
white, inc の ソフトウェアエンジニア r2en です。 自社では新規事業を中心としたコンサルタント業務を行なっており、普段エンジニアチームでは、新規事業を開発する無料のクラウド型ツール を開発したり、新規事業のコンサルティングからPoC開発まで携わったりしています
PoC開発フェーズから運用フェーズでの開発の引き継ぎや、既存のソフトウェアの運用などにおいて、インタラクティブにソースコードを理解できるツールがないか模索していたところ、SOURCETEAILを見つけたので今回は触ってみたので共有させてください

概要
SOURCETEAILは、開発者が他人の書いたソースコードを多大な時間を費やして理解しないように、ソースコードを解析し、可視化することで、生産的にコーディングを行えるよう支援するツール
TL;DR
実際に使って見ての感想は、操作が簡単でツールについて覚えることが少ないのに、割と見やすくて、割と使いやすい印象
完全に全容が理解できるわけではないにしろ、確実にソースコードを解読する手助けをしてくれると思うので、今後も使い続ける価値はあると思う
SOURCETEAIL インストール方法
https://www.sourcetrail.com/
sourcetrailのサイトへ飛び、ダウンロードボタンをクリック
sourcetrailのgithubのページに飛ぶため、自分のOS環境のイメージをダウンロードする
解凍してアプリケーションに移動させる

SOURCETEAIL 使用方法
起動すると以下の画面になる。
New Projectを押す。
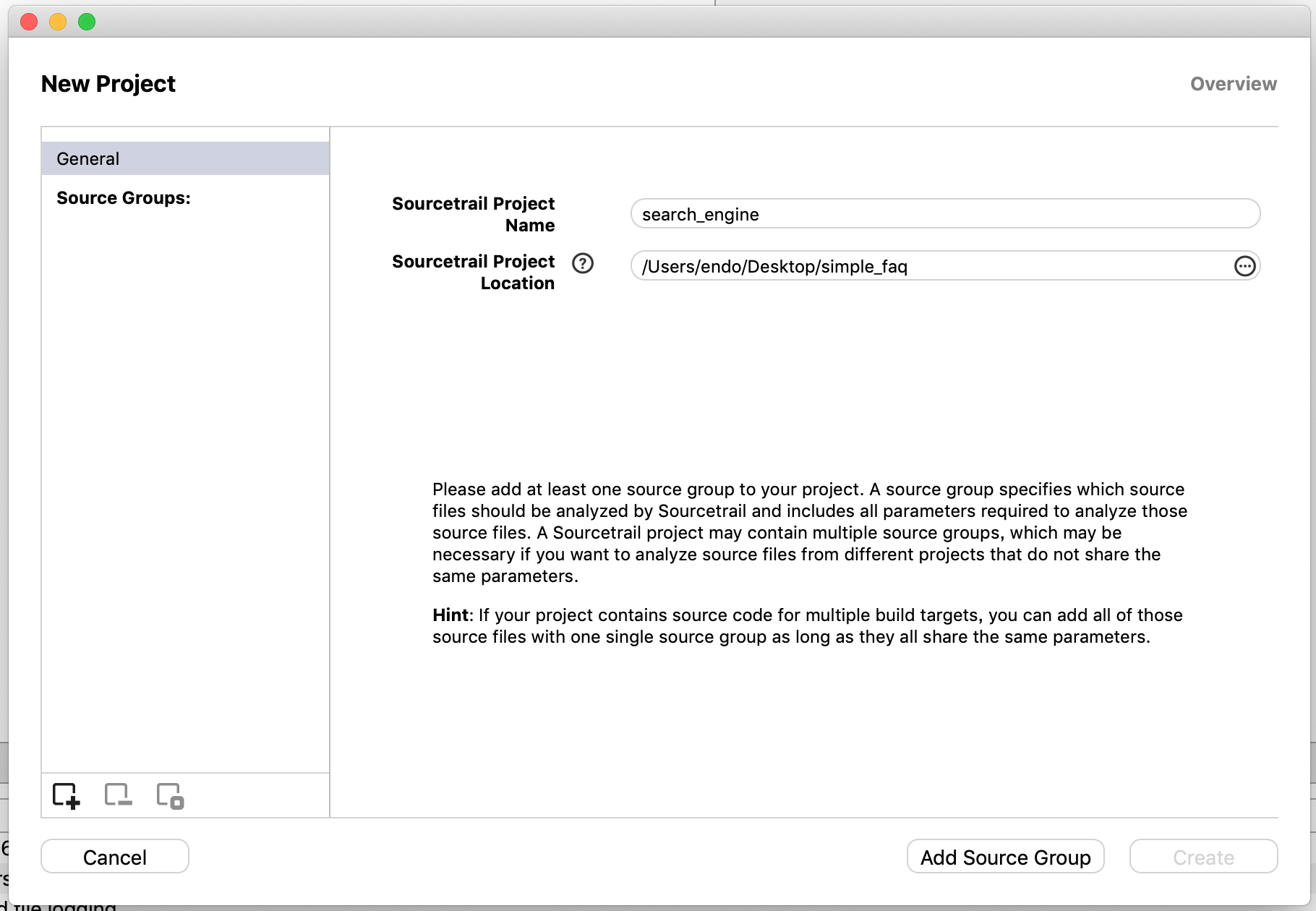
soucetailが静的解析した時に、解析したリポジトリ(ディレクトリ)に、ファイルが自動的に生成される。その時のために、project名とproject場所を選択する
add source groupを選択する
自分が使うプログラミング言語を選択してnextを選択する
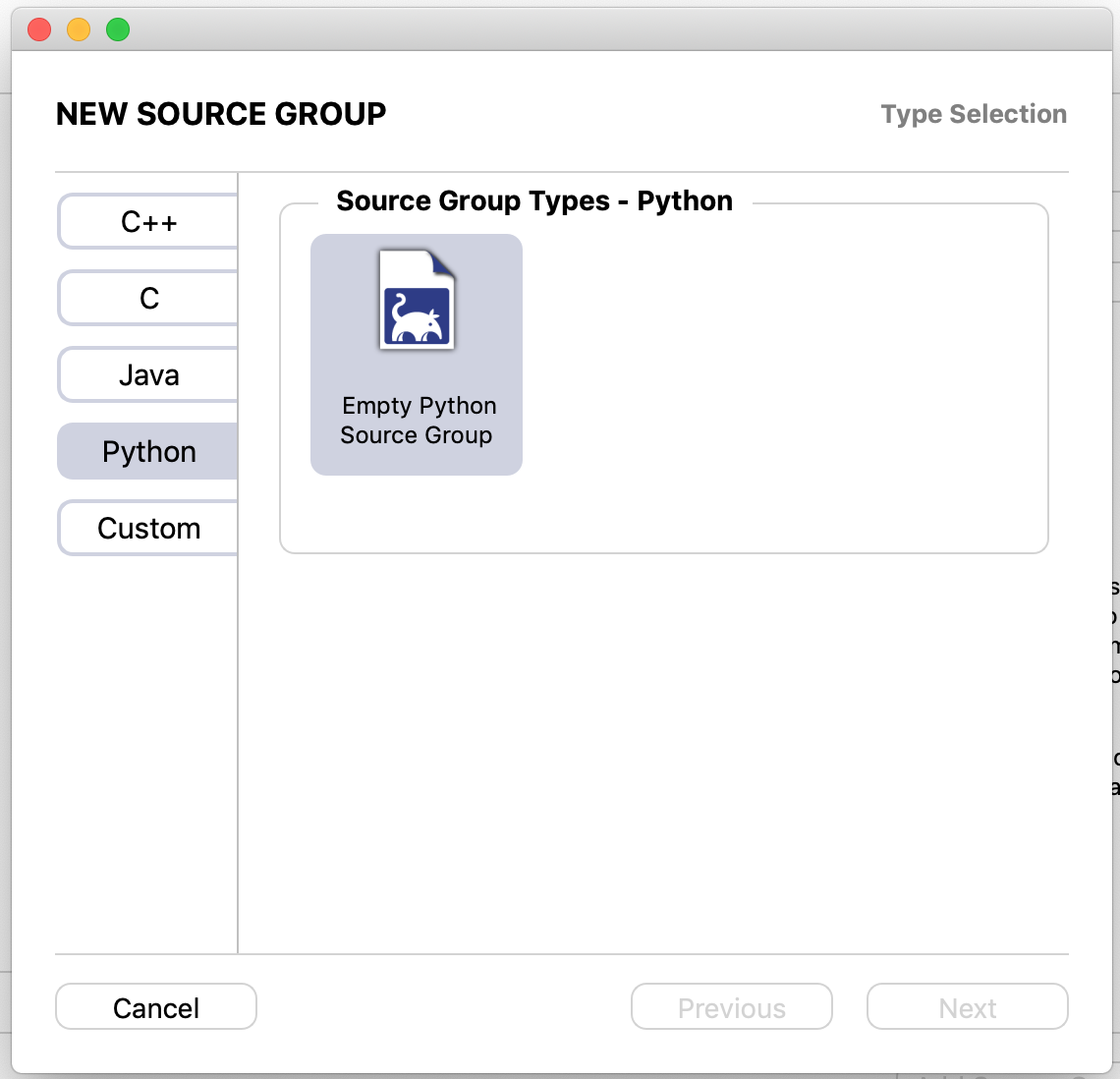
言語の環境や、外部モジュール、当該モジュールなどをここで入力する
ドラッグ&ドロップに対応しているため、当該リポジトリをそのままFiles & Directories to Indexに落とす
※ 環境や外部モジュールを選択しないでも動作する
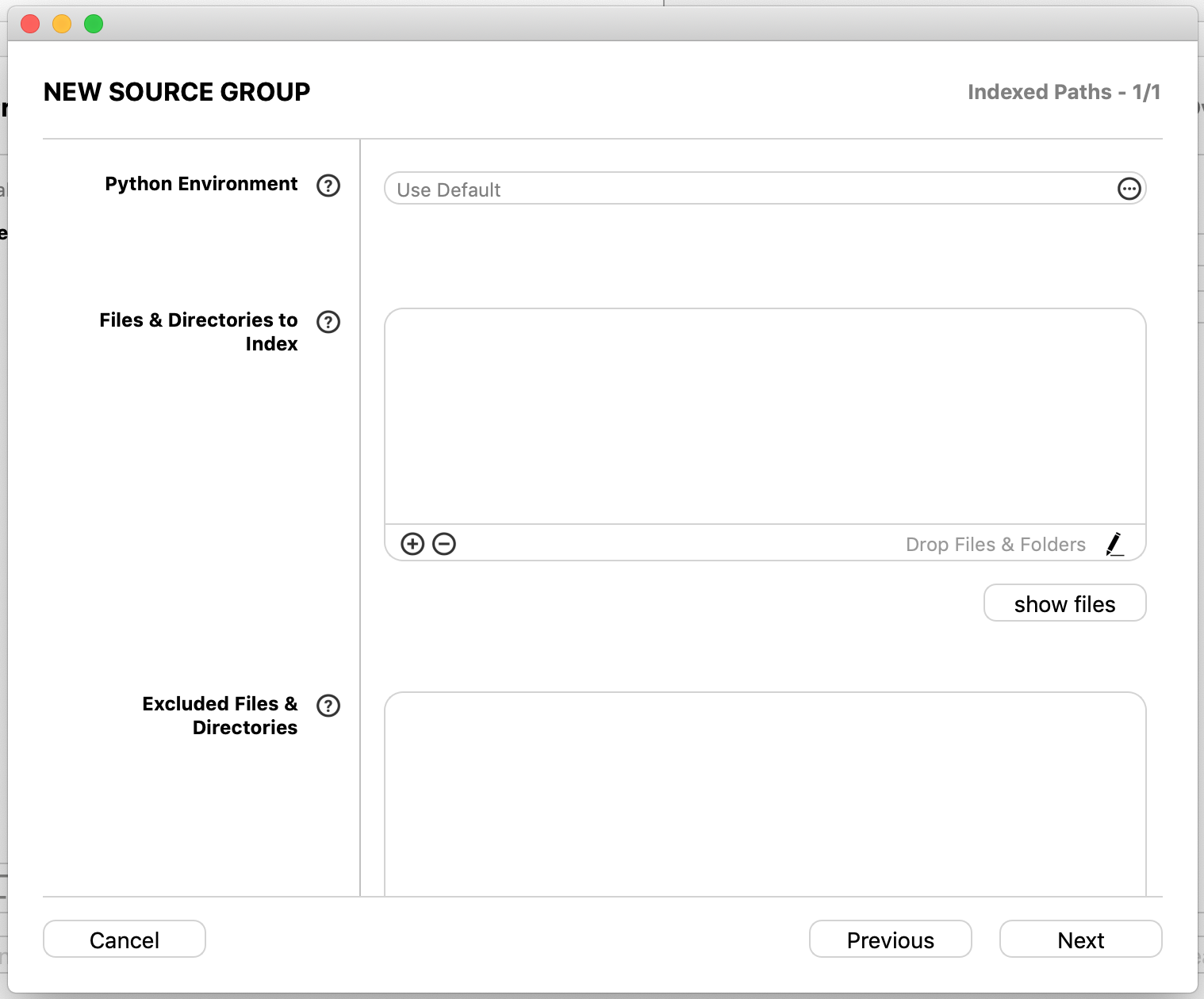
ドロップしたファイルを上記画面のshow filesで参照した画面
きちんとインポートされている
ある程度記入が終われば、createを選択する
ソースコードの静的解析をする画面が表示されるため、startを選択する
下記フォルダのように、seach_engine.srctrlbm, seach_engine.srctrldb, seach_engine.srctrlprjが生成される
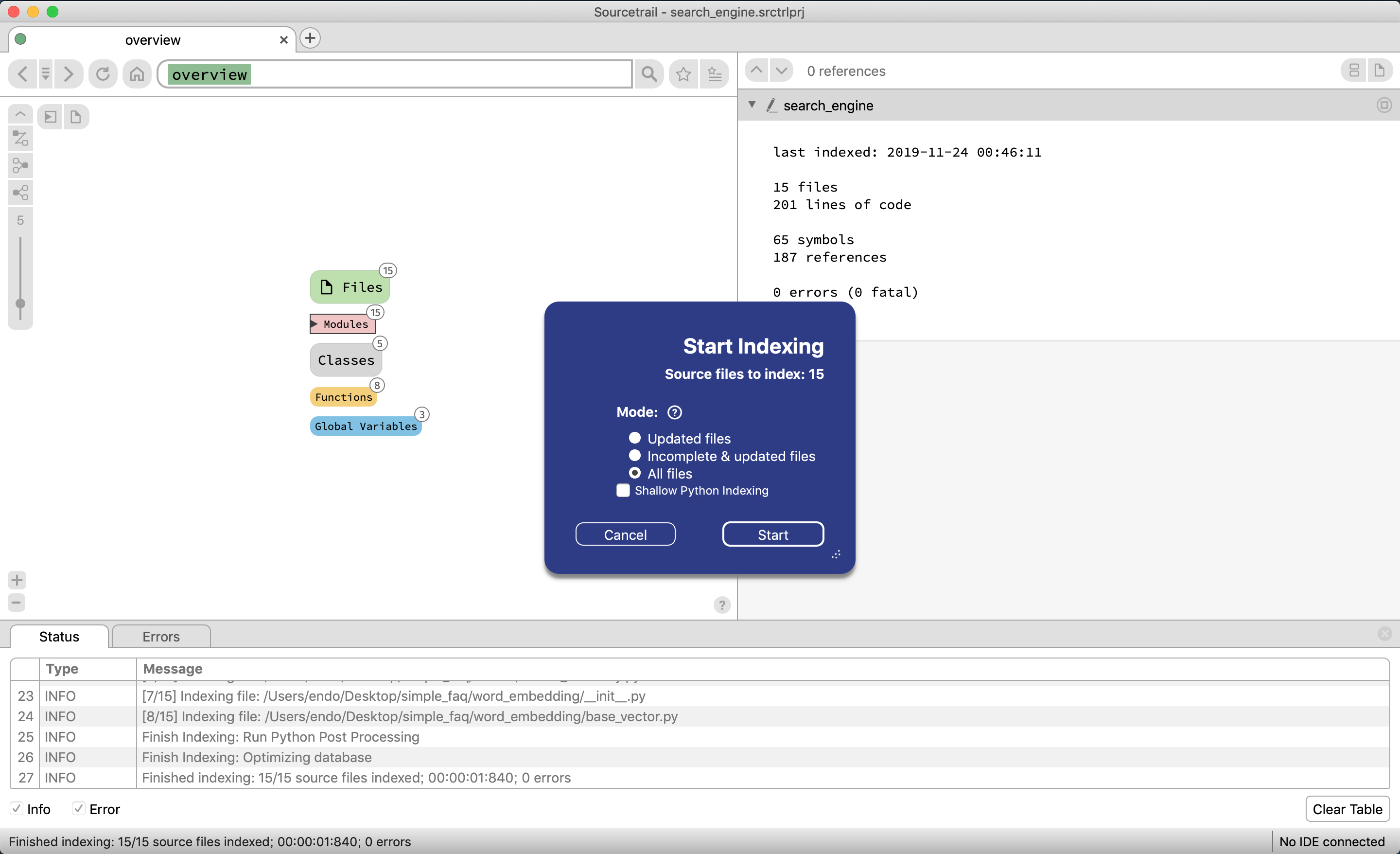
再度静的解析をより深くしてくれるらしいのでstart in-depth indexingを選択する

startを選択する
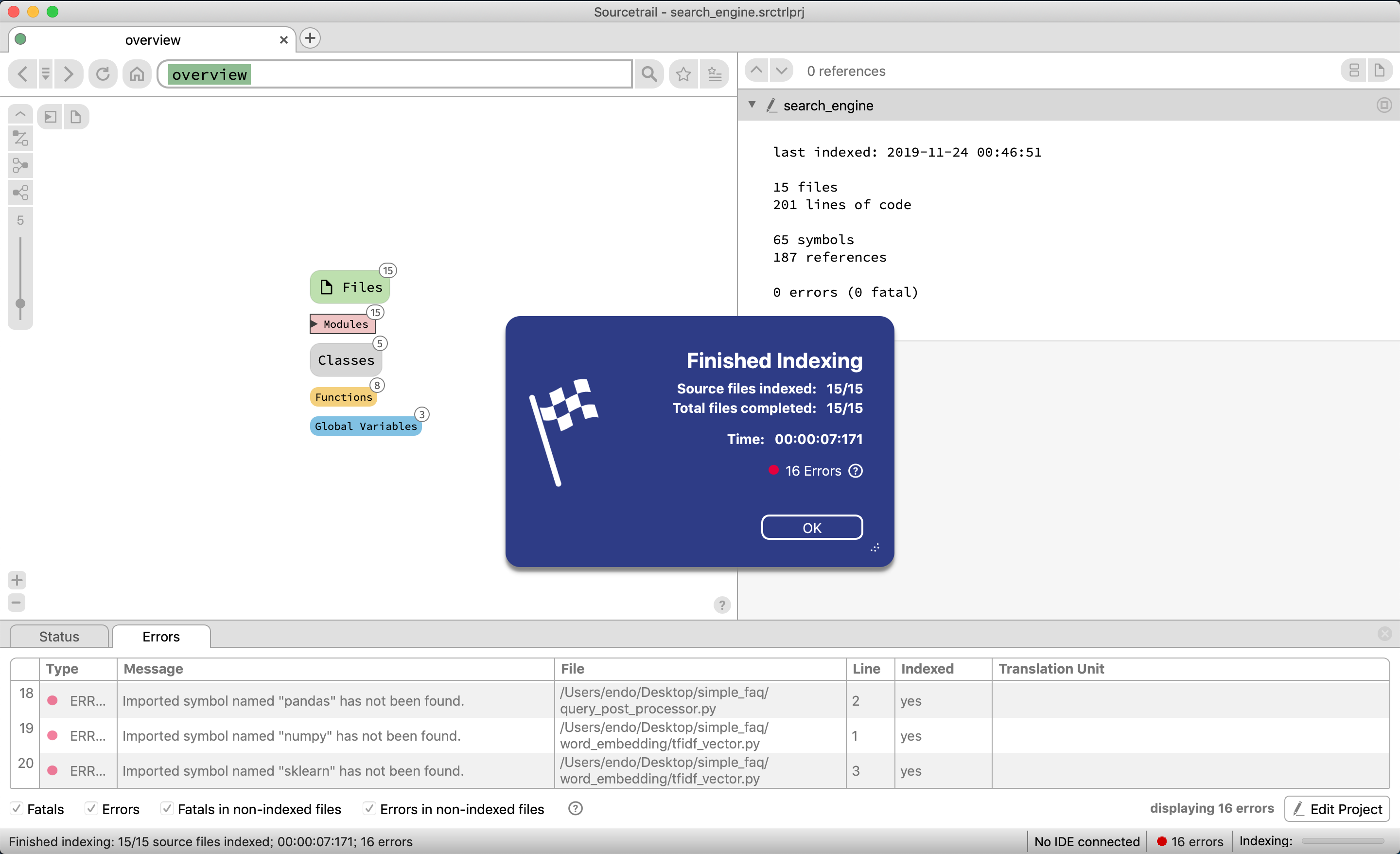
エラーが発生しているが、今回外部モジュール(numpy, pandas等々)を最初の設定の時に参照しなかったため。今回はそこまで差し支えないのでこのまま進める
ソースコード概要(モジュール・クラス・関数・変数)
それではソースコードの構成要素を表示できているか見てみる
リポジトリに存在するファイル群がアルファベット順で表示される
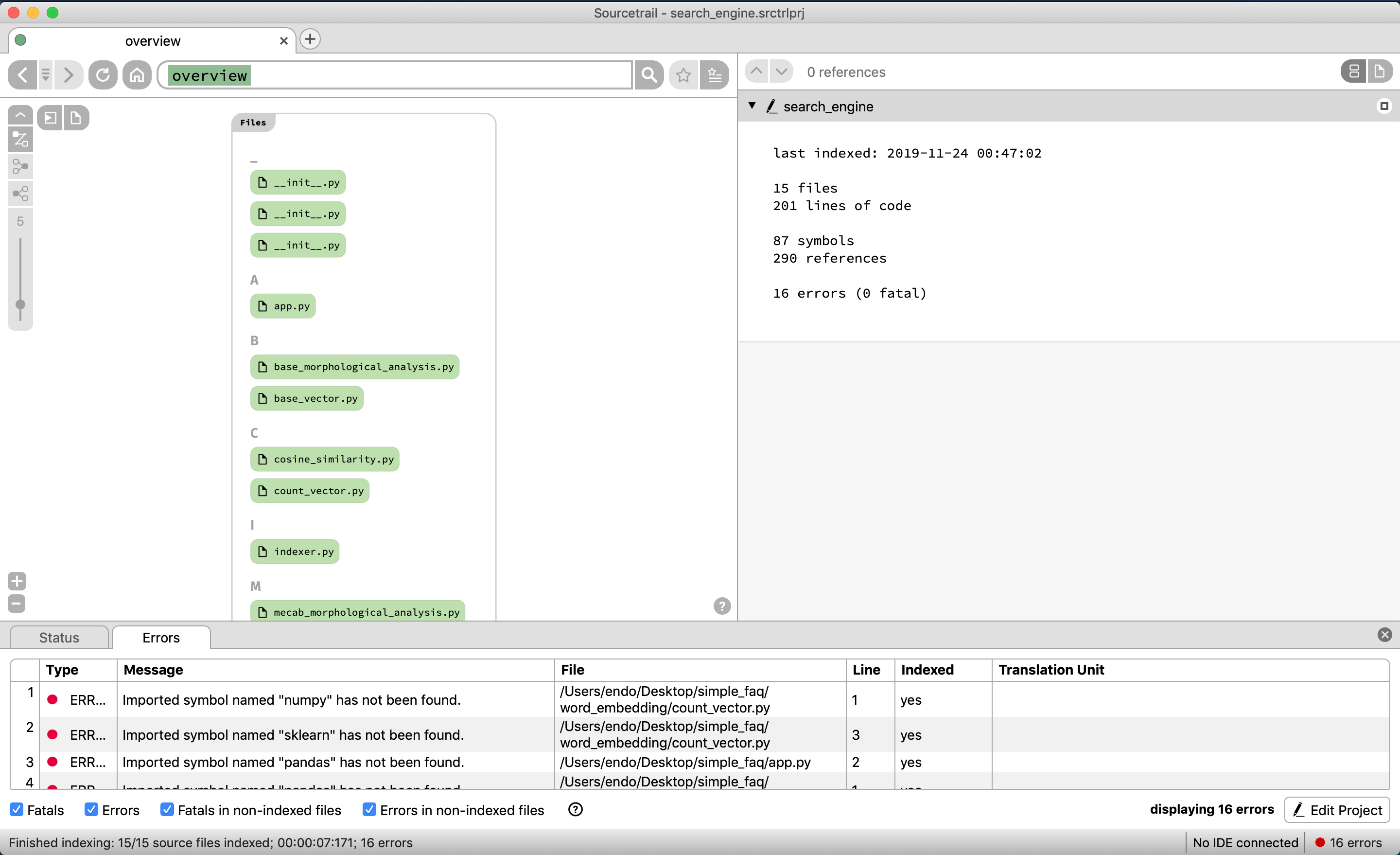
リポジトリに存在するモジュール群がアルファベット順で表示される
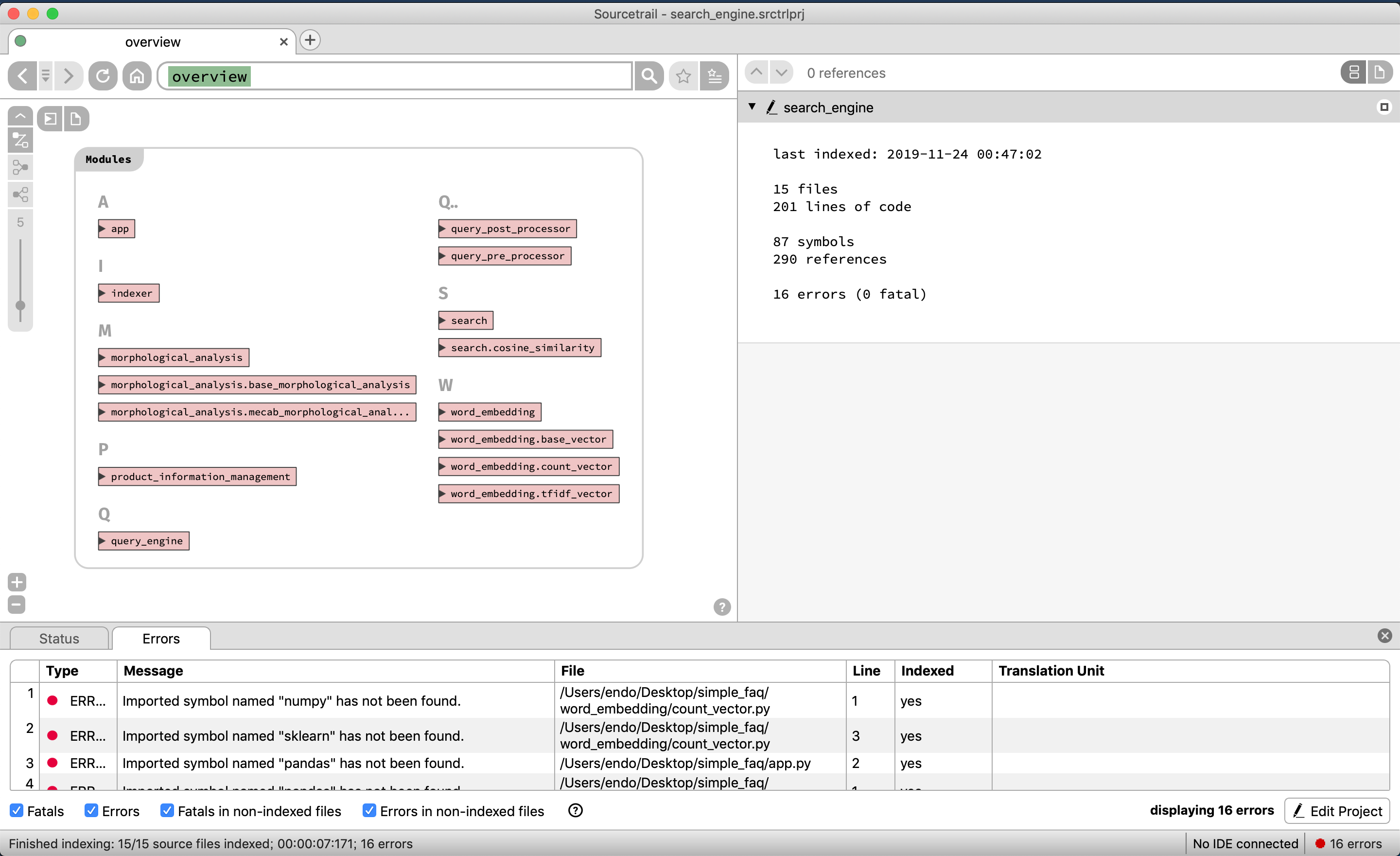
リポジトリに存在するクラス群がアルファベット順で表示される
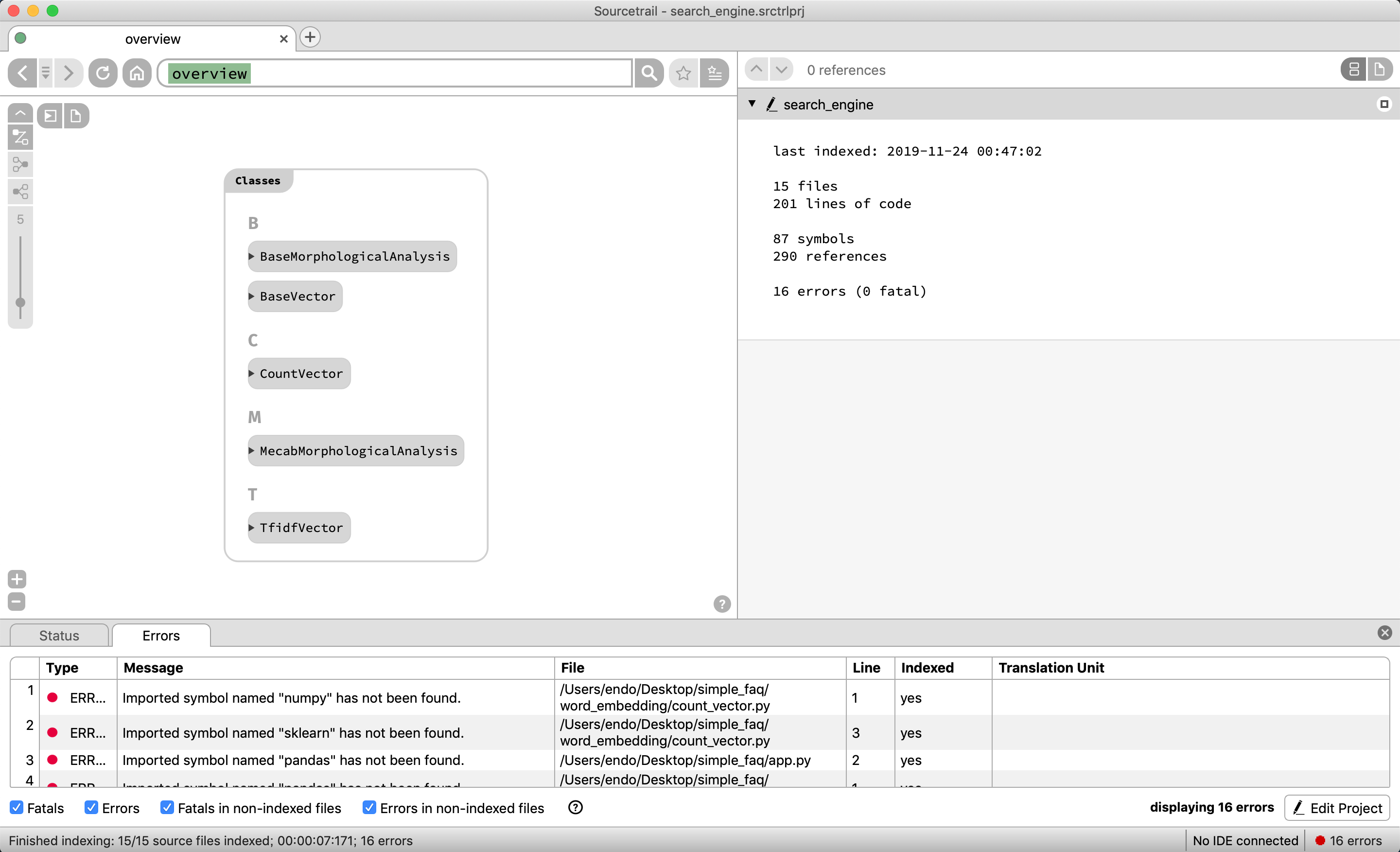
リポジトリに存在する関数群がアルファベット順で表示される
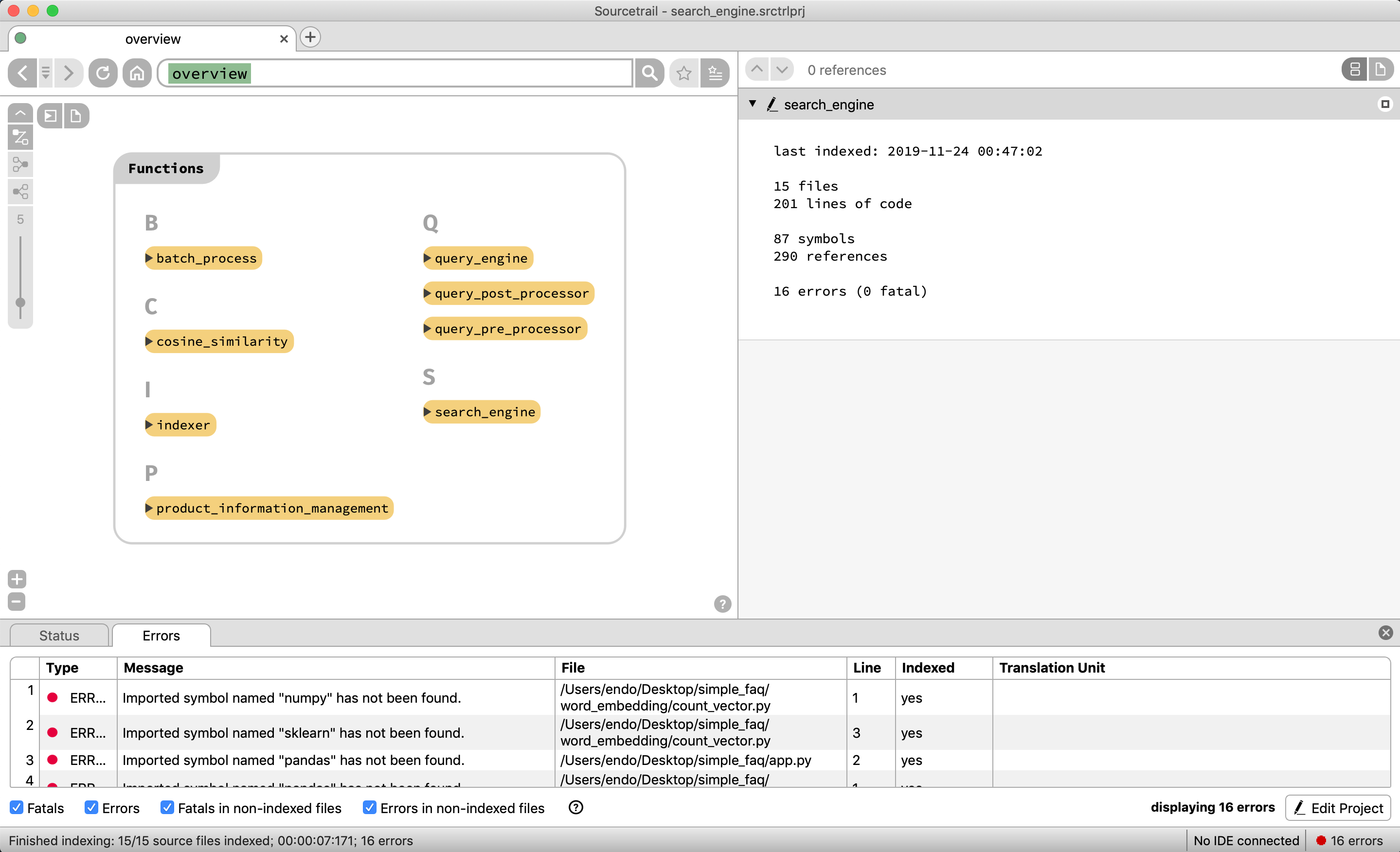
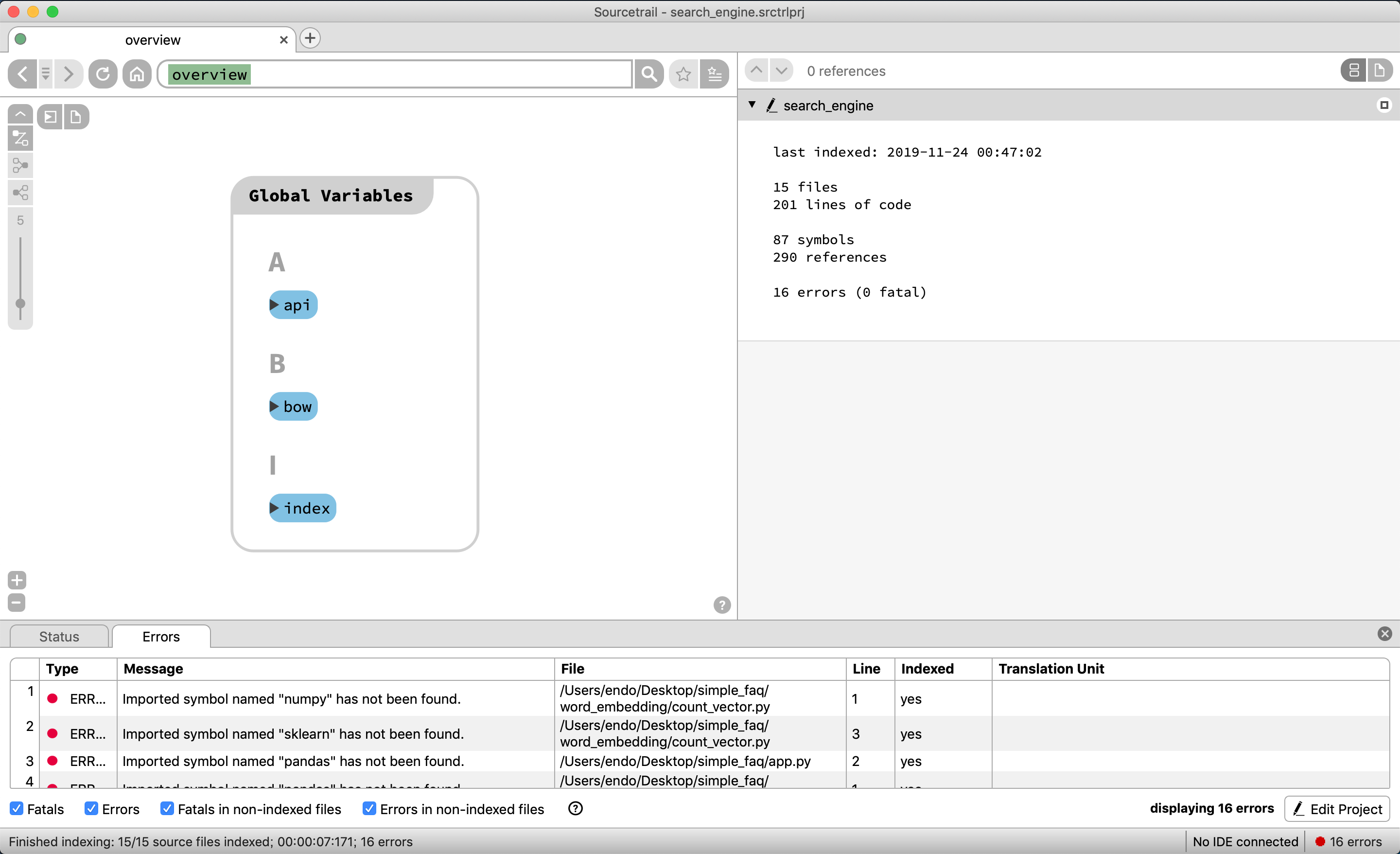
リポジトリに存在するグローバル変数群がアルファベット順で表示される
ソースコード解析(モジュール)
それではソースコードのより詳細な解析や依存関係が表示されているかどうか見ていく
まずはモジュールを見てみる
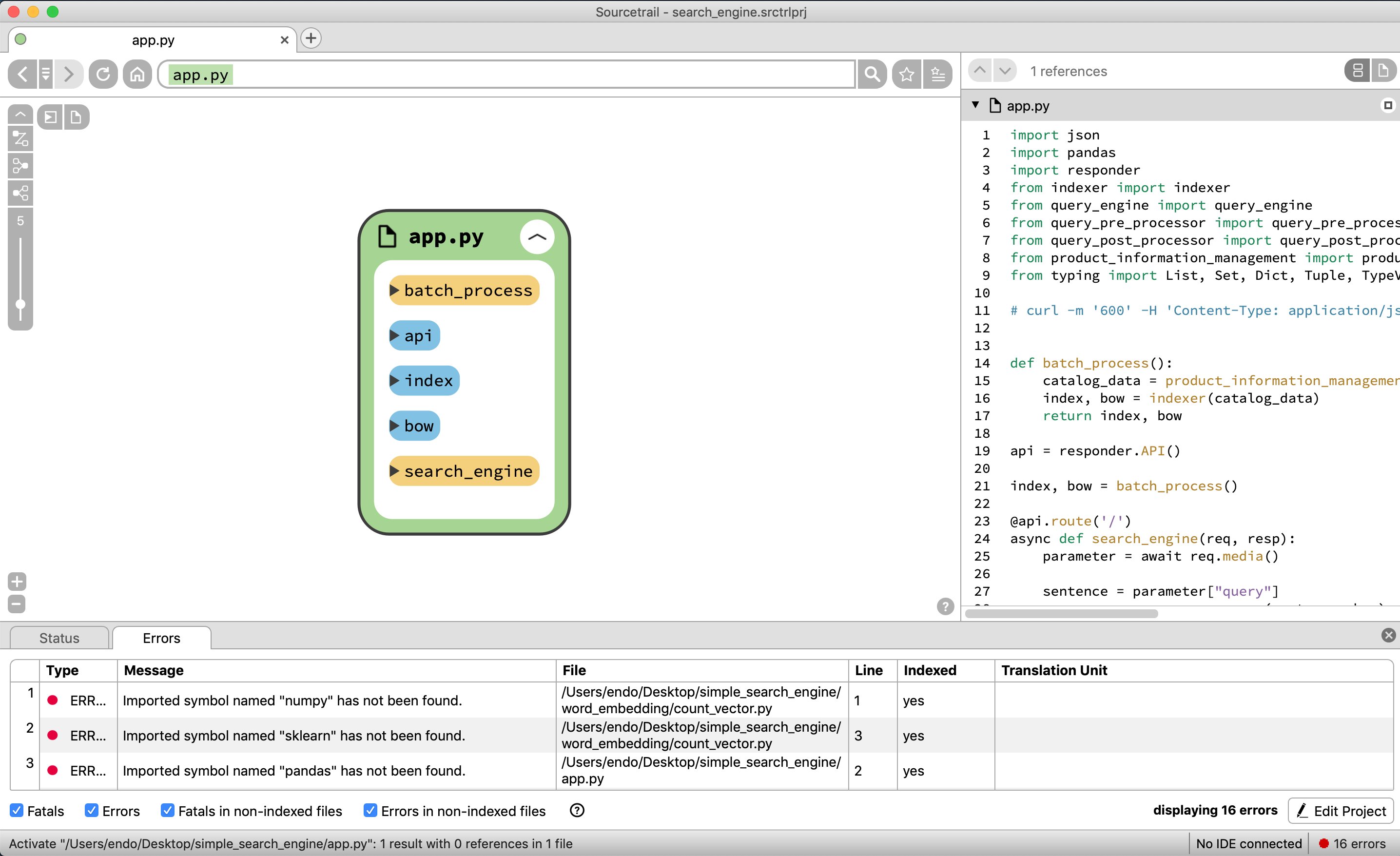
app.pyファイルには、responder serverを起動しているため、グローバル変数にapiを呼び、
本来リアルタイムAPiではなくバッチ処理しておくべきものであるが、
今回簡易的な検索エンジンを作成しているため、データのインデックスを作成し、初回起動時のみに作成するため、グローバル変数に存在する
関数ではindexとbowを作成するためのbatch_process関数が存在していたり、検索エンジンAPIであるsearch_engineが存在する
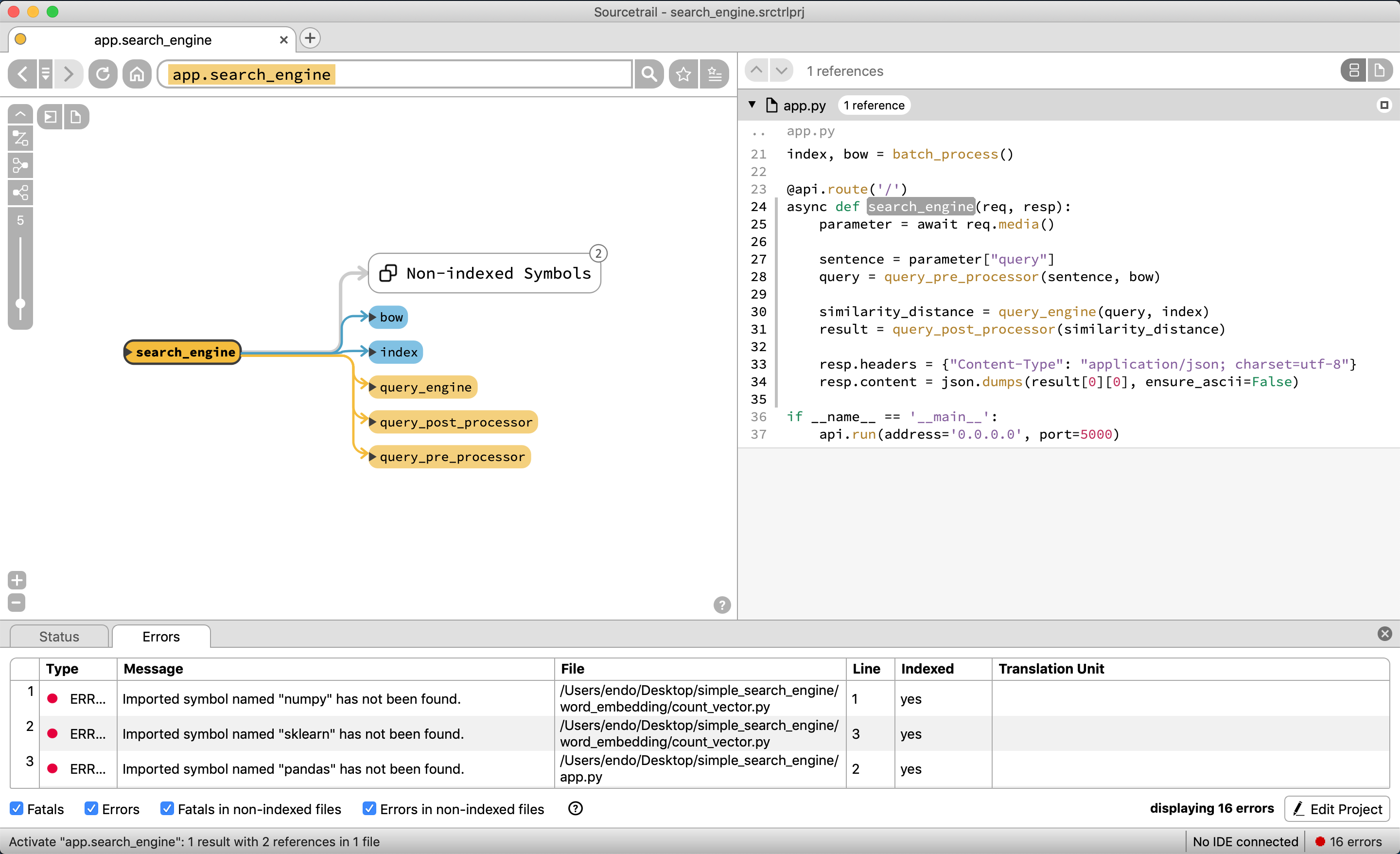
今回は、app.pyの中のsearch_engineが全ての処理のおおもとになるため、この関数を選択してみてみる。
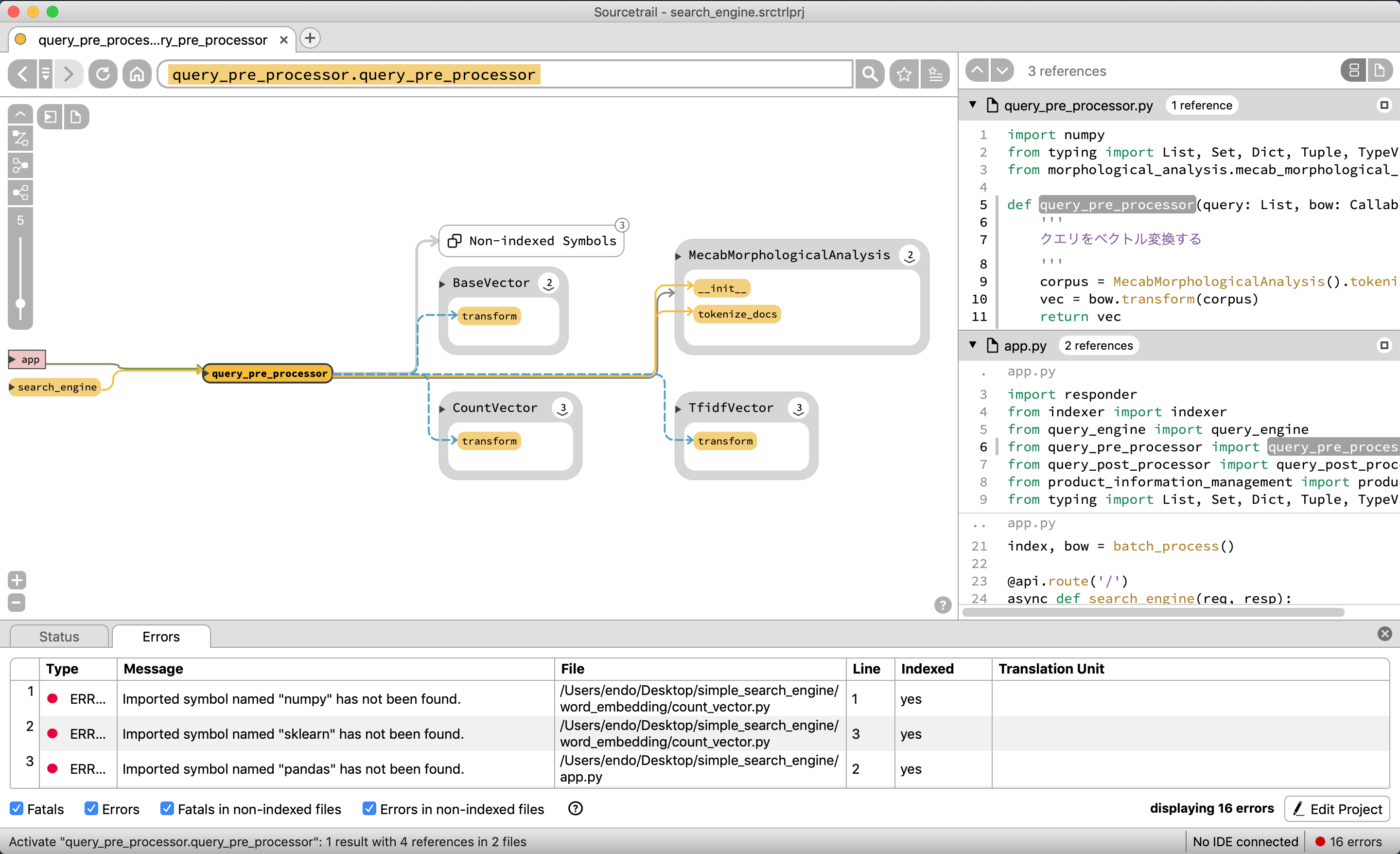
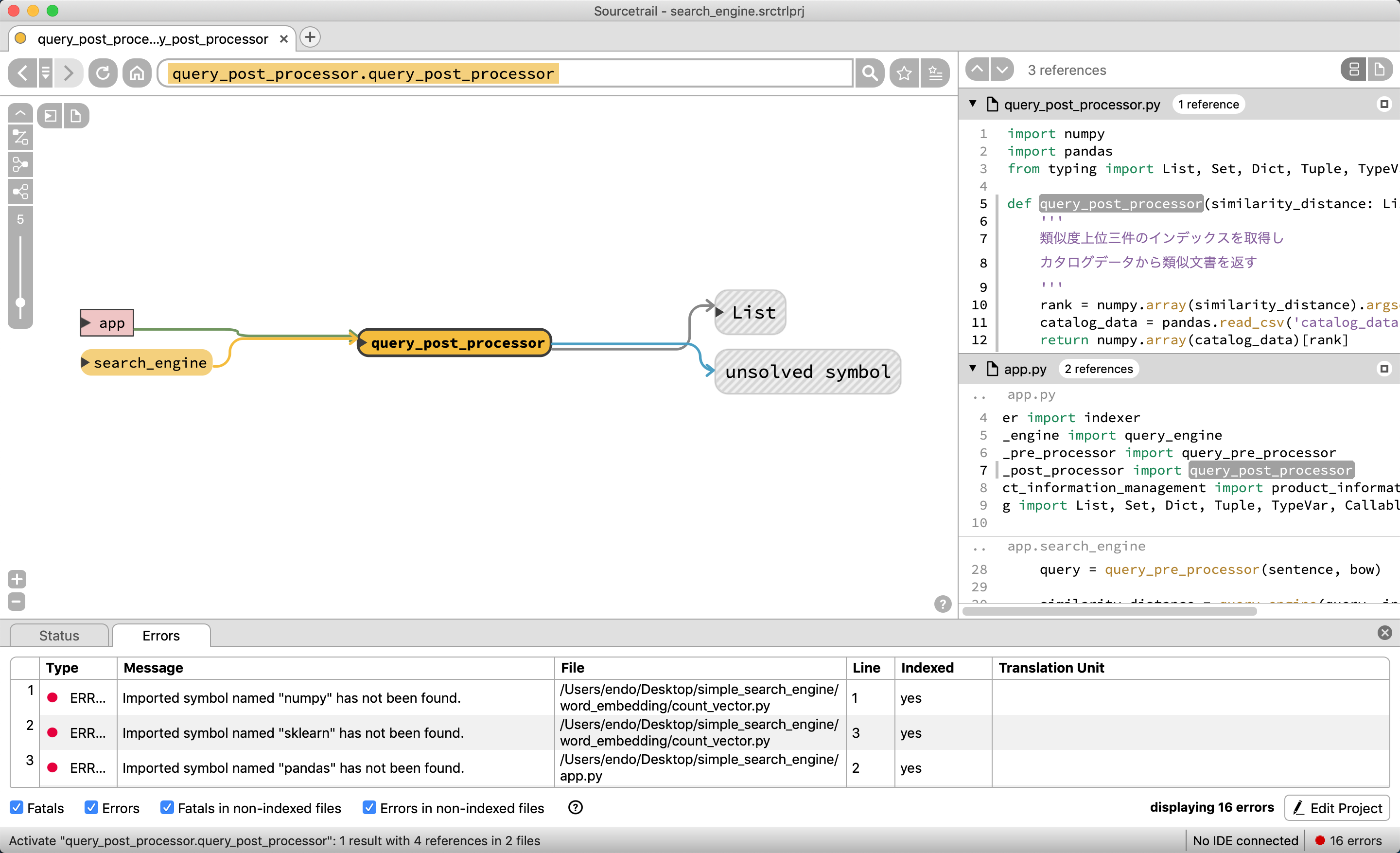
グローバル変数のbow, indexと、関数のquery_engine, query_post_processor, query_pre_processorで構成されていることがわかる。
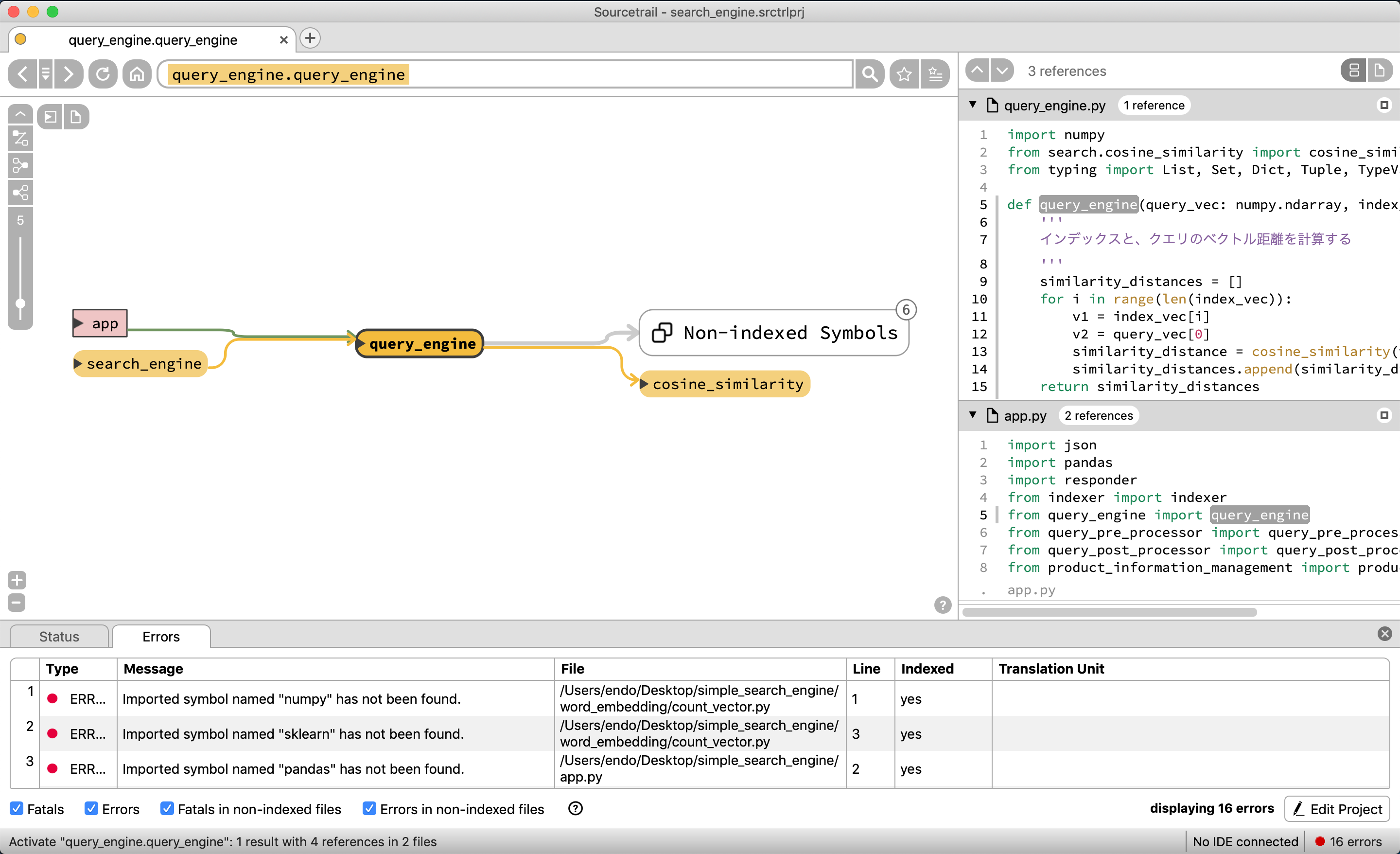
もう少し深くみるために、query_pre_processorを選択する
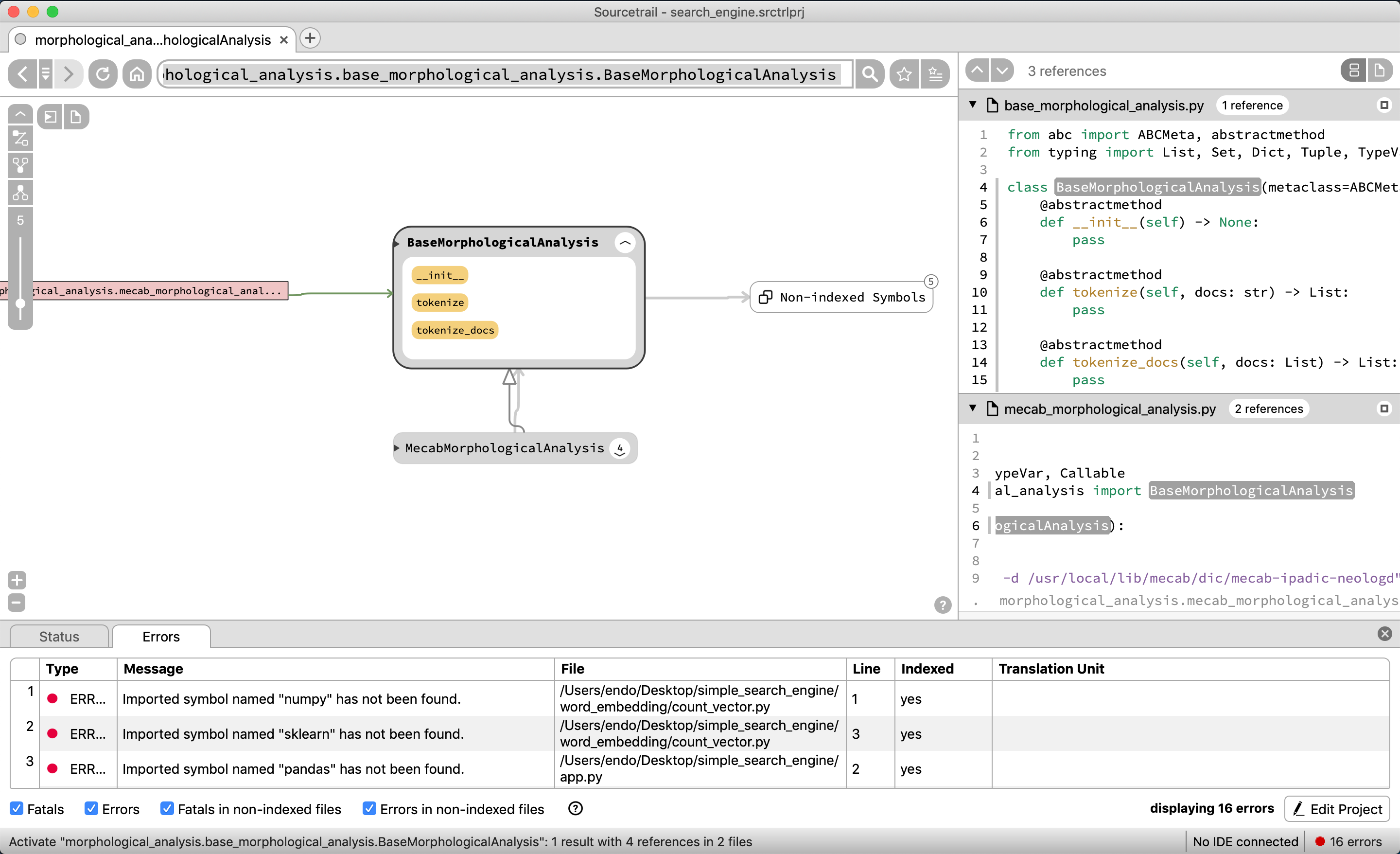
残念ながら、BaseVectorクラスを継承して、CountVectorやTfidfVectorのクラスが存在するが、この図表だと依存関係がわかりづらい。
MecabMorphologicalAnalysisも本来はBaseMorphologicalAnalysisクラスを継承しているのだが、それもぱっと見では表示されない。
他もそれぞれ見ていく
query_engineはcosine_similarityを使っていることがわかる
query_post_prosessorは他クラスや関数を使わずに閉じていることがわかる
ソースコード依存関係(クラス)
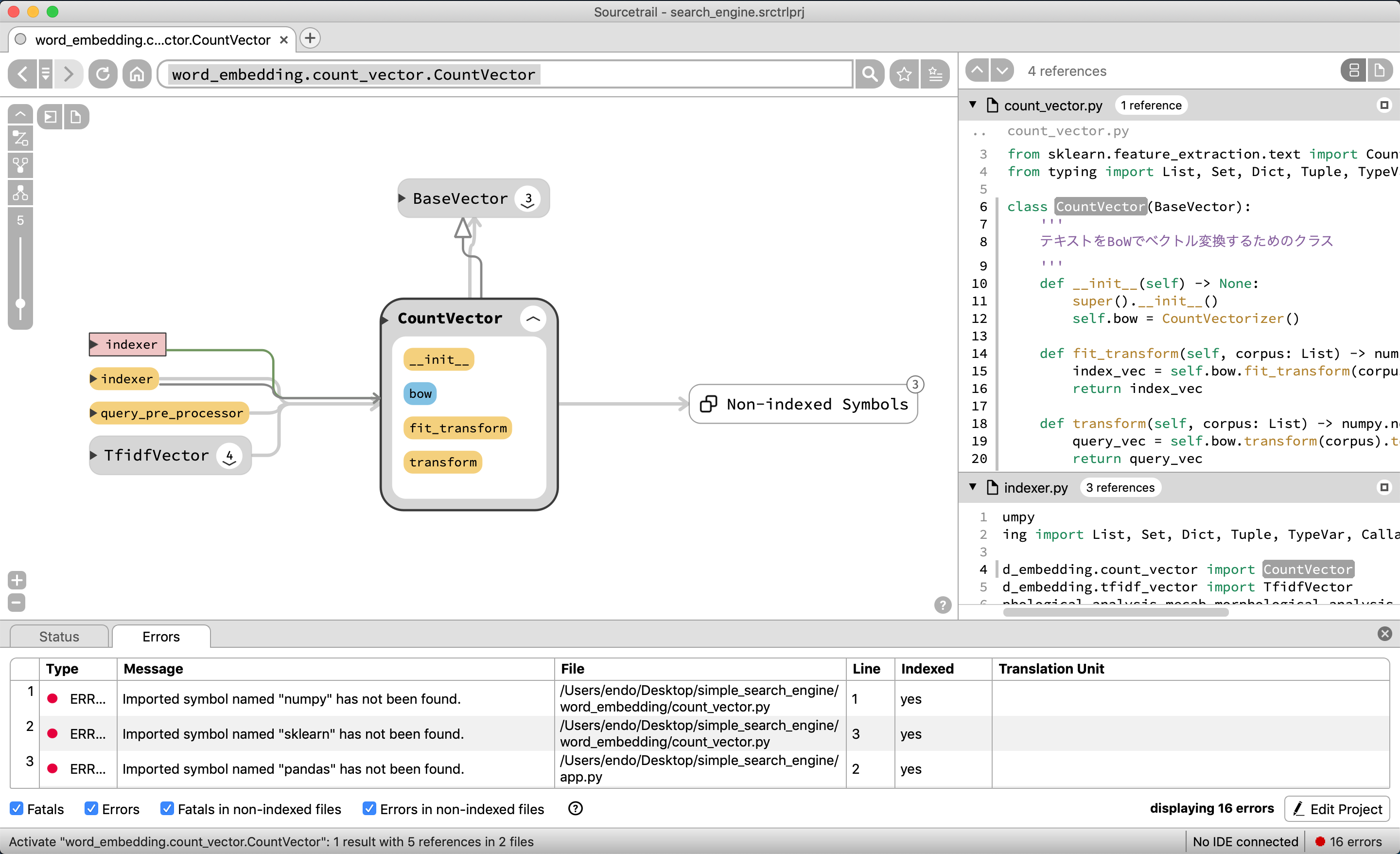
CountVectorをみると、BaseVectorから継承していることがわかる
また、indexerモジュール、indexer関数、query_pre_processor関数から呼ばれていることがわかる
逆にBaseVectorを見てみると、count_vectorモジュールや、tfidf_vectorモジュールから呼ばれ、
CountVectorクラスや、TfidfVectorクラスの親であることがわかる
使用するソースコード
ここの部分はSOURCETEAILには関連がないので、何を解析しているのかをより深く理解したい場合に読んで欲しい
このソースコードを選んだ理由としては、複数ファイル(モジュール)あるシステムでかつ、ある程度依存関係があるコードでプロジェクト等でも使用できるかどうかを検証しつつ、理解がしやすいシンプルな構成のものを考えたときに該当するコードが簡易検索エンジンだった為
概要
ユーザがAPIに対して、「ワンワンって鳴き声の動物はなに?」というクエリを投げると、APIが内部にデータとして保持している以下の質問リスト「鼻の長い動物はなんですか?」、「首の長い動物はなんですか?」、「百獣の王って誰ですか?」、「にゃんにゃんって鳴き声の動物はなんですか?」、「ワンワンって鳴き声の動物はなんですか?」から、もっともクエリに近い質問文を選択肢、それに対となる答えの「犬」という答えをレスポンスとして返すシステムになっている
論理構成
検索エンジンの理論的な構成要素は以下を参考にしている
検索したいデータをプロダクト情報管理を通して、前処理を行いインデックスとして生成しておき、ユーザからのリクエストで検索クエリが飛んできたら、同様の前処理をクエリプリプロセッサが行い、クエリエンジンで同質の要素を検索し、結果をクエリポストプロセッサで整形して、レスポンスとして検索結果を返すという至極シンプルで最低限の検索エンジンである
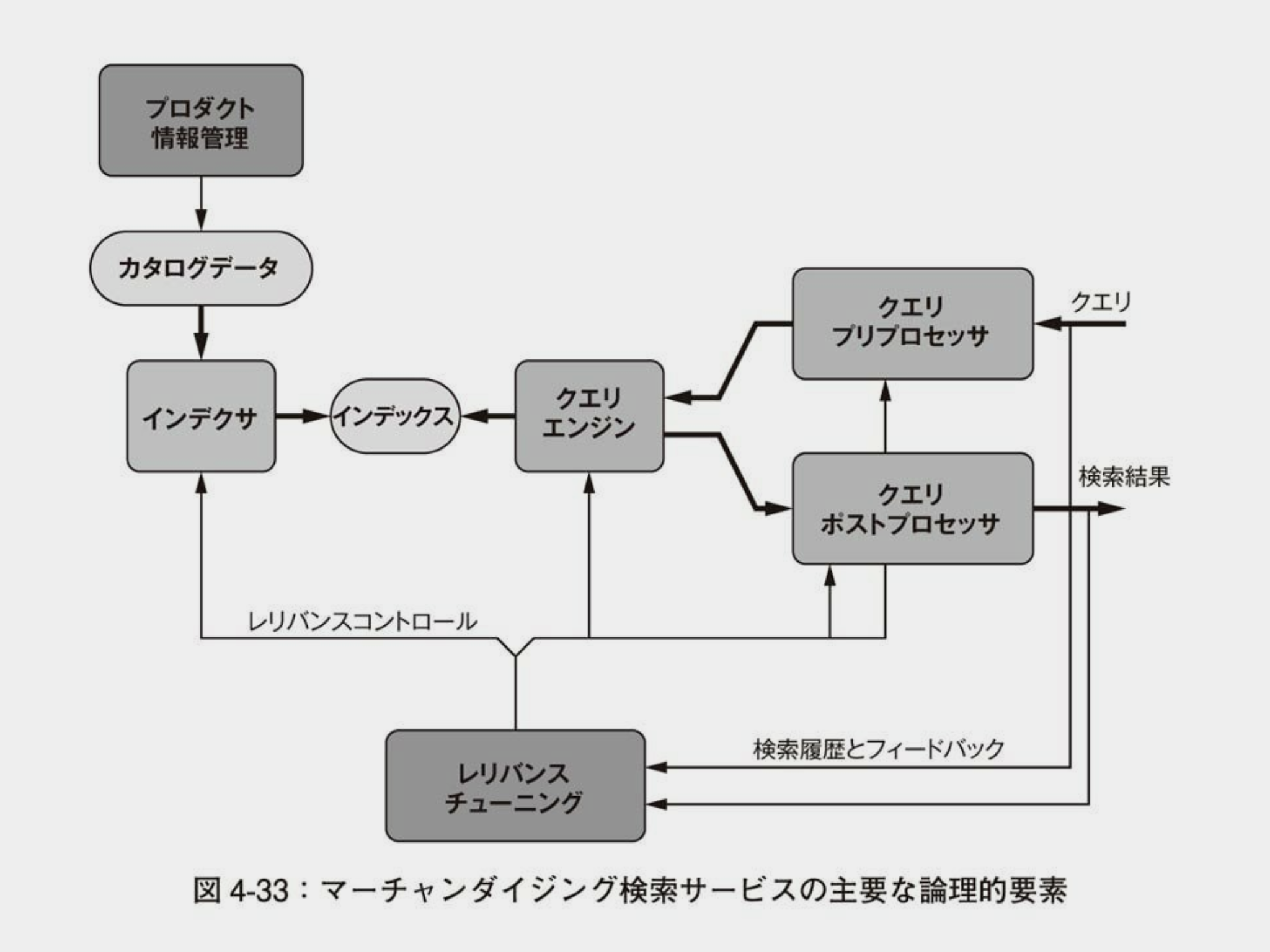
AIアルゴリズムマーケティング 自動化のための機械学習 の書籍から図表をお借りしました
あまり界隈で話題になってないような気がしますが、検索やレコメンドをやりたい人には、ものすごい学びが多い書籍なので是非みなさん読んで欲しいです
勝手に引用している為、著者や関係者からご連絡があった場合は即時削除させていただきます
ディレクトリ構成
具体的に落とし込むと以下の形になる
レリバンスチューニングの部分は今回はビジネス要件によって変動する部分なので、今回は割愛している
今回の記述したソースコードをgithub上にあげているので詳細に見たい場合は下記にアクセスしてください
├── app.py <- Responder APIサーバ 検索のリクエストを受けてつけて、検索結果を返す
│
│
├── indexer.py <- カタログデータ(文書)の前処理をして、インデックス(前処理済み文書のベクトル化)を生成する
│
│
├── query_engine.py <- クエリとカタログデータとのマッチングとスコアリングを行う
│
│
├── query_pre_processor.py <- クエリ(ユーザの検索のリクエスト)を、インデックス形式に処理をするindexerで行う前処理とほぼ同様のことを行う
│
│
├── query_post_processor.py <- クエリとカタログデータのマッチングの結果から検索結果を生成する
│
│
├── product_information_management.py <- 検索されるデータ群を操作する
│
│
├── catalog_data <- 検索されるデータを格納
│ │
│ │
│ ├── answer.csv <- クエリが求める回答のデータを格納
│ │
│ │
│ └── question.csv <- クエリと同質の質問のデータを格納
│
│
├── morphological_analysis <- 自然言語を形態素解析器するツール群
│ │
│ ├── base_morphological_analysis.py <- ベースとなる形態素解析機の親クラス
│ │
│ │
│ ├── mecab_morphological_analysis.py <- 形態素解析器のmecabが格納
│ │
│ │
│ └── __init__.py
│
│
├── search <- ベクトル化されたクエリと、カタログデータの類似性を検索する
│ │
│ ├── cosine_similarity.py <- 類似性をコサイン類似度で検索する
│ │
│ │
│ └── __init__.py
│
│
└── word_embedding <- クエリとカタログデータの検索を可能にするデータ構造、インデックスを作成する
│
│
├── base_vector.py <- ベースとなるベクトル変換器の親クラス
│
│
├── count_vector.py <- BoWカウントベースのベクトル変換器
│
│
│
├── tfidf_vector.py <- BoW Tf-Idfベースのベクトル変換器
│
│
└── __init__.py
感想
実際に使って見ての感想は、操作が簡単でツールについて覚えることが少ないのに、割と見やすくて、割と使いやすい印象
完全に全容が理解できるわけではないにしろ、確実にソースコードを解読する手助けをしてくれると思うので、今後も使い続ける価値はあると思う