Abstract: 機械学習モデルと結果を解釈するための手法
1. どの特徴量が重要か: モデルが重要視している要因がわかる
- feature importance
2. 各特徴量が予測にどう影響するか: 特徴量を変化させたときの予測から傾向を掴む
- partial dependence
- permutation importance
3. 予測結果が出たときの特徴量の寄与: 近似したモデルを作り、各特徴の寄与を算出
- LIME(Local Interpretable Model-agnostic Explainations)
- SHAP(SHapley Additive exPlanations)
Introduction: 機械学習の解釈性の重要が高まっている
現状、高精度を叩き出した機械学習は、ブラックボックスになりがちで根拠の説明を人間に提示しない
例えば、近い将来、お医者さんが機械学習モデルから導いたモデルから診断する時代になったとき
お医者さん「あなたは糖尿病に今後5年以内になりますよ。」
患者さん「どうしてわかったんですか? 何が原因なんですか!?」
お医者さん「...。 AIがそう判断したからですよ...。」
患者さん「納得できません!」
と、なってしまう。
機械学習モデルが予測結果に対して、なぜその予測をしたのかという説明が必要。
Environment:
実験環境
Python==3.6.8
matplotlib==3.0.3
jupyter notebook
import re
import sklearn
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
%reload_ext autoreload
%autoreload 2
データ
Kaggleのtitanicを使用。
適度なデータ数、カーディナリティの少なさ、解釈しやすさ、皆に認識されてる3点から採用。
Titanic: Machine Learning from Disaster
このコンペは、タイタニック号に乗船した、各乗客の購入したチケットのクラス(Pclass1, 2, 3の順で高いクラス)や、料金(Fare)、年齢(Age)、性別(Sex)、出港地(Embarked)、部屋番号(Cabin)、チケット番号(Tichket)、乗船していた兄弟または配偶者の数(SibSp)、乗船していた親または子供の数(Parch)など情報があり、そこからタイタニック号が氷山に衝突し沈没した際生存したかどうか(Survived)を予測する。
PassengerId – 乗客識別ユニークID
Survived – 生存フラグ(0=死亡、1=生存)
Pclass – チケットクラス
Name – 乗客の名前
Sex – 性別(male=男性、female=女性)
Age – 年齢
SibSp – タイタニックに同乗している兄弟/配偶者の数
parch – タイタニックに同乗している親/子供の数
ticket – チケット番号
fare – 料金
cabin – 客室番号
Embarked – 出港地(タイタニックへ乗った港)
train.head()

前処理
Pythonでアンサンブル(スタッキング)学習 & 機械学習チュートリアル in Kaggle
↑前処理が簡潔で、データをあまりいじっていないので参考にさせていただきました。ありがとうございます。
基本的には前処理により以下の用にビン分割した。(ビン分割した理由は結果を人間が解釈しやすくなるため)
| Value | Age(年齢) |
|---|---|
| 0 | 16歳以下 |
| 1 | 32歳以下 |
| 2 | 48歳以下 |
| 3 | 64歳以下 |
| 4 | それ以上 |
| Value | Fare(料金) |
|---|---|
| 0 | 凄い低い |
| 1 | 低い |
| 2 | 高い |
| 3 | 凄い高い |
| Value | Embarked(出港地) |
|---|---|
| 0 | S 人が多い |
| 1 | C お金持ちが多い |
| 2 | Q 貧困が多い |
| Value | Title(敬称) |
|---|---|
| 0 | Mr |
| 1 | Miss |
| 2 | Mrs |
| 3 | Master |
| 4 | Rare |
| Value | Sex(性別) |
|---|---|
| 0 | female 女性 |
| 1 | male 男性 |
| Value | Pclass(チケットクラス) |
|---|---|
| 0 | 高級 |
| 1 | 中級 |
| 2 | 下級 |
| Value | IsAlone(家族有無) |
|---|---|
| 0 | 家族なし |
| 1 | 家族あり |
full_data = [train, test]
# 客室番号データがあるなら1を、欠損値なら0
train['Has_Cabin'] = train["Cabin"].apply(lambda x: 0 if type(x) == float else 1)
test['Has_Cabin'] = test["Cabin"].apply(lambda x: 0 if type(x) == float else 1)
# 家族の大きさを"タイタニックに同乗している兄弟/配偶者の数"と
# "タイタニックに同乗している親/子供の数"から定義
for dataset in full_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
# 家族の有無 0なら家族なし、1なら家族あり
for dataset in full_data:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
# 出港地の欠損値を一番多い"S"としておく
for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna('S')
# 料金の欠損値を中央値としておく
# 料金の4グループに分ける
for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
train['CategoricalFare'] = pd.qcut(train['Fare'], 4)
# 年齢を5グループに分ける
for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
dataset['Age'] = dataset['Age'].astype(int)
train['CategoricalAge'] = pd.cut(train['Age'], 5)
# 正規表現で姓名を取り出す
def get_title(name):
title_search = re.search(' ([A-Za-z]+)\.', name)
if title_search:
return title_search.group(1)
return ""
for dataset in full_data:
dataset['Title'] = dataset['Name'].apply(get_title)
# 誤字修正
dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
for dataset in full_data:
# 性別を2種類にラベル付 女なら0、男なら1
dataset['Sex'] = dataset['Sex'].map( {'female': 0, 'male': 1} ).astype(int)
# 敬称を5種類にラベル付
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
dataset['Title'] = dataset['Title'].map(title_mapping)
dataset['Title'] = dataset['Title'].fillna(0)
# 出港地の3種類にラベル付
dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
# 料金を4グループに分ける
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Fare'] = dataset['Fare'].astype(int)
# 年齢を5グループに分ける
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1
dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2
dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3
dataset.loc[ dataset['Age'] > 64, 'Age'] = 4 ;
# 必要ない特徴を削除
drop_elements = ['PassengerId', 'Name', 'Ticket', 'Cabin', 'SibSp']
train = train.drop(drop_elements, axis = 1)
train = train.drop(['CategoricalAge', 'CategoricalFare'], axis = 1)
test = test.drop(drop_elements, axis = 1)
データを読み込み、学習させたいデータと正解ラベルに分ける
y_train = train['Survived'].ravel()
x_train = train.drop(['Survived'], axis=1)
x_test = test.values
モデル作成
Gradient Boosting Decision Tree の LightGBMでモデルを作成する。
import lightgbm as lgbm
model = lgbm.LGBMClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
prediction = np.round(y_pred).astype(int)
Method: Feature Importance
x軸が重要度を表し、y軸が上から順に重要な特徴を表示する
plot_importance(booster, ax=None, height=0.2,
xlim=None, ylim=None, title='Feature importance',
xlabel='Feature importance', ylabel='Features',
importance_type='split', max_num_features=None,
ignore_zero=True, figsize=None, grid=True,
precision=None, **kwargs):
Result:
lgbm.plot_importance(model, figsize=(12, 6))
plt.show()
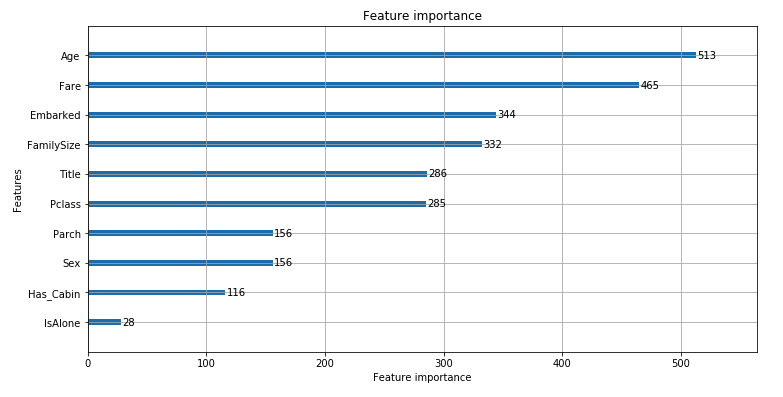
Discussion:
教師あり学習モデルを用いて個々の特徴量の重要性を算出する。モデルが学習時に自動的に算出してくれるのでお手軽に使用する事ができる。
Referances:
https://lightgbm.readthedocs.io/en/latest/_modules/lightgbm/plotting.html
https://qiita.com/hokuto_HIRANO/items/2c35a81fbc95f0e4b7c1#second-level-predictions-from-the-first-level-output