中期スイングトレードに適したRCIスパンの組み合わせの探索

はじめに
これまで記事にした銘柄財務+テクニカルスクリーニングでは、テクニカル指標の根幹として移動平均線(MA)を採用してきました。MAはトレンドの方向性を捉える上で安定しており、信頼性の高い指標です。しかし、その性質上、どうしても実際の値動きに対して反応が遅れる「遅行指標」だという弱点があると感じています。
前回の記事では、RCI(順位相関指数)という別のテクニカル指標を導入し、スクリーニング戦略として使えるのかをバックテストで検証しました。また、ヒットした銘柄を固定期間もしくはRCIのデッドクロスまで保有した場合のリターンとシャープレシオを比較することで、出口戦略の有用性に関しても考察しました。
これまでの経緯
本記事は、Pythonによる株式スクリーニング自動化・実践の続編です。これまでの背景や検証の流れは、以下の記事をご確認ください。
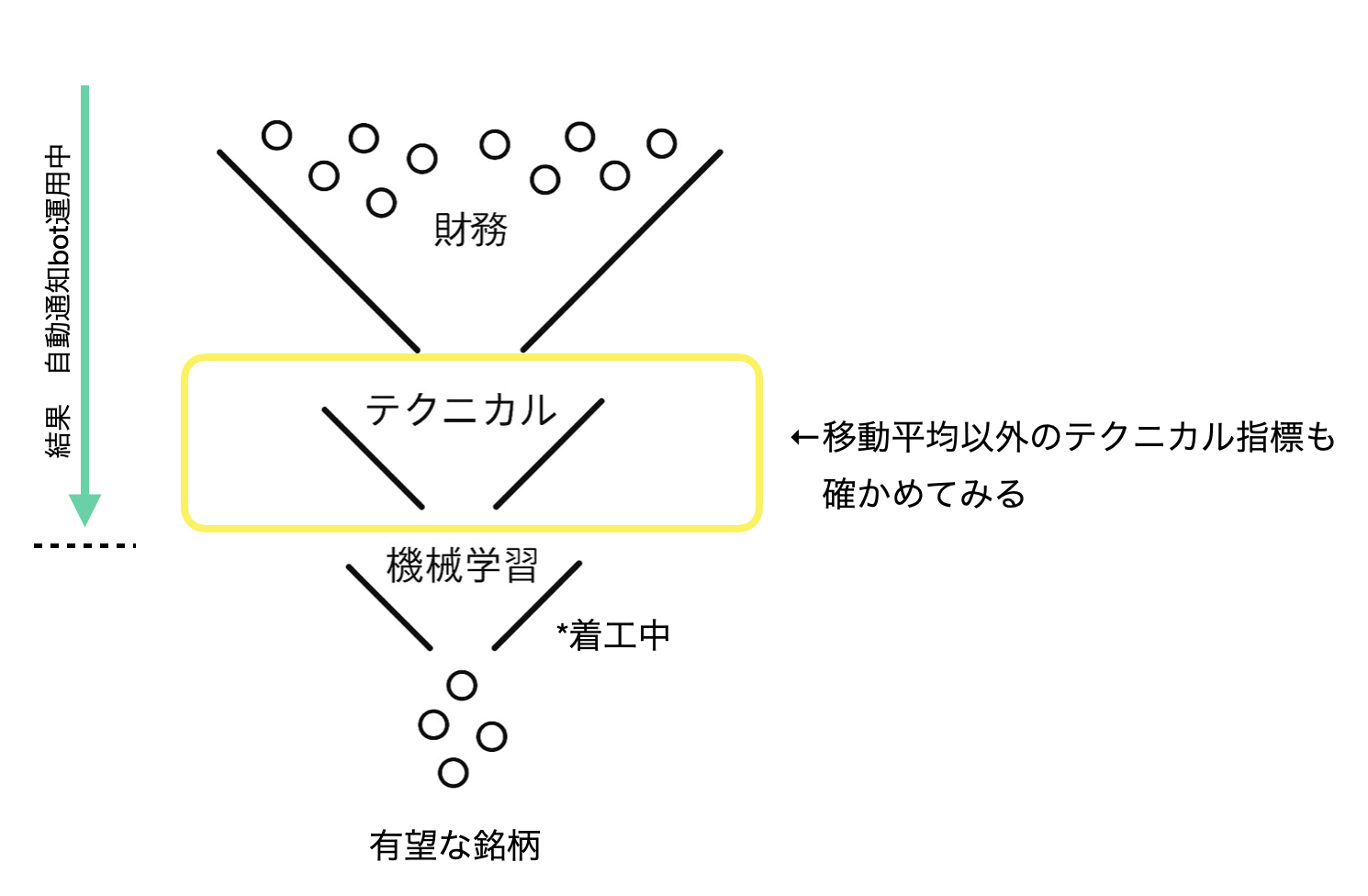
図1: 現在構築中のスクリーニングモデルの全体像と今回やること
- RCIが使える指標かどうか確かめ始めた
- 銘柄情報データベース作り始めたけど地味すぎて飽きた
- スクリーニング結果自動通知bot、結果の可視化とXへの投稿はできるようになった
- 生成AI無料期間にスクリーニング結果自動通知botを作り始めた
- 今回のモデルのスクリーニング速度を100倍向上した方法
- yfinance由来の軽量データセット構築
- 今回のモデルの改善点
- 今回のスクリーニングモデルの精度
- 相場状況を簡易的に数値化する
- 財務スクリーニング
前回の結果と課題
前回の検証では、固定期間保有した場合のシャープレシオは最高でも0.6程度と不十分でした。一方、RCIのデッドクロスまで保有した場合では、シャープレシオ1.0以上の良好なパターンが複数見つかりました。
しかし、RCIデッドクロスまで保有した場合においても、リターンとシャープレシオが良好なのは、長期保有(1年もしくはそれ以上)を行った場合で、自分の行いたい中期スイング投資には向かないことが想定されました。中期投資(数ヶ月から1年未満)を行う場合でも、一定のパフォーマンスを発揮する条件への改善が必要です。
さらに、バックテストでは、最初に公開したスクリーニングと比べると、サンプル数が6倍に増えたため、再現性の検証精度は向上したように思われますが、それでもまだ、精度検証に関して改善の余地が残っています。
今回の目的:中期投資に適したRCI条件の探索
今回の記事では、中期投資(数ヶ月から1年未満)に適したRCIスパンの組み合わせを探索することを主目的とします。
例:「RCI9とRCI26のゴールデンクロス(GC)でエントリーし、RCI5とRCI13のデッドクロス(DC)で出口すると他のRCIコンビよりも安定してリターンが得られる」。
このように、エントリーと出口それぞれに最適なRCI期間の組み合わせを見つけることです。
用語の定義:本記事では、エントリー用のRCIスパンとエグジット用のRCIスパンの組み合わせを「RCIコンビ」と呼びます。例えば、RCI13とRCI21の組み合わせでエントリーし、RCI5とRCI13の組み合わせでエグジットする場合、これらを合わせて1つのRCIコンビとします。
今回のアプローチ
従来の評価方法とその問題点
従来の方法では同一期間のデータで「パターンの発見」と「性能の検証」を同時に行っていました。
これを妥当だと認めてしまうと、同語反復のようなことをしていることになります。
「同じデータで検証した結果は正しいです。なぜなら同じデータで検証したからです」。
つまり、特定のバックテストで高精度を発揮した条件が、全く新しいデータ(未知の市場環境)に対応できる「真の実力」を持っているかどうかがわからなかったのです。
どこかにいますよね、こういうことをおっしゃる政治家が。
今回の改善点:従来より厳密な検証方法の採用
この問題を解決するため、今回は従来より厳密な検証方法を採用しました。
従来のように同一データでパターンの発見と検証を同時に行うのではなく、探索用データと検証用データを明確に分離しました。さらに、単一の検証期間では心許ないため、2つの独立した検証期間を設けて、発見した仮説の汎化性能をより確実に検証しました。これにより、これまでよりは精度評価の信頼性が向上したと考えられます。
アプローチの全体構造
【従来のアプローチ】
特定の期間を最初に決める
├── その中から抽出した日付を決める
├── その日付で財務スクリーニング
├── テクニカルスクリーニング(いくつかのパターンで)
├── 可視化・評価
└── リターンおよびシャープレシオが高いパターンを選抜→良さそうだなぁ...
【今回のアプローチ】
探索用データと検証用データの分離
2つの検証期間での厳密な検証
【第1段階:データ生成】
探索期間Aを設ける
├── その期間で各地合いスコアごとに日付を生成
├── 財務スクリーニング後に225のRCIコンビ(エントリーRCIとエグジットRCIの組み合わせ)のスクリーニング実行
評価期間Bを設ける(探索に使っていない未知データ)
├── その期間で各地合いスコアごとに日付を生成
├── 財務スクリーニング後に225のRCIコンビのスクリーニング実行
評価期間Cを設ける(探索にもBにも使っていない未知データ)
├── その期間で各地合いスコアごとに日付を生成
├── 財務スクリーニング後に225のRCIコンビのスクリーニング実行
【第2段階:評価解析】
探索期間Aの分析
├── リターン・シャープレシオ・保有期間などをヒートマップ(可視化)
├── 正規化を行う(保有期間・リターン・シャープレシオのバランスが良い順にランクアップ)
└── 各地合いスコアごとに、ランクが高いRCIコンビを15個ピックアップ
評価期間Bの分析
├── データを集計して、Aと同じように可視化
└── 探索期間で上位にランクされたRCIコンビがこの期間でどのようなパフォーマンスなのかを参照
評価期間Cの分析
├── データを集計して、Aと同じように可視化
└── 探索期間で上位にランクされたRCIコンビがこの期間でどのようなパフォーマンスなのかを参照
最終選抜
└── どの期間でもシャープレシオが高いものを、ロバストなRCIコンビとして選抜
図2: 従来のアプローチと今回のアプローチの概要
詳細条件
⚪︎第1段階:データ生成(バックテスト実行)
期間設定:
-
探索期間A(2021-2022年の合計2年間): 各地合いスコアごとに約30日の実行日をランダムに選定
-
評価期間B(2023年の1年間): 各地合いスコアごとに約15日の実行日をランダムに選定
-
評価期間C(2024年の1年間): 各地合いスコアごとに約20日の実行日をランダムに選定
*各期間のサンプルサイズについて:探索期間A(2年間で30日)と比べて評価期間B(1年間で15日)とC(1年間で20日)は少なくなっていますが、年間あたりのサンプリング密度で見ると、探索期間A(年間15日)、評価期間B(年間15日)、評価期間C(年間20日)となり、各期間における日付の密度が概ね同じ設定になっています。各期間の日数は、地合スコア間で日数の偏りが生じない最大日数を採用しているため、23年が24年よりも少なくなりました。
なお、DCクロスが発生しないデータは分析対象外として除外されており、2023年では2.99%、2024年では14.9%のデータが該当しました。今回は中期保有(最大でも200日程度)に適したRCIスパンの組み合わせを探索することを対象としているため、長期保有となるデータが不足していても目的への影響が小さいと考えられるため、この設定で分析を進めました。
スクリーニング条件:
- 財務スクリーニング: 東証プライム銘柄約1600銘柄から、財務指標による段階的スクリーニングで約200銘柄に絞り込み
-
RCIテクニカルスクリーニング: RCI期間[5, 8, 13, 21, 34, 55]から生成される225通りの組み合わせ
- エントリーRCI: 15通り(5-8, 5-13, 5-21, 5-34, 5-55, 8-13, 8-21, 8-34, 8-55, 13-21, 13-34, 13-55, 21-34, 21-55, 34-55)
- エグジットRCI: 15通り(同上)
- 総組み合わせ数: 15 × 15 = 225のRCIコンビ
エントリー条件:
- RCI収束: 2つのRCIの差が20未満
- RCIゴールデンクロスの領域: 中期RCIがマイナス
- RCI傾き: RCI傾きが0.5以上
- RSI範囲: RSIが25-50の範囲内
エグジット条件:
- RCIポジティブゾーン: 両方のRCIがプラス
- RCIデッドクロス: 短期RCIが長期RCIを下向きにクロス
データ処理:
- 各地合いスコア(-3〜+3)ごとに、Entry_Pattern(15通り)× Exit_Pattern(15通り)= 225のRCIコンビを実行
- 各RCIコンビについて、平均リターン、勝率、平均保有期間、銘柄数、シャープレシオを計算してcsvに保存
- 1日あたりのリターンとシャープレシオも同様
⚪︎第2段階:評価解析(結果分析)
探索期間でのRCIコンビ選抜:
-
正規化してランキング: 探索期間の結果のみを対象に、各指標を0-1の範囲に正規化して公平に比較
- リターンスコア:
(そのRCIコンビの1日あたり平均リターン - 探索期間内の最小値) ÷ (探索期間内の最大値 - 最小値) - シャープレシオスコア:
(そのRCIコンビの保有期間全体シャープレシオ - 探索期間内の最小値) ÷ (探索期間内の最大値 - 最小値) - 保有期間スコア:
1 - (そのRCIコンビの平均保有期間 - 探索期間内の最小値) ÷ (探索期間内の最大値 - 最小値)※短いほど良いため逆転
- リターンスコア:
-
総合スコア:
リターンスコア × 0.3 + シャープレシオスコア × 0.4 + 保有期間スコア × 0.3トータルスコア1.0ースコアが高いほど良いとみなす。 - フィルタリング: 10回以上の取引実績があるRCIコンビのみを評価対象(一部のRCIコンビで、銘柄が抽出された日付が30日のうち2-3日程度しかないと、統計的に信頼できないため除外)
- 選抜: 各地合いスコアごとに総合スコア上位15位のRCIコンビを選抜
評価期間での汎化性能検証:
- 期間ごとの精度比較: 探索期間Aで上位15位に選抜されたRCIコンビについて、評価期間B・Cでのパフォーマンスを詳細に比較
- 比較指標: 平均リターン、シャープレシオ、平均保有期間、取引回数など複数指標を3期間で横並び比較
- 最終選抜: 3つの期間すべてで安定した成績を残すRCIコンビを「普遍性のある優良RCIコンビ」として選抜
中期投資に最適なRCI組み合わせの探索と汎化性能検証の結果
探索期間で優良とされた105のRCIコンビのうち、探索期間および2つ評価期間においてシャープレシオ0.65以上を示したRCIコンビを選抜した結果、合計で19個が選ばれました。ここではまず、これらの19のRCIコンビの特徴を分析し、相場状況の関係を考察します。
そして、今回の目的の中期投資に適した7つのRCIコンビを特定します。
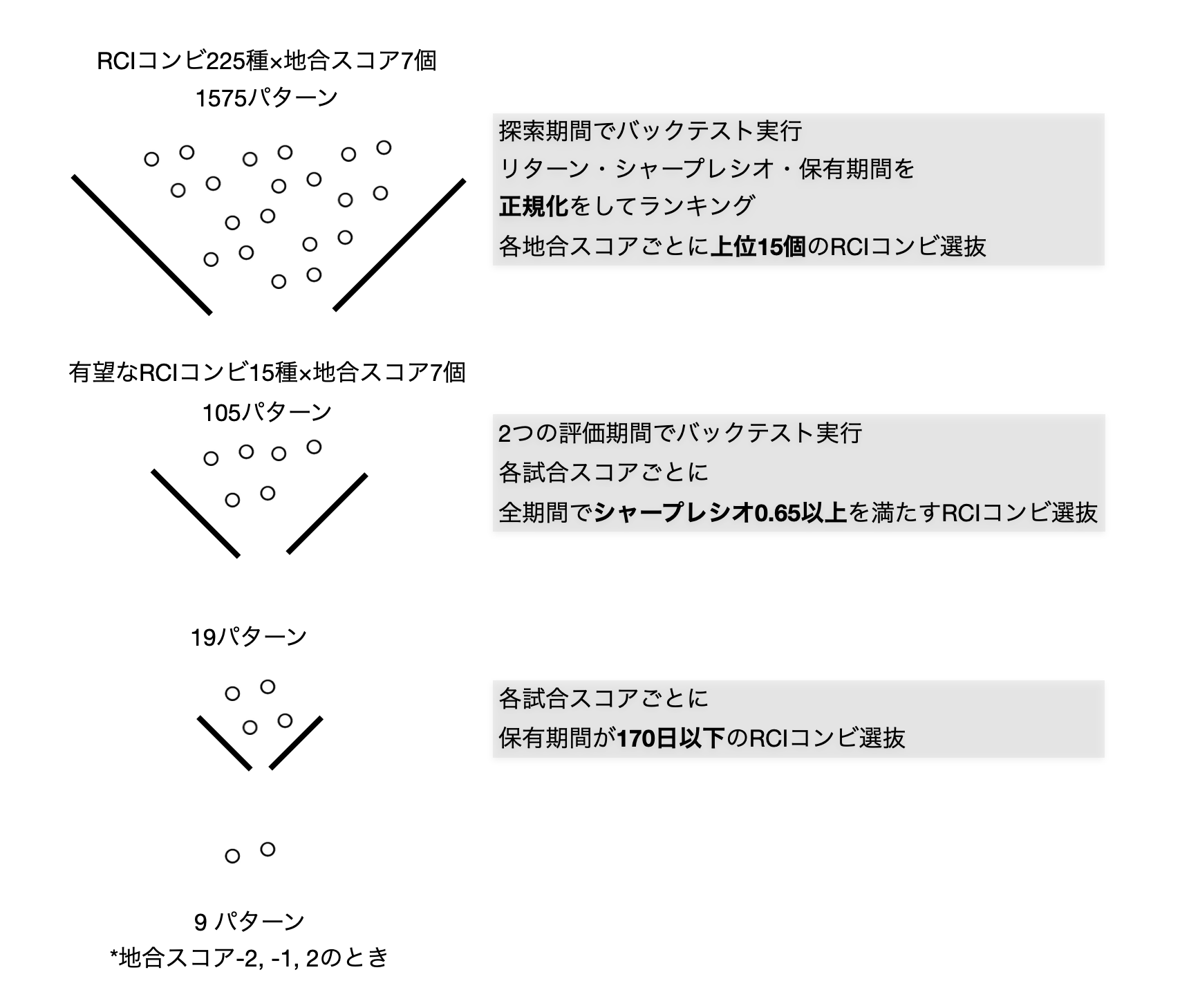
図3: 結果概要
1. シャープレシオが安定していたRCIコンビのエントリー・エグジットパターンの法則性
選抜されたRCIコンビの出現回数を比較すると**「買いは慎重に(中期RCIでノイズを除去)、売りは素早く(短期RCIで機敏に)」**という戦略が安定したリターンを出すために適していると考えられました。
⚪︎エントリー(買い)で頻出するRCIコンビ
Entry_13_21, Entry_21_34, Entry_5_21, Entry_13_34 がそれぞれ3回と最も多く抽出されました。
これらは中期(13, 21, 34)のRCIを中心とした組み合わせです。ノイズの少ない、より確かな相場の転換点を捉える戦略が、安定した成績に繋がっていると考えられます。
⚪︎エグジット(売り)で頻出するRCIコンビ
Exit_5_13が3回で最も多く、次いでExit_21_34, Exit_5_21, Exit_8_13, Exit_8_21がそれぞれ2回と続いています。
こちらは短期(5, 8)と中期(13, 21)の組み合わせが中心です。エントリーとは対照的に、細かい値動きに素早く反応して、上昇の勢いが少しでも衰えたら俊敏に利益を確定する出口戦略が有効であることを示唆しています。
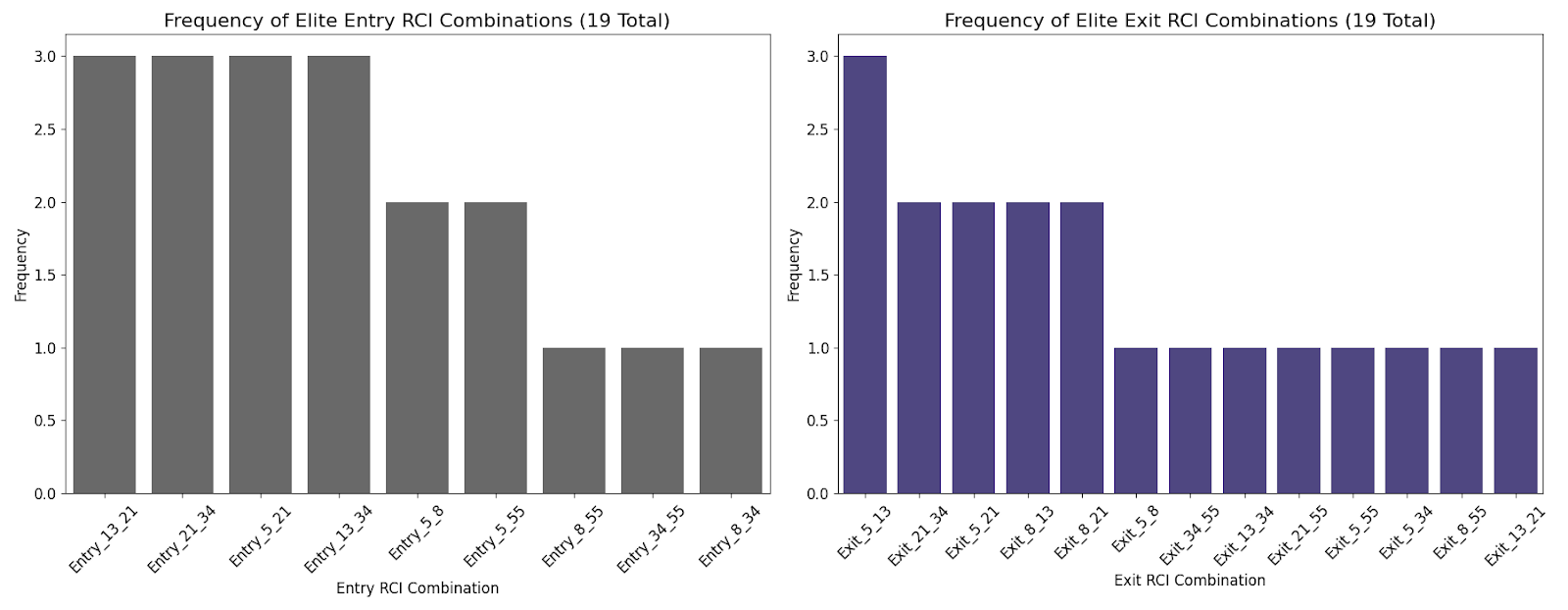
図4: エントリー・エグジットパターンの頻度
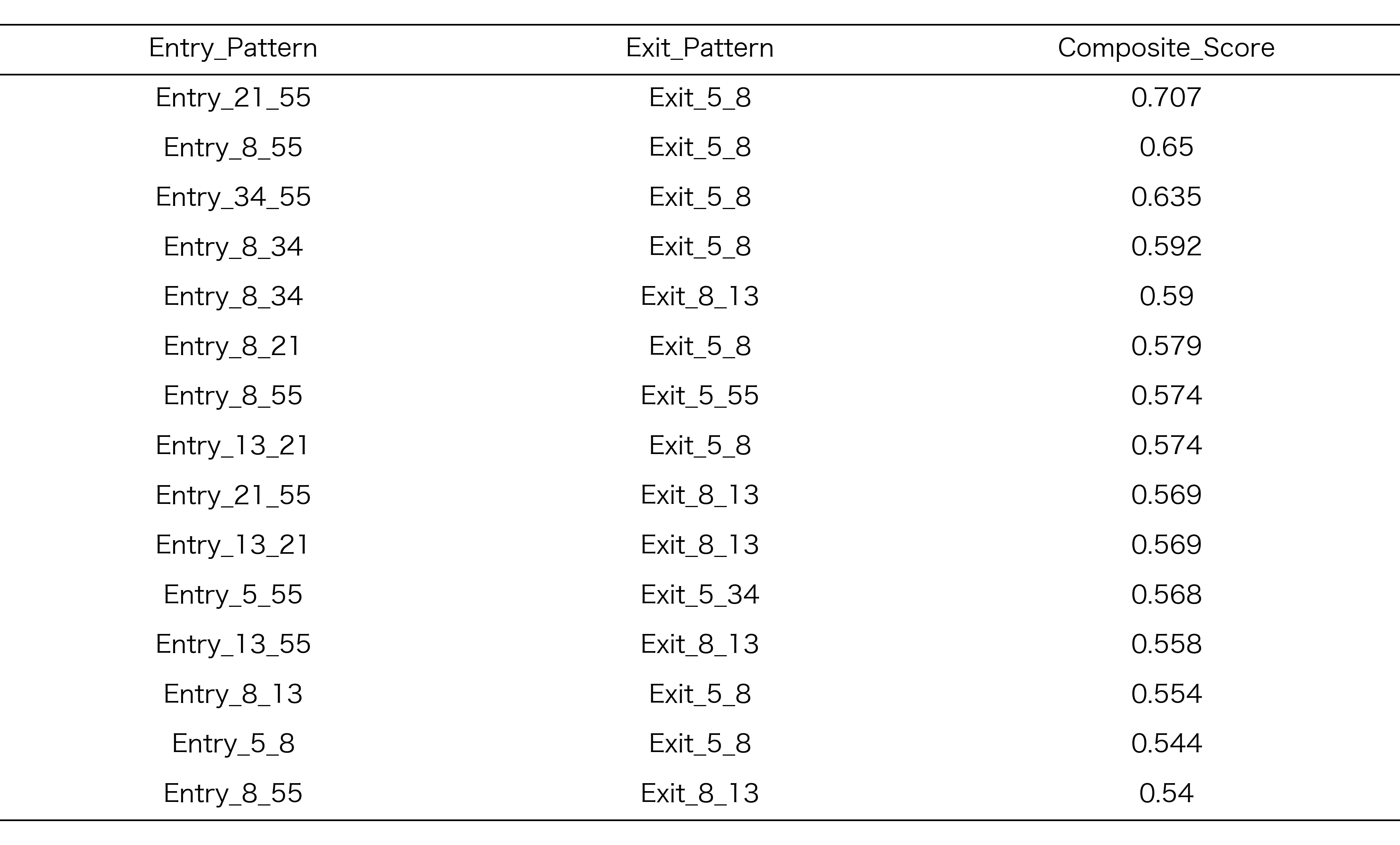
表1: 3期間すべてでシャープレシオ0.65以上を記録した19のRCIコンビ
地合スコア +3

地合スコア +2

地合スコア +1

地合スコア 0

地合スコア -1
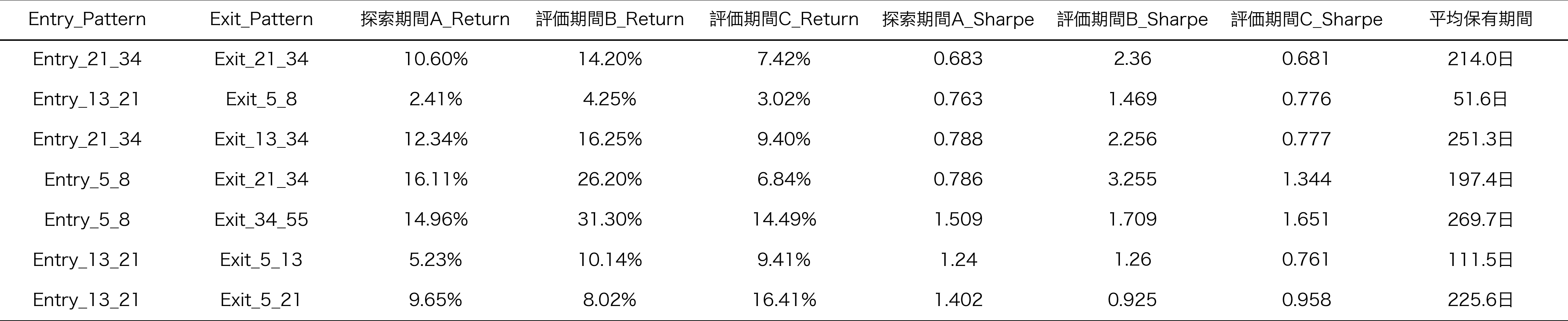
地合スコア -2

地合スコア -3

2. 悲観相場における優位性
地合スコアがマイナスの時の方が、プラスの時よりも多く選抜パターンが抽出され、投資機会として有望だと考えられました。
- 地合スコア -1〜-3の悲観市場:12 RCIコンビ
- 楽観市場(+1〜+3):6 RCIコンビ
- ただし、地合スコアとRCIコンビの数が直線的な関係というわけではなく、-1と2に極大があり、ニ峰性の傾向あり
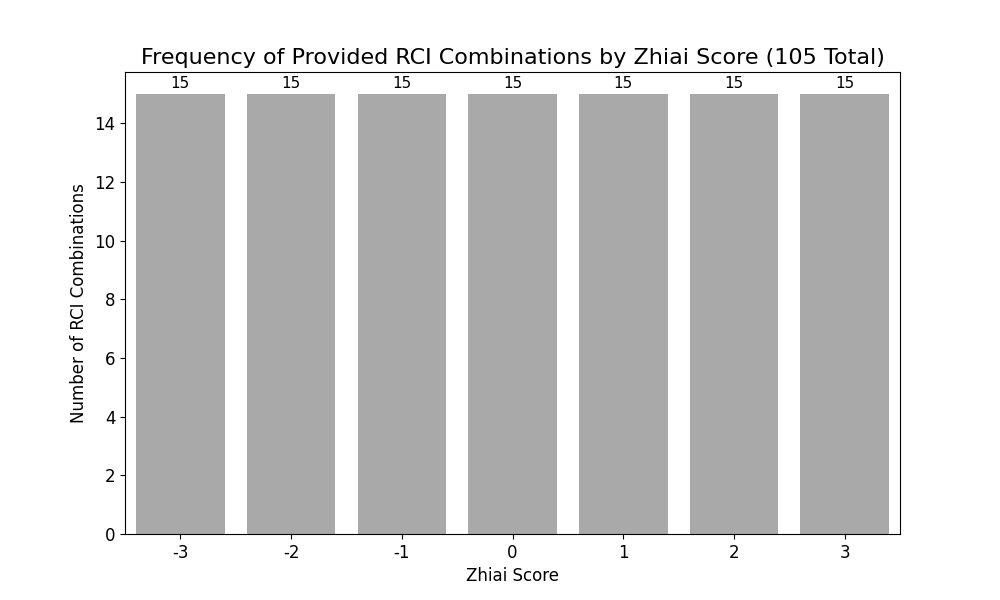
図5: 探索期間各地合スコア上位15RCIコンビの数
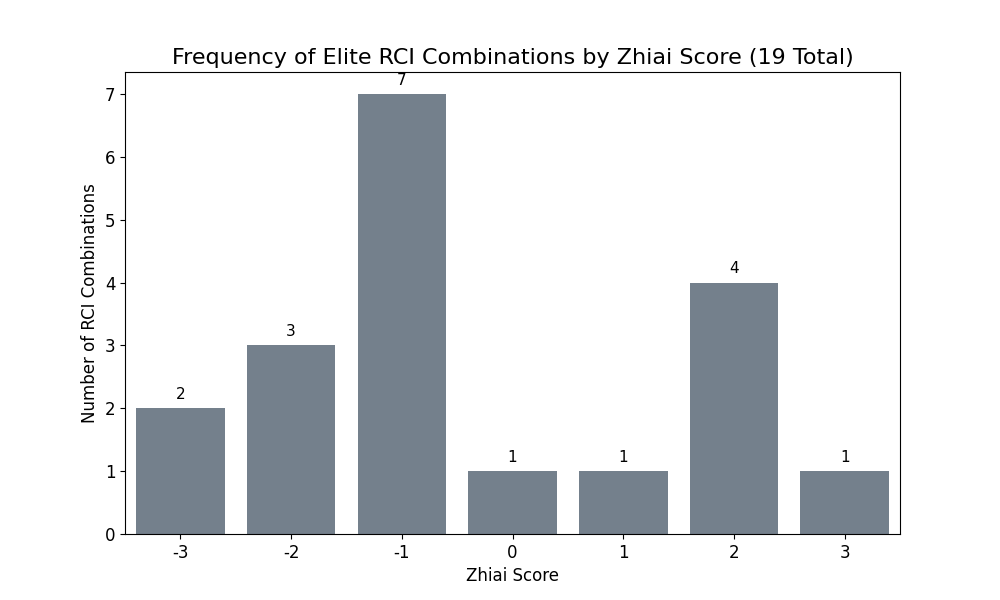
図6: 探索期間で抽出されたもののうち、2つの評価期間いずれも0.65以上だったRCIコンビの数
3. 中期スイング投資に有用なパターン
最初に選抜した異なる期間でも安定して機能する19個のRCIコンビに対し、さらに**「全評価期間で平均保有期間が170日以下」**という条件を加え、中長期スイングトレードに最適な戦略を最終選抜しました。
その結果、7つのコンビが全ての基準を満たす、組み合わせとして特定されました。
地合スコア -2、-1および+2の相場状況の時に、50-150日程度の保有期間でで中期スイング投資に適した保有期間のRCIコンビが含まれていました。「買いは慎重に(中期RCIでノイズを除去)、売りは素早く(短期RCIで機敏に)」という組み合わせがここでも選ばれていると思われます。
表2: 中期投資に適したRCIコンビ(50-150日保有期間)
地合スコア +2

地合スコア -1

地合スコア -2

まとめと今後の展望
今回の分析により、以下の結果が得られました。
結果と考察
選抜されたRCIコンビの特徴
3期間すべてでシャープレシオ0.65以上を示した19個のRCIコンビにおいて、エントリーでは中期RCI(13, 21, 34)の組み合わせが、エグジットでは短期RCI(5, 8)を含む組み合わせが頻出する傾向が観察されました。これを踏まえると、エントリー時にはノイズを除去した確実な転換点を捉え、エグジット時には機敏に利益を確定する戦略が、安定したリターンを得るために有効であることが推測できます。
市場環境による投資機会の差異
地合スコア-1〜-3の市場で12個、+1〜+3の市場で6個のRCIコンビが選抜され、悲観市場での選抜数が楽観市場の2倍となりました。これは、悲観市場における反転機会の豊富さを示唆しています。
中期投資戦略の実現可能性
19個のRCIコンビから平均保有期間170日以下の条件で絞り込み、7つのRCIコンビが中期スイング投資の基準を満たしました。これにより、中期投資においても一定のパフォーマンスを発揮するRCIスパンの組み合わせの存在が確認されました。
今後の課題
汎化性能の検証
今回確認されたパターンの汎化性能を2024年以降の未知データで検証する必要があります。特に、異なる市場環境下での安定性を確認することが重要です。
実用性の向上
ドローダウン管理や取引コストを考慮した実用的なモデルの開発が必要です。また、実際の運用におけるリスク管理手法の検討も今後の課題として挙げられます。
戦略の最適化
市場環境に応じた戦略の自動選択メカニズムの開発や、より詳細な市場環境の分類手法の検討も今後の研究課題です。
補足:全データの全体傾向の可視化
参考までに、選抜に使用した各地合スコア(-3 - +3)ごとの225個のRCIコンビのデータ(1575通り/各評価期間)を可視化した結果も紹介します。
今回のRCIコンビの選抜に使用したベースのデータです。
保有期間全体リターン
探索期間A

評価期間B

評価期間C

図7: 保有期間全体リターン
保有期間全体リターンでは、3期間を通じて一貫したパターンが見られます。探索期間Aで高リターンを記録したRCIコンビの多くが、評価期間B・Cでも同様に高いリターンを維持しており、RCIによる選抜で選ばれる銘柄のリターンには普遍性があると推測されます。
2023年(評価期間B)では全体的にリターンが高く、多くのRCIコンビで10%以上のリターンを記録しました。一方、2024年(評価期間C)では市場環境の変化により全体的にリターンが低下しました。
長期RCIコンビ(34-55)は全体的に安定したリターンを記録する傾向があり、これは長期の市場トレンドを捉えることで、短期的な市場変動の影響を軽減でき、どのような相場状況・投資期間においても安定した成績を発揮する可能性を示唆しています。
1日あたりリターン
探索期間A

評価期間B

評価期間C

図8: 1日あたりリターン
1日あたりリターンは投資効率を評価する重要な指標です。保有期間全体リターンと1日あたりリターンを比較することで、時間効率の観点から戦略の優劣を判断できます。
3期間を通じて、1日あたりリターンは、保有期間全体のリターンと反転している傾向があるように思えます。
2023年(評価期間B)では全体的に1日あたりリターンが高く、多くのRCIコンビで0.1%以上の値を記録しました。2024年(評価期間C)では全体的に値が低下しましたが、一部のRCIコンビは相対的に高い値を維持しています。
これらのパターンには何らかの法則性があると考えられますが、今後検討の余地が残っています。
保有期間全体シャープレシオ
探索期間A

評価期間B

評価期間C

図9: 保有期間全体シャープレシオ
これも、3期間を通じて、類似した傾向があると思われます。中期長期のRCIの組み合わせの時に、シャープレシオが高い傾向があるのは、リターンと同様の傾向でした。
2023年(評価期間B)では全体的にシャープレシオが高く、多くのRCIコンビで1.0以上の値を記録しました。2024年(評価期間C)では市場環境の変化により全体的にシャープレシオが低下しました。
1日あたりシャープレシオ
探索期間A

評価期間B

評価期間C

図10: 1日あたりシャープレシオ
3期間を通じて、1日あたりシャープレシオにも一定のパターンが見られます。
2023年(評価期間B)では全体的に1日あたりシャープレシオが高く、多くのRCIコンビで.0以上の値を記録しました。2024年(評価期間C)では全体的に値が低下しましたが、一部のRCIコンビは相対的に高い値を維持しています。
平均保有期間
探索期間A

評価期間B

評価期間C

図11: 平均保有期間
これも3期間において、類似した傾向が見られます。2024年の保有期間が短いのは、保有データ末までにDCをしなかったデータを除いているためです。
選抜銘柄数
探索期間A

評価期間B

評価期間C

図12: 選抜銘柄数
一日あたりの平均選抜銘柄数を示しています。いずれの期間においても概ね同じパターンであることが確認できます。
いずれの期間においても大半のRCIコンビが1以上を示したため、実際のスクリーニング運用の際に、銘柄が選抜されない期間が長く続く可能性は低いと思われます。地合スコア-2および-1の時に、銘柄数が多いところは、前回記事とも再現性があります。
探索期間での正規化ランキング
探索期間Aにおいて、各地合スコアごとに上位15位に選抜されたRCIコンビの正規化ランキング結果を以下に示します。このランキングは、リターン、シャープレシオ、保有期間のバランスを考慮した総合スコアに基づいています
表3:探索期間Aでランクが高かったRCIコンビ
地合スコア +3
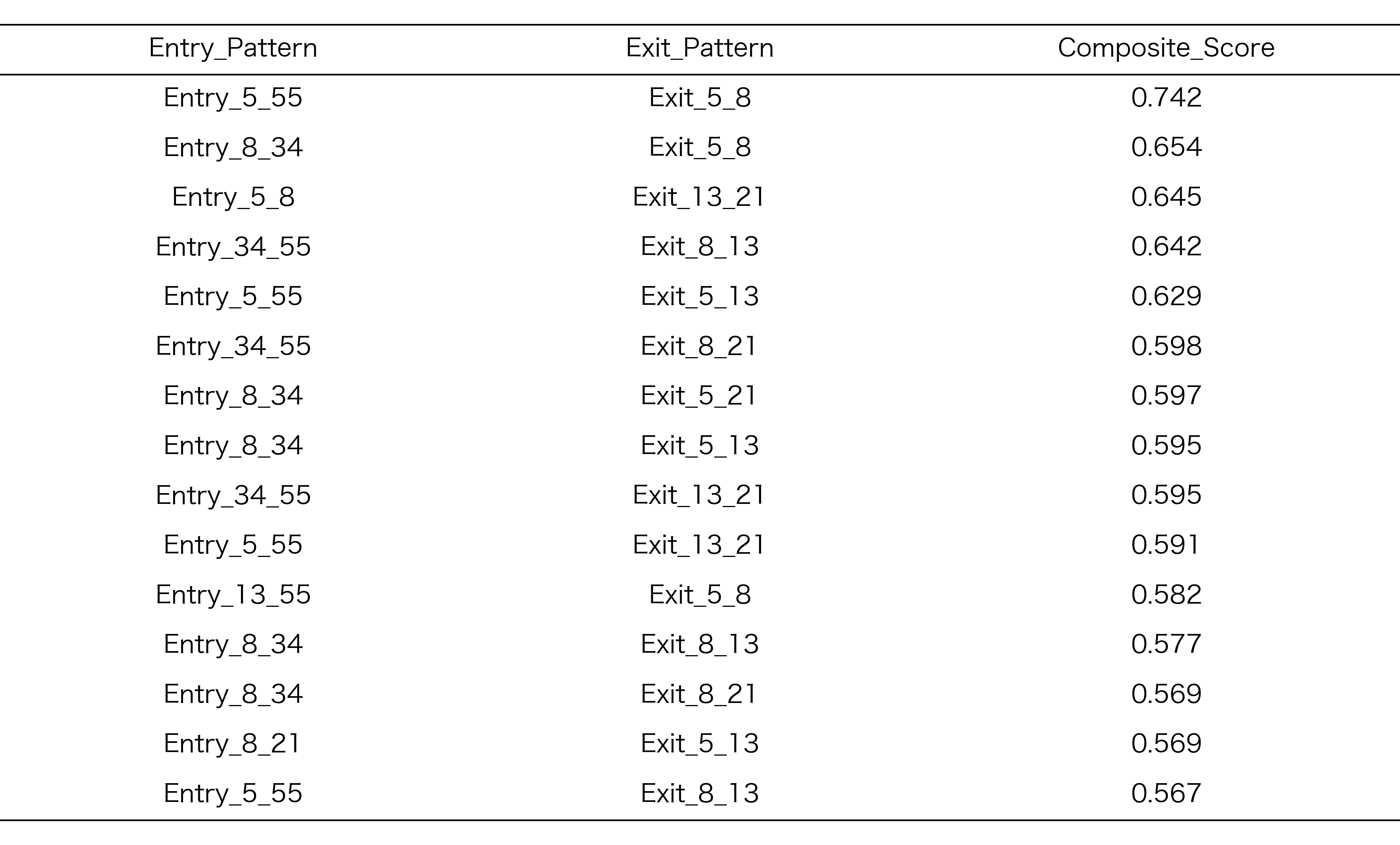
地合スコア +2
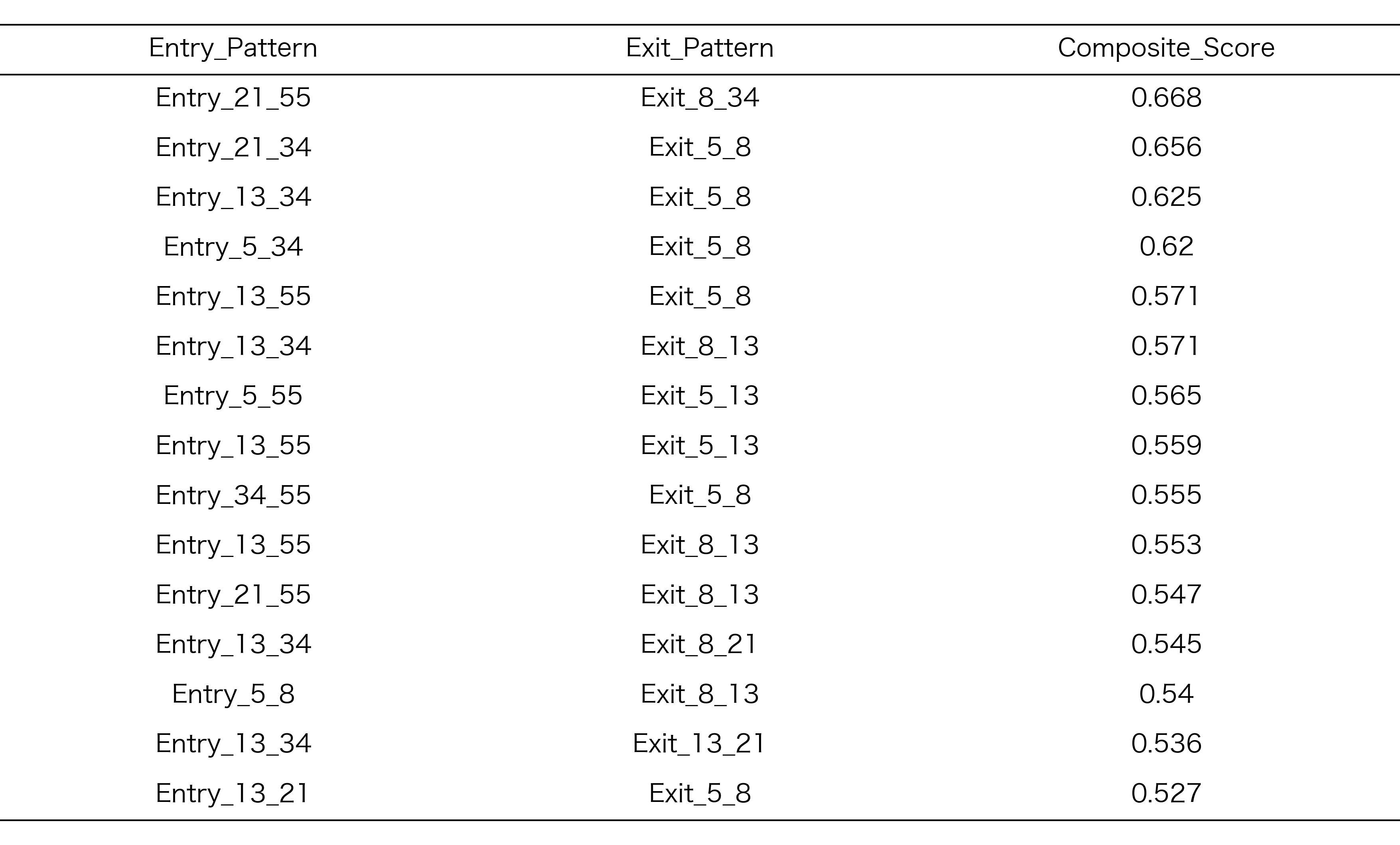
地合スコア +1
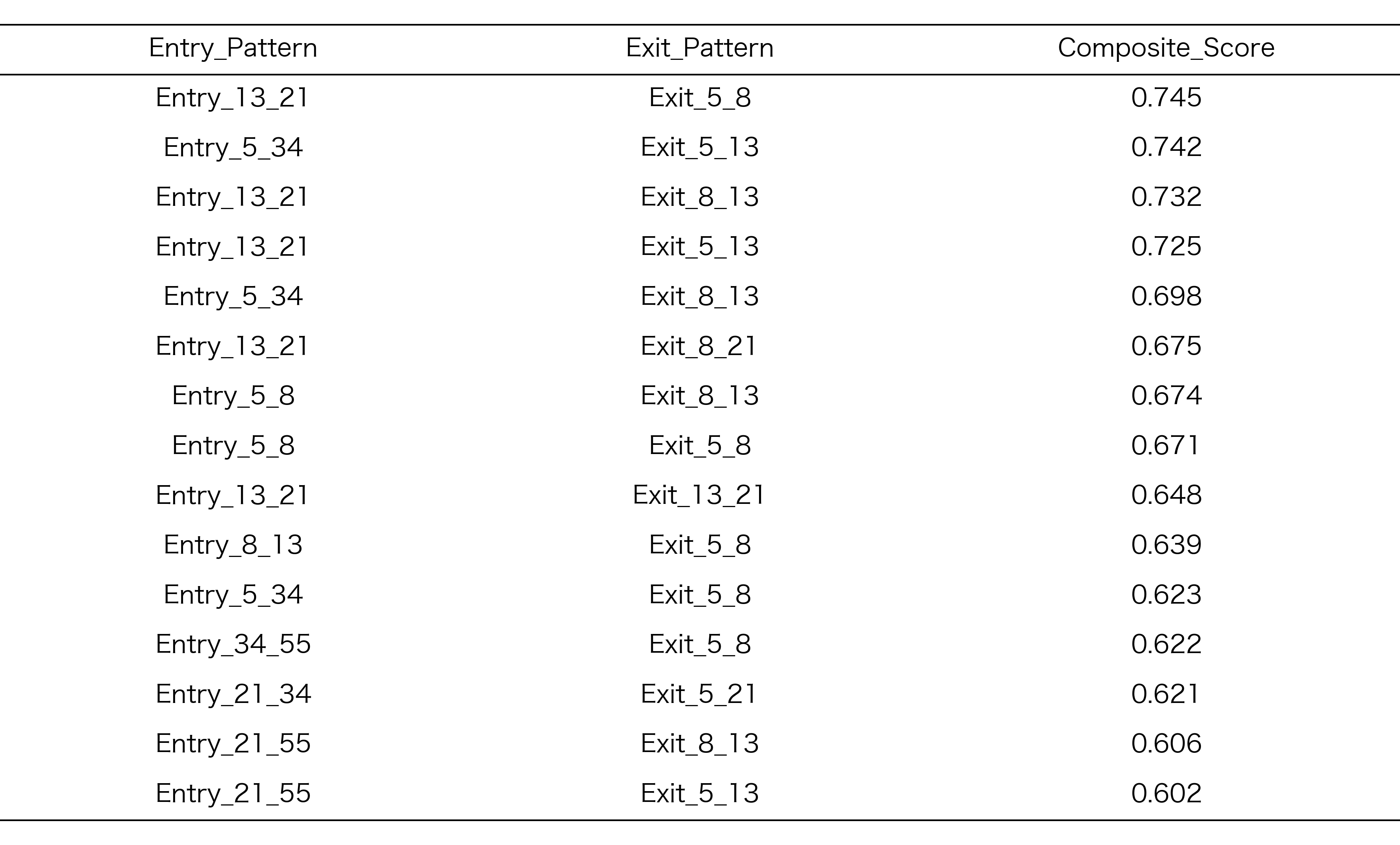
地合スコア 0
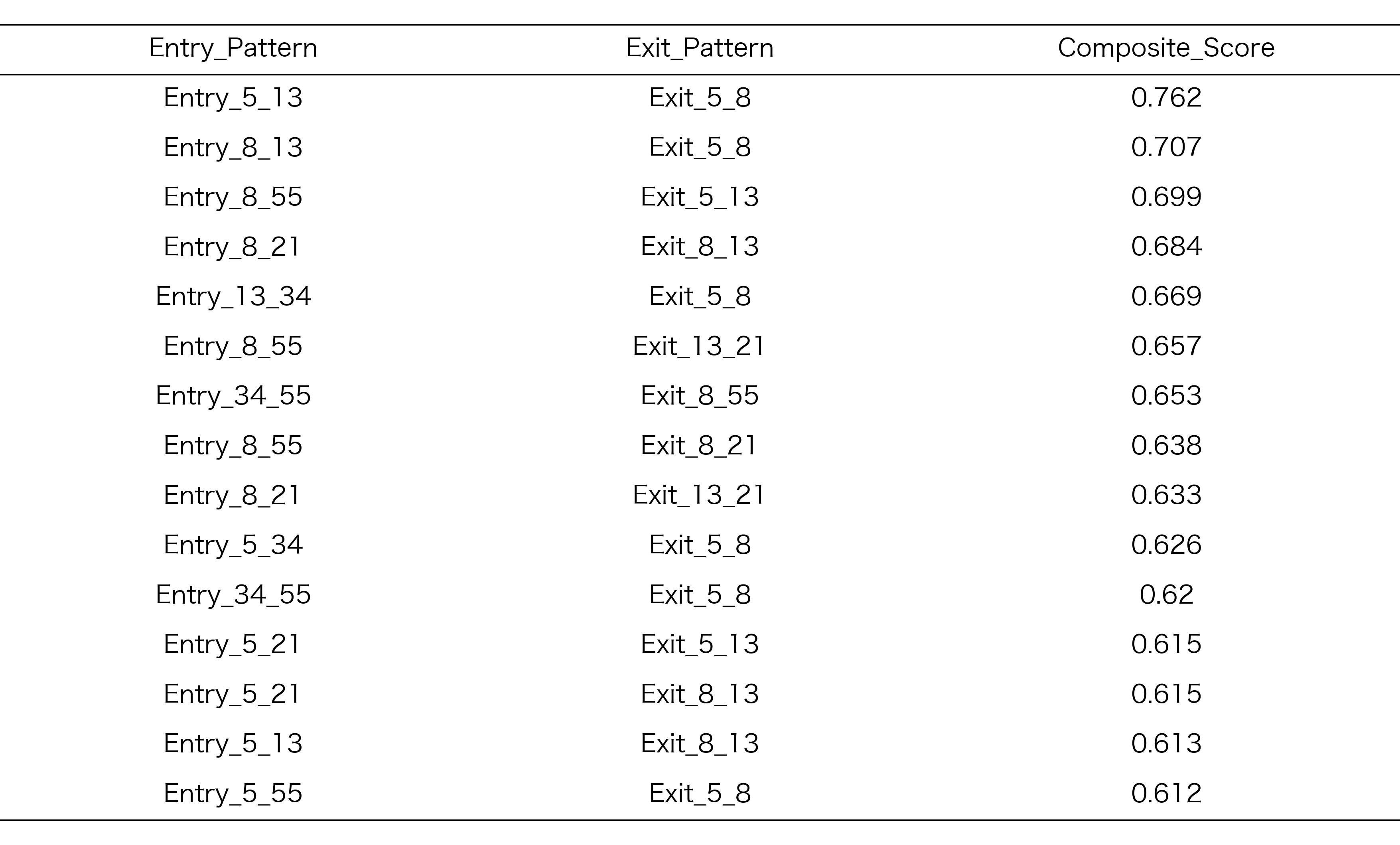
地合スコア -1
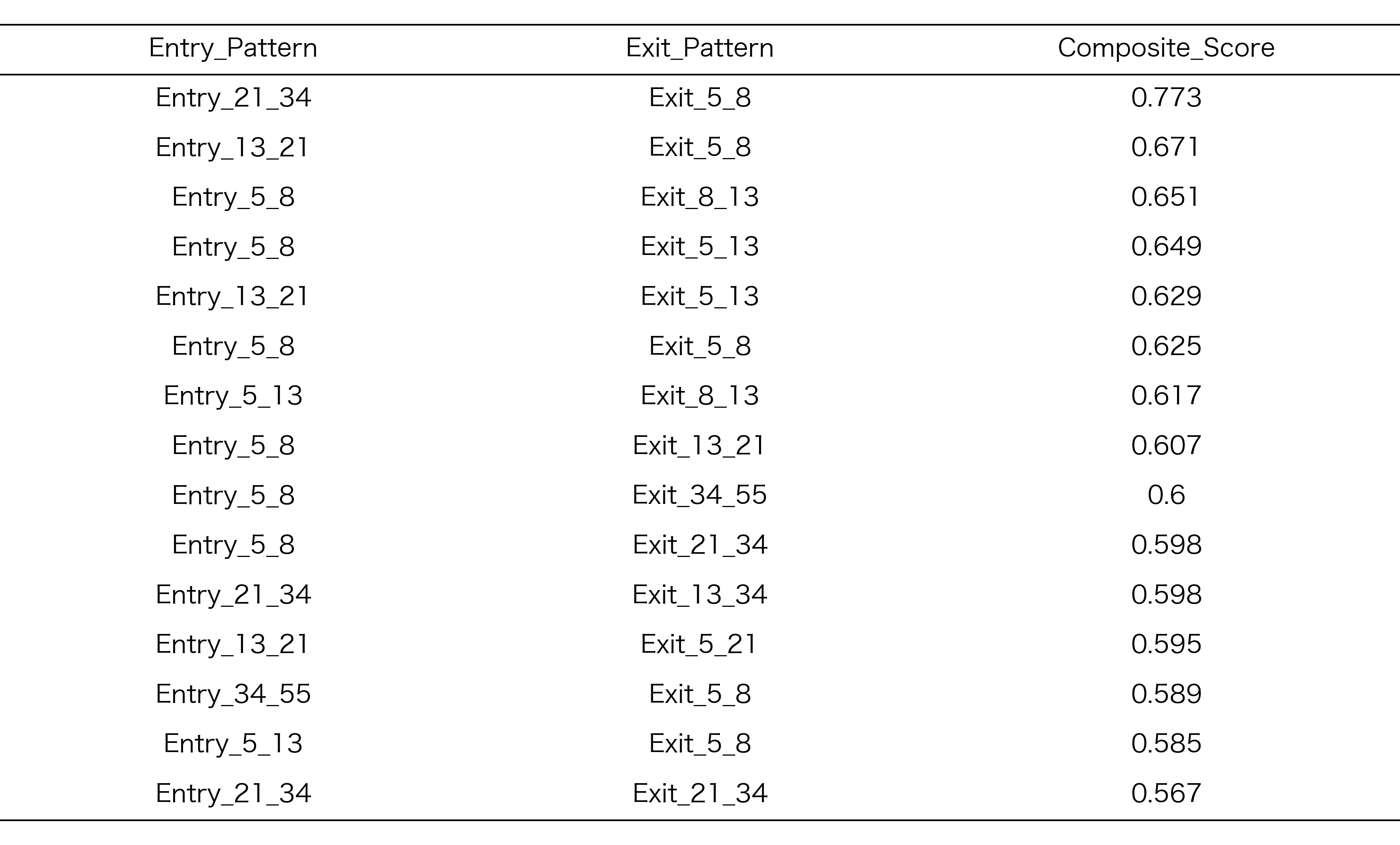
地合スコア -2
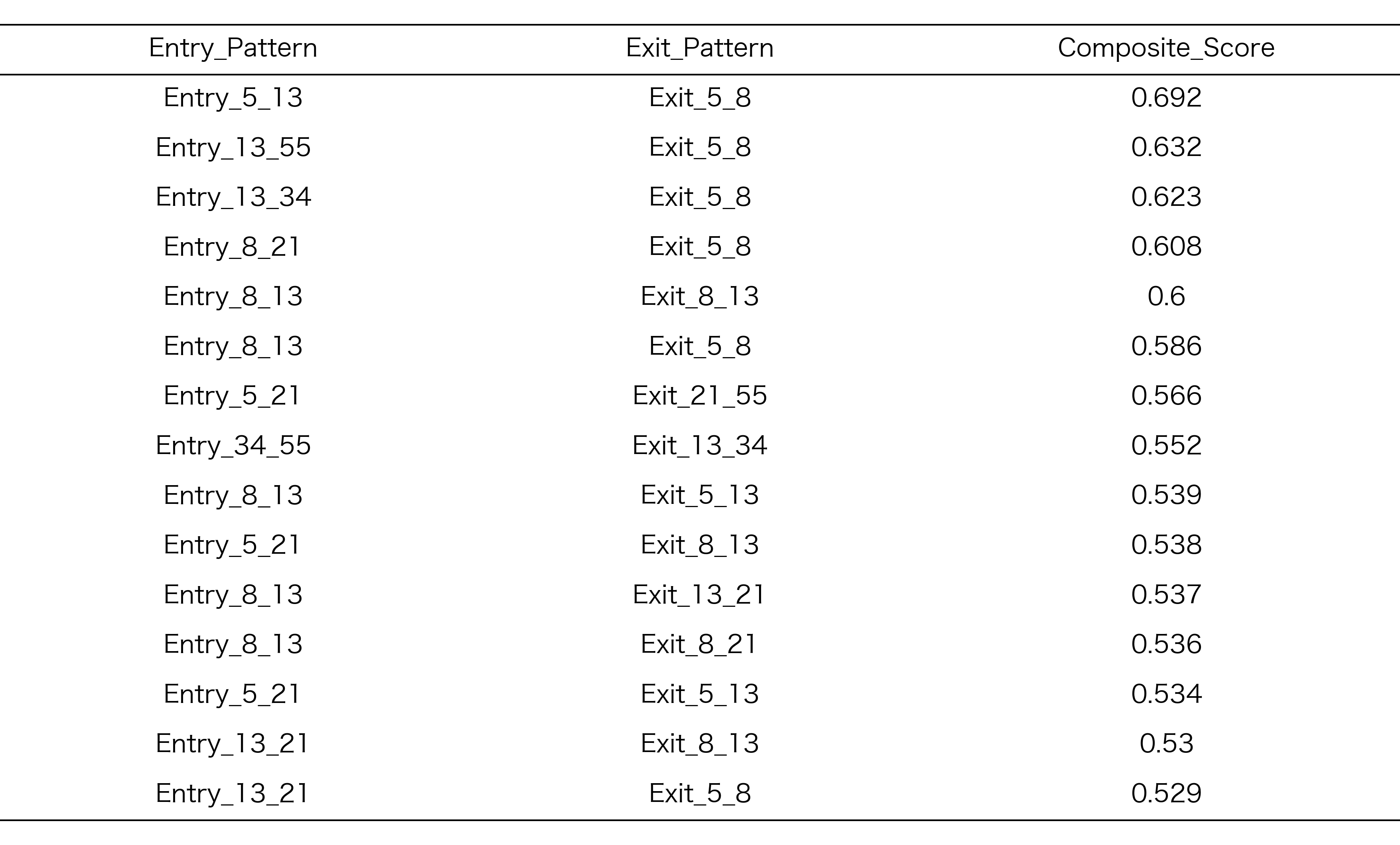
地合スコア -3
# -----------------------------
# RCI225通り + バックテスト
# -----------------------------
import time
global_start_time = time.time()
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
import numpy as np
import os
from tqdm.notebook import tqdm
import yfinance as yf
from curl_cffi import requests
import glob
import matplotlib.pyplot as plt
import seaborn as sns
from itertools import combinations, product
session = requests.Session(impersonate="safari15_5")
# --------------------------------------------------
#ヘルパー関数セクション
# --------------------------------------------------
def calculate_market_sentiment_score(ticker_symbol: str, start_date: str, end_date: str, session) -> pd.DataFrame:
"""
指定されたティッカーシンボル(TOPIX連動ETFなど)のデータに基づき、地合いスコアを計算する。
"""
print(f"地合いスコア計算のため、{ticker_symbol} のデータをダウンロード中...")
start_str = pd.Timestamp(start_date).strftime('%Y-%m-%d')
end_str = pd.Timestamp(end_date).strftime('%Y-%m-%d')
market_data = yf.download(ticker_symbol, start=start_str, end=end_str, interval="1d", session=session, auto_adjust=False)
if market_data.empty:
print(f"{ticker_symbol} のデータが見つかりません。")
return pd.DataFrame()
if isinstance(market_data.columns, pd.MultiIndex):
market_data.columns = market_data.columns.get_level_values(0)
market_data["LogReturn"] = np.log(market_data["Close"] / market_data["Close"].shift(1))
market_data["MA25"] = market_data["Close"].rolling(25).mean()
market_data["MA25_diff"] = (market_data["Close"] - market_data["MA25"]) / market_data["MA25"]
delta = market_data["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=market_data.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=market_data.index).rolling(14).mean()
rs = avg_gain / (avg_loss.replace(0, np.nan) + 1e-10)
market_data["RSI_14"] = 100 - (100 / (1 + rs))
market_data["score_today"] = 0
market_data["score_today"] += (market_data["LogReturn"].rolling(5).sum() > 0.01).astype(int)
market_data["score_today"] += (market_data["MA25_diff"] > 0).astype(int)
market_data["score_today"] += (market_data["RSI_14"] > 55).astype(int)
market_data["score_today"] -= (market_data["RSI_14"] < 45).astype(int)
market_data["score_today"] -= (market_data["LogReturn"].rolling(5).sum() < -0.01).astype(int)
market_data["score_today"] -= (market_data["MA25_diff"] < 0).astype(int)
market_data.index.name = 'Date'
market_df = market_data.dropna(subset=['score_today']).copy()
print(f"地合いスコア計算完了 ({ticker_symbol})。")
return market_df
# RCI計算関数 - MultiIndex (Ticker, Date) に対応
def calculate_rci(df_group, periods):
"""
個別銘柄のデータフレーム(MultiIndex: Ticker, Date)を受け取り、指定された期間でRCIを計算して返す。
より安定した計算ロジックに修正。
"""
df = df_group.copy()
df_reset = df.reset_index()
df_reset['date_rank_base'] = df_reset.groupby('Ticker').cumcount() + 1
df = df_reset.set_index(['Ticker', 'Date'])
for period in periods:
price_rank = df.groupby(level='Ticker')['Close'].transform(
lambda x: x.rolling(window=period).rank(ascending=False, pct=False)
)
date_rank = df.groupby(level='Ticker')['date_rank_base'].transform(
lambda x: x.rolling(window=period).rank(ascending=False, pct=False)
)
d_sq_sum = ((date_rank - price_rank)**2).groupby(level='Ticker').transform(
lambda x: x.rolling(window=period).sum()
)
n = period
denominator = n * (n**2 - 1)
if denominator != 0:
df[f'RCI_{period}'] = (1 - (6 * d_sq_sum) / denominator) * 100
else:
df[f'RCI_{period}'] = np.nan
if 'date_rank_base' in df.columns:
df = df.drop(columns=['date_rank_base'])
rci_cols = [col for col in df.columns if col.startswith('RCI_')]
return df[rci_cols]
# Tech Indicatorの計算関数 (MA, RSI, RCIを含む)
def calculate_technical_indicators(df_group, rci_periods):
"""
個別銘柄のデータフレーム(MultiIndex: Ticker, Date)を受け取り、移動平均、RSI、傾き、RCIを計算して返す。
"""
if df_group.empty: return df_group
df = df_group.copy()
processed_ticker_parts = []
for ticker, ticker_df_orig in df.groupby(level='Ticker'):
ticker_df = ticker_df_orig.sort_index(level='Date').copy()
if len(ticker_df) < max(rci_periods) + 5: # ★最小期間チェック
processed_ticker_parts.append(ticker_df)
continue
ticker_df["MA_5"] = ticker_df["Close"].rolling(window=5).mean()
ticker_df["MA_25"] = ticker_df["Close"].rolling(window=25).mean()
ticker_df["MA_75"] = ticker_df["Close"].rolling(window=75).mean()
delta = ticker_df["Close"].diff()
gain = np.where(delta > 0, delta, 0)
loss = np.where(delta < 0, -delta, 0)
avg_gain = pd.Series(gain, index=ticker_df.index).rolling(14).mean()
avg_loss = pd.Series(loss, index=ticker_df.index).rolling(14).mean()
rs = avg_gain / (avg_loss.replace(0, np.nan) + 1e-10)
ticker_df["RSI"] = 100 - (100 / (1 + rs))
processed_ticker_parts.append(ticker_df)
if processed_ticker_parts:
df_processed_ma_rsi_slope = pd.concat(processed_ticker_parts).sort_index()
else:
return pd.DataFrame() # 空のDFを返す
df_rci = calculate_rci(df_processed_ma_rsi_slope, periods=rci_periods)
df_combined = df_processed_ma_rsi_slope.merge(df_rci, left_index=True, right_index=True, how='left')
return df_combined
def analyze_and_visualize_summary(summary_df: pd.DataFrame, base_output_dir: str):
"""入口・出口パターン別に集計し、指定の条件でハイライトする"""
print("\n--- 📊 バックテスト結果の分析と可視化を開始します ---")
df = summary_df.copy()
column_rename_map = { "地合いスコア(当日)": "Score_Today", "平均リターン(DC)%": "Return_DC", "勝率(DC)%": "WinRate_DC", "平均保有期間(DC)": "HoldingPeriod_DC", "銘柄数": "Stock_Count" }
df = df.rename(columns=column_rename_map)
fig_dir = os.path.join(base_output_dir, "figs")
os.makedirs(fig_dir, exist_ok=True)
performance_summary = df.groupby(['Entry_Pattern', 'Exit_Pattern']).agg( Mean_Return=('Return_DC', 'mean'), Std_Return=('Return_DC', 'std'), Mean_Stock_Count=('Stock_Count', 'mean') ).reset_index()
performance_summary['Std_Return'] = performance_summary['Std_Return'].replace(0, np.nan)
performance_summary['Sharpe_Ratio'] = performance_summary['Mean_Return'] / performance_summary['Std_Return']
highlight_conditions = (performance_summary["Sharpe_Ratio"] >= 1.0) & (performance_summary["Mean_Stock_Count"] >= 1)
highlight_set = set(zip( performance_summary[highlight_conditions]["Entry_Pattern"], performance_summary[highlight_conditions]["Exit_Pattern"] ))
return_pivot = performance_summary.pivot(index="Entry_Pattern", columns="Exit_Pattern", values="Mean_Return")
plt.figure(figsize=(16, 12)); ax = sns.heatmap(return_pivot, annot=True, fmt=".2f", cmap="RdYlGn", center=0, linewidths=.5)
for i, entry_pattern in enumerate(return_pivot.index):
for j, exit_pattern in enumerate(return_pivot.columns):
if (entry_pattern, exit_pattern) in highlight_set:
ax.text(j + 0.5, i + 0.5, "★", color="black", ha='center', va='center', fontsize=16, fontweight='bold')
plt.title("Average Return (Entry vs Exit) with ★ (SR>=1.0 & Stocks>=1)"); plt.xlabel("Exit Pattern"); plt.ylabel("Entry Pattern"); plt.xticks(rotation=45, ha='right'); plt.yticks(rotation=0); plt.tight_layout(); plt.savefig(os.path.join(fig_dir, "avg_return_heatmap_highlighted.png")); plt.close()
sharpe_pivot = performance_summary.pivot(index="Entry_Pattern", columns="Exit_Pattern", values="Sharpe_Ratio")
plt.figure(figsize=(16, 12)); sns.heatmap(sharpe_pivot, annot=True, fmt=".2f", cmap="coolwarm", center=0, linewidths=.5); plt.title("Sharpe Ratio (Entry vs Exit)"); plt.xlabel("Exit Pattern"); plt.ylabel("Entry Pattern"); plt.xticks(rotation=45, ha='right'); plt.yticks(rotation=0); plt.tight_layout(); plt.savefig(os.path.join(fig_dir, "sharpe_ratio_heatmap.png")); plt.close()
print("分析と可視化が完了しました。")
# --------------------------------------------------
# 設定・定義セクション
# --------------------------------------------------
input_base_dir = "財務スクリーニングの結果のディレクトリ"
output_base_dir = "お好きなディレクトリ"
os.makedirs(output_base_dir, exist_ok=True)
PARQUET_PATH_FOR_PREDICTION = "以前の記事で書いた、OHLCVのparquitデータセットのディレクトリ"
MARKET_INDEX_TICKER = '1306.T'
date_list = ['2021-01-04', '2021-01-08', '2021-01-15', '2021-01-19', '2021-01-27', '2021-01-28']
FIBONACCI_PERIODS = [5, 8, 13, 21, 34, 55]#ご自由に設定ください
FIXED_RSI_RANGE = (25, 50)#ご自由に設定ください
FIXED_RCI_EPS = 20#ご自由に設定ください
FIXED_ENTRY_RCI_NEGATIVE_THRESH = 0 #ご自由に設定ください
FIXED_SLOPE_PERIOD = 1#ご自由に設定ください
FIXED_RCI_SLOPE_THRESH = 0.5#ご自由に設定ください
FIXED_EXIT_RCI_POSITIVE_THRESH = 0 #ご自由に設定ください
entry_combos = list(combinations(FIBONACCI_PERIODS, 2))
exit_combos = list(combinations(FIBONACCI_PERIODS, 2))
all_pattern_combos = list(product(entry_combos, exit_combos))
master_pattern_df = pd.DataFrame(all_pattern_combos, columns=['Entry_Combo', 'Exit_Combo'])
master_pattern_df['Entry_Pattern'] = [f"Entry_{c[0]}_{c[1]}" for c in master_pattern_df['Entry_Combo']]
master_pattern_df['Exit_Pattern'] = [f"Exit_{c[0]}_{c[1]}" for c in master_pattern_df['Exit_Combo']]
master_pattern_df['PatternID'] = [f"P{i:03d}" for i in range(1, len(master_pattern_df) + 1)]
master_pattern_df = master_pattern_df[['PatternID', 'Entry_Pattern', 'Exit_Pattern', 'Entry_Combo', 'Exit_Combo']]
mapping_path = os.path.join(output_base_dir, 'pattern_id_mapping.csv')
master_pattern_df[['PatternID', 'Entry_Pattern', 'Exit_Pattern']].to_csv(mapping_path, index=False)
print(f"マスターID対応表を先に作成・保存しました: {mapping_path}")
print(f" 合計検証パターン数: {len(master_pattern_df)} 通り")
# ------------------------------------------------------------------------------
# メイン処理
# ------------------------------------------------------------------------------
print("\n--- 全データセットの読み込みとテクニカル指標の事前計算を開始します ---")
global_data_load_start_time = time.time()
earliest_screening_date = pd.Timestamp(date_list[0])
max_lookback_days = 250
max_lookahead_days = 365 * 2
global_data_start_date = earliest_screening_date - pd.Timedelta(days=max_lookback_days)
global_data_end_date = pd.Timestamp(date_list[-1]) + pd.Timedelta(days=max_lookahead_days)
print(f"分析対象期間: {global_data_start_date.strftime('%Y-%m-%d')} から {global_data_end_date.strftime('%Y-%m-%d')}")
try:
df_market_sentiment = calculate_market_sentiment_score(
ticker_symbol=MARKET_INDEX_TICKER,
start_date=global_data_start_date, # 動的な開始日を使用
end_date=global_data_end_date,
session=session
)
df_market_sentiment_to_merge = df_market_sentiment[['score_today']].copy()
except Exception as e:
print(f"致命的エラー: 地合いスコアの計算に失敗しました: {e}")
df_market_sentiment_to_merge = pd.DataFrame(columns=['score_today'])
try:
df_all_data = pd.read_parquet(
PARQUET_PATH_FOR_PREDICTION,
columns=['Date', 'Ticker', 'Open', 'High', 'Low', 'Close', 'Volume'],
filters=[('Date', '>=', global_data_start_date), ('Date', '<=', global_data_end_date)]
)
df_all_data["Date"] = pd.to_datetime(df_all_data["Date"])
df_all_data["Ticker"] = df_all_data["Ticker"].str.replace(".T", "", regex=False)
except Exception as e:
print(f"エラー: 全データセットの読み込みに失敗しました: {e}")
exit()
df_all_data_processed = pd.merge(df_all_data, df_market_sentiment_to_merge.reset_index(), on='Date', how='left')
df_all_data_processed = df_all_data_processed.set_index(["Ticker", "Date"]).sort_index()
print("全銘柄のテクニカル指標(RSI, 全RCI, 全傾き)を計算中...")
df_all_data_processed = calculate_technical_indicators(df_all_data_processed, FIBONACCI_PERIODS)
for period in FIBONACCI_PERIODS:
df_all_data_processed[f'RCI_{period}_slope'] = df_all_data_processed.groupby(level='Ticker')[f'RCI_{period}'].diff(FIXED_SLOPE_PERIOD)
global_data_load_end_time = time.time()
print(f" 全データセットの読み込みとテクニカル指標の事前計算が完了しました。所要時間: {global_data_load_end_time - global_data_load_start_time:.2f} 秒")
all_days_summary = []
for today_str in tqdm(date_list, desc="全体進捗 (日付別)"):
today = pd.Timestamp(today_str)
daily_output_dir = os.path.join(output_base_dir, f"2nd_RCI_results_{today_str}")
os.makedirs(daily_output_dir, exist_ok=True)
input_csv_path = os.path.join(input_base_dir, f'1st_filtered_{today_str}.csv')
try:
df_list = pd.read_csv(input_csv_path)
except FileNotFoundError:
print(f"エラー: 1stスクリーニング結果ファイルが見つかりません: {input_csv_path}")
continue
score_today_val = np.nan
try:
if not df_market_sentiment.empty and today in df_market_sentiment.index:
score_today_val = df_market_sentiment.loc[today, 'score_today']
elif not df_market_sentiment.empty:
valid_dates = df_market_sentiment.index[df_market_sentiment.index <= today]
if not valid_dates.empty:
score_today_val = df_market_sentiment.loc[valid_dates[-1], 'score_today']
except Exception as e:
print(f"地合いスコア取得中にエラー: {e}")
daily_results = []
for index, pattern_row in tqdm(master_pattern_df.iterrows(), total=len(master_pattern_df), desc=f" ↳ 日付 {today_str} の全パターン処理", leave=False):
pattern_id, entry_combo, exit_combo, entry_pattern_name, exit_pattern_name = pattern_row['PatternID'], pattern_row['Entry_Combo'], pattern_row['Exit_Combo'], pattern_row['Entry_Pattern'], pattern_row['Exit_Pattern']
entry_p1, entry_p2 = entry_combo
exit_p1, exit_p2 = exit_combo
hit_stocks_for_entry = []
for _, row in df_list.iterrows():
ticker = str(row["LocalCode"])[0:4]
try:
if (ticker, today) not in df_all_data_processed.index:
ticker_data = df_all_data_processed.loc[ticker]
valid_dates = ticker_data.index[ticker_data.index <= today]
if valid_dates.empty: continue
screening_date = valid_dates[-1]
else:
screening_date = today
if (ticker, screening_date) not in df_all_data_processed.index: continue
last_row = df_all_data_processed.loc[(ticker, screening_date)]
rci_short, rci_mid, rci_slope, rsi_last, close_last = last_row.get(f"RCI_{entry_p1}"), last_row.get(f"RCI_{entry_p2}"), last_row.get(f"RCI_{entry_p1}_slope"), last_row.get("RSI"), last_row.get("Close")
if any(pd.isna([rci_short, rci_mid, rci_slope, rsi_last, close_last])): continue
rci_convergence_flag, gc_flag, rci_slope_flag, rsi_flag = (abs(rci_short - rci_mid) < FIXED_RCI_EPS), (rci_mid < FIXED_ENTRY_RCI_NEGATIVE_THRESH) and (abs(rci_short - rci_mid) < FIXED_RCI_EPS), rci_slope > FIXED_RCI_SLOPE_THRESH, (FIXED_RSI_RANGE[0] < rsi_last < FIXED_RSI_RANGE[1])
if gc_flag and rci_slope_flag and rsi_flag:
hit_stocks_for_entry.append({ "Ticker": ticker, "Name": row.get("Name", "NoName"), "Screening_Date": screening_date, "Close_Last": close_last })
except (KeyError, IndexError, TypeError): continue
df_hits = pd.DataFrame(hit_stocks_for_entry)
df_hits.to_csv(os.path.join(daily_output_dir, f"{pattern_id}_stocks_{today_str}.csv"), index=False)
exit_results = []
if not df_hits.empty:
for _, entry_data in df_hits.iterrows():
ticker, screening_date, close_last = entry_data["Ticker"], entry_data["Screening_Date"], entry_data["Close_Last"]
try:
future_data = df_all_data_processed.loc[ticker].loc[screening_date:].iloc[1:]
exit_date, exit_price = None, np.nan
for i in range(1, len(future_data)):
prev_day, current_day = future_data.iloc[i-1], future_data.iloc[i]
rci_exit_short_current, rci_exit_long_current, rci_exit_short_prev, rci_exit_long_prev = current_day.get(f'RCI_{exit_p1}'), current_day.get(f'RCI_{exit_p2}'), prev_day.get(f'RCI_{exit_p1}'), prev_day.get(f'RCI_{exit_p2}')
if pd.isna(rci_exit_short_current) or pd.isna(rci_exit_long_current) or pd.isna(rci_exit_short_prev) or pd.isna(rci_exit_long_prev): continue
is_positive_zone, is_crossed_down = (rci_exit_short_current > FIXED_EXIT_RCI_POSITIVE_THRESH and rci_exit_long_current > FIXED_EXIT_RCI_POSITIVE_THRESH), (rci_exit_short_prev > rci_exit_long_prev and rci_exit_short_current < rci_exit_long_current)
if is_positive_zone and is_crossed_down:
exit_date, exit_price = current_day.name, current_day['Close']
break
return_val, holding_period = (((exit_price - close_last) / close_last) * 100, (exit_date.date() - screening_date.date()).days) if exit_date else (np.nan, np.nan)
exit_results.append({"Return": return_val, "HoldingPeriod": holding_period})
except (KeyError, IndexError, TypeError):
exit_results.append({"Return": np.nan, "HoldingPeriod": np.nan})
df_exit_results = pd.DataFrame(exit_results)
mean_return, win_rate, avg_holding_period = (df_exit_results["Return"].mean(), (df_exit_results["Return"] > 0).mean() * 100 if df_exit_results["Return"].notna().any() else np.nan, df_exit_results["HoldingPeriod"].mean()) if not df_exit_results.empty else (np.nan, np.nan, np.nan)
daily_results.append({ "Date": today_str, "PatternID": pattern_id, "Entry_Pattern": entry_pattern_name, "Exit_Pattern": exit_pattern_name, "銘柄数": len(df_exit_results), "平均リターン(DC)%": mean_return, "勝率(DC)%": win_rate, "平均保有期間(DC)": avg_holding_period, "地合いスコア(当日)": score_today_val })
pd.DataFrame(daily_results).to_csv(os.path.join(daily_output_dir, f"summary_{today_str}.csv"), index=False, float_format='%.2f')
all_days_summary.extend(daily_results)
print("\n--- 全日付のサマリーファイルを集計します ---")
if all_days_summary:
df_combined_summary = pd.DataFrame(all_days_summary)
df_combined_summary.to_csv(os.path.join(output_base_dir, 'combined_summary_optimized.csv'), index=False, float_format='%.2f')
print(f" 統合サマリーファイルを保存しました: {os.path.join(output_base_dir, 'combined_summary_optimized.csv')}")
print("--- 統合サマリー (先頭5行) ---")
display(df_combined_summary.head())
analyze_and_visualize_summary(summary_df=df_combined_summary, base_output_dir=output_base_dir)
else:
print("集計対象のサマリーファイルが見つかりませんでした。")
global_end_time = time.time()
print(f"\n全処理完了!! 合計処理時間: {(global_end_time - global_start_time) / 60:.2f} 分 ({(global_end_time - global_start_time):.2f} 秒)")
参考
- Rank Correlation Index (RCI)
- RCI | オシレーター分析
- RCIとは?基本的な使い方やパラメーター設定値などを詳しく解説
- FXの過去検証(バックテスト)のやり方を5STEPでわかりやすく解説
- RCIのおすすめ設定期間とは?3本の組み合わせやデイトレ向きの最強設定も紹介!
- RCIのダイバージェンスを狙ったFXトレード手法 見つけ方から計算方法まで徹底解説
免責と注意点
この記事は、個人の投資研究の一環として公開したものです。参考情報であり、売買判断を保証するものではありません。投資判断は自己責任でお願いします。本分析は限定的なデータに基づいたものであり、異なる条件下では結果や解釈が変わる可能性があります。実際の運用にあたっては、地合い・セクター・ファンダメンタルズなど、複数の要因を組み合わせた総合的な判断が不可欠です。
2025年8月4日 マークダウンの表が特にスマホだと潰れて、醜くて仕方がなかったので、画像化しました。横に長いので、まだ醜いですが、最初よりは見やすいと思います
ので、どうかご勘弁を。