はじめに
筆者はかつてデータサイエンティストだった者です。
統計や機械学習をバリバリ使いこなしてデータを分析し、将来の売り上げ予測や要因分析、施策の効果検証などをすることに憧れてこの世界に入りましたが、そうした時間は全体の1割ほどに過ぎず、残り9割の時間の戦いに疲れて戦場を後にしました。
なぜデータサイエンティストは戦わなければならないのだろう。
おそらく一因としてあるのが、データサイエンティストという言葉がバズワード化しすぎてしまったせいで、その定義の輪郭が失われてしまったことだと思います。
整理された定義は、言わずと知れた尾崎隆さんのデータサイエンティスト・機械学習エンジニア・データアーキテクトの定義とスキル要件(2021年版)に記載されています。
しかし、専門家でも意見が別れる定義を素人がはっきりと分かるはずもなく、過度な期待が寄せられることで討死してしまうデータサイエンティストが少なからずいるのではないかと感じています。
本記事ではいくつかの戦いの記録を紹介してみようと思いますが、データサイエンティストになることをdiscourageしたり、不幸なデータサイエンティストが集まってエコーチェンバー現象を起こすことは本意ではありません。
避けられる戦いをなるべく避けて、データサイエンティストの不幸になる確率が少しでも下がれば幸いです。
目次
- データサイエンティストvs神エクセル
- データサイエンティストvsゴミデータ
- データサイエンティストvsパワーポイント
- データサイエンティストvs有効数字
- データサイエンティストvs外部とのデータやり取り
- データサイエンティストvs聴衆の背景知識
- データサイエンティストvs不正行為
データサイエンティストvs神エクセル
非エンジニア・データサイエンティストからするとデータサイエンティストは魔法使いですから、とりあえずエクセルファイル渡しとけばなんか良い感じのこと教えてくれると思われています。
エクセルファイルなだけならまだしも、例えばここで紹介されているような結合を駆使しまくって見やすさだけを求めた神エクセルを渡されることもしばしばです。
フォーマットが非統一だったり結合されていたり文字コードがめちゃくちゃなことはしばしばあります。
なるべく効率的にはやろうとしますがかなり泥臭くデータを整形しなおさないといけないです。
最近偶然見つけたのですが、@higa4さんのOpenRefineで神エクセルと戦うで紹介されているOpenRefineを使えば討死するデータサイエンティストが少なくなるかもしれないです。
データサイエンティストvsゴミデータ
神エクセルもゴミですが、ここでは形式ではなくデータ内容そのものがゴミである場合を指すとします。
Garbage in, garbage outという言葉が指すように
- 十分なレコード数がない
- 必要な変数がない
- バイアスだらけ
といったデータをいくらこねくり回しても何もわからないです。
しかしそういった状況でも、お客さんや上司の体裁を保つためになんとかするしかない場面も多いです。
そういう時は素直に知りたい仮説を検証できるようなデータを再度取得し直させてもらうか、とりあえずクロス集計とかしてなんとなくの傾向だけ示して鎮めることも必要です。
ちなみにデータにまつわるバイアスは江崎貴裕先生の分析者のためのデータ解釈学入門 データの本質をとらえる技術に詳しく載っています。
データサイエンティストvsパワーポイント
別にOffice製品をディスりたいわけではないのですが、分析結果を報告するかつ非専門家フレンドリーなツールを使う必要があるのでパワポにもよくお世話になります。
しかしテッキーな人は得てしてパワポが苦手です。
上司に以下のようなことを注意されるとその時点で脳死して午後休を取ってしまう人も少なからずいるでしょう。
- フォント
- 文字大きさ
- 色
- スライド縦横比(後で変更するとレイアウトが崩れる)
- 平仄
- グラフそのものやグラフに埋め込まれた文字などの大きさ、位置、色
- PythonでMatplotlibやseabornを使っている人はわかるかと思いますが文字の位置を変えるだけで死ぬこともあります。
これは一度レビューを受けて決まったフォーマットを握っておき、上記のようなことに脳のリソースを使わなくて済むようにするしかないかなと思います。
なお、@code_440さんのPythonでパワポの説明資料(報告書)を生成するにあるように、python-pptxというライブラリでppt as a code的なことができます。
パワポ生成のロジックをPythonコード化してGit管理などできるとサバイブ率が上がると思います。
Google Slideでも同じようなのがあるといいのですが。
データサイエンティストvs有効数字
分析の結果出てきた数値をどこまで厳密に扱うかも、データサイエンティストを悩ませることの一つです。
これは恐らく扱うドメインによって程度が異なるかと思います。
例えば金融のドメインだと完全に厳密でないといけないです。
(自分も、0.0000001円くらいの数値を曖昧にして算出して怒られた記憶があります。)
浮動小数点の扱いが面倒なことも多く、金融界で未だにCOBOLが蔓延るのはそのせいでしょうか。。
逆に、ある広告を出したことによる売り上げの効果が14.87%上がりました!というと、そこは15%でいいのでは?と突っ込まれたりします。
これはおそらく後々プレスリリースや社外プレゼンテーション資料などの宣伝媒体に載せる時に簡便でわかりやすくしたいという意図でしょう。
こういった知識も含めてドメイン知識と呼ぶのだと思います。
面倒ですが、ドメインごとに厳密さの程度を覚えるしかないです。
データサイエンティストvs外部とのデータやり取り
社内のデータリソースから取得できるデータで分析が完結する場合もありますが、クライアントが保持するデータを利用する必要がある場合も少なからずあります。
データ分析では、単体あるいは複数組み合わせると個人を特定できてしまう情報を扱うことがほとんどです。
その場合、データ利用規約などで個人情報の取り扱いを明文化し、契約を締結したりしないといけないです。
また、クライアントからデータを受領する際に、個人情報のマスクを依頼しなければなりません。
やり取りする相手のリテラシーは選べないので、個人情報のマスクの仕方について事細かに指示しなければならない可能性も十分にあります。
慣れない操作を依頼することで、データが欠損したり文字コードが変わっていたりしますが、データ受領後にそれらに対応するのも全てデータサイエンティストです。
なお、データのやり取りの方法は、話題の(?)暗号化zip+パスワードメール方式や、アクセス制限されたクラウド上に置く方式などがありえます。これもクライアントのリテラシーに合わせてやり方を決める必要があります。
クライアント毎に1度個人情報のマスクの仕方やデータやり取りの方法を取り決めておいて、あとはいつもその方法でやり取りするようにするしかないかなと思います。
データサイエンティストvs聴衆の背景知識
仮説を基にデータを分析し、得られた結果を、どんな背景知識を持つ人でも納得感を持てるように説明できないといけないです。
大学の先生とかだと、学習したLight GBMのSHAP値を見せて特徴量重要度はこんな感じです、とかAUCが0.5なのでこの分類器はデタラメに選ぶのと何も変わらないですね。くらいの説明で済みます。
しかし、営業や人事の方と話す際は上記のような説明では当然納得してもらえません。
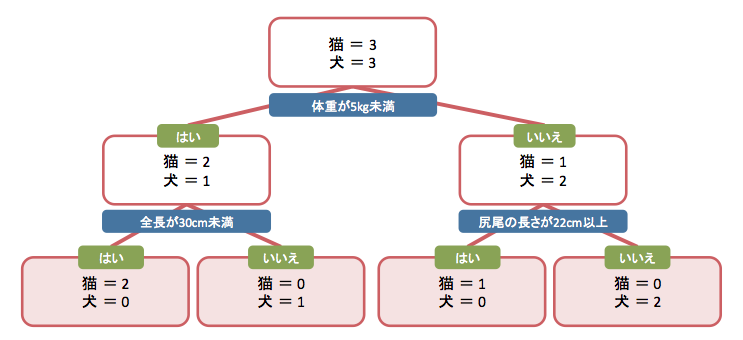
もしLight GBMの結果について話したい場合も、Light GBMだとかそういう専門用語は出さず、最も簡単な決定木の例題を示しつつ自身のケースに当てはめるのが良いかと思います。
その際、以下のような直感的にわかりやすい図を使用しつつ説明するのも重要です。
データサイエンティストvs不正行為
最後に個人的に最も重要な戦いを紹介します。
大学所属の方やPh.D.ホルダーの間では恐らく常識とされる、p-hackingやasterisk-seeking, HARKingの類です。
大まかな定義は以下です。
- p-hacking
p<0.05になることがわかっているデータセットのみを解析対象とすることです。 - asterisk-seeking
p<0.05になるまでデータ量を増やすことです。 - HARKing
Hypothesizing After the Results are Knownの略。検証してからそれに合うように仮説を作り替えることです。
よほど専門的な訓練を受けた人でない限り、これらが不正であることに気づけないです。
上司から、本人は意図しているわけではないがHARKingに当たる指示を受けて頭を悩ませる若きデータサイエンティストは非常に多いと思います。
企業人であるとクライアントに納得してもらうことが第一なので、ほとんどバレるリスクのない上記のような不正が好まれるのが実情です。
不正行為と戦う勇気のあるデータサイエンティストは、上司に正直に相談してみた方がいいです。
上司にリテラシーを期待できない場合は、信頼できる大学の先生などに共同研究を依頼して、その先生を介して不正を指摘してもらうといった回りくどい方法も考えられます。
いずれの方法も取れない場合は、ご自身のスキルレベルを上げてデータ分析リテラシーの高い企業へ移ることをお勧めします。
おわりに
データサイエンティスト(に限らずでしょうが)は知的営みとは程遠いような非本質的な戦いを数多く強いられます。
分析のキラキラした瞬間だけを切り取った情報がほとんどのため、上記のような非本質的な作業に辟易される方も多いのではないでしょうか。
この記事を機に、それらをいかに避けるか・効率よくこなすかに対して考える人が増え始めると幸いです。
もちろん今回取り上げたもの以外にも様々な戦いがあると思いますので、コメント欄での活発な議論をお待ちしています(誤りの指摘も歓迎です)。