概要
Apple Silicon Mac 上でローカル LLM 環境を構築し、ブラウザ UI から利用するまでの手順を整理した。vllm-mlx を推論サーバとして起動し、Open WebUI でChatUIを提供する。また、MacStudio (Apple M3 Ultra 256GB) 環境で複数モデルの動作確認とベンチマーク結果を示す。256GBの環境では 397B クラスのモデルも動作した。
はじめに
これまで Apple Silicon Mac 上でのローカル LLM 実行には llama.cpp を利用してきたが、最近は vllm-mlx の実装が進み、MLX ベースでより効率的に動作するようになっている。
実際にどの程度実用になるのか確認するため、vllm-mlx を使ったローカル LLM 環境を構築し、複数モデルでベンチマークを取得した。また、推論速度や使用感をすぐ確認できるように、チャット UI として Open WebUI も合わせて構築した。
検証環境は以下の通り
| 項目 | 内容 |
|---|---|
| SoC | Apple M3 Ultra |
| Unified Memory | 256 GB |
| Memory Bandwidth | 800 GB/s |
| GPU Cores | 80 |
セットアップ
Homebrew のインストール
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
echo >> /Users/raiko/.zprofile
echo 'eval "$(/opt/homebrew/bin/brew shellenv zsh)"' >> /Users/raiko/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv zsh)"
uv のインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
vllm-mlx のインストール
uv tool install vllm-mlx
Zed Editor のインストール
brew install --cask zed
vllm-mlx の起動
まずは軽量なモデルで起動確認を行う。
vllm-mlx serve mlx-community/Llama-3.2-3B-Instruct-4bit --port 8000 --continuous-batching
利用したオプション。
| オプション名 | 説明 |
|---|---|
| --host 0.0.0.0 | 外部PCから利用する場合 |
| --served-model-name "default" | サンプルコードを model="default" のまま利用する場合 |
起動後、OpenAI API 互換エンドポイントを確認する。
curl -s http://127.0.0.1:8000/v1/models | jq .
出力例。
{
"object": "list",
"data": [
{
"id": "mlx-community/Llama-3.2-3B-Instruct-4bit",
"object": "model",
"created": 1778727377,
"owned_by": "vllm-mlx"
}
]
}
Docker と Colima のセットアップ
Open WebUI は Docker コンテナとして起動する。
brew install docker
brew install colima
colima start
Open WebUI の起動
docker run -d \
--name open-webui \
-p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--restart always \
ghcr.io/open-webui/open-webui:main
コンテナの状態を確認する。
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
380509e25170 ghcr.io/open-webui/open-webui:main "bash start.sh" 5 minutes ago Up 5 minutes (healthy) 0.0.0.0:3000->8080/tcp, [::]:3000->8080/tcp open-webui
ブラウザで以下へアクセスする。
http://localhost:3000
初回アクセス時は管理者アカウント作成画面が表示される。

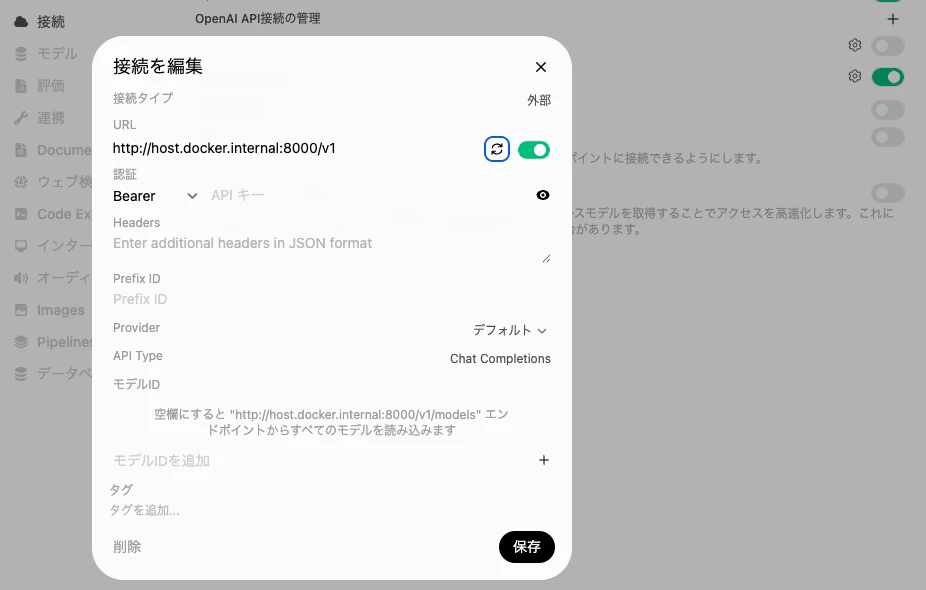
OpenAI API の接続設定で以下を指定する。
http://host.docker.internal:8000/v1
Docker コンテナ内からホスト側の vllm-mlx に接続するため、localhost ではなく host.docker.internal を利用する。
テキスト生成の確認
以下のプロンプトで動作確認を行った。
Rust言語でHello, Worldプログラムを作成せよ

画像入力の確認
画像入力も確認した。
プロンプト。
添付画像を解析して
添付画像。
| 添付画像 |
|---|
 |
実行結果。

ベンチマーク
ベンチマークは以下を利用した。
ベンチマーク対象モデル
| モデル | 量子化精度 | サイズ |
|---|---|---|
mlx-community/Llama-3.2-1B-Instruct-4bit |
4bit | 680 MB |
mlx-community/Qwen3.6-35B-A3B-nvfp4 |
NVFP4 | 19 GB |
mlx-community/Qwen3.5-122B-A10B-mxfp4 |
MXFP4 | 61 GB |
mlx-community/Qwen3.5-397B-A17B-4bit |
4bit | 209 GB |
結果
| Model | Quantization | Size | Gen Speed | TTFT | MLX Peak Mem | Notes |
|---|---|---|---|---|---|---|
mlx-community/Llama-3.2-1B-Instruct-4bit |
4bit | 680 MB | 516.7 tok/s | 63.6 ms | 0.69 GB | Extremely fast, tiny model |
mlx-community/Qwen3.6-35B-A3B-nvfp4 |
NVFP4 | 19 GB | 101.9 tok/s | 136.6 ms | 18.28 GB | Best balance of speed vs intelligence |
mlx-community/Qwen3.5-122B-A10B-mxfp4 |
MXFP4 | 61 GB | 61.0 tok/s | 176.3 ms | 60.65 GB | Large MoE model, very strong reasoning |
mlx-community/Qwen3.5-397B-A17B-4bit |
4bit | 209 GB | 40.7 tok/s | 221.2 ms | 207.89 GB | Massive model, near memory limit |
詳細指標
| Model | Output tok/s | TPOT | Latency | Requests/s | System Memory Usage |
|---|---|---|---|---|---|
| Llama-3.2-1B-Instruct-4bit | 516.7 tok/s | 1.94 ms | 0.50 s | 2.00 req/s | 20.2 / 256 GB (8%) |
| Qwen3.6-35B-A3B-nvfp4 | 101.9 tok/s | 9.82 ms | 2.16 s | 0.46 req/s | 42.0 / 256 GB (16%) |
| Qwen3.5-122B-A10B-mxfp4 | 61.0 tok/s | 16.39 ms | 3.51 s | 0.28 req/s | 81.5 / 256 GB (32%) |
| Qwen3.5-397B-A17B-4bit | 40.7 tok/s | 24.59 ms | 4.25 s | 0.24 req/s | 230.7 / 256 GB (90%) |
Qwen3.5-397B-A17B-4bit は動作したが、モデルロード時間が長い。
Fetching 56 files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 56/56 [1:31:45<00:00, 98.31s/it]
メモリ使用量も高く、ほぼ上限に近い。
System Memory 230.7 / 256 GB (90%)
まとめ
一般的なチャット用途で「実用的」と感じやすいラインは、おおよそ以下になることが多いようだ。
| 指標 | 体感 |
|---|---|
| 20 tok/s 未満 | 明確に遅い |
| 30〜50 tok/s | 十分実用 |
| 60〜100 tok/s | 快適 |
| 100 tok/s 超 | かなり速い |
| TTFT 100〜300ms | ほぼ待ち感なし |
| TTFT 500ms 超 | 若干待つ感覚 |
| メモリ使用率 80% 超 | 常用では不安定要素になりやすい |
この前提で見ると、実用性は下記のように整理できる。
| Model | 実用性 | 理由 |
|---|---|---|
| Llama-3.2-1B-Instruct-4bit | △ | 速度は極端に速いが、1B は知能面が厳しい。用途は軽量補助向け |
| Qwen3.6-35B-A3B-nvfp4 | ◎ | 速度・TTFT・メモリ使用量のバランスが良い。常用ライン |
| Qwen3.5-122B-A10B-mxfp4 | ○ | 十分実用。推論品質重視なら有力。ただし応答待ちは少し増える |
| Qwen3.5-397B-A17B-4bit | △ | 動作はするが、メモリ使用率 90% が重い。常用には余裕が少ない |
ベンチマーク実行コマンド
Llama-3.2-1B-Instruct-4bit
vllm-mlx-bench --model mlx-community/Llama-3.2-1B-Instruct-4bit --prompts 5 --max-tokens 256
Qwen3.6-35B-A3B-nvfp4
vllm-mlx-bench --model mlx-community/Qwen3.6-35B-A3B-nvfp4 --prompts 5 --max-tokens 256 2>&1 | tee benchmark_Qwen3.6-35B-A3B-nvfp4.log
Qwen3.5-122B-A10B-mxfp4
vllm-mlx-bench --model mlx-community/Qwen3.5-122B-A10B-mxfp4 --prompts 5 --max-tokens 256
Qwen3.5-397B-A17B-4bit
vllm-mlx-bench --model mlx-community/Qwen3.5-397B-A17B-4bit --prompts 5 --max-tokens 256
vllm-mlx で利用可能なモデル
MLX Community のモデル一覧。
リファレンス
- vllm-mlx official site: https://github.com/waybarrios/vllm-mlx
- Open WebUI: https://github.com/open-webui/open-webui