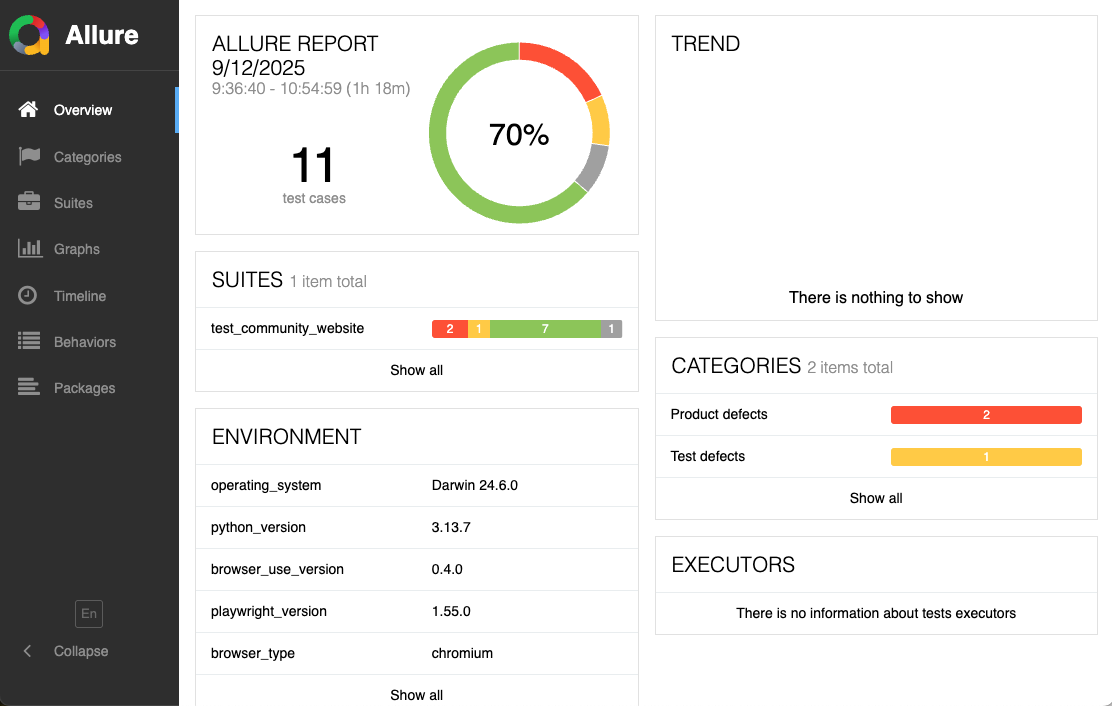
ただの「成功 / 失敗」表示では物足りませんよね?
AgentiTestは Allure と組み合わせることで、スクリーンショット・LLMの思考ログ・実行履歴まで可視化されたリッチなレポートが得られます。
brew install allure # macOSの場合
allure serve allure-results
これでブラウザにインタラクティブなレポートが開き、テスト全体のダッシュボード情報が確認できます。また、テストの一連の流れを「まるで動画を追体験するように」確認できます。各ステップのスクリーンショット、LLMの思考プロセス、実行履歴を詳細に確認できます。
AgentiTestによる課題解決アプローチ
1. セレクター依存からの脱却
従来のアプローチ
# 脆弱なセレクター指定
driver.find_element(By.ID, "search-input-123").send_keys("BigQuery")
driver.find_element(By.CSS_SELECTOR, ".btn-primary.search-btn").click()
AgentiTestのアプローチ
# 自然言語によるタスク定義
task = "find the search bar, type 'BigQuery', and press enter"
browser-useは ReAct (Reason and Act) ループの核心的な動作として、エージェントが現在の Web ページを調査し、DOM を理解しやすいアクセシビリティツリーに簡略化します。これにより、要素のIDやクラス名が変更されても、テストは継続して動作します。
2. AIエージェントによるテスト自動実行
AgentiTestの最大の強みは、単なるスクリプト実行ではなく、
「考えて行動する」AIエージェント がテストを進めてくれる点にあります。
その仕組みの核心にあるのが ReAct(Reason and Act)ループ。
人間が「画面を見て、考えて、操作する」プロセスを、AIが模倣します。
ReActループの流れ
-
観察(Observe)
エージェントが現在のWebページを調査し、
ボタンやリンクなどのインタラクティブ要素を整理して把握します。 -
推論(Reason)
取得したページ情報と「自然言語で書かれたテスト指示」をLLMに渡し、
「次にどの操作をすべきか?」 を推論します。 -
実行(Act)
LLMが決めたアクション(クリック・入力・スクロールなど)を
Playwrightドライバーを通じてブラウザに実際に実行します。
この「観察 → 推論 → 実行」のサイクルが繰り返されることで、 UIが少し変わってもテストが柔軟に対応できるのです。
従来の「セレクター依存テスト」ではなく、 「画面を理解して動く」エージェント型テスト。 これこそがAgentiTestの革新ポイントです。
3. pytestによる構造化されたテスト管理
AgentiTestは pytest をベースにしているため、「自然言語での柔軟さ」と「テストフレームワークとしての堅牢さ」を両立できます。 pytest の便利な仕組みを活用することで、テストの再利用性・メンテナンス性・可読性がぐっと高まります。
フィクスチャー機能で共通処理を集約
テストごとに毎回セットアップを記述する必要はありません。たとえば LLM やブラウザセッションを フィクスチャー として定義しておけば、各テスト関数に自動で注入されます。
@pytest.fixture(scope="session")
def llm() -> ChatGoogle:
return ChatGoogle(model=model_name)
async def test_search_for_term(self, llm, browser_session, term):
# llm と browser_session は pytest によって自動的に提供される
パラメータ化でテストケースを一括管理
同じ処理を複数の入力データで試したいとき、parametrize デコレータを使えばテストを簡潔に書けます。ナビゲーションリンクが正しいページに遷移するかを、複数パターンまとめて検証できます。
@pytest.mark.parametrize(
"link_text, expected_path_segment",
[
("Google Cloud", "google-cloud"),
("Looker", "looker"),
("Google Workspace Developers", "google-workspace"),
("AppSheet", "appsheet"),
],
)
async def test_main_navigation(self, llm, browser_session, link_text, expected_path_segment):
"""各主要ナビゲーションリンクが正しいページに遷移することを確認"""
このようにpytestの仕組みを取り入れることで、AgentiTestは「自然言語の柔軟さ」と「構造化されたテスト管理」を両立させています。
実際の検証:大幅なサイト変更への対応
予想外のサイト変更、でもテストは止めない
デモ用に用意していたサンプルは、Google Cloud Community を対象にしたものでした。 ところが実行してみると ── エラーの雪崩。原因を追うと、対象サイトが Google Developer Program forums(discuss.google.dev) に大幅リニューアルされていました。
- ドメイン変更:
googlecloudcommunity.com→discuss.google.dev - ナビゲーション構成の変更(例:「Looker & Looker Studio」→「Looker」)
- トップの統計ウィジェットが完全削除
- 検索動作の変更(候補表示 → Enter確定の二段階)
- UIの見た目とDOM構造が全体的に刷新
従来型テストなら、この時点で 大量のテストが失敗してレポート画面が真っ赤に染まり、結局は テストコードを総張り替え する羽目になるのが定番です。 しかし、AgentiTestは違います。
自然言語 + エージェント実行の組み合わせにより:
-
URLパターンの自動追跡:
q=→search?q=への変更に適応 -
検索の二段階確定にも対応:タスクを
type → サジェスト待ち → Enterで送信に言い換えるだけ - 廃止機能(統計ウィジェット)は pytestのスキップで明示的に無効化
- 変更されたメニュー文言は パラメータ差し替えで一括修正
結果として、テスト資産を廃棄せず、自然言語の微調整と最小限の修正で新サイトへスムーズに回復できました。
予想外のUI変更が来ても、テストは “読める自然言語” のまま直せる。それが AgentiTest の実戦力です。
サイト変更の詳細
| 変更項目 | 変更前(Google Cloud Community) | 変更後(Google Developer Program forums) |
|---|---|---|
| ドメイン | googlecloudcommunity.com | discuss.google.dev |
| ナビゲーション | "Looker & Looker Studio" | "Looker" |
| 統計表示 | Members/Online/Solutions表示 | 完全に削除 |
| 検索機能 | 直接遷移 | 候補表示→Enter確定 |
| UI全体 | 従来デザイン | モダンなタイル表示 |
| 変更前 | 変更後 |
|---|---|
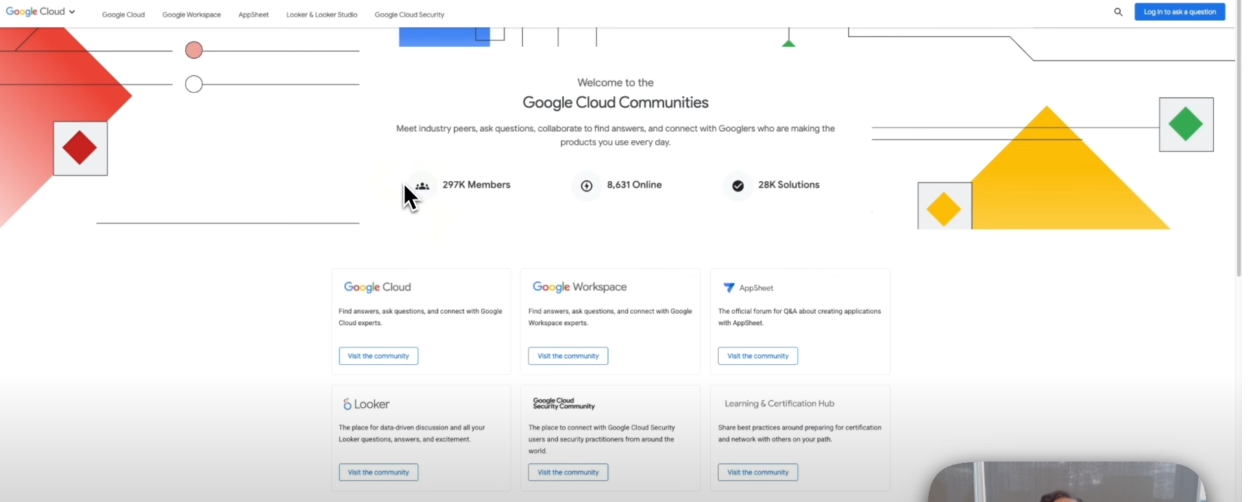 |
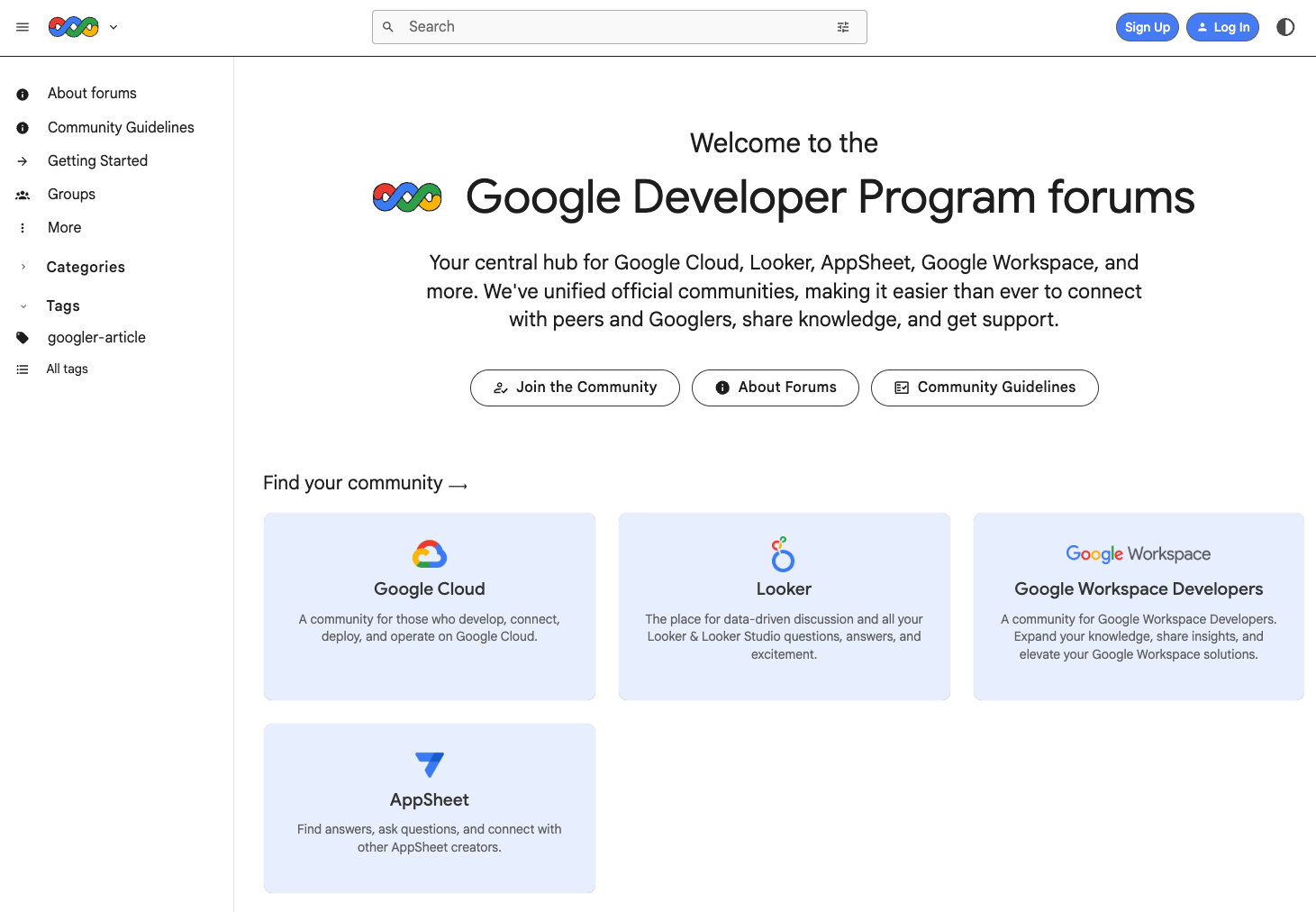 |
ChatGPTによる自動修正提案の実現
ここで「どうやってテストを直すんだ?」と思った方も多いでしょう。
そこで試したのが、ChatGPTに変更前後のスクリーンショットを食わせて「修正案を出して!」とお願いするというアプローチです。
結果は想像以上にパワフルでした。ChatGPTは変更点を正確に見抜き、以下のような修正提案を自動で生成してくれました。
ChatGPTへの入力例
「以下の変更前後のスクリーンショットを比較して、AgentiTestのテスト修正案を提案してください」
ChatGPTの解析結果と修正提案
-
ナビゲーションリンクの更新
- 「Looker & Looker Studio」→「Looker」
- 「Google Workspace」→「Google Workspace Developers」
- 「Google Cloud Security」は削除
-
統計表示テストの無効化
- 新サイトには「Members/Online/Solutions」の表示が存在しない
-
検索URLパターンの変更
-
q=→search?q=に仕様変更
-
ChatGPTが生成した修正コード(抜粋)
@pytest.mark.parametrize(
"link_text, expected_path_segment",
[
- ("Google Workspace", "google-workspace"),
+ ("Google Cloud", "google-cloud"),
+ ("Looker", "looker"),
+ ("Google Workspace Developers", "google-workspace"),
("AppSheet", "appsheet"),
- ("Looker & Looker Studio", "looker"),
- ("Google Cloud Security", "security"),
],
)
+@pytest.mark.skip(reason="Legacy community stats removed on the new site")
async def test_stats_are_visible(self, llm, browser_session):
-expected_url_part = f"q={quote(term)}"
+expected_url_part = f"search?q={quote(term)}"
さらなる問題の発見と動的解決
「これで修正完了!」と思いきや、テストを回してみると再び赤いアラートが…
今度は BigQueryの検索テストが失敗 です。
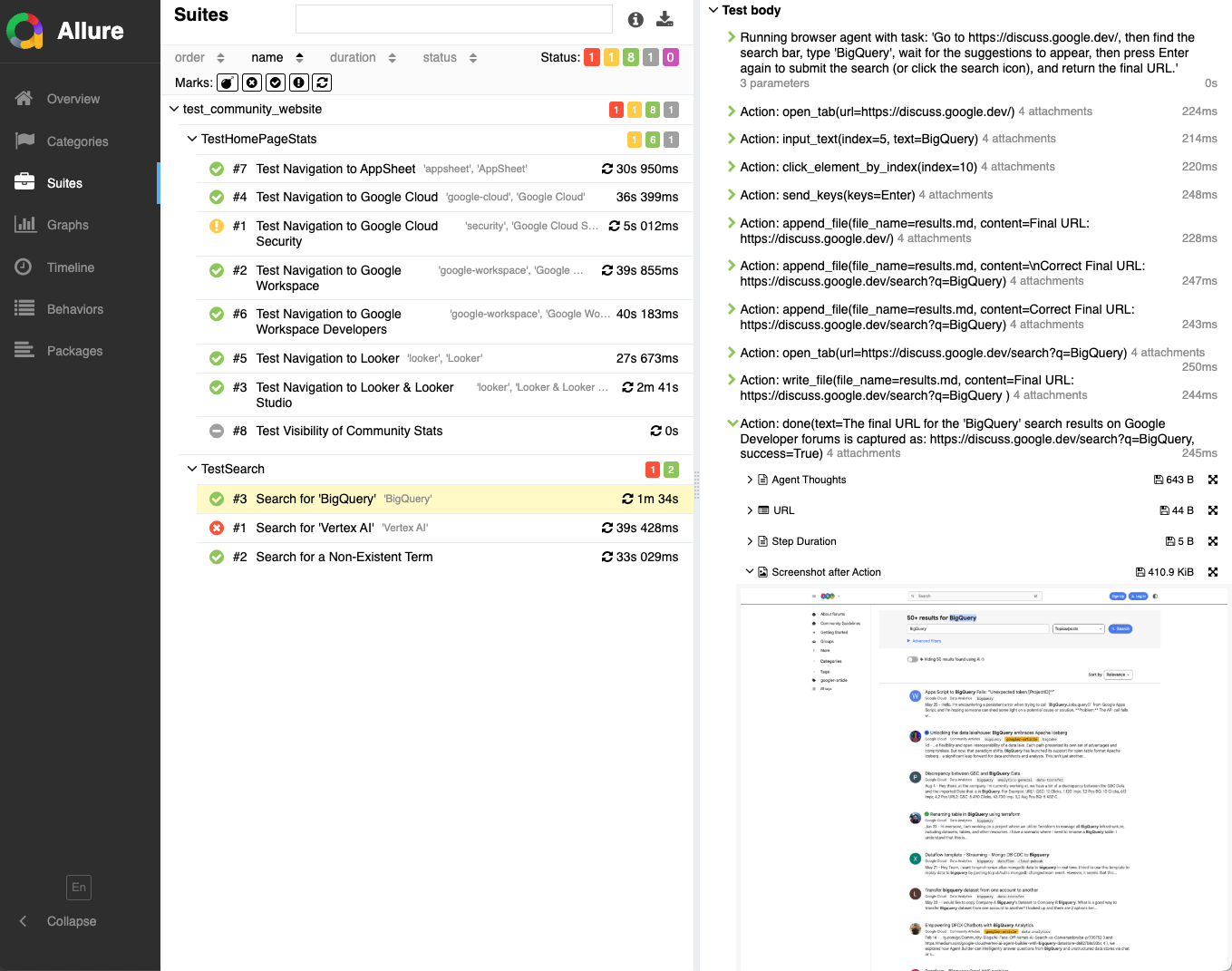
しかしここで威力を発揮したのが Allureレポートのスクリーンショット機能 でした。スクリーンショットを確認すると、原因はすぐに判明しました。
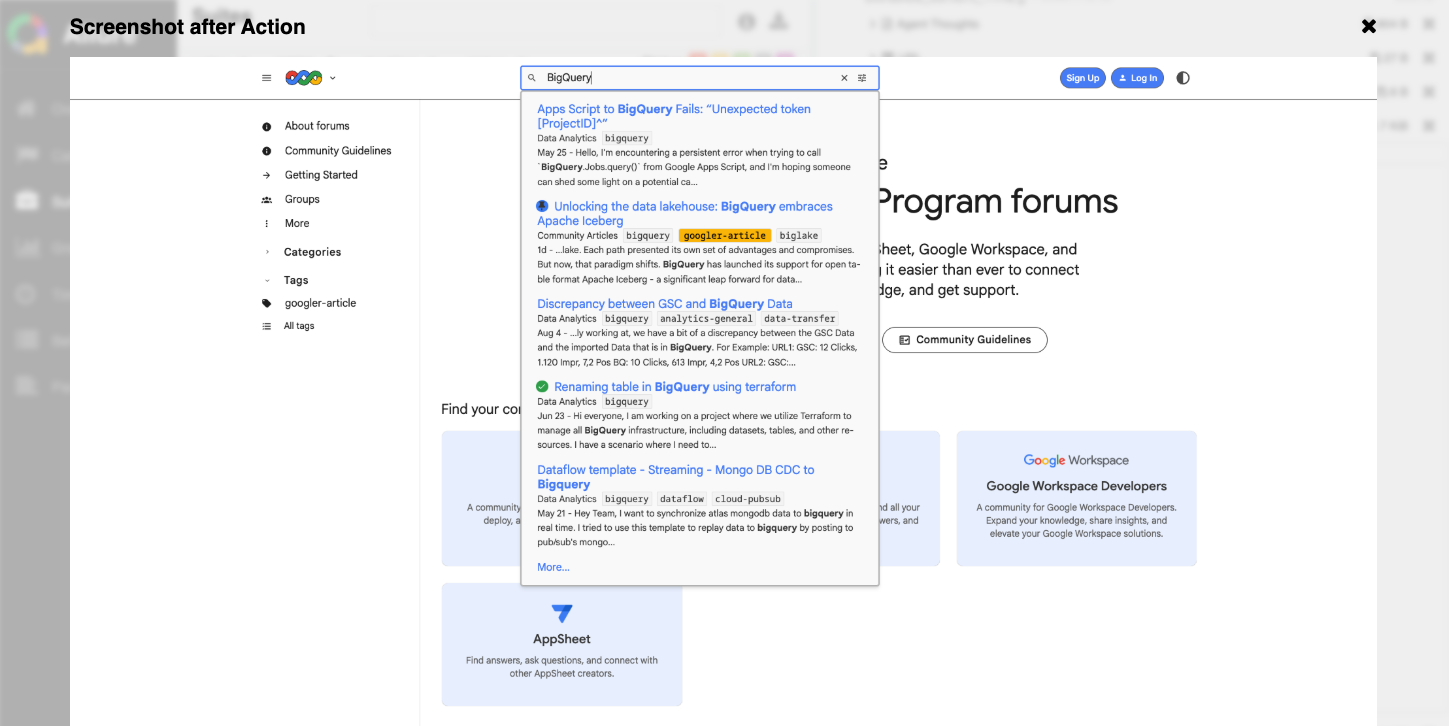
検索バーに「BigQuery」と入力すると、入力途中で候補がサジェスト表示され、すぐには検索結果に飛ばない仕様になっていたのです。
つまり「Enter一発で即検索」という想定が崩れていたのが失敗の理由でした。
問題点
- 検索窓に入力すると候補が表示される
- すぐには検索結果ページに遷移しない
**解決策: タスク記述を自然言語で変更する **
「候補が出るまで待ってからEnterを押す」という、人間が普通にやる手順を自然言語で追加してみました。
# 修正前
task = f"find the search bar, type '{term}', press enter, and return the final URL."
# 修正後
task = (
f"find the search bar, type '{term}', wait for the suggestions to appear, "
"then press Enter again to submit the search, and return the final URL."
)
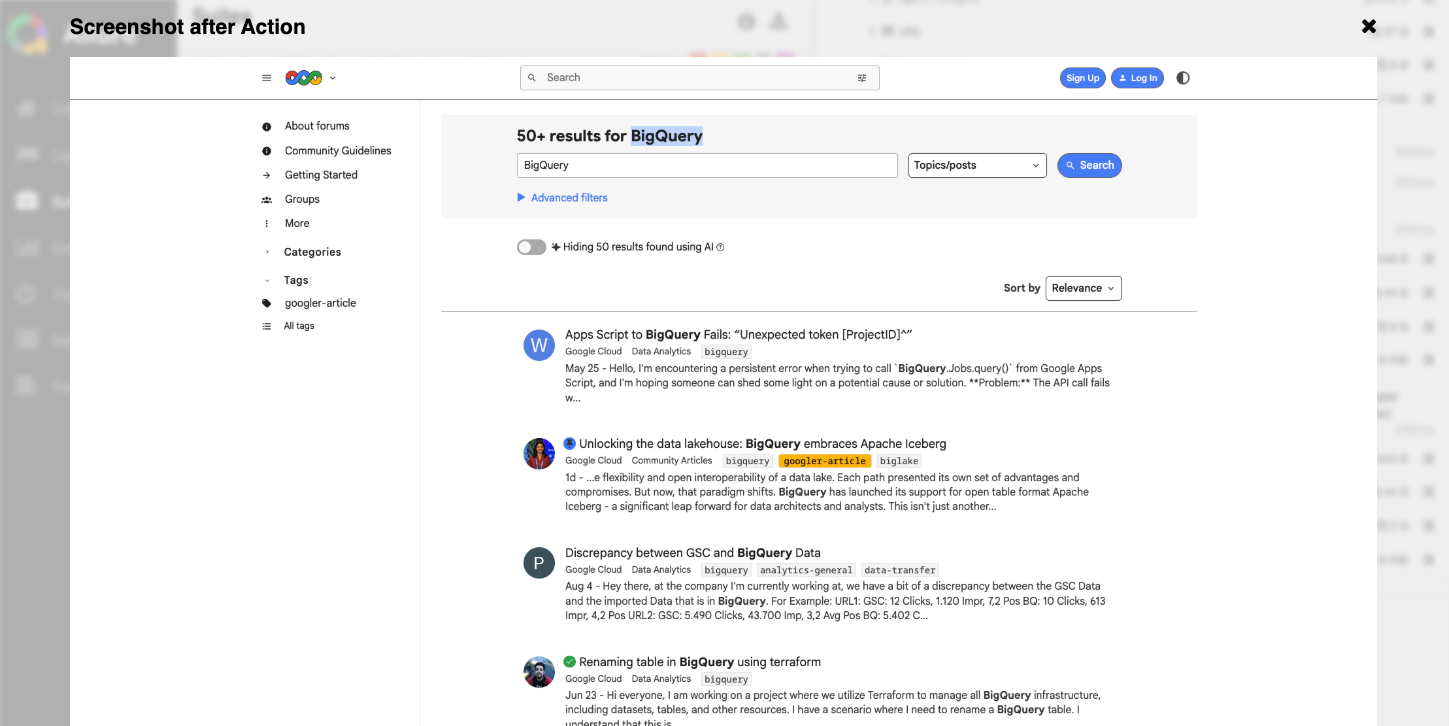
結果:
修正後のタスクでは、LLMが新仕様を理解して正しく動作
検索候補を経由した上で、無事に検索結果ページのURLを取得できました
AgentiTestアーキテクチャの革新性
AIエージェントによるテストの自動修正を可能にするアーキテクチャ特性
「スクリーンショットを食わせただけで、ChatGPTがテスト修正案を出せた」、これは魔法のように見えますが、実はAgentiTestの設計に秘密がありそうです。以下のアーキテクチャ特性があるからこそ、AIエージェントは変化に強く、柔軟に適応できるのです。
1. 自然言語ベースのテスト記述
- 技術的なセレクターやIDではなく、ユーザー行動レベルでタスクを定義
- 「リンクをクリック」「検索してEnter」といった自然な指示なので、LLMが意図を正しく理解して対応できる
2. 構造化されたテスト組織
パラメータ化やフィクスチャを活用しているため、変更に強い設計
# パラメーター駆動テストによる保守性
@pytest.mark.parametrize("link_text, expected_path_segment", [...])
3. 包括的な実行履歴の記録
browser-use の強みは「状態を丸ごと残す」こと。
- 各アクション
- LLMの思考プロセス
- 訪問したURL
- スクリーンショット
これらがすべて監査証跡として残るため、後から「なぜ動いた/動かなかった」を人間もAIも分析しやすい。
4. 宣言的なテスト構造
Allureとの統合により、テストコードが「仕様書」のように読める
class TestHomePageStats(BaseAgentTest):
@allure.feature("Navigation")
@allure.story("Main Navigation Links")
「何をテストしているのか」が自然に伝わるため、ビジネス要件と技術実装の橋渡しになる。
つまりAgentiTestは、自然言語+構造化+完全ログ+宣言的記述 という4本柱で成り立っているからこそ、画面が変わっても「AIがすぐに修正提案できる」仕組みになっているのです。
「AIがすぐに修正提案できる」についてはAgentiTestの公式サイトでは特に言及されていませんので、意図せずそのようになっているのかもしれません。
統合アーキテクチャの詳細
AgentiTestは、pytest × browser-use × Allure という3つの技術を組み合わせた エンドツーエンドのテストフレームワークです。 それぞれが役割を分担しながら、まるでオーケストラのように調和して動作します。
1. テスト初期化とオーケストレーション(pytest)
開発者は自然言語でテストケースを書き、pytest コマンドを実行するだけ。pytestは「指揮者」として全体を統括し、まず conftest.py を参照して必要なフィクスチャ(LLMやブラウザセッションなど)を準備します。
2. エージェント実行ループ(browser-use)
次にバトンを受け取るのが browser-use。AgentクラスがWebページの状態を調査し、その情報をLLM(例: Gemini, OpenAI)へ送信。LLMは「画面を理解して次のアクションを判断」し、その結果をブラウザ操作に反映します。ここがAgentiTestの“頭脳と手足”にあたる部分です。
3. レポーティングと可視化(Allure)
舞台裏では allure-pytest プラグインが静かに動作。各テストイベントや実行履歴をフックし、スクリーンショット・LLMの思考ログ・アクション履歴を美しいインタラクティブなHTMLレポートにまとめ上げます。
検証結果から見えるAgentiTestの価値
大幅なメンテナンスコスト削減
従来のセレクターベースのテストでは、大幅なUI変更が入ると…
- 新しいセレクターを調査
- テストコードを総張り替え
- 新機能に合わせたロジック追加
- 削除された機能のテスト無効化
こうした時間のかかる修正作業が避けられませんでした。
AgentiTestなら:
- スクリーンショット差分から自動で修正提案
- パラメータの一部を書き換えるだけで修正完了
- 自然言語タスクなので、仕様変更も柔軟に追従
メンテナンスにかかる時間を劇的に削減できます。
動的な問題解決能力
例えば検索機能の仕様が変わって「候補が表示されてからEnterで確定」という挙動になった場合でも、LLMが:
- 新しい挙動を観察
- 適切な対応策を推論
- 自己修正して正しく結果を取得
従来の静的なテストでは不可能だった、その場での自己適応が可能です。
透明性と理解しやすさ
AgentiTestのテストは技術者以外でも読めるレベルの自然言語で記述可能です。
task = (
f"find the search bar, type '{term}', wait for the suggestions to appear, "
"then press Enter again to submit the search, and return the final URL."
)
さらに、LLMの思考プロセス可視化により、「なぜそのアクションを取ったのか」がログで明確になり、デバッグや改善もスムーズに行えます。
🛠️ トラブルシューティング
環境構築やテスト実行で問題が発生した場合は、以下のコマンドでキャッシュやプロファイルをリセットし、最初からやり直すのが効果的です:
# 破損したキャッシュ/プロファイルを削除
rm -rf ~/Library/Caches/ms-playwright
rm -rf ~/.config/browseruse/profiles/default
rm -rf venv
# 最初からやり直し
今後の展望と可能性
AgentiTestが示すのは「いま動く便利な仕組み」だけではありません。
これからの進化によって、テスト自動化はさらに新しいステージへと向かいます。
🚀 1. 完全自動修正の実現
- スクリーンショット比較によるフル自動のテスト修正
- CI/CDパイプラインに組み込み、UI変更があっても即座に適応
✨ 2. 自然言語によるテスト生成
- 要件定義書からそのままテストケースを自動生成
- ビジネス要件とテストが常にシンクロした状態を維持
🌐 3. より広範な適用
- マルチブラウザやモバイルアプリへの拡張
- APIテストやパフォーマンステストとの統合による包括的な品質保証
まとめ
AgentiTestは、従来のフレームワークが抱えてきた弱点を乗り越え、しなやかで壊れにくい次世代のテスト自動化を実現できます。
今回の検証から見えてきた価値は次のとおりです:
技術的革新
- LLMによる動的な画面理解と自動適応
- 自然言語ベースで保守性の高いテスト記述
- ReActループによる自己修正能力
実用的価値
- テストメンテナンスコストの大幅削減
- UI変更に対する即応性と柔軟性
- 技術者以外でも理解できるテスト仕様
イノベーション
- スクリーンショット差分による自動修正提案
- LLMの思考プロセス可視化で透明性を確保
- エージェント型実行による動的な問題解決
人気のオープンソースツールに基づく「エージェントベースのアプローチ」により、AgentiTestはWebアプリのE2Eテスト自動化における新しい標準を提示します。
UI変更への柔軟な追従、自然言語によるわかりやすさ、そしてLLMがもたらす適応力によって、テスト自動化の未来はすでに始まっています。